数据结构—字符串
文章目录
- 7.字符串
- (1).字符串及其ADT
- #1.基本概念
- #2.ADT
- (2).字符串的基本操作
- #1.求子串substr
- #2.插入字符串insert
- #3.其他操作
- (3).字符串的模式匹配
- #1.简单匹配(Brute-Force方法)
- #2.KMP算法
- I.kmp_match()
- II.getNext()
- #3.还有更多
- 小结
- 附录:我自己写的string
7.字符串
字符串几乎算得上是我们平时最常用的数据结构了,比如你看到的这篇博客,它也是由一系列的字符组成的。说实话,字符串相关的问题其实多的非常离谱,并且往后的各种问题也非常复杂。
我们可以举这么一个例子,假设我给你一段C语言的代码:
#include <stdio.h>
int main()
{int a = 0;scanf("%d", &a);printf("%d\n", a + 10);return 0;
}
这一段代码在你眼里看来是代码,但是在gcc看来,就是一串可能包含代码的字符串,经过处理之后,我们需要把这段代码解析成下面正确的汇编代码,从而经过之后的链接器等完成最终可执行文件的生成操作,而读入代码,生成汇编文件这个过程就涉及到了有限自动机(FAM) 这个模型,它将一个系统分成若干可数个离散的状态,在识别到特定模式后,进行对应的跳转,最终再进行判断。
.file "a.c".text.section .rodata.str1.1,"aMS",@progbits,1
.LC0:.string "%d"
.LC1:.string "%d\n".text.globl main.type main, @function
main:
.LFB11:.cfi_startprocsubq $24, %rsp.cfi_def_cfa_offset 32movl $0, 12(%rsp)leaq 12(%rsp), %rsimovl $.LC0, %edimovl $0, %eaxcall __isoc99_scanfmovl 12(%rsp), %eaxleal 10(%rax), %esimovl $.LC1, %edimovl $0, %eaxcall printfmovl $0, %eaxaddq $24, %rsp.cfi_def_cfa_offset 8ret.cfi_endproc
.LFE11:.size main, .-main.ident "GCC: (GNU) 13.2.0".section .note.GNU-stack,"",@progbits
而字符串的操作还远不止这些,关于有限自动机以及编译器的实现细节等内容,你将会在未来的编译原理课程中学到(当然是你们学校开的课,我还没有写编译原理博客的计划),在这一篇当中,我们会介绍字符串的ADT,基本操作,以及两种常用的字符串模式匹配算法。
(1).字符串及其ADT
#1.基本概念
假设V是程序语言所使用的字符集,由字符集V中的字符所组成的任何有限序列,称为字符串。
不包含任何字符的字符串称为空字符串,而字符串的长度即为一个字符串所包含的字符个数;某个串的子串则是这个串中任意一个连续的子序列。
所以字符串也是一种线性表,其中的每个元素都是一个字符,这样我们用数组和链表理论上讲都是可以实现字符串的,不过通常情况下,我们会采取顺序存储的方式来实现字符串,因为有些算法可能涉及到随机访问,所以用顺序存储会方便些
#2.ADT
具体的我就不提了,这里就说一说关于字符串的一些操作:
- 创建、赋值、拷贝、清空、销毁
- 串互相比较
- 求串的长度
- 连接两个字符串
- 取出字符串的子串
- 判断是否为空串
- 子串替换、插入、删除
接下来我们就来看看这些基本操作的实现方式。
(2).字符串的基本操作
这里的字符串的容器采取STL vector实现,具体你可以试着自己写一写,我在GitHub上开源了一个MySTL,其中有基于vector<T>的basic_string<T>实现:MySTL-Voltline
#1.求子串substr
求子串其实还挺简单的,只是有一些边界情况需要考虑,比如beg < end,beg、end > 0,end < _size这样,所以就可以得到以下的代码:
string substr(int beg, int end) const
{if (beg < 0) beg = 0;if (end > _size) end = _size;vector<char> vc;for (int i = beg; i <= end; i++) {vc.push_back(container[i]);}return string{ vc };
}
还有一种子串的取法则是从位置i开始取j个字符形成子串,这个实现方法其实没什么太大的区别,你可以自己尝试实现。
#2.插入字符串insert
这个函数其实和线性表向其中某个位置插入指定个数的元素的操作差不多,所以我们也可以很快地写出下面的代码:
string insert(const string& s1, int pos)
{if (pos > _size) pos = _size;else if (pos < 0) pos = 0;container.resize(_size + s1.size() + 100);// 给容器直接扩容,避免之后再挪动的时候出现越界访问的问题int mov = s1.size();for (int i = _size-1; i >= pos; i--) {container[i + mov] = container[i]; }for (int i = pos; i < mov; i++) {container[i] = s1.container[i - pos];}return *this;
}
#3.其他操作
其他操作真的很简单,比如concat,如果操作的是vector,一个个push_back就好了,这些操作还是自己实现一下吧。
(3).字符串的模式匹配
什么是模式匹配呢,听起来有点复杂,不过其实很简单,就是依照查找子串的事情,比如:在hellowbabababbabbba中找到babb
#1.简单匹配(Brute-Force方法)
怎么找呢?很自然的想法就是一个个去遍历,比如这样:
int find_bf(const string& t, const string& p, int pos)
{int i{ pos }, j{ 0 };int n = t.size(), m = p.size();while (i < n && j < m) {if (t[i] == p[i]) { i++, j++;}else {i += 1-j;j = 0;}}if (j == m) return i - m;else return -1;
}
很简单,每到一个字符就往后匹配一次,匹配不上就继续遍历,如果匹配上了就直接返回,这样就好了
假设正文字符串长度为n,模式字符串长度为m,那么这个匹配方式的时间复杂度是 O ( n m ) O(nm) O(nm),如果模式串和正文串长度差不多,这个匹配方式的时间复杂度就会退化到 O ( n 2 ) O(n^2) O(n2)的时间复杂度,这有点太慢了。
#2.KMP算法
Knuth,Morris和Pratt共同提出了一种全新的模式匹配算法,这个算法能够在 O ( n + m ) O(n+m) O(n+m)的线性时间复杂度内完成字符串的模式匹配。
我们先来思考一下,Brute-Force方法到底有什么问题,比如t = abababcbababba,p = ababc,BF方法是这样:

我们会发现,p和t在第一次匹配的时候,前面的abab都已经匹配上了,只有c和a发生了失配,而因为失配,第二次我们把整个字符串往后挪动一次匹配,还得从a开始,这样我们貌似忘记了前面四个字符是匹配的了
如果我们试着看看t可能可以发现这么一件事,出现的第二个ab后面又是a,而在字符串p中,第一个ab后出现的也是a,所以如果我们的p可以这么跳转:

只让p对应的那个指针动,动到刚才我们发现的"aba"的地方,就可以去掉第二次匹配,这个例子举的可能差距不大,我们把t变成abababababcbab,那么情况就会变成这样:

比较次数明显减少!所以KMP算法的核心就在于:如何找到模式字符串本身具备的特性,通过它本身的性质得到一个失配跳转值,从而尽可能增加每一次模式字符串跳转的字符数,从而大大减少重复匹配的次数,接下来我们来具体提一提怎么实现KMP算法
I.kmp_match()
这次我打算先介绍一下,我们如何通过这个想法进行匹配,假设我们已经获得了对于模式字符串的next数组(这个等会儿再来看怎么实现),接下来要对正文串t和模式串p进行匹配,那么基于前面我们说的想法:在匹配的时候就继续前进,失配的时候根据失配跳转值让p向前跳,如果到第一个字符还是失配,那就不可能在现在已经走过的字符里找到能匹配的了,这时候只要让t的指针往后跳一个就行了,所以我们可以得出下面的代码:
struct chars
{char c; // 字符int idx; // 跳转值
};int kmp(const string& t, const string& p)
{int ans{ -1 };vector<chars> next = getNext(p);int t_size = t.size(), p_size = p.size();int i{ 0 }, j{ 0 };while (i < t_size) {if (j == -1 || t[i] == p[j]) {i++, j++;}else {if (j < p_size) j = next[j].idx;}if (j == p_size) {ans = i - j;break;}}return ans;
}
我们首先用getNext()函数获得next数组,然后进行基于next数组的匹配,next数组的数据模式如下:第一个字符对应的值为-1,其他的字符对应的值则是对应字符失配时的跳转值,如果找到的next值是-1,就让指向正文串的"指针"i向后移动一位,否则就让指向模式串的"指针"j移动到next[j]的位置上去。
那么接下来,我们就来看看这个getNext()函数怎么写的吧!
II.getNext()
首先说一说前缀和后缀的概念,前缀就是自第一个字符起的所有连续子串,后缀就是自最后一个字符起的所有连续子串,提到前缀和后缀主要是为了引入next的计算原理。
接下来我们来看看next数组是怎么生成的,next数组的跳转顺序基于这样一个规则:当失配发生时,失配字符a的上一个字符b对应的某一个子串S在不包含当前子串的最长前缀中,子串S最后一次出现的位置中,字符b的位置,有点拗口,我们来详细地解释一下,例如:p = abcabd,我们找next的规则就是基于每个下一个字符都有可能是失配字符来做的,那么我们可以得到下面的一张表:

a首先是-1没问题,b去往前找,只有a,那就赋为0吧。之后是c,往前找一个字符是b,它对应的idx是0,next[0]是a,a和b并不匹配,那就继续往前走,字符a对应的idx是-1,这时候就结束了,我们让c的idx为a的idx+1,也就是0。
然后又是b,b前面一个字符是a,而a在前面的字符中出现过,在第0个,因此当这个b失配的时候,下一次我们可以试着从它前面一个字符出现的上一次的后面一个字符继续匹配,很显然,a在0出现了,后面一位是1,所以b就赋为1了。
最后是d,d前面一个字符是b,而b上一次出现在数组中是1,那么d失配的时候,b满足,就跳转到上一次出现的b的后面一位,也就是c,对应的是2,所以d就赋为2了。
然后我们就走完了全程,你发现了,虽然我们是在做子串和前缀的重叠匹配,但是实际上,因为每个字符的上一个字符总是已经包含了之前字符的重叠情况,因此我们只需要考虑当前这个字符是不是匹配就好了,这其实也能算是一种动态规划的思想,因为我们让每一次字符的查找都变得有用了起来,每一次下一个字符的查找都基于上一个查找的结果来确定,因此查找的过程就变得简单了起来:
- 1.到了某一个字符c,先看看这个字符的前一个字符
- 2.如果这个字符的前一个字符b和b自己的next值对应的字符相同,那就让c的next值等于b的next值+1(允许你从上一次b出现的后面一个字符开始匹配)
- 3.如果这个字符的前一个字符b和b自己的next值对应的字符不相同,那就让继续找到b的next值对应的字符对应的next值,继续往前找,直到找到一个匹配的字符,或者找到第一个字符(对应的next值为-1),如果找到匹配的字符,则类似2操作,让c的next值等于找到的这个字符的位置+1;否则就赋值为0,对应最前的字符
很好,那代码就很好写了:
vector<chars> getNext(const string& sub_str)
{vector<chars> next;size_t sub_str_size{ sub_str.size() };next.push_back(chars{ sub_str[0], -1 });for (size_t i = 1; i < sub_str_size; i++) {next.push_back(chars{ sub_str[i], 0 });}for (size_t i = 1; i < sub_str_size; i++) {if (next[i - 1].idx != -1 && next[i - 1].c == next[next[i - 1].idx].c) {next[i].idx = next[i - 1].idx + 1;}else {int j = next[i - 1].idx;while (j != -1 && next[j].c != next[i - 1].c) {j = next[j].idx;}next[i].idx = j + 1;}}return next;
}
我这里next存的是一个叫做chars的结构体,它对应的结构是这样:
struct chars
{char c; // 字符int idx; // 跳转值
};
其实你只存这个idx也是可以的,你可以稍微改改,有一个特别需要注意的点:
for (size_t i = 1; i < sub_str_size; i++) {next.push_back(chars{ sub_str[i], 0 });}
这个数组在初始化的时候,我们把所有后续字符的idx值都赋为0,如果没有后续的操作,这个情况如果调用kmp_match函数的匹配过程就会和前面说的Brute-Force方式完全一样了,所以后续的找next过程还是非常重要的呢!那么KMP算法其实到这里基本上就结束了,我们会发现,如果真的理解了它的做法,其实感觉还挺简单的,实际上就是一个动态规划的思想,很多动态规划的问题也是这样,其实想出来之后它的思路并不复杂,但是要想到这个思路的过程是相当困难的。
#3.还有更多
其实字符串的匹配方式还有很多很多,例如BM算法等,因为时间的限制,在这里我就不做过多介绍了。
小结
字符串这一篇,相当的短啊哈哈哈哈哈哈,毕竟这一部分在数据结构中我们主要还是以掌握KMP算法为主,毕竟它在模式匹配上表现出的时间复杂度 O ( n + m ) O(n+m) O(n+m)是非常优秀的。下一篇我们将会介绍一系列内部排序的算法。
然后,我会在下面给出我写过的MySTL中的basic_string的代码,仅供参考,如果你发现了什么bug,一定要告诉我哦!这对我帮助很大!
附录:我自己写的string
#pragma once
#include <iostream>
#include <cstring>
#include "vector.h"namespace MySTL
{template <typename T>class basic_string{private:vector<T> container;size_t _size;public:using iterator = T*;using const_iterator = const T*;inline static size_t npos = -1;public:basic_string();basic_string(const char* _c_str);basic_string(const char* _c_str, size_t _size);basic_string(const char* _c_str, size_t _begin, size_t _size);basic_string(size_t _size, char c);basic_string(const basic_string<T>& _str);basic_string(basic_string<T>&& _mv_str) noexcept;basic_string(std::initializer_list<T> l);~basic_string();basic_string<T>& operator=(const basic_string<T>& _Right);basic_string<T>& operator=(basic_string<T>&& _Right) noexcept;basic_string<T>& operator=(const char* _str);basic_string<T>& operator=(char c);basic_string<T> operator+(const basic_string<T>& _Right);basic_string<T> operator+(const char* _str);basic_string<T> operator+(char c);basic_string<T>& operator+=(const basic_string<T>& _Right);basic_string<T>& operator+=(const char* _str);basic_string<T>& operator+=(char c);T& operator[](size_t _index);const T& operator[](size_t _index) const;T& at(size_t _index);bool operator==(const basic_string<T>& _Right);bool operator!=(const basic_string<T>& _Right);bool operator>(const basic_string<T>& _Right);bool operator<(const basic_string<T>& _Right);bool operator>=(const basic_string<T>& _Right);bool operator<=(const basic_string<T>& _Right);bool operator==(const char* _c_Right);bool operator!=(const char* _c_Right);bool operator>(const char* _c_Right);bool operator<(const char* _c_Right);bool operator>=(const char* _c_Right);bool operator<=(const char* _c_Right);size_t size() const noexcept;size_t capacity() const noexcept;bool empty() const noexcept;const T* data();const T* c_str();iterator begin();iterator end();const_iterator begin() const;const_iterator end() const;void reserve(size_t new_capacity_size);void resize(size_t new_elem_size);void clear();void erase(const size_t _Where);void erase(const size_t _Off, const size_t _Count);void erase(iterator _begin, iterator _end);void erase(iterator _pos);void append(size_t _Count, char c);void append(const basic_string<T>& _str);void append(const basic_string<T>& _str, size_t _Begin = 0);void append(const basic_string<T>& _str, size_t _Begin, size_t _Count);void append(const char* _str);void append(const char* _str, size_t _Begin);void append(const char* _str, size_t _Begin, size_t _Count);void append(std::initializer_list<char> l);void push_back(char c);size_t find(char c, size_t _begin_pos = 0);size_t find(const char* _str, size_t _begin_pos = 0);size_t find(const basic_string<T>& _str, size_t _begin_pos = 0);void swap(basic_string<T>& _Right);template<typename U>friend std::ostream& operator<<(std::ostream& output, const basic_string<U>& _str){for (auto& i : _str) {output << i;}return output;}template<typename U>friend std::istream& operator>>(std::istream& input, basic_string<U>& _str){_str.clear();U c = input.get();while (c != ' ' && c != '\n' && c != '\t') {_str.push_back(c);c = input.get();}return input;}};template<typename T>basic_string<T>::basic_string(){container = vector<unsigned char>{};}template<typename T>basic_string<T>::basic_string(const char* _c_str){size_t length{ strlen(_c_str) };_size = length;container = vector<T>();for (size_t i = 0; i < length; i++) {container.push_back(*(_c_str + i));}container.push_back('\0');}template<typename T>basic_string<T>::basic_string(const char* _c_str, size_t _size){size_t length{ _size };if (_size > strlen(_c_str)) {length = strlen(_c_str);}_size = length;container = vector<T>();for (size_t i = 0; i < length; i++) {container.push_back(*(_c_str + i));}container.push_back('\0');}template<typename T>basic_string<T>::basic_string(const char* _c_str, size_t _begin, size_t _size){size_t c_str_len{ strlen(_c_str) };container = vector<T>();if (_begin > c_str_len) {_size = 0;}else {size_t length{ _size };if (_size > strlen(_c_str + _begin)) {length = strlen(_c_str + _begin);}_size = length;for (size_t i = _begin; i < length; i++) {container.push_back(*(_c_str + i));}container.push_back('\0');}}template<typename T>basic_string<T>::basic_string(size_t _size, char c){container = vector<T>(_size, c);_size = _size;}template<typename T>basic_string<T>::basic_string(const basic_string<T>& _str){container = vector<T>(_str.container);_size = _str._size;}template<typename T>basic_string<T>::basic_string(basic_string<T>&& _mv_str) noexcept{container = std::move(_mv_str.container);_size = _mv_str._size;_mv_str.container = vector<T>{};}template<typename T>basic_string<T>::basic_string(std::initializer_list<T> l){container = vector<T>(l.size() + 128);_size = l.size();for (auto it = l.begin(); it != l.end(); it++) {container.push_back(static_cast<T>(*it));}container.push_back('\0');}template<typename T>basic_string<T>::~basic_string(){_size = 0;container.~vector();}template<typename T>basic_string<T>& basic_string<T>::operator=(const basic_string<T>& _Right){container.~vector();container = _Right.container;_size = _Right._size;return *this;}template<typename T>basic_string<T>& basic_string<T>::operator=(basic_string<T>&& _Right) noexcept{container.~vector();container = std::move(_Right.container);_size = _Right._size;return *this;}template<typename T>basic_string<T>& basic_string<T>::operator=(const char* _str){container.~vector();size_t length{ strlen(_str) };container = vector<T>(length + 128);_size = 0;for (size_t i = 0; i < length; i++) {container.push_back(_str[i]);_size++;}return *this;}template<typename T>basic_string<T>& basic_string<T>::operator=(char c){clear();push_back(c);return *this;}template<typename T>basic_string<T> basic_string<T>::operator+(const basic_string<T>& _Right){basic_string<T> temp{ *this };for (auto& i : _Right) {temp.push_back(i);}return temp;}template<typename T>basic_string<T> basic_string<T>::operator+(const char* _str){basic_string<T> temp{ *this };size_t length{ strlen(_str) };for (size_t i = 0; i < length; i++) {temp.push_back(_str[i]);}return temp;}template<typename T>basic_string<T> basic_string<T>::operator+(char c){basic_string<T> temp{ *this };temp.push_back(c);return temp;}template<typename T>basic_string<T>& basic_string<T>::operator+=(const basic_string<T>& _Right){for (auto& i : _Right) {push_back(i);}return *this;}template<typename T>basic_string<T>& basic_string<T>::operator+=(const char* _str){size_t length{ strlen(_str) };for (size_t i = 0; i < length; i++) {push_back(_str[i]);}return *this;}template<typename T>basic_string<T>& basic_string<T>::operator+=(char c){push_back(c);return *this;}template<typename T>T& basic_string<T>::operator[](size_t _index){return container[_index];}template<typename T>const T& basic_string<T>::operator[](size_t _index) const{return container[_index];}template<typename T>T& basic_string<T>::at(size_t _index){if (_index <= _size) {return container[_index];}else {throw std::out_of_range("Index Out of Range");}}template<typename T>bool basic_string<T>::operator==(const basic_string<T>& _Right){if (_size != _Right._size) {return false;}else {for (size_t i = 0; i < _size; i++) {if (container[i] != _Right[i]) return false;}return true;}}template<typename T>bool basic_string<T>::operator!=(const basic_string<T>& _Right){return !(*this == _Right);}template<typename T>bool basic_string<T>::operator>(const basic_string<T>& _Right){size_t min_size{ _size < _Right.size() ? _size : _Right.size() };for (size_t i = 0; i < min_size; i++) {if (container[i] > _Right[i]) return true;else if (container[i] < _Right[i]) {return false;}}return _size > _Right.size();}template<typename T>bool basic_string<T>::operator<(const basic_string<T>& _Right){return (*this <= _Right) && (*this != _Right);}template<typename T>bool basic_string<T>::operator>=(const basic_string<T>& _Right){return (*this > _Right) || (*this == _Right);}template<typename T>bool basic_string<T>::operator<=(const basic_string<T>& _Right){return !(*this > _Right);}template<typename T>bool basic_string<T>::operator==(const char* _c_Right){if (strlen(_c_Right) != _size) return false;else {for (size_t i = 0; i < _size; i++) {if (container[i] != _c_Right[i])return false;}return true;}}template<typename T>bool basic_string<T>::operator!=(const char* _c_Right){return !(*this == _c_Right);}template<typename T>bool basic_string<T>::operator>(const char* _c_Right){size_t length{ strlen(_c_Right) };size_t min_size{ _size < length ? _size : length };for (size_t i = 0; i < min_size; i++) {if (container[i] > _c_Right[i]) return true;else if (container[i] < _c_Right[i]) {return false;}}return _size > length;}template<typename T>bool basic_string<T>::operator<(const char* _c_Right){return (*this <= _c_Right) && (*this != _c_Right);}template<typename T>bool basic_string<T>::operator>=(const char* _c_Right){return (*this > _c_Right) || (*this == _c_Right);}template<typename T>bool basic_string<T>::operator<=(const char* _c_Right){return !(*this > _c_Right);}template<typename T>size_t basic_string<T>::size() const noexcept{return _size;}template<typename T>size_t basic_string<T>::capacity() const noexcept{return container.capacity();}template<typename T>bool basic_string<T>::empty() const noexcept{if (_size != 0) return false;else return true;}template<typename T>const T* basic_string<T>::data(){return container.data();}template<typename T>const T* basic_string<T>::c_str(){return container.data();}template<typename T>typename basic_string<T>::iterator basic_string<T>::begin(){return container.begin();}template<typename T>typename basic_string<T>::iterator basic_string<T>::end(){return container.begin() + _size;}template<typename T>typename basic_string<T>::const_iterator basic_string<T>::begin() const{return container.begin();}template<typename T>typename basic_string<T>::const_iterator basic_string<T>::end() const{return container.begin() + _size;}template<typename T>void basic_string<T>::reserve(size_t new_capacity_size){container.reserve(new_capacity_size);}template<typename T>void basic_string<T>::resize(size_t new_elem_size){container.resize(new_elem_size);_size = new_elem_size;}template<typename T>void basic_string<T>::clear(){_size = 0;container.clear();}template<typename T>void basic_string<T>::erase(const size_t _Where){if (_Where <= _size) {_size = _Where;container.erase(container.begin() + _Where, container.end());container.push_back('\0');}}template<typename T>void basic_string<T>::erase(const size_t _Off, const size_t _Count){if (_Off <= _size) {if (_size - _Off > _Count) {_size -= _Count;container.erase(container.begin() + _Off, container.begin() + _Off + _Count);container[_size] = '\0';}else {erase(_Off);}}}template<typename T>void basic_string<T>::erase(basic_string<T>::iterator _begin, basic_string<T>::iterator _end){if (_end >= _begin) {if (_begin >= begin()) {size_t _Off = _begin - begin();size_t _Count = _end - _begin;if (_Off <= _size) {if (_size - _Off > _Count) {_size -= _Count;container.erase(container.begin() + _Off, container.begin() + _Off + _Count);container[_size] = '\0';}else {erase(_Off);}}}else {throw IteratorOutOfRangeException{};}}else {throw IteratorErrorException{};}}template<typename T>void basic_string<T>::erase(basic_string<T>::iterator _pos){if (_pos >= begin()) {if (_pos < end()) {size_t _Where = _pos - begin();if (_Where <= _size) {_size--;container.erase(_pos, _pos + 1);container[_size] = '\0';}}}else {throw IteratorErrorException{};}}template<typename T>void basic_string<T>::append(size_t _Count, char c){for (size_t i = 0; i < _Count; i++) {push_back(c);}}template<typename T>void basic_string<T>::append(const basic_string<T>& _str){*this += _str;}template<typename T>void basic_string<T>::append(const basic_string<T>& _str, size_t _Begin){if (_Begin <= _str.size()) {if (_Begin == 0) {*this += _str;}else {for (auto it = _str.begin() + _Begin; it != _str.end(); it++) {push_back(*it);}}}else {throw std::out_of_range("Begin index out of range!");}}template<typename T>void basic_string<T>::append(const basic_string<T>& _str, size_t _Begin, size_t _Count){if (_Begin <= _str.size()) {if (_Begin + _Count > _str.size()) {_Count = _str.size() - _Begin;}for (size_t i = 0; i < _Count; i++) {push_back(_str[_Begin + i]);}}else {throw std::out_of_range("Begin index out of range!");}}template<typename T>void basic_string<T>::append(const char* _str){*this += _str;}template<typename T>void basic_string<T>::append(const char* _str, size_t _Begin){if (_Begin <= strlen(_str)) {*this += (_str + _Begin);}else {throw std::out_of_range("Begin index out of range!");}}template<typename T>void basic_string<T>::append(const char* _str, size_t _Begin, size_t _Count){if (_Begin <= strlen(_str)) {if (strlen(_str) - _Begin < _Count) {_Count = strlen(_str) - _Begin;}if (_Count != 0) {for (size_t i = 0; i < _Count; i++) {push_back(_str[_Begin + i]);}}}else {throw std::out_of_range("Begin index out of range!");}}template<typename T>void basic_string<T>::append(std::initializer_list<char> l){for (auto& i : l) {push_back(i);}}template<typename T>void basic_string<T>::push_back(char c){if (_size == container.size()) {container.push_back(c);}else {container[_size] = c;}container.push_back('\0');_size++;}template<typename T>size_t basic_string<T>::find(char c, size_t _begin_pos){for (size_t i = _begin_pos; i < _size; i++) {if (container[i] == c) {return i;}}return npos;}template<typename T>size_t basic_string<T>::find(const char* _str, size_t _begin_pos){size_t length{ strlen(_str) };bool isFind{ true };if (_size < length) return npos;else {for (size_t i = _begin_pos; i < _size; i++) {if (_size - i >= length) {if (container[i] == _str[0]) {isFind = true;for (size_t j = 1; j < length; j++) {if (container[i + j] != _str[j]) {i = i + j - 1;isFind = false;break;}}if (isFind) return i;}}else {return npos;}}return npos;}}template<typename T>size_t basic_string<T>::find(const basic_string<T>& _str, size_t _begin_pos){size_t length{ _str.size() };bool isFind{ true };if (_size < length) return npos;else {for (size_t i = _begin_pos; i < _size; i++) {if (_size - i >= length) {if (container[i] == _str[0]) {isFind = true;for (size_t j = 1; j < length; j++) {if (container[i + j] != _str[j]) {i = i + j - 1;isFind = false;break;}}if (isFind) return i;}}else {return npos;}}return npos;}}template<typename T>void basic_string<T>::swap(basic_string<T>& _Right){basic_string<T> temp{ _Right };_Right.clear();for (auto& c : *this) {_Right.push_back(c);}clear();for (auto& c : temp) {push_back(c);}}template<typename T>bool operator==(const char* _Left, const basic_string<T>& _Right){return _Right == _Left;}template<typename T>bool operator!=(const char* _Left, const basic_string<T>& _Right){return _Right != _Left;}template<typename T>bool operator>(const char* _Left, const basic_string<T>& _Right){return _Right < _Left;}template<typename T>bool operator<(const char* _Left, const basic_string<T>& _Right){return _Right > _Left;}template<typename T>bool operator>=(const char* _Left, const basic_string<T>& _Right){return _Right <= _Left;}template<typename T>bool operator<=(const char* _Left, const basic_string<T>& _Right){return _Right >= _Left;}template<typename T>std::istream& getline(std::istream& input, basic_string<T>& _Target, const char _End = '\n'){_Target.clear();T c = input.get();while (c != '\n') {_Target.push_back(c);c = input.get();}return input;}using string = basic_string<char>;using wstring = basic_string<wchar_t>;
#ifdef __cpp_lib_char8_tusing u8string = basic_string<char8_t>;
#endif // __cpp_lib_char8_tusing u16string = basic_string<char16_t>;using u32string = basic_string<char32_t>;
}
相关文章:
数据结构—字符串
文章目录 7.字符串(1).字符串及其ADT#1.基本概念#2.ADT (2).字符串的基本操作#1.求子串substr#2.插入字符串insert#3.其他操作 (3).字符串的模式匹配#1.简单匹配(Brute-Force方法)#2.KMP算法I.kmp_match()II.getNext() #3.还有更多 小结附录:我自己写的string 7.字符…...

inne所属公司抢注“童年时光”商标仍被冻结
根据中国商标网查询,国家知识产权局已于2023年3月10日裁定,被告inne所属的南京童年时光生物技术有限公司注册的“童年时光”商标无效。随着这起保健品行业品牌资产争夺事件的发酵,更多的细节得到披露,至此,一个从“代理…...

20231106-前端学习加载和视频球特效
加载效果 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>加载效果</title><!-- 最新…...

Arrays.asList() 和 List.of() 的列表之争
1. 概述 有时在Java中,为了方便,我们需要创建一个小列表或将数组转换为列表。Java 为此提供了一些辅助方法。 在本文中,我们将比较初始化小型临时数组的两种主要方法:List.of()和 Array.asList()。 2. Arrays.asList() Java 自…...
基于51单片机的停车场管理系统仿真电路设计
**单片机设计介绍,基于51单片机的停车场管理系统仿真电路设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 停车场管理系统仿真电路设计介绍 停车场管理系统主要用于自动化管理和控制停车场,以提高停车…...

APIView单一资源的查看更新删除
APIView单一资源的查看更新删除 一、构建路由 re_path("author/(/d)",AuthorDetailView.as_view)), 二、视图类 在views.py中添加AuthorDetailView类 class AuthorDetailView(APIView):def get(self, request, pk):author Author.objects.get(pkpk)serializer A…...

UML--类图的表示
1. 类的表示 1.1 访问属性 : public -: private #: protected 1.2 接口与抽象类 斜体 表示抽象类和抽象方法 <<Interface>> 类表示接口 1.3 类图示意 Mclass- val: int getVal(): int 2. 类关系 2.1 实现关系 空心三角形和虚线组成 B实现A,则三角形尖尖朝…...
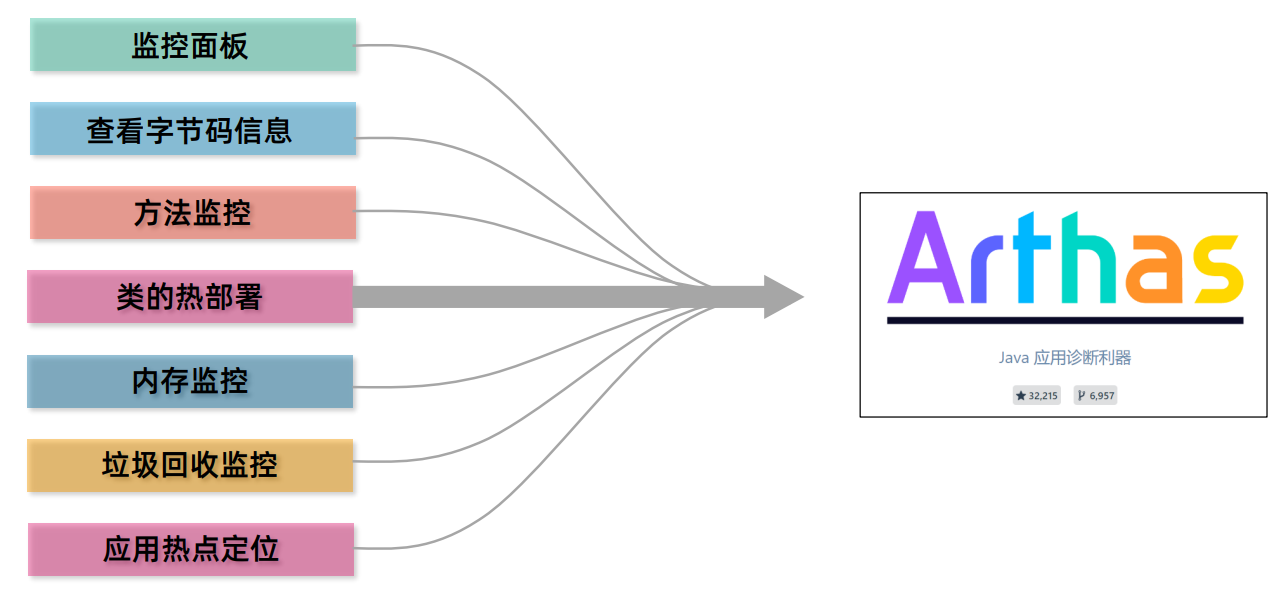
JVM字节码文件浅谈
文章目录 版权声明java虚拟机的组成字节码文件打开字节码文件的姿势字节码文件的组成魔数(基本信息)主副版本号(基本信息)主版本号不兼容的错误解决方法基本信息常量池方法 字节码文件的常用工具javap -v命令jclasslib插件阿里art…...
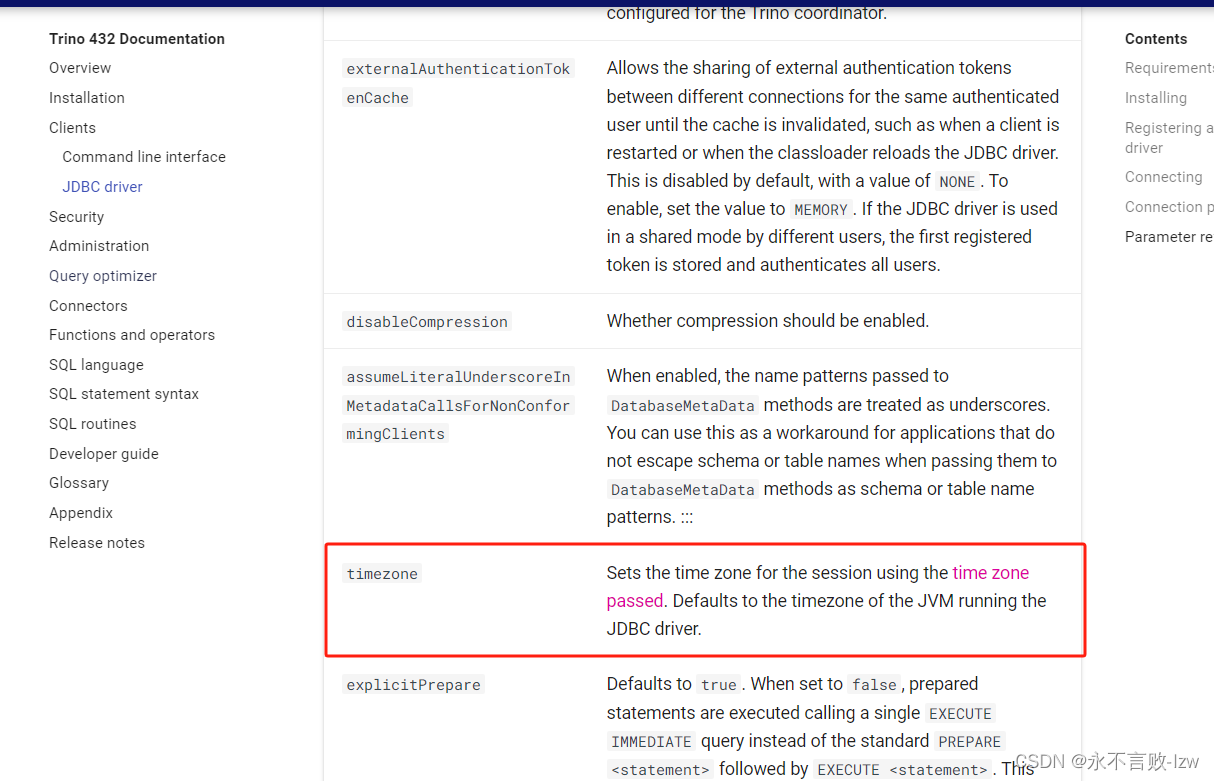
DBever 连接trino时区问题 The datetime zone id ‘GMT+08:00‘ is not recognised
DBever连接trino 测试连接成功,但是执行sql报时区不对、如果你默认使用的是大于jdk8的版本 会存在这个问题,因为jdk版本 jdk8 和jdk17 版本默认时区是不同的 trino官网明确说明了时区默认跟jdk走 解决方案 可以先行查看JDK本地时区库版本,执…...

xlua源码分析(二)lua Call C#的无wrap实现
xlua源码分析(二)lua Call C#的无wrap实现 上一节我们主要分析了xlua中C# Call lua的实现思路,本节我们将根据Examples 03_UIEvent,分析lua Call C#的底层实现。例子场景里有一个简单的UI面板,面板中包含一个input fie…...

MySql优化经验分享
一条sql的具体执行过程 连接 我们怎么查看MySQL当前有多少个连接? 可以用show status命令,模糊匹配Thread, Show global status like "Thread%" show global variables like wait timeout;—非交互式超时时间,如JDBC…...
【Linux】:使用git命令行 || 在github创建项目 || Linux第一个小程序——进度条(进阶版本)
在本章开始之前还是先给大家分享一张图片 这是C的笔试题 感兴趣的同学可以去试一试 有难度的哟 也可以直接在牛客网直接搜索这几道题目哈 好了今天我们正式进入我们的正题部分 🕖1.使用git命令行 安装git yum install git🕠2.在github创建项目 使用…...

Kotlin apply 交换两个数
代码: fun main() {var a 1var b 2a b.apply {b aprintln("$b")println("$this")}println("$a $b") }打印结果: 1 2 2 1原理分析: /*** Calls the specified function [block] with this value as its r…...

Android jetpack : Navigation 导航 路由 、 单个Activity嵌套多个Fragment的UI架构方式
Android Navigation 如何动态的更换StartDestination &&保存Fragment状态 Navigation(一)基础入门 google 官网 : Navigation 导航 路由 讨论了两年的 Navigation 保存 Fragment 状态问题居然被关闭了 Navigation是一种导航的概念,即把Activ…...

【react】在react中祖父、父亲、孙子组件层层解构其余属性props时报错children.forEach is not function
起因 报错children.forEacht is not function 分析原因 由于地址组件本身存在options,此时父组件又传递…otherProps,且解构了父级组件的otherProps,其中others解构后的属性就有options,因此产生了属性冲突,导致属性…...
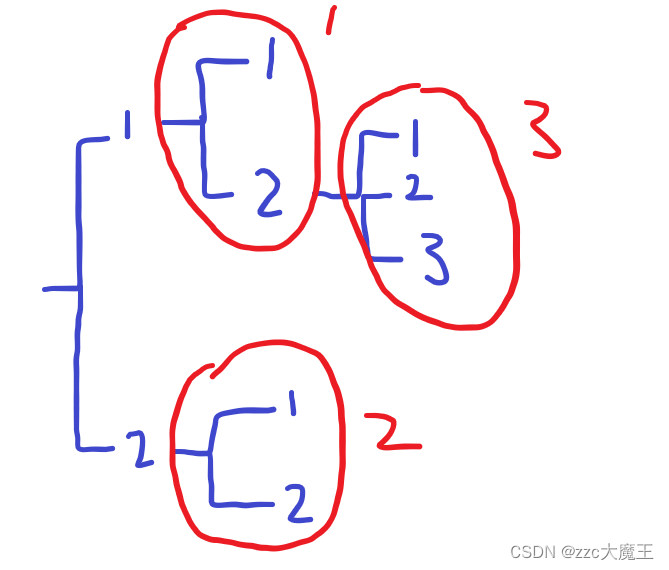
P9831 [ICPC2020 Shanghai R] Gitignore
P9831 [ICPC2020 Shanghai R] Gitignore - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 只看题意翻译这道题是做不出来的,还要去看英文里面的规定(这里就不放英文了),主要问题是不要公用子文件夹。 例如: 1 / a / 2 2 / a / 3…...
)
LinkList集合方法(自写)
在使用以下方法时需要定义一个LinkNode类来定义变量,new一个新对象进行调用,输出时需要定义输出方法 public class ListNode {int value;ListNode next;//public ListNode(int value) {this.value value;}public String toString(){return "ListN…...
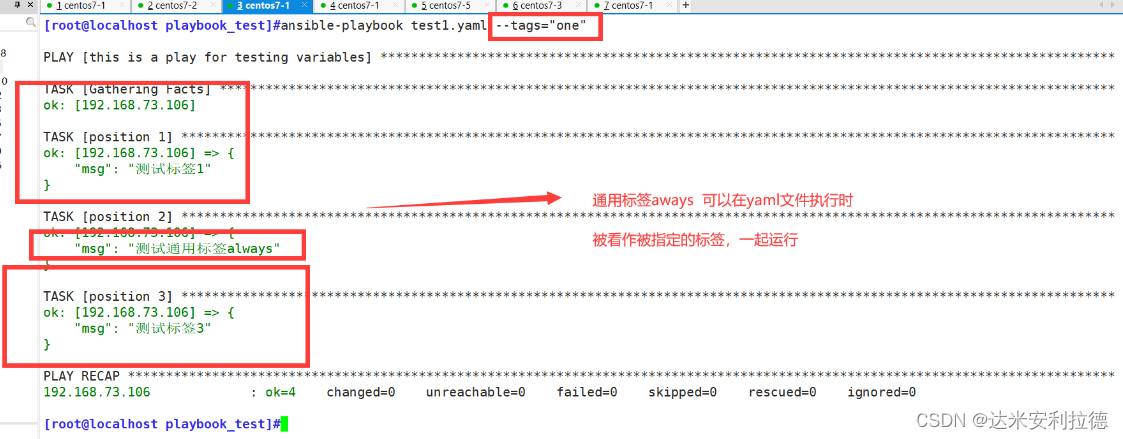
Ansible playbook自动化运维工具详解
Ansible playbook自动化运维工具详解 一、playbook的相关知识1.1、playbook 的简介1.2、playbook的 各部分组成 二、基础的playbook剧本编写实例三、 playbook的定义、引用变量3.1、基础变量的定义与引用3.2、引用fact信息中的变量 四、playbook中的when条件判断和变量循环使用…...
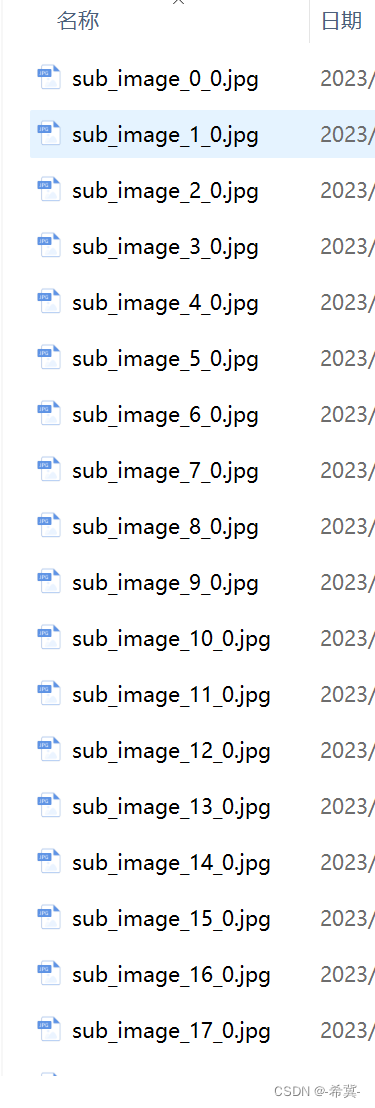
图像切分:将一张长图片切分为指定长宽的多张图片
1.需求 比如有一张很长的图片其大小为宽度779,高度为122552,那我想把图片切分为779乘以1280的格式。 步骤如下: 使用图像处理库(如PIL或OpenCV)加载原始图片。确定子图片的宽度和高度。计算原始图片的宽度和高度&am…...
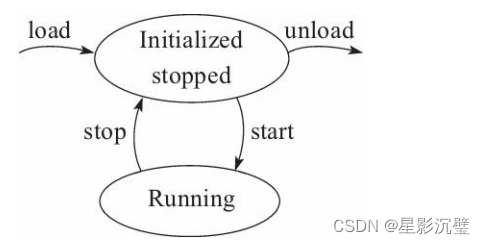
ROS学习笔记(5):ros_control
1.ros_control简介 ros_control - ROS Wiki ros_control是为ROS提供的机器人控制包,包含一系列控制器接口、传动装置接口、控制器工具箱等,有效帮助机器人应用功能包快速落地,提高开发效率。 2.ros_control框架 ros_control总体框架: 针对…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...