SwissArmyTransformer瑞士军刀工具箱使用手册
Introduction sat(SwissArmyTransformer)是一个灵活而强大的库,用于开发您自己的Transformer变体。
sat是以“瑞士军刀”命名的,这意味着所有型号(例如BERT、GPT、T5、GLM、CogView、ViT…)共享相同的backone代码,并通过一些超轻量级的mixin满足多种用途。
sat由deepspeed ZeRO和模型并行性提供支持,旨在为大模型(100M\~20B参数)的预训练和微调提供最佳实践。
从 SwissArmyTransformer 0.2.x 迁移到 0.3.x
- 导入时将包名称从 SwissArmyTransformer 更改为 sat,例如从 sat 导入 get_args。
- 删除脚本中的所有--sandwich-ln,使用layernorm-order='sandwich'。
- 更改顺序 from_pretrained(args, name) => from_pretrained(name, args)。
- 我们可以直接使用 from sat.model import AutoModel;model, args = AutoModel.from_pretrained('roberta-base') 以 仅模型模式 加载模型,而不是先初始化 sat。
安装
pip install SwissArmyTransformer特征
添加与模型无关的组件,例如前缀调整,只需一行!
前缀调整(或 P 调整)通过在每个注意力层中添加可训练参数来改进微调。使用我们的库可以轻松地将其应用于 GLM 分类(或任何其他)模型。
class ClassificationModel(GLMModel): # can also be BertModel, RobertaModel, etc. def __init__(self, args, transformer=None, **kwargs):super().__init__(args, transformer=transformer, **kwargs)self.add_mixin('classification_head', MLPHeadMixin(args.hidden_size, 2048, 1))# Arm an arbitrary model with Prefix-tuning with this line!self.add_mixin('prefix-tuning', PrefixTuningMixin(args.num_layers, args.hidden_size // args.num_attention_heads, args.num_attention_heads, args.prefix_len))GPT 和其他自回归模型在训练和推理过程中的行为有所不同。在推理过程中,文本是逐个令牌生成的,我们需要缓存以前的状态以提高效率。使用我们的库,您只需要考虑训练期间的行为(教师强制),并通过添加 mixin 将其转换为缓存的自回归模型:
model, args = AutoModel.from_pretrained('glm-10b-chinese', args)
model.add_mixin('auto-regressive', CachedAutoregressiveMixin())
# Generate a sequence with beam search
from sat.generation.autoregressive_sampling import filling_sequence
from sat.generation.sampling_strategies import BeamSearchStrategy
output, *mems = filling_sequence(model, input_seq,batch_size=args.batch_size,strategy=BeamSearchStrategy(args.batch_size))使用最少的代码构建基于 Transformer 的模型。我们提到了 GLM,它与标准转换器(称为 BaseModel)仅在位置嵌入(和训练损失)上有所不同。我们在编码的时候只需要关注相关的部分就可以了。
扩展整个定义:
class BlockPositionEmbeddingMixin(BaseMixin):# Here define parameters for the mixindef __init__(self, max_sequence_length, hidden_size, init_method_std=0.02):super(BlockPositionEmbeddingMixin, self).__init__()self.max_sequence_length = max_sequence_lengthself.hidden_size = hidden_sizeself.block_position_embeddings = torch.nn.Embedding(max_sequence_length, hidden_size)torch.nn.init.normal_(self.block_position_embeddings.weight, mean=0.0, std=init_method_std)# Here define the method for the mixindef position_embedding_forward(self, position_ids, **kwargs):position_ids, block_position_ids = position_ids[:, 0], position_ids[:, 1]position_embeddings = self.transformer.position_embeddings(position_ids)block_position_embeddings = self.block_position_embeddings(block_position_ids)return position_embeddings + block_position_embeddingsclass GLMModel(BaseModel):def __init__(self, args, transformer=None, parallel_output=True):super().__init__(args, transformer=transformer, parallel_output=parallel_output)self.add_mixin('block_position_embedding', BlockPositionEmbeddingMixin(args.max_sequence_length, args.hidden_size)) # Add the mixin for GLM全方位的培训支持。 sat 旨在提供预训练和微调的最佳实践,您只需要完成forward_step 和 create_dataset_function,但可以使用超参数来更改有用的训练配置。
通过指定 --num_nodes、--num_gpus 和一个简单的主机文件,将训练扩展到多个 GPU 或节点。
DeepSpeed 和模型并行性。
ZeRO-2 和激活检查点的更好集成。
自动扩展和改组训练数据和内存映射。
成功支持CogView2和CogVideo的训练。
目前唯一支持在 GPU 上微调 T5-10B 的开源代码库。
快速浏览
在 sat 中使用 Bert(用于推理)的最典型的 python 文件如下:
# @File: inference_bert.py
from sat import get_args, get_tokenizer, AutoModel
# Parse args, initialize the environment. This is necessary.
args = get_args()
# Automatically download and load model. Will also dump model-related hyperparameters to args.
model, args = AutoModel.from_pretrained('bert-base-uncased', args)
# Get the BertTokenizer according to args.tokenizer_type (automatically set).
tokenizer = get_tokenizer(args)
# Here to use bert as you want!
# ...然后我们可以通过以下方式运行代码
SAT_HOME=/path/to/download python inference_bert.py --mode inference所有官方支持的模型名称都在 urls.py 中。
# @File: finetune_bert.py
from sat import get_args, get_tokenizer, AutoModel
from sat.model.mixins import MLPHeadMixindef create_dataset_function(path, args):# Here to load the dataset# ...assert isinstance(dataset, torch.utils.data.Dataset)return datasetdef forward_step(data_iterator, model, args, timers):inputs = next(data_iterator) # from the dataset of create_dataset_function.loss, *others = model(inputs)return loss# Parse args, initialize the environment. This is necessary.
args = get_args()
model, args = AutoModel.from_pretrained('bert-base-uncased', args)
tokenizer = get_tokenizer(args)
# Here to use bert as you want!
model.del_mixin('bert-final')
model.add_mixin('classification_head', MLPHeadMixin(args.hidden_size, 2048, 1))
# ONE LINE to train!
# args already includes hyperparams such as lr, train-iters, zero-stage ...
training_main(args, model_cls=model, forward_step_function=forward_step, # user definecreate_dataset_function=create_dataset_function # user define
)然后我们可以通过以下方式运行代码
deepspeed --include localhost:0,1 finetune_bert.py \--experiment-name ftbert \--mode finetune --train-iters 1000 --save /path/to/save \--train-data /path/to/train --valid-data /path/to/valid \--lr 0.00002 --batch-size 8 --zero-stage 1 --fp16这里我们在 GPU 0,1 上使用数据并行。我们还可以通过 --hostfile/path/to/hostfile 在许多互连的机器上启动训练。请参阅教程了解更多详细信息。
要编写自己的模型,您只需要考虑与标准 Transformer 的差异。例如,如果你有一个改进注意力操作的想法:
from sat.model import BaseMixin
class MyAttention(BaseMixin):def __init__(self, hidden_size):super(MyAttention, self).__init__()# MyAttention may needs some new params, e.g. a learnable alpha.self.learnable_alpha = torch.nn.Parameter(torch.ones(hidden_size))# This is a hook function, the name `attention_fn` is special.def attention_fn(q, k, v, mask, dropout=None, **kwargs):# Code for my attention.# ...return attention_results这里的attention_fn是一个钩子函数,用新函数替换默认动作。所有可用的钩子都在transformer_defaults.py中。现在我们可以使用 add_mixin 将更改应用到所有转换器,例如 BERT、Vit 和 CogView。请参阅教程了解更多详细信息。
教程
- How to use pretrained models collected in sat?
- Why and how to train models in sat?
Citation
Currently we don't have a paper, so you don't need to formally cite us!~
If this project helps your research or engineering, use \footnote{https://github.com/THUDM/SwissArmyTransformer} to mention us and recommend SwissArmyTransformer to others.
The tutorial for contributing sat is on the way!
The project is based on (a user of) DeepSpeed, Megatron-LM and Huggingface transformers. Thanks for their awesome work.
训练指导
The Training API
我们提供了一个简单但功能强大的训练APItraining_main(),它不仅限于我们的Transformer模型,还适用于任何torch.nn.Module。
from sat import get_args, training_main
from sat.model import AutoModel, BaseModel
args = get_args()
# to pretrain from scratch, give a class obj
model = BaseModel
# to finetuned from a given model, give a torch.nn.Module
model = AutoModel.from_pretrained('bert-base-uncased', args)training_main(args, model_cls=model,forward_step_function=forward_step,create_dataset_function=dataset_func,handle_metrics_function=None,init_function=None
)以上是使用 sat 的标准训练计划的(不完整)示例。 Training_main 接受 5 个参数:(必需)model_cls:继承 torch.nn.Module 的类型对象,或我们训练的 torch.nn.Module 对象。
(必需)forward_step_function:一个自定义函数,输入 data_iterator、model、args、timers、returns loss、{'metric0': m0, ...}。
(必填)create_dataset_function:返回一个torch.utils.data.Dataset用于加载。我们的库会自动将数据分配给多个worker,并将数据迭代器交给forward_step_function。
(可选)handle_metrics_function:在评估过程中处理特殊指标。
(可选)init_function:在训练之前更改模型的钩子,对于继续训练很有用。
有关完整示例,请参阅 Finetune BERT 示例。
相关文章:
SwissArmyTransformer瑞士军刀工具箱使用手册
Introduction sat(SwissArmyTransformer)是一个灵活而强大的库,用于开发您自己的Transformer变体。 sat是以“瑞士军刀”命名的,这意味着所有型号(例如BERT、GPT、T5、GLM、CogView、ViT…)共享相同的backo…...
unity【动画】脚本_角色动画控制器 c#
首先创建一个代码文件夹Scripts 从人物角色Player的基类开始 创建IPlayer类 首先我们考虑到如果不挂载MonoBehaviour需要将角色设置成预制体实例化到场景上十分麻烦, 所以我们采用继承MonoBehaviour类的角色基类方法写代码 也就是说这个脚本直接绑定在角色物体…...
Java代码如何对Excel文件进行zip压缩
1:新建 ZipUtils 工具类 package com.ly.cloud.datacollection.util;import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import java.net.URLEncoder; import ja…...
改进YOLO系列:12.Repulsion损失函数【遮挡】
1. RepLoss论文 物体遮挡问题可以分为类内遮挡和类间遮挡两种情况。类间遮挡产生于扎堆的同类物体,也被称为密集遮挡(crowd occlusion)。Repulsion损失函数由三个部分构成,yolov5样本匹配,得到的目标框和预测框-一对应第一部分主要作用:预测目标框吸引IOU最大的真实目标框,…...

win11网络连接正常,但是无法正常上网
前言: 这个是一个win11的bug,好多人都遇到了,在孜孜不倦的百度下,毫无收获,终于是在抖音上看到有人分享的经验而解决了这个问题。 找到internet选项,然后点击打开 选择连接 将代理服务器中,为…...

硬科技企业社区“曲率引擎”品牌正式发布
“曲率引擎”,是科幻作品中最硬核的加速系统,通过改变时空的曲率,可实现光速飞行甚至能够超越光速。11月3日,“曲率引擎(warp drive)”作为硬科技企业社区品牌,在2023全球硬科技创新大会上正式对…...
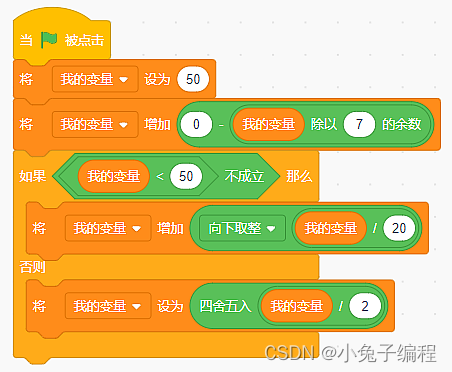
少儿编程 2023年9月中国电子学会图形化编程等级考试Scratch编程三级真题解析(判断题)
2023年9月scratch编程等级考试三级真题 判断题(共10题,每题2分,共20分) 19、运行程序后,“我的变量”的值为25 答案:对 考点分析:考查积木综合使用,重点考查变量和运算积木的使用 开始我的变量为50,执行完第二行代码我的变量变为49,条件不成立执行否则语句,所以…...

MCU常见通信总线串讲(二)—— RS232和RS485
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言一…...

LazyVim: 将 Neovim 升级为完整 IDE | 开源日报 No.67
curl/curl Stars: 31.5k License: NOASSERTION Curl 是一个命令行工具,用于通过 URL 语法传输数据。 核心优势和关键特点包括: 可在命令行中方便地进行数据传输支持多种协议 (HTTP、FTP 等)提供丰富的选项和参数来满足不同需求 kubernetes/ingress-n…...

想要搭建网站帮助中心,看这一篇指南就对了!
在现今互联网时代,除了让用户了解产品的功能和一些操作,很多企业都需要在网上进行信息的发布和产品销售等业务活动。而这就需要一个帮助中心,在用户遇到问题或者需要了解更多信息的时候,能够快速地解答他们的疑惑和提供响应的帮助…...

92.更新一些收藏的经验贴总结学习
一、JS相关 1.进制转换 (1)十进制转二进制 十进制数除2取余法:十进制数除2,余数为权位上的数,得到的商继续除2,直到商为0。最后余数从下往上取值。 (2)二进制转十进制 把二进制…...

mysql 问题解决 4
7、集群 7.1 日志 1、MySQL 中有哪些常见日志? MySQL 中有以下常见的日志类型: 错误日志(Error Log):记录 MySQL 服务器在运行过程中出现的错误信息。通用查询日志(General Query Log):记录所有连接到 MySQL 服务器的 SQL 查询语句。慢查询日志(Slow Query Log):…...

llama-7B、vicuna-7b-delta-v1.1和vicuna-7b-v1.3——使用体验
Chatgpt的出现给NLP领域带来了让人振奋的消息,可以很逼真的模拟人的对话,回答人们提出的问题,不过Chatgpt参数量,规模,训练代价都很昂贵。 幸运的是,出现了开源的一些相对小的模型,可以在本地或…...

深入理解JVM虚拟机第十九篇:JVM字节码中方法内部的结构和与局部变量表中变量槽的介绍
大神链接:作者有幸结识技术大神孙哥为好友,获益匪浅。现在把孙哥视频分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员 本专栏简介:话不多说,让我们一起干翻JVM 本文章简介:话不多说,让我们讲清楚虚拟机栈存储结构和运行原理 文章目…...

windows好玩的cmd命令
颜色 后边的数字查表吧,反正我是喜欢一个随机的数字 color 01MAC getmac /v更新主机IP地址 通过DHCP更新 ipconfig /release ipconfig /renew改标题 title code with 你想要的标题...
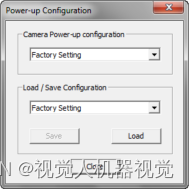
线扫相机DALSA--常见问题四:修改相机参数,参数保存无效情况
该问题是操作不当,未按照正常步骤保存参数所致,相机为RAM机制,参数需保存在采集卡的ROM内。 保存参数步骤: ①首先将相机参数保存至User Set1; ②然后回到Board(采集卡)参数设置区,鼠标选中Basic Timing&a…...

linux中用date命令获取昨天、明天或多天前后的日期
在实际操作中,一些脚本中会调用明天,或者昨天,或更多天前的日期,本文将叙述讲述用date命令实现时间的显示。在Linux系统中用man date -d 查询的参数说的比较模糊,以下举例进一步说明: # man date -d, --da…...
【无标题】360压缩软件怎么用?超级好用!
360压缩是一款功能强大的解压缩软件,如何用它压缩文件呢?下面给出了详细的操作步骤。 一、360压缩详细步骤 1、下载软件后,在电脑上右击需要压缩的文件,在弹出的菜单中点击【添加到压缩文件】选项。 2、在360压缩窗口中按需设置相…...
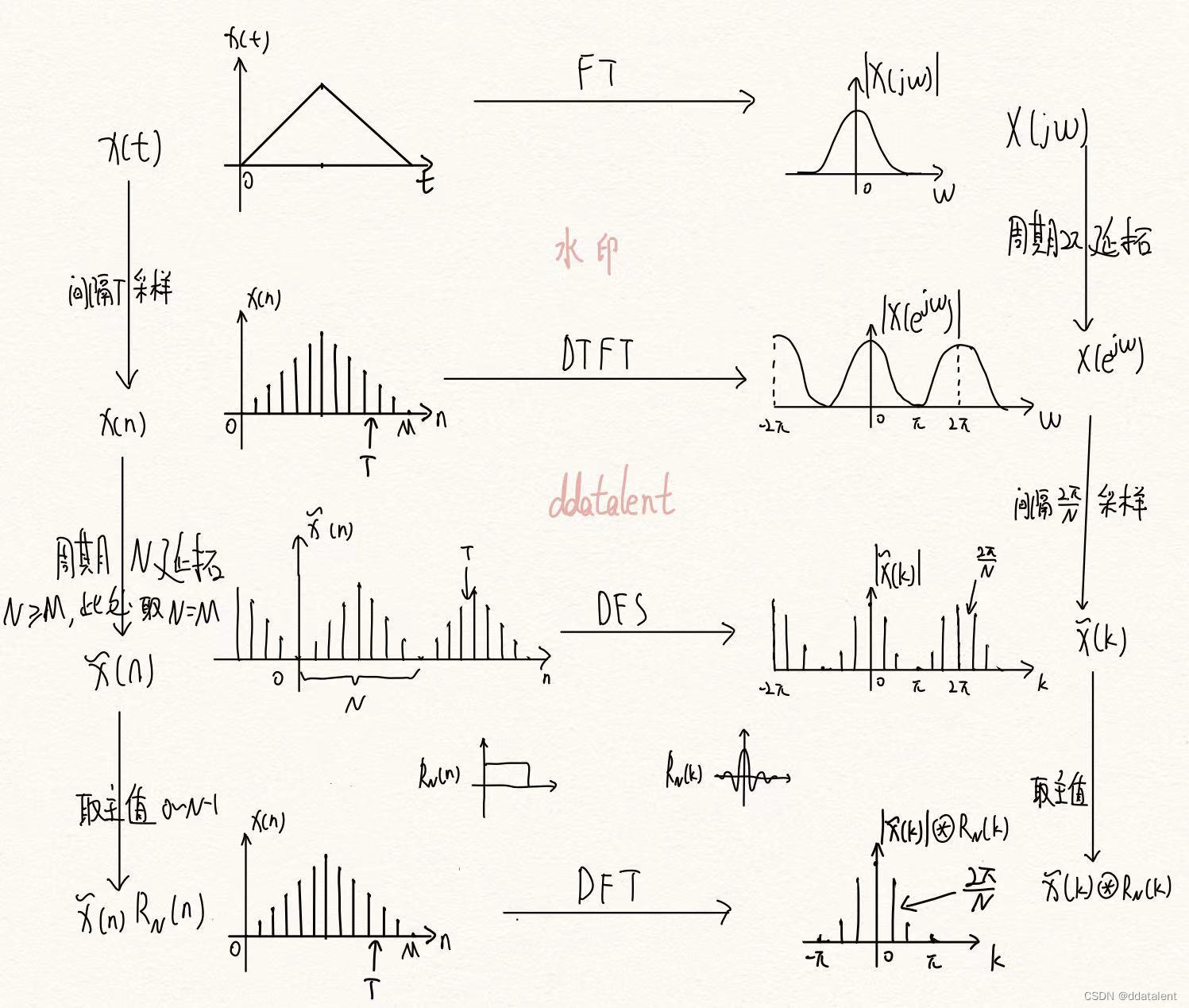
一图搞懂傅里叶变换(FT)、DTFT、DFS和DFT之间的关系
自然界中的信号都是模拟信号,计算机无法处理,因此我们会基于奈奎斯特定理对模拟信号采样得到数字信号。 但是我们发现,即便是经过采样,在时域上得到了数字信号,而在频域上还是连续信号。 因此我们可以在时域中选取N点…...
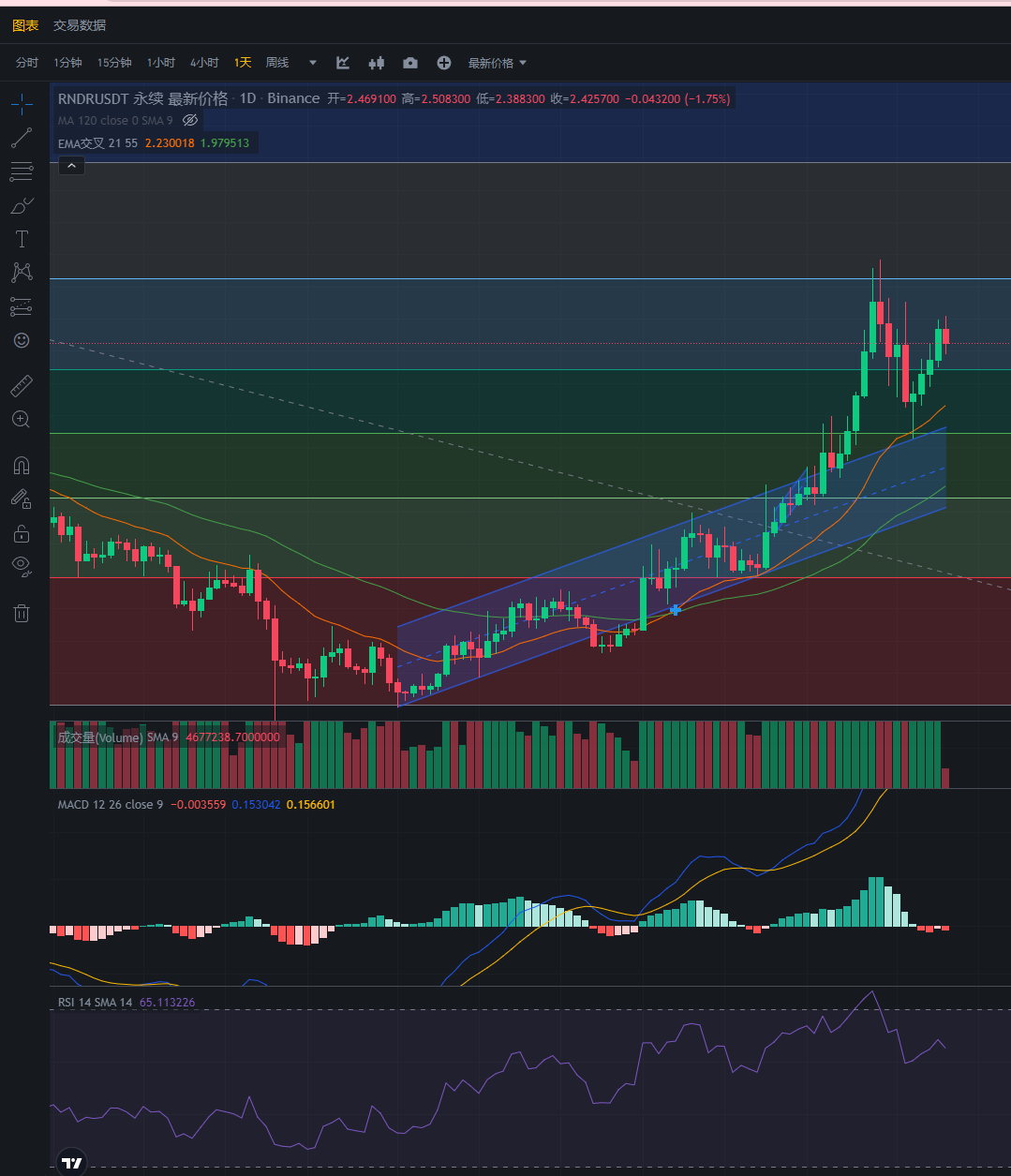
行情分析——加密货币市场大盘走势(11.7)
大饼昨日下跌过后开始有回调的迹象,现在还是在做指标修复,大饼的策略保持逢低做多。稳健的依然是不碰,目前涨不上去,跌不下来。 以太昨天给的策略,依然有效,现在以太坊开始回调。 目前来看,回踩…...

别再只盯着mAP了:用YOLO做项目时,TP/FP/FN这些指标到底该怎么看?
别再只盯着mAP了:用YOLO做项目时,TP/FP/FN这些指标到底该怎么看? 当你第一次看到YOLO模型的预测结果时,那些密密麻麻的边界框可能会让你感到既兴奋又困惑。兴奋的是模型确实检测到了目标,困惑的是——这些检测结果到底…...

OpenClaw内存优化:Qwen3-32B在24G显存下的高效利用技巧
OpenClaw内存优化:Qwen3-32B在24G显存下的高效利用技巧 1. 为什么需要关注显存优化? 当我第一次在RTX 4090D上部署Qwen3-32B模型时,本以为24GB显存足够应对各种任务。但实际运行OpenClaw后,很快就遇到了显存溢出的问题——一个简…...

RTOS在嵌入式开发中的核心价值与实战应用
1. RTOS在嵌入式开发中的核心价值我第一次接触RTOS是在2015年开发工业控制器时遇到的困境。当时用裸机编程实现多任务调度,代码已经膨胀到难以维护的程度。一个简单的功能修改需要通读上万行代码,调试一个BUG经常引发连锁反应。直到引入RTOS后࿰…...

Linux系统调用原理与性能优化实践
1. Linux系统调用基础概念在Linux系统中,系统调用是用户空间程序与内核交互的唯一合法途径。作为操作系统最基础的接口,它就像一扇严格管控的大门,既保护了内核的安全稳定,又为应用程序提供了必要的服务支持。为什么需要这种隔离机…...

LangChain与向量库集成:Document Loaders与Text Splitters
上周三凌晨两点,我被一个奇怪的召回问题卡住了:明明在PDF里写得很清楚的配置项,用相似问题去查向量库,总是返回一些边缘内容。打开调试日志一看,发现切出来的文本片段里,前半段是某个章节的结尾,…...

seo网站诊断需要哪些资料_seo网站诊断的重要性是什么
SEO网站诊断需要哪些资料 网站的关键字分析资料 关键字分析是SEO网站诊断中的核心部分之一。你需要收集关于网站当前使用的关键字的数据,包括关键字的搜索量、竞争程度、点击率和转化率等信息。可以使用工具如Google关键字规划师、Ahrefs或SEMrush来获取这些数据。…...

AO3镜像站终极访问指南:3步解决同人作品访问难题
AO3镜像站终极访问指南:3步解决同人作品访问难题 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site Archive of Our Own(AO3)作为全球最大的同人作品平台,为无数创作者和读…...

飞腾D3000M一体机主板硬核动力打破金融移动终端应用落地壁垒
数字经济浪潮下,金融行业正加速迈入“移动化信创化”双轮驱动时代,移动终端已成为连接金融机构与客户的核心枢纽,承载着交易结算、风险管控、服务触达等关键职能。然而,金融场景的特殊性的要求,让终端设备不仅需要强劲…...

中国科技发展与华人贡献解析
中国科技发展与华人贡献解析纵观全球科技发展的壮阔历程,华人力量始终是不可或缺的核心支柱,中国科技的崛起与腾飞,既离不开本土科研工作者的深耕细作,更得益于海外华人的默默坚守与无私奉献。然而,长期以来࿰…...

CANoe诊断实战:从Console到Fault Memory的故障排查全流程
1. 当车辆故障灯突然亮起时,工程师如何用CANoe快速定位问题 那天我正在测试车间调试一台新车型的ECU,仪表盘上那个刺眼的黄色故障灯突然亮了起来。作为从业多年的汽车电子工程师,我立刻意识到这可能是偶发性故障——最让人头疼的问题类型。不…...