lamada表达式、stream、collect整理
lamada表达式格式
格式:( parameter-list ) -> { expression-or-statements }
实例:简化匿名内部类的写法
原本写法:
public class LamadaTest {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("沉默王二");
}
}).start();
}
}
直接通过lamada表达式可以改写成:
public class LamadaTest {
public static void main(String[] args) {
new Thread(() -> {System.out.println("沉默王二")}.start();
}
}
2 结合foreach替代for循环
List<Student> stus = Lists.newArrayList();//假设stus里面有数据,这里就不添加了
stus.foreach(stu->system.out.println(stu.getName()));
或者采用如下遍历方式:
for(Student stu : stus){
system.out.println(stu.getName());
}
lamada实现排序
Collections.sort(list,(Integer o1,Integer o2) ->{
return o2-o1;
}) //降序
stream流相关
https://blog.csdn.net/anyi2351033836/article/details/125027710
filter操作
方法的定义,源码如下Stream filter(Predicate< super T> predicate);一个单纯的过滤操作直接返回传入类型
String[] dd = { “a”, “b”, “c” };
Stream stream = Arrays.stream(dd);
stream.filter(str -> str.equals(“a”)).forEach(System.out::println);//返回字符串为a的值
stream项目实例:
CppBankExercise cppBankExercise = exerciseList.stream().filter(exercise -> Objects.equals(projectId, exercise.getProjectId())).findFirst().orElse(null);
map操作
先看方法定义,源码如下** Stream map(Function< super T, extends R> mapper);**
这个方法传入一个Function的函数式接口,这个接口,接收一个泛型T,返回泛型R,map函数的定义,返回的流,表示的泛型是R对象,这个表示,调用这个函数后,可以改变返回的类型
Integer[] dd = { 1, 2, 3 };
Stream<Integer> stream = Arrays.stream(dd);
stream.map(str -> Integer.toString(str)).forEach(str -> {
System.out.println(str);// 1 ,2 ,3
System.out.println(str.getClass());// class java.lang.String
});
List<String> list = Arrays.asList(bankProjectQueryDto.getArithmeticLabel().split(",")).stream().map(label -> labelBiz.getArithmeticLabelById(label)).collect(Collectors.toList());
总结:无论是经过filte\map都是返回的stream
stream转化成clollector的方法
1️ collect是Stream流的一个终止方法,会使用传入的收集器(入参)对结果执行相关的操作,这个收集器必须是Collector接口的某个具体实现类
2️ Collector是一个接口,collect方法的收集器是Collector接口的具体实现类
3️ Collectors是一个工具类,提供了很多的静态工厂方法, 提供了很多Collector接口的具体实现类,是为了方便程序员使用而预置的一些较为通用的收集器(如果不使用Collectors类,而是自己去实现Collector接口,也可以)
又可将收集器分为几种不同的大类:恒等 归约 分组,如下图
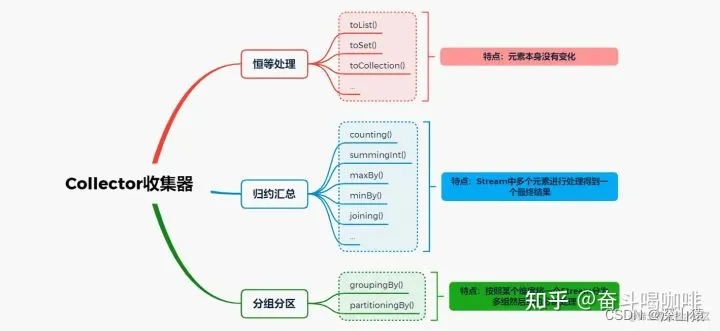
恒等,例如toList()操作,只是最终将结果从Stream中取出放入到List对象中,并没有对元素本身做任何的更改处理,如:
list.stream().collect(Collectors.toList());
list.stream().collect(Collectors.toSet());
list.stream().collect(Collectors.toCollection());
归约,如Collectors.summingInt(),Stream流中的元素逐个遍历,进入到Collector处理函数中,然后会与上一个元素的处理结果进行合并处理,并得到一个新的结果
例1:计算总薪资
public void calculateSum() {
Integer salarySum = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.summingInt(Employee::getSalary));
System.out.println(salarySum);
}
例2:找薪资最高的员工
Optional<Employee> highestSalaryEmployee = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.max(Comparator.comparingInt(Employee::getSalary));
分组
常规的数据分组操作时,可以仅传入一个分组函数,这样collect返回的结果,就是一个HashMap,其每一个HashValue的值为一个List类型。
// 按照子公司维度将员工分组
Map<String, List<Employee>> resultMap = getAllEmployees()
.stream().collect(Collectors.groupingBy(Employee::getSubCompany));
collect返回的结果,就是一个HashMap,其每一个HashValue的值为一个List类型。
如果不仅需要分组,还需要对分组后的数据进行处理的时候,则需要同时给定分组函数以及值收集器:
public void groupAndCaculate() {
// 按照子公司分组,并统计每个子公司的员工数
Map<String, Long> resultMap = getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany,
Collectors.counting()));
System.out.println(resultMap);
}
public void filterEmployeesThenGroupByStream() {
Map<String, List<Employee>> resultMap = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(resultMap);
}
public void streamFilterAndMap(){
List<String> addressList = data.toJavaList(DecrepitHouseInfo.class).stream().filter(item -> {
//filter 过滤目标,返回值true:保留 返回值false:不保留
return "C".equals(item.getType()) && "泥木结构".equals(item.getType2());
}).map(item ->{
//map 映射 可改变数据结构,添加、删除、组合数据均可
return item.getCity()+item.getStreet();
}).collect(Collectors.toList());
System.out.println(JSON.toJSON(addressList));
}
for循环、foreache、stream性能对比
普通for循环、foreache、stream三种方式性能差别不大,甚至在少量数据的时候stream效率低于for循环,但是stream写法更简洁、提供了并发处理的方式、且丰富的功能可以简化代码。
stream的parallelStream
如果要操作的集合很大,如针对答题结果的数据统计,则可以使用并发流,充分利用机器多核的特性,实例如下:
List<CompStuInfoReq> registerReqs = notRegister.parallelStream().map(userEntry ->
CompStuInfoReq.builder()
.secretKey(Constants.UC_SECRET_KEY)
.userId(userEntry.getUserId())
.competitionId(userEntry.getCompetitionId())
.passwordSalt(userEntry.getPasswordSalt())
.passwordHash(userEntry.getPasswordHash())
.mobile(userInfoService.getDecryptMsg(userEntry.getMobile()))
.name(userEntry.getName())
.identity(userEntry.getIdentity())
.build())
.collect(Collectors.toList());
说明:
parallelStream默认使用了fork-join框架,其默认线程数是CPU核心数。也可以通过如下方式指定:
1.全局设置
在运行代码之前,加入如下代码:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "64");
一般不建议修改,因为修改虽然改进当前的业务逻辑,但对于整个项目中其它地方只是用来做非耗时的并行流运算,性能就不友好了,因为所有使用并行流parallerStream的地方都是使用同一个Fork-Join线程池,而Fork-Join线程数默认仅为cpu的核心数。最好是自己创建一个Fork-Join线程池来用,即下面的方法2。
2.默认优先用在CPU密集型计算中
这里有的人就说了,用在IO密集比如HTTP请求啊什么的这种耗时高的操作并行去请求不是效果显著吗
由于默认并行流使用的是全局的线程池,线程数量是根据cpu核数设置的,所以如果某个操作占用了线程,将影响全局其他使用并行流的操作
所以IO密集型场景的正确用法是自定义线程池来执行某个并行流操作
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
forkJoinPool.execute(() -> {
listByPage.parallelStream().forEach(str -> {
});
});
相关文章:
lamada表达式、stream、collect整理
lamada表达式格式 格式:( parameter-list ) -> { expression-or-statements } 实例:简化匿名内部类的写法 原本写法: public class LamadaTest { public static void main(String[] args) { new Thread(new Runnable() { …...
Nacos 入门微服务项目实战
Nacos 核心源码精讲 - IT贱男 - 掘金小册全方位源码精讲,深度剖析 Nacos 注册中心和配置中心的核心思想。「Nacos 核心源码精讲」由IT贱男撰写,375人购买https://s.juejin.cn/ds/BuC3Vs9/ Hi,大家好,欢迎大家来学习《Nacos 核心源…...
【c++】类和对象:让你明白“面向一个对象有多重要”:构造函数,析构函数,拷贝构造函数的深入学习
文章目录 什么是面向对象?一:类是什么? 1.类的访问限定符 2.封装 3.类的实例化 4.this指针二:类的6个默认成员函数 1.构造函数 2.析构函数 3.拷贝构造函数什么是面向对象? c语言是面向…...

职场IT老手教你3步教你玩转可视化大屏设计,让领导眼前一亮!
我是制造企业的IT中心的研发人员,平常工作就是配合业务部门出出报表,选型一些商业软件,并在内部负责实施运维。最近领导出去参观了一些数字化转型比较领先的工厂和制造企业,回来就甩给我几张图,问能不能我们也做几个这…...
【光伏功率预测】基于EMD-PCA-LSTM的光伏功率预测模型(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

大数据Kylin(二):Kylin安装使用
文章目录 Kylin安装使用 一、Kylin安装要求 二、Kylin安装 1、Kylin安装前环境准备...
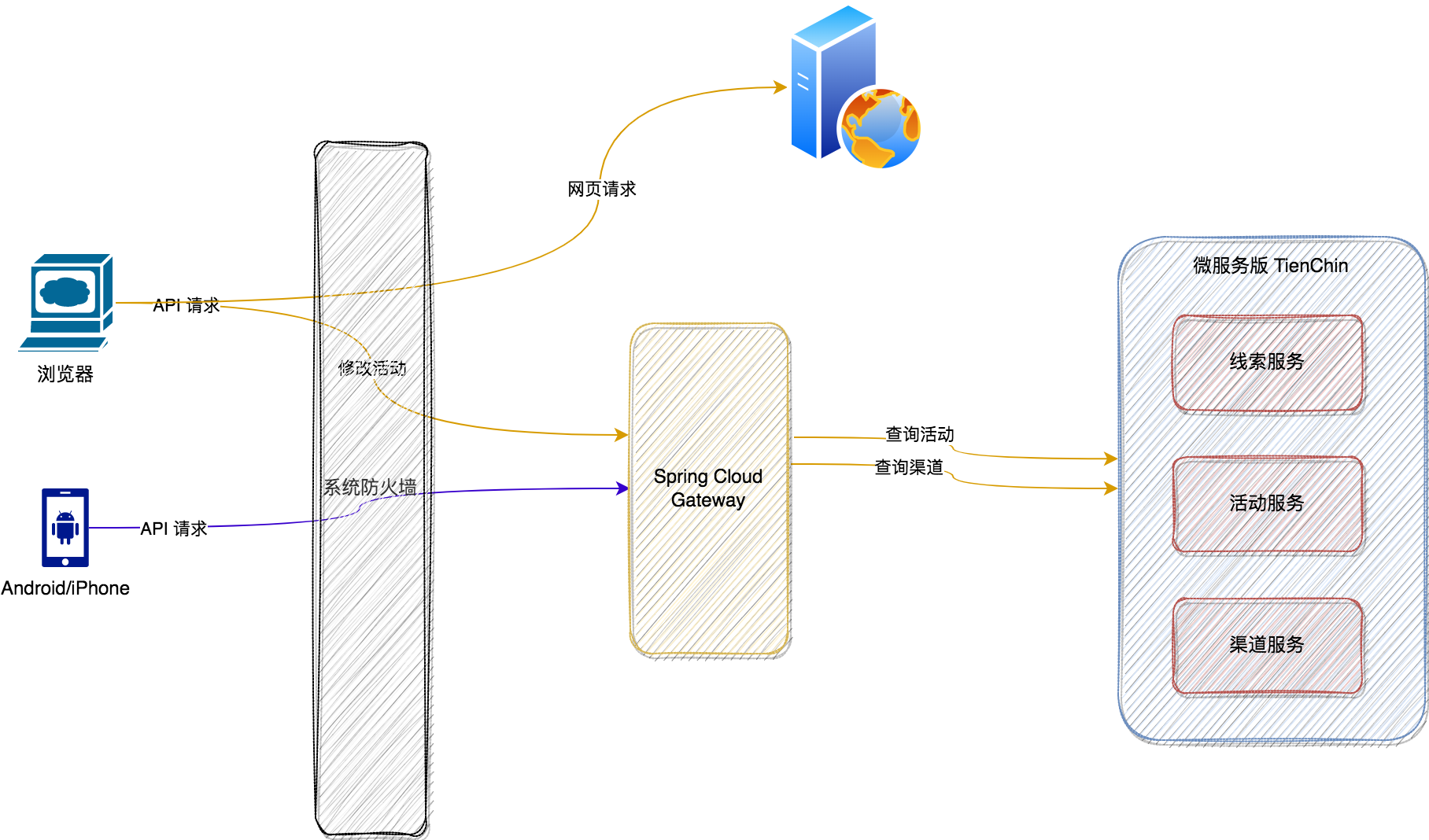
我们的微服务中为什么需要网关?
说起 Spring Cloud Gateway 的使用场景,我相信很多小伙伴都能够脱口而出认证二字,确实,在网关中完成认证操作,确实是 Gateway 的重要使用场景之一,然而并不是唯一的使用场景。在微服务中使用网关的好处可太多了&#x…...

互联网医院源码 线上问诊 智慧医院源码 C#源码
互联网医院平台源码 智慧医院管理系统源码 开发环境:ASP.NET C# VS2019 SQL2008 依托于实体医院利用互联网技术对接院内业务信息系统,向患者提供基于线上问诊、预约挂号、缴费结算、医患互动、诊后随访、健康科普和复诊等全面的医疗健康互联网服务。…...

基于昇腾计算语言AscendCL开发AI推理应用
01 初始AscendCL AscendCL(Ascend Computing Language,昇腾计算语言)是昇腾计算开放编程框架,是对底层昇腾计算服务接口的封装,它提供运行时资源(例如设备、内存等)管理、模型加载与执行、算子…...
JS document.write()换行
换行效果: 通过传递多个参数,即可实现换行效果: document.write("<br>",ar) 效果: 示例源码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&quo…...
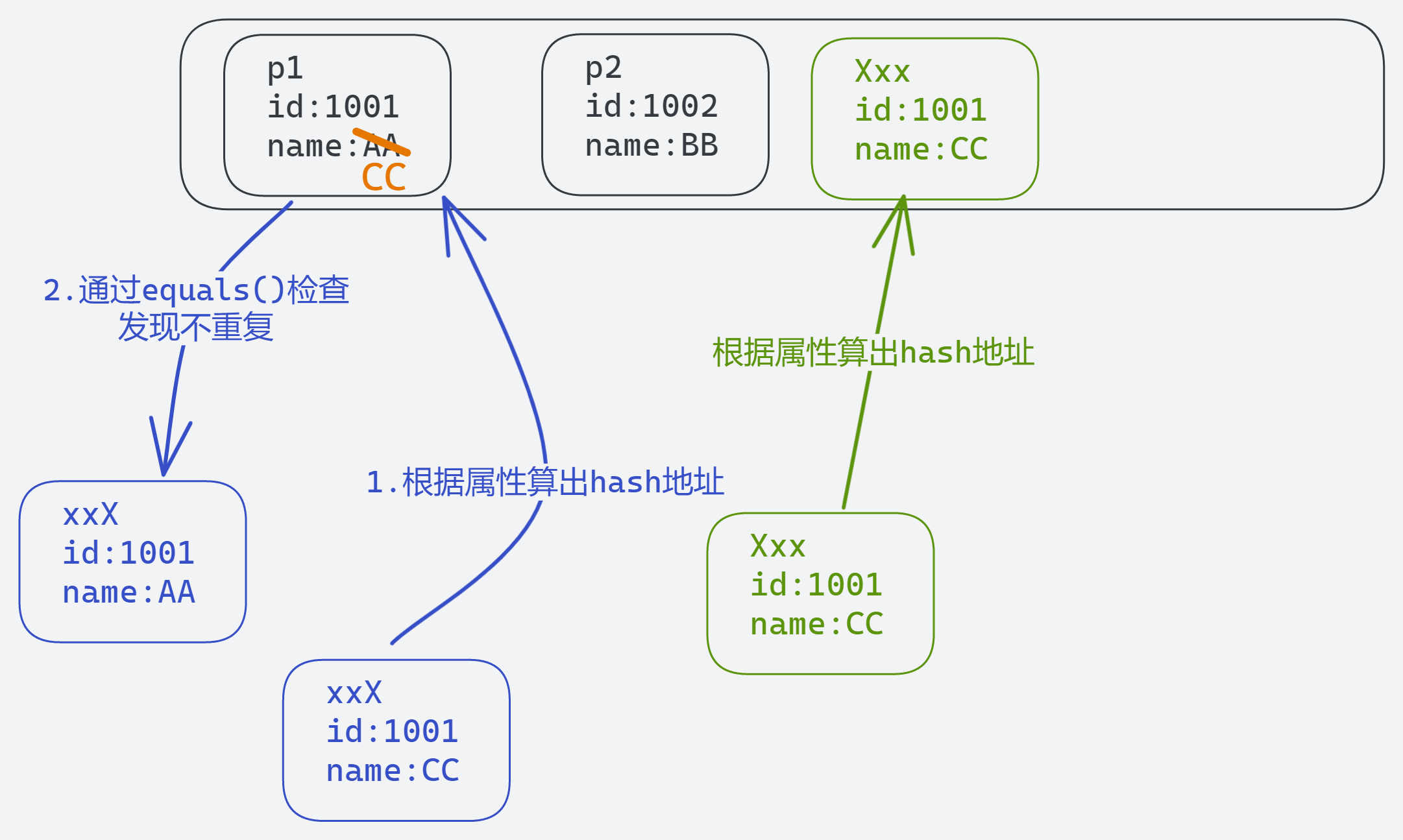
Java高级-集合-Collection部分
本篇讲解java集合 集合 集合框架的概述 集合、数组都是对多个数据进行存储操作的结构,简称Java容器。 说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi,数据库中…...
Android性能优化:getResources()与Binder交火导致的界面卡顿优化
欢迎:https://juejin.cn/post/7198430801851531324/ 欢迎:https://nasdaqgodzilla.github.io/2023/02/10/Android%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%EF%BC%9AgetResources-%E4%B8%8EBinder%E4%BA%A4%E7%81%AB%E5%AF%BC%E8%87%B4%E7%9A%84%E7%95%8C%E…...

常见的内存操作函数
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...

python关键字
文章目录1 and、or、not2 if、elif、else3 for、while4 True、False5 continue、break6 pass7 try、except、finally、raise8 import、from、as9 def、return10 class11 lambda12 del13 global、nonlocal14 in、is15 None16 assert17 with18 yield1 and、or、not and、or、not…...
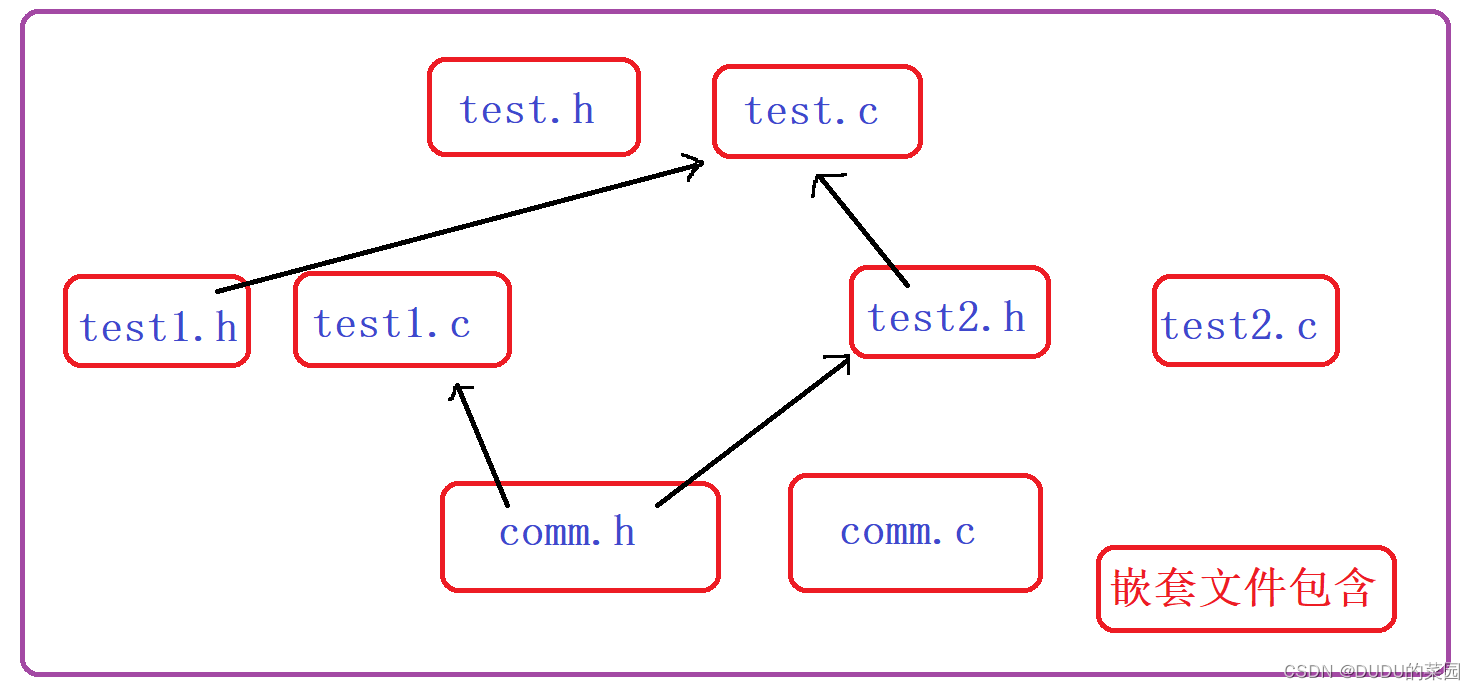
C语言 | 预处理知识详解 #预处理指令有哪些?他们如何使用?宏和函数有哪些区别?...#
文章目录前言预定义符号介绍预处理指令#define#define替换规则预处理指令 #undef宏和函数的对比宏和函数的对比图命名约定命令行定义条件编译预处理指令 #include嵌套文件包含其他预处理指令写在最后前言 上篇文章介绍了一个程序运行的 编译与链接 ,其中编译阶段有个…...
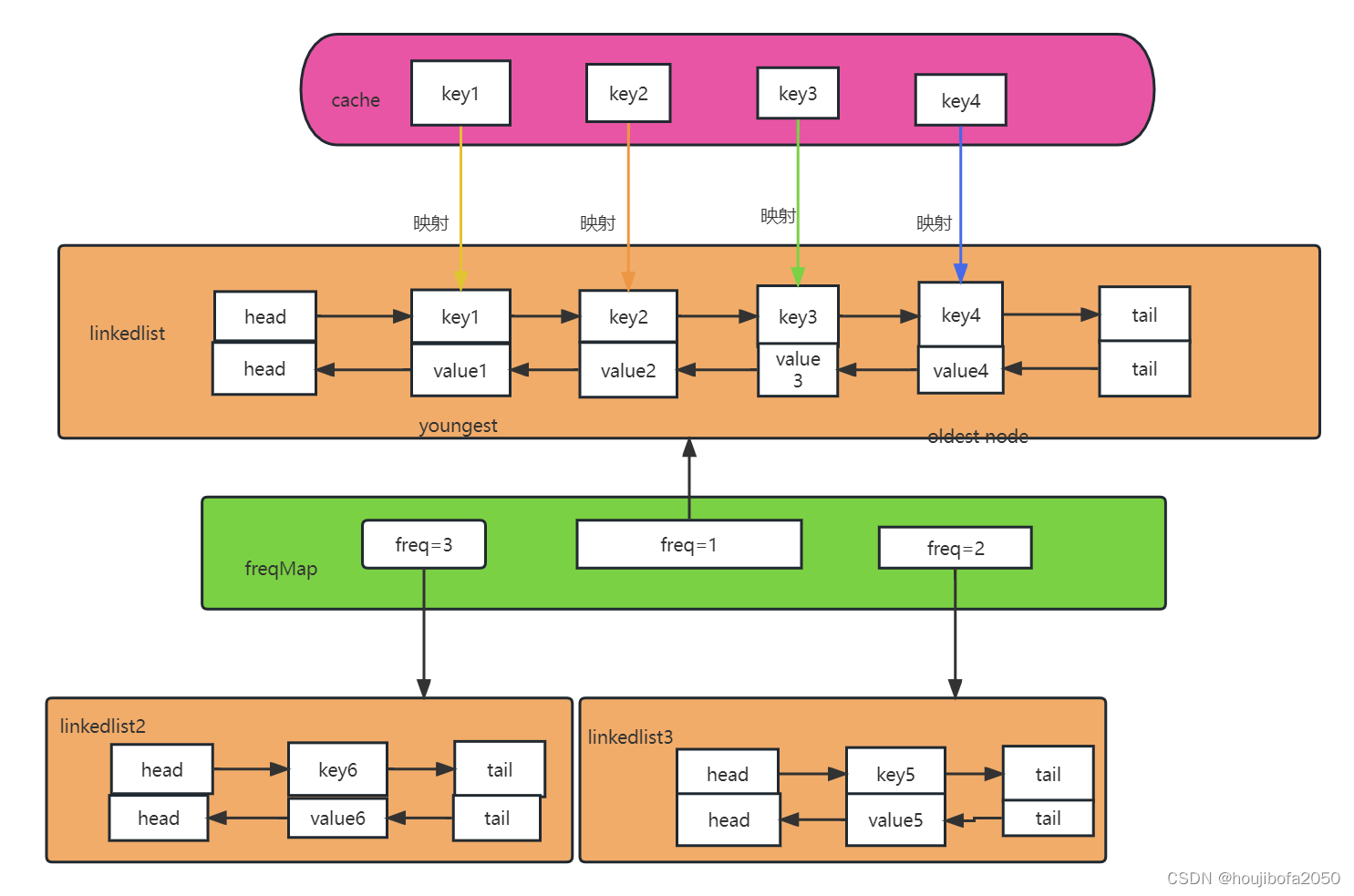
如何实现LFU缓存(最近最少频率使用)
目录 1.什么是LFU缓存? 2.LFU的使用场景有哪些? 3.LFU缓存的实现方式有哪些? 4.put/get 函数实现具体功能 1.什么是LFU缓存? LFU缓存是一个具有指定大小的缓存,随着添加元素的增加,达到容量的上限&…...
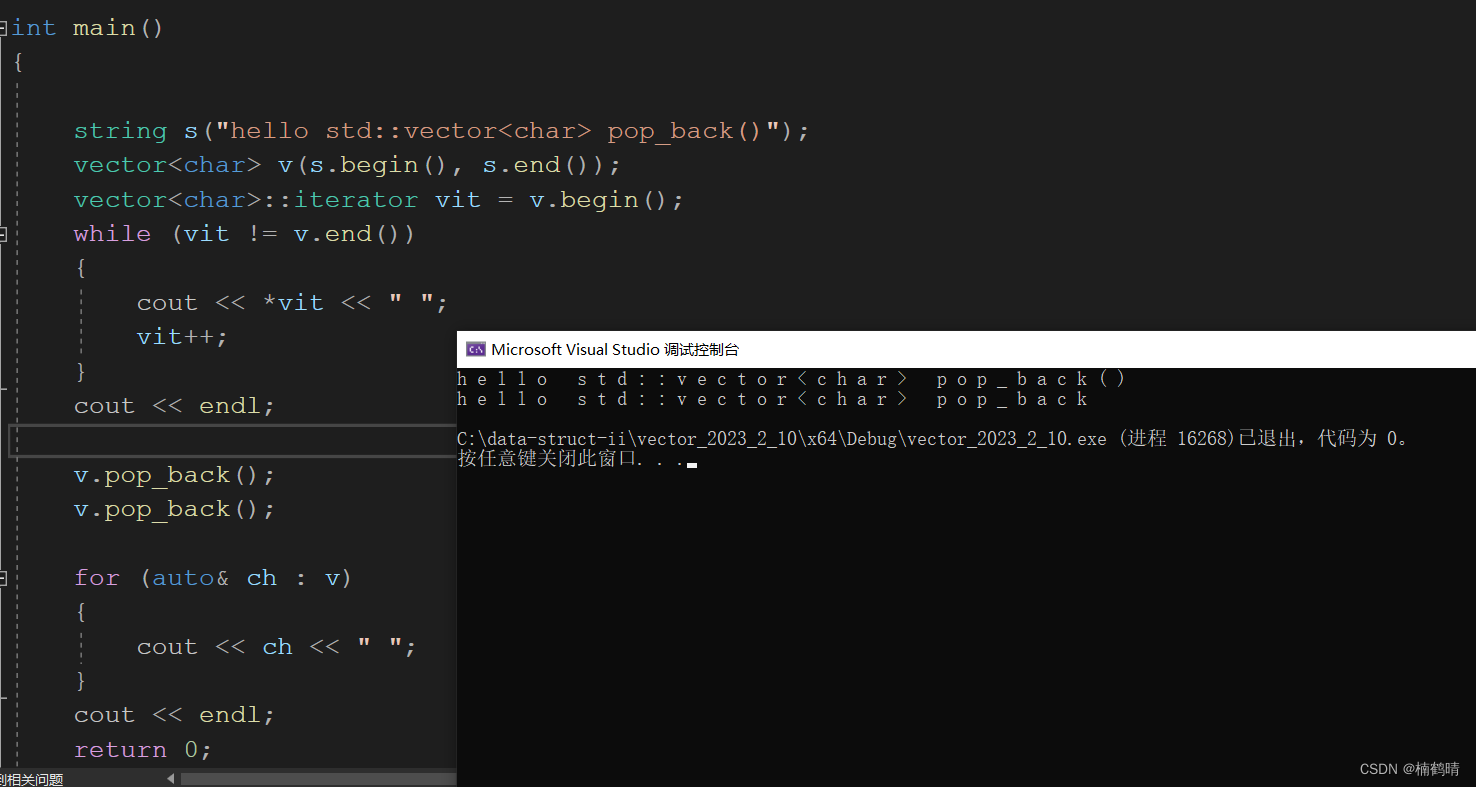
【C++之容器篇】精华:vector常见函数的接口的熟悉与使用
目录前言一、认识vector1. 介绍2. 成员类型二、默认成员函数(Member functions)1. 构造函数2. 拷贝构造函数vector (const vector& x);3. 析构函数4. 赋值运算符重载函数三、迭代器(Iterators)1. 普通对象的迭代器2. const对象…...
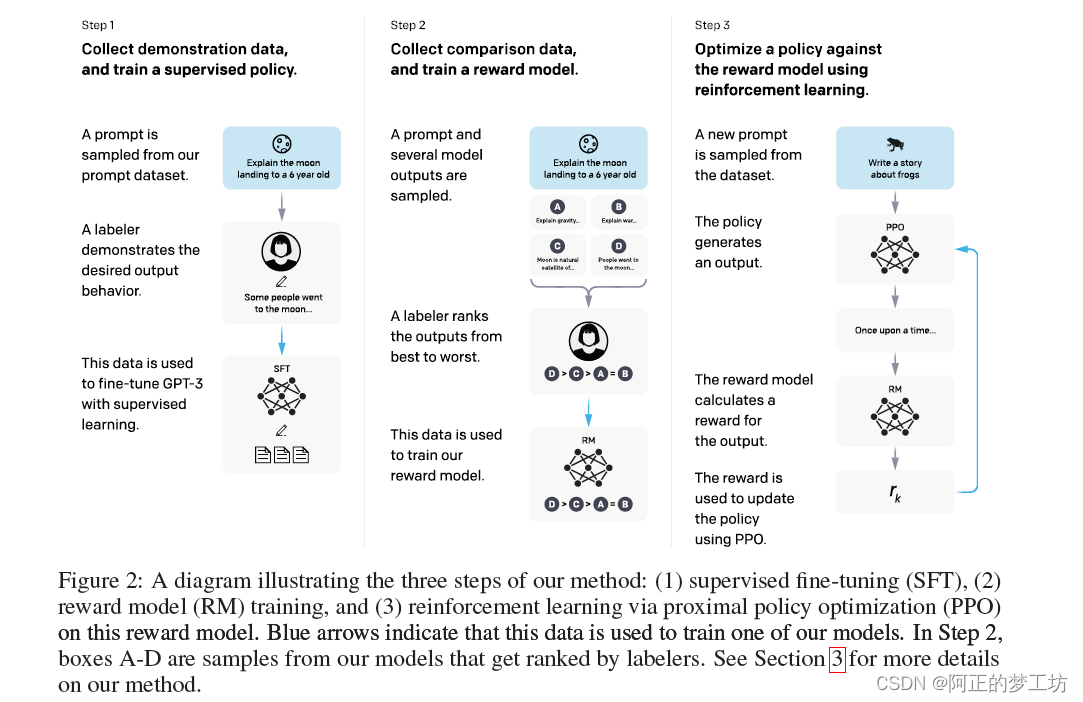
InstructGPT
文章目录Abstract 给定人类的命令,并且用人工标注想要的结果,构成数据集,使用监督学习来微调GPT-3。 然后,我们对模型输出进行排名,构成新的数据集,我们利用强化学习来进一步微调这个监督模型。 我们把产…...
)
RTOS之一环境搭建(基于TM4C123GXL)
硬件TM4C123GXLBOOSTXL-EDUMKII keil5micriumOSA软件安装:1 ARM-MDK(MDK538aMDK_Stellaris_ICDI_AddOn)MDK538a链接:https://www.keil.com/demo/eval/arm.htmICDI链接:https://documentation-service.arm.com/static/60509bd61da8f8344a2ca1b…...
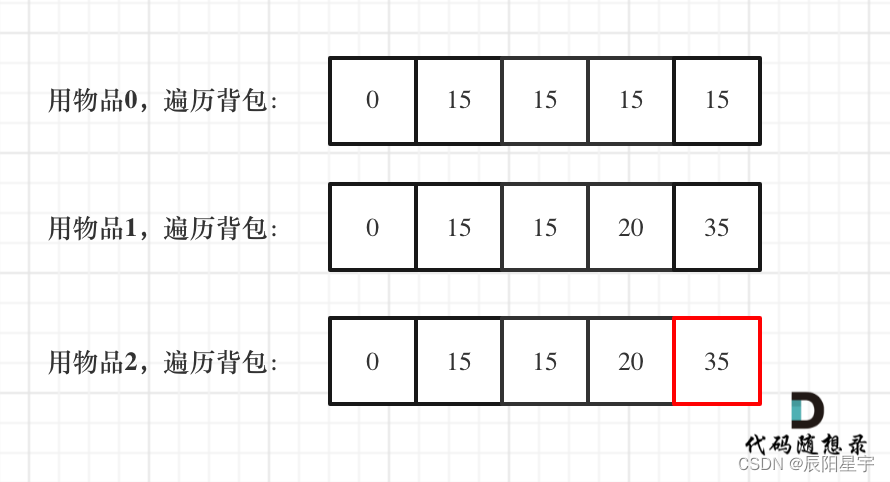
151、【动态规划】AcWing ——2. 01背包问题:二维数组+一维数组(C++版本)
题目描述 原题链接:2. 01背包问题 解题思路 (1)二维dp数组 动态规划五步曲: (1)dp[i][j]的含义: 容量为j时,从物品1-物品i中取物品,可达到的最大价值 (2…...

还在手工整理IT报表?这套自动化模板让你彻底解放双手
在不断变化的IT管理环境中,透明度和合规性已成为企业生存和发展的基石。面对日益繁杂的法规与标准,组织需要精细的报表与审计流程来支撑业务稳健运行。作为一款专为现代IT打造的尖端平台,Endpoint Central不仅大幅减轻了合规负担,…...

从预处理指令看跨语言兼容:手把手封装C++库供C调用的5个关键步骤
从预处理指令看跨语言兼容:手把手封装C库供C调用的5个关键步骤 在嵌入式开发和SDK设计中,经常需要将C库封装成C语言接口。这种跨语言调用看似简单,实则暗藏玄机。本文将深入剖析extern "C"和__cplusplus预处理指令的底层原理&#…...

图表数据提取的智能转换革命:从像素到数据点的精准跨越
图表数据提取的智能转换革命:从像素到数据点的精准跨越 【免费下载链接】WebPlotDigitizer WebPlotDigitizer: 一个基于 Web 的工具,用于从图形图像中提取数值数据,支持 XY、极地、三角图和地图。 项目地址: https://gitcode.com/gh_mirror…...

OpenClaw成本优化方案:ollama GLM-4-7-Flash替代OpenAI API实测
OpenClaw成本优化方案:ollama GLM-4-7-Flash替代OpenAI API实测 1. 为什么需要寻找OpenAI API的替代方案 去年我开始在个人项目中使用OpenClaw实现自动化办公流程时,很快被OpenAI API的token消耗速度震惊了。一个简单的"读取邮件附件-解析内容-生…...

Qwen2-VL-2B-Instruct性能优化:Web服务并发请求处理与队列管理
Qwen2-VL-2B-Instruct性能优化:Web服务并发请求处理与队列管理 当你的AI图片分析服务突然火了,用户蜂拥而至,同时上传几十张图片要求分析,会发生什么?最直接的结果可能就是服务器卡死,用户看到“服务超时”…...

像素幻梦工坊实战落地:数字艺术教育机构像素创作课AI教具部署
像素幻梦工坊实战落地:数字艺术教育机构像素创作课AI教具部署 1. 项目背景与教育价值 在数字艺术教育领域,像素艺术作为入门门槛较低但创意空间广阔的艺术形式,正受到越来越多教育机构的青睐。然而传统像素艺术教学面临两大挑战:…...

[认知计算] 神经网络架构:从生物启发的神经元到现代激活函数演进
1. 从生物神经元到人工神经元的数学抽象 1943年,麦卡洛克和皮茨在论文《神经活动中内在思想的逻辑演算》中首次提出用数学模型模拟生物神经元。这个看似简单的想法,彻底改变了人类对智能的认知方式。生物神经元由树突、细胞体和轴突三部分组成࿱…...

像素幻梦工坊实战案例:为开源像素游戏引擎PixiJS提供AI素材管道
像素幻梦工坊实战案例:为开源像素游戏引擎PixiJS提供AI素材管道 1. 项目背景与价值 在游戏开发领域,像素艺术因其独特的复古魅力和相对较低的制作成本,始终保持着旺盛的生命力。然而传统像素素材创作需要艺术家逐像素绘制,耗时耗…...

什么时候会触发FullGC
面试 1、老年代空间不足。应该让对象在年轻代多存活一段时间,不要创建过大的对象及数组。 2、元空间满了。说明此时,系统中要加载的类、反射的类和调用的方法较多。 3、MinorGC执行后晋升到老年代的平均大小大于老年代的剩余空间。...

如何快速使用iOS App Signer:iOS应用签名完整指南
如何快速使用iOS App Signer:iOS应用签名完整指南 【免费下载链接】ios-app-signer DanTheMan827/ios-app-signer: 是一个 iOS 应用的签名工具,适合用于 iOS 开发中,帮助开发者签署和发布他们的 APP。 项目地址: https://gitcode.com/gh_mi…...