pandas教程:Introduction to pandas Data Structures pandas的数据结构
文章目录
- Chapter 5 Getting Started with pandas
- 5.1 Introduction to pandas Data Structures
- 1 Series
- 2 DataFrame
- 3 Index Objects (索引对象)
Chapter 5 Getting Started with pandas
这样导入pandas:
import pandas as pd
e:\python3.7\lib\site-packages\numpy\_distributor_init.py:32: UserWarning: loaded more than 1 DLL from .libs:
e:\python3.7\lib\site-packages\numpy\.libs\libopenblas.TXA6YQSD3GCQQC22GEQ54J2UDCXDXHWN.gfortran-win_amd64.dll
e:\python3.7\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dllstacklevel=1)
另外可以导入Series和DataFrame,因为这两个经常被用到:
from pandas import Series, DataFrame
5.1 Introduction to pandas Data Structures
数据结构其实就是Series和DataFrame。
1 Series
这里series我就不翻译成序列了,因为之前的所有笔记里,我都是把sequence翻译成序列的。
series是一个像数组一样的一维序列,并伴有一个数组表示label,叫做index。创建一个series的方法也很简单:
obj = pd.Series([4, 7, -5, 3])
obj
0 4
1 7
2 -5
3 3
dtype: int64
可以看到,左边表示index,右边表示对应的value。可以通过value和index属性查看:
obj.values
array([ 4, 7, -5, 3], dtype=int64)
obj.index # like range(4)
RangeIndex(start=0, stop=4, step=1)
当然我们也可以自己指定index的label:
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
d 4
b 7
a -5
c 3
dtype: int64
obj2.index
Index(['d', 'b', 'a', 'c'], dtype='object')
可以用index的label来选择:
obj2['a']
-5
obj2['d'] = 6
obj2[['c', 'a', 'd']]
c 3
a -5
d 6
dtype: int64
这里[‘c’, ‘a’, ‘d’]其实被当做了索引,尽管这个索引是用string构成的。
使用numpy函数或类似的操作,会保留index-value的关系:
obj2[obj2 > 0]
d 6
b 7
c 3
dtype: int64
obj2 * 2
d 12
b 14
a -10
c 6
dtype: int64
import numpy as np
np.exp(obj2)
d 403.428793
b 1096.633158
a 0.006738
c 20.085537
dtype: float64
另一种看待series的方法,它是一个长度固定,有顺序的dict,从index映射到value。在很多场景下,可以当做dict来用:
'b' in obj2
True
'e' in obj2
False
还可以直接用现有的dict来创建series:
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon':16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
obj3
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
series中的index其实就是dict中排好序的keys。我们也可以传入一个自己想要的顺序:
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
顺序是按states里来的,但因为没有找到california,所以是NaN。NaN表示缺失数据,用之后我们提到的话就用missing或NA来指代。pandas中的isnull和notnull函数可以用来检测缺失数据:
pd.isnull(obj4)
California True
Ohio False
Oregon False
Texas False
dtype: bool
pd.notnull(obj4)
California False
Ohio True
Oregon True
Texas True
dtype: bool
series也有对应的方法:
obj4.isnull()
California True
Ohio False
Oregon False
Texas False
dtype: bool
关于缺失数据,在第七章还会讲得更详细一些。
series中一个有用的特色自动按index label来排序(Data alignment features):
obj3
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
obj4
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
obj3 + obj4
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
这个Data alignment features(数据对齐特色)和数据库中的join相似。
series自身和它的index都有一个叫name的属性,这个能和其他pandas的函数进行整合:
obj4.name = 'population'
obj4.index.name = 'state'
obj4
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
series的index能被直接更改:
obj
0 4
1 7
2 -5
3 3
dtype: int64
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
obj
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int64
2 DataFrame
DataFrame表示一个长方形表格,并包含排好序的列,每一列都可以是不同的数值类型(数字,字符串,布尔值)。DataFrame有行索引和列索引(row index, column index);可以看做是分享所有索引的由series组成的字典。数据是保存在一维以上的区块里的。
(其实我是把dataframe当做excel里的那种表格来用的,这样感觉更直观一些)
构建一个dataframe的方法,用一个dcit,dict里的值是list:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002, 2003], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}frame = pd.DataFrame(data)frame
| pop | state | year | |
|---|---|---|---|
| 0 | 1.5 | Ohio | 2000 |
| 1 | 1.7 | Ohio | 2001 |
| 2 | 3.6 | Ohio | 2002 |
| 3 | 2.4 | Nevada | 2001 |
| 4 | 2.9 | Nevada | 2002 |
| 5 | 3.2 | Nevada | 2003 |
dataframe也会像series一样,自动给数据赋index, 而列则会按顺序排好。
对于一个较大的DataFrame,用head方法会返回前5行(注:这个函数在数据分析中经常使用,用来查看表格里有什么东西):
frame.head()
| pop | state | year | |
|---|---|---|---|
| 0 | 1.5 | Ohio | 2000 |
| 1 | 1.7 | Ohio | 2001 |
| 2 | 3.6 | Ohio | 2002 |
| 3 | 2.4 | Nevada | 2001 |
| 4 | 2.9 | Nevada | 2002 |
如果指定一列的话,会自动按列排序:
pd.DataFrame(data, columns=['year', 'state', 'pop'])
| year | state | pop | |
|---|---|---|---|
| 0 | 2000 | Ohio | 1.5 |
| 1 | 2001 | Ohio | 1.7 |
| 2 | 2002 | Ohio | 3.6 |
| 3 | 2001 | Nevada | 2.4 |
| 4 | 2002 | Nevada | 2.9 |
| 5 | 2003 | Nevada | 3.2 |
如果你导入一个不存在的列名,那么会显示为缺失数据:
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five', 'six'])
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | NaN |
| three | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
| six | 2003 | Nevada | 3.2 | NaN |
frame2.columns
Index(['year', 'state', 'pop', 'debt'], dtype='object')
从DataFrame里提取一列的话会返回series格式,可以以属性或是dict一样的形式来提取:
frame2['state']
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
six Nevada
Name: state, dtype: object
frame2.year
one 2000
two 2001
three 2002
four 2001
five 2002
six 2003
Name: year, dtype: int64
注意:frame2[column]能应对任何列名,但frame2.column的情况下,列名必须是有效的python变量名才行。
返回的series有DataFrame种同样的index,而且name属性也是对应的。
对于行,要用在loc属性里用 位置或名字:
frame2.loc['three']
year 2002
state Ohio
pop 3.6
debt NaN
Name: three, dtype: object
列值也能通过赋值改变。比如给debt赋值:
frame2['debt'] = 16.5
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | 16.5 |
| two | 2001 | Ohio | 1.7 | 16.5 |
| three | 2002 | Ohio | 3.6 | 16.5 |
| four | 2001 | Nevada | 2.4 | 16.5 |
| five | 2002 | Nevada | 2.9 | 16.5 |
| six | 2003 | Nevada | 3.2 | 16.5 |
frame2['debt'] = np.arange(6.)
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | 0.0 |
| two | 2001 | Ohio | 1.7 | 1.0 |
| three | 2002 | Ohio | 3.6 | 2.0 |
| four | 2001 | Nevada | 2.4 | 3.0 |
| five | 2002 | Nevada | 2.9 | 4.0 |
| six | 2003 | Nevada | 3.2 | 5.0 |
如果把list或array赋给column的话,长度必须符合DataFrame的长度。如果把一二series赋给DataFrame,会按DataFrame的index来赋值,不够的地方用缺失数据来表示:
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
frame2
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | NaN |
| two | 2001 | Ohio | 1.7 | -1.2 |
| three | 2002 | Ohio | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | -1.5 |
| five | 2002 | Nevada | 2.9 | -1.7 |
| six | 2003 | Nevada | 3.2 | NaN |
如果列不存在,赋值会创建一个新列。而del也能像删除字典关键字一样,删除列:
frame2['eastern'] = frame2.state == 'Ohio'
frame2
| year | state | pop | debt | eastern | |
|---|---|---|---|---|---|
| one | 2000 | Ohio | 1.5 | NaN | True |
| two | 2001 | Ohio | 1.7 | -1.2 | True |
| three | 2002 | Ohio | 3.6 | NaN | True |
| four | 2001 | Nevada | 2.4 | -1.5 | False |
| five | 2002 | Nevada | 2.9 | -1.7 | False |
| six | 2003 | Nevada | 3.2 | NaN | False |
然后用del删除这一列:
del frame2['eastern']
frame2.columns
Index(['year', 'state', 'pop', 'debt'], dtype='object')
注意:columns返回的是一个view,而不是新建了一个copy。因此,任何对series的改变,会反映在DataFrame上。除非我们用copy方法来新建一个。
另一种常见的格式是dict中的dict:
pop = {'Nevada': {2001: 2.4, 2002: 2.9},'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
把上面这种嵌套dict传给DataFrame,pandas会把外层dict的key当做列,内层key当做行索引:
frame3 = pd.DataFrame(pop)
frame3
| Nevada | Ohio | |
|---|---|---|
| 2000 | NaN | 1.5 |
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
另外DataFrame也可以向numpy数组一样做转置:
frame3.T
| 2000 | 2001 | 2002 | |
|---|---|---|---|
| Nevada | NaN | 2.4 | 2.9 |
| Ohio | 1.5 | 1.7 | 3.6 |
指定index:
pd.DataFrame(pop, index=[2001, 2002, 2003])
| Nevada | Ohio | |
|---|---|---|
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
| 2003 | NaN | NaN |
series组成的dict:
pdata = {'Ohio': frame3['Ohio'][:-1],'Nevada': frame3['Nevada'][:2]}
pd.DataFrame(pdata)
| Nevada | Ohio | |
|---|---|---|
| 2000 | NaN | 1.5 |
| 2001 | 2.4 | 1.7 |
如果DataFrame的index和column有自己的name属性,也会被显示:
frame3.index.name = 'year'; frame3.columns.name = 'state'
frame3
| state | Nevada | Ohio |
|---|---|---|
| year | ||
| 2000 | NaN | 1.5 |
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
values属性会返回二维数组:
frame3.values
array([[ nan, 1.5],[ 2.4, 1.7],[ 2.9, 3.6]])
如果column有不同的类型,dtype会适应所有的列:
frame2.values
array([[2000, 'Ohio', 1.5, nan],[2001, 'Ohio', 1.7, -1.2],[2002, 'Ohio', 3.6, nan],[2001, 'Nevada', 2.4, -1.5],[2002, 'Nevada', 2.9, -1.7],[2003, 'Nevada', 3.2, nan]], dtype=object)
3 Index Objects (索引对象)
pandas的Index Objects (索引对象)负责保存axis labels和其他一些数据(比如axis name或names)。一个数组或其他一个序列标签,只要被用来做构建series或DataFrame,就会被自动转变为index:
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
index
Index(['a', 'b', 'c'], dtype='object')
index[1:]
Index(['b', 'c'], dtype='object')
index object是不可更改的:
index[1] = 'd'
---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-67-676fdeb26a68> in <module>()
----> 1 index[1] = 'd'/Users/xu/anaconda/envs/py35/lib/python3.5/site-packages/pandas/indexes/base.py in __setitem__(self, key, value)1243 1244 def __setitem__(self, key, value):
-> 1245 raise TypeError("Index does not support mutable operations")1246 1247 def __getitem__(self, key):TypeError: Index does not support mutable operations
正因为不可修改,所以data structure中分享index object是很安全的:
labels = pd.Index(np.arange(3))
labels
Int64Index([0, 1, 2], dtype='int64')
obj2 = pd.Series([1.5, -2.5, 0], index=labels)
obj2
0 1.5
1 -2.5
2 0.0
dtype: float64
obj2.index is labels
True
index除了想数组,还能像大小一定的set:
frame3
| state | Nevada | Ohio |
|---|---|---|
| year | ||
| 2000 | NaN | 1.5 |
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
frame3.columns
Index(['Nevada', 'Ohio'], dtype='object', name='state')
'Ohio' in frame3.columns
True
2003 in frame3.columns
False
与python里的set不同,pandas的index可以有重复的labels:
dup_labels = pd.Index(['foo', 'foo', 'bar', 'bar'])
dup_labels
Index(['foo', 'foo', 'bar', 'bar'], dtype='object')
在这种重复的标签中选择的话,会选中所有相同的标签。
相关文章:

pandas教程:Introduction to pandas Data Structures pandas的数据结构
文章目录 Chapter 5 Getting Started with pandas5.1 Introduction to pandas Data Structures1 Series2 DataFrame3 Index Objects (索引对象) Chapter 5 Getting Started with pandas 这样导入pandas: import pandas as pde:\python3.7\lib\site-packages\numpy…...
MinIO 分布式文件(对象)存储
简介 MinIO是高性能、可扩展、云原生支持、操作简单、开源的分布式对象存储产品。 在中国:阿里巴巴、腾讯、百度、中国联通、华为、中国移动等等9000多家企业也都在使用MinIO产品 官网地址:http://www.minio.org.cn/ 下载 官网下载(8.4.3版本)&#x…...

HTML表单标签
## HTML标签:表单标签 * 表单: * 概念:用于采集用户输入的数据的。用于和服务器进行交互。 * form:用于定义表单的。可以定义一个范围,范围代表采集用户数据的范围 * 属性࿱…...

【黑马程序员】SpringCloud——Eureka
文章目录 前言一、提供者与消费者1. 服务调用关系 二、远程调用的问题三、eureka 原理分析1. eureka 的作用 四、Eureka 案例1. 搭建 eureka 服务1. 服务注册1.1 注册 user-service1.2 启动 user-service3. order-service 完成服务注册 3. 服务发现1. 在 order-service 完成服务…...
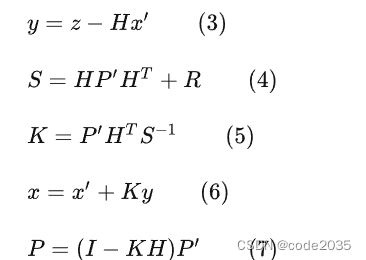
目标跟踪(DeepSORT)
本文首先将介绍在目标跟踪任务中常用的匈牙利算法(Hungarian Algorithm)和卡尔曼滤波(Kalman Filter),然后介绍经典算法DeepSORT的工作流程以及对相关源码进行解析。 目前主流的目标跟踪算法都是基于Tracking-by-Detec…...
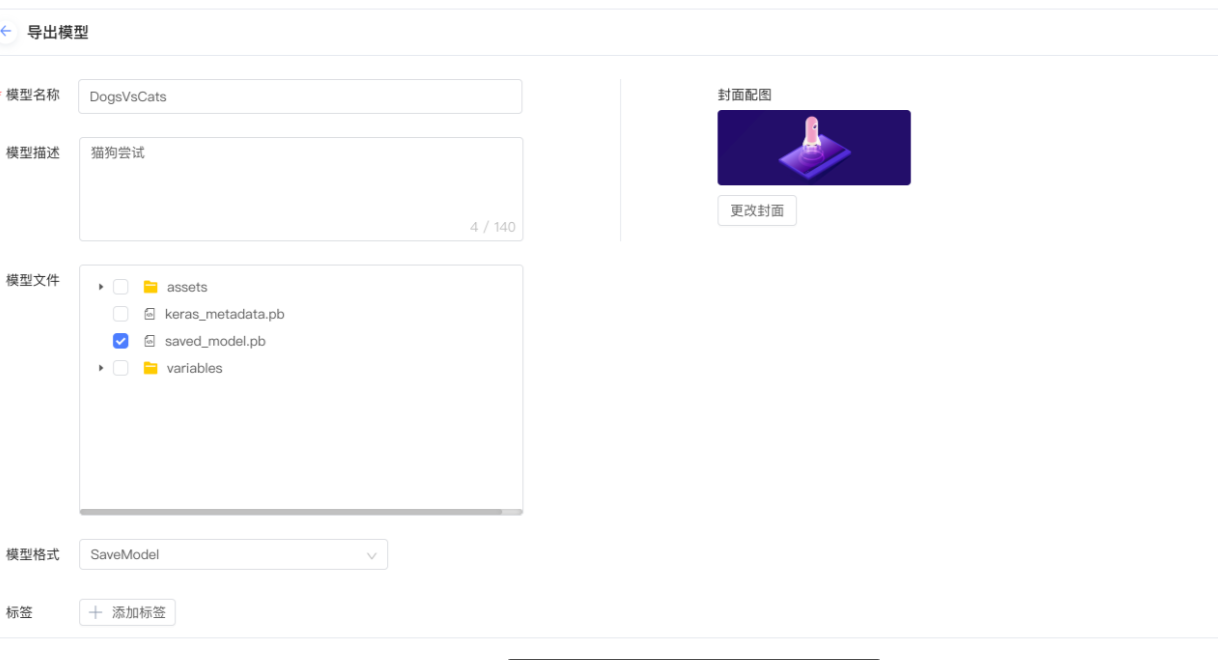
2 任务2: 使用趋动云GPU进行猫狗识别实践
使用趋动云GPU进行猫狗识别实践 1 创建项目2 初始化开发环境3 调试代码4 提交离线任务5 结果集存储与下载 使用趋动云提供的免费GPU,进行猫狗识别实践。 虽然例程里面提供的是基于tensorflow的,但是你也可以使用pytorch的代码 使用这个平台的一个优点就是…...

技术分享 | app自动化测试(Android)--显式等待机制
WebDriverWait类解析 WebDriverWait 用法代码 Python 版本 WebDriverWait( driver,timeout,poll_frequency0.5,ignored_exceptionsNone) 参数解析: driver:WebDriver 实例对象 timeout: 最长等待时间,单位秒 poll_frequency: 检测的间…...
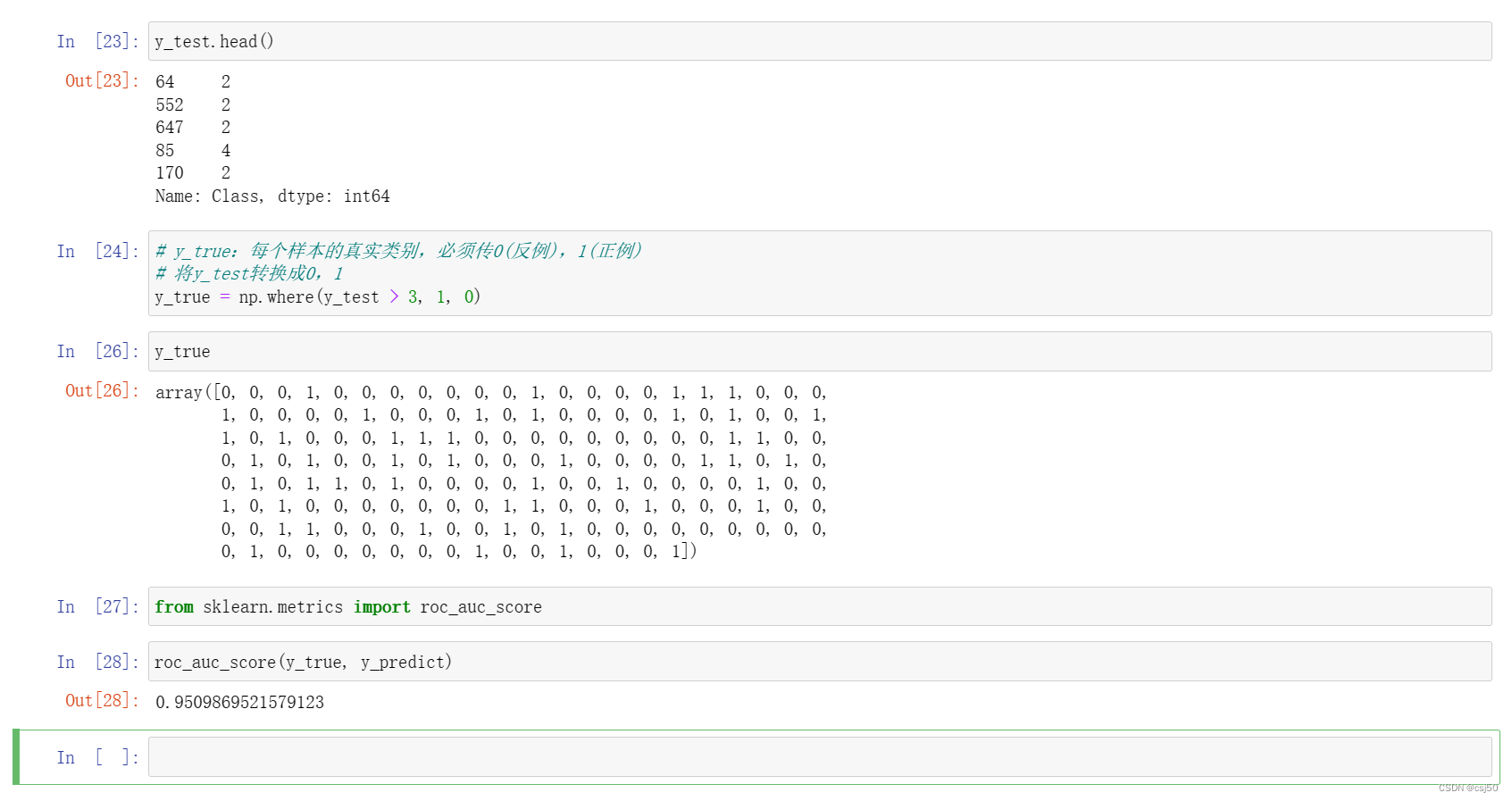
机器学习基础之《回归与聚类算法(5)—分类的评估方法》
问题:上一篇的案例,真的患癌症的,能被检查出来的概率? 一、精确率和召回率 1、混淆矩阵 在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适…...

如何在macbook上删除文件?Mac删除文件的多种方法
在使用MacBook电脑时,桌面上经常会积累大量的文件,而这些文件可能已经不再需要或已经过时。为了保持桌面的整洁和提高电脑性能,我们需要及时删除这些文件。本文将介绍MacBook怎么删除桌面文件,以及macbook删除桌面文件快捷键。 一…...

Java代码Demo——Map根据key或value排序
Map根据key排序 升序 Demo代码: //使用TreeMap Map<Integer, String> map new TreeMap<>(); map.put(10, "第10名次"); map.put(15, "第15名次"); map.put(1, "第1名次"); map.put(5, "第5名次"); map.put…...
一个Linux自动备份脚本的示例
一个简单的Linux自动备份脚本的示例,根据需要进行自定义: 请确保按照您的需求修改source_dir和backup_dir为要备份的源目录和备份目录的路径。此脚本使用tar命令创建一个以当前日期命名的压缩备份文件,并在备份完成后检查是否成功。此外&…...
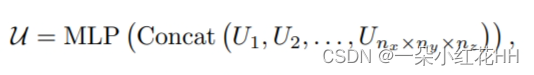
[论文阅读]PV-RCNN++
PV-RCNN PV-RCNN: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection 论文网址:PV-RCNN 论文代码:PV-RCNN 简读论文 这篇论文提出了两个用于3D物体检测的新框架PV-RCNN和PV-RCNN,主要的贡献如下: 提出P…...
测试老鸟整理,Postman加密接口测试-Rsa/Aes对参数加密(详细总结)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 一些问题 postma…...

JavaScript使用对象
对象(object)是最基本、最通用的类型,具有复合性结构,属于引用型数据,对象的结构具有弹性,内部的数据是无序的,每个成员被称为属性。在JavaScript中,对象是一个泛化的概念,任何值都可以转换为对…...
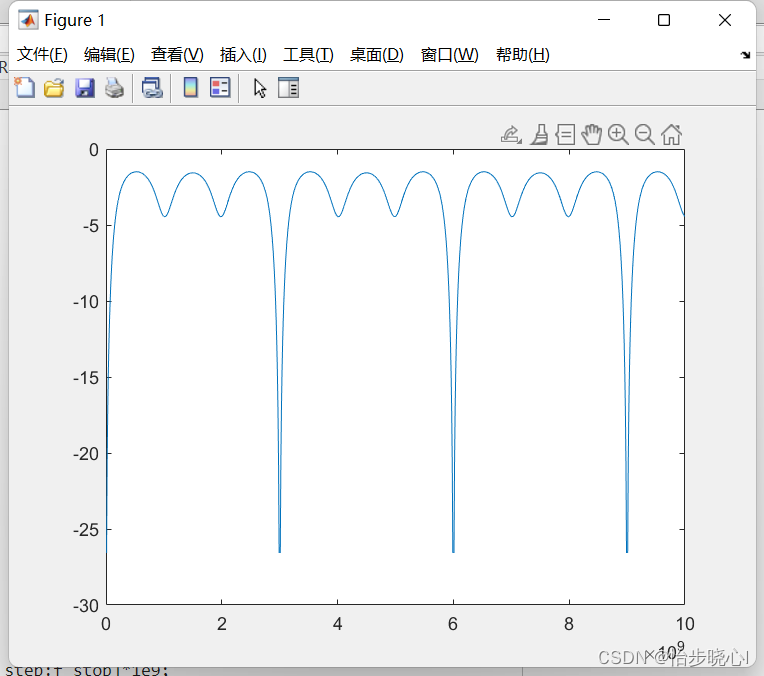
微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例
微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例 散射参数矩阵有实际的物理意义,但是其无法级联计算,但是ABCD参数和传输散射矩阵可以级联计算,在此先简单介绍ABCD参数矩阵的基本用法。 1、微带线的ABCD矩阵的推导 其他的一些常用的二端…...
“网站不安全”该如何解决
当我们的网站被客户访问的时候,经常会出现提示不安全的情况,导致客户的不信任,从而出现客户流失的现象,这种情况我们应该如何解决呢? 首先,我们要确定网站会出现不安全的原因,一般来说ÿ…...

gitlab数据备份和恢复
gitlab数据备份 sudo gitlab-rake gitlab:backup:create备份文件默认存放在/var/opt/gitlab/backups路径下, 生成1697101003_2023_10_12_12.0.3-ee_gitlab_backup.tar 文件 gitlab数据恢复 sudo gitlab-rake gitlab:backup:restore BACKUP1697101003_2023_10_12_…...
嵌入式Linux和stm32区别? 之间有什么关系吗?
嵌入式Linux和stm32区别? 之间有什么关系吗? 主要体现在以下几个方面: 1.硬件资源不同 单片机一般是芯片内部集成flash、ram,ARM一般是CPU,配合外部的flash、ram、sd卡存储器使用。最近很多小伙伴找我,说想要一些嵌…...

【Redis】String字符串类型-内部编码使用场景
文章目录 内部编码使用场景缓存功能计数功能共享会话手机验证码 内部编码 字符串类型的内部编码有3种: int:8个字节(64位)的⻓整型,存储整数embstr:压缩字符串,适用于表示较短的字符串raw&…...

电脑发热发烫,具体硬件温度达到多少度才算异常?
环境: 联想E14 问题描述: 电脑发热发烫,具体硬件温度达到多少度才算异常? 解决方案: 电脑硬件的温度正常范围会因设备类型和使用的具体硬件而有所不同。一般来说,以下是各种硬件的正常温度范围: CPU:正…...

国产SeekWave 双频WIFI6+BT5.4 VS6621SR80基于RK3588平台成功替换RTL8822模组 硬件兼容 速率可达600Mbps
RK3588是瑞芯微(Rockchip)推出的旗舰级SoC芯片,采用8nm工艺,集成四核Cortex-A76和四核Cortex-A55 CPU、ARM Mali-G610 MP4 GPU、6 TOPS NPU,支持8K视频编解码。12CPU:八核ARM架构ÿ…...

拆解中金2025财报:飞轮效应,如何驱动高质量增长?
2025年的中国资本市场,有三条主线在交汇:创新驱动、资本市场深化改革、个人养老金全面推开。它们分别指向一家投行必须具备的三种能力——资产端的挖掘、交易端的兑现、资金端的配置。 与此同时,证券行业正在经历一场无声的洗牌。牌照红利在…...

考虑浆液黏度时变性与重力效应的注浆压力作用下隧道围岩变形的流固耦合动态分析模型 基于6.1版本...
考虑浆液黏度时变性与重力效应的注浆压力作用下隧道围岩变形的流固耦合动态分析模型 基于6.1版本 可视化结果:位移大小(时间、应力不同而不同)、应力分布、 打开COMSOL 6.1新建模型时,突然发现隧道注浆模拟要考虑浆液黏度的时间变…...

免死金牌: OpenClaw + keepalived
文章目录背景解决方案查看IP检测脚本keepalived 配置演练故障openclaw-gateway.service背景 问题来自 小龙虾自杀, 当我让 OpenClaw 更新一些配置时, 它执行了一条 openclaw gateway stop 命令, 导致 OpenClaw 服务停止, 然后我就干瞪眼了, 还在傻等, 它甚至一句分别的话都没有…...

电商 SEO 优化与社交媒体营销的关系是什么_电商 SEO 优化效果如何评估
电商 SEO 优化与社交媒体营销的关系 在当今互联网时代,电子商务(电商)已成为全球经济的重要组成部分。电商 SEO 优化和社交媒体营销是两种互补的推广手段,它们之间的关系不仅丰富了电商平台的推广策略,也为企业带来了…...

Comsol模拟土壤中冰的融化过程:奇妙的微观世界之旅
comsol模拟土壤中冰的融化过程模型 在天气升温过程中,土壤表层的冰融化,深入土壤中,同时随着水流的渗入,土壤中的冰夹杂物融化,采用达西定律与包含相变的“多孔介质传热”接口相耦合,可以模拟土壤中冰夹杂物…...

「码动四季·开源同行」go实战案例:如何保证微服务实例资源安全?
今天我和你分享的是如何保证微服务实例资源安全的案例。在前文,我们实践了如何使用Go搭建一个基本的授权服务器,它的主要功能是颁发访问令牌和验证访问令牌的有效性。在统一认证与授权服务体系中,还存在资源服务器对用户数据进行保护…...

Linux source命令详解与应用场景解析
说得好!这是一个非常核心且常见的Linux/Unix命令。简单直接的回答是:不,source 命令远不止是加载环境变量,虽然这是它最常用的场景之一。它的核心功能是:在当前Shell环境中读取并执行指定文件中的命令。让我们来深入分…...

AI 短剧变现的 4 大合规赛道 新手低门槛可切入
当下AI短剧成为内容领域的热门风口,不少人想入局分一杯羹,却因担心踩坑违规、找不准变现方向而犹豫不决。其实新手入局无需焦虑,只要选对合规赛道,低门槛也能轻松切入。本文将详细拆解4个核心变现路径,全程贴合平台审核…...
)
帕拉丁调试指南之SDL 语言编写指南(快速参考)
1. SDL 文件基本结构SDL 程序由三个主要部分组成:text// 1. 全局定义段(可选) scope ...; define ...; enum ...; tdef ...; trigger ...; if (...) trigger; ...// 2. 实例定义段(至少一个实例,可多个) i…...