面试题:线上MySQL的自增id用尽怎么办?
文章目录
- 前言
- 表定义自增值id
- InnoDB系统自增row_id
- Xid
- Innodb trx_id
- InnoDB数据可见性的核心思想
- 为什么要加248?
- 为何只读事务不分配trx_id?
- thread_id
- 总结
前言
MySQL的自增id都定义了初始值,然后不断加步长。虽然自然数没有上限,但定义了表示这个数的字节长度,计算机存储就有上限。比如,无符号整型(unsigned int)是4个字节,上限就是2^32 - 1。那自增id用完,会怎么样?
表定义自增值id
表定义的自增值达到上限后的逻辑是:再申请下一个id时,得到的值保持不变。
mysql> create table t(id int unsigned auto_increment primary key) auto_increment=4294967295;
Query OK, 0 rows affected (0.01 sec)mysql> insert into t values(null);
Query OK, 1 row affected (0.00 sec)mysql> show create table t;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t | CREATE TABLE `t` (`id` int unsigned NOT NULL AUTO_INCREMENT,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4294967295 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)//成功插入一行 4294967295
mysql> insert into t values(null);
ERROR 1062 (23000): Duplicate entry '4294967295' for key 't.PRIMARY'
第一个insert成功后,该表的AUTO_INCREMENT还是4294967295,导致第二个insert又拿到相同自增id值,再试图执行插入语句,主键冲突。
2^32 - 1(4294967295)不是一个特别大的数,一个频繁插入删除数据的表是可能用完的。建表时就需要考虑你的表是否有可能达到该上限,若有,就应创建成8字节的bigint unsigned。
InnoDB系统自增row_id
若你创建的InnoDB表未指定主键,则InnoDB会自动创建一个不可见的,6个字节的row_id。InnoDB维护了一个全局的dict_sys->row_id值
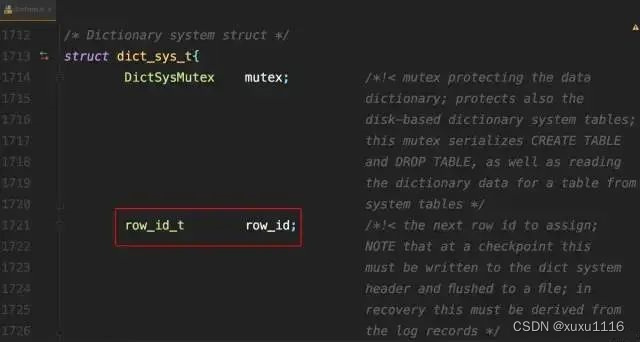
所有无主键的InnoDB表,每插入一行数据,都将当前的dict_sys->row_id作为要插入数据的row_id,然后把dict_sys->row_id加1。
代码实现时row_id是个长度为8字节的无符号长整型(bigint unsigned)。但InnoDB在设计时,给row_id留的只是6个字节的长度,这样写到数据表中时只放了最后6个字节,所以row_id能写到数据表中的值,就有两个特征:
-
row_id写入表中的值范围,是从0到2^48 - 1
-
当dict_sys.row_id=2^48时,如果再有插入数据的行为要来申请row_id,拿到以后再取最后6个字节的话就是0
即写入表的row_id从0~2^48 - 1。达到上限后,下个值就是0,然后继续循环。
2^48 - 1已经很大,但若一个MySQL实例活得久,还是可能达到上限。
InnoDB里,申请到row_id=N后,就将这行数据写入表中;若表中已经存在row_id=N的行,新写入的行就会覆盖原有的行。
验证该结论:通过gdb修改系统的自增row_id。用gdb是为了便于复现问题,只能在测试环境使用。
-
row_id用完的验证序列

-
row_id用完的效果验证
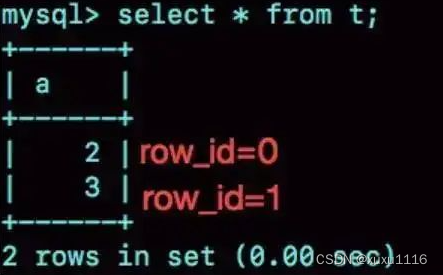
可见,在我用gdb将dict_sys.row_id设置为2^48之后,再插入a=2会出现在表t的第一行,因为该值的row_id=0。
之后再插入a=3,由于row_id=1,就覆盖了之前a=1的行,因为a=1这一行的row_id也是1。
所以应该在InnoDB表中主动创建自增主键:当表自增id到达上限后,再插入数据时会报主键冲突错误。
毕竟覆盖数据,就意味着数据丢失,影响数据可靠性;报主键冲突,插入失败,影响可用性。一般可靠性优于可用性。
Xid
redo log和binlog有个共同字段Xid,用来对应事务。Xid在MySQL内部是如何生成的呢?
MySQL内部维护了一个全局变量global_query_id
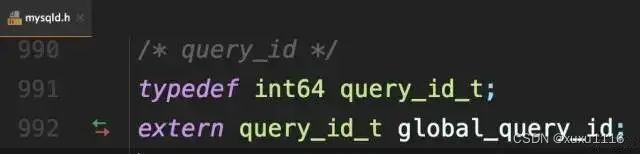
每次执行语句时,将它赋值给query_id,然后给该变量+1:
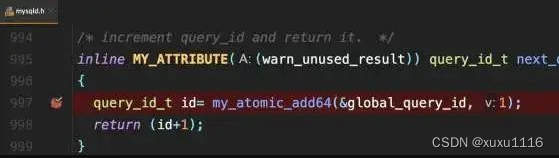
若当前语句是该事务执行的第一条语句,则MySQL还会同时把query_id赋值给该事务的Xid:
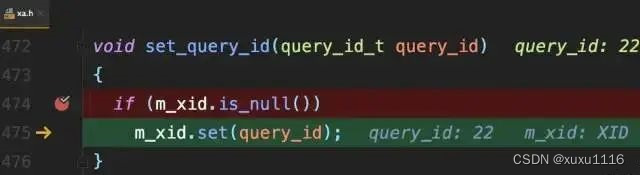
而global_query_id是一个纯内存变量,重启之后就清零了。所以同一DB实例,不同事务的Xid可能相同。
但MySQL重启之后会重新生成新binlog文件,这就保证同一个binlog文件里的Xid唯一。
虽然MySQL重启不会导致同一个binlog里面出现两个相同Xid,但若global_query_id达到上限,就会继续从0开始计数。理论上还是会出现同一个binlog里面出现相同Xid。
因为global_query_id8字节,上限2^64 - 1。要出现这种情况,需满足:
- 执行一个事务,假设Xid是A
- 接下来执行2^64次查询语句,让global_query_id回到A
2^64太大了,这种可能只存在于理论中。 - 再启动一个事务,这个事务的Xid也是A
Innodb trx_id
Xid由server层维护
InnoDB内部使用Xid,为了关联InnoDB事务和server
但InnoDB自己的trx_id,是另外维护的事务id(transaction id)。
InnoDB内部维护了一个max_trx_id全局变量,每次需要申请一个新的trx_id时,就获得max_trx_id的当前值,然后并将max_trx_id加1。
InnoDB数据可见性的核心思想
每一行数据都记录了更新它的trx_id,当一个事务读到一行数据时,判断该数据是否可见,就是通过事务的一致性视图与这行数据的trx_id做对比。
对于正在执行的事务,你可以从information_schema.innodb_trx表中看到事务的trx_id。
看如下案例:事务的trx_id

S2 的执行记录:
mysql> use information_schema;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changedmysql> select trx_id, trx_mysql_thread_id from innodb_trx;
+-----------------+---------------------+
| trx_id | trx_mysql_thread_id |
+-----------------+---------------------+
| 421972504382792 | 70 |
+-----------------+---------------------+
1 row in set (0.00 sec)mysql> select trx_id, trx_mysql_thread_id from innodb_trx;
+---------+---------------------+
| trx_id | trx_mysql_thread_id |
+---------+---------------------+
| 1355623 | 70 |
+---------+---------------------+
1 row in set (0.01 sec)
S2从innodb_trx表里查出的这两个字段,第二个字段trx_mysql_thread_id就是线程id。显示线程id,是为说明这两次查询看到的事务对应的线程id都是5,即S1所在线程。
t2时显示的trx_id是一个很大的数;t4时刻显示的trx_id是1289,看上去是一个比较正常的数字。这是为啥?
t1时,S1还未涉及更新,是一个只读事务。对于只读事务,InnoDB并不会分配trx_id:
- t1时,trx_id的值就是0。而这个很大的数,只是显示用
- 直到S1在t3时执行insert,InnoDB才真正分配trx_id。所以t4时,S2查到该trx_id的值就是1289。
除了明显的修改类语句,若在select 语句后面加上for update,也不是只读事务。
- update 和 delete语句除了事务本身,还涉及到标记删除旧数据,即要把数据放到purge队列里等待后续物理删除,这个操作也会把max_trx_id+1,
因此在一个事务中至少加2 - InnoDB的后台操作,比如表的索引信息统计这类操作,也是会启动内部事务的,因此你可能看到,trx_id值并不是按照加1递增的。
t2时查到的很大数字是怎么来的?
每次查询时,由系统临时计算:
当前事务的trx变量的指针地址转成整数,再加上248
这样可以保证:
- 因为同一只读事务在执行期间,它的指针地址不会变,所以无论在
innodb_trx还是在innodb_locks表里,同一个只读事务查出来的trx_id就会是一样的 - 若有并行只读事务,每个事务的trx变量的指针地址肯定不同。这样,不同并发只读事务,查出来的trx_id就是不同的。
为什么要加248?
保证只读事务显示的trx_id值比较大,正常情况下就会区别于读写事务的id。但trx_id跟row_id的逻辑类似,定义为8个字节。
理论上还是可能出现一个读写事务与一个只读事务显示的trx_id相同。不过概率很低,也没有什么实质危害,不管。
为何只读事务不分配trx_id?
- 减小事务视图里面活跃事务数组的大小。因为当前正在运行的只读事务,不影响数据的可见性判断。所以,在创建事务的一致性视图时,InnoDB就只需要拷贝读写事务的trx_id
- 减少trx_id的申请次数。InnoDB执行一个普通的select语句,也要对应一个只读事务。所以只读事务优化后,普通查询语句无需申请trx_id,大大减少并发事务申请trx_id的锁冲突
由于只读事务不分配trx_id,显然trx_id的增速变慢。
但 max_trx_id 会持久化存储,重启也不会重置为0。理论上,只要一个MySQL实例跑得够久,就可能出现max_trx_id达到2^48 - 1,然后从0开始循环。
达到该状态后,MySQL就会持续出现一个脏读bug:
首先把当前的max_trx_id先修改成2^48 - 1。这里是可重复读。
- 复现脏读


- 因为系统的max_trx_id被设置成2^48 - 1,所以在session A启动的事务TA的低水位就是2^48 - 1。
t2时:
- session B执行第一条update语句的事务id=2^48 - 1
- 第二条事务id就是0了,这条update执行后生成的数据版本上的trx_id=0
t3时:
session A执行select的可见性判断:c=3这个数据版本的trx_id(0),小于事务TA的低水位(2^48 - 1),所以认为该数据可见。
但这是脏读。
由于低水位值会持续增加,而事务id从0开始计数,导致系统在该时刻后,所有查询都会出现脏读。
并且MySQL重启时max_trx_id也不会清0,即重启MySQL,这个bug仍然存在。那这bug也是只存在于理论上吗?
假设一个MySQL实例的TPS是50w,持续这样,17.8年后就会出现该情况。但从MySQL真正开始流行到现在,恐怕都还没有实例跑到过这个上限。不过,只要MySQL实例服务时间够长,就必然会出现该bug。
这也可以加深对低水位和数据可见性的理解
thread_id
系统保存了一个全局变量thread_id_counter
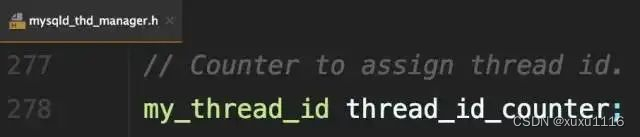
每新建一个连接,就将thread_id_counter赋值给这个新连接的线程变量new_id。
thread_id_counter定义为4个字节,因此达到2^32 - 1,就会重置为0,继续增加。

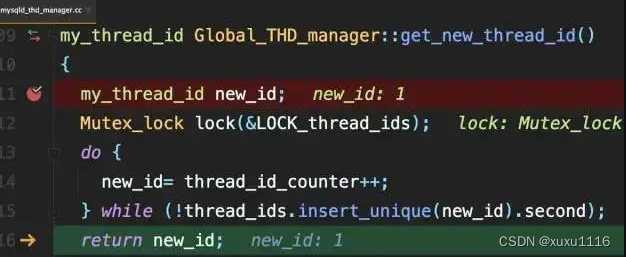
但不会在show processlist看到两个相同的thread_id。因为MySQL使用了一个唯一数组

给新线程分配thread_id时的逻辑:
总结
每种自增id有各自的应用场景,在达到上限后的表现也不同:
表的自增id达到上限后,再申请时它的值就不会改变,进而导致继续插入数据时报主键冲突错误
row_id达到上限后,则会归0再重新递增,如果出现相同的row_id,后写的数据会覆盖之前的数据
Xid只需要不在同一个binlog文件中出现重复值即可。虽然理论上会出现重复值,但是概率极小,可以忽略不计
InnoDB的max_trx_id 递增值每次MySQL重启都会被保存起来,所以我们文章中提到的脏读的例子就是一个必现的bug,好在留给我们的时间还很充裕。
相关文章:
面试题:线上MySQL的自增id用尽怎么办?
文章目录 前言表定义自增值idInnoDB系统自增row_idXidInnodb trx_id InnoDB数据可见性的核心思想为什么要加248?为何只读事务不分配trx_id?thread_id 总结 前言 MySQL的自增id都定义了初始值,然后不断加步长。虽然自然数没有上限,…...

Java集合框架:Collection 与 Map 接口深度解析
Java的集合框架提供了丰富的工具和数据结构,其中 Collection 和 Map 接口是这个框架的核心。这两个接口分别用于处理一组对象和键值对的映射关系,是Java编程中不可或缺的部分。让我们深入挖掘这两个接口的特性以及它们的实际应用场景。 1. Collection 接…...

qt多线程例子,不断输出数字
dialog.h #include "dialog.h" #include "ui_dialog.h"Dialog::Dialog(QWidget *parent) :QDialog(parent),ui(new Ui::Dialog) {ui->setupUi(this); }Dialog::~Dialog() {delete ui; }// 启动线程按钮 void Dialog::on_startButton_clicked() {//conn…...
基于厨师算法的无人机航迹规划-附代码
基于厨师算法的无人机航迹规划 文章目录 基于厨师算法的无人机航迹规划1.厨师搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用厨师算法来优化无人机航迹规划。 1.厨师搜索算法 …...

设计模式的六大原则
1、开闭原则(Open Close Principle) 开闭原则的意思是:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代 码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好&…...

原文远知行COO张力加盟逐际动力 自动驾驶进入视觉时代?
11月7日,通用足式机器人公司逐际动力LimX Dynamics官宣了两位核心成员的加入。原文远知行COO张力出任逐际动力联合创始人兼COO,香港大学长聘副教授潘佳博士为逐际动力首席科学家。 根据介绍,两位核心成员的加入,证明一家以技术驱…...

【公益案例展】火山引擎公益电子票据服务——连接善意,共创美好
火山引擎公益案例 本项目案例由火山引擎投递并参与数据猿与上海大数据联盟联合推出的 #榜样的力量# 《2023中国数据智能产业最具社会责任感企业》榜单/奖项”评选。 大数据产业创新服务媒体 ——聚焦数据 改变商业 捐赠票据是慈善组织接受捐赠后给捐赠方开具的重要凭证&…...
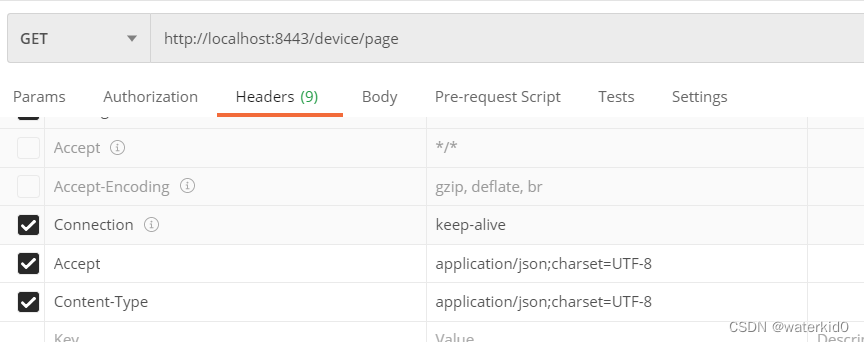
postman中文乱码
在header中添加这两个: Content-Type application/json;charsetUTF-8 Accept application/json;charsetUTF-8...

设计模式简要介绍
设计模式有很多,较为重要的如下 静态和单例模式 单例模式的本质就是类成员中有一个对象实例 public class Animal{public static string Title "Animal" // 类成员public string Name; // 对象成员public const float Pi 3.14f; // 类成员public rea…...
)
LeetCode-232. 用栈实现队列(C++)
目录捏 一、题目描述二、示例与提示三、思路四、代码 一、题目描述 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的…...

无人机红外相机的畸变矫正
在项目开展过程中,发现大疆M30T的红外相机存在比较明显的畸变问题,因此需要对红外图像进行畸变矫正。在资料检索过程中,发现对红外无人机影像矫正的资料较少,对此,我从相机的成像原理角度出发,探索出一种效…...
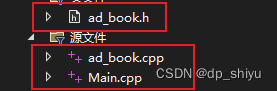
C++编程案例讲解-基于结构体的控制台通讯录管理系统
基于结构体的控制台通讯录管理系统 通讯录是一个可以记录亲人、好友信息的工具,系统中需要实现的功能如下: 添加联系人:向通讯录中添加新人,信息包括(姓名、性别、年龄、联系电话、家庭住址)最多记录1000人…...
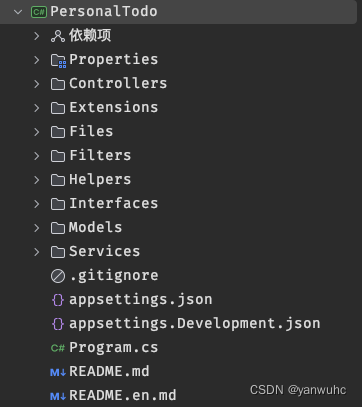
ASP.NETCore6开启文件服务允许通过url访问附件(图片)
需求背景 最近在做一个工作台的文件上传下载功能,主要想实现上传图片之后,可以通过url直接访问。由于url直接访问文件不安全,所以需要手动开启文件服务。 配置 文件路径如下,其中Files是存放文件的目录: 那么&…...

python爬取Web of science论文信息
一、python爬取WOS总体思路 (一)拟实现功能描述 wos里面,爬取论文的名称,作者名称,作者单位,引用数量 要求:英文论文、期刊无论好坏 检索关键词:zhejiang academy of agricultural sciences、 xianghu lab…...
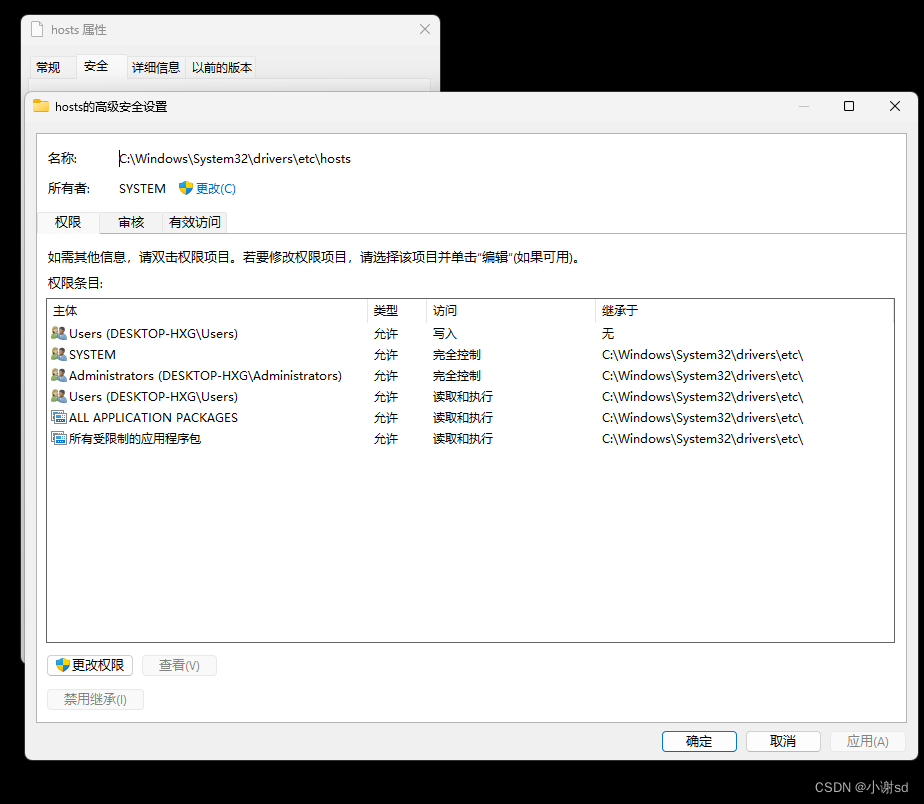
本地域名 127.0.0.1 / localhost
所谓本地域名就是 只能在本机使用的域名 ,一般在开发阶段使用。 编辑文件 C:\Windows\System32\drivers\etc\hosts。 127.0.0.1 www.baidu.com如果修改失败,可以修改该文件的权限。 原理: 在地址栏输入 域名 之后,浏览器会先进行 DNS…...

Python —— 不同类型的数据长度计算方式
在Python 中,不同类型的数据长度计算方式,有何不同👇 字符串(String) my_string "Hello, World!" string_length len(my_string) print("字符串的长度是:", string_length) //输出…...

NowCoder | 环形链表的约瑟夫问题
NowCoder | 环形链表的约瑟夫问题 OJ链接 思路: 创建带环链表带环链表的删除节点 代码如下: #include<stdlib.h>typedef struct ListNode ListNode; ListNode* ListBuyNode(int x) {ListNode* node (ListNode*)malloc(sizeof(ListNode));node…...

华为政企数据中心网络交换机产品集
产品类型产品型号产品说明 核心/汇聚交换机CE8850-EI-B-B0BCloudEngine 8850-64CQ-EI 提供 64 x 100 GE QSFP28,CloudEngine 8800系列交换机是面向数据中心推出的新一代高性能、高密度、低时延灵活插卡以太网交换机,可以与华为CloudEngine系列数据中心…...
多门店自助点餐+外卖二合一小程序源码系统 带完整搭建教程
随着餐饮业的快速发展和互联网技术的不断进步,越来越多的餐厅开始采用自助点餐和外卖服务。市场上许多的外卖小程序APP应运而生。下面罗峰来给大家介绍一款多门店自助点餐外卖二合一小程序源码系统。该系统结合了自助点餐和外卖服务的优势,为餐厅提供了一…...
kafka可视化工具
Offset Explorer kafka可视化工具...

利用Graphormer进行化学反应预测:从反应物到产物的智能推断
利用Graphormer进行化学反应预测:从反应物到产物的智能推断 1. 化学反应预测的挑战与机遇 有机化学合成是药物研发和材料科学的核心环节,但传统反应预测高度依赖化学家的经验。一个资深化学家可能需要花费数小时甚至数天时间,通过试错法来设…...

圣邦微电子冲刺港股:年营收39亿,净利5.3亿 派息1亿 已获IPO备案
雷递网 雷建平 4月2日圣邦微电子(北京)股份有限公司(简称:“圣邦微电子”)日前更新招股书,准备在港交所上市。圣邦微电子已在A股上市,截至今日收盘,圣邦微电子股价为67.45元…...

4个简单步骤:如何用OpenCore Legacy Patcher让老旧Mac焕发新生
4个简单步骤:如何用OpenCore Legacy Patcher让老旧Mac焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一个开源…...

如何快速掌握LeaguePrank:英雄联盟客户端个性化修改完整指南
如何快速掌握LeaguePrank:英雄联盟客户端个性化修改完整指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟客户端中展示独特的个人风格吗?LeaguePrank是一个基于LCU API的英雄联盟客户…...
的)
实战分享:我是如何搞定SHEIN新版反爬(anti-in, smdeviceid, armortoken, x-gw-auth)的
电商平台数据采集实战:逆向工程与参数生成策略 最近半年,电商平台的反爬机制呈现出明显的升级趋势。以某国际快时尚电商为例,其新增的四个核心校验参数(anti-in、smdeviceid、armortoken、x-gw-auth)构成了完整的安全验…...

obs-multi-rtmp技术突破:多平台直播资源效率提升的5大实践方法
obs-multi-rtmp技术突破:多平台直播资源效率提升的5大实践方法 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp obs-multi-rtmp作为一款开源的OBS Studio插件,通过…...

文脉定序保姆级教程:3步完成BGE-Reranker-v2-m3镜像免配置部署
文脉定序保姆级教程:3步完成BGE-Reranker-v2-m3镜像免配置部署 你是否遇到过这样的烦恼?用自己搭建的知识库或者搜索引擎提问,系统确实返回了一大堆结果,但最相关、最准确的答案却淹没在列表的中间甚至末尾。传统的检索方法&…...

用LingBot-Depth解决实际问题:如何修复不完整的深度传感器数据?
用LingBot-Depth解决实际问题:如何修复不完整的深度传感器数据? 1. 深度传感器数据修复的挑战 深度传感器在机器人导航、三维重建和增强现实等领域发挥着关键作用,但原始传感器数据往往存在各种问题: 数据缺失:由于…...

use-context-selector 与 Suspense 集成:实现数据加载的优雅处理
use-context-selector 与 Suspense 集成:实现数据加载的优雅处理 【免费下载链接】use-context-selector React useContextSelector hook in userland 项目地址: https://gitcode.com/gh_mirrors/us/use-context-selector 在 React 18 的并发渲染时代&#x…...

Linux下用tar.gz压缩含软连接的目录,为什么比zip更靠谱?
Linux下处理含软连接目录:为什么tar.gz比zip更可靠? 在Linux系统管理中,文件打包和压缩是日常操作中不可或缺的一部分。当目录结构中含有软连接(symbolic link)时,选择合适的压缩格式就显得尤为重要。许多管…...