CUDA学习笔记7——CUDA内存组织
CUDA内存组织
CUDA设备内存的分类与特征
| 内存类型 | 物理位置 | 访问权限 | 可见范围 | 生命周期 | |
|---|---|---|---|---|---|
| 1 | 全局内存 | 芯片外 | 可读写 | 所有线程和主机端 | 由主机分配与释放 |
| 2 | 常量内存 | 芯片外 | 只读 | 所有线程和主机端 | 由主机分配与释放 |
| 3 | 纹理和表面内存 | 芯片外 | 一般只读 | 所有线程和主机端 | 由主机分配与释放 |
| 4 | 寄存器内存 | 芯片内 | 可读写 | 单个线程 | 所在线程 |
| 5 | 局部内存 | 芯片外 | 可读性 | 单个线程 | 所在线程 |
| 6 | 共享内存 | 芯片内 | 可读性 | 单个线程块 | 所在线程块 |
-
全局内存:核函数中所有线程都能访问其中的数据。
用cudaMalloc()为全局内存变量分配设备内存;
用cudaMemcpy()将主机数据复制到全局内存; -
常量内存:一共64KB,只读,可见范围与生命周期与全局内存一样,访问速度比全局内存快;在核函数未满用 _constant_ 定义变量;并使用cudaMemcpyToSymbol()将数据从主机端复制到设备的常量内存。
-
纹理内存与表面内存:类似于常量内存(可见范围与生命周期相同);
-
寄存器:在核函数中定义的不加任何限定符的变量一般来说放在寄存器中,核函数定义不加任何限定符的数组可能放于寄存器,也可能放于局部内存中;
-
局部内存:寄存器放不下的变量,索引值不能在编译时确定的数组;
-
共享内存:与寄存器类似,存在于芯片上,仅次于寄存器的读写速度;
CUDA中的内存组织示意图

GPU设备规格查询
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"int main()
{int device_id = 0;cudaDeviceProp prop;cudaGetDeviceProperties(&prop, device_id);printf("Device id: %d\n", device_id);printf("Device name: %s\n", prop.name);printf("Compute capability: %d.%d\n", prop.major, prop.minor);printf("Amount of global memory: %g GB\n", prop.totalGlobalMem / 1024.0);printf("Amount of constant memory: %g KB\n", prop.totalConstMem / 1024.0);printf("Maximum grid size: %d %d %d\n",prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);printf("Maximum block size: %d %d %d\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);printf("Number of SMs: %d\n", prop.multiProcessorCount);printf("----------------------------- \n");printf("Maximum amount of shared memory per block: %g KB\n", prop.sharedMemPerBlock / 1024.0);printf("Maximum amount of shared memory per SM: %g KB\n",prop.sharedMemPerMultiprocessor / 1024.0);printf("Maximum number of registers per block: %d K\n", prop.regsPerBlock / 1024.0);printf("Maximum number of registers per SM: %d K\n", prop.regsPerMultiprocessor / 1024.0);printf("Maximum number of threads per block: %d \n", prop.maxThreadsPerBlock);printf("Maximum number of threads per SM: %d \n", prop.maxThreadsPerMultiProcessor);return 0;
}
全局内存的合并与非合并访问
合并访问:一个线程束对全局内存的一次访问(读/写)导致最少数量的数据传输;否则为非合并访问。
利用共享内存和统一内存优化矩阵乘

#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<math.h>
#include <malloc.h>
#include <opencv2/opencv.hpp>
#include <stdlib.h>//利用share memory 和统一内存优化矩阵乘#define M 1000
#define N 500
#define K 1000__managed__ int a[M*N];
__managed__ int b[N*K];
__managed__ int c_gpu[M*K];
__managed__ int c_cpu[M*N];#define BLOCK_SIZE 16__global__ void gpu_matrix(int* a, int* b, int* c, int m, int n, int k)
{__shared__ int sub_a[BLOCK_SIZE][BLOCK_SIZE];__shared__ int sub_b[BLOCK_SIZE][BLOCK_SIZE];int x = blockIdx.x*blockDim.x + threadIdx.x;int y = blockIdx.y*blockDim.y + threadIdx.y;int tmp = 0;int idx;for (int step = 0; step < N/BLOCK_SIZE; step++){int step_x = step*BLOCK_SIZE + threadIdx.x;int step_y = y;idx = step_y*n + step_x;if (step_x>n || step_y>m){sub_a[threadIdx.y][threadIdx.x] = 0;}else{sub_a[threadIdx.x][threadIdx.x] = a[idx];}step_x = x;step_y = step*BLOCK_SIZE + threadIdx.y;idx = step * k + step_x;if (step_x >= k || step_y>=n){sub_b[threadIdx.y][threadIdx.x] = 0;}else{sub_b[threadIdx.y][threadIdx.x] = b[idx];}__syncthreads();for (int i = 0; i < BLOCK_SIZE; i++){tmp += sub_a[threadIdx.y][i] * sub_b[i][threadIdx.x];}__syncthreads();}if (x<k && y<m){c[y*k + x] = tmp;}}void cpu_matrix(int* a, int* b, int* c, int m, int n, int k)
{for (int y = 0; y < m; y++){for (int x = 0; x < k; x++){int tmp = 0;for (int step = 0; step < n; step++){tmp += a[y*n + step] * b[step*n + x];}c[y*k + x] = tmp;}}}int main()
{for (int y = 0; y < M; y++){for (int x = 0; x < N; x++){a[y * N + x] = rand() % 1024;}}for (int y = 0; y < N; y++){for (int x = 0; x < K; x++){b[y*K + x] = rand() % 1024;}}unsigned int grid_x = (K + BLOCK_SIZE - 1) / BLOCK_SIZE;unsigned int grid_y = (M + BLOCK_SIZE - 1) / BLOCK_SIZE;dim3 dimGrid(grid_x, grid_y);dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);gpu_matrix<<<dimGrid, dimBlock>>>(a, b, c_gpu, M, N, K);cpu_matrix(a, b, c_cpu, M, N, K);bool errors = false;for (int y = 0; y < M; y++){for (int x = 0; x < K; x++){if (fabs(c_cpu[y*K + x] - c_gpu[y*K + x]) > (1.0e-10)){errors = true;}}}printf("Result: %s\n", errors ? "Error" : "Pass");return 0;
}相关文章:
CUDA学习笔记7——CUDA内存组织
CUDA内存组织 CUDA设备内存的分类与特征 内存类型物理位置访问权限可见范围生命周期1全局内存芯片外可读写所有线程和主机端由主机分配与释放2常量内存芯片外只读所有线程和主机端由主机分配与释放3纹理和表面内存芯片外一般只读所有线程和主机端由主机分配与释放4寄存器内存…...

C#把自启动程序添加到注册表中
1.Regedit自启动注册表路径 计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run 2.获取运行程序路径 SetAutoStart(AppDomain.CurrentDomain.FriendlyName, AppDomain.CurrentDomain.BaseDirectory); 3.添加到注册表中,如果注册表已经存…...

Java面试题(每天10题)-------连载(26)
目录 多线程篇 1、什么是FutureTask? 2、什么是同步容器和并发容器的实现? 3、什么是多线程的上下文切换? 4、ThreadLocal的设计理念与作用? 5、ThreadPool(线程池)用法与优势? 6、Concur…...
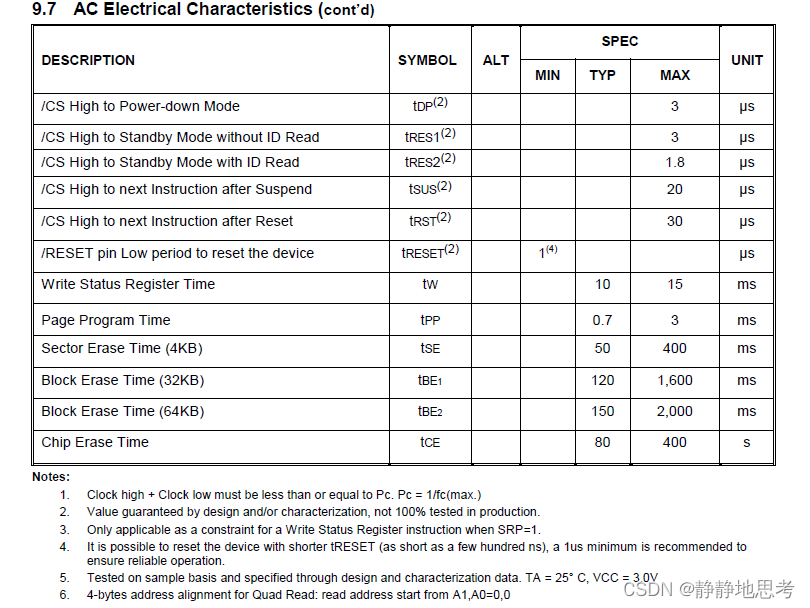
通用型 SPI-Flash 相关知识汇总(w25q16\q64,gd25q128\q256)
目录 管脚定义: 常用指令: GD25q16: gd25Q28 编辑 gw25q16 编辑 芯片丝印说明: GD系列: winbond系列: Read Identification(9FH): 常见ID: GD: 编辑…...

鸿蒙原生应用开发-DevEco Studio超级终端模拟器的使用
一、了解超级终端模拟器支持的设备情况 该特性在DevEco Studio V2.1 Release及更高版本中支持。 目前超级终端模拟器支持“PhonePhone”、“PhoneTablet”和“PhoneTV”的设备组网方式,开发者可以使用该超级终端模拟器来调测具备跨设备特性的应用/服务,如…...

抖音AAN服务商有几家?
大家都知道抖音服务商多如牛毛,有本地生活服务商,MCN机构服务商,企业认证服务商,ISV服务商等等。但是aan服务商就屈指可数。 aan技术服务商 从关系层面讲,aan服务商的关系友好到啥程度呢,就好比微信指定了…...
10-26 maven配置
打开idea 打开setting 基于Idea创建idea项目 加载jar包:(一般需要自己去手动加入,本地仓库是没有的)...
贰[2],OpenCV函数解析
1,imread:图片读取 CV_EXPORTS_W Mat imread( const String& filename, int flags IMREAD_COLOR );//参数1(filename):文件地址 //参数2(flags):读取标志 注:ImreadModes,参数2(flags)枚举定义 enum ImreadModes { IMREAD…...

探秘Python闭包与作用域
文章目录 闭包的定义与作用LEGB规则nonlocal与global关键字在Python的世界里,理解闭包(Closure)和作用域(Scope)是提升编程技巧和深度的一大步。这篇文章将带你深入了解闭包的神秘面纱,掌握LEGB规则,并使用nonlocal与global关键字来巧妙控制变量作用域。 闭包的定义与作…...

GPT-4V:AI在教育领域的应用
OpenAI于9月25日发布了最新的GPT-4V模型,为ChatGPT引入了语音和图像功能,为用户提供更多元化的使用方式。这次更新将为用户带来更便捷、直观的交互体验,用户可以直接拍照上传并针对照片内容提出问题。OpenAI的最终目标是构建安全、有益的人工…...

自动化之Java面试
1.重写与重载的区别 重载规则: 方法名相同,参数个数或类型不同,与返回值类型无关,节约词汇,例如driver.switchTo().frame(index/nameOrId/frameElement) java的重载(overload) 最重要的应用场景就是构造器…...

Redis中的Zset类型
目录 Zset的相关命令 zadd zrange zcard zcount zrevrange zrangebyscore zpopmax bzpopmax zpopmin和bzpopmin zrank zrevrank zscore zrem zremrangebyrank zremrangebyscore 操作集合间的命令 zinterstore和zunionstore 内部编码 Zset的应用场景 Zset表…...

Python行对齐工具difflib
1 用途 1.1 功能 对比两个字符串数组之间的差异,以第一个参数为基准,与第二个参数比较。 1.2 使用场景 一个原文件,一个改过的文件,对比差异;一个纯文本,一个带格式的,对比差异;…...

Flutter利用GridView创建网格布局实现优美布局
文章目录 简介使用详解导入依赖项创建一个基本的 GridView一些参数说明使用GridView.count来构造 其他控制总结 简介 GridView 是 Flutter 中用于创建网格布局的强大小部件。它允许你在行和列中排列子小部件,非常适合显示大量项目,例如图像、文本、卡片…...

IDEA 基本配置
IDEA 基本配置 1、基本样式2、环境参数3、基本插件4、参考 1、基本样式 设置全局字体大小 配置font 字体大小:15 配置类注释 /** ** Author: ${USER}* Date: ${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE}* Version: 1.0.0 */配置注释keymap 添加 注释 ccm&…...

计算机组成原理平时作业一
计算机组成原理平时作业一 1.单选题 1.1计算机中使用总线结构便于增减外设,同时(c )。 a.减少了信息传输量 b.提高了信息传输量 c.减少了信息传输量的条数 d.三者均正确 答案解析: 概念规定 1.2在定点补码运算器中,…...

iOS Crash 治理:淘宝VisionKitCore 问题修复
本文通过逆向系统,阅读汇编指令,逐步找到源码,定位到了 iOS 16.0.<iOS 16.2 WKWebView 的系统bug 。同时苹果已经在新版本修复了 Bug,对于巨大的存量用户,仍旧会造成日均 Crash pv 1200 uv 1000, 最终通…...

NSSM部署window服务
nssm 下载 安装服务:nssm install <servicename> 启动服务:nssm start <servicename> 停止服务:nssm stop <servicename> 重启服务: nssm restart <servicename> 删除创建的servername服务: nssm remove <service…...

Go语言数据类型
文章目录 Go语言数据类型一、布尔类型二、数字类型三、字符串类型四、派生类型 Go语言数据类型 在 Go 编程语言中,数据类型用于声明函数和变量。 数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存…...

Python爬取汽车之家二手车数据并作可视化
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 课程亮点: 1、系统分析目标网页 2、html标签数据解析方法 3、海量数据一键保存 获取二手车数据 环境介绍: python 3.8 pycharm 2022.3专业版 requests >>>…...
)
MacOS自动操作神器:3个隐藏功能一键搞定桌面整理(附脚本)
MacOS自动操作神器:3个隐藏功能一键搞定桌面整理(附脚本) 每次打开Mac电脑,看到满屏的文件和图标,是不是感觉工作效率瞬间降了一半?特别是视频创作者和设计师,桌面上经常堆满素材和半成品&#…...

30分钟搞定OpenClaw:Qwen3-4B镜像云端体验与技能测试
30分钟搞定OpenClaw:Qwen3-4B镜像云端体验与技能测试 1. 为什么选择云端体验OpenClaw 上周我在本地尝试部署OpenClaw时,被各种环境依赖和配置问题折磨得够呛。正当我准备放弃时,偶然发现星图平台提供了预置OpenClaw和Qwen3-4B模型的完整镜像…...

ChatGPT_JCM路由管理策略:SPA应用的导航设计与实现
ChatGPT_JCM路由管理策略:SPA应用的导航设计与实现 【免费下载链接】ChatGPT_JCM 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGPT_JCM ChatGPT_JCM是一个基于Vue2开发的OpenAI Web管理界面,提供完整的路由管理策略和单页面应用导航设计。…...

ChatGPT_JCM深色模式实现:保护眼睛的界面显示方案
ChatGPT_JCM深色模式实现:保护眼睛的界面显示方案 【免费下载链接】ChatGPT_JCM 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGPT_JCM ChatGPT_JCM是一款功能强大的AI交互工具,其深色模式实现为用户提供了舒适的夜间使用体验,有…...

OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块
OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块 1. 为什么需要自定义OpenClaw技能 去年夏天,我接手了一个重复性极高的周报生成工作。每周都要从十几个PDF报告中提取关键数据,整理成固定格式的Excel表格,再转成PPT汇报。当…...
)
LoRa网关实战:5分钟搞定MQTT通信(附Java代码示例)
LoRa网关实战:5分钟搞定MQTT通信(附Java代码示例) 在物联网项目开发中,LoRa网关与服务器的高效通信是确保数据可靠传输的关键环节。MQTT协议凭借其轻量级、低功耗的特性,成为连接LoRa设备与云端服务的首选方案。本文将…...

XML 指南
XML 指南 引言 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。自从1998年发布以来,XML因其灵活性和广泛的应用场景而成为数据交换的标准格式。本文旨在为您提供一个全面的XML指南,帮助您了解XML的基本概念、语法规则、应用场景以及相关的最佳实践。 XML的基本…...

突破百度网盘下载限速:BaiduPCS-Go命令行客户端的3大技术突破
突破百度网盘下载限速:BaiduPCS-Go命令行客户端的3大技术突破 【免费下载链接】BaiduPCS-Go iikira/BaiduPCS-Go原版基础上集成了分享链接/秒传链接转存功能 项目地址: https://gitcode.com/GitHub_Trending/ba/BaiduPCS-Go 你是否厌倦了百度网盘的龟速下载&…...

AI Token Platform - AI Token 中转计费平台
AI Token Platform - AI Token 中转计费平台 AI Token Platform 是一款企业级 AI Token 中转与计费平台,深度融合 多模型 AI 网关、Kill Bill 计费引擎 与 企业级会员管理 三大核心能力。平台以"统一 API 接入 灵活计费策略 企业级会员体系"为核心理念…...

游戏服务器检测扣除消耗防算数溢出的安全判断及解决方法
游戏服务器检测扣除消耗防算数溢出的安全判断及解决方法 数量 > (类型最大值 / 价格) 负数存在风险 价格 > (类型最大值 / 数量) || 价格 < (最小值 / 数量) 游戏服务器在处理道具消耗时需防止数值溢出问题。当检测扣除消耗时,应进行双重安全判…...