2023年大数据面试开胃菜
1、kafka的message包括哪些信息
一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成,
header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、压缩格式等等);如果magic的值为0,那么不存在attributes属性。
body是由N个字节构成的一个消息体,包含了具体的key/value消息。
2、怎么查看kafka的offset
0.9版本以上,可以用最新的Consumer client 客户端,有consumer.seekToEnd() / consumer.position() 可以用于得到当前最新的offset。
3、hadoop的shuffle过程
①、Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
②、Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也成为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
4、spark集群运算的模式
Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然Spark 还有自带的 Standalone 模式,对于大多数情况 Standalone 模式就足够了,如果企业已经有 Yarn 或者 Mesos 环境,也是很方便部署的。
standalone(集群模式):典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现 HA。
on yarn(集群模式): 运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
on mesos(集群模式): 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
on cloud(集群模式):比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3
5、HDFS读写数据的过程
读:
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
写:
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
相关文章:

2023年大数据面试开胃菜
1、kafka的message包括哪些信息一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成,header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。当magic的值为1的时候,会在magic和crc32之间多一个字节…...

优雅的controller层设计
controller层设计 Controller 层逻辑 MVC架构下,我们的web工程结构会分为三层,自下而上是dao层,service层和controller层。controller层为控制层,主要处理外部请求。调用service层,一般情况下,contro…...

同步、通信、死锁
基础概念竞争资源引起两个问题死锁:因资源竞争陷入永远等待的状态饥饿:一个可运行程序由于其他进程总是优先于它,而被调用程序总是无限期地拖延而不能执行进程互斥:若干进程因相互争夺独占型资源而产生的竞争关系进程同步…...
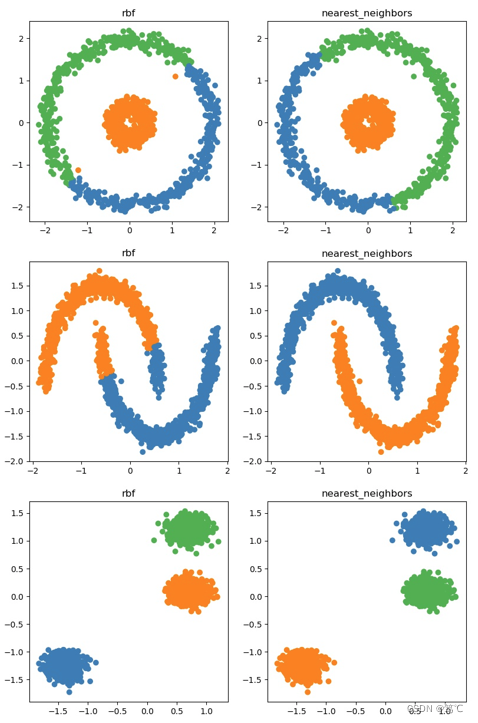
【聚类】谱聚类解读、代码示例
【聚类】谱聚类详解、代码示例 文章目录【聚类】谱聚类详解、代码示例1. 介绍2. 方法解读2.1 先验知识2.1.1 无向权重图2.1.2 拉普拉斯矩阵2.2 构建图(第一步)2.2.1 ϵ\epsilonϵ 邻近法2.2.2 k 近邻法2.2.3 全连接法2.3 切图(第二步…...
,简介)
最牛逼的垃圾回收期ZGC(1),简介
1丶什么是ZGC? ZGC是JDK 11中引入的一种可扩展的、低延迟的垃圾收集器。ZGC最主要的特点是:在非常短的时间内(一般不到10ms),就可以完成一次垃圾回收,而且这个时间是与堆的大小无关的。另外,ZGC支持非常大…...

微服务的Feign到底是什么
Feign是什么 分区是一种数据库优化技术,它可以将大表按照一定的规则分成多个小表,从而提高查询和维护的效率。在分区的过程中,数据库会将数据按照分区规则分配到不同的分区中,并且可以在分区中使用索引和其他优化技术来提高查询效…...

JavaScript 正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。搜索模式可用于文本搜索和文本替换。什么是正则表达式?正则表达式是由一…...

【批处理脚本】-1.15-文件内字符串查找命令find
"><--点击返回「批处理BAT从入门到精通」总目录--> 共7页精讲(列举了所有find的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中,…...
【手撕面试题】JavaScript(高频知识点二)
目录 面试官:请你谈谈JS的this指向问题 面试官:说一说call apply bind的作用和区别? 面试官:请你谈谈对事件委托的理解 面试官:说一说promise是什么与使用方法? 面试官:说一说跨域是什么&a…...

Web学习1_HTML
在学校期间学的Web知识忘了一些,很多东西摸棱两可,现重新系统的学习一下。 首先下载安装完vsc后并下载拓展文件live server(模拟一个服务器) Auto Rename Tag(在写网页时,自动对齐前后标签)在设…...
)
华为OD机试真题Java实现【靠谱的车】真题+解题思路+代码(20222023)
靠谱的车 题目 程序员小明打了一辆出租车去上班。出于职业敏感,他注意到这辆出租车的计费表有点问题,总是偏大。 出租车司机解释说他不喜欢数字4,所以改装了计费表,任何数字位置遇到数字4就直接跳过,其余功能都正常。 比如: 23再多一块钱就变为25; 39再多一块钱变…...
【C++入门(下篇)】C++引用,内联函数,auto关键字的学习
前言: 在上一期我们进行了C的初步认识,了解了一下基本的概念还学习了包括:命名空间,输入输出以及缺省参数等相关的知识。今天我们将进一步对C入门知识进行学习,主要还需要大家掌握我们接下来要学习的——引用…...

基于合作型Stackerlberg博弈的考虑差别定价和风险管理的微网运行策略研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

2023年全国最新保安员精选真题及答案8
百分百题库提供保安员考试试题、保安职业资格考试预测题、保安员考试真题、保安职业资格证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 81.以下各组情形都属于区域巡逻中异常情况的是()。 A&#x…...

JavaScript高级程序设计读书分享之6章——MapSet
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 Map 作为 ECMAScript 6 的新增特性,Map 是一种新的集合类型,为这门语言带来了真正的键/值存储机制。Map 的大多数特性都可以通过 Object 类型实现,但二者之间还是存在…...
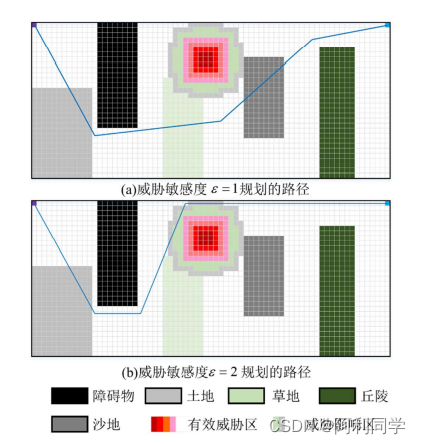
改进的 A*算法的路径规划(路径规划+代码+毕业设计)
引言 近年来,随着智能时代的到来,路径规划技术飞快发展,已经形成了一套较为成熟的理论体系。其经典规划算法包括 Dijkstra 算法、A算法、D算法、Field D算法等,然而传统的路径规划算法在复杂的场景的表现并不如人意,例…...

Tina_Linux存储性能参考指南
OpenRemoved_Tina_Linux_存储性能_参考指南 1 概述 1.1 编写目的 介绍TinaLinux 存储性能的测试方法和历史数据,提供参考。 1.2 适用范围 Tina V3.0 及其后续版本。 1.3 相关人员 适用于TinaLinux 平台的客户及相关技术人员。 2 经验性能值 Flash 性能与实…...

NCRE计算机等级考试Python真题(四)
第四套试题1、以下选项中,不属于需求分析阶段的任务是:A.需求规格说明书评审B.确定软件系统的性能需求C.确定软件系统的功能需求D.制定软件集成测试计划正确答案: D2、关于数据流图(DFD)的描述,以下选项中正…...

LeetCode每周刷题总结2.20-2.26
本栏目记录本人每周写的力扣题的相关学习总结。 虽然开新的栏目都没有完成 70.爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 解题思路: 斐波那契数列递归 class Solution {…...

u盘里删除的文件可以恢复吗?分享解决方法
u盘里删除的文件可以恢复吗?不知道使用过U盘的你,是否遇到过这样的问题呢?其实正常情况下,在电脑中操作u盘,并删除相关的文件,删除的文件是不会经过电脑回收站的。想要找回就需要借助相关的恢复工具才能实现。下面小编给大家分享…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...