在Windows或Mac上安装并运行LLAMA2
LLAMA2在不同系统上运行的结果
LLAMA2 在windows 上运行的结果

LLAMA2 在Mac上运行的结果

安装Llama2的不同方法
方法一:
编译 llama.cpp
克隆 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git通过conda 创建或者venv. 下面是通过conda 创建的。
conda create --name llama_test python=3.9
conda activate llama_test安装python依赖的包
pip3 install -r requirements.txt编译llama.cpp
mac
LLAMA_METAL=1 makewindows , 用powershell 运行 make
下载llama2模型
直接在huggingface里下载量化了的 gguf格式的llama2模型。
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/tree/main
我下载的是llama-2-7b-chat.Q4_0.gguf
拷贝llama-2-7b-chat.Q4_0.gguf 到llama.cpp目录里的models目录里
运行模型
如果是windows,要用powershell
./main -m ./models/llama-2-7b-chat.Q4_0.gguf --color --ctx_size 2048 -n -1 -ins -b 256 --top_k 10000 --temp 0.2 --repeat_penalty 1.1 -t 8
方法二:
Meta已将llama2开源,任何人都可以通过在meta ai上申请并接受许可证、提供电子邮件地址来获取模型。 Meta 将在电子邮件中发送下载链接。

下载llama2
- 获取download.sh文件,将其存储在mac上
- 打开mac终端,执行 chmod +x ./download.sh 赋予权限。
- 运行 ./download.sh 开始下载过程
- 复制电子邮件中的下载链接,粘贴到终端
- 仅下载13B-chat
安装系统依赖的东西
必须安装 Xcode 才能编译 C++ 项目。 如果您没有,请执行以下操作:
xcode-select --install接下来,安装用于构建 C++ 项目的依赖项。
brew install pkgconfig cmake
最后,我们安装 Torch。
如果您没有安装python3,请通过以下方式安装
brew install python@3.11像这样创建一个虚拟环境:
/opt/homebrew/bin/python3.11 -m venv venv激活 venv。
source venv/bin/activate安装 PyTorch:
pip install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu编译 llama.cpp
克隆 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git安装python依赖包
pip3 install -r requirements.txt编译
LLAMA_METAL=1 make
如果你有两个arch (x86_64, arm64), 可以用下面指定arm64
arch -arm64 make


将下载的 13B 移至 models 文件夹下的 llama.cpp 项目。

将模型转换为ggml格式
13B和70B是不一样的。 Convert-pth-to-ggml.py 已弃用,请使用 Convert.py 代替
13B-chat
python3 convert.py --outfile ./models/llama-2-13b-chat/ggml-model-f16.bin --outtype f16 ./models/llama-2-13b-chatQuantize 模型:
In order to run these huge LLMs in our small laptops we will need to reconstruct and quantize the model with the following commands, here we will convert the model’s weights from float16 to int4 requiring less memory to be executed and only losing a little bit of quality in the process.
13B-chat:
./quantize ./models/llama-2-13b-chat/ggml-model-f16.bin ./models/llama-2-13b-chat/ggml-model-q4_0.bin q4_0运行模型
./main -m ./models/llama-2-13b-chat/ggml-model-q4_0.bin -t 4 -c 2048 -n 2048 --color -i -r '### Question:' -p '### Question:'您可以使用 -ngl 1 命令行参数启用 GPU 推理。 任何大于 0 的值都会将计算负载转移到 GPU。 例如:
./main -m ./models/llama-2-13b-chat/ggml-model-q4_0.bin -t 4 -c 2048 -n 2048 --color -i -ngl 1 -r '### Question:' -p '### Question:'在我的 Mac 上测试时,它比纯 cpu 快大约 25%。
其它
ggml格式的llama2
如果你下载的是ggml格式的, 要运行下面命令转换格式
python convert-llama-ggml-to-gguf.py --eps 1e-5 -i ./models/llama-2-13b-chat.ggmlv3.q4_0.bin -o ./models/llama-2-13b-chat.ggmlv3.q4_0.gguf.bin(llama) C:\Users\Harry\PycharmProjects\llama.cpp>python convert-llama-ggml-to-gguf.py --eps 1e-5 -i ./models/llama-2-13b-chat.ggmlv3.q4_0.bin -o ./models/llama-2-13b-chat.ggmlv3.q4_0.gguf.bin
* Using config: Namespace(input=WindowsPath('models/llama-2-13b-chat.ggmlv3.q4_0.bin'), output=WindowsPath('models/llama-2-13b-chat.ggmlv3.q4_0.gguf.bin'), name=None, desc=None, gqa=1, eps='1e-5', context_length=2048, model_metadata_dir=None, vocab_dir=None, vocabtype='spm')=== WARNING === Be aware that this conversion script is best-effort. Use a native GGUF model if possible. === WARNING ===- Note: If converting LLaMA2, specifying "--eps 1e-5" is required. 70B models also need "--gqa 8".
* Scanning GGML input file
* File format: GGJTv3 with ftype MOSTLY_Q4_0
* GGML model hyperparameters: <Hyperparameters: n_vocab=32000, n_embd=5120, n_mult=256, n_head=40, n_layer=40, n_rot=128, n_ff=13824, ftype=MOSTLY_Q4_0>=== WARNING === Special tokens may not be converted correctly. Use --model-metadata-dir if possible === WARNING ===* Preparing to save GGUF file
This gguf file is for Little Endian only
* Adding model parameters and KV items
* Adding 32000 vocab item(s)
* Adding 363 tensor(s)gguf: write headergguf: write metadatagguf: write tensors
* Successful completion. Output saved to: models\llama-2-13b-chat.ggmlv3.q4_0.gguf.bin参考资料
GitHub - facebookresearch/llama: Inference code for LLaMA models
A comprehensive guide to running Llama 2 locally – Replicate
相关文章:
在Windows或Mac上安装并运行LLAMA2
LLAMA2在不同系统上运行的结果 LLAMA2 在windows 上运行的结果 LLAMA2 在Mac上运行的结果 安装Llama2的不同方法 方法一: 编译 llama.cpp 克隆 llama.cpp git clone https://github.com/ggerganov/llama.cpp.git 通过conda 创建或者venv. 下面是通过conda 创建…...
)
Spring底层原理学习笔记--第七讲--(初始化与销毁)
初始化与销毁 Spring提供了多种初始化和销毁手段它们的执行顺序 A07Application.java package com.lucifer.itheima.a07;import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springfram…...

基于斑马算法的无人机航迹规划-附代码
基于斑马算法的无人机航迹规划 文章目录 基于斑马算法的无人机航迹规划1.斑马搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用斑马算法来优化无人机航迹规划。 1.斑马搜索算法 …...

干货 | 接口自动化测试分层设计与实践总结
接口测试三要素: 参数构造 发起请求,获取响应 校验结果 一、原始状态 当我们的用例没有进行分层设计的时候,只能算是一个“苗条式”的脚本。以一个后台创建商品活动的场景为例,大概流程是这样的(默认已经是登录状态下)&#…...
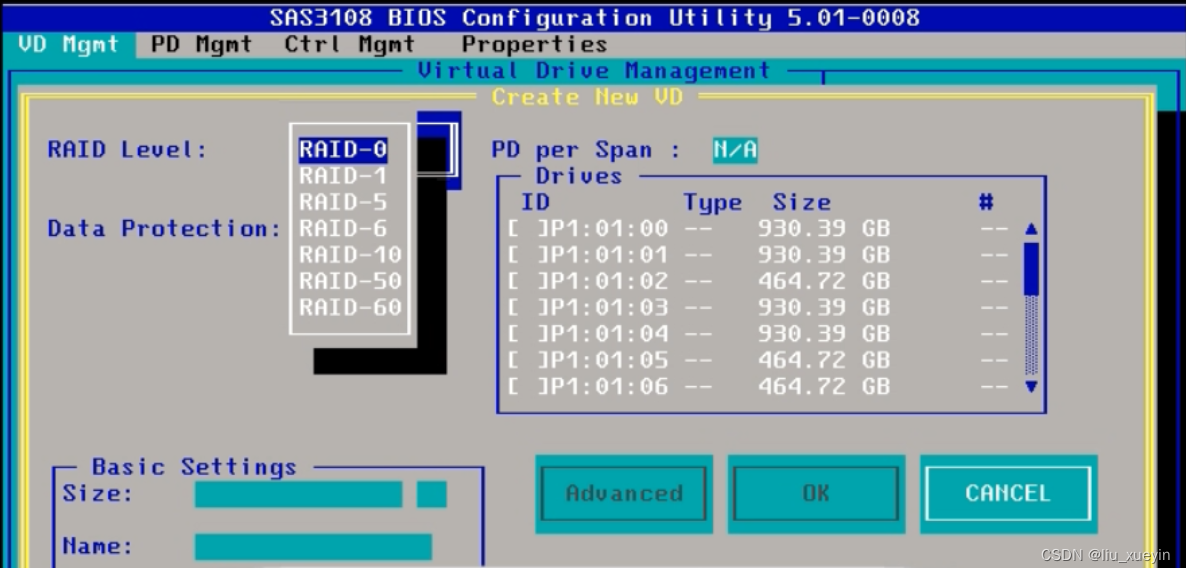
【Linux】服务器与磁盘补充知识,硬raid操作指南
服务器硬件 cpu 主板 内存 硬盘 网卡 电源 raid卡 风扇 远程管理卡 1.硬盘尺寸: 目前生产环境中主流的两种类型硬盘 3.5寸 和2.5寸硬盘 2.5寸硬盘可以通过使用硬盘托架后适用于3.5寸硬盘的服务器 但是3.5寸没法转换成2.5寸 2.如何在服务器上制作raid 华为服务器为例子做…...
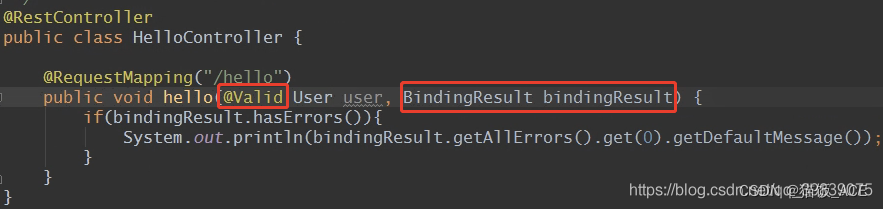
【java】实现自定义注解校验——方法二
自定义注解校验的实现步骤: 1.创建注解类,编写校验注解,即类似NotEmpty注解 2.编写自定义校验的逻辑实体类,编写具体的校验逻辑。(这个类可以实现ConstraintValidator这个接口,让注解用来校验) 3.开启使用自定义注解进…...

算法通关村第六关|白银|二叉树的层次遍历【持续更新】
1.二叉树基本的层序遍历 仅仅遍历并输出全部元素。 List<Integer> simpleLevelOrder(TreeNode root) {if (root null) {return new ArrayList<Integer>();}List<Integer> res new ArrayList<Integer>();LinkedList<TreeNode> queue new Lin…...

vue中通过js控制scss变量
<!--* Description:* Author: 李大玄* Date: 2022-07-28 20:34:43* FilePath: /web-framework-demo/src/views/layout.vue* LastEditors: 李大玄* LastEditTime: 2022-11-01 09:25:31 --> <template><div height"100%" class"b"><inp…...

深度学习理论知识入门【EM算法、VAE算法、GAN算法】和【RBM算法、MCMC算法、HMC算法】
目录 深度学习理论知识入门首先,让我们了解第一个流程:现在,让我们看看第二个流程: EM算法GMM(高斯混合模型) 深度学习理论知识入门 首先,让我们了解第一个流程: EM(Exp…...

Java8实战-总结47
Java8实战-总结47 CompletableFuture:组合式异步编程让代码免受阻塞之苦使用定制的执行器 对多个异步任务进行流水线操作 CompletableFuture:组合式异步编程 让代码免受阻塞之苦 使用定制的执行器 就这个主题而言,明智的选择似乎是创建一个…...

功能: 在web应用程序中、读取文件
通过使用文件 API,web 内容可以要求用户选择本地文件,然后读取这些文件的内容。这种选择可以通过使用 HTML <input type"file"> 元素或通过拖放来完成。 1.通过 click() 方法使用隐藏的文件 input 元素 你可以隐藏公认难看的文件 <…...

TDD、BDD、ATDD以及SBE的概念和区别
在软件开发或是软件测试中会遇到以下这些词:TDD 、BDD 、ATDD以及SBE,这些词代表什么意思呢? 它们之间有什么关系吗? TDD 、BDD 、ATDD以及SBE的基本概念 TDD:(Test Driven Development)是一种…...
Android studio:打开应用程序闪退的问题
目录 问题描述分析原因解决方法 在开发Android应用程序的过程中遇到的问题 问题描述 在开发(或者叫测试,这么简单的程序可能很难叫开发)好一个android之后,在Android studio中调试开发好的app时,编辑器没有提示错误&a…...

Mysql数据库性能优化--performance_SCHEMA.STATEMENTS语句分析
使用performance_schema解决常见的故障案例 1 检查sql语句 使用performance_schema很容易找到引起性能问题的查询以及原因。 要启动语句检测,需要启动statement类型的插装。 插装类: statement/sql sql语句,如select,或者create table。s…...
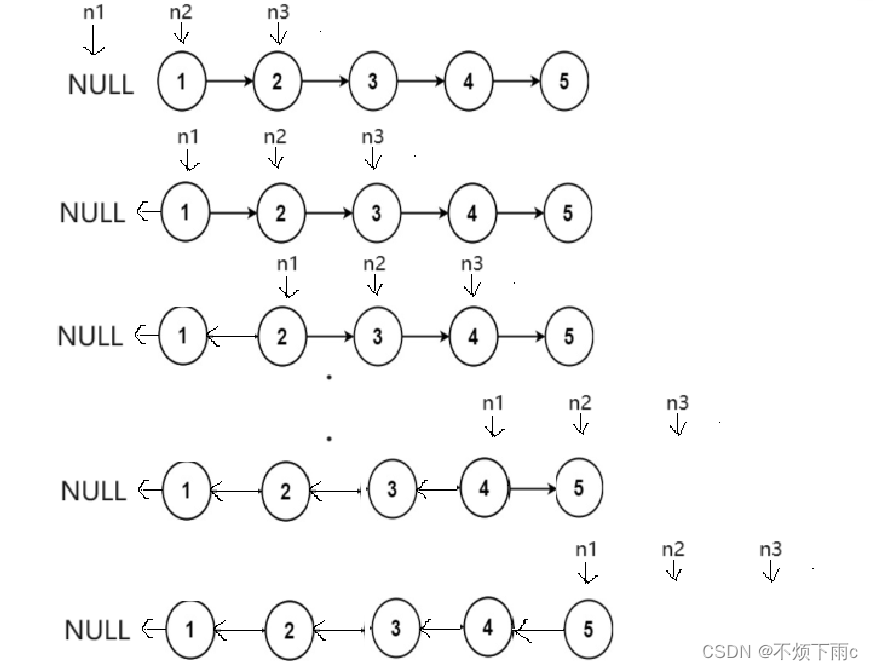
[C/C++]数据结构 链表OJ题: 反转链表
描述: 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表 示例: 方法一: 让链表指向反向 如图所示: 代码思路: struct ListNode* reverseList(struct ListNode* head) {struct ListNode* n1NULL;struct ListNode* n2head;struct ListNode*…...
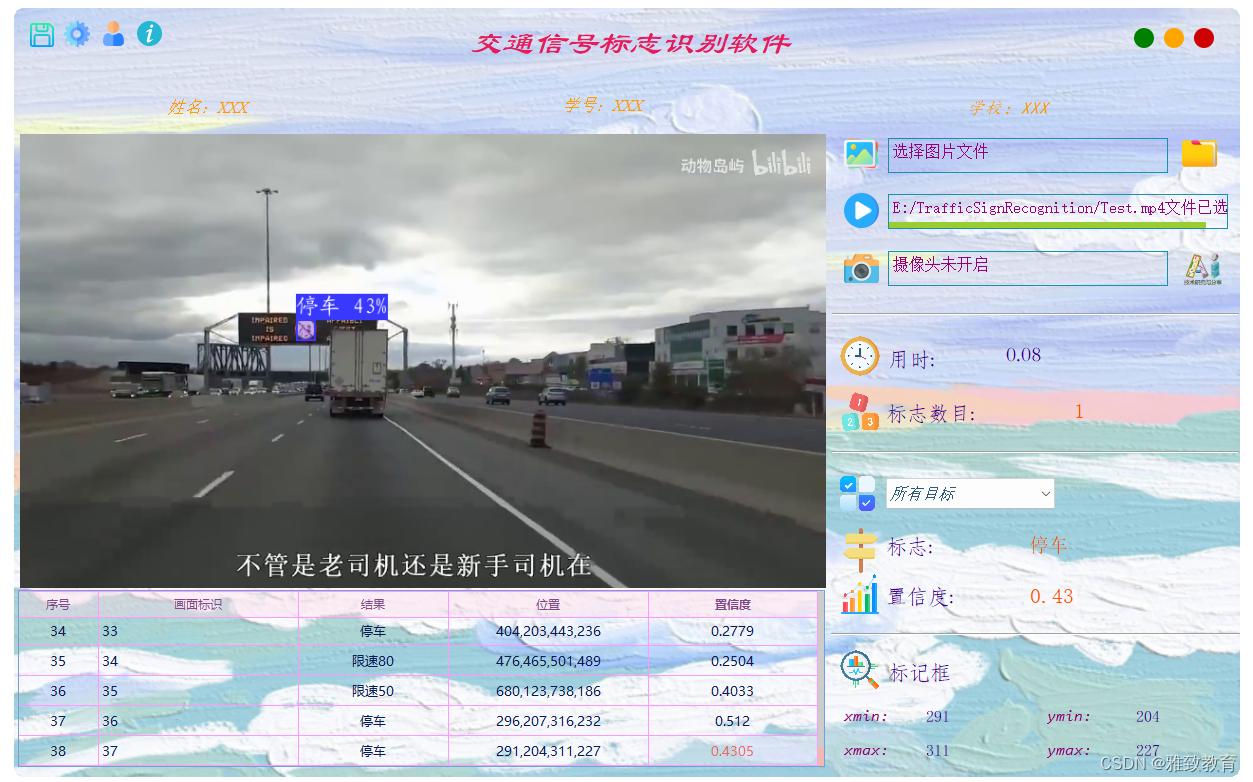
深度学习之基于YoloV5交通信号标志识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 基于YoloV5交通信号标志识别系统介绍 基于YoloV5的交通信号标志识别系统是一种深度学习应用,旨在通过使…...

Linux命令大全
荒诞也好,愚笨也好,总会过去的 文章目录 文件相关压缩相关tarzip 进程相关pskill 网络相关netstat IPC相关ipcsipcrm 系统资源相关topfreefdiskdfdu 权限相关umaskchmodchownchgrp 总结 文件相关 ls:列出当前目录中的文件和子目录。 ls常用…...
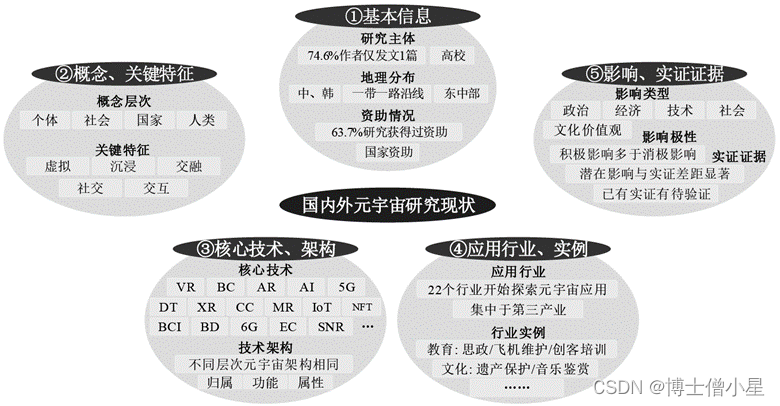
元宇宙是否为噱头?若不是,什么是元宇宙?他的概念、技术、应用和影响是什么?
文章来源:元宇宙的概念、技术、应用与影响——一项系统性文献综述 - 中国知网 (cnki.net) 摘要 [目的/意义]系统综述与分析当前国内外的元宇宙研究现状,有利于准确把握元宇宙发展方向,强化元宇宙基础研究,争取元宇宙建构权。[方法…...

293_C++_告警类
2、IncPos S32 AlarmList::IncPos(U32 *pu32Pos, U32 *pu32Cycle) {if((pu32Pos == NULL) || (pu32Cycle == NULL))</...
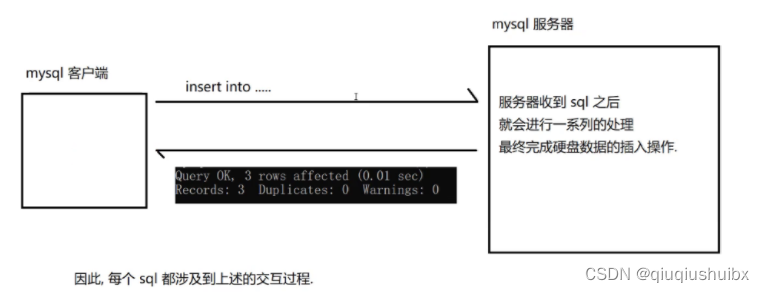
MySQL基础操作
注:mysql是大小写不敏感的. 1.数据库基础操作(展示) //1.展示当前数据库 show databases;//2.创建数据库 create database 数据库名;//3.使用数据库 use 数据库名;//4.删除数据库 drop database 数据库名;2.SQL中基本类型 2.1 数值类型(整数和浮点型) 注:decimal和numeric…...

ROS2编译报错CMake未找到diagnostic_updater:从诊断工具缺失到精准安装
1. 当CMake告诉你找不到diagnostic_updater时发生了什么 第一次看到这个报错的时候,我也是一头雾水。明明代码是从GitHub上clone下来的标准功能包,怎么一编译就报错呢?那个红色的"CMake Error"特别扎眼,就像开车时突然亮…...

基于CasRel的微信小程序开发:智能合同关键信息抽取工具
基于CasRel的微信小程序开发:智能合同关键信息抽取工具 1. 引言 你有没有过这样的经历?面对一份几十页的合同,需要手动找出甲方、乙方、合同金额、签约日期、违约责任条款……一页页翻,一行行看,不仅耗时费力&#x…...

C语言入门避坑指南:从雨课堂高频错题解析编程新手常见误区
C语言入门避坑指南:从雨课堂高频错题解析编程新手常见误区 刚接触C语言时,很多同学会被看似简单的语法规则绊倒。那些在课堂上反复强调的细节,往往成为考试中最容易丢分的陷阱。本文将结合电子科技大学《程序设计与算法基础I》课程的真实错题…...

别再让AI单打独斗了:用MCP协议手把手教你搭建一个能‘对话’的智能体协作系统
从零构建智能体协作系统:基于MCP协议的周末旅行规划实战 想象一下这样的场景:周五晚上,你对着手机说"帮我规划一个去杭州的周末旅行",30秒后,一份完整的行程建议出现在屏幕上——包含根据实时天气推荐的穿搭…...

GLM-4-9B-Chat-1M实战教程:构建私有化AI客服——长FAQ精准匹配引擎
GLM-4-9B-Chat-1M实战教程:构建私有化AI客服——长FAQ精准匹配引擎 你是不是也遇到过这样的烦恼?公司客服系统里堆满了成百上千条产品文档、用户手册和常见问题解答,每当用户提问时,客服要么得在茫茫文档里大海捞针,要…...

3步实现Web界面设计标注高效交付:面向全栈团队的Sketch Measure应用指南
3步实现Web界面设计标注高效交付:面向全栈团队的Sketch Measure应用指南 【免费下载链接】sketch-measure Make it a fun to create spec for developers and teammates 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-measure 在Web开发项目中&#x…...

LeetCode 300. Longest Increasing Subsequence 题解
LeetCode 300. Longest Increasing Subsequence 题解 题目描述 给你一个整数数组 nums,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,…...

当前主流的AI编程助手Trae、Cursor、通义灵码功能对比分析
Trae、Cursor和通义灵码是当前主流的AI编程助手,它们在功能定位、技术架构和使用体验上各有特色。以下是三款工具的详细对比分析: Trae详细操作手册和常见问题解决,请访问http://www.zrscsoft.com/sitepic/12166.html 一、核心功能对比 功能…...

音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具
音乐标签编辑器:让本地音乐元数据管理效率提升90%的开源工具 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/…...

一站式融合赋能,企业级私有化视频会议系统EasyDSS助力企业培训全流程闭环管理
传统企业培训往往面临诸多痛点,线下培训受地域、时间限制,直播培训错过即无,核心内容无法有效沉淀,会议、直播、点播多平台切换,操作繁琐效率低,EasyDSS企业级私有化视频会议系统,打破单一功能局…...