[SSD综述 1.5] SSD 主控和固件核心功能详解(万字)
依公知及经验整理,原创保护,禁止转载。
- 1. 主控概述
- 1.1 主控作用
- 2. 主控的硬件功能和实现
- 2.1 主控处理器
- 2.2 闪存、主机接口
- 2.3 主控纠错
- 2.4 断电保护
- 3 固件功能
- 3.1 FTL
- 3.2 预留空间(Over-provisioning)
- 3.3 Trim
- 3.4 写入放大(Write amplification)
- 3.5 垃圾回收(Garbagecollection)
- 3.6 磨损平衡(Wear leveling)
- 3.7 闪存多Plane操作
- 3.8 闪存多Die交错操作
前言

了解一颗固态硬盘首先要从主控入手,主控对于固态硬盘的影响丝毫不亚于闪存。那么主控芯片对于固态硬盘到底有多重要?下面我们一起来了解主控的地位、功能和运作模式。
1. 主控概述
主控简介
主控芯片顾名思义,起到主要控制的作用。它负责闪存芯片与外部数据接口的连接,以及调节各闪存芯片间的数据读写,确保其损耗平衡。
主控芯片是固态硬盘的管理中心。如果将整个固态硬盘视为小型计算机,则主控芯片为计算机的CPU,它主要负责闪存芯片与外界接口之间的沟通、闪存数据的部署、垃圾回收等重要功能。每一块硬盘都有它的主控,即便是机械硬盘也不例外,只是机械硬盘的性能基本已经定型,而且全球也只剩下希捷、西数和Toshiba三家主要厂商,对主控的关心就远不如丰富的固态硬盘产品。
而主控中的灵魂是固件算法。
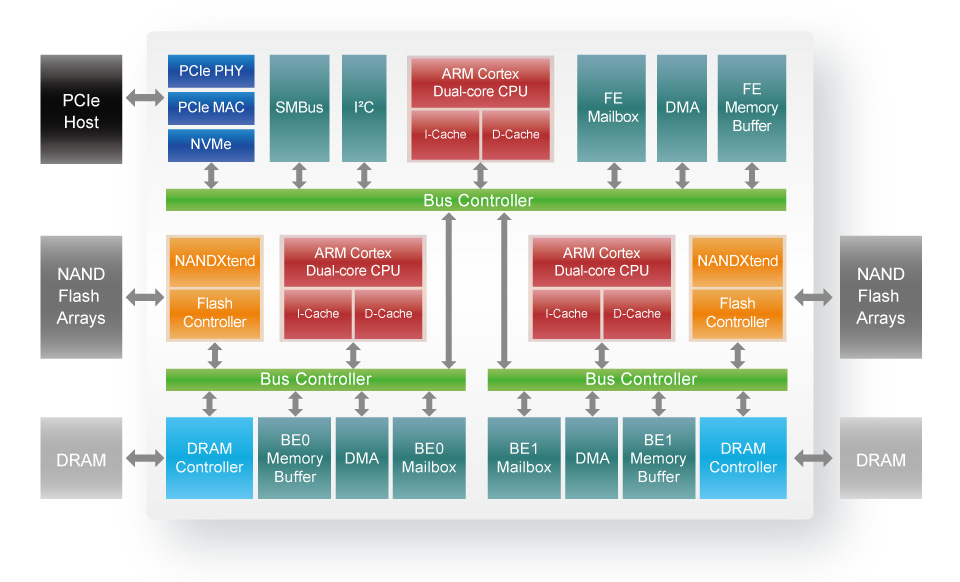
图 Silicicon Motion 主控 2270 架构框图
图片来源 https://www.inhdd.net/
1.1 主控作用
SSD的主控本质上是一颗CPU,大部分为ARM架构,主要是旗舰级主控。代表作就是Marvell家的9187以及三星的MDX。当然ARM并不是全部。主流级的大部分是RISC架构,或者老旧的ARM9架构。SSD的主控主要负责管理SSD的垃圾回收,磨损平衡,写入平衡等等,而主控的性能对于那些用了白片甚至黑片的SSD来说尤为重要,因为主控的性能不够的话,很容易造成卡顿等情况,对TLC来说也是一样的,所以TLC时代我们经常可以看到一颗硕大的主控,比MLC时代大很多,这就是原因所在。
数据中转:连接闪存芯片和外部SATA接口
内部各项指令:IO Read/Write, Trim, GC , WL, ECC 纠错等
NAND驱动: 遵照NAND SPEC,对NAND进行操作, 兼容不同NAND。
主控芯片的好坏直接决定了固态硬盘的实际体验以及使用寿命,主控的性能越强劲,数据处理、闪存芯片的数据读写控制就会有越好的表现。可以更好发挥出闪存颗粒的性能,固态硬盘在数据读写时,就不易出现发热、掉速的情况。
不同的主控之间能力相差非常大,在数据处理能力、算法上,对闪存芯片的读取写入控制上会有非常大的不同,直接会导致固态硬盘产品在性能上产生很大的差距。劣质主控不单单会影响产品性能,更有可能比颗粒坏的更早,影响产品使用寿命。
2. 主控的硬件功能和实现
为什么主控在固态硬盘中的地位如此重要呢?有三点。第一点,作为固态硬盘的"大脑",这个是对主控最基本的功能需要。主控首先要有一个处理器,但又不仅仅是一个处理器那么简单。
2.1 主控处理器
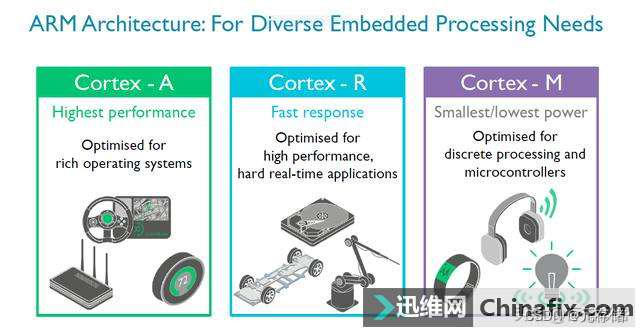
需要用到主控计算能力的地方有很多,比如FTL闪存映射表的结构管理、闪存磨损均衡的规划、垃圾回收时控制先读取,再写入,后擦除的步伐。一些定位比较高的主控通常会有多个处理器核心,分别用来执行不一样的任务,并且在多个核心之间还需要有一套协同的机制。现在很多主控都运用了ARM的处理器架构,通常选择Cortex-R系列。

这个架构和我们平时在手机上见到的A系列不一样,R系列用于实时数据处理,在响应速度上更有优势,汽车自动驾驶系统中运用的往往就是R系列,当然我们的硬盘主控也用到了它。
2.2 闪存、主机接口
第二点,主控一方面是固态硬盘的大脑,另一方面也处在大脑主机与闪存颗粒之间,起到一个搭桥的作用,一方面要跟主机沟通协作,接受和处理主机发来的命令,另一方面也要跟呆头呆脑缺乏智能的闪存颗粒打交道,搞好底层数据存取的具体实现。对于主机端的沟通,主要难点在于节能特点的把握上,SATA链路节能可以降低功耗,提升笔记本电脑电池电池续航时间,同时也符合绿色环保的理念。但是SATA链路进出节能状态的过程中需要主机和固态硬盘双方的协同,稍有不注意就会导致卡慢甚至掉盘的恶劣情况出现。现在很多非原厂的主控为了减少麻烦,图省事直接禁用了节能特点,也是一种不太自信的表现。
主控与闪存的沟通同样很复杂。固态硬盘中的闪存通常被叫做RAW闪存,智能化程度很低,只能遵循特定的闪存接口,如Toggle或者ONFI进行访问。而不一样的闪存芯片在工作特点上有些千丝万别的不一样,这就需要主控去主动适应闪存的特点。

单单要往闪存芯片中写入一个数据就要通过给闪存芯片不一样针脚施加各种高低电位,完成控制和传输指令的发出。这个过程如果仔细研究,绝对是个耗费脑细胞的工作,所以不要小看那些能够自己研究主控或是给主控开发固件的攻城狮,绝对是高智商人群。主控要完成的功能还有很多,譬如温度管理、SMART健康度报告、坏块管理等等,绝非易事。
2.3 主控纠错
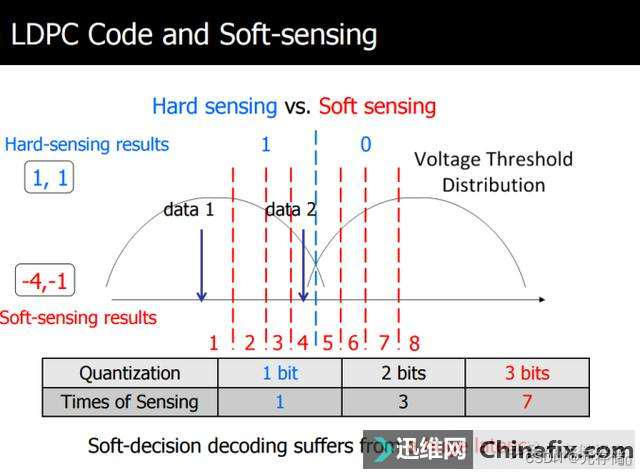
第三点,是对主控纠错引擎的要求。我们平时经常看到固态硬盘标注"支持LDPC纠错"。LDPC纠错实际上包含了硬判决和软判决两部分,前者在主控硬件内有硬件加速实现,后者则需要结合主控的运算能力去加强纠错效果。
和很多朋友想象中不一样,闪存颗粒并不是只到了寿命末期才会出错的,只是末期的出错率更高一些。所以说主控纠错引擎其实是始终在运作的,每一笔写入和读出的数据,都要经过主控纠错引擎的检验和处理。
2.4 断电保护
断电保护则是每一个固态硬盘主控都必须考虑的,它原本是只出现在企业级型号中的。过去我们讲一颗固态硬盘带不带断电保护,指的是固态硬盘是否有独立的断电保护电路,包括储能电容、监测电路和固件中的保护动作执行逻辑。完整的断电保护应该包括运行时用户数据保护以及DRAM缓存当中元数据的保护。

消费级的固态硬盘因为成本和定位的原因,在应对意外断电的防护上只做到了防止掉盘的作用。比如在美光MX300上这样一排小电容,容量上比较有限,只能保护FTL闪存映射表的安全,保护固态硬盘不掉盘就算完成使命了。

还有更多的固态硬盘,连一排小电容都没有的,它们的断电保护也并不是说就不存在。只是执行起来比较被动,比如在闪存中给FTL映射表做多次备份,这样一旦损毁还能有保底不至于彻底掉盘。再比如说定时的刷新FTL映射表到闪存中储存,降低断电产生的影响。
3 固件功能
固件就是主控芯片中的程序,是用来驱动控制器的,是各个厂商的技术核心机密. SSD需要FTL层和系统直接对话,因此固件的功能有Mapping, Trim, WL ,GC, ECC,所以固件中的算法非常多。
固件的好坏非常重要,相同主控相同闪存颗粒的产品会因为固件的不同,便会带来完全不一样的的寿命以及读写的性能。这就是各大厂家最核心的最赚钱的机密。
好的固件开发出来需要让闪存以及主控达到完美的兼容,需要按照最新先进技术的主控还有闪存颗粒的更新而修改,维护。
之所以说主控要选用大品牌,主要的原因便是在固件算法上,大厂有技术优势。固件可以看成是主控的一个驱动程序,没有固件主控就不知道要做什么和怎么做,大厂的固件总能以最短的时间做完整个事情。比如SSD需要通过FTL层和系统进行直接对话,闪存一定要在完全擦除后再能重新写入数据,所以SSD需要Trim来把闪存重新“擦干净。SSD需要一个非常完善的平衡写入算法,让所有的颗粒都均衡的被消耗,不至于导致有一部分颗粒写入寿命耗尽,而其他颗粒未使用的情况。这些都需要靠固件里的算法来实现,而固件中还有很多其他的算法,比如错误校正码(ECC),坏块管理,垃圾回收算法等等,所以,SSD固件的编写难度很高,大厂的技术优势表现的非常明显。
3.1 FTL
操作系统通常将硬盘理解为一连串 512B 大小的扇区[注意:操作系统对磁盘进行一次读或写的最小单位并不是扇区,而是文件系统的块,一般为 512B/1KB/4KB 之一(也可能更大),其具体大小在格式化时设定]。
闪存的读写单位是 4KB 或 8KB 大小的页,而且闪存的擦除操作是按照 128 或 256 页大小的块来操作的。更要命的是写入数据前必须要先擦除整个块,而不能直接覆盖。这完全不符合现有的、针对传统硬盘设计的文件系统的操作方式,很明显,我们需要更高级、专门针对 SSD 设计的文件系统来适应这种操作方式。但遗憾的是,目前还没有这样的文件系统。
为了兼容现有的文件系统,就出现了 FTL(闪存转换层),它位于文件系统和物理介质之间,把闪存的操作习惯虚拟成以传统硬盘的 512B 扇区进行操作。这样,操作系统就可以按照传统的扇区方式操作,而不用担心之前说的擦除/读/写问题。一切逻辑到物理的转换,全部由 FTL 层包了。
FTL 算法,本质上就是一种逻辑到物理的映射,因此,当文件系统发送指令说要写入或者更新一个特定的逻辑扇区时,FTL 实际上写入了另一个空闲物理页,并更新映射表,再把这个页上包含的旧数据标记为无效(更新后的数据已经写入新地址了,旧地址的数据自然就无效了)。
3.2 预留空间(Over-provisioning)
预留空间是指用户不可操作的容量,为实际物理闪存容量减去用户可用容量。这块区域一般被用来做优化,包括磨损均衡,GC和坏块映射。
第一层为固定的7.37%,这个数字是如何得出的哪?我们知道机械硬盘和 SSD 的厂商容量是这样算的,1GB 是1,000,000,000字节(10的9 次方),但是闪存的实际容量是每 GB=1,073,741,824,(2的30次方) ,两者相差7.37%。所以说假设1块 128GB 的 SSD,用户得到的容量是 128,000,000,000 字节,多出来的那个 7.37% 就被主控固件用做OP了。
第二层来自制造商的设置,通常为 0%,7%,28% 等,打个比方,对于 128G 颗粒的 SandForce 主控 SSD,市场上会有 120G 和 100G 两种型号卖,这个取决于厂商的固件设置,这个容量不包括之前的第一层 7.37% 。
第三层是用户在日常使用中可以分配的预留空间,用户可以在分区的时候,不分到完全的 SSD 容量来达到这个目的。不过需要注意的是,需要先做安全擦除(Secure Erase),以保证此空间确实没有被使用过。
预留空间的具体作用:
(1)垃圾回收:就是要把数据搬来搬去,那就需要始终有空的地方来放搬的数据。空的越多,搬的越快,多多益善,有些SSD为了更快,还会再拿走一些用户的容量。
(2)映射表等内部数据保存:SSD里面有一个巨大的映射表,把用户地址转成物理Flash颗粒地址,需要保存,以防掉电丢失。这个大概是千分之三的容量。
(3)坏块替换:写得多了,坏块会逐渐增加,需要用好的顶替。随着Flash的制程从32nm不断变小,变到现在的14nm,Flash质量越来越差,坏块越来越多,这部分可能会到3%甚至更多。
3.3 Trim
Trim 是一个 ATA 指令,当操作系统删除文件或格式化的时候,由操作系统同时把这个文件地址发送给 SSD 的主控制器,让主控制器知道这个地址的数据无效了。当你删除一个文件的时候,文件系统其实并不会真正去删除它,而只是把这个文件地址标记为“已删除”,可以被再次使用,这意味着这个文件占的地址已经是“无效”的了。这就会带来一个问题,硬盘并不知道操作系统把这个地址标记为“已删除”了,机械盘的话无所谓,因为可以直接在这个地址上重新覆盖写入,但是到了 SSD 上问题就来了。NAND 需要先擦除才能再次写入数据,要得到空闲的 NAND 空间,SSD 必须复制所有的有效页到新的空闲块里,并擦除旧块(垃圾回收)。如果没有 Trim 指令,意味着 SSD 主控制器不知道这个页是“无效”的,除非再次被操作系统要求覆盖上去。
Trim 只是条指令,让操作系统告诉 SSD 主控制器这个页已经“无效”了。Trim 会减少写入放大,因为主控制器不需要复制“无效”的页(没 Trim 就是“有效”的)到空白块里,这同时代表复制的“有效”页变少了,垃圾回收的效率和 SSD 性能也提升了。Trim 能大量减少伪有效页的数量,它能大大提升垃圾回收的效率。目前,支持 Trim 需要三个要素,
(1)系统:操作系统必须会发送 Trim 指令,Win7, Win2008R2 , Linux-2.6.33 以上。
(2)固件: SSD 的厂商在固件里要放有 Trim 算法,也就是 SSD 的主控制器必须认识 Trim 指令。
(3)驱动: 控制器驱动必须要支持 Trim 指令的传输,也就是能够将 Trim 指令传输到 SSD 控制器。MS 的驱动,Intel 的 AHCI 驱动目前支持。别的要看之后的更新了。
目前,RAID 阵列里的盘明确不支持 TRIM,不过 RAID 阵列支持 GC。
3.4 写入放大(Write amplification)
因为闪存必须先擦除(也叫编程)才能写入,在执行这些操作的时候,移动或覆盖用户数据和元数据(metadata)不止一次。这些额外的操作,不但增加了写入数据量,减少了SSD的使用寿命,而且还吃光了闪存的带宽,间接地影响了随机写入性能。这种效应就叫写入放大(Write amplification)。一个主控的好坏主要体现在写入放大上。
比如我要写入一个 4KB 的数据,最坏的情况是,一个块里已经没有干净空间了,但是有无效数据可以擦除,所以主控就把所有的数据读到缓存,擦除块,从缓存里更新整个块的数据,再把新数据写回去。这个操作带来的写入放大就是:我实际写4K的数据,造成了整个块(1024KB)的写入操作,那就是256倍放大。同时带来了原本只需要简单的写4KB的操作变成闪存读取(1024KB),缓存改(4KB),闪存擦(1024KB),闪存写(1024KB),造成了延迟大大增加,速度急剧下降也就是自然的事了。所以,写入放大是影响 SSD 随机写入性能和寿命的关键因素。
用100%随机4KB来写入 SSD,对于目前的大多数 SSD 主控而言,在最糟糕的情况下,写入放大的实际值可能会达到或超过20倍。当然,用户也可以设置一定的预留空间来减少写入放大,假设你有个 128G 的 SSD,你只分了 64G 的区使用,那么最坏情况下的写入放大就能减少约3倍。
许多因素影响 SSD 的写入放大。下面列出了主要因素,以及它们如何影响写入放大。
(1)垃圾回收虽然增加了写入放大(被动垃圾回收不影响,闲置垃圾回收影响),但是速度有提升。
(2)预留空间可以减少写入放大,预留空间越大,写入放大越低。
(3)开启 TRIM 指令后可以减少写入放大
(4)用户使用中没有用到的空间越大,写入放大越低(需要有 Trim 支持)。
(5)持续写入可以减少写入放大。理论上来说,持续写入的写入放大为1,但是某些因素还是会影响这个数值。
(6)随机写入将会大大提升写入放大,因为会写入很多非连续的 LBA。
(7)磨损平衡机制直接提高了写入放大
3.5 垃圾回收(Garbagecollection)
当整个SSD写满后,从用户角度来看,如果想写入新的数据,则必须删除一些数据,然后腾出空间再写。用户在删除和写入数据的过程中,会导致一些Block里面的数据变无效或者变老。Block中的数据变老或者无效,是指没有任何映射关系指向它们,用户不会访问到这些FLASH空间,它们被新的映射关系所取代。比如有一个Host Page A,开始它存储在FLASH空间的X,映射关系为A->X。后来,HOST重写了该Host Page,由于FLASH不能覆盖写,SSD内部必须寻找一个没有写过的位置写入新的数据,假设为Y,这个时候新的映射关系建立:A->Y,之前的映射关系解除,位置X上的数据变老失效,我们把这些数据叫垃圾数据。随着HOST的持续写入,FLASH存储空间慢慢变小,直到耗尽。如果不及时清除这些垃圾数据,HOST就无法写入。SSD内部都有垃圾回收机制,它的基本原理是把几个Block中的有效数据(非垃圾数据)集中搬到一个新的Block上面去,然后再把这几个Block擦除掉,这样就产生新的可用Block了.
另一方面,由前面的磨损平衡机制知道,磨损平衡的执行需要有“空白块”来写入更新后的数据。当可以直接写入数据的“备用空白块”数量低于一个阀值后,SSD主控制器就会把那些包含无效数据的块里的所有有效数据合并起来写到新的“空白块”中,然后擦除这个块以增加“备用空白块”的数量。
有三种垃圾回收策略:
闲置垃圾回收:很明显在进行垃圾回收时候会消耗大量的主控处理能力和带宽造成处理用户请求的性能下降,SSD 主控制器可以设置在系统闲置时候做“预先”垃圾回收(提前做垃圾回收操作),保证一定数量的"备用空白块",让 SSD 在运行时候能够保持较高的性能。闲置垃圾回收的缺点是会增加额外的"写入放大",因为你刚刚垃圾回收的"有效数据",也许马上就会被更新后的数据替代而变成"无效数据",这样就造成之前的垃圾回收做无用功了。
被动垃圾回收:每个 SSD 都支持的技术,但是对主控制器的性能提出了很高的要求,适合在服务器里用到,SandForce 的主控就属这类。在垃圾回收操作消耗带宽和处理能力的同时处理用户操作数据,如果没有足够强劲的主控制器性能则会造成明显的速度下降。这就是为啥很多 SSD 在全盘写满一次后会出现性能下降的道理,因为要想继续写入数据就必须要边垃圾回收边做写入。
手动垃圾回收:用户自己手动选择合适的时机运行垃圾回收软件,执行垃圾回收操作。
可以想象,如果系统经常进行垃圾回收处理,频繁的将一些区块进行擦除操作,那么 SSD 的寿命反而也会进一步下降。由此把握这个垃圾回收的频繁程度,同时确保 SSD 中的闪存芯片拥有更高的使用寿命,这确实需要找到一个完美的平衡点。所以,SSD 必须要支持 Trim 技术,不然 GC 就显不出他的优势了。
3.6 磨损平衡(Wear leveling)
简单说来,磨损平衡是确保闪存的每个块被写入的次数相等的一种机制。
如果系统中的所有块都定期更新,这就没有问题,因为当页面被标记为无效然后被回收时,磨损均衡几乎会自然发生。通常情况下,在 NAND 块里的数据更新频度是不同的。具体来说:如果我们有一些冷块,即数据永远不会改变的位置,那么我们必须采取措施手动重新定位该数据,否则这些块将永远不会磨损……磨损均衡需要将数据搬移到新的块,这意味着我们也在增加写入工作量,这最终意味着增加磨损。
因此,简而言之,我们对均匀磨损均衡的要求越高,我们造成的磨损就越多。但不够积极可能会导致热点和冷点,因为磨损变得更加不均匀。一如既往,这是一个找到正确平衡的问题。或者,如果您愿意,找到写入平衡。
磨损平衡算法分静态和动态。动态磨损算法是基本的磨损算法:只有用户在使用中更新的文件占用的物理页地址被磨损平衡了。而静态磨损算法是更高级的磨损算法:在动态磨损算法的基础上,增加了对于那些不常更新的文件占用的物理地址进行磨损平衡,这才算是真正的全盘磨损平衡。简单点说来,动态算法就是每次都挑最年轻的 NAND 块来用,老的 NAND 块尽量不用。静态算法就是把长期没有修改的老数据从一个年轻 NAND 块里面搬出来,重新找个最老的 NAND 块放着,这样年轻的 NAND 块就能再度进入经常使用区。
尽管磨损均衡的目的是避免数据重复在某个空间写入,以保证各个存储区域内磨损程度基本一致,从而达到延长固态硬盘的目的。但是,它对固态硬盘的性能有不利影响,并且会增加磨损。
3.7 闪存多Plane操作
多 Plane 操作 是一种能够有效提升性能的设计。例如,一个Die内部分成了4个 Plane,想象我们在操作时,也可以进行多Plane并行操作来提升性能,
不同的 Die 是独立工作的,可以并行操作。
多个SSD Channel 可以并行操作。
3.8 闪存多Die交错操作
交错操作可以成倍提升NAND的传输率,因为NAND颗粒封装时候可能有多Die、多Plane(每个plane都有4KB寄存器),不同Die操作时候可以交叉操作(第一个plane接到指令后,在操作的同时第二个指令已经发送给了第二个Die,以此类推),达到接近双倍甚至4倍的传输能力(看闪存颗粒支持度)。
参考:
[1] SSD(固态硬盘)简介 SSD(固态硬盘)简介 [金步国]
[2] SSD背后的秘密:SSD基本工作原理 http://www.ssdfans.com/?p=131
[3] 固态硬盘(SSD)原理及相关介绍 固态硬盘(SSD)原理及相关介绍_cighao的博客-CSDN博客
[4] [SSD固态硬盘技术 15] FTL映射表的神秘面纱 [SSD核心技术:FTL 15] 固态存储FTL映射表的神秘面纱_ssd映射表_元存储的博客-CSDN博客
[5] [SSD固态硬盘技术 9] FTL详解 [SSD核心技术:FTL 2] 固态硬盘数据是怎么找到的?神秘的FTL详解_元存储的博客-CSDN博客
[6] 王发宽.基于NADA闪存的混合固态硬盘设计研究[D].杭州:杭州电子科技大学,2017.
[7] SSD Fans.深入浅出SSD[M].机械工业出版社,2018.
[8] 李想.基于软件架构的固态硬盘FTL设计[D].武汉:华中科技大学,2015.
[9] 赵鹏,白石.基于随机游走的大容量固态硬盘磨损均衡算法[J].计算机学报,2012,35(5):972-978.
[10] 周懿,戴紫彬,面向Nand Flash自适应纠错码方案研究与设计[J].计算机工程与设计,2017,38(6):1681-1685.
[11] 固态硬盘存储技术的分析https://blog.csdn.net/weixin_46637351/article/details/126013567
[12] NOR Flash 和 NAND Flash 闪存详解https://blog.csdn.net/vagrant0407/article/details/127813278
[13] SSD 架构 - StorageReview.com

相关文章:
[SSD综述 1.5] SSD 主控和固件核心功能详解(万字)
依公知及经验整理,原创保护,禁止转载。 1. 主控概述1.1 主控作用 2. 主控的硬件功能和实现2.1 主控处理器2.2 闪存、主机接口2.3 主控纠错2.4 断电保护 3 固件功能3.1 FTL3.2 预留空间(Over-provisioning)3.3 Trim3.4 写入放大(Write amplification)3.5 …...
Mybatis-Plus前后端分离多表联查模糊查询分页
数据准备 数据库配置: /*Navicat Premium Data TransferSource Server : localhost_3306Source Server Type : MySQLSource Server Version : 80100 (8.1.0)Source Host : localhost:3306Source Schema : test01Target Server Type : MySQLT…...
【Ruoyi管理后台】用户登录强制修改密码
近期有个需求,就是需要调整Ruoyi管理后台:用户如果三个月(长时间)未修改过密码,需要在登录时强制修改密码,否则不能登录系统。 一、后端项目调整 从需求来看,我们需要在用户表增加一个字段,用于标记用户最…...

计算机网络基础知识1
1、tcp三次握手? SYN,标志位,用于建立TCP连接的握手过程中的标志位。 ACK,确认位,用于说明整个包是确认报文。 TCP/IP协议是传输层的一个面向连接提供可靠安全的传输协议。第一次握手有客户端发起,客户端向…...

人机交互中的多/变尺度态势感知
人机交互是指在人与计算机之间进行信息交换和任务完成的过程中,通过各种界面和交互方式来实现人机之间的有效沟通和协作。多尺度上下文是人机交互中一个重要的概念,它指的是在不同层次或不同尺度的信息之间建立联系,以便更好地理解和处理信息…...
命名管道原理(和匿名管道的对比),mkfifo(命令行,函数),命名管道模拟实现代码+与多个子进程通信代码
目录 命名管道 引入 原理 和匿名管道的对比 使用 -- mkfifo 命令行指令 创建 文件类型p 使用 函数 函数原型 模拟实现 头文件 客户端代码 服务端代码 运行情况 模拟实现 -- 与多个子进程 介绍 服务端代码: 运行情况 命名管道 引入 匿名管道只能用于父子进程…...
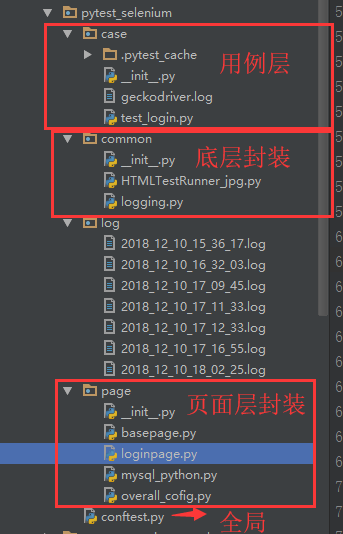
pytest全局变量的使用
这里重新阐述下PageObject设计模式: PageObject设计模式是selenium自动化最成熟,最受欢迎的一种模式,这里用pytest同样适用 这里直接提供代码: 全局变量 conftest.py """ conftest.py 全局变量,主要实…...

FreeRTOS源码阅读笔记2--list.c
list.c中主要完成列表数据结构的操作,有列表和列表项的初始化、列表的插入和移除。 2.1列表初始化vListInitialise() 2.1.1函数原型 void vListInitialise( List_t * const pxList ) pxList:列表指针,指向要初始化的列表。 2.1.2函数框架…...
杂货铺 | citespace的使用
安装教程 【CiteSpace保姆级教程1】文献综述怎么写? 📚数据下载 1. 新建文件夹 2. 数据下载 知网高级检索 数据选中导出 :一次500 导出后重命名为download_xxx.txt,放到input文件里 3. 数据转换 把output里的数据复制到data里…...

C++ 静态成员变量初始化规则
每一天一个小trick!! 为什么静态成员不能在类内初始化? 在C中,类的静态成员(static member)必须在类内声明,在类外初始化,像下面这样。 class A { private: static int count …...
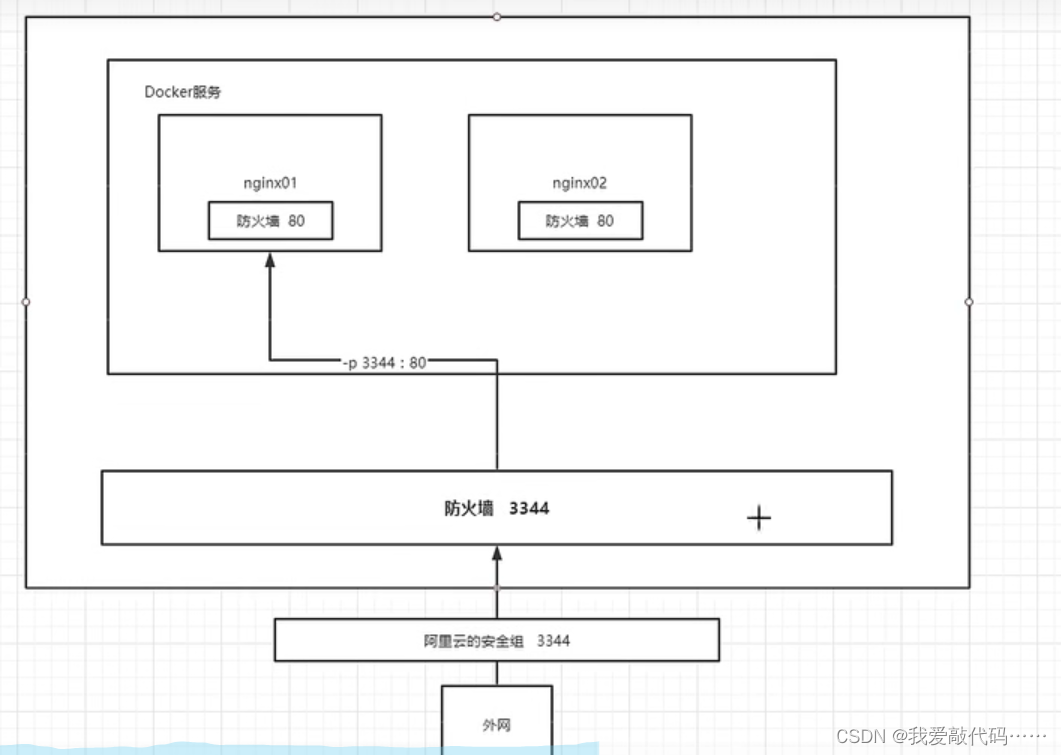
Docker安装、卸载,以及各种操作
docker是一个软件,是一个运行与linux和windows上的软件,用于创建、管理和编排容器;docker平台就是一个软件集装箱化平台,是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中…...

深入理解 C 语言的内存管理
文章目录 引言内存管理的重要性C语言内存布局C语言内存管理堆和栈内存的区别和用途内存分配和释放的过程C语言动态内存分配的概念和原因malloc()、calloc() 和 realloc() 等函数的使用悬挂指针和野指针内存泄漏和如何避免结论 引言 C语言是充满力量且灵活的编程语言࿰…...

利用Caddy实现http反向代理
利用Caddy实现http反向代理 1 Caddy是什么 Caddy是一个开源的,使用Golang编写的,支持HTTP/2的Web服务端。它的一个显著特征就是默认启用HTTPS。 和nginx类似。 2 多个后端服务 假如现在有3个后端http服务:分别在启动在 app1 http://10…...

【Qt之QVariant】使用
介绍 QVariant类类似于最常见的Qt数据类型的联合。由于C禁止联合类型包括具有非默认构造函数或析构函数的类型,大多数有趣的Qt类不能在联合中使用。如果没有QVariant,则QObject::property()和数据库操作等将会受到影响。 QVariant对象同时持有一个单一…...
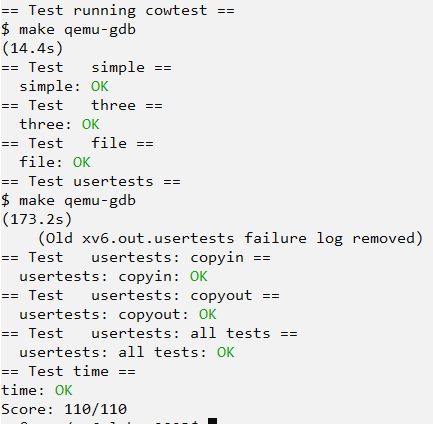
xv6实验课程--xv6的写时复制fork(2023)
7. xv6实验课程--xv6的写时拷贝(COW)(2021) 7. xv6实验课程--xv6懒惰分页分配(lazy)(2020) 本文来源: https://mp.weixin.qq.com/s/XJkhjrlP232ZDsRyXd0oHQ 已完成的实验代码可以从下列网站获取: git clone https://gitee.com/lhwhit196…...
在Windows或Mac上安装并运行LLAMA2
LLAMA2在不同系统上运行的结果 LLAMA2 在windows 上运行的结果 LLAMA2 在Mac上运行的结果 安装Llama2的不同方法 方法一: 编译 llama.cpp 克隆 llama.cpp git clone https://github.com/ggerganov/llama.cpp.git 通过conda 创建或者venv. 下面是通过conda 创建…...
)
Spring底层原理学习笔记--第七讲--(初始化与销毁)
初始化与销毁 Spring提供了多种初始化和销毁手段它们的执行顺序 A07Application.java package com.lucifer.itheima.a07;import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springfram…...

基于斑马算法的无人机航迹规划-附代码
基于斑马算法的无人机航迹规划 文章目录 基于斑马算法的无人机航迹规划1.斑马搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用斑马算法来优化无人机航迹规划。 1.斑马搜索算法 …...

干货 | 接口自动化测试分层设计与实践总结
接口测试三要素: 参数构造 发起请求,获取响应 校验结果 一、原始状态 当我们的用例没有进行分层设计的时候,只能算是一个“苗条式”的脚本。以一个后台创建商品活动的场景为例,大概流程是这样的(默认已经是登录状态下)&#…...
【Linux】服务器与磁盘补充知识,硬raid操作指南
服务器硬件 cpu 主板 内存 硬盘 网卡 电源 raid卡 风扇 远程管理卡 1.硬盘尺寸: 目前生产环境中主流的两种类型硬盘 3.5寸 和2.5寸硬盘 2.5寸硬盘可以通过使用硬盘托架后适用于3.5寸硬盘的服务器 但是3.5寸没法转换成2.5寸 2.如何在服务器上制作raid 华为服务器为例子做…...

Axios知识
安装:npm方式:npm install axios直接方式:<script src"https://unpkg.com/axios/dist/axios.min.js"></script>实例:// 发起一个post请求 axios({method: post,url: /user/12345,data: { // 向后端传参数firstName: Fr…...

原神帧率解锁终极指南:3步轻松突破60FPS限制,享受极致流畅体验
原神帧率解锁终极指南:3步轻松突破60FPS限制,享受极致流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为原神60帧限制而苦恼吗?高端显卡却…...

kin-openapi版本迁移指南:从v0.x到v1.0的平滑升级
kin-openapi版本迁移指南:从v0.x到v1.0的平滑升级 【免费下载链接】kin-openapi OpenAPI 3.0 (and Swagger v2) implementation for Go (parsing, converting, validation, and more) 项目地址: https://gitcode.com/gh_mirrors/ki/kin-openapi kin-openapi是…...

从idea ai插件到在线原型:用快马平台快速构建你的智能代码生成器
最近在开发中频繁使用IDEA的AI插件辅助编码,发现这类工具能大幅减少重复劳动。但插件功能往往局限于当前IDE环境,于是萌生了一个想法:能否把这种智能生成能力搬到线上,做成一个轻量级的Web工具?经过在InsCode(快马)平台…...

ComfyUI翻译节点终极指南:如何选择最适合你的AI创作翻译工具
ComfyUI翻译节点终极指南:如何选择最适合你的AI创作翻译工具 【免费下载链接】ComfyUI_Custom_Nodes_AlekPet Custom nodes that extend the capabilities of Comfyui 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_Custom_Nodes_AlekPet 在AI图像生…...

基于历史数据的加密货币交易系统策略验证实践指南
基于历史数据的加密货币交易系统策略验证实践指南 【免费下载链接】node-binance-trader 💰 Cryptocurrency Trading Strategy & Portfolio Management Development Framework for Binance. 🤖 项目地址: https://gitcode.com/gh_mirrors/no/node-…...

Kandinsky-5.0-I2V-Lite-5s实战案例:用会议合影生成带入场动画的团队介绍视频
Kandinsky-5.0-I2V-Lite-5s实战案例:用会议合影生成带入场动画的团队介绍视频 1. 项目背景与价值 想象一下这个场景:公司刚开完年度战略会议,团队拍了一张大合影。现在需要制作一个团队介绍视频,传统方式需要找专业剪辑师&#…...
)
机械革命无界14X实战:用VMware 17.5给AMD 8845HS装macOS 15(附8核/16核OC引导)
机械革命无界14X实战:AMD 8845HS笔记本在VMware 17.5上运行macOS 15全攻略 最近不少技术爱好者都在尝试将macOS系统运行在AMD平台的笔记本上,尤其是搭载锐龙8845HS处理器的设备。作为一款性能强劲的移动处理器,8845HS配合780M核显确实具备运…...

FastAPI 2.0流式AI接口上线前必须做的4项压力测试:QPS突破1200+的实测阈值与熔断配置清单
第一章:FastAPI 2.0流式AI接口压力测试全景认知FastAPI 2.0 引入了对异步流式响应(如 StreamingResponse)的深度优化,使大语言模型(LLM)类接口可原生支持 Server-Sent Events(SSE)、…...

如何用Obsidian Image Converter实现图像高效管理?超实用技巧分享
如何用Obsidian Image Converter实现图像高效管理?超实用技巧分享 【免费下载链接】obsidian-image-converter ⚡️ Convert, compress, resize, annotate, markup, draw, crop, rotate, flip, align images directly in Obsidian. Drag-resize, rename with variab…...