缓存-基础理论和Guava Cache介绍
缓存-基础理论和Guava Cache介绍
缓存基础理论
缓存的容量和扩容
缓存初始容量、最大容量,扩容阈值以及相应的扩容实现。
缓存分类
本地缓存:运行于本进程中的缓存, 如Java的 concurrentHashMap, Ehcache,Guava Cache。
分布式缓存:支持分布式环境读取的缓存, 如Redis,
另外还有其他特定场景的缓存,如:浏览器缓存、CDN、反向代理、数据库缓存。
多级缓存
缓存在系统中根据作用域形成的层次级的缓存,如mybatis的一级(sqlSession级)、二级缓存(跨sqlSession mapper级); 本地缓存+分布式缓存的多级组合;
缓存过期策略
缓存数据的过期清理算法。通常有:设置key的过期时间,当内存不足时的数据淘汰算法,常见的淘汰算法如:LRU (Least Recently Used)最近最少使用算法,FIFO先进先出算法,LFU (Least Frequently Used)剔除最近使用频率最低的数据,随机算法等。
缓存更新策略
缓存更新策略是指定时对缓存中数据进行更新的策略。包括定时刷新,另外也指缓存和后台数据源的数据同步策略。如常见的三种更新策略:
Cache Aside Pattern(旁路缓存模式):写数据:先更新db,删除缓存;读数据时如果存在,则直接返回;如果不存在从db加载写入缓存。
Read/Write Through Pattern(读写穿透模式):缓存作为主数据源,写入数据写入缓存,缓存再负责更新到db。读取时如读取不到则将数据从db加载到缓存再从缓存返回。
Write Behind Pattern (异步缓存写入模式):和Read/Write Through Pattern区别是更新db时是异步的批量更新模式。
缓存预热
根据业务场景,提前将缓存数据加载到缓存中,可以避免使用时才查询数据库。
缓存命中率
缓存命中是指通过缓存读取数据时直接从缓存获取数据,未命中是指无法从缓存获取数据,或者是缓存中不存在,或者是数据已过期,需要重新从该数据库或其他敌法加载数据到缓存中。缓存命中率是缓存使用的最重要指标,命中率越高缓存的提升越高。缓存框架应提供缓存命中率的统计和查看工具。
缓存命中率的影响因素主要包括:业务场景、缓存粒度、缓存容量、过期策略等因素。
缓存雪崩/缓存穿透/缓存击穿
缓存雪崩:缓存大量数据失效或则缓存系统出现异常,造成大量请求直接形成对数据库的巨大压力。解决方法:缓存失效随机;缓存集群; key永不失效; 请求加锁等。
缓存穿透:请求数据库中不存在的数据,缓存失效。解决方案:布隆过滤器;缓存空对象。
缓存击穿:指当缓存中热点数据过期,在热点数据重新载入缓存之前,大量的查询请求穿过缓存,直接查询数据库。 解决方案:key 永不过期;分布式锁。
Guava Cache
Guava Cache 是Guava Java工具包中提供的本地缓存工具,可以作为独立的本地缓存或多级缓存中的本地缓存使用。
数据结构
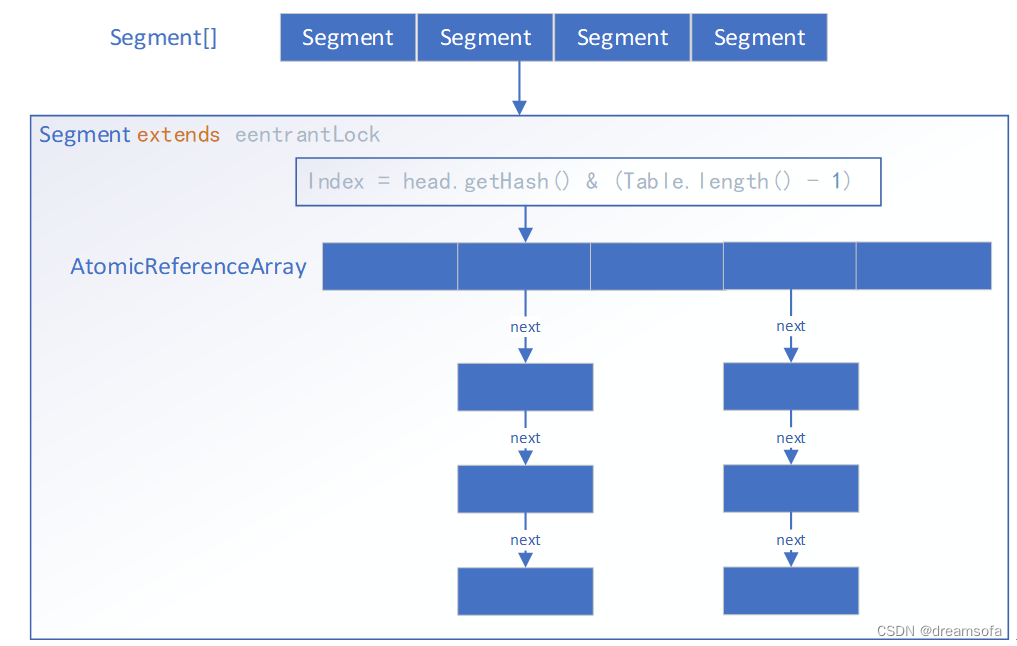
图1 Guava Cache存储数据结构
Guava Cache 将缓存换分为多个段(Segment[]), 每个段都是ReentrantLock的子类,段和段之间是完全并行,段内是写入加锁,读取不加锁的并发控制。
Segment内部数据结构使用AtomicReferenceArray来表示Hash入口,相同hash在AtomicReferenceArray的同一位置形成一个链表。
有多少个Segment?
- 由配置参数ConcurrencyLevel决定:ConcurrencyLevel 默认是4,最大是65536(1<<16)
- (!evictsBySize() ||segmentCount * 20 <= maxWeight):当制定了最大数据权值时,通过段数*20 < 最大权值来避免过于稀疏的端。
| int segmentShift = 0; int segmentCount = 1; while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) { ++segmentShift; segmentCount <<= 1; } this.segmentShift = 32 - segmentShift; segmentMask = segmentCount - 1; |
如 segmentCount = 4时, segmentShift = 32 – 2 = 30, segmentMask = 0x03
无符号Hash, 最高的两位用于识别Segment位置, segments[(hash >>> segmentShift) & segmentMask]。
数据的释放
除了根据缓存协议的过期时间、数据替换策略对缓存元素进行释放外, Guava Cache可以设置缓存key/value应用强度,是的在内存不足时缓存数据可以得到释放。
Java引用强度
强引用:普通对象引用,当对象存在引用时不会回收。
软引用: SoftReference<String> ref = new SoftReference<String>(“test”);,当内存足够时,对象不会被回收, 当内存不足时,对象会被回收。
弱引用:WeakReference<T> 垃圾回收中,不管内存是否充足,如果对象只存在弱引用则被回收。如果WeakReference指定ReferenceQueue的话,在释放的时候就把这个Reference放到ReferenceQueue里面。
虚引用: PhantomReference<T>虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
查找过程
- 定位Segment
- 定位Segment内数组Hash索引: table.get(hash & (table.length() - 1));
- 遍历同hash的队列找出相等的key
- 检查是否过期, 如不过期返回,过期则尝试加载后返回。
过期检查
accessQueue: 缓存元素引用的队列,当元素被使用(包括加载)时加入accessQueue的队尾,也就是accessQueue中包含缓存所有元素的引用。
writeQueue: 缓存元素引用的队列,当元素被写入时,加入到writeQueue队尾。
当每次获取某个元素时,都对段内元素按AccessQueue和WriteQueue顺序检查元素是否过期,因为两个队列都是按照操作顺序(加载或写)加入队列的, 所以只需要从头移除过期元素直到碰到第一个未过期的元素即可。
注: 将元素提前进行排序或分组以加快后续功能的查找速度是常用的优化方法,类似如RocketMQ延期队列按延期时间划分到不同的子主题中,也体现了性能优化:分而治之、提前部署、异步非阻塞的思维之一:提前部署。 缓存本身也是该思维的体现。
加载
当查找无法找到元素或元素已过期时将触发一个元素加载的过程, 元素加载细分为两个操作: 在Segment中加入引用;实际进行元素加载。
- 在Segment上加锁,完成添加引用操作后释放Segment锁。
- 在新的引用入口上加同步锁,完成实际的元素加载后释放。如果是新建的引用,针对引用对象进行枷锁,完成加载。如其他线程此时读取对象,发现该引用对象属于加锁状态,则等待元素的加载完成后获取。
注:分段加锁体现了多并发所操作的重要原则之一:正确确定锁的作用范围。 引入更多层次上的锁,避免粗放使用,造成锁的范围扩大。其他类似如:数据库的表锁、行锁。
新增/更新(put)
Put操作时,在Segment中根据key对应hash值查找到元素, 如查找则更新值,如无法找到,新建元素引用并加入到响应的索引位置。新增元素将放置于AtomicRefereceArray中索引位置, 新增元素的Next引用指向原索引位置的元素。
吸入之前将对Segment进行清除: 已过期的,或因弱引用已经被释放的key/value对象。
扩容
当Segment中元素数量超过指定阈值时将触发扩容。阈值是当前AtomicReferencyArray长度的3/4。扩容在Segment锁下进行。
扩容过程:
- 新建一个常度为原长度两倍的AtomicReferenceArray。
- 遍历原AtomicReferenceArray 所有元素,计算Key的hash值,按照新的长度取余插入新引用数组中, 插入方式同新增。
- 使用新的AtomicReferenceArray。
数据同步方案
Guava Cache 的数据同步有三种模式:
- 客户PUT或REPLACE数据。
- 查找时无法找到或则元素已经过期时进行同步的加载。
- 异步批量刷新。
过期策略
设置过期时间
Guava Cache 通过设置expireAfterAccess(读取后过期时间),expireAfterWrite(写入后过期时间),refreshAfterWrite(写入后刷新过期时间)三个过期时间触发数据刷新
最近最少使用替换算法
当设置了缓存的最大权重并且当前段的总权重已经超过最大权重,则需要进行数据的主动清理,也就是缓存中的过期策略或替换算法。
Guava Cache使用最近最少使用的算法。 当超过是使用AccessQueue将最早的元素释放,直到总权重小于最大权重。
命中率
Guava cache使用 StatsCounter 统计缓存的命中,当缓存命中或未命中时进行计数。通过Cache接口的CacheStats stats()方法展示信息。
相关文章:
缓存-基础理论和Guava Cache介绍
缓存-基础理论和Guava Cache介绍 缓存基础理论 缓存的容量和扩容 缓存初始容量、最大容量,扩容阈值以及相应的扩容实现。 缓存分类 本地缓存:运行于本进程中的缓存, 如Java的 concurrentHashMap, Ehcache,Guava Cache。 分布式缓…...
机器人伺服驱动控制环
伺服驱动器的控制环,包括:位置环、速度环、电流环这三种类型。 对于伺服的控制回路,内侧控制环的响应带宽一般会是外侧控制环的5到10倍。也就是说,电流环带宽大致是速度环的5到10倍,速度环带宽则约为位置环的5到10倍…...
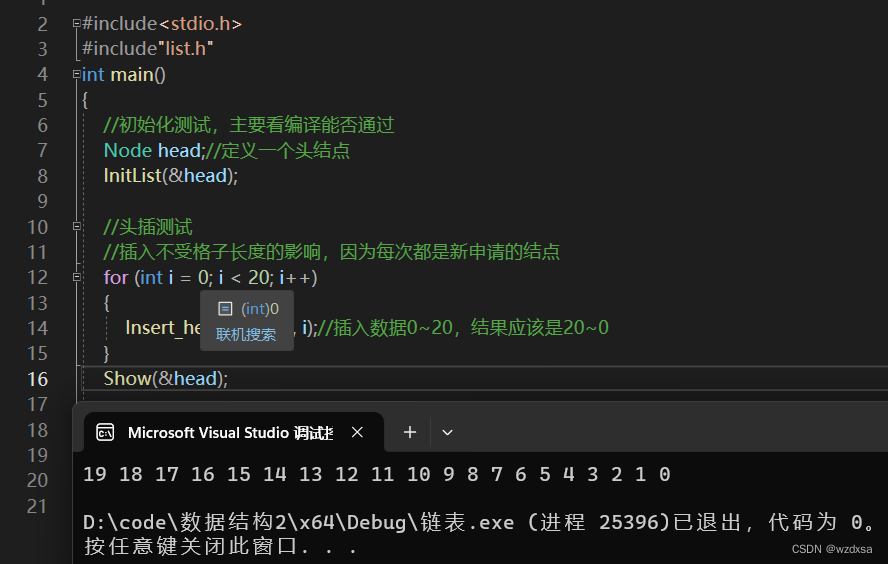
单链表(3)
现在有一个指针p,指向数据2所在的结点的地址——那么如何访问这个数据2 前面说过指针访问数据成员使用的是 指向符->。则访问这个数据2就是——p->data.因为p一开始就指向数据2的结点地址了 那么如何访问数据3,4往后等等 访问3就是——p->next->data…...

Android14前台服务适配指南
Android14前台服务适配指南 Android 10引入了android:foregroundServiceType属性,用于帮助开发者更有目的地定义前台服务。这个属性在Android 14中被强制要求,必须指定适当的前台服务类型。以下是可选择的前台服务类型: camera: 相机应用。…...

Spring Boot中使用Spring Data JPA访问MySQL
Spring Data JPA是Spring框架提供的用于简化JPA(Java Persistence API)开发的数据访问层框架。它通过提供一组便捷的API和工具,简化了对JPA数据访问的操作,同时也提供了一些额外的功能,比如动态查询、分页、排序等。 …...
)
Go 语言函数闭包(匿名函数)
Go 语言函数闭包(匿名函数) 在Go语言中,闭包是一种特殊的匿名函数,它可以捕获并访问其周围的变量。闭包允许将函数与其引用的环境捆绑在一起,使得函数可以在其创建的范围之外继续使用这些变量。以下是关于Go语言闭包的…...

2023年11月编程语言流行度排名
点击查看最新编程语言流行度排名(每月更新) 2023年11月编程语言流行度排名 编程语言流行度排名是通过分析在谷歌上搜索语言教程的频率而创建的 一门语言教程被搜索的次数越多,大家就会认为该语言越受欢迎。这是一个领先指标。原始数据来自…...

apache-maven-3.6.3 安装配置教程
链接:https://pan.baidu.com/s/1RkMXipnvac9EKcZyUStfGQ?pwdl32m 提取码:l32m 1. 将 maven 压缩包解压至指定文件夹 2. 配置环境变量 (1)打开此电脑-> 鼠标右键选择属性->点击高级系统设置 (2)点…...

你一般什么时候使用GPT
一般在寻求帮助的时候才使用gpt 一个优秀的gpt项目gpt-on-web...
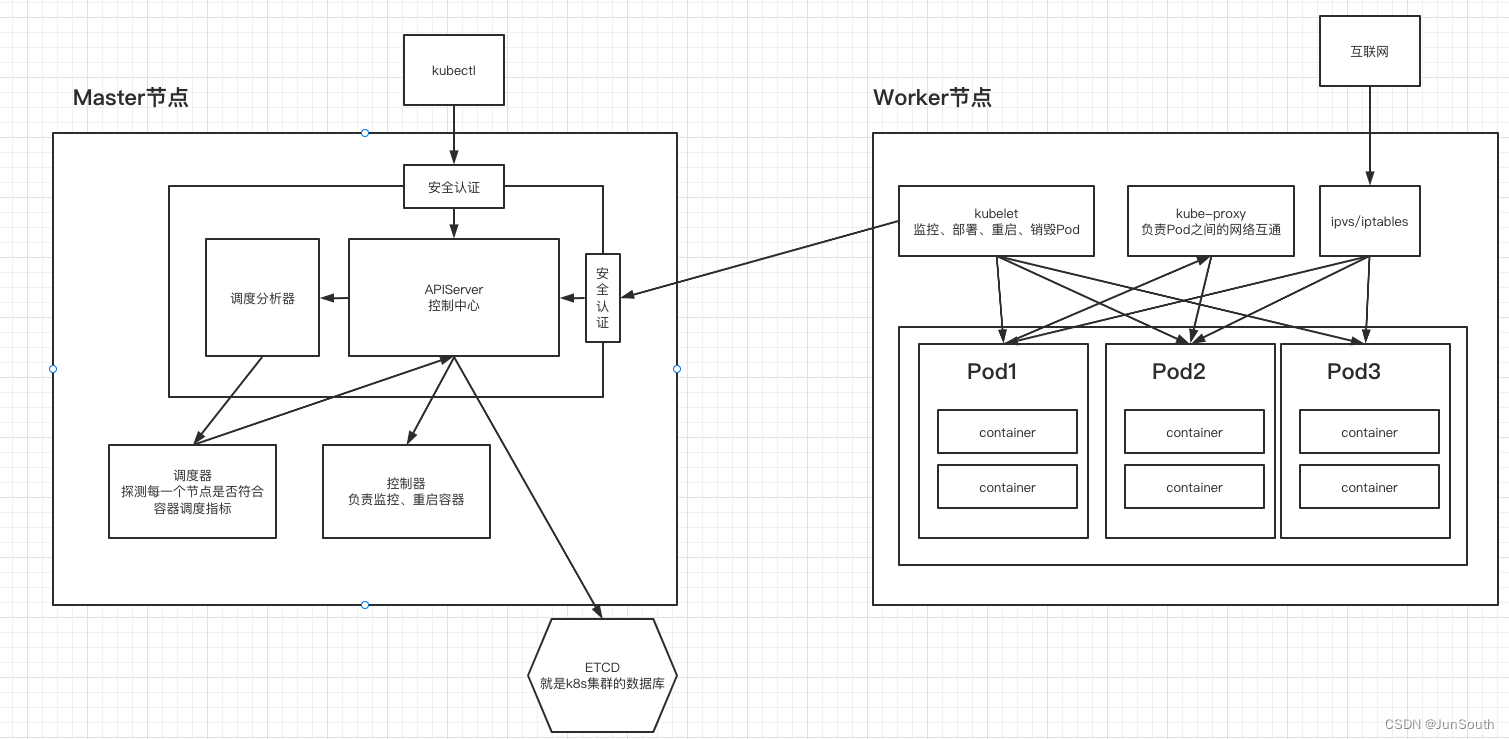
kubernetes (k8s)的使用
一、kubernetes 简介 谷歌2014年开源的管理工具项目,简化微服务的开发和部署。 提供功能:自愈和自动伸缩、调度和发布、调用链监控、配置管理、Metrics监控、日志监控、弹性和容错、API管理、服务安全等。官网:https://kubernetes.io/zh-cn…...
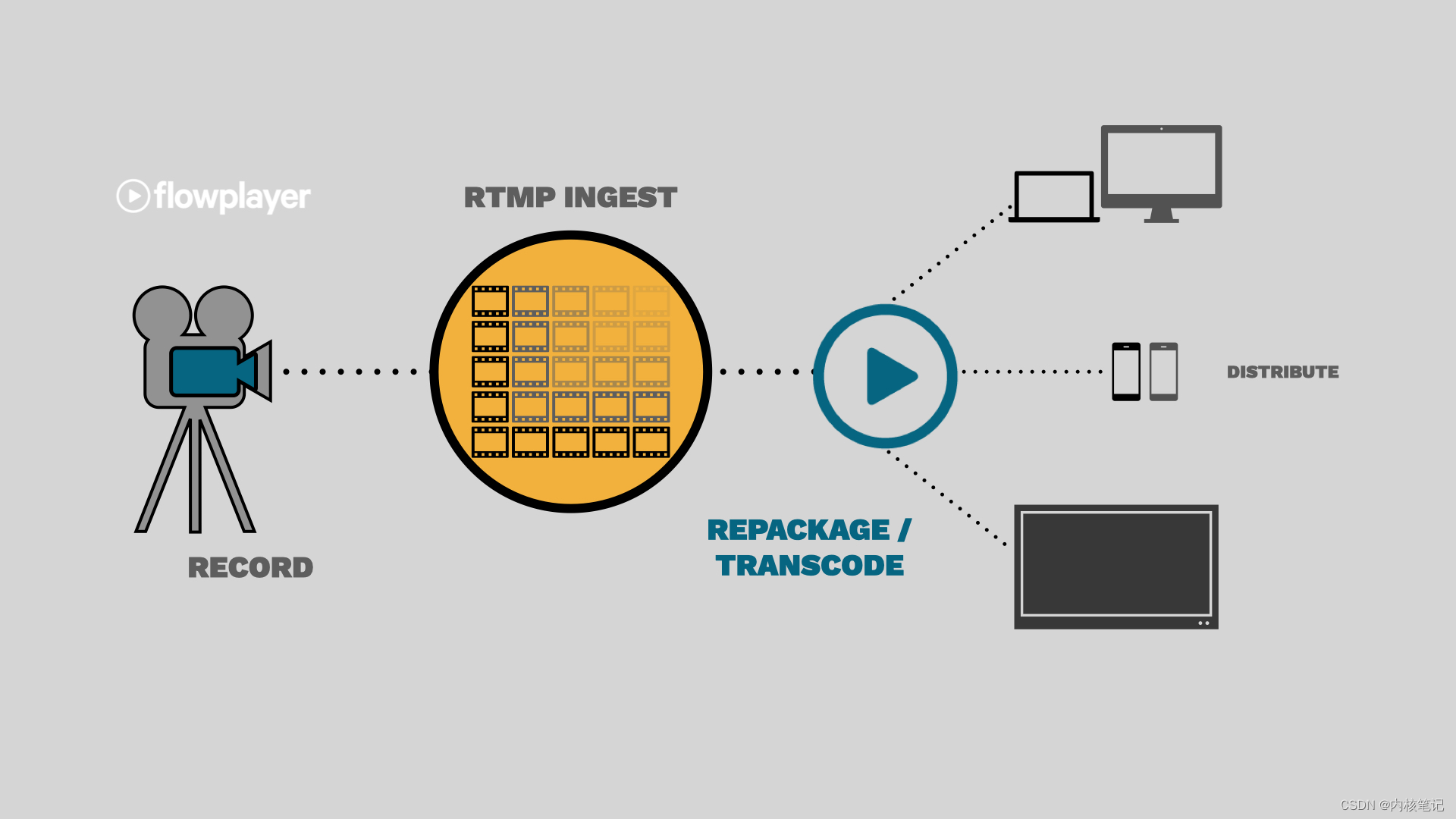
RK3568平台开发系列讲解(音视频篇)RTMP 推流
🚀返回专栏总目录 文章目录 一、RTMP 的工作原理二、RTMP 流媒体服务框架2.1、Nginx 流媒体服务器2.2、FFmpeg 推流沉淀、分享、成长,让自己和他人都能有所收获!😄 📢目前常见的视频监控和视频直播都是使用了 RTMP、RTSP、HLS、MPEG-DASH、 WebRTC流媒体传输协议等。 R…...

掌握这几个技巧,才敢称为Jenkins大神!
01、Performance插件兼容性问题 自由风格项目中,有使用 Performance 插件收集构建产物,但是截至到目前最新版本(Jenkins v2.298,Performance:v3.19),此插件和Jenkins都存在有兼容性问题…...

帷幄内容管理系统:从立人设、做内容到定向投流,品牌 KOS 体系打造「百万导购」
随着公域流量越来越贵,获客成本越来越高,品牌们已经越来越不满足于高曝光,而是更多地关注起销售转化率。继 KOL、KOC(关键意见消费者) 之后,KOS(关键意见销售)营销模式走入品牌的视野…...
:实现顶部导航栏功能:导航栏静态搭建,菜单折叠功能实现,面包屑动态展示路径,刷新页面功能,全屏功能)
5.vue3项目(五):实现顶部导航栏功能:导航栏静态搭建,菜单折叠功能实现,面包屑动态展示路径,刷新页面功能,全屏功能
目录 一、左侧菜单栏刷新,不要合并菜单 二、顶部tabbar静态搭建 1.新建文件 2.编辑页面 3.结果测试...
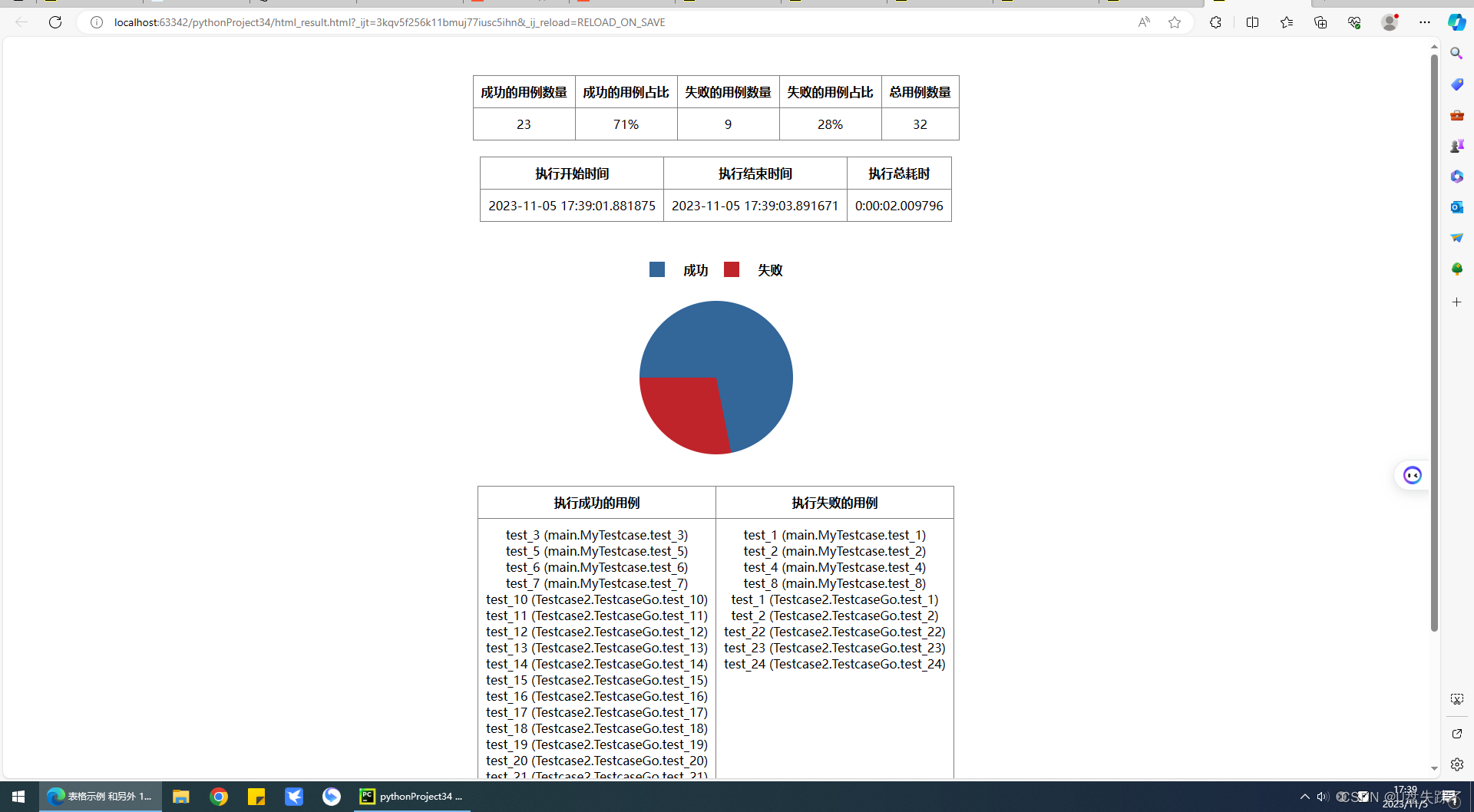
unittest 统计测试执行case总数,成功数量,失败数量,输出至文件,生成一个简易的html报告带饼图
这是一个Python的单元测试框架的示例代码,主要用于执行测试用例并生成测试报告。其中,通过unittest模块创建主测试类MainTestCase,并加载其他文件中的测试用例,统计用例的执行结果并将结果写入文件,最后生成一个简单的…...
推荐一款功能强大的在线文件预览工具-kkFileView
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
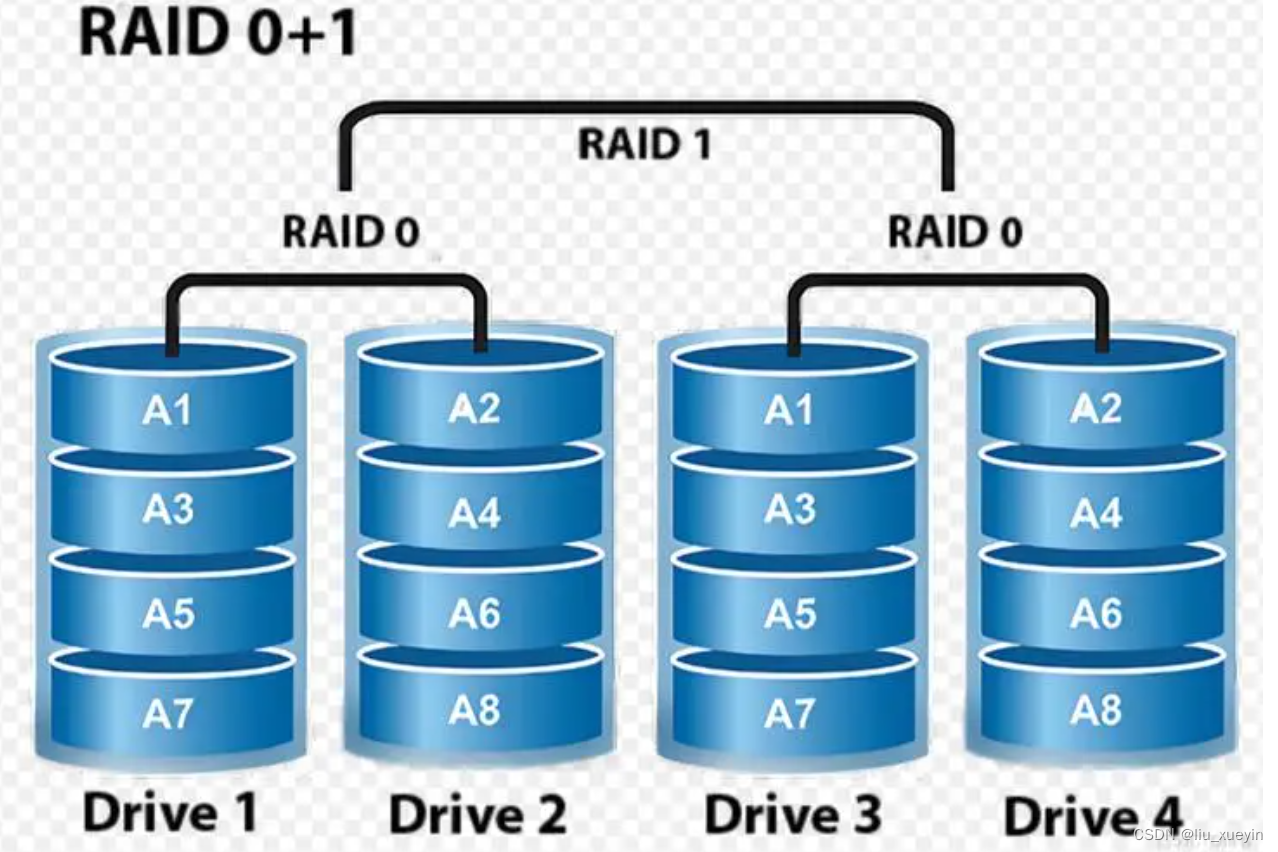
【Linux】磁盘阵列,了解不同raid的特点
一、raid和阵列卡介绍 1、什么是磁盘阵列: 磁盘阵列是利用虚拟化存储技术把很多块独立的磁盘组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放…...

Go 语言初探:从基础到实战
1.Go概述 程序是一段计算机指令的有序组合。程序算法数据结构。任何程序都可以将模块通过三种基本的控制结构(顺序、分支、循环)进行组合来实现。 Go(也称为Golang)是一种由Google开发的开源编程语言。设计目标是使编程更简单、…...
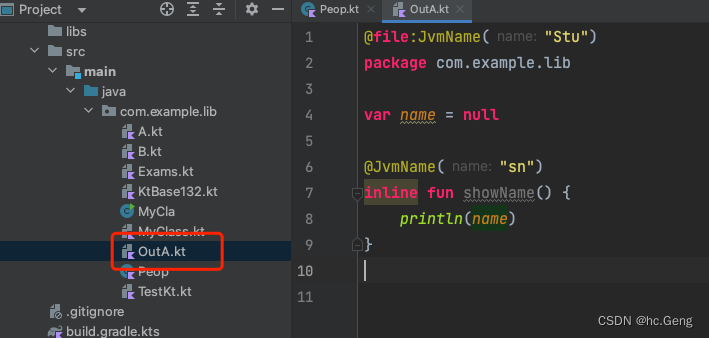
Kotlin文件和类为什么不是一对一关系
在Java中,一个类文件的public类名必须和文件名一致,如何不一致就会报异常,但是在kotlin的文件可以和类名一致,也可以不一致。这种特性,就跟c有点像,毕竟c的.h 和 .cpp文件是分开的。只要最终编译的时候对的…...
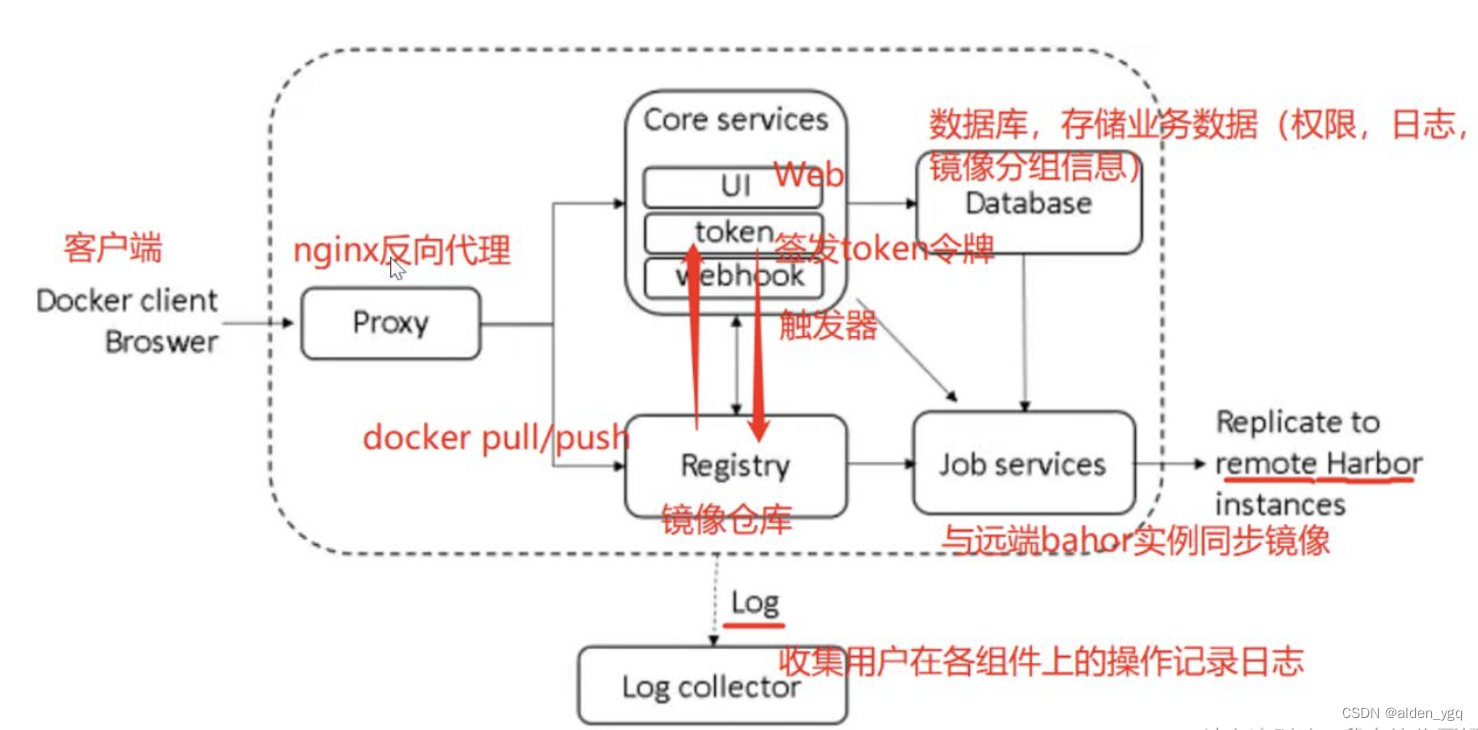
Kubernetes实战(四)-部署docker harbor私有仓库
1 Docker原生私有仓库Registry 1.1 原生私有仓库Registry概述 Docker的仓库主要分两类: 私有仓库公有仓库 共有仓库只要在官方注册用户,登录即可使用。但对于仓库的使用,企业还是会有自己的专属镜像,所以私有库的搭建也是很有…...

gte-base-zh中文Embedding工业化:CI/CD流水线实现模型版本灰度发布
gte-base-zh中文Embedding工业化:CI/CD流水线实现模型版本灰度发布 1. 项目背景与价值 在人工智能工程化落地的过程中,模型部署和版本管理一直是技术团队面临的挑战。特别是对于文本嵌入模型如gte-base-zh,如何在生产环境中实现平滑的版本升…...

大整数乘法运算
// // Created by Administrator on 2026/3/28. // #include <stdio.h> #include <stdlib.h> #include <string.h>#define MAXSIZE 1000 // 大整数支持的最大位数// 大整数结构体定义(与教材完全一致) typedef struct {int digits[MA…...

别再手动传文件了!用MinIO Java SDK的预签名URL功能,5分钟搞定安全文件分享
别再手动传文件了!用MinIO Java SDK的预签名URL功能,5分钟搞定安全文件分享 上周团队新来的架构师老张给我看了一个令人后怕的日志:某个内部系统的文件下载接口在24小时内被调用了17万次,而实际业务需求只有不到200次。调查发现是…...

OpenClaw节日应用:GLM-4.7-Flash驱动春节祝福邮件批量定制与发送
OpenClaw节日应用:GLM-4.7-Flash驱动春节祝福邮件批量定制与发送 1. 为什么需要自动化节日邮件? 每年春节前,我都会陷入同样的困境——需要给200多位合作伙伴发送祝福邮件。手动操作意味着:反复复制粘贴内容、检查收件人姓名、调…...

从潍坊一中赛题看算法竞赛中的数据类型陷阱与优化策略
1. 数据类型陷阱:从潍坊一中T1赛题看数值溢出问题 第一次参加算法竞赛的同学,90%都会在数据类型上栽跟头。就拿潍坊一中T1"揽月湖"这道题来说,表面是简单的数学表达式计算,实则是数据类型选择的经典案例。题目要求计算3…...

跨平台开源工具OptiScaler:释放显卡潜能的性能优化指南
跨平台开源工具OptiScaler:释放显卡潜能的性能优化指南 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler 你是否曾因显卡…...

【实战指南】彻底解决conda环境变量配置错误:从报错分析到.bashrc修复
1. 遇到conda环境变量报错怎么办? 刚装完Anaconda/Miniconda,满心欢喜准备大展身手,结果终端里输入conda却蹦出一行刺眼的红色报错:"bash: /opt/conda/bin/conda: No such file or directory"。这种场景我见过太多次了&…...

可视化拖拽组件库终极指南:响应式设计与适配方案完整解析
可视化拖拽组件库终极指南:响应式设计与适配方案完整解析 【免费下载链接】visual-drag-demo 一个低代码(可视化拖拽)教学项目 项目地址: https://gitcode.com/gh_mirrors/vi/visual-drag-demo 可视化拖拽组件库是现代低代码开发平台的…...

如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南
如何一站式管理Mac周边所有设备的电池电量:AirBattery终极指南 【免费下载链接】AirBattery Get the battery level of all your devices on your Mac and put them on the Dock / Status Bar / Widget! && 在Mac上获取你所有设备的电量信息并显示在Dock / …...

Rockchip Android 12编译踩坑记:手把手教你修改BoardConfig.mk生成userdata.img
Rockchip Android 12编译实战:从BoardConfig.mk修改到userdata.img生成的避坑指南 第一次在Rockchip平台上编译Android 12系统时,我遇到了一个令人抓狂的问题——编译过程看似顺利,但生成的固件烧写到设备后,系统始终无法正常启动…...