【C++】stack | queue | priority_queue | deque
一、stack栈
介绍
1.栈是一种特殊的线性表,其元素遵循“后进先出”的原则,即仅允许在在表的一端进行插入、删除操作,这一模式被称为“后进先出”或LIFO(last in fisrt out)。

2.从底层实现来看,stack是作为容器适配器被实现的,什么是容器适配器?我们来解释一下先。
先来看看我们身边的适配器。比方说,你有注意到笔记本电脑的充电器吗?
其实,笔记本的充电器就是一个适配器。适配器要做的就是电压的转换。一般来说,电脑的电池电压为14V左右,而标准电压为220V,要想给电脑充电,这就需要对标准电压进行转换,这就是适配器发挥的作用,适配就是转换的意思。

适配器是一种设计模式,该模式将一个类的接口转换为用户希望的另一个类的接口,你可以认为适配器是一种转换器。
容器适配器,能让程序员选择一种合适的底层数据结构。如stack,之前我们写c语言时,要用到栈的数据结构时,是不是得还先模拟一个栈出来?
那现在就不用这么麻烦了,要用到栈和队列的地方,直接用就行。

3.stack的底层容器可以是 任何容器类模板 or 其他特定的容器类。
这些容器类应该支持以下操作:
empty:判空操作
back:获取尾部元素操作
push_back:尾部插入元素操作
pop_back:尾部删除元素操作
栈的底层实现(简易版):
可以看到,栈的这些方法都是直接复用容器的方法,体现了代码复用的思想。

这里的Container就是容器类,它可以是vector、deque、list,也可以省略不传。若省略,那默认情况下是deque类。
使用
使用时要包<stack>头文件。

栈提供的方法有:判空、取大小、取栈顶数据、压栈(插入)、出栈(删除)、交换 还有emplace安放。
这里对其中几点方法做个说明:
1.构造函数:
stack<Type, Container> (<数据类型,容器类型>) stackName;数据类型一定要有,容器类型可以是vector、deque、list。(容器类型可省略,默认是deque)
2.在用top()前,得判断下栈是否为空。只有不为空的时候,才能调用top(),不然会发生段错误。
这是因为,在栈为空时,stack 的top函数返回的是超尾-1,而不是NULL。
3.和上面的top一样,在调用pop函数前,也要确保栈中至少有一个元素。
如果栈为空,调用pop会抛出EmptyStackException异常。
4.关于emplace,意为“安放”,就是说,构造一个新的元素放入栈顶。emplace和push很像,这里做一下区分。
push的话,得是你先构造好对象,然后push插进栈里;emplace则是主动帮你调用构造函数,构造出对象,然后插进栈里。
示例:
#include<iostream>
#include<stack>
using namespace std;
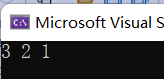
int main() {stack<int> st;st.push(1);st.push(2);st.push(3);
while (!st.empty()) {cout << st.top() << " ";st.pop();}cout << endl;return 0;
}
从底层来看,Container是一个模板,你传数组or链表都可以。
来看看它是怎么适配的:

二、queue队列
介绍
1.队列是一种特殊的线性表,它只能在队尾插入数据,队头出数据,这一模式被称为“先进先出”或FIFO(first in first out)。
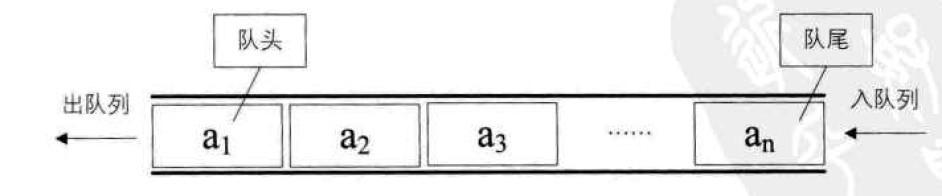
2.从底层实现来看,queue也是作为容器适配器被实现的。
展示下queue简易版的底层实现:

底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。
该底层容器应至少支持以下操作:
empty:检测队列是否为空
size:返回队列中有效元素的个数
front:返回队头元素的引用
back:返回队尾元素的引用
push_back:在队列尾部入队列
pop_front:在队列头部出队列
标准容器类deque和list满足了这些要求。也就是说,Container的位置可以传deque/ list过去,也可以省略不传。当省略不传时,那默认Container是deque。
(为什么vector不满足呢?因为vector没有头删。之前我们说过,vector嫌头删效率低就没实现)
使用
使用时要包头文件<queue>。

根据队列的特性,实现的方法有:判空、取大小、取队头、取队尾、(队尾)插入、(队头)删除、交换 和emplace安放。
几点说明:
1.构造函数:
queue<Type, Container> (<数据类型,容器类型>) queueName;在初始化时必须要有数据类型,容器可省略,省略时默认为deque 类型。
所以构造一个queue可以是这样两种情况:
queue<int> q; queue<int,list<int>> q;
示例:
#include<iostream>
#include<queue>
#include<vector>
using namespace std;
int main() {queue<int> q;q.push(1);q.push(2);q.push(3);
while (!q.empty()) {cout << q.front()<<" ";q.pop();}cout << endl;return 0;
}
这张图说明了,为什么deque是容器适配器:

三、priority_queue优先级队列
介绍
1.优先级队列是一种特殊的队列结构,它队列中的顺序并非插入的顺序,而是按权重来排序。
它给每个元素加上了优先级,每次出队的元素是队列中优先级最高的那个元素。

注:不是越大的元素,优先级就越高。
那优先级是如何评定的呢?其实,优先级队列在创建伊始,它的优先级就已经定好了,默认为降序。
那要如何排升序呢?一会会在仿函数那说到。
2.优先级队列 底层被实现为容器适配器。
底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。
容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
容器类vector和deque满足这些需求。如果容器类被省略不写,那默认使用vector。
3.需要支持随机访问迭代器,以便始终在内部保持堆结构。
priority_queue是用堆实现的,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。
注:默认情况下priority_queue是大堆。
使用
使用时要包头文件<queue>。

注:取顶端数据不是用front了!是用top。
示例:
#include<iostream>
#include<queue>
using namespace std;
int main() {priority_queue<int> q;q.push(4);q.push(12);q.push(3);
while (!q.empty()) {cout << q.top()<<" ";q.pop();}cout << endl;return 0;
}
模拟实现
priority_queue具有队列的所有特性,只是在此基础上又在内部加入了排序。它的底层原理是用堆实现的。
现在我们来模拟实现一下它的简易版,这样能更好地理解它的底层原理。
➡️复用代码
先把top、empty这种,通过复用代码而实现的 函数给写了:
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace jzy
{template<class T,class Container = vector<T>> //T是优先级队列中的 数据存储类型class priority_queue //Container是优先级队列中的数据结构{public:void push(const T& val) {}void pop() {}T top() {return _con.front(); //直接复用容器的方法}bool empty() {return _con.empty();}size_t size() {return _con.size();}
private:T _val;Container _con;};
}➡️push
push的实现:(大根堆)先尾插再向上调整。
void AdjustUp(Container& _con) {int child = _con.size()-1;int parent = (child - 1) / 2;
while (child > 0){if (_con[child] > _con[parent]) {swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}
}
void push(const T& val) {_con.push_back(val);AdjustUp(_con);
}➡️pop
pop的实现:先把首尾交换,让优先级最高的元素来到队尾,以便尾删。再向下调整。
void AdjustDown(Container& _con) {int parent = 0;int child = 2 * parent + 1;
while (child < _con.size()) {if (child + 1 < _con.size() && _con[child + 1] > _con[child]) {child++;}
if(_con[parent] <_con[child]) {swap(_con[parent], _con[child]);parent = child;child = 2 * parent + 1;}else {break;}}
}
void pop() {swap(_con.front(), _con[_con.size()-1]);_con.pop_back();AdjustDown(_con);
}➡️如何排降序
目前排的是升序,那要想排降序,要怎么办呢?
我倒是有个很朴素的办法:每次插入元素,向上调整时,我把小的往上调,不就行了吗?
其实就只要改个符号:
void AdjustUp(Container& _con) {int child = _con.size()-1;int parent = (child - 1) / 2;
while (child > 0){if (_con[child] < _con[parent]) { //这里原本是>,现在给改成<。越小越往上调swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}
}但是,这种方法并不好。我想排升序,要把符号改成>;想排降序,又要改回<,麻烦。
能不能用泛型解决呢?
其实在STL库里,就是用泛型解决的,我们来学习一下。
STL里,priority_queue有3个模板参数:
template <class T, class Container = vector<T>, class Compare = less<typename Container::value_type>>第三个模板参数Compare,定义了比较的方式。就是说,我们通过定义Compare类,来制定比较的规则。
不过,要想理解参数Compare,我们得先学习一个知识点:仿函数。
仿函数
仿函数(functor)不是函数,它描述的是对象,只不过这个对象重载了operator(),所以它使用起来像函数一样。
比方说,你定义了一个A类,用A实例化出对象a。此时a是一个普通的对象。
但当你在A里面重载了operator()(即函数调用运算符),那a就是仿函数,就可以这样用:
class A
{……int operator() (int x,int y){return x+y;}
};
int mian(){A a;cout<<a(1,2); //A实例化出的对象a,就可以像函数一样使用,a就叫仿函数return 0;
}关于():
我一开始大为不解,怎么圆括号()也能重载?
没错!()叫做”函数调用运算符“,我们在调用函数时,往往要传参,此时就用到这个运算符。
所以说,要想让对象成为仿函数,只需要在它的类里面重载operator()。
用仿函数实现升降序
先实现两个类:Greater、Less,分别用于定义升序、降序(这俩类实现为模板)。
然后在priority_queue类中增加一个模板参数compare,此参数用于接收 比较方式 的类型(是升序,还是降序)。
compare默认为降序。当我们想要升序,那就在传参时,实例化出Greator类型的对象,传过去即可。
//先实现Less和Greater两个类,来定义比大小的规则
template<class T>
struct Less //less意为越来越小,即降序
{bool operator() (const T& x, const T& y) {return x > y;}
};
template<class T>
struct Greater //升序
{bool operator() (const T& x, const T& y) {return x < y;}
};
template<class T,class Container = vector<T>,class Compare=Less<T>> //增加模板参数,默认为降序
class priority_queue
{Compare com;
public:void AdjustUp(Container& _con) {int child = _con.size()-1;int parent = (child - 1) / 2;
while (child > 0){if (com(_con[child],_con[parent])) {swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}}void AdjustDown(Container& _con) {Compare com;int parent = 0;int child = 2 * parent + 1;
while (child < _con.size()) {if (child + 1 < _con.size() && com(_con[child+1],_con[child])) { child++;}
if(com(_con[child], _con[parent])) {swap(_con[parent], _con[child]);parent = child;child = 2 * parent + 1;}else {break;}}}void push(const T& val) {_con.push_back(val);AdjustUp(_con);}void pop() {swap(_con.front(), _con[_con.size()-1]);_con.pop_back();AdjustDown(_con);}……
};注:因为我们展开了STL库,所以在命名Less/Greater时,注意不要写成less/greater,不然就和库里的重名了,编译器就就晕了 不知道用哪个。
测试:排升序
#include"priority_queue.h"
using namespace jzy;
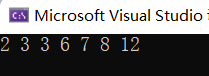
int main() {priority_queue<int,vector<int>,Greater<int>> pq;pq.push(7);pq.push(3);pq.push(8);pq.push(2);pq.push(12);pq.push(6);pq.push(3);
while (!pq.empty()) {cout << pq.top() << " ";pq.pop();}return 0;
}
模拟实现的总代码
priority_queue.h:
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace jzy
{template<class T>struct Less //less意为越来越小,即降序{bool operator() (const T& x, const T& y) {return x > y;}};
template<class T>struct Greater //升序{bool operator() (const T& x, const T& y) {return x < y;}};
template<class T,class Container = vector<T>,class Compare=Less<T>>class priority_queue{Compare com;public:void AdjustUp(Container& _con) {int child = _con.size()-1;int parent = (child - 1) / 2;
while (child > 0){if (com(_con[child],_con[parent])) {swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else {break;}}}void AdjustDown(Container& _con) {Compare com;int parent = 0;int child = 2 * parent + 1;
while (child < _con.size()) {if (child + 1 < _con.size() && com(_con[child+1],_con[child])) { child++;}
if(com(_con[child], _con[parent])) {swap(_con[parent], _con[child]);parent = child;child = 2 * parent + 1;}else {break;}}}void push(const T& val) {_con.push_back(val);AdjustUp(_con);}void pop() {swap(_con.front(), _con[_con.size()-1]);_con.pop_back();AdjustDown(_con);}T top() {return _con.front();}bool empty() {return _con.empty();}size_t size() {return _con.size();}
private:T _val;Container _con;};
}四、deque双端队列
(这个容器了解即可,这个容器很少用)
介绍
1.deque是“double-ended queue”的缩写。
虽然叫双端队列,但它和队列没啥关系。deque是一种双开口的"连续"空间的数据结构。双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1)。

deque支持随机访问,也支持任意位置的插入、删除。似乎,deque结合了vector和list的优点。
但,deque真的是完美的吗?
并不是!deque随机访问的效率比较低。至于为什么,那先让我们了解一下它的底层实现。
底层实现
和vector不同,deque的底层并不是 真正意义上的连续的空间,而是由一段段连续的小空间拼接而成的,这些小空间不一定是连续的,可能是位于内存的不同区域。如图:

这里的map,并不是STL里的map容器。而是数组,数组的每个元素都是 指向另一块连续空间(缓冲区buffer)的 指针。我们插入的元素,实际上是存进buffer里的。
可见,deque对空间利用率很高,几乎没什么空间的浪费。
➡️如何进行扩容呢?
当一个buffer存满了,要尾插,此时不会给当前buffer扩容(因为它是大小固定的),而是再开一个buffer空间,尾插的内容存进新的buffer里。指针数组的下一个元素指向新的buffer。头插同理。下图可以帮助我们理解:

可见,头插、尾插不需要挪动数据,效率自然高。
如果map满了,那就再开一个更大的map,如何把数据拷到新的map里。
➡️关于deque的迭代器,它的原理很复杂,由四个指针组成。node指向中控区的指针数组,first和node分别指向一段空间的开始和结束,cur指向访问到的位置。如果访问的元素不在当前空间,cur就等于下一个空间的first,再继续访问。
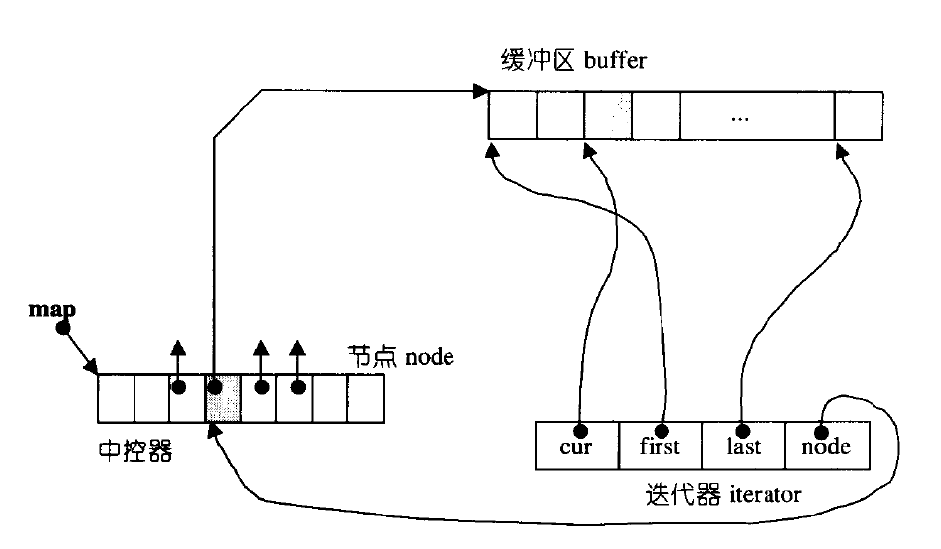
➡️当需要随机访问时,deque得先完整复制到一个vector上,如何vector排序后,再复制deque。这就导致了deque的随机访问效率较vector更低。
关于deque的小结
优势:1.相比vector,deque的头插、头删不需要挪动数据,而是直接开新buffer插入,效率很高;
在扩容时,也无需开新空间、拷数据,而是直接开个新buffer,效率高。
2.相比list,deque的底层是连续的存指针的map数组,空间利用率比较高,不需要存储额外字段。况且,deque还支持随机访问,虽然效率不高。
劣势:1.不适合遍历。
因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下。
而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
2.中间插入、删除的效率并不高。(因为下标需要经过计算,并且要挪动元素)
相关文章:
【C++】stack | queue | priority_queue | deque
一、stack栈 介绍 1.栈是一种特殊的线性表,其元素遵循“后进先出”的原则,即仅允许在在表的一端进行插入、删除操作,这一模式被称为“后进先出”或LIFO(last in fisrt out)。 2.从底层实现来看,stack是作…...

华为gre带验证key案例
配置FW_A。 a.配置接口的IP地址,并将接口加入安全区域。 system-view [sysname] sysname FW_A [FW_A] interface GigabitEthernet 1/0/1 [FW_A-GigabitEthernet1/0/1] ip address 1.1.1.1 24 [FW_A-GigabitEthernet1/0/1] quit [FW_A] interface GigabitEthernet 1/…...

Java算法(三): 判断两个数组是否为相等 → (要求:长度、顺序、元素)相等
Java算法(三) 需求: 1. 定义一个方法,用于比较两个数组是否相同2. 需求:长度,内容,顺序完全相同package com.liujintao.compare;public class SameArray {public static void main (String[] a…...
)
基于STM32的设计智慧超市管理系统(带收银系统+物联网环境监测)
一、前言 基于STM32+OneNet设计的智慧超市管理系统(2023升级版) 1.1 项目背景 随着IoT技术的不断发展,智能无人超市也越来越受到人们的关注。智能无人超市是指在无人值守的情况下,通过物联网、大数据等技术手段实现自助选购、结算和配送的新型商场。当前设计了一种基于STM32…...

深入浅出理解ResNet网络模型+PyTorch实现
温故而知新,可以为师矣! 一、参考资料 原始论文:Identity Mappings in Deep Residual Networks 原论文地址:Deep Residual Learning for Image Recognition ResNet详解PyTorch实现 PyTorch官方实现ResNet 【pytorch】ResNet18、…...
【C++】万字一文全解【继承】及其特性__[剖析底层化繁为简](20)
前言 大家好吖,欢迎来到 YY 滴C系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! 目录 一.继承&复用&组合的区别1&…...
微信小程序之自定义组件开发
1、前言 从小程序基础库版本 1.6.3 开始,小程序支持简洁的组件化编程。所有自定义组件相关特性都需要基础库版本 1.6.3 或更高。开发者可以将页面内的功能模块抽象成自定义组件,以便在不同的页面中重复使用;也可以将复杂的页面拆分成多个低耦…...

MCU系统的调试技巧
MCU系统的调试技巧对于确保系统稳定性和性能至关重要。无论是在嵌入式系统开发的初期阶段还是在产品维护和优化的过程中,有效的调试技巧可以帮助开发人员快速发现和解决问题,本文将讨论一些MCU系统调试的技巧。 首先,使用调试工具是非常重要…...
【机器学习基础】机器学习概述
目录 前言 一、机器学习概念 二、机器学习分类 三、机器学习术语 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 &#x…...

Python Selenium 执行 JavaScript
简介 Selenium是一个用于自动化浏览器操作的工具,可以模拟人工操作,执行各种浏览器操作,包括点击、输入文字、提交表单等。而JavaScript是一种常用的脚本语言,用于在网页上添加交互性和动态性。在Python中使用Selenium执行JavaSc…...

HTML的表单标签和无语义标签的讲解
HTML的表单标签 表单是让用户输入信息的重要途径, 分成两个部分: 表单域: 包含表单元素的区域. 重点是 form 标签. 表单控件: 输入框, 提交按钮等. 重点是 input 标签 form 标签 使用form进行前后端交互.把页面上,用户进行的操作/输入提交到服务器上 input 标签 有很多形态,能…...

8.spark自适应查询-AQE之自适应调整Shuffle分区数量
目录 概述主要功能自适应调整Shuffle分区数量原理默认环境配置修改配置 结束 概述 自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。…...

【Java 进阶篇】Java Filter 快速入门
欢迎来到这篇有关 Java Filter 的快速入门指南!如果你是一名 Java 开发者或者正在学习 Java Web 开发,Filter 是一个强大的工具,可以帮助你管理和控制 Web 应用程序中的请求和响应。本文将向你解释 Filter 的基本概念,如何创建和配…...
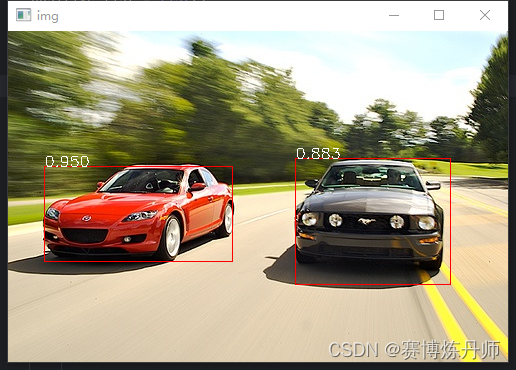
Pytorch R-CNN目标检测-汽车car
概述 目标检测(Object Detection)就是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。其准确性和实时性是整个系统的一项重要能力。 R-CNN的全称是Region-CNN(区域卷积神经…...

【PG】PostgreSQL13主从流复制部署(详细可用)
目录 版本 部署主从注意点 1 主库上创建复制用户 2 主库上修改pg_hba.conf文件 3 修改文件后重新加载配置使其生效 4 主库上修改配置文件 5 重启主库pg使参数生效 6 部署从库 7 备份主库数据至从库 停止从库 备份从库的数据库目录 新建数据库数据目录data 创建和…...

学习pytorch15 优化器
优化器 官网如何构造一个优化器优化器的step方法coderunning log出现下面问题如何做反向优化? 官网 https://pytorch.org/docs/stable/optim.html 提问:优化器是什么 要优化什么 优化能干什么 优化是为了解决什么问题 优化模型参数 如何构造一个优化器…...

[算法日志]图论刷题 沉岛思想的运用
[算法日志]图论刷题: 沉岛思想的运用 leetcode 695 岛屿最大面积 给你一个大小为 m x n 的二进制矩阵 grid . 岛屿 是由一些相邻的 1 (代表土地) 构成的组合, 这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻. 你可以假设 grid 的四个边缘都被 0(…...

Web服务器的搭建
网站需求: 1.基于域名www.openlab.com可以访问网站内容为 welcome to openlab!!! 2.给该公司创建三个网站目录分别显示学生信息,教学资料和缴费网站,基于www.openlab.com/student 网站访问学生信息,www.openlab.com/data网站访问教…...

如何使用 GTX750 或 1050 显卡安装 CUDA11+
前言 由于兼容性问题,使得我们若想用较新版本的 PyTorch,通过 GPU 方式训练模型,也得更换较新版本得 CUDA 工具包。然而 CUDA 的版本又与电脑显卡的驱动程序版本关联,如果是低版本的显卡驱动程序安装 CUDA11 及以上肯定会失败。 比…...

跟着森老师学React Hooks(1)——使用Vite构建React项目
Vite是一款构建工具,对ts有很好的支持,最近也是在前端越来越流行。 以往的React项目的初始化方式大多是通过脚手架create-react-app(本质是webpack),其实比起Vite来构建,启动会慢一些。 所以这次跟着B站的一个教程,使用…...

PCB布局翻车实录:一个开尔文连接没做好,我的电流检测误差直接飙升2.5%
PCB布局中的开尔文连接陷阱:如何避免电流检测误差飙升2.5% 在硬件电路设计中,电流检测是一个看似简单却暗藏玄机的环节。许多工程师在调试电路时都曾遇到过这样的困惑:明明选用了高精度的电流感应放大器和低阻值分流电阻,实测数据…...
)
信息学奥赛刷题必备:OpenJudge NOI 2.5 156题LETTERS的两种DFS解法详解(附C++代码)
信息学奥赛刷题进阶:LETTERS题目的DFS双解与竞赛思维突破 在信息学竞赛的征途中,DFS(深度优先搜索)算法就像一把瑞士军刀,能解决各类路径搜索与状态遍历问题。OpenJudge NOI 2.5 156题LETTERS正是检验这把"军刀&…...

LightChat本地AI助手部署指南:架构解析与Ollama集成实战
1. 项目概述与核心价值 最近在折腾一些本地化的AI应用,发现了一个挺有意思的开源项目,叫LightChat。简单来说,它就是一个让你能在自己的电脑上,用类似ChatGPT的对话界面,去调用各种开源大语言模型(LLM&…...

这个USB Hub不太正常:它能“看见”设备内部状态 ——解读 USB Insight Hub
你桌上肯定有一个USB Hub。甚至可能不止一个。但你有没有遇到过这些问题:串口设备 COM 号乱跳不知道哪个设备对应哪个端口板子死机,只能反复拔插功耗异常,却完全没法定位如果你做过嵌入式开发,这些几乎是日常。而这个项目的核心目…...

Elasticsearch实战:客户端连接池配置与性能优化,彻底解决连接耗尽问题
Elasticsearch实战:客户端连接池配置与性能优化,彻底解决连接耗尽问题前言一、为什么 ES 客户端需要连接池?1.1 连接池的作用1.2 ES 连接池核心架构流程图二、ES 客户端连接池核心组件2.1 关键连接参数2.2 核心参数关系三、连接池默认配置&am…...

【基于 macOS 虚拟机的 iMessage 批量消息处理技术实践】
一、研究背景与技术意义iMessage 作为苹果生态内置的原生通讯服务,依托系统底层优势,具备端到端加密、无运营商拦截、原生展示等特性,常用于企业内部事务提醒、授权用户服务告知等合规场景。在技术研究过程中,手动单条发送消息效率…...

文本数据净化与脱敏实战:构建安全高效的数据预处理流水线
1. 项目概述与核心价值最近在整理个人知识库和开源项目时,发现一个非常普遍但棘手的问题:如何安全、高效地处理来自不同渠道的文本数据,特别是那些可能包含用户隐私、敏感信息或格式混乱的内容。无论是从网页爬取的数据、用户提交的表单&…...

终极cocur/slugify高级配置指南:掌握正则表达式、大小写控制和分隔符定制技巧
终极cocur/slugify高级配置指南:掌握正则表达式、大小写控制和分隔符定制技巧 【免费下载链接】slugify Converts a string to a slug. Includes integrations for Symfony, Silex, Laravel, Zend Framework 2, Twig, Nette and Latte. 项目地址: https://gitcode…...

JavaScript多智能体AI框架KaibanJS开发指南
1. 项目概述:JavaScript生态中的多智能体AI框架作为一名长期工作在JavaScript和AI交叉领域的开发者,我见证了近年来AI技术在前端和后端应用中的爆发式增长。然而,一个明显的痛点始终存在:绝大多数先进的AI框架(如LangC…...

vSAN维护模式选‘无操作’就万事大吉?详解关机重启前必须做的5项关键检查
vSAN维护模式选‘无操作’就万事大吉?详解关机重启前必须做的5项关键检查 在虚拟化运维领域,vSAN集群的关机重启操作看似简单,实则暗藏玄机。许多工程师习惯性地选择维护模式中的"无操作"选项,认为这样可以省去数据迁移…...