万字解析 Linux 中 CPU 利用率是如何算出来的?
在线上服务器观察线上服务运行状态的时候,绝大多数人都是喜欢先用 top 命令看看当前系统的整体 cpu 利用率。例如,随手拿来的一台机器,top 命令显示的利用率信息如下

这个输出结果说简单也简单,说复杂也不是那么容易就能全部搞明白的。例如:
问题 1:top 输出的利用率信息是如何计算出来的,它精确吗?
问题 2:ni 这一列是 nice,它输出的是 cpu 在处理啥时的开销?
问题 3:wa 代表的是 io wait,那么这段时间中 cpu 到底是忙碌还是空闲?
今天我们对 cpu 利用率统计进行深入的学习。通过今天的学习,你不但能了解 cpu 利用率统计实现细节,还能 nice、io wait 等指标有更深入的理解。
区别于以往的文章,今天我们不直接进入 Linux 实现,而是先从自己的思考开始!
一、先思考一下
抛开 Linux 的实现先不谈,如果有如下需求,有一个四核服务器,上面跑了四个进程。

让你来设计计算整个系统 cpu 利用率的这个需求,支持像 top 命令这样的输出,满足以下要求:
- cpu 使用率要尽可能地准确
- 要能地体现秒级瞬时 cpu 状态
可以先停下来阅读思考几分钟。

好,思考结束。经过思考你会发现,这个看起来很简单的需求,实际还是有点小复杂的。
其中一个思路是把所有进程的执行时间都加起来,然后再除以系统执行总时间*4。

这个思路是没问题的,用这种方法统计很长一段时间内的 cpu 利用率是可以的,统计也足够的准确。
但只要用过 top 你就知道 top 输出的 cpu 利用率并不是长时间不变的,而是默认 3 秒为单位会动态更新一下(这个时间间隔可以使用 -d 设置)。我们的这个方案体现总利用率可以,体现这种瞬时的状态就难办了。你可能会想到那我也 3 秒算一次不就行了?但这个 3 秒的时间从哪个点开始呢。粒度很不好控制。
上一个思路问题核心就是如何解决瞬时问题。提到瞬时状态,你可能就又来思路了。那我就用瞬时采样去看,看看当前有几个核在忙。四个核中如果有两个核在忙,那利用率就是 50%。
这个思路思考的方向也是正确的,但是问题有两个:
- 你算出的数字都是 25% 的整数倍
- 这个瞬时值会导致 cpu 使用率显示的剧烈震荡。
比如下图:

在 t1 的瞬时状态看来,系统的 cpu 利用率毫无疑问就是 100%,但在 t2 时间看来,使用率又变成 0% 了。思路方向是对的,但显然这种粗暴的计算无法像 top 命令一样优雅地工作。
我们再改进一下它,把上面两个思路结合起来,可能就能解决我们的问题了。在采样上,我们把周期定的细一些,但在计算上我们把周期定的粗一些。
我们引入采用周期的概念,定时比如每 1 毫秒采样一次。如果采样的瞬时,cpu 在运行,就将这 1 ms 记录为使用。这时会得出一个瞬时的 cpu 使用率,把它都存起来。

在统计 3 秒内的 cpu 使用率的时候,比如上图中的 t1 和 t2 这段时间范围。那就把这段时间内的所有瞬时值全加一下,取个平均值。这样就能解决上面的问题了,统计相对准确,避免了瞬时值剧烈震荡且粒度过粗(只能以 25 %为单位变化)的问题了。
可能有同学会问了,假如 cpu 在两次采样中间发生变化了呢,如下图这种情况。

在当前采样点到来的时候,进程 A 其实刚执行完,有一点点时间没有既没被上一个采样点统计到,本次也统计不到。对于进程 B,其实只开始了一小段时间,把 1 ms 全记上似乎有点多记了。
确实会存在这个问题,但因为我们的采样是 1 ms 一次,而我们实际查看使用的时候最少也有是秒级别地用,会包括有成千上万个采样点的信息,所以这种误差并不会影响我们对全局的把握。
事实上,Linux 也就是这样来统计系统 cpu 利用率的。虽然可能会有误差,但作为一项统计数据使用已经是足够了的。在实现上,Linux 是将所有的瞬时值都累加到某一个数据上的,而不是真的存了很多份的瞬时数据。
接下来就让我们进入 Linux 来查看它对系统 cpu 利用率统计的具体实现。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
二、top 命令使用数据在哪儿
上一节我们说的 Linux 在实现上是将瞬时值都累加到某一个数据上的,这个值是内核通过 /proc/stat 伪文件来对用户态暴露。Linux 在计算系统 cpu 利用率的时候用的就是它。
整体上看,top 命令工作的内部细节如下图所示。

- top 命令访问 /proc/stat 获取各项 cpu 利用率使用值
- 内核调用 stat_open 函数来处理对 /proc/stat 的访问
- 内核访问的数据来源于 kernel_cpustat 数组,并汇总
- 打印输出给用户态
接下来我们把每一步都展开来详细看看。
通过使用 strace 跟踪 top 命令的各种系统调用,可以看的到它对该文件的调用。
# strace top
...
openat(AT_FDCWD, "/proc/stat", O_RDONLY) = 4
openat(AT_FDCWD, "/proc/2351514/stat", O_RDONLY) = 8
openat(AT_FDCWD, "/proc/2393539/stat", O_RDONLY) = 8
...除了 /proc/stat 外,还有各个进程细分的 /proc/{pid}/stat,是用来计算各个进程的 cpu 利用率时使用的。
内核为各个伪文件都定义了处理函数,/proc/stat 文件的处理方法是 proc_stat_operations。
//file:fs/proc/stat.c
static int __init proc_stat_init(void)
{proc_create("stat", 0, NULL, &proc_stat_operations);return 0;
}static const struct file_operations proc_stat_operations = {.open = stat_open,...
};proc_stat_operations 中包含了该文件时对应的操作方法。当打开 /proc/stat 文件的时候,stat_open 就会被调用到。stat_open 依次调用 single_open_size,show_stat 来输出数据内容。我们来看看它的代码:
//file:fs/proc/stat.c
static int show_stat(struct seq_file *p, void *v)
{u64 user, nice, system, idle, iowait, irq, softirq, steal;for_each_possible_cpu(i) {struct kernel_cpustat *kcs = &kcpustat_cpu(i);user += kcs->cpustat[CPUTIME_USER];nice += kcs->cpustat[CPUTIME_NICE];system += kcs->cpustat[CPUTIME_SYSTEM];idle += get_idle_time(kcs, i);iowait += get_iowait_time(kcs, i);irq += kcs->cpustat[CPUTIME_IRQ];softirq += kcs->cpustat[CPUTIME_SOFTIRQ];...}//转换成节拍数并打印出来seq_put_decimal_ull(p, "cpu ", nsec_to_clock_t(user));seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice));seq_put_decimal_ull(p, " ", nsec_to_clock_t(system));seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle));seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait));seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq));seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq));...
}在上面的代码中,for_each_possible_cpu 是在遍历存储着 cpu 使用率数据的 kcpustat_cpu 变量。该变量是一个 percpu 变量,它为每一个逻辑核都准备了一个数组元素。里面存储着当前核所对应各种事件,包括 user、nice、system、idel、iowait、irq、softirq 等。
在这个循环中,将每一个核的每种使用率都加起来。最后通过 seq_put_decimal_ull 将这些数据输出出来。

注意,在内核中实际每个时间记录的是纳秒数,但是在输出的时候统一都转化成了节拍单位。至于节拍单位多长,下一节我们介绍。总之, /proc/stat 的输出是从 kernel_cpustat 这个 percpu 变量中读取出来的。
我们接着再看看这个变量中的数据是何时加进来的。
三、统计数据怎么来的
前面我们提到内核是以采样的方式来统计 cpu 使用率的。这个采样周期依赖的是 Linux 时间子系统中的定时器。
Linux 内核每隔固定周期会发出 timer interrupt (IRQ 0),这有点像乐谱中的节拍的概念。每隔一段时间,就打出一个拍子,Linux 就响应之并处理一些事情。

一个节拍的长度是多长时间,是通过 CONFIG_HZ 来定义的。它定义的方式是每一秒有几次 timer interrupts。不同的系统中这个节拍的大小可能不同,通常在 1 ms 到 10 ms 之间。可以在自己的 Linux config 文件中找到它的配置。
# grep ^CONFIG_HZ /boot/config-5.4.56.bsk.10-amd64
CONFIG_HZ=1000从上述结果中可以看出,我的机器的每秒要打出 1000 次节拍。也就是每 1 ms 一次。
每次当时间中断到来的时候,都会调用 update_process_times 来更新系统时间。更新后的时间都存储在我们前面提到的 percpu 变量 kcpustat_cpu 中。

我们来详细看下汇总过程 update_process_times 的源码,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
void update_process_times(int user_tick)
{struct task_struct *p = current;//进行时间累积处理account_process_tick(p, user_tick);...
}这个函数的参数 user_tick 值得是采样的瞬间是处于内核态还是用户态。接下来调用 account_process_tick。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick)
{cputime = TICK_NSEC;...if (user_tick)//3.1 统计用户态时间account_user_time(p, cputime);else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))//3.2 统计内核态时间account_system_time(p, HARDIRQ_OFFSET, cputime);else//3.3 统计空闲时间account_idle_time(cputime);
}在这个函数中,首先设置 cputime = TICK_NSEC, 一个 TICK_NSEC 的定义是一个节拍所占的纳秒数。接下来根据判断结果分别执行 account_user_time、account_system_time 和 account_idle_time 来统计用户态、内核态和空闲时间。
3.1 用户态时间统计
//file:kernel/sched/cputime.c
void account_user_time(struct task_struct *p, u64 cputime)
{//分两种种情况统计用户态 CPU 的使用情况int index;index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER;//将时间累积到 /proc/stat 中task_group_account_field(p, index, cputime);......
}account_user_time 函数主要分两种情况统计:
- 如果进程的 nice 值大于 0,那么将会增加到 CPU 统计结构的 nice 字段中。
- 如果进程的 nice 值小于等于 0,那么增加到 CPU 统计结构的 user 字段中。
看到这里,开篇的问题 2 就有答案了,其实用户态的时间不只是 user 字段,nice 也是。之所以要把 nice 分出来,是为了让 Linux 用户更一目了然地看到调过 nice 的进程所占的 cpu 周期有多少。
我们平时如果想要观察系统的用户态消耗的时间的话,应该是将 top 中输出的 user 和 nice 加起来一并考虑,而不是只看 user!
接着调用 task_group_account_field 来把时间加到前面我们用到的 kernel_cpustat 内核变量中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,u64 tmp)
{__this_cpu_add(kernel_cpustat.cpustat[index], tmp);...
}3.2 内核态时间统计
我们再来看内核态时间是如何统计的,找到 account_system_time 的代码。
//file:kernel/sched/cputime.c
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime)
{if (hardirq_count() - hardirq_offset)index = CPUTIME_IRQ;else if (in_serving_softirq())index = CPUTIME_SOFTIRQ;elseindex = CPUTIME_SYSTEM;account_system_index_time(p, cputime, index);
}内核态的时间主要分 3 种情况进行统计。
- 如果当前处于硬中断执行上下文, 那么统计到 irq 字段中
- 如果当前处于软中断执行上下文, 那么统计到 softirq 字段中
- 否则统计到 system 字段中
判断好要加到哪个统计项中后,依次调用 account_system_index_time、task_group_account_field 来将这段时间加到内核变量 kernel_cpustat 中
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,u64 tmp)
{ __this_cpu_add(kernel_cpustat.cpustat[index], tmp);
}3.3 空闲时间的累积
没错,在内核变量 kernel_cpustat 中不仅仅是统计了各种用户态、内核态的使用统计,空闲也一并统计起来了。
如果在采样的瞬间,cpu 既不在内核态也不在用户态的话,就将当前节拍的时间都累加到 idle 中。
//file:kernel/sched/cputime.c
void account_idle_time(u64 cputime)
{u64 *cpustat = kcpustat_this_cpu->cpustat;struct rq *rq = this_rq();if (atomic_read(&rq->nr_iowait) > 0)cpustat[CPUTIME_IOWAIT] += cputime;elsecpustat[CPUTIME_IDLE] += cputime;
}在 cpu 空闲的情况下,进一步判断当前是不是在等待 IO(例如磁盘 IO),如果是的话这段空闲时间会加到 iowait 中,否则就加到 idle 中。从这里,我们可以看到 iowait 其实是 cpu 的空闲时间,只不过是在等待 IO 完成而已。
看到这里,开篇问题 3 也有非常明确的答案了,io wait 其实是 cpu 在空闲状态的一项统计,只不过这种状态和 idle 的区别是 cpu 是因为等待 io 而空闲。
四、总结
本文深入分析了 Linux 统计系统 CPU 利用率的内部原理。全文的内容可以用如下一张图来汇总:

Linux 中的定时器会以某个固定节拍,比如 1 ms 一次采样各个 cpu 核的使用情况,然后将当前节拍的所有时间都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一项上。
top 命令是读取的 /proc/stat 中输出的 cpu 各项利用率数据,而这个数据在内核中的是根据 kernel_cpustat 来汇总并输出的。
回到开篇问题 1,top 输出的利用率信息是如何计算出来的,它精确吗?
/proc/stat 文件输出的是某个时间点的各个指标所占用的节拍数。如果想像 top 那样输出一个百分比,计算过程是分两个时间点 t1, t2 分别获取一下 stat 文件中的相关输出,然后经过个简单的算术运算便可以算出当前的 cpu 利用率。
我也提供了一个简单的 shell 代码,你可以把它下载下来,用它来实际查看一下你服务器的 cpu 利用率,我放到我的 github 上了。
Github 地址:https://github.com/yanfeizhang/coder-kung-fu/blob/main/tests/cpu/test06/cpu_stat.sh
再说是否精确。这个统计方法是采样的,只要是采样,肯定就不是百分之百精确。但由于我们查看 cpu 使用率的时候往往都是计算 1 秒甚至更长一段时间的使用情况,这其中会包含很多采样点,所以查看整体情况是问题不大的。
另外从本文,我们也学到了 top 中输出的 cpu 时间项目其实大致可以分为三类:
第一类: 用户态消耗时间,包括 user 和 nice。如果想看用户态的消耗,要将 user 和 nice 加起来看才对。
第二类: 内核态消耗时间,包括 irq、softirq 和 system。
第三类: 空闲时间,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空闲状态,只不过是在等 io 完成而已。如果只是想看 cpu 到底有多闲,应该把 io_wait 和 idle 加起来才对。

相关文章:
万字解析 Linux 中 CPU 利用率是如何算出来的?
在线上服务器观察线上服务运行状态的时候,绝大多数人都是喜欢先用 top 命令看看当前系统的整体 cpu 利用率。例如,随手拿来的一台机器,top 命令显示的利用率信息如下 这个输出结果说简单也简单,说复杂也不是那么容易就能全部搞明白…...
芯驰(E3-gateway)开发板环境搭建
1-Windows下环境配置 可以在Windows上使用命令行或者IAR IDE编译SSDK项目。Windows编译依赖的工具已经包含在 prebuilts/windows 目录中,包括编译器、Python和命令行工具。 1.1.1 CMD SSDK集成 msys 工具,可以在Windows命令行中完成SDK的配置、编译和…...
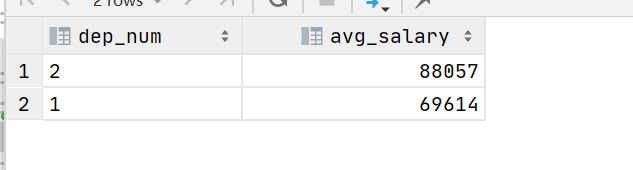
HiveSql一天一个小技巧:如何巧用分布函数percent_rank()求去掉最大最小值的平均薪水问题
0 问题描述参考链接(3条消息) HiveSql面试题12--如何分析去掉最大最小值的平均薪水(字节跳动)_莫叫石榴姐的博客-CSDN博客文中已经给出了三种解法,这里我们借助于此题,来研究如何用percent_rank()函数求解,简化解题思路…...

【python实现华为OD机试真题】优雅子数组【2023 Q1 | 200分】
题目描述 如果一个数组Q中出现次数最多的元素出现大于等于K次,被称为k-优雅数组,k也可以被称为优雅阈值只。 例如: 数组1,2, 3, 1、2, 3, 1,它是一个3-优雅数组,因为元素1出现次数大于等于3次, 数组[1,2, 3, 1, 2]就不是一一个3-优雅数组,因为其中出现次数最多的元素是1和…...

九种分布式ID解决方案
文章目录背景1、UUID2、数据库自增ID2.1、主键表2.2、ID自增步长设置3、号段模式4、Redis INCR5、雪花算法6、美团(Leaf)7、百度(Uidgenerator)8、滴滴(TinyID)总结比较背景 在复杂的分布式系统中,往往需要对大量的数据进行唯一标识,比如在对一个订单表…...

RocketMQ源码分析
RocketMQ源码深入剖析 1 RocketMQ介绍 RocketMQ 是阿里巴巴集团基于高可用分布式集群技术,自主研发的云正式商用的专业消息中间件,既可为分布式应用系统提供异步解耦和削峰填谷的能力,同时也具备互联网应用所需的海量消息堆积、高吞吐、可靠…...
第六天)
跟着我从零开始入门FPGA(一周入门系列)第六天
6、有限状态机状态机,只要C代码写过2年的人,估计无人不识君,稍微复杂的逻辑都可以借助状态机来简化问题。为了方便,我们使用前面用过的一个例子,来说明状态机的应用,也就是说我们前面已经有意无意的用过状态…...

2023最新JVM面试题汇总进大厂必备
JVM 面试题汇总 1.什么是 JVM?它有什么作用? 答:JVM 是 Java Virtual Machine(Java 虚拟机)的缩写,顾名思义它是一个虚 拟计算机,也是 Java 程序能够实现跨平台的基础。它的作用是加载 Java 程…...
Cocoa-presentViewController
presentViewController:animator: 将一个viewController以动画方式显示出来 当VCA模态的弹出了VCB,那么VCA就是presenting view controller,VCB就是presented view controller presentViewController 相较于addSubView 直接作为subView就是不会出现一…...

Vue Mixins
Vue Mixins 详解 Vue.js 是一个非常流行的 JavaScript 框架,它提供了一系列的工具来简化 Web 应用程序的开发。其中一个非常有用的工具就是 Mixins。 什么是 Mixins? Mixins 是一种 Vue.js 组件复用的方法,它允许您将一组组件选项合并到一…...

Django-版本信息介绍-版本选择
文章目录1.如何获取Django1.1.选项1:获取最新的正式版本1.2.选项2:获取4.2的beta版1.3.选项3:获取最新的开发版本2.得到之后3.支持版本4.选择版本1.如何获取Django Django在BSD许可下是开源的。我们建议使用最新版本的Python 3。支持Python 2.7的最新版本是Django 1.11 LTS。请…...
写给交互设计新手的信息架构全方位指南
目录什么是信息架构?通用方法日常工作可以关注的大神常用工具相关书籍什么是信息架构?信息架构是一个比众多其他领域更难定义的领域。内容策划由内容策划师来完成,交互设计由设计师来完成,而信息架构的完成与它们不同,…...

15、主从复制,gtid,并行复制,半同步复制,实操案例,常用命令,故障处理
主从复制,gtid,并行复制,半同步复制,实操案例,常用命令,故障处理 1.认识主从复制1.1 主从复制原理深入讲解1.2 主从复制相关参数1.3.主从复制架构部署1.4从库状态详解1.5 .过滤复制2 .gtid复制2.1 什么是GTID?2.2 GTID主从配置2.5 gtid维护2.4 GTID的特点2.3 工作原理2.4 g…...

【C语言】实现文件内容映射转移
有两个文件(QA,与QB)。 文件A是经过了字母映射加密的文本(将英文字母一一映射成了另一个), 文件B是字母映射的关系表(格式如A-c;B-R;…,其中前一个字母为加密前的),编写程…...
html css输入框获得焦点、失去焦点效果
input输入框获得焦点、失去焦点效果 废话shao shuo ! 直接看效果图,好吧! 效果图: code: <!DOCTYPE html> <html> <head><title></title><meta charset"utf-8" /><style type"text…...

Spark Streaming
第1章 SparkStreaming 概述1.1 Spark Streaming 是什么Spark 流使得构建可扩展的容错流应用程序变得更加容易。**Spark Streaming 用于流式数据的处理。**Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字…...

[kubernetes]-k8s通过psp限制nvidia-plugin插件的使用
导语: k8s通过psp限制nvidia-plugin插件的使用。刚开始接触psp 记录一下 后续投入生产测试了再完善。 通过apiserver开启psp 静态pod会自动更新 # PSP(Pod Security Policy) 在默认情况下并不会开启。通过将PodSecurityPolicy关键词添加到 --enbale-admission-plu…...
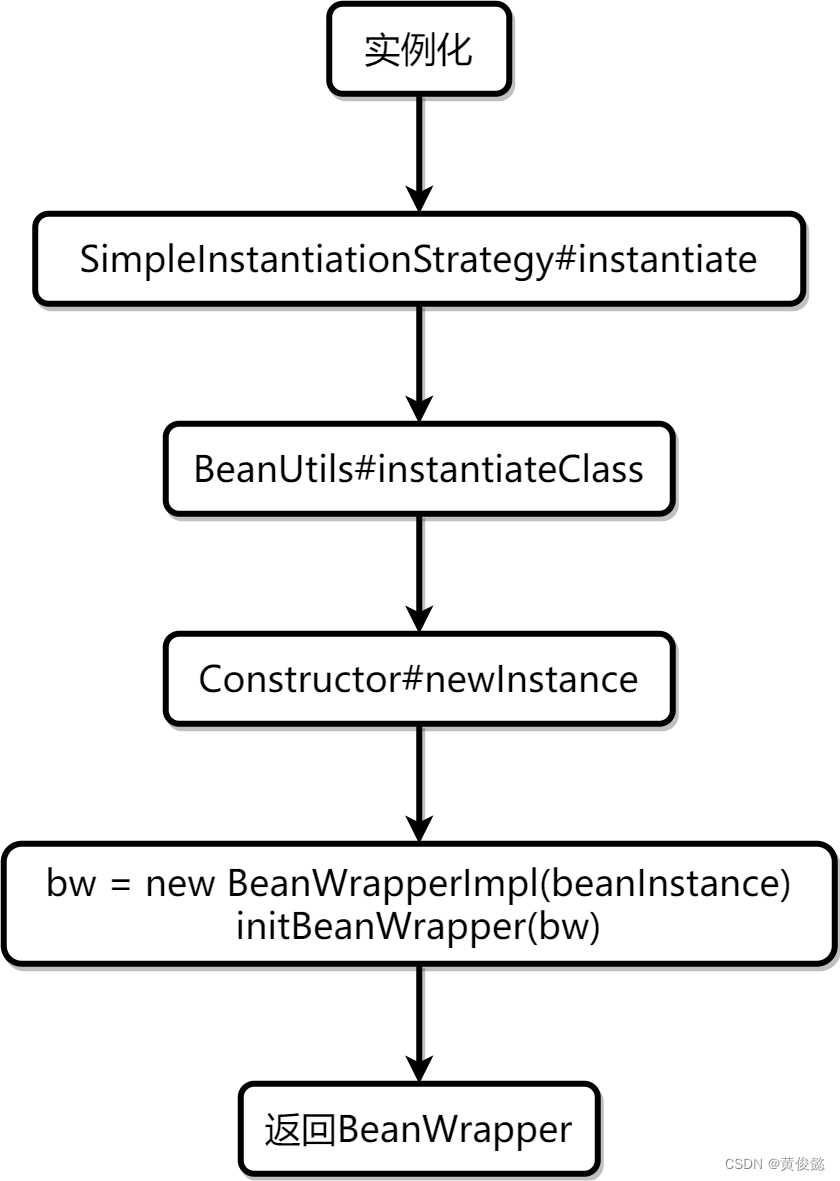
简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化
简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化原理解析实例化bean的入口工厂方法实例化推断构造初次筛选二次筛选bean的实例化代码走读实例化bean的入口createBeanInstance方法内部的流程推断构造初次筛选二次筛选bean的实例化总结往期文章࿱…...
Win11的两个实用技巧系列清理磁盘碎片、设置系统还原点的方法
Win11如何清理磁盘碎片?Win11清理磁盘碎片的方法磁盘碎片过多,会影响电脑的运行速度,所以需要定期清理,这篇文章将以Win11为例,给大家分享的整理磁盘碎片方法相信很多用户都会发现,随着电脑使用时间的增加,…...
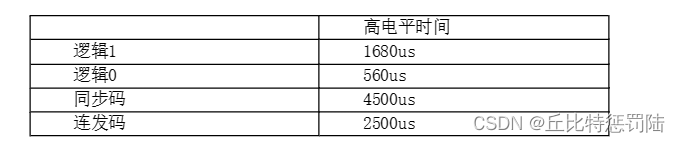
嵌入式 STM32 红外遥控
目录 红外遥控 NEC码的位定义 硬件设计 软件设计 源码程序 红外遥控 红外遥控是一种无线、非接触控制技术,具有抗干扰能力强,信息传输可靠,功耗低,成本低,容易实现等显著的特点,被诸多电子设备特别…...

Java Web 新冠物资管理系统系统源码-SpringBoot2+Vue3+MyBatis-Plus+MySQL8.0【含文档】
摘要 新冠疫情的爆发对全球公共卫生体系提出了严峻挑战,物资管理成为疫情防控中的关键环节。传统物资管理方式依赖人工操作,效率低下且易出错,难以应对突发公共卫生事件中的大规模物资调配需求。为解决这一问题,新冠物资管理系统应…...

Quartus中生成与烧录FPGA板载Flash的jic文件全流程解析
1. 为什么需要jic文件? 刚接触FPGA开发的朋友可能会疑惑:为什么编译生成的sof文件不能直接烧录到Flash?这个问题要从FPGA的特性说起。FPGA芯片内部是基于SRAM结构的,这意味着每次断电后配置数据都会丢失。想象一下你正在用电脑写文…...

SPIRAN ART SUMMONER跨平台适配:Windows/macOS/Linux下Streamlit祭坛兼容性
SPIRAN ART SUMMONER跨平台适配:Windows/macOS/Linux下Streamlit祭坛兼容性 1. 引言:当幻光祭坛遇见不同操作系统 想象一下,你刚刚在网络上看到了一个令人惊叹的AI图像生成工具——SPIRAN ART SUMMONER。它那充满《最终幻想10》风格的“幻光…...

LFM2.5-1.2B-Thinking-GGUF效果展示:同一Prompt下Thinking中间态与终版回答对比图
LFM2.5-1.2B-Thinking-GGUF效果展示:同一Prompt下Thinking中间态与终版回答对比图 1. 模型简介 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,特别适合在资源有限的环境中快速部署和使用。该模型采用GGUF格式存储,通过ll…...

零基础玩转OpenClaw:nanobot镜像可视化控制台入门
零基础玩转OpenClaw:nanobot镜像可视化控制台入门 1. 为什么选择nanobot镜像作为OpenClaw入门 第一次接触OpenClaw时,我被它强大的本地自动化能力所吸引,但很快就被复杂的命令行配置劝退了。直到发现了nanobot这个超轻量级OpenClaw镜像&…...
LumiPixel优化升级:如何利用Z-Image模型生成更细腻的像素人像
LumiPixel优化升级:如何利用Z-Image模型生成更细腻的像素人像 1. 引言:像素艺术的复兴与挑战 像素艺术作为一种独特的数字艺术形式,近年来在游戏、NFT和数字设计领域迎来复兴。然而传统像素创作面临两大核心挑战: 细节表现力不…...
)
GIS小白必看!Global Mapper处理正射影像的5个高频问题解答(含奥维地图导入避坑指南)
GIS新手实战指南:Global Mapper正射影像处理全解析 第一次打开Global Mapper时,那些密密麻麻的工具栏和复杂的参数设置确实让人望而生畏。去年我刚接触GIS时,处理无人机航拍的正射影像就踩了不少坑——坐标系选错导致影像偏移几百米、导出分幅…...

智能家居控制中心:OpenClaw桥接Qwen3-32B-Chat与HomeAssistant
智能家居控制中心:OpenClaw桥接Qwen3-32B-Chat与HomeAssistant 1. 为什么需要AI驱动的家居控制中心 去年冬天的一个深夜,我被空调异常制热的噪音惊醒。摸黑在手机APP上反复调整参数无果后,突然意识到:如果有个能理解自然语言的智…...
开发中,EEG实时预处理流程设计与避坑指南)
从实验室到产品:脑机接口(BCI)开发中,EEG实时预处理流程设计与避坑指南
从实验室到产品:脑机接口(BCI)开发中EEG实时预处理流程设计与避坑指南 在咖啡馆见到那位渐冻症患者用脑电波操控机械臂喝咖啡时,我意识到脑机接口技术正从实验室走向真实世界。但鲜有人提及的是,这套酷炫系统背后藏着怎样的信号处理炼狱——当…...

OpenClaw终端整合:QwQ-32B命令行操作增强方案
OpenClaw终端整合:QwQ-32B命令行操作增强方案 1. 为什么需要终端智能助手 作为开发者,我们每天要处理大量命令行操作。从简单的目录跳转、文件操作,到复杂的管道命令组合,再到调试报错信息,这些重复性工作消耗了大量…...