Spark SQL自定义collect_list分组排序
想要在spark sql中对group by + concat_ws()的字段进行排序,可以参考如下方法。
原始数据如下:
+---+-----+----+
|id |name |type|
+---+-----+----+
|1 |name1|p |
|2 |name2|p |
|3 |name3|p |
|1 |x1 |q |
|2 |x2 |q |
|3 |x3 |q |
+---+-----+----+
目标数据如下:
+----+---------------------+
|type|value_list |
+----+---------------------+
|p |[name3, name2, name1]|
|q |[x3, x2, x1] |
+----+---------------------+
spark-shell:
val df=Seq((1,"name1","p"),(2,"name2","p"),(3,"name3","p"),(1,"x1","q"),(2,"x2","q"),(3,"x3","q")).toDF("id","name","type")
df.show(false)
1.使用开窗函数
df.createOrReplaceTempView("test")
spark.sql("select type,max(c) as c1 from (select type,concat_ws('&',collect_list(trim(name)) over(partition by type order by id desc)) as c from test) as x group by type ")
因为使用开窗函数本身会使用比较多的资源,
这种方式在大数据量下性能会比较慢,所以尝试下面的操作。
2.使用struct和sort_array(array,asc?true,flase)的方式来进行,效率高些:
val df3=spark.sql("select type, concat_ws('&',sort_array(collect_list(struct(id,name)),false).name) as c from test group by type ")
df3.show(false)
例如:计算一个结果形如:
user_id stk_id:action_type:amount:price:time stk_id:action_type:amount:price:time stk_id:action_type:amount:price:time stk_id:action_type:amount:price:time
需要按照time 升序排,则:
Dataset<Row> splitStkView = session.sql("select client_id, innercode, entrust_bs, business_amount, business_price, trade_date from\n" +"(select client_id,\n" +" split(action,':')[0] as innercode,\n" +" split(action,':')[1] as entrust_bs,\n" +" split(action,':')[2] as business_amount,\n" +" split(action,':')[3] as business_price,\n" +" split(action,':')[4] as trade_date,\n" +" ROW_NUMBER() OVER(PARTITION BY split(action,':')[0] ORDER BY split(action,':')[4] DESC) AS rn\n" +"from stk_temp)\n" +"where rn <= 5000");splitStkView.createOrReplaceTempView("splitStkView");Dataset<Row> groupStkView = session.sql("select client_id, CONCAT(innercode, ':', entrust_bs, ':', business_amount, ':', business_price, ':', trade_date) as behive, trade_date from splitStkView");groupStkView.createOrReplaceTempView("groupStkView");Dataset<Row> resultData = session.sql("SELECT client_id, concat_ws('\t',sort_array(collect_list(struct(trade_date, behive)),true).behive) as behives FROM groupStkView GROUP BY client_id");3.udf的方式
import org.apache.spark.sql.functions._
import org.apache.spark.sql._
val sortUdf = udf((rows: Seq[Row]) => {rows.map { case Row(id:Int, value:String) => (id, value) }.sortBy { case (id, value) => -id } //id if asc.map { case (id, value) => value }
})val grouped = df.groupBy(col("type")).agg(collect_list(struct("id", "name")) as "id_name")
val r1 = grouped.select(col("type"), sortUdf(col("id_name")).alias("value_list"))
r1.show(false)
相关文章:

Spark SQL自定义collect_list分组排序
想要在spark sql中对group by concat_ws()的字段进行排序,可以参考如下方法。 原始数据如下: ------------ |id |name |type| ------------ |1 |name1|p | |2 |name2|p | |3 |name3|p | |1 |x1 |q | |2 |x2 |q | |3 |x3 |q | …...

2023年云计算的发展趋势如何?
混合云的持续发展:混合云指的是将公有云和私有云进行结合,形成一种统一的云计算环境。随着企业对数据隐私和安全性的要求越来越高,以及在数据存储和处理方面的需求不断增长,混合云正在逐渐成为主流。预计未来混合云将会继续保持高…...
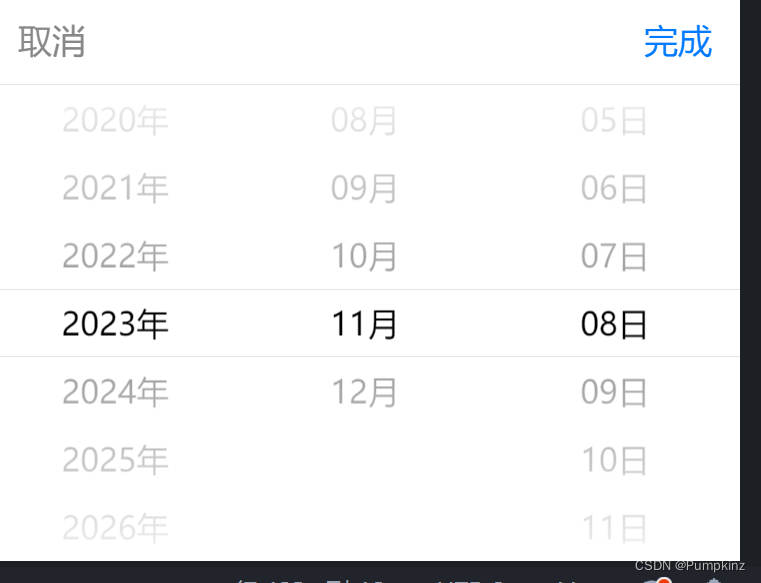
uniapp中picker 获取时间组件如何把年月日改成年月日默认时分秒为00:00:00
如图所示,uniapp中picker组件的日期格式为: 但后端要 2023-11-08 00:00:00格式 如何从2023-11-08转化为 2023-11-08 00:00:00:👇 const date new Date(e.detail.value);//"2023-11-17" date.setHours(0, 0, 0); // 2…...

k8s operator
Kubernetes Operator 是一种用于特定应用的控制器,可扩展 Kubernetes API 的功能,来代表 Kubernetes 用户创建、配置和管理复杂应用的实例。它基于基本 Kubernetes 资源和控制器概念构建,但又涵盖了特定领域或应用的知识,用于实现…...

使用io_uring
目录 升级内核以支持io_uring Io_uring 关注点 有序性 IOPOLL SQPOLL 环大小 wrk线程数量 升级内核以支持io_uring #!/bin/bash#内核源码压缩包 kernel_targz"linux-5.14.21.tar.xz"#内核源码解压后的目录 kernel_source"linux-5.14.21"echo "…...
|LeetCode93. 复原 IP 地址、LeetCode78. 子集、LeetCode90. 子集 II)
LeetCode算法题解(回溯)|LeetCode93. 复原 IP 地址、LeetCode78. 子集、LeetCode90. 子集 II
一、LeetCode93. 复原 IP 地址 题目链接:93. 复原 IP 地址 题目描述: 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。 例如:"0.…...

vue、react数据绑定的区别?
Vue 和 React 是两个流行的前端框架,它们在数据绑定方面有一些区别。 Vue 的数据绑定: Vue 使用双向数据绑定(two-way data binding)的概念。这意味着当数据发生变化时,视图会自动更新;同时,当…...
前端Vue 页面滑动监听 拿到滑动的坐标值
前言 前端Vue 页面滑动监听 拿到滑动的坐标值 实现 Vue2写法 mounted() {// 监听页面滚动事件window.addEventListener("scroll", this.scrolling);}, methods: { scrolling() {// 滚动条距文档顶部的距离let scrollTop window.pageYOffset ||document.documentE…...

CSS实现鼠标移至图片上显示遮罩层及文字效果
效果图: 1、将遮罩层html代码与图片放在一个div 我是放在 .proBK里。 <div class"proBK"><img src"../../assets/image/taskPro.png" class"proImg"><div class"imgText"><h5>用户在线发布任务&l…...
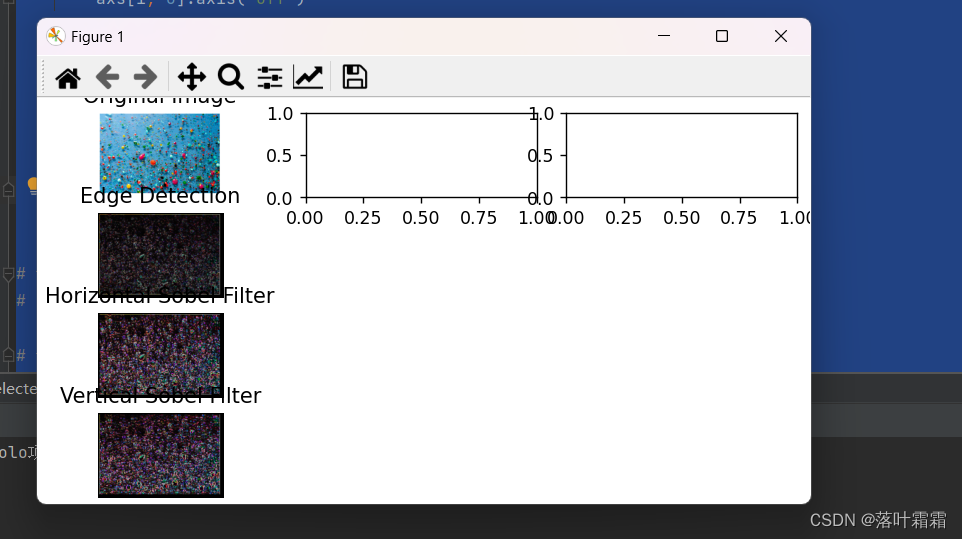
【OpenCV实现图像:图像处理技巧之空间滤波】
文章目录 概要导入库空间过滤器模板展示效果分析与总结 概要 空间滤波器是数字图像处理中的基本工具之一。它通过在图像的每个像素位置上应用一个特定的滤波模板,根据该位置周围的相邻像素值进行加权操作,从而修改该像素的值。这种加权操作能够突出或模…...

载波通讯电表的使用年限是多久?
随着科技的飞速发展,智能家居、物联网等概念逐渐深入人心,载波通讯电表作为一种新型的智能电表,凭借其低功耗、高可靠性、远程通讯等优点,广泛应用于居民用电、工业生产等领域。那么,载波通讯电表的使用年限是多久呢&a…...

微信小程序多端应用 Donut 多端编译
目前支持 wxml、wxs、js/ts、json,less/sass 等文件类型,资源支持通过配置区分不同平台 wxml中使用 <!-- #if MP --><view class"test-view">wechat</view><!-- #elif IOS --><view class"test-view"…...
调试 Mahony 滤波算法的思考 10
调试 Mahony 滤波算法的思考 1. 说在前面的2.Mahony滤波算法的核心思想3. 易懂的理解 Mahony 滤波算法的过程4. 其他的一些思考5. 民间 9轴评估板 1. 说在前面的 之前调试基于QMI8658 6轴姿态解算的时候,我对Mahony滤波的认识还比较浅薄。初次的学习和代码的移植让…...
Bean——IOC(Github上有代码)
源码 https://github.com/cmdch2017/Bean_IOC.git 获取Bean对象 BeanFactory Bean的作用域 第三方Bean需要用Bean注解 比如消息队列项目中,需要用到Json的消息转换器,这是第三方的Bean对象,所以不能用Component,而要用Bean …...
功能更新|Leangoo领歌免费敏捷工具支持SAFe大规模敏捷框架
Leangoo领歌是一款永久免费的专业的敏捷开发管理工具,提供端到端敏捷研发管理解决方案,涵盖敏捷需求管理、任务协同、进展跟踪、统计度量等。 Leangoo可以支持敏捷研发管理全流程,包括小型团队敏捷开发,规模化敏捷SAFe…...
漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案
漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案漏刻有时百度地图API实战开发(2)文本标签显示和隐藏的切换开关漏刻有时百度地图API实战开发(3)自动获取地图多边形中心点坐标漏刻有时百度地图API实战开发(4)显示指定区域在移动端异常的解…...

交流信号继电器 DX-31BJ/AC220V JOSEF约瑟 电压启动 面板嵌入式安装
DX系列信号继电器由矩形脉冲激磁,磁钢保持。本继电器为双绕组。工作线圈可为电压型,亦可为电流型。复归线圈为电压型。继电器的工作电流或工作电压为长脉冲,亦可为脉冲不小于20mS的短脉冲。 系列型号 DX-31B信号继电器DX-31BJ信号继电器 D…...
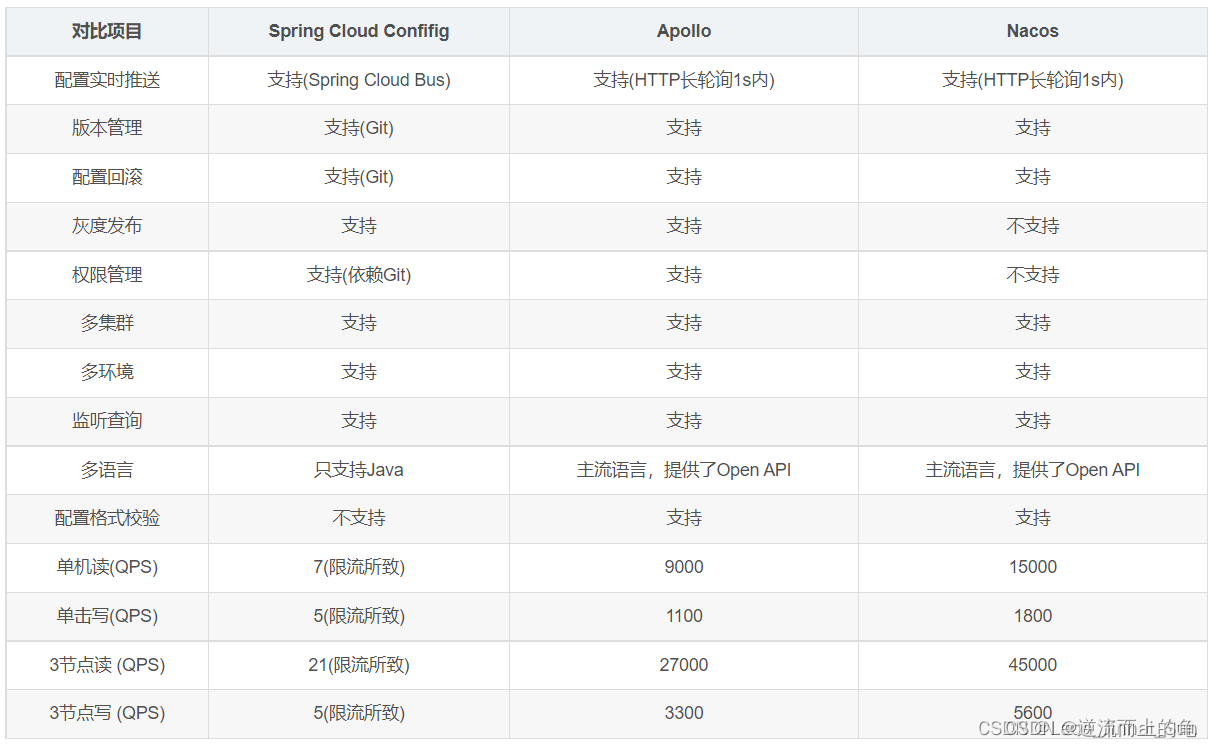
SpringCloudAlibaba系列之Nacos配置管理
目录 说明 认识配置中心 Nacos架构图 Nacos配置管理实现原理 核心源码分析-客户端 核心源码分析-服务端 配置修改的实时通知 主流配置中心对比 小小收获 说明 本篇文章主要目的是从头到尾比较粗粒度的分析Nacos配置中心的一些实现,很多细节没有涉及&#…...

Kyligence Copilot 亮相第六届进博会,增添数智新活力
11月5日,第六届中国国际进口博览会(以下简称“进博会”)在上海国家会展中心盛大启幕,众多新科技、新成果、新展品亮相本届进博会。作为阿斯利康(AstraZeneca)合作伙伴,跬智信息(Kyli…...

MySQL 批量修改表的列名为小写
1、获取脚本 SELECT concat( alter table , TABLE_NAME, change column , COLUMN_NAME, , lower( COLUMN_NAME ), , COLUMN_TYPE, comment \, COLUMN_COMMENT, \; ) AS 脚本 FROM information_schema.COLUMNS WHERE TABLE_SCHEMA 数据库名 and TABLE_NAME表名-- 大写是up…...
)
别再折腾了!2024年最新TeX Live + TeXstudio保姆级安装配置指南(含清华镜像加速)
2024年LaTeX终极配置指南:从零搭建高效学术写作环境 第一次接触LaTeX时,我被那些复杂的命令和报错信息吓得不轻。记得研究生入学第二天,导师扔给我一份LaTeX模板说"用这个写论文",结果光是安装环境就折腾了整整三天。如…...

Yew Context API:组件间数据传递的终极指南
Yew Context API:组件间数据传递的终极指南 【免费下载链接】yew Rust / Wasm framework for creating reliable and efficient web applications 项目地址: https://gitcode.com/gh_mirrors/ye/yew Yew是一个基于Rust和WebAssembly的现代Web框架,…...

Revelation光影包:为Minecraft打造电影级物理渲染体验
Revelation光影包:为Minecraft打造电影级物理渲染体验 【免费下载链接】Revelation An explorative shaderpack for Minecraft: Java Edition 项目地址: https://gitcode.com/gh_mirrors/re/Revelation 想要将Minecraft的方块世界升级为电影大片般的视觉盛宴…...

GHelper:轻量级华硕笔记本控制工具完整使用指南
GHelper:轻量级华硕笔记本控制工具完整使用指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, an…...

抖音下载终极解决方案:douyin-downloader完全指南,新手也能轻松上手
抖音下载终极解决方案:douyin-downloader完全指南,新手也能轻松上手 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, an…...
)
从零开始学习 Linux SPI 驱动开发(基于 IMX6ULL + TLC5615 DAC)
从零开始学习 Linux SPI 驱动开发(基于 IMX6ULL TLC5615 DAC) 文章目录从零开始学习 Linux SPI 驱动开发(基于 IMX6ULL TLC5615 DAC)[TOC]1. 什么是 SPI?硬件信号与连接
如何用PythonDataScienceHandbook掌握自监督学习:无标签数据训练的终极指南
如何用PythonDataScienceHandbook掌握自监督学习:无标签数据训练的终极指南 【免费下载链接】PythonDataScienceHandbook Python Data Science Handbook: full text in Jupyter Notebooks 项目地址: https://gitcode.com/gh_mirrors/py/PythonDataScienceHandbook…...
深度解析TCP/IP网络协议栈:从基础概念到核心机制的全方位指南)
(10个核心知识点解构分章版)深度解析TCP/IP网络协议栈:从基础概念到核心机制的全方位指南
(10个核心知识点解构分章版)深度解析TCP/IP网络协议栈:从基础概念到核心机制的全方位指南作者:培风图南以星河揽胜 发布日期:2026-04-24 标签:#计算机网络 #TCP/IP #面试必备 #网络原理 #CSDN原创前言:为什么我们需要深…...
(Windows系统))
教程太碎总失败?这篇Claude Code配置文:从Node.js到API调用一篇搞定(亲测跑通)(Windows系统)
前言 最近AI代码工具更新太快,很多教程刚出来就过时,尤其是Claude Code这类工具,环境配置和API对接总让新手头疼——不是Node.js版本不对,就是海外接口连不上,折腾半天还是报错。 其实核心问题就两个:一是…...