Etcd 常用命令与备份恢复
1. etcd简介
官方网站:etcd.io
官方文档:etcd.io/docs/v3.5/op-guide/maintenance
官方硬件推荐:etcd.io/docs/v3.5/op-guide/hardware
github地址:github.com/etcd-io/etcd
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。
etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
2. etcd 特点
(1)完全复制: 集群中的每个节点都可以使用完整的存档(就是集群中每个节点的数据都是一模一样的)
(2)高可用性: Etcd可用于避免硬件的单点故障或网络问题(比如3节点集群,一个宕机了,另外两个会进行自动选主)
(3)一致性: 每次读取都会返回跨多主机的最新写入(就是我在A节点写入的数据,在B节点就能立马查到)
(4)简单: 包括一个定义良好、面向用户的API (gRPC)
(5)安全: 实现了带有可选的客户端证书身份验证的自动化TLS(集群内部通信明文,外部通信加密)
(6)快速: 每秒10000次写入的基准速度
(7)可靠: 使用Raft算法实现了存储的合理分布
3. etcd启动参数介绍
etcd启动基本就是靠传参的方式
[root@k8s-etcd01 ~]# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos[Service]
Type=notify
WorkingDirectory=/data/etcd
ExecStart=/usr/local/bin/etcd \--name=etcd-10.31.200.105 \ # 节点名称,这个每个节点都必须不同,因为是基于这个节点名称来识别节点的。# 这里注意,签发给etcd的证书,都是绑定了节点的IP的,如果涉及到etcd节点的替换,那么IP地址一定要和原节点的IP一样才行。--cert-file=/etc/kubernetes/ssl/etcd.pem \ # 公钥--key-file=/etc/kubernetes/ssl/etcd-key.pem \ # 私钥--peer-cert-file=/etc/kubernetes/ssl/etcd.pem \ # 一样--peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \ # 一样--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ # ca公钥,主要作用就是来校验上面的公钥和私钥是不是基于我这个ca签发的--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \--initial-advertise-peer-urls=https://10.31.200.105:2380 \ # 通告自己的集群地址和端口,主要用来角色选举、数据同步--listen-peer-urls=https://10.31.200.105:2380 \ # 本机监听端口--listen-client-urls=https://10.31.200.105:2379,http://127.0.0.1:2379 \ # 客户端访问地址--advertise-client-urls=https://10.31.200.105:2379 \--initial-cluster-token=etcd-cluster-0 \ # 创建集群时使用的token,同一个集群内的节点保持一致--initial-cluster=etcd-10.31.200.105=https://10.31.200.105:2380,etcd-10.31.200.106=https://10.31.200.106:2380,etcd-10.31.200.107=https://10.31.200.107:2380 \ # 集群所有节点信息。后续集群内的数据传输都在这3个节点之间。这里害得注意,etcd-10.31.200.105这个配置,必须和--name那里的配置是一样的。--initial-cluster-state=new \ # 新建集群这个值为new,如果是已经存在的集群,为existing。--data-dir=/data/etcd \ # 数据目录路径--wal-dir= \ --snapshot-count=50000 \--auto-compaction-retention=1 \--auto-compaction-mode=periodic \--max-request-bytes=10485760 \--quota-backend-bytes=8589934592
Restart=always
RestartSec=15
LimitNOFILE=65536
OOMScoreAdjust=-999[Install]
WantedBy=multi-user.target
4. etcd选举介绍
4.1 选举使用的算法
etcd基于Raft算法进行集群角色选举,使用Raft的还有Consul、InfluxDB、kafka(新版用KRaft、旧版还是zk)等。
4.2 etcd集群角色状态
集群中每个节点只能处于Leader、Follower和Candidate三种状态的一种。(1)follower: 追随者(相当于Redis Cluster的Slave节点),负责同步主节点的数据(读从,不能写)。
(2)Candidate:候选者,选举过程中才会出现。
(3)Leader:主节点(相当于Redis Cluster的Master节点),负责当前节点的数据写入(写主,不能读)。
4.3 etcd集群选举过程-简述版
节点启动后基于termID(任期ID)进行相互投票,termID是一个整数默认值为0,在Raft算法中,一个term代表leader的一段任期周期,
每当一个节点成为leader时,就会进入一个新的term, 然后每个节点都会在自己的term ID上加1,以便与上一轮选举区分开来。假设启动一个3节点etcd集群,当3个节点都在同一时间启动时(启动时间秒级别内就行),会进入Candidate(候选者)状态,然后各节点进行投票,最终诞生1个leader,该leader会向集群内通告自己当前的角色和状态,说自己成为了leader,剩下2个节点就会自动切换为follower,并设置主地址为leader,从这个leader开始同步数据,同时还会对leader进行心跳检测(看leader还正不正常)。
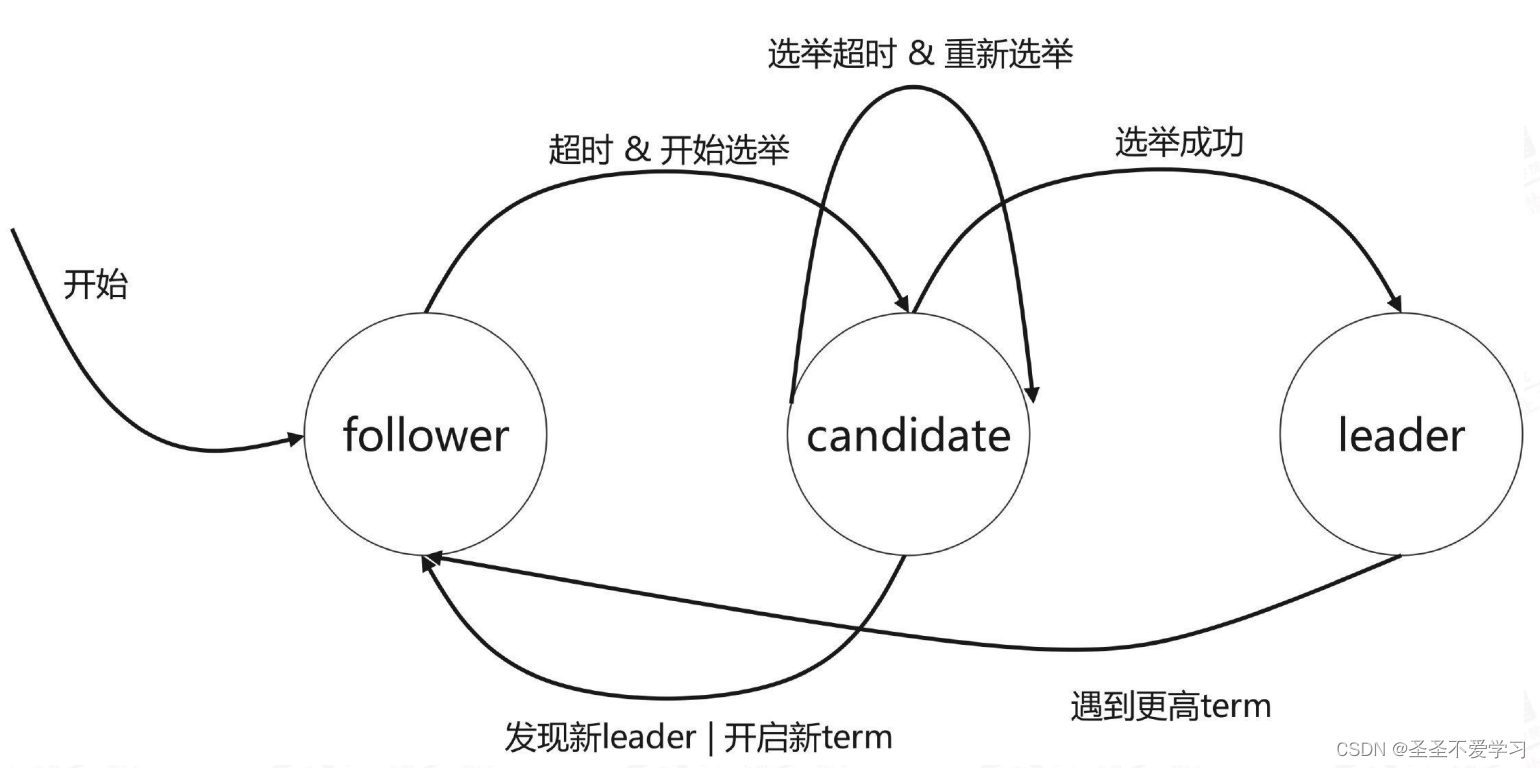
4.4 etcd集群选举过程-详细版
4.4.1 首次选举
(1)各etcd节点启动后默认为follower角色、默认termID为0、如果发现集群内没有leader,则会变成 candidate角色并进行选举 leader。
(2)candidate(候选节点)向其它候选节点发送投票信息(RequestVote),默认投票给自己。
(3)各候选节点相互收到另外的投票信息(如A收到BC的,B收到AC的,C收到AB 的),然后对比日志是否比自己的更新,如果比自己的更新,则将自己的选票 投给目的候选人,并回复一个包含自己最新日志信息的响应消息,如果C的日 志更新,那么将会得到A、B、C的投票,则C全票当选,如果B挂了,得到A、 C的投票,则C超过半票当选。
(4)C向其它节点发送自己leader心跳信息,以维护自己的身份(heartbeat- interval、默认100毫秒通告一次)。
(5)其它节点将角色切换为Follower并向leader同步数据。
(6)如果选举超时(election-timeout )、则重新选举,如果选出来两个leader, 则超过集群总数半票的生效。
4.4.2 后期选举
(1)当一个follower节点在规定时间内未收到leader的消息时,它将转换为candidate状态,向其他节点发送投票请求(自己的term ID和日志更新记录时间), 并等待其他节点的响应,如果该candidate的(日志更新记录最新),则会获多数投票,它将成为新的leader。
(2)新的leader将自己的termID +1 并通告至其它节点。
(3)如果旧的leader恢复了,发现已有新的leader,则加入到已有的leader中,并将自己的term ID更新为和leader一致,在同一个任期内所有节点的term ID是一致的。
5. etcd优化
5.1 配置优化
5.1.1 最大请求字节数
--max-request-bytes=10485760 #request size limit(最大请求字节数。默认客户端请求一个key最大只能是1.5Mib,官方推荐最大不要超出10Mib。改的话就是改这个参数)
[root@k8s-etcd01 ~]# etcd --help|grep max-request-bytes
--max-request-bytes '1572864' # 这就是默认配置# 修改方式
[root@k8s-etcd01 ~]# grep 'max-request-bytes' /etc/systemd/system/etcd.service --max-request-bytes=10485760 \ # 就是这个参数,没有的话添加一个就行
5.1.2 磁盘存储空间大小限制
# 因为etcd存储的只是k8s集群的元数据信息,所以不会占用很大的存储空间,只是对IO消耗比较大。
--quota-backend-bytes=8589934592 #storage size limit(磁盘存储空间大小限制,默认为2G,这里配置的8G,超过8G启动会有警告信息)# 修改方式
[root@k8s-etcd01 ~]# grep 'quota-backend-bytes' /etc/systemd/system/etcd.service --quota-backend-bytes=8589934592 # 也是在启动配置文件中加个参数就好了
5.2 磁盘碎片整理
etcd集群运行时间长了,包括备份这些操作,就会产生一些磁盘碎片,所以需要定期清理一下
# 如果etcd版本较老,则需要声明下api版本,可以使用etcdctl version查看版本
ETCDCTL_API=3
/usr/local/bin/etcdctl defrag --cluster --endpoints=https://10.31.200.105:2379 -- cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem# 新版本的话就不用声明api版本
etcdctl defrag --cluster --endpoints=https://10.31.200.105:2379 -- cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem# 清理演示.随便一个节点都行
[root@k8s-etcd01 ~]# etcdctl defrag --cluster --endpoints=https://10.31.200.105:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem
Finished defragmenting etcd member[https://10.31.200.105:2379]
Finished defragmenting etcd member[https://10.31.200.106:2379]
Finished defragmenting etcd member[https://10.31.200.107:2379]
6. etcd客户端命令使用
etcd服务器的权限、安全、备份,一定要弄好,一旦数据被删除,k8s集群里面就啥也没有了。
etcd有多个不同的API访问版本,v1版本已经废弃,etcd v2 和 v3 本质上是共享同一套 raft 协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离。
也就是说如果从 Etcd v2 升级到 Etcd v3,原来v2 的数据还是只能用 v2 的接口访问,v3 的接口创建的数据也只能访问通过v3 的接口访问。WARNING:
Environment variable ETCDCTL_API is not set; defaults to etcdctl v2. #默认使用V2版本
Set environment variable ETCDCTL_API=3 to use v3 API or ETCDCTL_API=2 to use v2 API. #设置API版本# 使用下面的命令可以查看api版本
[root@k8s-etcd01 ~]# etcdctl version
etcdctl version: 3.5.5
API version: 3.5
6.1 查看集群成员列表
[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107" # 声明一个节点变量
[root@k8s-etcd01 ~]# etcdctl --write-out=table member list --endpoints=https://10.31.200.105:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem
+------------------+---------+--------------------+----------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS(集群端口) | CLIENT ADDRS(客户端端口) | IS LEARNER(数据同步状态) |
+------------------+---------+--------------------+----------------------------+----------------------------+------------+
| 43c78a8a8ac5fcae | started | etcd-10.31.200.105 | https://10.31.200.105:2380 | https://10.31.200.105:2379 | false |
| 9869c8c8af112f55 | started | etcd-10.31.200.106 | https://10.31.200.106:2380 | https://10.31.200.106:2379 | false |
| a4a3b2754c389591 | started | etcd-10.31.200.107 | https://10.31.200.107:2380 | https://10.31.200.107:2379 | false |
+------------------+---------+--------------------+----------------------------+----------------------------+------------+# 参数讲解
--write-out=table: 表格形式输出信息
member list:列出当前集群中的成员
6.2 查看节点心跳信息
[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107"
[root@k8s-etcd01 ~]# for ip in ${NODE_IPS}; do etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
https://10.31.200.105:2379 is healthy: successfully committed proposal: took = 8.50254ms
https://10.31.200.106:2379 is healthy: successfully committed proposal: took = 15.281376ms
https://10.31.200.107:2379 is healthy: successfully committed proposal: took = 14.666677ms
6.3 查看集群成员详细信息
[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107"
[root@k8s-etcd01 ~]# for ip in ${NODE_IPS}; do etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem; done
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.105:2379 | 43c78a8a8ac5fcae | 3.5.5 | 2.2 MB | true | false | 4 | 3250690 | 3250690 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.106:2379 | 9869c8c8af112f55 | 3.5.5 | 2.2 MB | false | false | 4 | 3250690 | 3250690 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.107:2379 | a4a3b2754c389591 | 3.5.5 | 2.2 MB | false | false | 4 | 3250690 | 3250690 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
6.4.1 查看所有key
[root@k8s-etcd01 ~]# etcdctl get / --prefix --keys-only|head # 加个head,或者grep过滤想查的key,防止卡死
/calico/ipam/v2/assignment/ipv4/block/10.200.122.128-26/calico/ipam/v2/assignment/ipv4/block/10.200.135.128-26/calico/ipam/v2/assignment/ipv4/block/10.200.195.0-26/calico/ipam/v2/assignment/ipv4/block/10.200.32.128-26/calico/ipam/v2/assignment/ipv4/block/10.200.58.192-26[root@k8s-etcd01 ~]# etcdctl get / --prefix --keys-only|grep pods
/registry/pods/default/net-test1
/registry/pods/default/net-test3
/registry/pods/kube-system/calico-kube-controllers-b6445bbf8-6gqx2
/registry/pods/kube-system/calico-node-bcpqf
/registry/pods/kube-system/calico-node-cf7xm
/registry/pods/kube-system/calico-node-gnrlx
/registry/pods/kube-system/calico-node-hsm8c
/registry/pods/kube-system/calico-node-hv9l4
/registry/pods/kube-system/calico-node-smzz9
/registry/pods/kube-system/coredns-5879bb4b8c-g8z8b
/registry/pods/kube-system/coredns-5879bb4b8c-ph4h4
/registry/pods/myserver/myserver-nginx-deployment-5c9d79c56f-zcj7b
6.4.2 查看某个key的详细信息
[root@k8s-etcd01 ~]# etcdctl get /registry/pods/default/net-test1 # 但是直接这样查看会乱码,需要额外安装一个工具[root@k8s-etcd01 ~]# chmod u+x auger # 上传并授权
[root@k8s-etcd01 ~]# mv auger /usr/local/bin/# 再次查看
[root@k8s-etcd01 ~]# etcdctl get /registry/namespaces/myserver |auger decode # 就相当于直接查看yaml文件
apiVersion: v1
kind: Namespace
metadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"v1","kind":"Namespace","metadata":{"annotations":{},"name":"myserver"}}creationTimestamp: "2023-04-25T08:14:09Z"labels:kubernetes.io/metadata.name: myservername: myserveruid: ead8e171-3d5d-4313-8b32-cb1ff02da6b9
spec:finalizers:- kubernetes
status:phase: Active
6.5.1 添加数据
[root@k8s-etcd01 ~]# etcdctl put /name "tom" # key: name。value: tom
OK[root@k8s-etcd01 ~]# etcdctl get /name
/name
tom
6.5.2 修改数据
直接覆盖就是更新数据
[root@k8s-etcd01 ~]# etcdctl put /name "jac"
OK[root@k8s-etcd01 ~]# etcdctl get /name
/name
jac
6.5.3 删除数据
[root@k8s-etcd01 ~]# etcdctl del /name
1[root@k8s-etcd01 ~]# etcdctl get /name # 这里因为key已经被删除了,所以返回空
[root@k8s-etcd01 ~]#
7. etcd watch(监听)机制
7.1 etcd watch(监听)机制
基于不断监看数据,发生变化就主动触发通知客户端,Etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围。详细如下:etcd的watch机制可以监听etcd中的key或者prefix,当这些key或者prefix发生变化时,可以触发watch事件,并返回变化的内容。watch机制是etcd的一个核心功能,可以用来实现实时更新、通知等功能。具体的watch机制如下:1. 客户端创建一个watcher:客户端先通过watcher API创建一个watcher对象,并指定要监听的key或prefix。2. 客户端向etcd提交watcher请求:客户端向etcd提交watcher请求,并指定要监听的key或prefix,同时还可以指定其他的参数,如revision等。3. etcd接收watcher请求并处理:etcd首先会检查watcher请求中的revision是否有效,如果有效则直接返回watcher的初始值。如果无效则阻塞请求,等待key或prefix发生变化时再返回。4. etcd监视key或prefix的变化:etcd开始监视指定的key或prefix,并在其发生变化时触发watch事件。这时etcd会将变化的内容发送给客户端,并更新watcher的revision值。如果客户端在接收变化内容后仍然需要继续监听,则需要再次提交watcher请求。5. 客户端接收变化内容并处理:客户端接收到变化内容后可以进行相应的处理,比如更新缓存、通知其他进程等。需要注意的是,etcd的watch机制是基于long polling实现的,并不是同步推送。这意味着当etcd监视的key或prefix长时间没有变化时,watcher请求会一直阻塞,直到发生变化才返回。这种机制可以大大减少网络开销,但也会带来一定的延迟。
7.2 k8s中哪些组件是watch etcd的
(1)kube-apiserver:Kubernetes的控制面板组件,负责暴露API并接收来自用户的请求。kube-apiserver会watch etcd中的特定资源对象,以便能够在发生变化时及时响应客户端请求。(2)kube-controller-manager:Kubernetes的控制器管理器组件,负责监控系统中的资源,并调节资源状态以符合期望状态。kube-controller-manager会watch etcd中的各种资源对象,以监控资源的创建、更新、删除等事件。(3)kube-scheduler:Kubernetes的调度器组件,负责将Pod调度到合适的节点上运行。kube-scheduler会watch etcd中的Pod对象(/registry/events),以获取Pod的调度信息,并根据调度策略进行调度。(4)kubelet:Kubernetes的节点代理组件,负责管理节点上的容器。kubelet会watch etcd中的Pod对象,以获取自己所管理的Pod的信息,并根据Pod的状态进行容器的创建、启动、停止等操作。(5)kube-proxy: 它会watch etcd中的/registry/ranges/service,来进行网络规则变更。
7.3 k8s 组件和etcd之间watch过程
当某个组件或API server向etcd注册一个watch时,etcd会保持一个持久的连接,并在特定的目录下等待事件。当在这个目录下的值被修改、删除或添加时,etcd会发送一个通知给watcher,并返回最新的版本号,watcher可以根据这个版本号获取最新的数据。例如,当Kubernetes Scheduler注册一个watch来监听新的Pod的创建时,etcd会在Pod目录下等待事件。当一个新的Pod被创建时,etcd会将此事件通知给Scheduler,并返回最新的版本号。如果Scheduler希望获取最新的Pods列表,它可以使用这个版本号去获取最新的数据。 在Kubernetes中,watch机制被广泛应用于各种场景,比如监听新的Pods的创建、更新和删除,监听节点状态的变化,监听Service发现的改变等等。这种机制能够帮助各个组件及时感知资源的变化,从而做出相应的调整。
7.4 watch演示
#在etcd node1上watch一个key,没有此key也可以执行watch,后期可以再创建
[root@k8s-etcd01 ~]# etcdctl watch /data# 这就已经开始监听了# 新开一个终端写入数据
[root@k8s-etcd01 ~]# etcdctl put /data "data v1"
OK# 回到第一个终端检查监听情况
[root@k8s-etcd01 ~]# etcdctl watch /data # 这个命令是之前执行的。下面可以看到刚才写入的数据,这边监听到了
PUT
/data
data v1
8. V3版 etcd单节点(单机模式)数据备份恢复
集群模式不能这样恢复数据,不然恢复数据后,会从1个主变成3个主
etcd的数据写入是基于WAL机制,是write ahead log(预写日志)的缩写,顾名思义,也就是在执行真正的写操作之前先写一个日志,预写日志,类似mysql的binlog,最大的作用是记录了整个数据变化的全部历程。
在etcd中,所有数据的修改在提交前,都要先写入到WAL中。
8.1 备份数据
快照备份,只需要在一个节点执行就行
[root@k8s-etcd01 ~]# etcdctl snapshot save /tmp/etcd.db
{"level":"info","ts":"2023-05-08T18:43:39.868+0800","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/tmp/etcd.db.part"}
{"level":"info","ts":"2023-05-08T18:43:39.870+0800","logger":"client","caller":"v3/maintenance.go:211","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":"2023-05-08T18:43:39.870+0800","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2023-05-08T18:43:39.895+0800","logger":"client","caller":"v3/maintenance.go:219","msg":"completed snapshot read; closing"}
{"level":"info","ts":"2023-05-08T18:43:39.970+0800","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"2.2 MB","took":"now"}
{"level":"info","ts":"2023-05-08T18:43:39.970+0800","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/tmp/etcd.db"}
Snapshot saved at /tmp/etcd.db
[root@k8s-etcd01 ~]# ll -rt /tmp/
总用量 2172
-rw------- 1 root root 2220064 5月 8 18:43 etcd.db
8.2 恢复数据
无法恢复备份后被误删的增量数据
[root@k8s-etcd01 ~]# etcdctl snapshot restore /tmp/etcd.db --data-dir=/opt/etcd-testdir # #将数据恢复到一个新
的不存在的目录中,--data-dir参数必须要加,且必须指定一个不存在的目录,如果存在会报错
Deprecated: Use `etcdutl snapshot restore` instead.2023-05-08T18:50:33+08:00 info snapshot/v3_snapshot.go:248 restoring snapshot {"path": "/tmp/etcd.db", "wal-dir": "/opt/etcd-testdir/member/wal", "data-dir": "/opt/etcd-testdir", "snap-dir": "/opt/etcd-testdir/member/snap", "stack": "go.etcd.io/etcd/etcdutl/v3/snapshot.(*v3Manager).Restore\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdutl/snapshot/v3_snapshot.go:254\ngo.etcd.io/etcd/etcdutl/v3/etcdutl.SnapshotRestoreCommandFunc\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdutl/etcdutl/snapshot_command.go:147\ngo.etcd.io/etcd/etcdctl/v3/ctlv3/command.snapshotRestoreCommandFunc\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/command/snapshot_command.go:129\ngithub.com/spf13/cobra.(*Command).execute\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:856\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:960\ngithub.com/spf13/cobra.(*Command).Execute\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:897\ngo.etcd.io/etcd/etcdctl/v3/ctlv3.Start\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/ctl.go:107\ngo.etcd.io/etcd/etcdctl/v3/ctlv3.MustStart\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/ctl.go:111\nmain.main\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/main.go:59\nruntime.main\n\t/usr/local/google/home/siarkowicz/.gvm/gos/go1.16.15/src/runtime/proc.go:225"}
2023-05-08T18:50:33+08:00 info membership/store.go:141 Trimming membership information from the backend...
2023-05-08T18:50:33+08:00 info membership/cluster.go:421 added member {"cluster-id": "cdf818194e3a8c32", "local-member-id": "0", "added-peer-id": "8e9e05c52164694d", "added-peer-peer-urls": ["http://localhost:2380"]}
2023-05-08T18:50:33+08:00 info snapshot/v3_snapshot.go:269 restored snapshot {"path": "/tmp/etcd.db", "wal-dir": "/opt/etcd-testdir/member/wal", "data-dir": "/opt/etcd-testdir", "snap-dir": "/opt/etcd-testdir/member/snap"}[root@k8s-etcd01 ~]# ll /opt/etcd-testdir/member/ # 恢复的数据都在这里
总用量 0
drwx------ 2 root root 62 5月 8 18:50 snap
drwx------ 2 root root 51 5月 8 18:50 wal
8.3 通过脚本自动备份
[root@k8s-etcd01 ~]# mkdir /data/etcd-backup-dir/ -p
[root@k8s-etcd01 ~]# cat etcd-backup.sh
#!/bin/bash
source /etc/profile
DATE=`date +%Y-%m-%d_%H-%M-%S`
ETCDCTL_API=3 /usr/local/bin/etcdctl snapshot save /data/etcd-backup-dir/etcd-snapshot-${DATE}.db[root@k8s-etcd01 ~]# sh etcd-backup.sh # 测试可用后,加入定时任务就行了
[root@k8s-etcd01 ~]# ll /data/etcd-backup-dir
总用量 2172
-rw------- 1 root root 2220064 5月 8 19:04 etcd-snapshot-2023-05-08_19-04-40.db
9. 备份恢复案例演示(集群模式)
9.1 备份集群数据
[root@k8s-harbor01 kubeasz]# ./ezctl backup k8s-cluster1 # 这个命令其实也是在执行edctctl命令
[root@k8s-harbor01 kubeasz]# ll clusters/k8s-cluster1/backup/ # 备份的数据
总用量 4344
-rw------- 1 root root 2220064 5月 8 22:00 snapshot_202305082200.db
-rw------- 1 root root 2220064 5月 8 22:00 snapshot.db
9.2 删除k8s集群中的数据
[root@k8s-harbor01 kubeasz]# kubectl get po
NAME READY STATUS RESTARTS AGE
net-test1 1/1 Running 0 3h41m
net-test3 1/1 Running 0 13d
[root@k8s-harbor01 kubeasz]# kubectl delete po net-test3 # 这里我删除了net-test3这个pod
pod "net-test3" deleted
[root@k8s-harbor01 kubeasz]# kubectl get po
NAME READY STATUS RESTARTS AGE
net-test1 1/1 Running 0 3h42m
9.3 再次备份集群数据
模拟有多备份文件,得从中找到我们需要的这个备份数据
[root@k8s-harbor01 kubeasz]# ./ezctl backup k8s-cluster1
[root@k8s-harbor01 kubeasz]# ll clusters/k8s-cluster1/backup/
总用量 6516
-rw------- 1 root root 2220064 5月 8 22:00 snapshot_202305082200.db
-rw------- 1 root root 2220064 5月 8 22:07 snapshot_202305082207.db # 这里需要注意:snapshot_202305082207.db就是snapshot.db,看文件修改时间能看出来。由于安装k8s的工具脚本里面写死了,恢复的时候一定要用snapshot.db,所以必须要把snapshot_202305082207.db,重命名成snapshot.db。
-rw------- 1 root root 2220064 5月 8 22:07 snapshot.db
9.4 恢复数据
** 注意:在恢复数据期间API server不可用,必须在业务低峰期操作或者是在其它紧急场景。
生产中的备份,数据量不大的话,一天一备就行,所以直接直接找删除数据前一天的备份就行**
[root@k8s-harbor01 backup]# pwd
/etc/kubeasz/clusters/k8s-cluster1/backup
[root@k8s-harbor01 backup]# ll # 因为这些都是二进制文件,所以没法grep过滤字符
总用量 6516
-rw------- 1 root root 2220064 5月 8 22:00 snapshot_202305082200.db
-rw------- 1 root root 2220064 5月 8 22:07 snapshot_202305082207.db
-rw------- 1 root root 2220064 5月 8 22:07 snapshot.db# 重命名备份文件
[root@k8s-harbor01 backup]# cp snapshot_202305082200.db snapshot.db
cp:是否覆盖"snapshot.db"? y# 恢复数据
[root@k8s-harbor01 kubeasz]# ./ezctl restore k8s-cluster1 # 这里会根据剧本中的集群级别恢复命令,来进行数据恢复。恢复过程中会先关闭k8s所有节点的相关服务,防止新的数据写入
ansible-playbook -i clusters/k8s-cluster1/hosts -e @clusters/k8s-cluster1/config.yml playbooks/95.restore.yml
2023-05-08 22:16:12 INFO cluster:k8s-cluster1 restore begins in 5s, press any key to abort:
TASK [stopping kube_master services]
TASK [stopping kube_node services]
TASK [cluster-restore : 停止ectd 服务]
TASK [cluster-restore : 清除etcd 数据目录]
TASK [cluster-restore : 清除 etcd 备份目录]
TASK [cluster-restore : etcd 数据恢复]
TASK [cluster-restore : 分发恢复文件到 etcd 各个节点]
TASK [cluster-restore : 重启etcd 服务]
……省略部分内容
9.5 查看恢复后的数据
[root@k8s-harbor01 kubeasz]# kubectl get po
NAME READY STATUS RESTARTS AGE
net-test1 1/1 Running 0 3h59m
net-test3 0/1 ContainerCreating 1 13d
[root@k8s-harbor01 kubeasz]# kubectl get po
NAME READY STATUS RESTARTS AGE
net-test1 1/1 Running 0 3h59m
net-test3 1/1 Running 0 13d # 这里可以看到,被删除的net-test3又恢复了# 被删除的pod是恢复了,但是集群中的其他pod可能会有问题,因为当前版本的kubeasz有个bug,会导致etcd恢复数据后,从集群变成单机,有3个主
[root@k8s-harbor01 kubeasz]# kubectl get po -A|grep '0/1'
default net-test3 0/1 ContainerCreating 1 13d
kube-system coredns-5879bb4b8c-g8z8b 0/1 Running 0 14d
[root@k8s-harbor01 kubeasz]# kubectl get po -A|grep '0/1'
kube-system calico-kube-controllers-b6445bbf8-6gqx2 0/1 Running 1 (17m ago) 14d
kube-system calico-node-cf7xm 0/1 Running 0 14d
kube-system calico-node-hsm8c 0/1 Running 0 14d
kube-system calico-node-smzz9 0/1 Running 0 14d
kube-system coredns-5879bb4b8c-ph4h4 0/1 Running 0 12d[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107"
[root@k8s-etcd01 ~]# for ip in ${NODE_IPS}; do etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem; done
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.105:2379 | 8e9e05c52164694d | 3.5.5 | 2.2 MB | true | false | 2 | 19078 | 19078 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.106:2379 | 8e9e05c52164694d | 3.5.5 | 2.2 MB | true | false | 2 | 18332 | 18332 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.107:2379 | 8e9e05c52164694d | 3.5.5 | 2.2 MB | true | false | 2 | 18191 | 18191 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
9.6 恢复etcd多主bug
当前版本的修复文件:https://github.com/easzlab/kubeasz/blob/3.5.3/roles/cluster-restore/tasks/main.yml
# 旧的备份剧本
[root@k8s-harbor01 kubeasz]# cat roles/cluster-restore/tasks/main.yml
- name: 停止ectd 服务service: name=etcd state=stopped- name: 清除etcd 数据目录file: name={{ ETCD_DATA_DIR }}/member state=absent- name: 清除 etcd 备份目录file: name={{ cluster_dir }}/backup/etcd-restore state=absentdelegate_to: 127.0.0.1 run_once: true- name: etcd 数据恢复 # 就这里,采用了单机etcd的恢复方式,导致集群有了3个主shell: "cd {{ cluster_dir }}/backup && \ETCDCTL_API=3 {{ base_dir }}/bin/etcdctl snapshot restore snapshot.db \--data-dir={{ cluster_dir }}/backup/etcd-restore"delegate_to: 127.0.0.1run_once: true- name: 分发恢复文件到 etcd 各个节点copy: src={{ cluster_dir }}/backup/etcd-restore/member dest={{ ETCD_DATA_DIR }}- name: 重启etcd 服务service: name=etcd state=restarted- name: 以轮询的方式等待服务同步完成shell: "systemctl is-active etcd.service"register: etcd_statusuntil: '"active" in etcd_status.stdout'retries: 8delay: 8# 用官网的修复文件替换上面的文件
[root@k8s-harbor01 kubeasz]# cat roles/cluster-restore/tasks/main.yml
- name: 停止ectd 服务service: name=etcd state=stopped- name: 清除etcd 数据目录file: name={{ ETCD_DATA_DIR }}/member state=absent- name: 清理上次备份恢复数据file: name=/etcd_backup state=absent- name: 生成备份目录file: name=/etcd_backup state=directory- name: 准备指定的备份etcd 数据copy:src: "{{ cluster_dir }}/backup/{{ db_to_restore }}"dest: "/etcd_backup/snapshot.db"- name: etcd 数据恢复 # 集群级别的恢复方式shell: "cd /etcd_backup && \ETCDCTL_API=3 {{ bin_dir }}/etcdctl snapshot restore snapshot.db \--name etcd-{{ inventory_hostname }} \--initial-cluster {{ ETCD_NODES }} \--initial-cluster-token etcd-cluster-0 \--initial-advertise-peer-urls https://{{ inventory_hostname }}:2380"- name: 恢复数据至etcd 数据目录shell: "cp -rf /etcd_backup/etcd-{{ inventory_hostname }}.etcd/member {{ ETCD_DATA_DIR }}/"- name: 重启etcd 服务service: name=etcd state=restarted- name: 以轮询的方式等待服务同步完成shell: "systemctl is-active etcd.service"register: etcd_statusuntil: '"active" in etcd_status.stdout'retries: 8delay: 8# 重新执行一次恢复命令
[root@k8s-harbor01 kubeasz]# ./ezctl restore k8s-cluster1# 查看etcd集群状态
[root@k8s-etcd01 ~]# export NODE_IPS="10.31.200.105 10.31.200.106 10.31.200.107"
[root@k8s-etcd01 ~]# for ip in ${NODE_IPS}; do etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem; done # 这里就能看到集群恢复正常了
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.105:2379 | 43c78a8a8ac5fcae | 3.5.5 | 3.0 MB | true | false | 2 | 1303 | 1303 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.106:2379 | 9869c8c8af112f55 | 3.5.5 | 3.0 MB | false | false | 2 | 1303 | 1303 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.31.200.107:2379 | a4a3b2754c389591 | 3.5.5 | 3.0 MB | false | false | 2 | 1303 | 1303 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+# 查看pod状态
[root@k8s-harbor01 kubeasz]# kubectl get po -A # 可以看到所有pod都恢复了正常
NAMESPACE NAME READY STATUS RESTARTS AGE
default net-test1 1/1 Running 0 4h27m
default net-test3 1/1 Running 0 13d
kube-system calico-kube-controllers-b6445bbf8-6gqx2 1/1 Running 2 (8m3s ago) 14d
kube-system calico-node-bcpqf 1/1 Running 0 14d
kube-system calico-node-cf7xm 1/1 Running 0 14d
kube-system calico-node-gnrlx 1/1 Running 0 14d
kube-system calico-node-hsm8c 1/1 Running 0 14d
kube-system calico-node-hv9l4 1/1 Running 0 14d
kube-system calico-node-smzz9 1/1 Running 0 14d
kube-system coredns-5879bb4b8c-g8z8b 1/1 Running 0 14d
kube-system coredns-5879bb4b8c-ph4h4 1/1 Running 0 12d
myserver myserver-nginx-deployment-5c9d79c56f-zcj7b 1/1 Running 0 4d1h
10. etcd数据恢复流程
当etcd集群宕机数量超过集群总节点数一半以上的时候(如总数为三台宕机两台),就会导致整合集群宕机,后期需要重新恢复数据,则恢复流程如下:
10.1 如果宕机导致机器没法开机了
(1)停止kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy。
(2)重新找机器部署ETCD集群。
(3)停止运行ETCD集群。
(4)各ETCD节点恢复同一份备份数据。
(5)启动各节点并验证ETCD集群(1主2从)。
(6)启动kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy。
(7)验证k8s master状态及pod数据。
10.2 如果意外宕机,能开机,但有数据丢失
(1)停止kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy。
(2)启动宕机的服务器,看etcd集群是否正常运行。
(3)停止运行ETCD集群。
(4)各ETCD节点恢复同一份备份数据。
(5)启动各节点并验证ETCD集群。
(6)启动kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy。
(7)验证k8s master状态及pod数据。
11. etcd集群节点删除和添加
工作中更多的还是数据备份恢复,一般不会涉及节点的扩容和缩容
# 具体过程看剧本
add-etcd
del-etcd
相关文章:
Etcd 常用命令与备份恢复
1. etcd简介 官方网站:etcd.io 官方文档:etcd.io/docs/v3.5/op-guide/maintenance 官方硬件推荐:etcd.io/docs/v3.5/op-guide/hardware github地址:github.com/etcd-io/etcd etcd是CoreOS团队于2013年6月发起的开源项目…...

获取任意时间段内周、季度、半年的二级联动
#需求是获取两个时间内 年周 、年季度、年半年的二级联动# 找了半天也找不到什么有用的信息 就自己简单写了一个 思路是先获取年的列表再去嵌套查询 根据前端VUE提供的格式嵌套 public function getDate(){$leixing Request::param(leixing);$larr array(1,2,3,4);if(empty(…...

前端面试系列之工程化篇
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 前端工程化 Webpack 概念 本质上,webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具。当 webpack 处理应用程序时,它会在内部从一个…...
京东按关键词搜索商品列表接口:竞品分析,商品管理,营销策略制定
京东搜索商品列表接口是京东开放平台提供的一种API接口,通过调用该接口,开发者可以获取京东平台上商品的列表数据,包括商品的标题、价格、库存、月销量、总销量、详情描述、图片等信息。 接口的主要作用包括: 市场调研ÿ…...
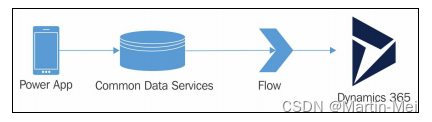
Microsoft Dynamics 365 CE 扩展定制 - 9. Dynamics 365扩展
在本章中,我们将介绍以下内容: Dynamics 365应用程序Dynamics 365通用数据服务构建Dynamics 365 PowerApp使用Flow在CDS和Dynamics 365之间移动数据从AppSource安装解决方案使用数据导出服务解决方案进行数据复制从CRM数据构建Power BI仪表板简介 多年来,Dynamics CRM已从一…...

多篇论文介绍-Wiou
论文地址 目录 https://arxiv.org/pdf/2301.10051.pdf 01 CIEFRNet:面向高速公路的抛洒物检测算法 02改进 YOLOv5 的 PDC 钻头复合片缺损识别 03 基于SimAM注意力机制的DCN-YOLOv5水下目标检测 04 基于改进YOLOv7-tiny 算法的输电线路螺栓缺销检测 05 基于改…...

Django介绍,安装,创建
文章目录 1. web应用程序1.1 什么是web?1.2 web应用程序的优点1.3 web应用程序的缺点1.4 什么是web框架? 2. 手撸web框架 1. web应用程序 1.1 什么是web? Web应用程序是一种可以通过Web访问的应用程序,用户只需要有浏览器即可,不需要再安装其他软件 案…...
)
Java通过javacv获取视频、音频、图片等元数据信息(分辨率、大小、帧等信息)
相信我们都会或多或少需要给前端返回视频或者音频的一些信息,那么今天这篇文章通过Java语言使用javacv来获取视频、音频、图片等元数据信息(分辨率、大小、帧等信息) 一、首先导入依赖 可以先导入javacv/javacv-platform依赖,由于依赖比较大,所以我们可以先去除部分不需…...

flask和fastapi的区别以及demo实现
flask和fastapi的区别以及demo实现 flask和fastapi的区别fastapi简单demoFastAPI包括全局异常捕捉和参数验证的demoflask和fastapi的区别 Flask:Flask是一个轻量级的Web框架,它提供了最基本的工具,可以自由选择其他库和组件来构建应用。灵活性:Flask允许用户自由选择数据库、…...
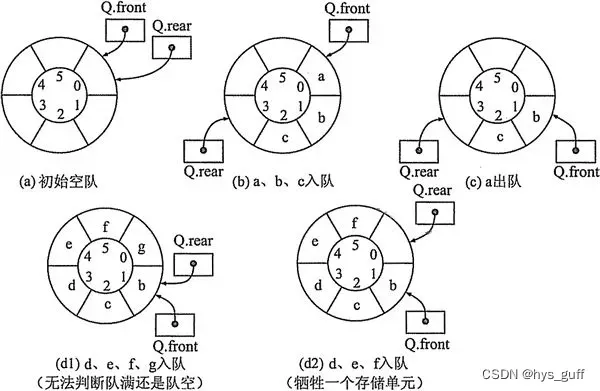
python特殊循环队列_队中元素个数代替队尾指针
对于循环队列来说,如果知道队头指针和队中元素个数,则可以计算出队尾指针。也就是说,可以用队中元素个数代替队尾指针。设计出这种循环队列的判队空、进队、出队和取队头元素的算法。 本例的循环队列包含data 数组、队头指针 front和队中元素…...
什么是观察者模式?用 Python 如何实现 Observer(观察者或发布订阅)对象行为型模式?
什么是观察者模式? 观察者模式(Observer pattern)是一种行为型设计模式,它允许对象之间建立一种一对多的依赖关系,当一个对象的状态发生变化时,其相关依赖对象都会得到通知并自动更新。 在观察者模式中&am…...
pytorch直线拟合
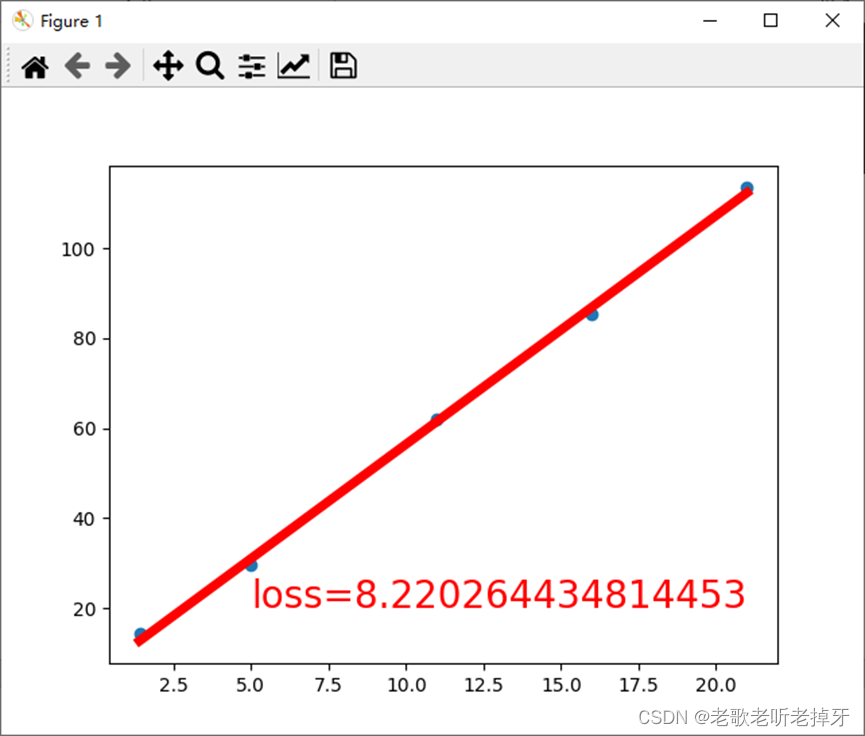
目录 1、数据分析 2、pytorch直线拟合 1、数据分析 直线拟合的前提条件通常包括以下几点: 存在线性关系:这是进行直线拟合的基础,数据点之间应该存在一种线性关系,即数据的分布可以用直线来近似描述。这种线性关系可以是数据点…...

相机传感器
相机的传感器大小通常用英寸(1英寸2.54厘米)来表示。例如:全画幅相机的传感器大小为:36mm*24mm,称为 35mm全画幅。 几分之一英寸 所谓的 1/2.7,1/2.5等等,里面的分子1是一个标准,分…...

大语言模型的关键技术
大语言模型的关键技术: 经过漫长的发展,LLM 进化到了当前的状态——通用且有能力的学习者。在这个过程中,人们提出了许多重要的技术,大大提升了 LLM 的能力。在此,我们简要列举了几种重要的技术,这些技术&a…...

uniapp使用vur-cli新建项目并打包
新建项目 npm install -g vue/cli vue create -p dcloudio/uni-preset-vue my-project选择默认模板npm run dev:h5 运行 安装sass和uview (npm安装失败) bug:使用uni.scss中的变量或样式,<style lang"scss"> 必…...

后台管理系统解决方案-中大型-Vben Admin
后台管理系统解决方案-中大型-Vben Admin 官网 Vben Admin 在线演示 Vben Admin 为什么选择它 github现有20K星,并且它有个可视化生成表单,我很喜欢 快速开始 # 拉取代码 git clone https://github.com/vbenjs/vue-vben-admin-doc# 安装依赖 yarn#…...

通俗理解repartition和coalesce区别
官方的解释 reparation 返回一个具有恰好numPartitions分区的新RDD。 可以增加或减少此RDD中的并行级别。在内部,reparation会使用shuffle来重新分发的数据。 如果要减少此RDD中的分区数量,请考虑使用coalesce,这样可以避免执行shuffle。 coalesce 返回一个新的RDD,该RDD被…...

优雅设计之美:实现Vue应用程序的时尚布局
本文为翻译文章,原文链接: ** https://fadamakis.com/clean-layout-architecture-for-vue-applications-a738201a2a1e 前言 页面布局是减少代码重复和创建可维护且具有专业外观的应用程序的基本模式。如果使用的是Nuxt,则可以提供开箱即用…...
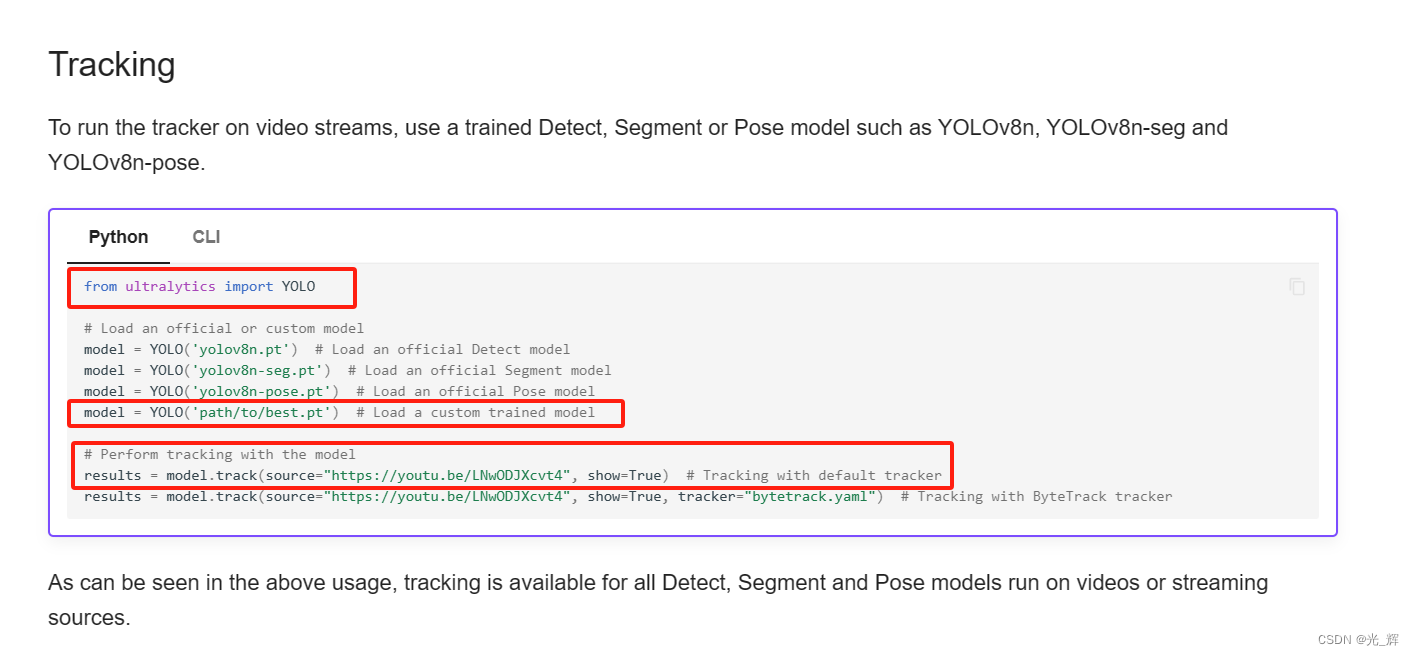
05预测识别-依托YOLO V8进行训练模型的识别——对视频中的目标进行跟踪统计
上文中详细介绍了如何对视频进行抽帧,并对帧的图像进行目标识别。但在日常工作中,我们也会遇到需要对目标进行跟踪统计的情况,比如我们需要连续统计某一类目标有多少个的时候,如果单纯从帧中抽取图像的话,系统将无法判断是否为同一目标,从而造成目标数量统计的重复,导致…...
)
Android Studio(意图Intent)
前言 意图的作用:页面的跳转(从一个页面跳转到另一个页面)。 意图的创建:需要哪些参数?首先,从哪个页面跳转到哪个页面;其二,跳转到另一个页面需要携带数据吗。 下面介绍顺序&#x…...

机器学习模型评估:训练集-测试集划分原理与实践
1. 机器学习模型评估中的训练集-测试集划分在机器学习项目中,我们经常需要评估模型在未知数据上的表现。训练集-测试集划分(Train-Test Split)是最基础也是最常用的模型评估方法之一。这种方法的核心思想很简单:将原始数据集分成两…...

基于开源LLM的生物医学智能体:从RAG到专业问答系统构建
1. 项目概述:当AI遇上生物医学文献如果你是一名生物信息学研究员、药物研发工程师,或者正在攻读生命科学相关学位的研究生,那么你肯定对PubMed、bioRxiv这类数据库又爱又恨。爱的是它们海量的前沿知识,恨的是每天面对动辄数百篇新…...
)
算子数学|独立完整学科章节(百条原创公式· ROOT传世定稿)
算子数学|独立完整学科章节(百条原创公式 ROOT传世定稿) 算子数学|独立完整学科章节(百条原创公式 ROOT传世定稿) 归属著作:算法联盟ROOT 本源数学一万公式典藏全书 章节编号:第十一…...

科技报告:基于弱监督BERT-CRF与知识元特征融合的专利价值评估研究
科技报告:基于弱监督BERT-CRF与知识元特征融合的专利价值评估研究 摘要 本研究围绕专利价值评估与知识元识别两大核心任务展开,构建了融合文献计量与深度学习方法的专利价值分析框架。首先,基于CSSCI/SSCI文献的系统梳理,构建了包含法律价值、技术价值、经济价值和战略价…...

RP2040实现I2C-USB桥接:低成本传感器数据采集方案
1. 项目概述:RP2040变身I2C-USB桥接器 去年在调试一个环境监测项目时,我遇到了一个棘手问题:需要将多个I2C传感器(温湿度、气压、空气质量)的数据实时采集到笔记本电脑进行分析,但手头的开发板没有USB主机…...

CentOS 7.9 离线安装 Docker 完整指南【20260425-002篇】
文章目录 一、准备:在能上网的 CentOS 7.9 上下载所有 rpm 1.1 配置 yum 源(阿里) 1.2 下载 Docker 及全部依赖(离线包) 1.3 打包 二、离线机安装(无网) 2.1 解压 2.2 离线安装(关键:用 yum localinstall 自动处理依赖) 三、配置 Docker 系统服务(systemd) 3.1 创建…...

如何将Flat Color Icons集成到React/Vue项目中:完整代码示例
如何将Flat Color Icons集成到React/Vue项目中:完整代码示例 【免费下载链接】flat-color-icons Free Flat Color Icons 项目地址: https://gitcode.com/gh_mirrors/fl/flat-color-icons Flat Color Icons是一套包含312个免费图标资源的开源项目,…...

RWKV7-1.5B-world多场景落地:边缘设备对话服务、RWKV架构教学、底座兼容验证
RWKV7-1.5B-world多场景落地:边缘设备对话服务、RWKV架构教学、底座兼容验证 1. RWKV7-1.5B-world模型概述 RWKV7-1.5B-world是基于第7代RWKV架构的轻量级双语对话模型,拥有15亿参数。该模型采用创新的线性注意力机制替代传统Transformer的自回归结构&…...

【工业级MCP网关开发白皮书】:基于C++20/Boost.Asio/FlatBuffers构建延迟<50μs的金融级网关
更多请点击: https://intelliparadigm.com 第一章:工业级MCP网关的设计目标与性能边界 工业级MCP(Modbus Control Protocol)网关并非普通协议转换桥接器,而是面向严苛生产环境构建的实时数据中枢。其核心使命是在毫秒…...

如何用Idle Master实现Steam卡片自动化收集:终极完整指南
如何用Idle Master实现Steam卡片自动化收集:终极完整指南 【免费下载链接】idle_master Get your Steam Trading Cards the Easy Way 项目地址: https://gitcode.com/gh_mirrors/id/idle_master 还在为收集Steam交易卡片而烦恼吗?每天手动切换游戏…...