kafka微服务学习
消息中间件对比:
1、吞吐、可靠性、性能

Kafka安装
Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper
- Docker安装zookeeper
下载镜像:
docker pull zookeeper:3.4.14
创建容器
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14
- Docker安装kafka
下载镜像:
docker pull wurstmeister/kafka:2.12-2.3.1
创建容器
docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.200.130 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.200.130:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.200.130:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
--net=host wurstmeister/kafka:2.12-2.3.1
kafka入门
- 生产者发送消息,多个消费者只能有一个消费者接收到消息
- 生产者发送消息,多个消费者都可以接收到消息
(1)创建kafka-demo项目,导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
(2)生产者发送消息
package com.heima.kafka.sample;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** 生产者*/
public class ProducerQuickStart {public static void main(String[] args) {//1.kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");//发送失败,失败的重试次数properties.put(ProducerConfig.RETRIES_CONFIG,5);//消息key的序列化器properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//2.生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);//封装发送的消息ProducerRecord<String,String> record = new ProducerRecord<String, String>("itheima-topic","100001","hello kafka");//3.发送消息producer.send(record);//4.关闭消息通道,必须关闭,否则消息发送不成功producer.close();}}
(3)消费者接收消息
package com.heima.kafka.sample;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** 消费者*/
public class ConsumerQuickStart {public static void main(String[] args) {//1.添加kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");//消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group2");//消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//2.消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);//3.订阅主题consumer.subscribe(Collections.singletonList("itheima-topic"));//当前线程一直处于监听状态while (true) {//4.获取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}}
kafka高可用设计
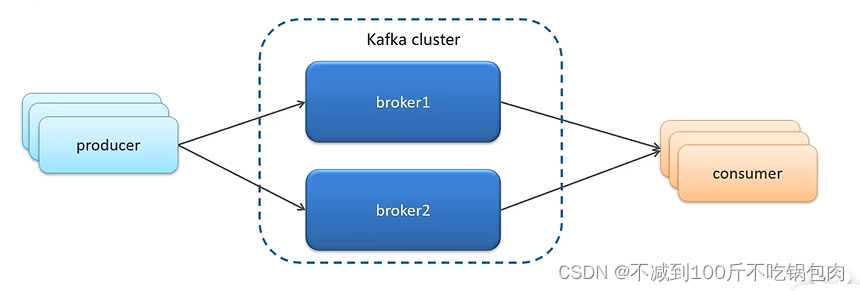
1、设计集群模式:
Kafka的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个Broker 组成。当一个机器宕机了,另外一个机器就会替补山
2、备份机制:
Kafka定义了两类副本
- 领导者副本(Leader Replica)
- 追随者副本 (Follower Replica)
追随者副本分为两类:
1、一种是ISR副本,同步保存
2、普通的副本,异步保存
出现主节点宕机,会先选ISR副本中的一个成为新的主节点,保证数据一致性,没有ISR节点,再从普通节点中挑选
针对全部节点宕机的情况,有两种策略:
1、等待第一个ISR副本,保证了数据的尽可能一致
2、等待一个复活的追随者,无论是ISR还是普通,提高系统的高可用性。
kafka生产者详解
1发送类型
-
同步发送
使用send()方法发送,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
RecordMetadata recordMetadata = producer.send(kvProducerRecord).get();
System.out.println(recordMetadata.offset());
-
异步发送
调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数
//异步消息发送
producer.send(kvProducerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(e != null){System.out.println("记录异常信息到日志表中");}System.out.println(recordMetadata.offset());}
});
2参数详解
- ack
代码的配置方式:
//ack配置 消息确认机制
prop.put(ProducerConfig.ACKS_CONFIG,"all");
参数的选择说明
| 确认机制 | 说明 |
|---|---|
| acks=0 | 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 |
| acks=1(默认值) | 只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应 |
| acks=all | 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 |
- retries
生产者从服务器收到的错误有可能是临时性错误,在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
代码中配置方式:
//重试次数
prop.put(ProducerConfig.RETRIES_CONFIG,10);
- 消息压缩
默认情况下, 消息发送时不会被压缩。
代码中配置方式:
//数据压缩
prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
| 压缩算法 | 说明 |
|---|---|
| snappy | 占用较少的 CPU, 却能提供较好的性能和相当可观的压缩比, 如果看重性能和网络带宽,建议采用 |
| lz4 | 占用较少的 CPU, 压缩和解压缩速度较快,压缩比也很客观 |
| gzip | 占用较多的 CPU,但会提供更高的压缩比,网络带宽有限,可以使用这种算法 |
使用压缩可以降低网络传输开销和存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。
kafka消费者
消息的有序性
方法:一个topic分区能保证自己的数据是按照先后消费的,但是不能保证跨分区消息处理的先后顺序。我么只能使用一个分区,在单分区种,消息可以保证严格顺序消费
提交和偏移量
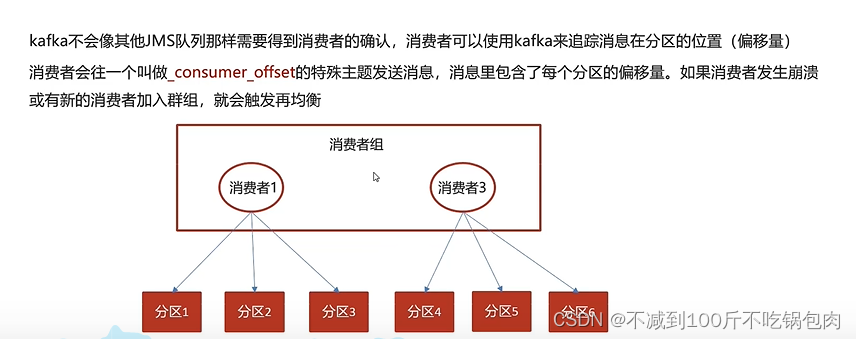
自动提交:
当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll0方法接收的最大偏移量提交上去,这样只是记录了规定时间内的最大偏移量,其实与数据提交的偏移量存在偏差,因此可能会出现数据的重复提交或者丢失
手动提交
当enableauto.commit被设置为false可以有以下三种提交方式
- 提交当前偏移量(同步提交)
- 异步提交
- 同步和异步组合提交
同步提交:commitSync()方法会一直尝试直至提交成功,如果提交失败也可以记录到错误日志里。
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());try {consumer.commitSync();//同步提交当前最新的偏移量}catch (CommitFailedException e){System.out.println("记录提交失败的异常:"+e);}}
}
异步提交:手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。消息没有重试机制
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.out.println("记录错误的提交偏移量:"+ map+",异常信息"+e);}}});
}
同步和异步组合提交
异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。相比较起来,同步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
举个例子,假如我们发起了一个异步提交commitA,此时的提交位移为2000,随后又发起了一个异步提交commitB且位移为3000;commitA提交失败但commitB提交成功,此时commitA进行重试并成功的话,会将实际上将已经提交的位移从3000回滚到2000,导致消息重复消费。
try {while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync();}
}catch (Exception e){+e.printStackTrace();System.out.println("记录错误信息:"+e);
}finally {try {consumer.commitSync();}finally {consumer.close();}
}
springboot整合kafka
1、在父类中的pop文件中导入依赖包
```xml
<!-- kafkfa -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
2、在需要用到kafka的微服务的naco中分别配置生产者和消费者配置
spring:kafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
spring:kafka:bootstrap-servers: 192.168.200.130:9092consumer:group-id: ${spring.application.name}key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
传递消息为对象
目前springboot整合后的kafka,因为序列化器是StringSerializer,这个时候如果需要传递对象可以有两种方式
方式一:可以自定义序列化器,对象类型众多,这种方式通用性不强,本章节不介绍
方式二:可以把要传递的对象进行转json字符串,接收消息后再转为对象即可,本项目采用这种方式
- 发送消息
@GetMapping("/hello")
public String hello(){User user = new User();user.setUsername("xiaowang");user.setAge(18);kafkaTemplate.send("user-topic", JSON.toJSONString(user));return "ok";
}
- 接收消息
package com.heima.kafka.listener;import com.alibaba.fastjson.JSON;
import com.heima.kafka.pojo.User;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;@Component
public class HelloListener {@KafkaListener(topics = "user-topic")public void onMessage(String message){if(!StringUtils.isEmpty(message)){User user = JSON.parseObject(message, User.class);System.out.println(user);}}
}
相关文章:
kafka微服务学习
消息中间件对比: 1、吞吐、可靠性、性能 Kafka安装 Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper Docker安装zookeeper 下载镜像: docker pull zookeeper:3.4.14创建容器 do…...
5G网络切片,到底是什么?
网络切片,是5G引入的一个全新概念。 一看到切片,首先想到的,必然是把一个完整的东西切成薄片。于是,切面包或者切西瓜这样的画面,映入脑海。 添加图片注释,不超过 140 字(可选) 然而…...

linux安装nodejs
写在前面 因为工作需要,需要使用到nodejs,所以这里简单记录下学习过程。 1:安装 wget https://nodejs.org/dist/v14.17.4/node-v14.17.4-linux-x64.tar.xz tar xf node-v14.17.4-linux-x64.tar.xz mkdir /usr/local/lib/node // 这一步骤根…...

第1天:Python基础语法(一)
** 1、Python简介 ** Python是一种高级、通用的编程语言,由Guido van Rossum于1989年创造。它被设计为易于阅读和理解,具有简洁而清晰的语法,使得初学者和专业开发人员都能够轻松上手。 Python拥有丰富的标准库,提供了广泛的功…...
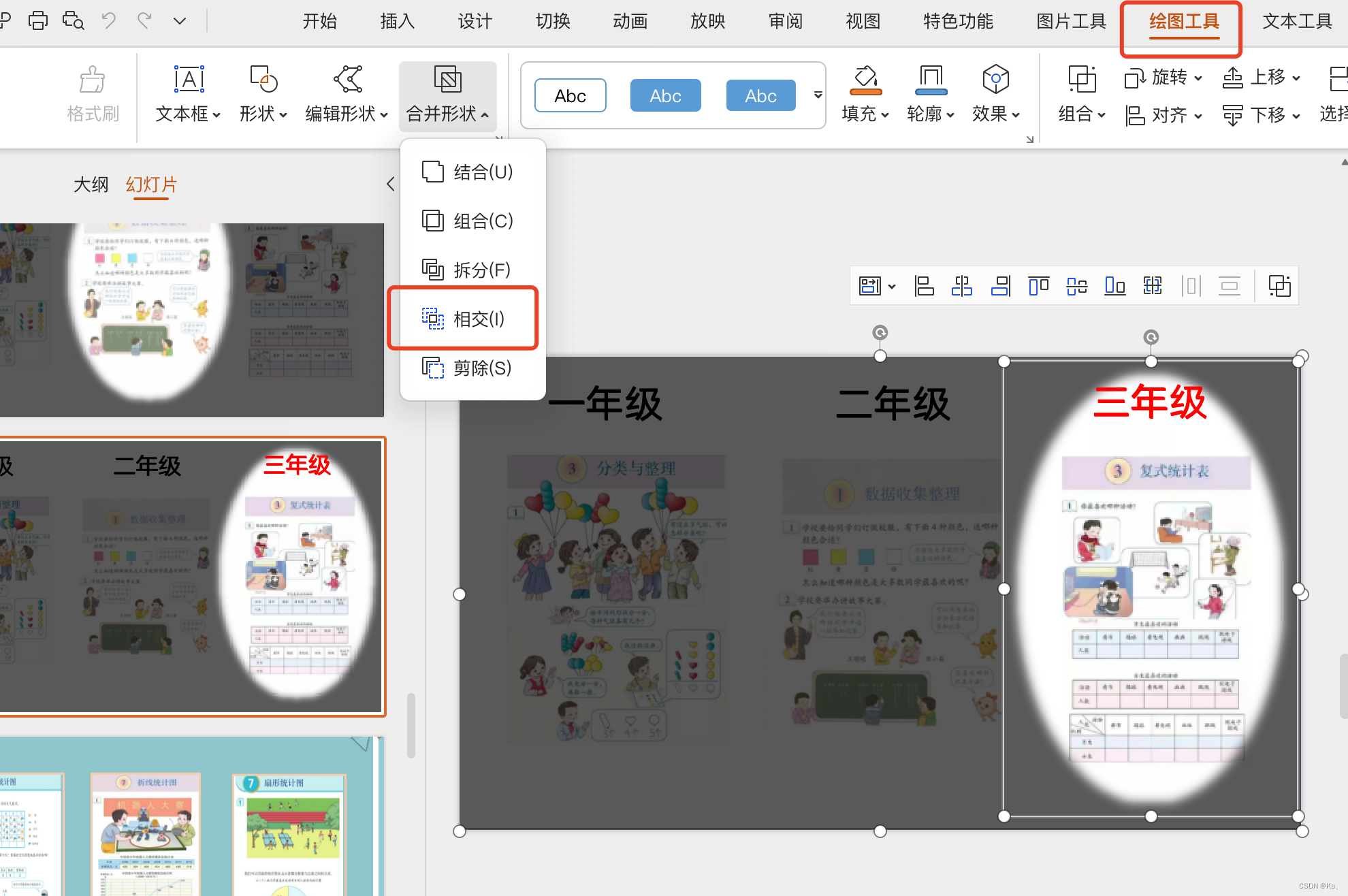
ppt聚光灯效果
1.放入三张图片内容或其他 2.全选复制成图片 3.设置黑色矩形,透明度30% 4.粘贴复制后的图片,制定图层 5.插入椭圆,先选中矩形,再选中椭圆,点击绘图工具,选择相交即可(关键)...

图文解析 Nacos 配置中心的实现
目录 一、什么是 Nacos 二、配置中心的架构 三、Nacos 使用示例 (一)官方代码示例 (二)Properties 解读 (三)配置项的层级设计 (四)获取配置 (五)注册…...

P1918 保龄球
Portal. 记录每一个瓶子数对应的位置即可。 注意到值域很大( a i ≤ 1 0 9 a_i\leq 10^9 ai≤109),要用 map 存储。 #include <bits/stdc.h> using namespace std;map<int,int> p;int main() {int n;cin>>n;for(int i…...
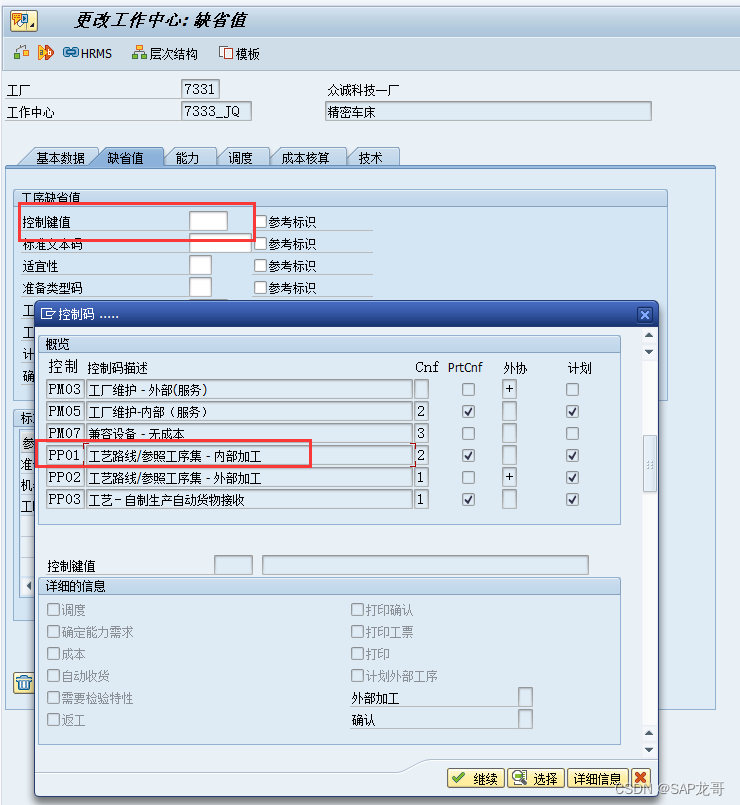
SAP-PP-报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在
创建工艺路线时报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在, 这是因为在创建工作中心时未维护控制键值导致的...
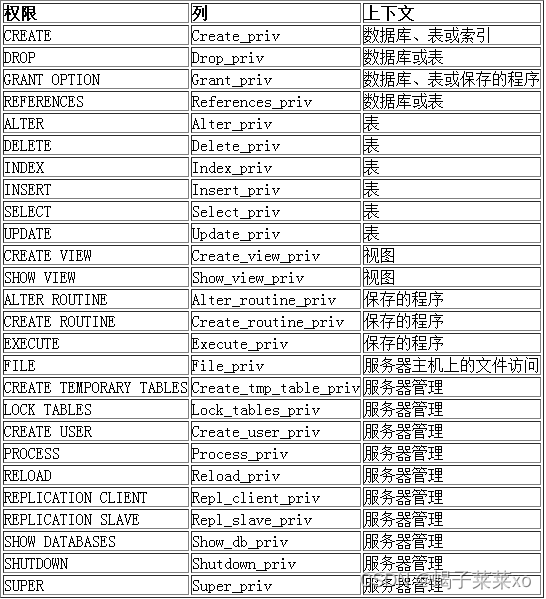
MySQL -- 用户管理
MySQL – 用户管理 文章目录 MySQL -- 用户管理一、用户1.用户信息2.创建用户3.删除用户4.远端登录MySQL5.修改用户密码6.数据库的权限 一、用户 1.用户信息 MySQL中的用户,都存储在系统数据库mysql的user表中: host: 表示这个用户可以从…...

IOS浏览器不支持对element ui table的宽度设置百分比
IOS浏览器不支持对element ui table的宽度设置百分比 IOS浏览器会把百分号识别成px,所以我们可以根据屏幕宽度将百分比转换成px getColumnWidth(data) {const screenWidth window.innerWidth;const desiredPercentage data;const widthInPixels (screenWidth *…...
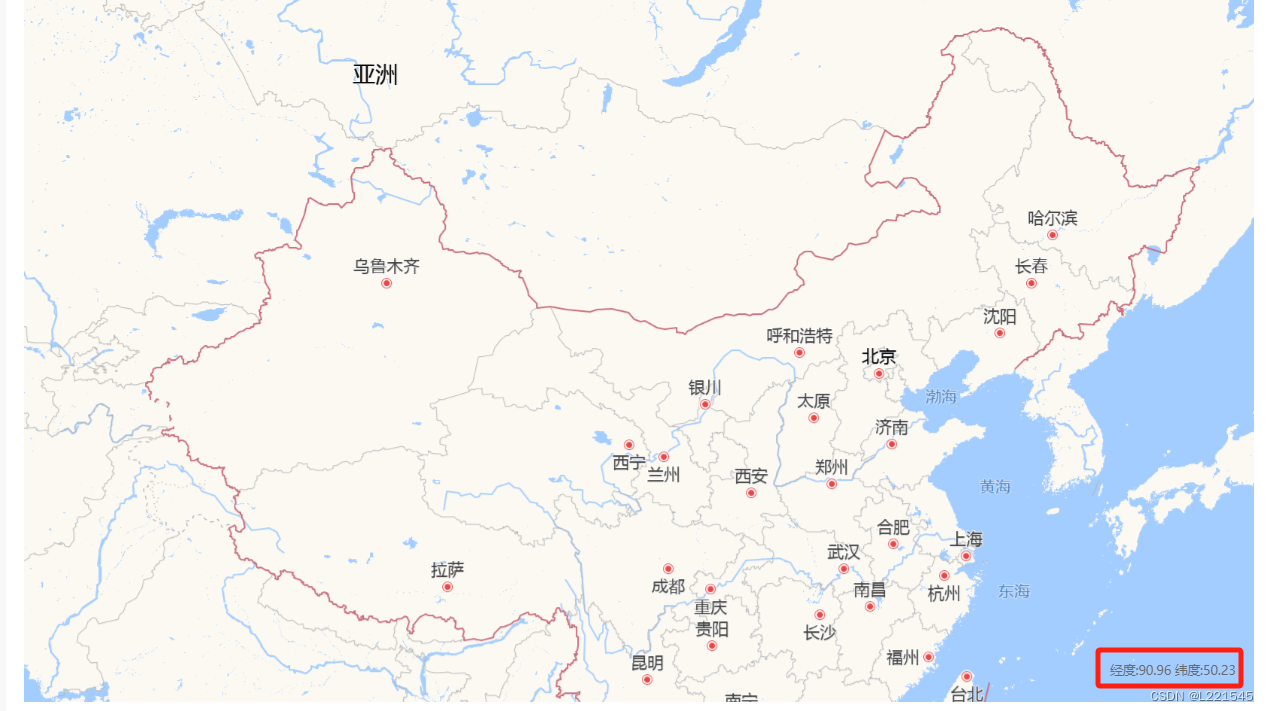
Vue+OpenLayers 创建地图并显示鼠标所在经纬度
1、效果 2、创建地图 本文用的是高德地图 页面 <div class"map" id"map"></div><div id"mouse-position" class"position_coordinate"></div>初始化地图 var gaodeLayer new TileLayer({title: "高德地…...

01-编码-H264编码原理
1.整体概念 编码的含义就是压缩,将摄像头采集的YUV或RGB数据压缩成H264。 压缩的过程就是去除信息冗余的过程,一般视频有如下的冗余信息。 (1)空间冗余:在同一个画面中,相邻的像素点之间的变化很小,因而可以用一个特定大小的矩阵来描述相邻的这些像素。 (2)时间冗余:…...
RxJava/RxAndroid的操作符使用(二)
文章目录 一、创建操作1、基本创建2、快速创建2.1 empty2.2 never2.3 error2.4 from2.5 just 3、定时与延时创建操作3.1 defer3.2 timer3.3 interval3.4 intervalRange3.5 range3.6 repeat 二、过滤操作1、skip/skipLast2、debounce3、distinct——去重4、elementAt——获取指定…...
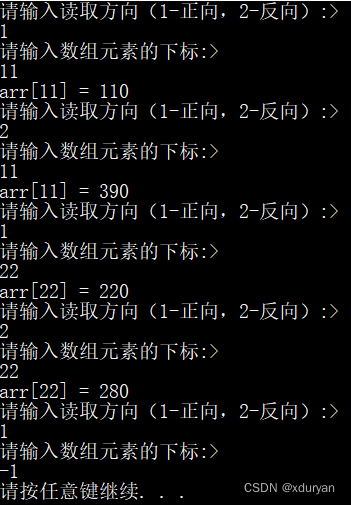
【C语法学习】20 - 文件访问顺序
文章目录 0 前言1 文件位置指示符2 rewind()函数2.1 函数原型2.2 参数2.3 返回值2.4 使用说明 3 ftell()函数3.1 函数原型3.2 参数3.3 返回值 4 fseek()函数4.1 函数原型4.2 参数4.3 返回值 5 示例5.1 示例15.2 示例2 0 前言 C语言文件访问分为顺序文件访问和随机文件访问。 …...
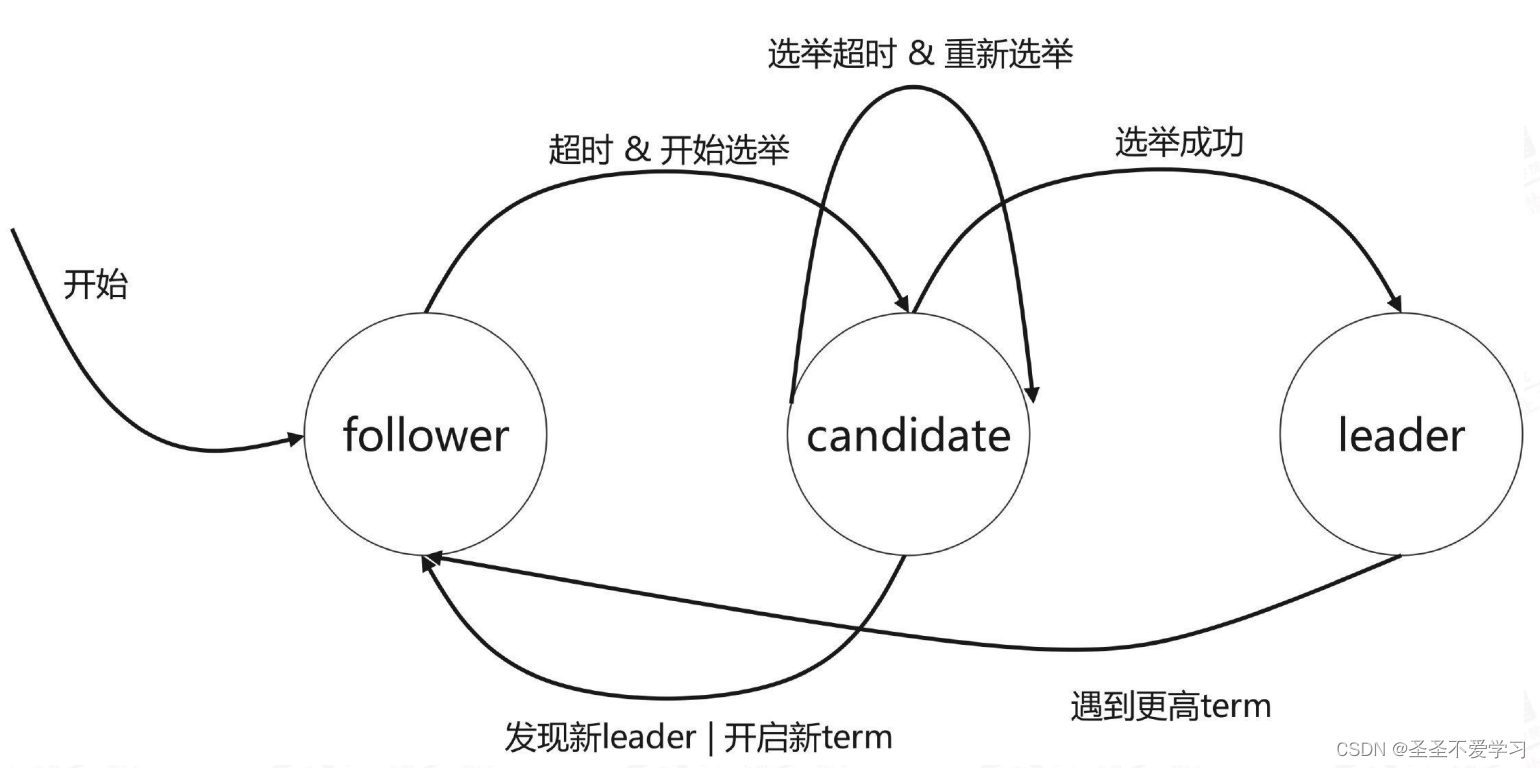
Etcd 常用命令与备份恢复
1. etcd简介 官方网站:etcd.io 官方文档:etcd.io/docs/v3.5/op-guide/maintenance 官方硬件推荐:etcd.io/docs/v3.5/op-guide/hardware github地址:github.com/etcd-io/etcd etcd是CoreOS团队于2013年6月发起的开源项目…...

获取任意时间段内周、季度、半年的二级联动
#需求是获取两个时间内 年周 、年季度、年半年的二级联动# 找了半天也找不到什么有用的信息 就自己简单写了一个 思路是先获取年的列表再去嵌套查询 根据前端VUE提供的格式嵌套 public function getDate(){$leixing Request::param(leixing);$larr array(1,2,3,4);if(empty(…...

前端面试系列之工程化篇
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 前端工程化 Webpack 概念 本质上,webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具。当 webpack 处理应用程序时,它会在内部从一个…...
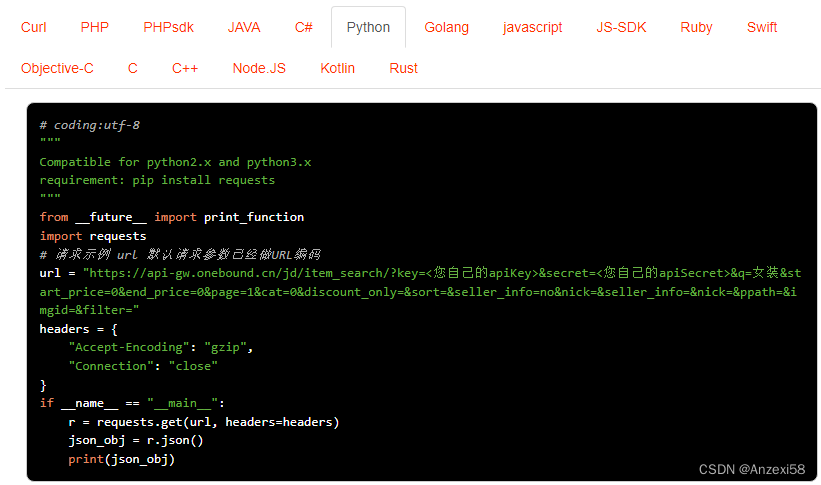
京东按关键词搜索商品列表接口:竞品分析,商品管理,营销策略制定
京东搜索商品列表接口是京东开放平台提供的一种API接口,通过调用该接口,开发者可以获取京东平台上商品的列表数据,包括商品的标题、价格、库存、月销量、总销量、详情描述、图片等信息。 接口的主要作用包括: 市场调研ÿ…...
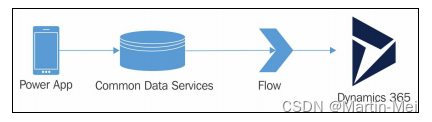
Microsoft Dynamics 365 CE 扩展定制 - 9. Dynamics 365扩展
在本章中,我们将介绍以下内容: Dynamics 365应用程序Dynamics 365通用数据服务构建Dynamics 365 PowerApp使用Flow在CDS和Dynamics 365之间移动数据从AppSource安装解决方案使用数据导出服务解决方案进行数据复制从CRM数据构建Power BI仪表板简介 多年来,Dynamics CRM已从一…...

多篇论文介绍-Wiou
论文地址 目录 https://arxiv.org/pdf/2301.10051.pdf 01 CIEFRNet:面向高速公路的抛洒物检测算法 02改进 YOLOv5 的 PDC 钻头复合片缺损识别 03 基于SimAM注意力机制的DCN-YOLOv5水下目标检测 04 基于改进YOLOv7-tiny 算法的输电线路螺栓缺销检测 05 基于改…...

【VSCode 2026农业可视化插件首发指南】:5大核心能力+3类真实农田数据落地案例,仅限首批内测开发者获取
更多请点击: https://kaifayun.com 第一章:VSCode 2026农业可视化插件发布背景与核心定位 随着智慧农业加速落地,田间传感器、无人机遥感、气象站及IoT边缘设备每日产生TB级时空数据,但开发者长期受限于专业GIS工具门槛高、轻量级…...

BepInEx游戏插件框架:3分钟解锁你的游戏无限可能 [特殊字符]
BepInEx游戏插件框架:3分钟解锁你的游戏无限可能 🎮 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 想为心爱的游戏添加新功能吗?厌倦了游戏的原…...

AI代码生成在《我的世界》中的应用:从自然语言到可执行程序
1. 项目概述:当AI学会在《我的世界》里“思考”如果你玩过《我的世界》,一定有过这样的体验:想造个中世纪城堡,结果对着空荡荡的平地发呆半小时,不知从何下手;或者想自动化农场,却对着红石电路抓…...

线性回归与XGBoost实战对比:原理与性能解析
1. 线性回归与XGBoost的实战对比:从原理到性能解析在房价预测、销量预估等实际业务场景中,回归模型的选择往往让数据科学从业者面临"简单模型够用就好"还是"复杂模型追求精度"的抉择。本文将以加州房价数据集为实验对象,…...

【相机内参标定实战】—— 从棋盘格到配置文件:手把手完成张正友标定
1. 为什么需要相机标定? 第一次接触计算机视觉项目时,我拿着USB相机拍了几张照片就直接开始做目标检测,结果发现检测框总是对不齐物体。后来才知道,就像人眼戴了度数不合适的眼镜会看不清东西一样,未经标定的相机拍出来…...

告别提取码烦恼:3分钟掌握百度网盘资源高效获取秘诀
告别提取码烦恼:3分钟掌握百度网盘资源高效获取秘诀 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而四处搜索吗?每次遇到需要密码的资源都要浪费宝贵时间在各种平台间…...

npm实战指南:从基础配置到高效开发
1. npm基础配置:从零搭建开发环境 第一次接触npm时,我完全被满屏的依赖关系搞懵了。直到后来才发现,只要掌握几个核心命令,就能快速搭建起开发环境。现在我就把这些年总结的配置经验分享给你。 安装Node.js时会自动附带npm&#x…...

从“能用”到“好用”,还有几道坎?——DeepSeek V4 遇上昇腾后的冷静追问
从“能用”到“好用”,还有几道坎?——DeepSeek V4 遇上昇腾后的冷静追问 2026年4月25日 | DeepSeek 华为昇腾 国产算力 产业观察前情提示:本文侧重于国产算力替代的商业化落地实证与冷静分析。对 DeepSeek V4 模型技术架构、昇腾适配细节…...
你还没用?)
VSCode 2026车载调试爆发式升级:5大原生支持新特性(Adaptive AUTOSAR调试器、UDS over DoIP直连、时间敏感网络TSN时序可视化)你还没用?
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026车载调试能力全景概览 VSCode 2026 版本深度整合了 AUTOSAR Adaptive 平台、ISO 26262 ASIL-B 级调试支持及车规级实时数据流可视化能力,成为首个原生支持 CAN FD、Ethernet AVB…...

网页截图革命:如何用Full Page Screen Capture解决长页面截图的三大技术难题
网页截图革命:如何用Full Page Screen Capture解决长页面截图的三大技术难题 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen…...