机器学习 - DBSCAN聚类算法:技术与实战全解析
目录
- 一、简介
- DBSCAN算法的定义和背景
- 聚类的重要性和应用领域
- DBSCAN与其他聚类算法的比较
- 二、理论基础
- 密度的概念
- 核心点、边界点和噪声点
- DBSCAN算法流程
- 邻域的查询
- 聚类的形成过程
- 参数选择的影响
- 三、算法参数
- eps(邻域半径)
- 举例说明:
- 如何选择:
- minPts(最小点数)
- 举例说明:
- 如何选择:
- 参数调优的技巧
- 实战技巧:
- 四、案例实战
- 场景描述
- 数据准备
- DBSCAN聚类
- 结果可视化
- 处理过程与输出
- 五、最佳实践
- 最佳适合使用场景
- 最佳方法
- 六、总结
探索DBSCAN算法的内涵与应用,本文详述其理论基础、关键参数、实战案例及最佳实践,揭示如何有效利用DBSCAN处理复杂数据集,突破传统聚类限制。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、简介
在机器学习的众多子领域中,聚类算法一直占据着不可忽视的地位。它们无需预先标注的数据,就能将数据集分组,组内元素相似度高,组间差异大。这种无监督学习的能力,使得聚类算法成为探索未知数据的有力工具。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是这一领域的杰出代表,它以其独特的密度定义和能力,处理有噪声的复杂数据集,揭示了数据中潜藏的自然结构。
DBSCAN算法的定义和背景
DBSCAN,全称为“基于密度的空间聚类的应用”,由Martin Ester, Hans-Peter Kriegel, Jörg Sander和Xiaowei Xu于1996年提出。不同于K-means等划分聚类算法,DBSCAN不需要事先指定簇的数量,它能够根据数据本身的特性,自动发现簇的数量。更重要的是,DBSCAN能识别任意形状的簇,同时将不属于任何簇的点标识为噪声,这对于现实世界中充满噪声和非线性分布的数据集尤为重要。
例如,考虑一个电商平台的用户购买行为数据集。用户群体根据购买习惯和兴趣可能形成不同的聚类,而这些聚类并非总是圆形或球形。DBSCAN能够识别用户群体的自然聚集,哪怕是最复杂的形状,如环形分布的用户聚类,这对于划分用户细分市场非常有用。
聚类的重要性和应用领域
聚类在很多领域都有着广泛的应用,从生物信息学中基因表达的分析到社交网络中社区的检测,从市场细分到图像和语音识别,它的用途多样而深远。每个聚类的发现都像是在数据的海洋中发现了一个个岛屿,它们代表着数据中的模式和结构。
DBSCAN与其他聚类算法的比较
与K-means这种经典聚类算法相比,DBSCAN的优势在于它不需要预设簇的数目,且对于簇的形状没有假设。想象在一个城市中有多个不同的聚会活动,每个活动吸引不同数量和类型的人群。K-means可能会将城市划分成几个大小相近的区域,而无视了每个聚会的实际分布情况。DBSCAN则更像是聪明的侦探,不预设任何犯罪模式,而是根据线索(数据点)自行发现犯罪团伙(数据簇)的大小和形状。
二、理论基础
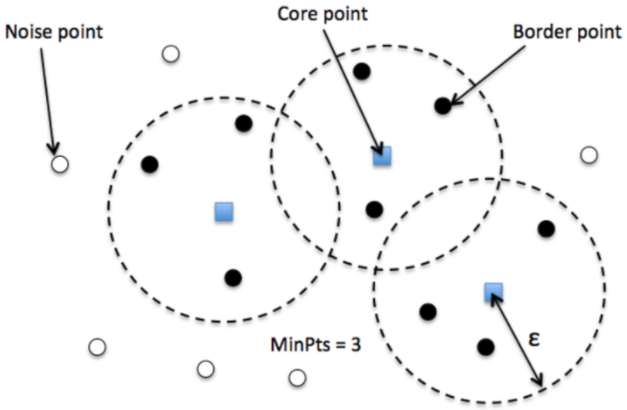
DBSCAN算法的魅力在于其简洁的定义与强大的实际应用能力。它通过两个简单的参数:邻域半径(eps)和最小点数(minPts),揭示了数据的内在结构。这一节将逐步深入这两个参数背后的理论基础,并通过贴近现实的例子,展现其在数据集上的应用。
密度的概念
在DBSCAN算法中,密度是由给定点在指定半径内邻域的点数来定义的。具体来说,如果一个点的eps-邻域内至少包含minPts数目的点,这个点就被视为核心点(core point)。这里,eps和minPts是算法的两个输入参数。
举个现实生活中的例子,想象我们要研究一个国家的城市化模式。我们可以将城市中的每个建筑物视作一个数据点,将eps设定为一个建筑物周围的距离(例如500米),minPts设为某个区域内建筑物的最小数量(例如50栋)。那么,任何在500米内有至少50栋其他建筑物的建筑都可以被视为“核心建筑”,指示着城市化的“核心区域”。
核心点、边界点和噪声点
在密度的定义下,DBSCAN算法将数据点分为三类:
- 核心点:如前所述,如果一个点的eps-邻域内包含至少minPts数目的点,它就是一个核心点。
- 边界点:如果一个点不是核心点,但在某个核心点的eps-邻域内,则该点是边界点。
- 噪声点:既不是核心点也不是边界点的点被视为噪声点。
以城市化的例子来说,那些周围建筑物较少但靠近“核心区域”的建筑可能是商店、小型办公室或独立住宅,它们是“边界建筑”。而那些偏远、孤立的建筑物就好比数据中的噪声点,它们可能是乡村的农舍或偏远的仓库。
DBSCAN算法流程
DBSCAN算法的执行流程可以分为以下步骤:
邻域的查询
对于数据集中的每个点,算法会计算其eps-邻域内的点数。这个过程类似于画家在画布上点画,每个点画都需要考虑其周围一定半径内的颜色深浅,以决定这一点的属性。
聚类的形成过程
- 选择核心点:如果一个点的eps-邻域内点数超过minPts,将其标记为核心点。
- 构建邻域链:对每个核心点,将它的eps-邻域内所有点(包括其他核心点)连接起来,形成一个聚类。
- 边界点的归属:将边界点分配给与之相连的核心点的聚类。
- 标记噪声:最后,未被归入任何聚类的点被标记为噪声。
回到我们的城市化例子,这就像是通过识别城市中的商业中心区域(核心区域),然后将与其相邻的居民区、商店(边界区域
)纳入同一城市规划单元,而那些偏离主要居民区的地方则被看作是未开发区域。
参数选择的影响
DBSCAN算法的效果在很大程度上取决于eps和minPts这两个参数的选择。参数的不同取值可能会导致聚类结果的显著变化。选择合适的参数需要对数据有一定的了解,通常需要通过多次尝试或基于领域知识进行决定。
以城市化模式研究为例,一个小国家的城市化密度(eps和minPts)与一个大国家可能大不相同。对于一个人口稠密的小岛国,较小的eps和minPts就足够揭示出城市化的核心区域。而对于一个地域辽阔的国家,则需要更大的参数值来捕捉广阔区域内的城市化趋势。
三、算法参数
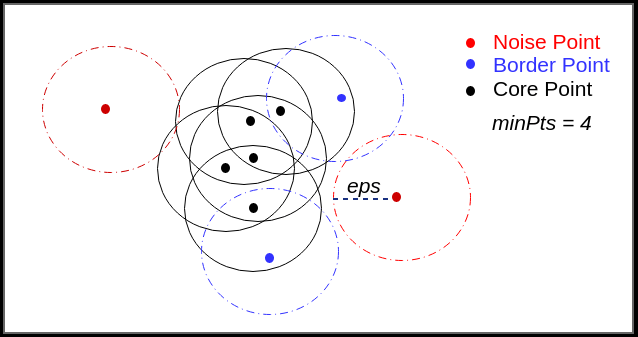
在DBSCAN算法中,参数的选取决定了算法能否正确地揭示数据的结构。这一节将深入探讨如何挑选合适的邻域半径(eps)和最小点数(minPts),并结合具体例子说明参数选择对聚类结果的影响。
eps(邻域半径)
eps是指点与点之间的最大距离,可以被视为一个点邻域的物理尺寸。选择较小的eps值可能导致聚类过于分散,而过大的eps值可能将本不属于同一类的点强行聚合在一起。
举例说明:
想象我们要分析一张客户分布的地图。如果我们把eps设定得太小,那么只有非常近距离的客户才会被认为是一组,这可能会忽略掉那些只是偶然间相距稍远的客户群体。相反,如果把eps设定得太大,那么本属于不同区域的客户也可能会被错误地分类为一组,从而失去了进行精确市场细分的机会。
如何选择:
选择eps的一个常见方法是使用k-距离图。简单来说,对于数据集中的每一个点,计算它与最近的k个点之间的距离,并绘制这些距离的图。通常,这个图会在合适的eps值处出现一个拐点。
minPts(最小点数)
minPts定义了一个点的邻域中需要有多少个点才能将其视为核心点。minPts的选择与数据的维度、密度和噪声水平密切相关。一般来说,更高的维度和噪声水平需要更大的minPts值。
举例说明:
设想我们在分析社交媒体上的用户群体,试图通过共同的兴趣和活动来发现自然形成的社区。如果minPts太低,我们可能会找到一些只由几个紧密相连的用户组成的“微社区”,但这些可能只是偶然的小圈子。如果minPts太高,我们可能会漏掉这些小但紧密的群体,只识别出大规模的社区,从而忽略了社交媒体动态的多样性。
如何选择:
一种方法是基于经验规则,比如将minPts设置为维度数加1,然而这只适用于较低维度数据。另一种方法是通过试验和领域知识来逐步调整,直到找到反映数据结构的minPts值。
参数调优的技巧
参数的调整不应该依靠猜测,而应该是一个基于数据探索的迭代过程。利用可视化工具来观察不同参数下的聚类结果,评估其对数据分布的合理性。
实战技巧:
- 数据探索:在调整参数之前,对数据进行彻底的探索,包括可视化和基础统计分析。
- 领域知识:利用领域知识来指导初步参数的选择。
- 迭代实验:进行一系列的实验,逐步调整参数,每次变化后都仔细分析聚类结果的变化
。
4. 效果评估:使用轮廓系数等指标评估聚类质量,而不仅仅依赖于视觉上的判断。
5. 工具应用:利用像Python中的sklearn库提供的工具来实现上述过程。
通过综合考虑eps和minPts参数,我们可以有效地利用DBSCAN进行数据的聚类分析。
四、案例实战
在本节中,我们将通过一个具体的案例来展示如何使用Python和sklearn库中的DBSCAN实现对合成数据集的聚类。我们将演示数据准备、DBSCAN参数的选择、聚类过程以及结果的可视化。
场景描述
假设我们有一组二维数据,代表某城市中的地标位置。我们希望通过DBSCAN算法识别出城市中的热点区域。这些热点区域可能代表商业中心、文化聚集地或其他人群密集的地方。
数据准备
首先,我们需要生成一个合成的二维数据集来模拟地标位置。
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler# 生成合成数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)# 数据标准化
X = StandardScaler().fit_transform(X)
DBSCAN聚类
选择DBSCAN的参数,并对数据进行聚类。
# DBSCAN算法实现
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_# 聚类结果的噪声数据点标记为-1
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
结果可视化
最后,我们使用matplotlib来可视化聚类的结果。
# 绘制聚类结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):if k == -1:# 黑色用于噪声点col = [0, 0, 0, 1]class_member_mask = (labels == k)# 绘制核心点xy = X[class_member_mask & core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=14)# 绘制非核心点xy = X[class_member_mask & ~core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=6)plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
在执行这段代码之后,输出将是聚类的数量和噪声点的数量,以及一幅图表,图表中不同颜色的点表示不同的簇,黑色点表示噪声。这些图像将帮助我们直观地理解DBSCAN在特定参数设置下是如何分隔数据点的。
处理过程与输出
通过上述步骤,我们得到了聚类的数量以及标识噪声的数据点。通过可视化的结果,我们可以看到算法如何将数据点分成不同的簇,以及如何识别出噪声。
注意,为了适应特定的数据集,可能需要对eps和min_samples参数进行调整。这需要根据实际数据和聚类结果的质量来进行迭代实验和优化。在现实世界的应用中,参数的选择往往依赖于对数据的理解和领域知识。
五、最佳实践

在本节中,我们将探讨DBSCAN算法的最佳实践,包括最适合使用DBSCAN的场景和方法。
最佳适合使用场景
DBSCAN作为一种基于密度的聚类算法,它在以下场景中表现尤为出色:
- 噪声数据较多的情况: DBSCAN能有效识别并处理噪声点,将其与核心点和边界点区分开。
- 簇形状多样性: 与基于距离的聚类算法(如K-means)不同,DBSCAN不假设簇在空间中是圆形的,因此能识别任意形状的簇。
- 簇大小不均: DBSCAN可以发现大小差异较大的簇,而不会像K-means那样倾向于发现大小相近的簇。
- 数据维度不高: 虽然DBSCAN可以应对多维数据,但当数据维度增加时,寻找合适的
eps值变得困难,且“维度的诅咒”可能导致算法效率降低。
最佳方法
为了最大化DBSCAN算法的效果,建议遵循以下方法:
-
参数选择: 仔细选择
eps和min_samples参数。使用领域知识和参数搜索技术,如网格搜索配合轮廓系数,来确定最佳参数。 -
数据预处理: 标准化数据以确保所有特征按相同的标准衡量,这对于基于距离的算法尤为重要。
-
维度选择: 对于高维数据,考虑使用PCA或其他降维技术以减少维度的诅咒影响。
-
可视化: 在可能的情况下,使用可视化工具来评估聚类效果。对于高维数据,可以使用t-SNE等降维可视化技术。
-
密度估计: 在确定
eps之前,使用KNN(K-Nearest Neighbors)距离图来估计数据的密度分布。 -
算法变体: 对于特定类型的数据集,可以考虑使用DBSCAN的变体,例如HDBSCAN,它对参数选择不那么敏感,能够自适应地确定
eps值。 -
并行处理: 针对大型数据集,利用DBSCAN的并行实现或近似算法来加速处理。
遵循这些最佳实践,您将能够更有效地应用DBSCAN算法,以解决实际的聚类问题。
六、总结
通过对DBSCAN聚类算法的深入探讨,我们不仅理解了其理论基础、核心参数和算法流程,而且通过实际案例实战了解了如何在实践中应用这一强大的工具。此外,我们还探讨了DBSCAN的最佳实践,为数据科学家提供了关于如何在各种情境中使用DBSCAN的实用建议。
在技术领域,DBSCAN的独特之处在于它对数据集中的簇形状和大小没有固定的假设,这让它在处理现实世界复杂数据时显得尤为重要。与此同时,DBSCAN提供了对噪声和异常值具有内在抵抗力的优点,这是许多其他聚类算法所不具备的。
不过,DBSCAN也不是万能的。在高维空间中,它的表现可能会因为距离度量变得不太可靠而大打折扣,这是所谓的“维度的诅咒”。另外,参数eps和min_samples的选择对算法的结果影响巨大,但这也提供了一个利用领域知识深入数据挖掘的机会。
从技术洞见的角度来看,DBSCAN的深度和灵活性提示我们在面对任何一种算法时,都不应仅仅关注其表面的应用,而应深究其背后的原理和假设。理解这些可以帮助我们更好地调整算法以适应特定的问题,从而解锁数据的真正潜力。
在人工智能和机器学习的迅猛发展中,聚类算法如DBSCAN是我们工具箱中的重要工具。通过本文的学习,读者应能够在理解其深度的同时,将这一工具应用于现实世界的问题,以及在未来的工作中进行进一步的探索和创新。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
机器学习 - DBSCAN聚类算法:技术与实战全解析
目录 一、简介DBSCAN算法的定义和背景聚类的重要性和应用领域DBSCAN与其他聚类算法的比较 二、理论基础密度的概念核心点、边界点和噪声点DBSCAN算法流程邻域的查询聚类的形成过程 参数选择的影响 三、算法参数eps(邻域半径)举例说明:如何选择…...
kafka微服务学习
消息中间件对比: 1、吞吐、可靠性、性能 Kafka安装 Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper Docker安装zookeeper 下载镜像: docker pull zookeeper:3.4.14创建容器 do…...
5G网络切片,到底是什么?
网络切片,是5G引入的一个全新概念。 一看到切片,首先想到的,必然是把一个完整的东西切成薄片。于是,切面包或者切西瓜这样的画面,映入脑海。 添加图片注释,不超过 140 字(可选) 然而…...

linux安装nodejs
写在前面 因为工作需要,需要使用到nodejs,所以这里简单记录下学习过程。 1:安装 wget https://nodejs.org/dist/v14.17.4/node-v14.17.4-linux-x64.tar.xz tar xf node-v14.17.4-linux-x64.tar.xz mkdir /usr/local/lib/node // 这一步骤根…...

第1天:Python基础语法(一)
** 1、Python简介 ** Python是一种高级、通用的编程语言,由Guido van Rossum于1989年创造。它被设计为易于阅读和理解,具有简洁而清晰的语法,使得初学者和专业开发人员都能够轻松上手。 Python拥有丰富的标准库,提供了广泛的功…...
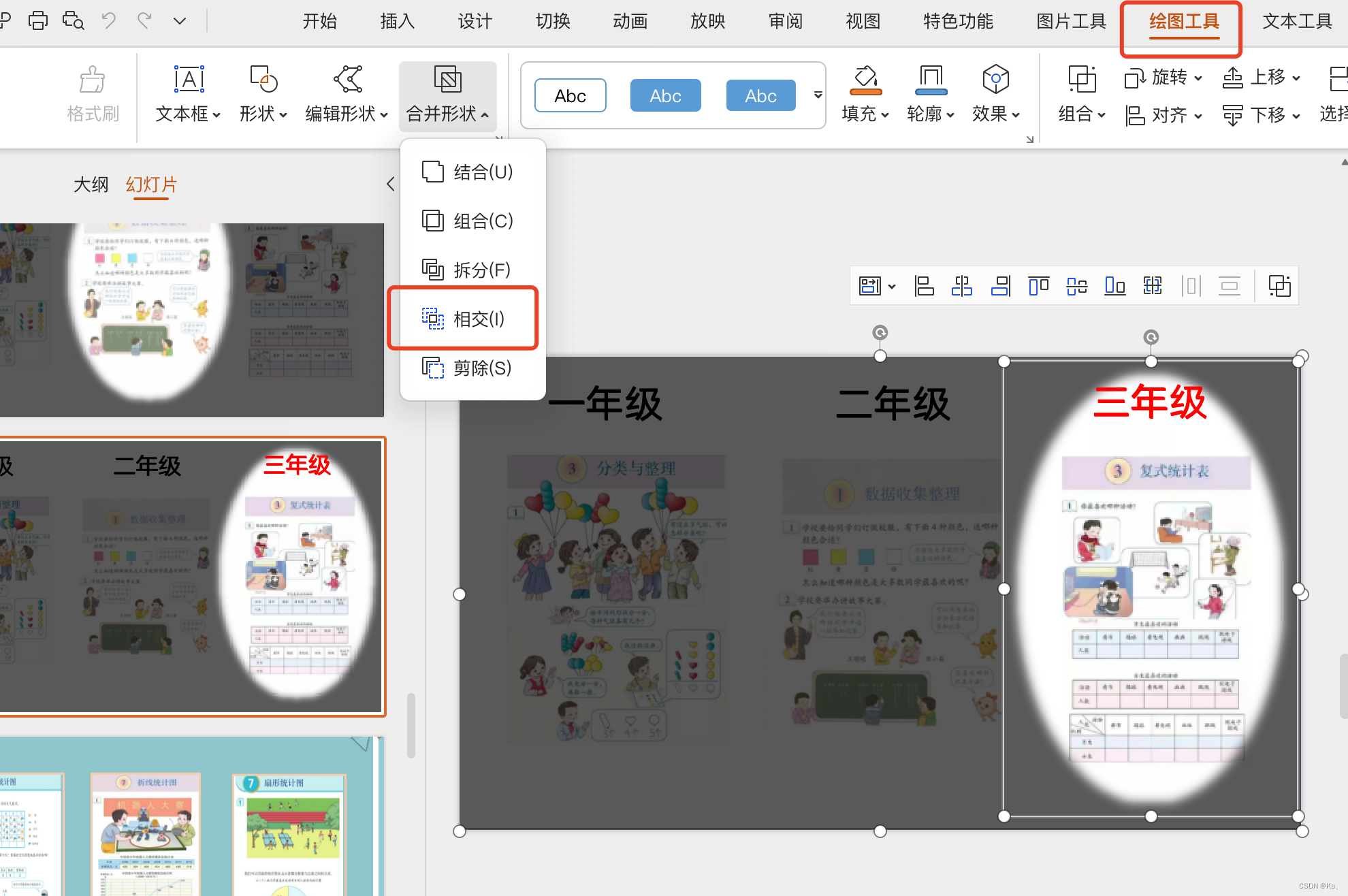
ppt聚光灯效果
1.放入三张图片内容或其他 2.全选复制成图片 3.设置黑色矩形,透明度30% 4.粘贴复制后的图片,制定图层 5.插入椭圆,先选中矩形,再选中椭圆,点击绘图工具,选择相交即可(关键)...

图文解析 Nacos 配置中心的实现
目录 一、什么是 Nacos 二、配置中心的架构 三、Nacos 使用示例 (一)官方代码示例 (二)Properties 解读 (三)配置项的层级设计 (四)获取配置 (五)注册…...

P1918 保龄球
Portal. 记录每一个瓶子数对应的位置即可。 注意到值域很大( a i ≤ 1 0 9 a_i\leq 10^9 ai≤109),要用 map 存储。 #include <bits/stdc.h> using namespace std;map<int,int> p;int main() {int n;cin>>n;for(int i…...
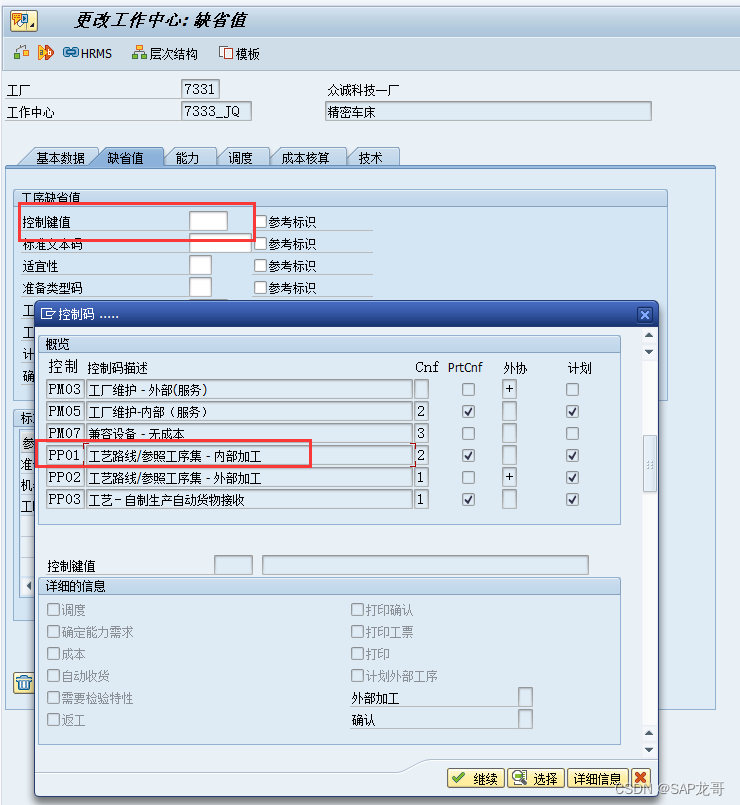
SAP-PP-报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在
创建工艺路线时报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在, 这是因为在创建工作中心时未维护控制键值导致的...
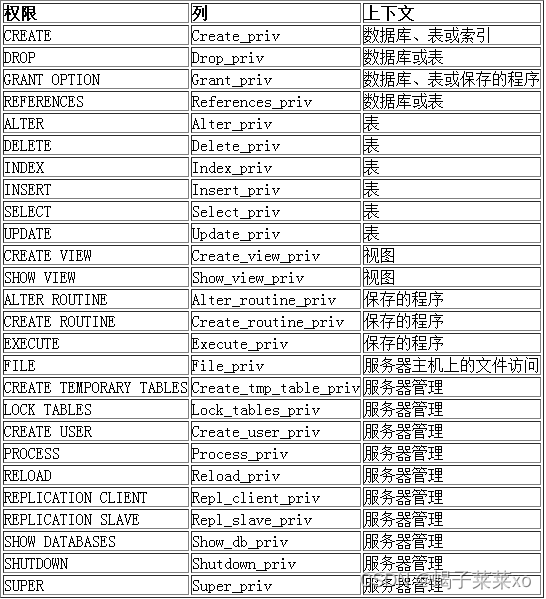
MySQL -- 用户管理
MySQL – 用户管理 文章目录 MySQL -- 用户管理一、用户1.用户信息2.创建用户3.删除用户4.远端登录MySQL5.修改用户密码6.数据库的权限 一、用户 1.用户信息 MySQL中的用户,都存储在系统数据库mysql的user表中: host: 表示这个用户可以从…...

IOS浏览器不支持对element ui table的宽度设置百分比
IOS浏览器不支持对element ui table的宽度设置百分比 IOS浏览器会把百分号识别成px,所以我们可以根据屏幕宽度将百分比转换成px getColumnWidth(data) {const screenWidth window.innerWidth;const desiredPercentage data;const widthInPixels (screenWidth *…...
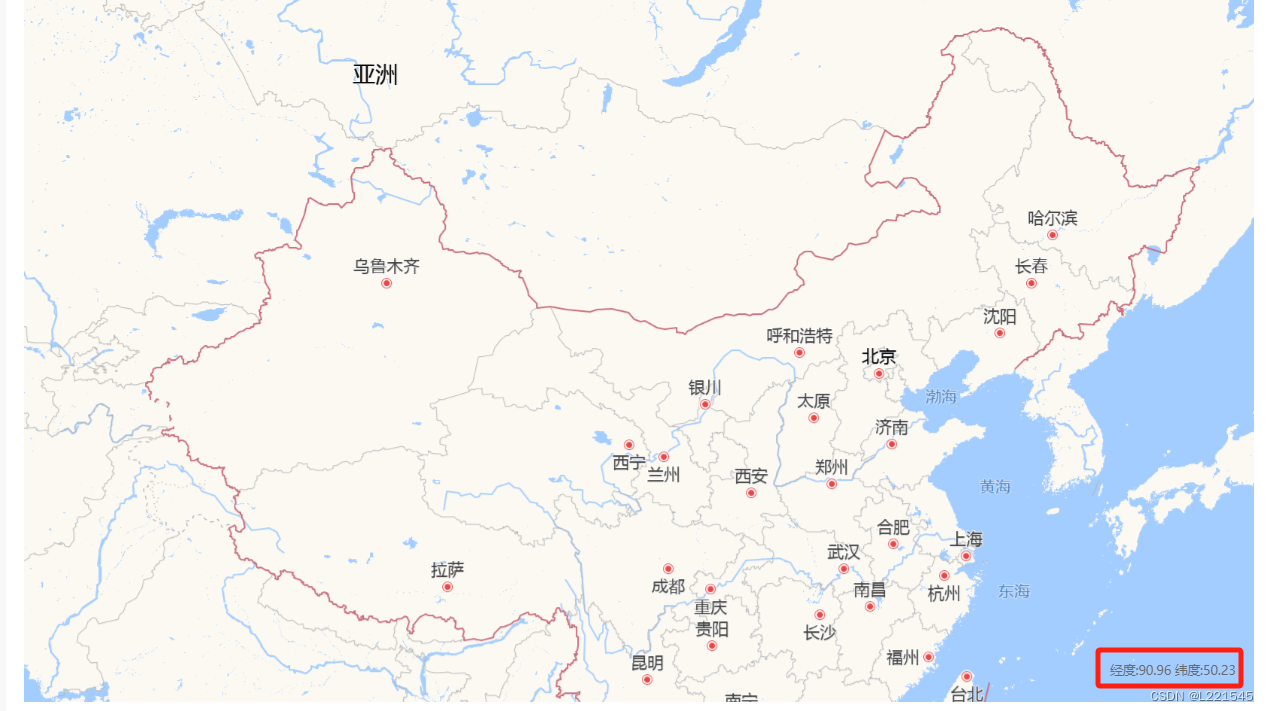
Vue+OpenLayers 创建地图并显示鼠标所在经纬度
1、效果 2、创建地图 本文用的是高德地图 页面 <div class"map" id"map"></div><div id"mouse-position" class"position_coordinate"></div>初始化地图 var gaodeLayer new TileLayer({title: "高德地…...

01-编码-H264编码原理
1.整体概念 编码的含义就是压缩,将摄像头采集的YUV或RGB数据压缩成H264。 压缩的过程就是去除信息冗余的过程,一般视频有如下的冗余信息。 (1)空间冗余:在同一个画面中,相邻的像素点之间的变化很小,因而可以用一个特定大小的矩阵来描述相邻的这些像素。 (2)时间冗余:…...
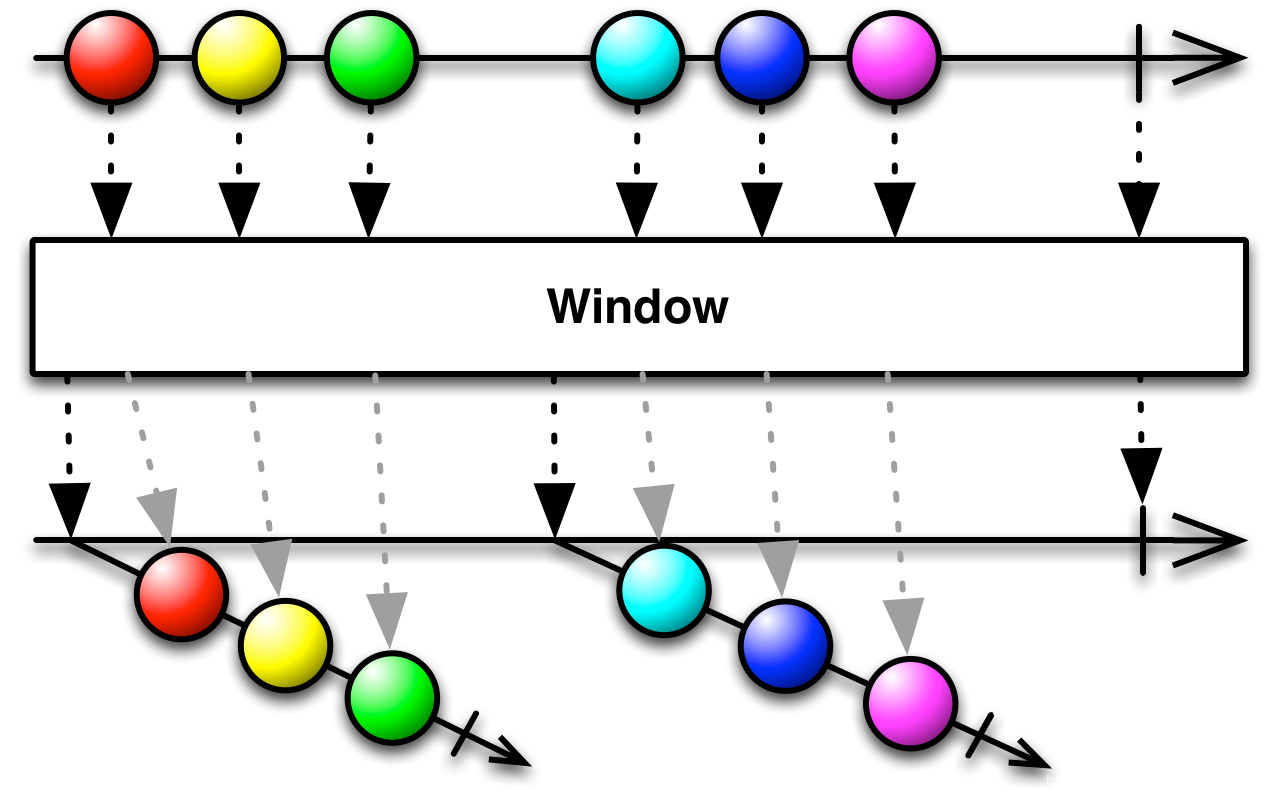
RxJava/RxAndroid的操作符使用(二)
文章目录 一、创建操作1、基本创建2、快速创建2.1 empty2.2 never2.3 error2.4 from2.5 just 3、定时与延时创建操作3.1 defer3.2 timer3.3 interval3.4 intervalRange3.5 range3.6 repeat 二、过滤操作1、skip/skipLast2、debounce3、distinct——去重4、elementAt——获取指定…...
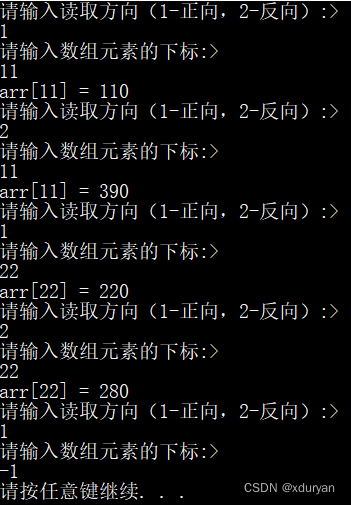
【C语法学习】20 - 文件访问顺序
文章目录 0 前言1 文件位置指示符2 rewind()函数2.1 函数原型2.2 参数2.3 返回值2.4 使用说明 3 ftell()函数3.1 函数原型3.2 参数3.3 返回值 4 fseek()函数4.1 函数原型4.2 参数4.3 返回值 5 示例5.1 示例15.2 示例2 0 前言 C语言文件访问分为顺序文件访问和随机文件访问。 …...
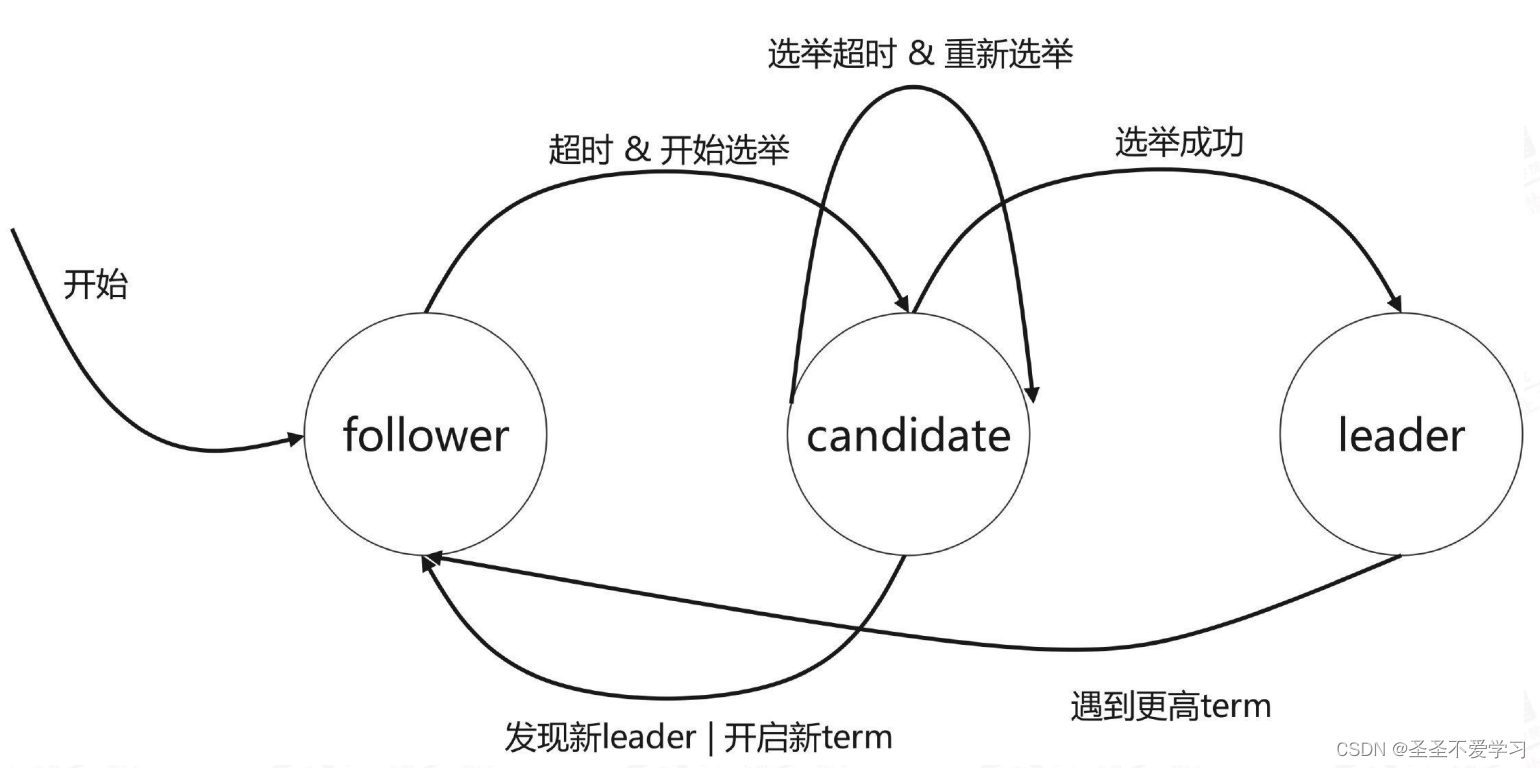
Etcd 常用命令与备份恢复
1. etcd简介 官方网站:etcd.io 官方文档:etcd.io/docs/v3.5/op-guide/maintenance 官方硬件推荐:etcd.io/docs/v3.5/op-guide/hardware github地址:github.com/etcd-io/etcd etcd是CoreOS团队于2013年6月发起的开源项目…...

获取任意时间段内周、季度、半年的二级联动
#需求是获取两个时间内 年周 、年季度、年半年的二级联动# 找了半天也找不到什么有用的信息 就自己简单写了一个 思路是先获取年的列表再去嵌套查询 根据前端VUE提供的格式嵌套 public function getDate(){$leixing Request::param(leixing);$larr array(1,2,3,4);if(empty(…...

前端面试系列之工程化篇
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 前端工程化 Webpack 概念 本质上,webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具。当 webpack 处理应用程序时,它会在内部从一个…...
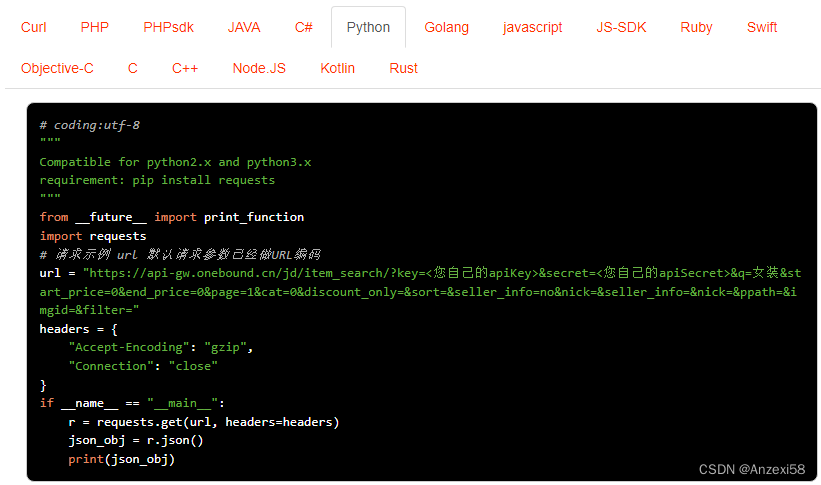
京东按关键词搜索商品列表接口:竞品分析,商品管理,营销策略制定
京东搜索商品列表接口是京东开放平台提供的一种API接口,通过调用该接口,开发者可以获取京东平台上商品的列表数据,包括商品的标题、价格、库存、月销量、总销量、详情描述、图片等信息。 接口的主要作用包括: 市场调研ÿ…...
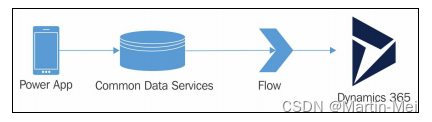
Microsoft Dynamics 365 CE 扩展定制 - 9. Dynamics 365扩展
在本章中,我们将介绍以下内容: Dynamics 365应用程序Dynamics 365通用数据服务构建Dynamics 365 PowerApp使用Flow在CDS和Dynamics 365之间移动数据从AppSource安装解决方案使用数据导出服务解决方案进行数据复制从CRM数据构建Power BI仪表板简介 多年来,Dynamics CRM已从一…...

MLP、CNN与RNN选型指南:深度学习三大经典网络解析
1. 神经网络选型指南:MLP、CNN与RNN的适用场景解析作为从业十余年的深度学习工程师,我经常被问到同一个问题:"我的项目该用哪种神经网络?"这确实是个值得深入探讨的话题。在本文中,我将结合工业界实战经验&a…...

中国汽车在俄罗斯市场下跌后,日本汽车迎来倍增,新的较量开始了
日前一家媒体在追踪丰田在中国市场的销量超越大众的数据时发现丰田悄然回归俄罗斯市场,并且已居于俄罗斯市场第七名,销量更是同比猛涨1.5倍,增速在俄罗斯前十大汽车品牌之中居于第一名,显示出日本汽车正悄然回归俄罗斯市场。由于众…...

ARM硬件断点与BREAKWRITE命令详解
1. ARM硬件断点与BREAKWRITE命令概述在ARM架构的嵌入式系统开发中,硬件断点(Hardware Breakpoint)是调试复杂实时系统的关键工具。与软件断点不同,硬件断点不修改目标代码,而是利用处理器内置的调试硬件来监控特定内存访问行为。BREAKWRITE作…...


云原生入门系列|第12集:K8s日常运维实战,新手也能稳管集群
前言 各位云原生入门的小伙伴,欢迎继续跟进《云原生入门系列》专栏!上一集我们掌握了K8s故障排查的核心方法,能快速定位并解决Pod、Service、存储等常见故障,避免业务中断。 但K8s的运维不止“排查故障”,更重要的是“日常管理”——就像养花草,不仅要在生病时治病,还…...

Cursor Pro破解工具深度解析:5步实现AI编程助手永久免费完整方案
Cursor Pro破解工具深度解析:5步实现AI编程助手永久免费完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reache…...

GPT-5.5降临:OpenAI打造最强智能体,引领AI工作新纪元!
北京时间 4 月 24 日凌晨,OpenAI 突然发布了 GPT-5.5,以及更高规格的 GPT-5.5 Pro。 这不是一次常规的小版本迭代。在 OpenAI 看来,GPT-5.5 不仅是他们最强的模型,更是新的智能模型,即专为真实工作和智能体任务打造的模…...

4点法、7点法、8点法、5点法——OpenCV多视图几何四大矩阵求解器源码深度拆解
两张不同角度拍摄的照片,怎么算出来场景的三维结构? 这个问题困扰了计算机视觉研究者三十多年。答案藏在三个矩阵里:单应性矩阵 H、基础矩阵 F、本质矩阵 E。OpenCV 为每一个矩阵都实现了专门的求解算法,它们分别需要 4 个、7 个(或 8 个)、5 个点对应。这些数字不是凭空…...

医疗器械管代的职责
医疗器械管代的职责 医疗器械管代(质量管理负责人)是医疗器械生产企业中负责质量管理体系建立、实施和保持的关键人员,主要职责包括以下几个方面: 质量管理体系建立与维护 负责组织制定、实施和保持符合医疗器械相关法规和标准的质…...

HunyuanVideo-FoleyAPI可观测性:Prometheus指标采集与Grafana看板
HunyuanVideo-FoleyAPI可观测性:Prometheus指标采集与Grafana看板 1. 引言 在视频和音效生成领域,HunyuanVideo-Foley作为一款强大的AI工具,其私有部署版本需要完善的可观测性方案来确保服务稳定运行。本文将详细介绍如何为HunyuanVideo-Fo…...