BP神经网络的数据分类——语音特征信号分类
大家好,我是带我去滑雪!
BP神经网络,也称为反向传播神经网络,是一种常用于分类和回归任务的人工神经网络(ANN)类型。它是一种前馈神经网络,通常包括输入层、一个或多个隐藏层和输出层。BP神经网络的分类任务涉及将输入数据分为不同的类别,其中每个类别由网络输出的一个节点表示。
目录
(1)BP神经网络的训练步骤
(2)语音特征识别分类
(3)模型建立
(4)数据选择与归一化
(5)BP神经网络结构初始化
(6)模型训练
(7)模型分类
(8)结果分析
(1)BP神经网络的训练步骤
BP神经网络的训练过程包括以下几个步骤:
- 输入层:输入层接收原始数据,将其传递给神经网络。每个输入节点对应于数据的一个特征或属性。
- 隐藏层:BP神经网络可以包含一个或多个隐藏层。隐藏层的目的是学习数据中的复杂模式和特征。每个隐藏层包含多个神经元,这些神经元通过权重和激活函数进行连接。
- 输出层:输出层产生网络的最终输出,通常对应于分类的不同类别。每个输出节点表示一个类别,并输出的值通常被解释为某个样本属于该类别的概率。
- 权重:在BP神经网络中,每个连接都有一个相关联的权重。这些权重是网络的参数,通过训练来学习。它们用于控制信号在网络中的传递和变换。
- 激活函数:每个神经元都包含一个激活函数,用于将神经元的输入转换为输出。常见的激活函数包括Sigmoid、ReLU(Rectified Linear Unit)和Softmax函数。
- 前向传播:前向传播是指从输入层到输出层的信息传递过程。每个神经元将其输入与相关的权重相乘,并将结果传递给激活函数。这一过程逐层进行,直到得到输出。
- 反向传播:反向传播是BP神经网络的关键部分。它使用损失函数来度量网络输出与实际目标之间的误差。然后,通过链式法则,误差被反向传播回网络,以调整权重,减小误差。这是通过梯度下降算法实现的,以最小化损失函数。
- 训练:训练是指通过提供大量已知的输入和目标输出数据来调整网络的权重,以使网络能够对新数据进行分类。训练通常涉及多次迭代的前向传播和反向传播过程。
- 预测:一旦网络经过训练,它可以用来对未知数据进行分类。输入数据传递到网络中,然后网络输出表示每个类别的概率或类别标签。
(2)语音特征识别分类
语音特征信号识别是一种技术,它涉及分析和识别从声音信号中提取出的语音特征。这些特征是声音信号中的可量化属性,有助于理解和识别说话者的身份、语言、情感、语速、音调和其他相关信息。语音特征信号识别在语音处理、语音识别、情感分析、说话者识别等领域中具有广泛的应用。
语音识别的运算过程为:首先,将待识别语音转化为电信号后输入识别系统,经过预处理后用数学方法提取语音特征信号,提取出的语音特征信号可以看成该段语音的模式;然后,将该段语音模型同已知参考模式相比较,获得最佳匹配的参考模式为该段语音的识别结果。
选取民歌、古筝、摇滚、流行四类不同音乐,用BP神经网络实现对这四类音乐的有效分类。每段音乐都用倒谱系数法(倒谱系数法的核心思想是将信号的频谱信息转化为倒谱域,以便更好地分析和处理信号的特征)提取500组24维语音特征信号,提出的语音特征信号。
(3)模型建立
由于语音特征输入信号有24维,待分类的语音信号有4类,所以将BP神经网络的结构设置为24-25-4,即输入层有24个节点,隐含层有25个节点,输出层有4个节点。BP神经网络训练用训练数据训练BP神经网络,由于一共有2000组的语音特征信号,从中随机选择1500组作为训练数据训练神经网络,500组数据作为测试数据测试网络分类能力。BP神经网络再用训练好的神经网络对测试数据所属语音类别进行分类。
(4)数据选择与归一化
首先根据倒谱系数法提取四类音乐特征信号,不同的语音信号分别用1、2、3、4标识,提取的信号分别存储于data1.mat、data2.mat、data3.mat、data4.mat数据库文件中,每组数据为25维,第一维为类别标识,后24维为语音特征信号。对汇总后的数据进行归一化处理。根据语音类别标识设定每组语音信号的期望输出值,如标识类为1,期望输出向量为[1,0,0,0]。
%% 清空环境变量
clc
clear%% 训练数据预测数据提取及归一化%下载四类语音信号
load data1 c1
load data2 c2
load data3 c3
load data4 c4%四个特征信号矩阵合成一个矩阵
data(1:500,:)=c1(1:500,:);
data(501:1000,:)=c2(1:500,:);
data(1001:1500,:)=c3(1:500,:);
data(1501:2000,:)=c4(1:500,:);%从1到2000间随机排序
k=rand(1,2000);
[m,n]=sort(k);%输入输出数据
input=data(:,2:25);
output1 =data(:,1);%把输出从1维变成4维
output=zeros(2000,4);
for i=1:2000switch output1(i)case 1output(i,:)=[1 0 0 0];case 2output(i,:)=[0 1 0 0];case 3output(i,:)=[0 0 1 0];case 4output(i,:)=[0 0 0 1];end
end%随机提取1500个样本为训练样本,500个样本为预测样本
input_train=input(n(1:1500),:)';
output_train=output(n(1:1500),:)';
input_test=input(n(1501:2000),:)';
output_test=output(n(1501:2000),:)';%输入数据归一化
[inputn,inputps]=mapminmax(input_train);
(5)BP神经网络结构初始化
根据语音特征信号的特点确定BP神经网络的结构为24-25-4,随机初始化BP神经网络权值和阈值。
innum=24;
midnum=25;
outnum=4;%权值初始化
w1=rands(midnum,innum);
b1=rands(midnum,1);
w2=rands(midnum,outnum);
b2=rands(outnum,1);w2_1=w2;w2_2=w2_1;
w1_1=w1;w1_2=w1_1;
b1_1=b1;b1_2=b1_1;
b2_1=b2;b2_2=b2_1;%学习率
xite=0.1;
alfa=0.01;
loopNumber=10;
I=zeros(1,midnum);
Iout=zeros(1,midnum);
FI=zeros(1,midnum);
dw1=zeros(innum,midnum);
db1=zeros(1,midnum);(6)模型训练
使用训练数据训练模型,在训练过程中根据网络预测误差调整网络的权值和阈值。
E=zeros(1,loopNumber);
for ii=1:10E(ii)=0;for i=1:1:1500%% 网络预测输出 x=inputn(:,i);% 隐含层输出for j=1:1:midnumI(j)=inputn(:,i)'*w1(j,:)'+b1(j);Iout(j)=1/(1+exp(-I(j)));end% 输出层输出yn=w2'*Iout'+b2;%% 权值阀值修正%计算误差e=output_train(:,i)-yn; E(ii)=E(ii)+sum(abs(e));%计算权值变化率dw2=e*Iout;db2=e';for j=1:1:midnumS=1/(1+exp(-I(j)));FI(j)=S*(1-S);end for k=1:1:innumfor j=1:1:midnumdw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));endendw1=w1_1+xite*dw1'+alfa*(w1_1-w1_2);b1=b1_1+xite*db1'+alfa*(b1_1-b1_2);w2=w2_1+xite*dw2'+alfa*(w2_1-w2_2);b2=b2_1+xite*db2'+alfa*(b2_1-b2_2);w1_2=w1_1;w1_1=w1;w2_2=w2_1;w2_1=w2;b1_2=b1_1;b1_1=b1;b2_2=b2_1;b2_1=b2;end
end(7)模型分类
使用已经训练后的BP神经网络模型分类语音特征信号,根据分类结果分析BP神经网络的分类能力。
output_fore=zeros(1,500);
for i=1:500output_fore(i)=find(fore(:,i)==max(fore(:,i)));
end%BP网络预测误差
error=output_fore-output1(n(1501:2000))';%画出预测语音种类和实际语音种类的分类图
figure(1)
plot(output_fore,'r')
hold on
plot(output1(n(1501:2000))','b')
legend('预测语音类别','实际语音类别')%画出误差图
figure(2)
plot(error)
title('BP网络分类误差','fontsize',12)
xlabel('语音信号','fontsize',12)
ylabel('分类误差','fontsize',12)%print -dtiff -r600 1-4k=zeros(1,4);
%找出判断错误的分类属于哪一类
for i=1:500if error(i)~=0[b,c]=max(output_test(:,i));switch ccase 1 k(1)=k(1)+1;case 2 k(2)=k(2)+1;case 3 k(3)=k(3)+1;case 4 k(4)=k(4)+1;endend
end%找出每类的个体和
kk=zeros(1,4);
for i=1:500[b,c]=max(output_test(:,i));switch ccase 1kk(1)=kk(1)+1;case 2kk(2)=kk(2)+1;case 3kk(3)=kk(3)+1;case 4kk(4)=kk(4)+1;end
end%正确率
rightridio=(kk-k)./kk;(8)结果分析
BP神经网络分类误差如下图所示。
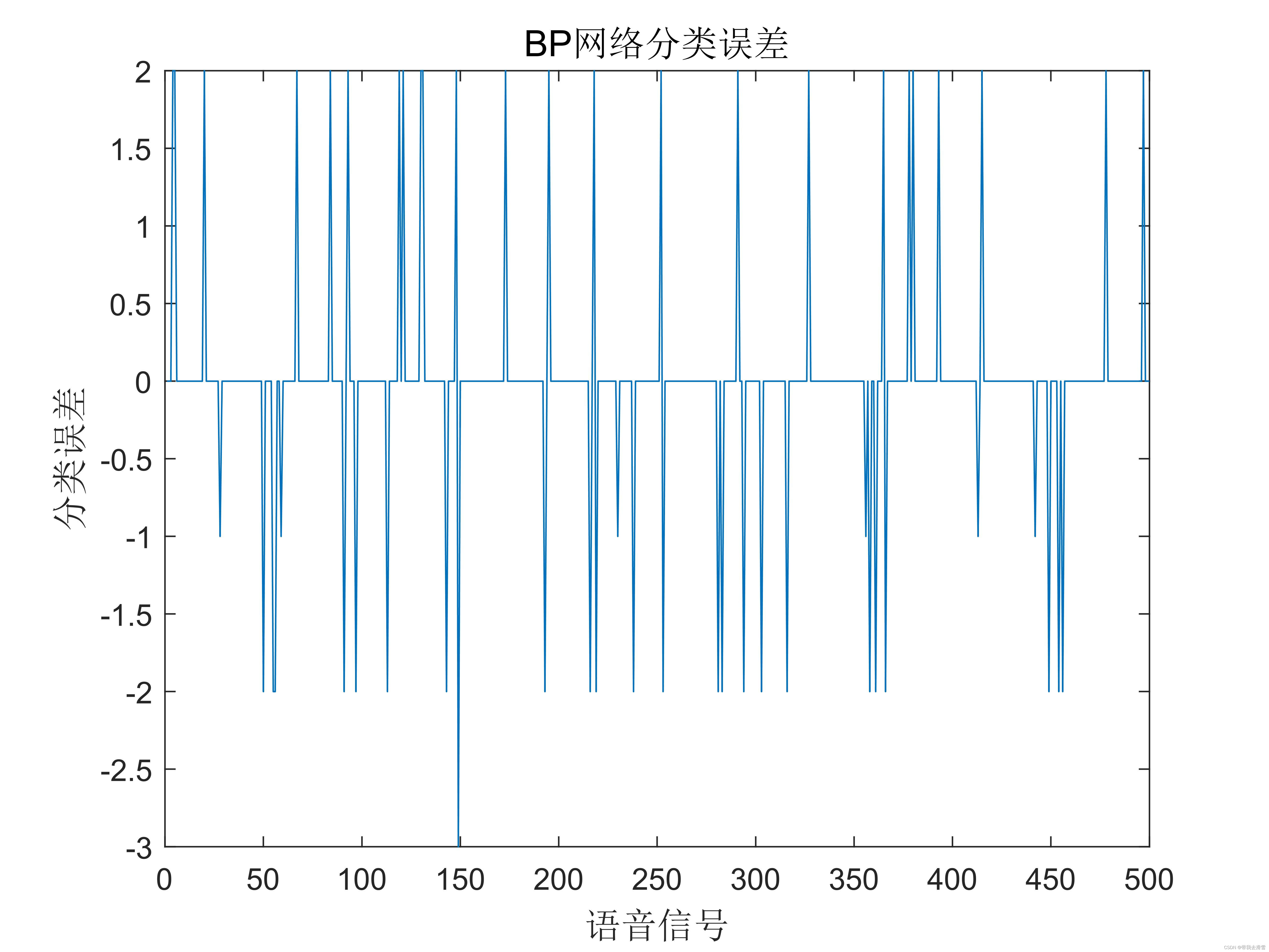
BP神经网络的分类正确率为:
| 语音信号识别 | 第一类 | 第二类 | 第三类 | 第四类 |
| 正确率 | 0.8049 | 1 | 0.8702 | 0.8984 |
通过分类结果的准确率可以发现,基于BP神经网络的语音信号分类算法具有较高的准确性,能够准确识别出语音信号所属类别。
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!
相关文章:
BP神经网络的数据分类——语音特征信号分类
大家好,我是带我去滑雪! BP神经网络,也称为反向传播神经网络,是一种常用于分类和回归任务的人工神经网络(ANN)类型。它是一种前馈神经网络,通常包括输入层、一个或多个隐藏层和输出层。BP神经网…...
基于SSM+Vue的随心淘网管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
)
大语言模型的关键技术(二)
一、Transformer 语言模型存在明显的扩展效应: 更大的模型/数据规模和更多的训练计算通常会导致模型能力的提升。 1、扩展效应的原因: 模型规模:增加模型的规模,即增加模型的参数数量和层数,通常会提高模型的表示能力…...

世界互联网大会领先科技奖发布 百度知识增强大语言模型关键技术获奖
11月8日,2023年世界互联网大会乌镇峰会正式开幕,今年是乌镇峰会举办的第十年,本次峰会的主题为“建设包容、普惠、有韧性的数字世界——携手构建网络空间命运共同体”。 目录 百度知识增强大语言模型关键技术荣获“世界互联网大会领先科技奖”…...
2023.11.09 homework (2)
【七年级上数学】 教别人也是教自己,总结下: 13)找规律的题目,累加题目,要整体看,不然不容易算出来,求最大值,那么就是【最大值集群和】减去【最小集群和】就是最大值 9-12&#x…...
ARMday01(计算机理论、ARM理论)
计算机理论 计算机组成 输入设备、输出设备、运算器、控制器、存储器 1.输入设备:将编写好的软件代码以及相关的数据输送到计算机中,转换成计算机能够识别、处理和存储的数据形式 键盘、鼠标、手柄、扫描仪、 2.输出设备:将计算机处理好的数…...

C#中通过LINQtoXML加载、创建、保存、遍历XML和修改XML树
目录 一、加载、创建、保存、遍历XML 1.加载XML (1)从已有文件加载XML (2)从字符串加载XML 2.创建并保存XML 3.遍历XML 4.示例源码 5.运行 二、修改XML的树 1.添加节点 2.删除 3.更新 4.示例源码 5.运行效果 三、…...
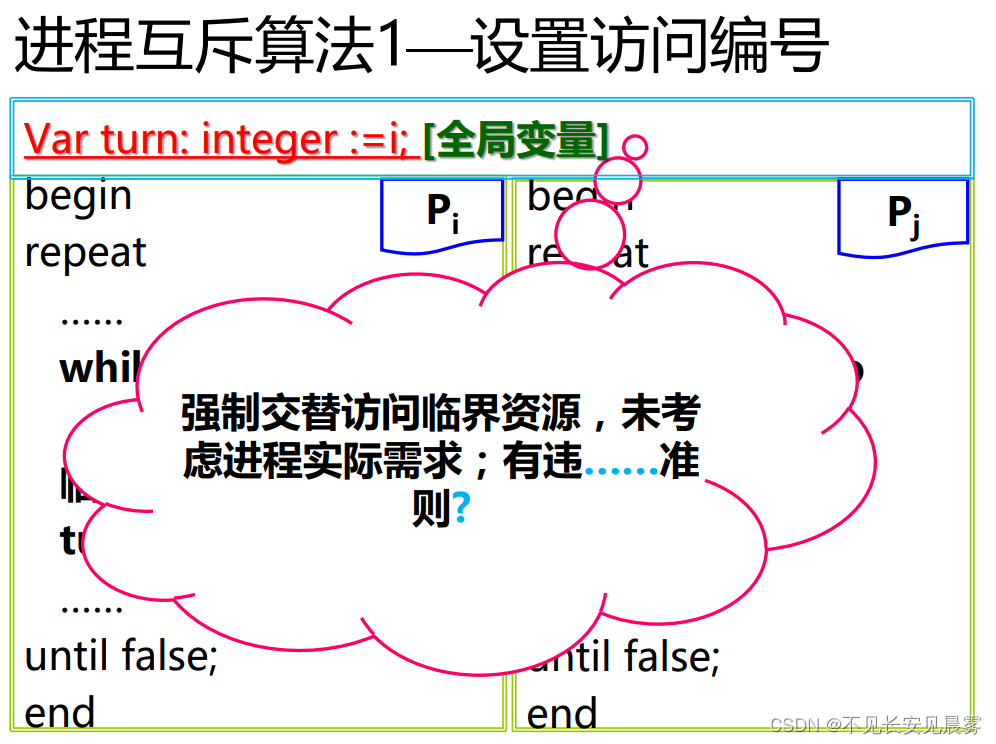
进程管理(二)
进程并发制约关系及临界区 (3)比如A的n为MAX,此时B执行buf[Max]出错。 临界区是访问临界资源的代码。 par并发执行 进程同步机制准则 让权等待:主动让位 进程互斥访问临界资源的软件解决方案 算法1——设置访问编号 no_op是空指令,做空操作,空转指令。no_op依然会占…...

数字图像处理 基于numpy库的傅里叶变换
一、傅里叶变换 图像可以用两个域表示:空间域和频域。空间域是图像最常见的表示形式,其中像素值表示图像中每个点的亮度或颜色。另一方面,频域将图像表示为不同频率和幅度的正弦波的集合。 傅里叶变换(一种图像处理中使用的数学技术)可以通过分析图像的频率分量并揭示隐藏…...
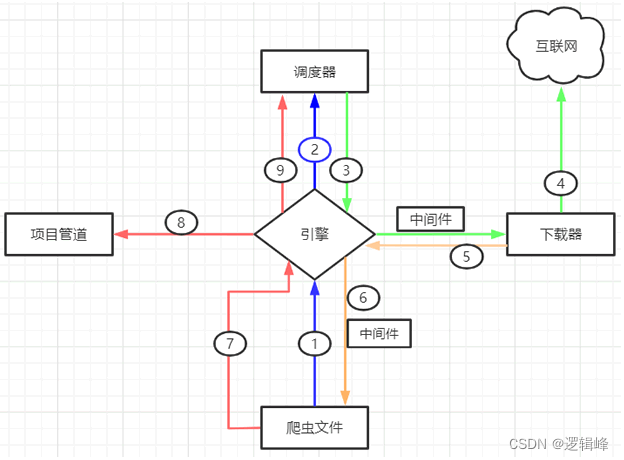
scrapy案例教程
文章目录 1 scrapy简介2 创建项目3 自定义初始化请求url4 定义item5 定义管道 1 scrapy简介 scrapy常用命令 |命令 | 格式 |说明| |–|–|–| |startproject |scrapy startproject <项目名> |创建一个新项目| |genspider| scrapy genspider <爬虫文件名> <域名…...
1-3 docker 安装 prometheus
一、环境 1、环境准备 安装Docker 镜像加速 安装 docker 检查版本 安装Docker-compose 二、Docker-compose 安装 Prometheus 1、【方式一】手动创建 docker-compose 和 配置文件 创建prometheus监控的文件夹 创建alertmanager的配置文件 - config.yml 新建grafana的…...
Mac使用brew搭建kafka集群
1. 第一步:单机搭建 单机搭建: 安装完后,默认自动安装对应版本zookeeper brew install kafka2.第二步:修改配置文件: 配置3个Kafka 第一个(使用默认配置) vi /opt/homebrew/etc/kafka/server.propertie…...
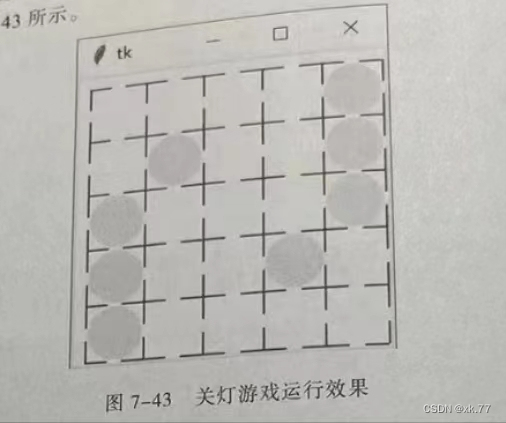
图形界面应用案例——关灯游戏(以及扩展)(python)
7.8 图形界面应用案例——关灯游戏 题目: [案例]游戏初步——关灯游戏。 关灯游戏是很有意思的益智游戏,玩家通过单击关掉(或打开)一盏灯。如果关(掉(或打开)一个电灯,其周围(上下左右)的电灯也会触及开关,成功地关掉所有电灯即可过关。 图7-43 关灯游戏运行效…...

Android平台上执行C/C++可执行程序,linux系统编程开发,NDK开发前奏。
Android平台上执行C/C可执行程序,linux系统编程开发,NDK开发前奏准备。 1.下载NDK,搭建NDK开发环境 下载地址 https://developer.android.com/ndk/downloads 下载过程中点击下面箭头的地方,点击鼠标右键,复制好下载…...

elasticsearch 基本使用,ES8.10
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html ES版本:8.10 By default, Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure…...

pytorch中常用的损失函数
1 损失函数的作用 损失函数是模型训练的基础,并且在大多数机器学习项目中,如果没有损失函数,就无法驱动模型做出正确的预测。 通俗地说,损失函数是一种数学函数或表达式,用于衡量模型在某些数据集上的表现。损失函数在…...

申克SCHENCK动平衡机显示器维修CAB700系统控制面板
适用电枢转子的卧式平衡机,高测量率,自动测量循环,自动定标完整的切槽计数可选项,CAB700动平衡测量系统两种皮带驱动方式(上置式或下置式)适用于站立或坐姿操作的人性化工作台设计。 动平衡机申克控制器面板维修型号:V…...

【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数
【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数 Abstract1 Introduction3 Overview3.1 Hybrid Data Structure3.2 3D Representations3.3 Pipeline 4 PSDF Fusion and Surface Reconstruction4.1 PSDF Fusion4.2 Inlier Ratio Evaluati…...

React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化
React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化 这段时间都在重构代码,把本来奇奇怪怪(singleton)的实现改成用 redux 的实现,然后就突然想到……即然 redux 的改变不涉及到 UI 的改变,那么是不是说可以单独写 redux 的测试……&#…...
xilinx primitives(原语)
Xilinx的原语分为10类,包括:计算组件,IO端口组件,寄存器/锁存器,时钟组件,处理器组件,移位寄存器,配置和检测组件,RAM/ROM组件,Slice/CLB组件,G-t…...

Rust重构AutoGPT:高性能自主AI智能体框架深度解析
1. 项目概述:当AI学会“自己动手” 最近在GitHub上看到一个挺有意思的项目,叫 kevin-rs/autogpt 。这名字一看就让人联想到去年那个火遍全网的AutoGPT,没错,它正是那个“让AI自己思考、自己执行任务”的明星项目的Rust语言实现…...

图像缩放方法在计算机视觉中的优化与应用
1. 像素缩放方法评估的核心价值在计算机视觉任务中,图像分类模型的性能往往与输入图像的质量密切相关。当我们使用卷积神经网络(CNN)处理图像时,原始图像尺寸与网络输入层要求的尺寸不匹配是常态而非例外。这就引出了一个基础但关…...

电脑屏幕如何实时监控?分享五个实时监控电脑屏幕的方法,码住
在企业管理的过程中,许多管理者都曾遇到过这样的困惑:办公室里键盘声此起彼伏,员工们看似都在忙碌,但项目进度却停滞不前。某科技公司的负责人王总就曾发现,团队在项目冲刺阶段,竟然有核心成员在上班时间观…...

如何用Python免费获取Google Scholar学术数据?scholarly库让学术研究效率飙升!
如何用Python免费获取Google Scholar学术数据?scholarly库让学术研究效率飙升! 【免费下载链接】scholarly Retrieve author and publication information from Google Scholar in a friendly, Pythonic way without having to worry about CAPTCHAs! …...

02.YOLO核心技术初探:锚定框与交并比
从环境搭建和基础概念中走出来,现在我们要触碰YOLO最核心的两个技术基石:锚定框和交并比。这两个概念是理解YOLO如何检测物体的关键,也是你从“知道YOLO是什么”迈向“懂得YOLO怎么工作”的第一步。 我们先说交并比,它通常被简称为…...

终极指南:Google Mesop项目中CSP策略优化与样式表查询参数处理
终极指南:Google Mesop项目中CSP策略优化与样式表查询参数处理 【免费下载链接】mesop Rapidly build AI apps in Python 项目地址: https://gitcode.com/GitHub_Trending/me/mesop 在Web开发中,内容安全策略(CSP)是保护应…...

5分钟快速上手:用Universal Android Debloater终极优化你的手机系统
5分钟快速上手:用Universal Android Debloater终极优化你的手机系统 【免费下载链接】universal-android-debloater Cross-platform GUI written in Rust using ADB to debloat non-rooted android devices. Improve your privacy, the security and battery life o…...

多项式特征变换在机器学习中的实践指南
1. 多项式特征变换在机器学习中的应用价值在机器学习实践中,我们常常会遇到这样的困境:输入特征之间存在着复杂的非线性关系,而简单的线性模型无法有效捕捉这些关系。这时候,多项式特征变换就成为了一个强有力的工具。通过将原始特…...

Yoga Pro 14s装完Win11+Ubuntu 22.04,开机直接进Windows?手把手教你进Grub救援模式找回启动菜单
Yoga Pro 14s双系统启动项丢失?Grub救援模式实战指南 刚入手Yoga Pro 14s的兴奋还没褪去,就遭遇了双系统用户的经典噩梦——安装完Windows 11和Ubuntu 22.04后,开机直接进入Windows,Ubuntu仿佛从未存在过。这不是个例,…...

VSCode嵌入式开发效率提升300%的7个隐藏技巧:从Cortex-M启动文件自动补全到RTOS任务可视化调试
更多请点击: https://intelliparadigm.com 第一章:VSCode嵌入式开发效率跃迁的底层逻辑 VSCode 并非原生嵌入式 IDE,其效率跃迁源于可编程扩展架构与标准化协议的深度协同。核心驱动力在于 Language Server Protocol(LSP…...