pytorch中常用的损失函数
1 损失函数的作用
损失函数是模型训练的基础,并且在大多数机器学习项目中,如果没有损失函数,就无法驱动模型做出正确的预测。 通俗地说,损失函数是一种数学函数或表达式,用于衡量模型在某些数据集上的表现。损失函数在深度学习主要作用如下:
- 衡量模型性能:损失函数用于评估模型的预测结果与真实结果之间的误差程度。较小的损失值表示模型的预测结果与真实结果更接近,反之则表示误差较大。因此,损失函数提供了一种度量模型性能的方式。
- 参数优化:在训练机器学习和深度学习模型时,损失函数被用作优化算法的目标函数。通过最小化损失函数,可以调整模型的参数,使模型能够更好地逼近真实结果。
- 反向传播:在深度学习中,通过反向传播算法计算损失函数对模型参数的梯度。这些梯度被用于参数更新,以便优化模型。损失函数在反向传播中扮演着重要的角色,指导参数的调整方向。
- 防止过拟合:过拟合是指模型在训练数据上表现良好,但在新数据上表现较差的现象。损失函数可以帮助在训练过程中监控模型的过拟合情况。通过观察训练集和验证集上的损失,可以及早发现模型是否过拟合,从而采取相应的措施,如正则化等。
2 pytorch中常见的损失函数
| 损失函数 | 名称 | 适用场景 |
|---|---|---|
| torch.nn.MSELoss() | 均方误差损失 | 回归 |
| torch.nn.L1Loss() | 平均绝对值误差损失 | 回归 |
| torch.nn.CrossEntropyLoss() | 交叉熵损失 | 多分类 |
| torch.nn.NLLLoss() | 负对数似然函数损失 | 多分类 |
| torch.nn.NLLLoss2d() | 图片负对数似然函数损失 | 图像分割 |
| torch.nn.KLDivLoss() | KL散度损失 | 回归 |
| torch.nn.BCELoss() | 二分类交叉熵损失 | 二分类 |
| torch.nn.MarginRankingLoss() | 评价相似度的损失 | |
| torch.nn.MultiLabelMarginLoss() | 多标签分类的损失 | 多标签分类 |
| torch.nn.SmoothL1Loss() | 平滑的L1损失 | 回归 |
| torch.nn.SoftMarginLoss() | 多标签二分类问题的损失 | 多标签二分类 |
2.1 L1损失函数
预测值与标签值进行相差,然后取绝对值,根据实际应用场所,可以设置是否求和,求平均,公式可见下,Pytorch调用函数:nn.L1Loss

import torch
import torch.nn as nnLoss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean')input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = Loss_fn(input, target)
print(output)运行结果显示如下:
tensor(1.4177, grad_fn=<MeanBackward0>)2.2 L2损失函数
预测值与标签值进行相差,然后取平方,根据实际应用场所,可以设置是否求和,求平均,公式可见下,Pytorch调用函数:nn.MSELoss
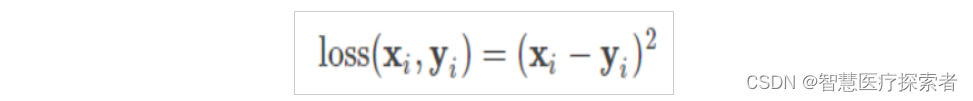
import torch.nn as nn
import torchloss = nn.MSELoss(size_average=None, reduce=None, reduction='mean')input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
print(output)运行结果显示如下:
tensor(1.7956, grad_fn=<MseLossBackward0>)2.3 Huber Loss损失函数
简单来说就是L1和L2损失函数的综合版本,结合了两者的优点,公式可见下,Pytorch调用函数:nn.SmoothL1Loss
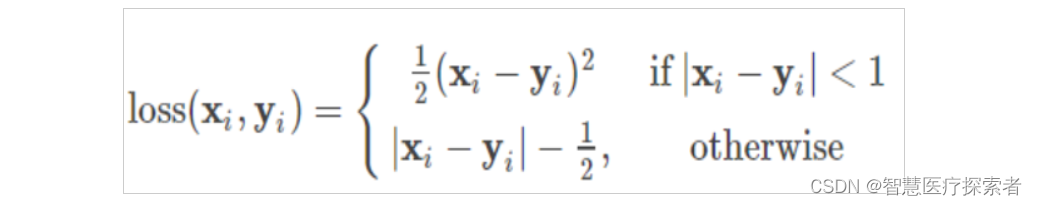
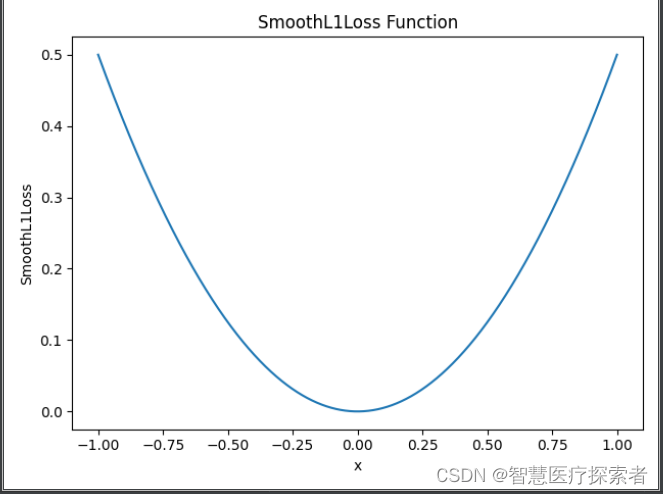
import matplotlib.pyplot as plt
import torch# 定义函数和参数
smooth_l1_loss = nn.SmoothL1Loss(reduction='none')
x = torch.linspace(-1, 1, 10000)
y = smooth_l1_loss(torch.zeros(10000), x)# 绘制图像
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('SmoothL1Loss')
plt.title('SmoothL1Loss Function')
plt.show()运行结果显示如下:
2.4 二分类交叉熵损失函数
简单来说,就是度量两个概率分布间的差异性信息,在某一程度上也可以防止梯度学习过慢,公式可见下,Pytorch调用函数有两个,一个是nn.BCELoss函数,用的时候要结合Sigmoid函数,另外一个是nn.BCEWithLogitsLoss()

import torch.nn as nn
import torchm = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
print(output)运行结果显示如下:
tensor(0.6214, grad_fn=<BinaryCrossEntropyBackward0>)import torch
import torch.nn as nnlabel = torch.empty((2, 3)).random_(2)
x = torch.randn((2, 3), requires_grad=True)bce_with_logits_loss = nn.BCEWithLogitsLoss()
output = bce_with_logits_loss(x, label)print(output)运行结果显示如下:
tensor(0.7346, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>)2.5 多分类交叉熵损失函数
也是度量两个概率分布间的差异性信息,Pytorch调用函数也有两个,一个是nn.NLLLoss,用的时候要结合log softmax处理,另外一个是nn.CrossEntropyLoss
import torch
import torch.nn.functional as Finput = torch.randn(3, 5, requires_grad=True)
target = torch.tensor([1, 0, 4])
output = F.nll_loss(F.log_softmax(input, dim=1), target)
print(output)运行结果显示如下:
tensor(2.9503, grad_fn=<NllLossBackward0>)import torch
import torch.nn as nnloss = nn.CrossEntropyLoss()
inputs = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(inputs, target)print(output)运行结果显示如下:
tensor(1.6307, grad_fn=<NllLossBackward0>)2.6 自定义损失
通过对 nn 模块进行子类化,将损失函数创建为神经网络图中的节点。 这意味着我们的自定义损失函数是一个 PyTorch 层,与卷积层完全相同。
class Custom_MSE(nn.Module):def __init__(self):super(Custom_MSE, self).__init__();def forward(self, predictions, target):square_difference = torch.square(predictions - target)loss_value = torch.mean(square_difference)return loss_value# def __call__(self, predictions, target):# square_difference = torch.square(y_predictions - target)# loss_value = torch.mean(square_difference)# return loss_value可以在“forward”函数调用或“call”内部定义损失的实际实现。
3 总结
损失函数在人工智能领域中起着至关重要的作用,它不仅是模型训练和优化的基础,也是评估模型性能、解决过拟合问题以及指导模型选择的重要工具。不同的损失函数适用于不同的问题和算法,选择合适的损失函数对于取得良好的模型性能至关重要。
相关文章:
pytorch中常用的损失函数
1 损失函数的作用 损失函数是模型训练的基础,并且在大多数机器学习项目中,如果没有损失函数,就无法驱动模型做出正确的预测。 通俗地说,损失函数是一种数学函数或表达式,用于衡量模型在某些数据集上的表现。损失函数在…...

申克SCHENCK动平衡机显示器维修CAB700系统控制面板
适用电枢转子的卧式平衡机,高测量率,自动测量循环,自动定标完整的切槽计数可选项,CAB700动平衡测量系统两种皮带驱动方式(上置式或下置式)适用于站立或坐姿操作的人性化工作台设计。 动平衡机申克控制器面板维修型号:V…...

【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数
【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数 Abstract1 Introduction3 Overview3.1 Hybrid Data Structure3.2 3D Representations3.3 Pipeline 4 PSDF Fusion and Surface Reconstruction4.1 PSDF Fusion4.2 Inlier Ratio Evaluati…...

React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化
React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化 这段时间都在重构代码,把本来奇奇怪怪(singleton)的实现改成用 redux 的实现,然后就突然想到……即然 redux 的改变不涉及到 UI 的改变,那么是不是说可以单独写 redux 的测试……&#…...
xilinx primitives(原语)
Xilinx的原语分为10类,包括:计算组件,IO端口组件,寄存器/锁存器,时钟组件,处理器组件,移位寄存器,配置和检测组件,RAM/ROM组件,Slice/CLB组件,G-t…...

机器学习 - DBSCAN聚类算法:技术与实战全解析
目录 一、简介DBSCAN算法的定义和背景聚类的重要性和应用领域DBSCAN与其他聚类算法的比较 二、理论基础密度的概念核心点、边界点和噪声点DBSCAN算法流程邻域的查询聚类的形成过程 参数选择的影响 三、算法参数eps(邻域半径)举例说明:如何选择…...
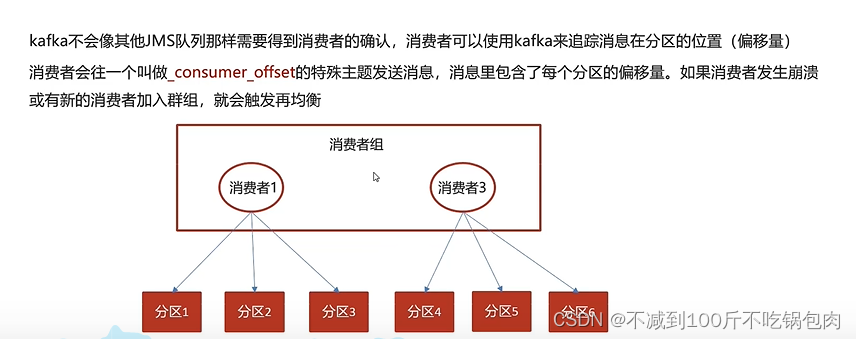
kafka微服务学习
消息中间件对比: 1、吞吐、可靠性、性能 Kafka安装 Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper Docker安装zookeeper 下载镜像: docker pull zookeeper:3.4.14创建容器 do…...
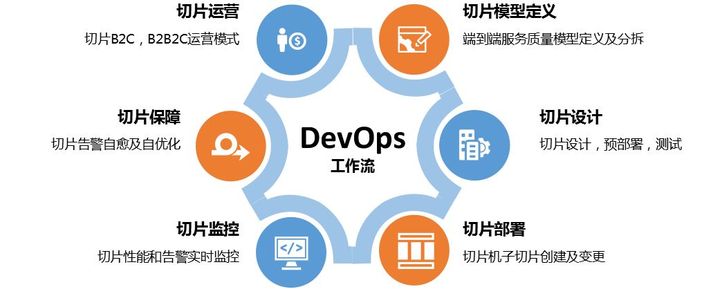
5G网络切片,到底是什么?
网络切片,是5G引入的一个全新概念。 一看到切片,首先想到的,必然是把一个完整的东西切成薄片。于是,切面包或者切西瓜这样的画面,映入脑海。 添加图片注释,不超过 140 字(可选) 然而…...

linux安装nodejs
写在前面 因为工作需要,需要使用到nodejs,所以这里简单记录下学习过程。 1:安装 wget https://nodejs.org/dist/v14.17.4/node-v14.17.4-linux-x64.tar.xz tar xf node-v14.17.4-linux-x64.tar.xz mkdir /usr/local/lib/node // 这一步骤根…...

第1天:Python基础语法(一)
** 1、Python简介 ** Python是一种高级、通用的编程语言,由Guido van Rossum于1989年创造。它被设计为易于阅读和理解,具有简洁而清晰的语法,使得初学者和专业开发人员都能够轻松上手。 Python拥有丰富的标准库,提供了广泛的功…...
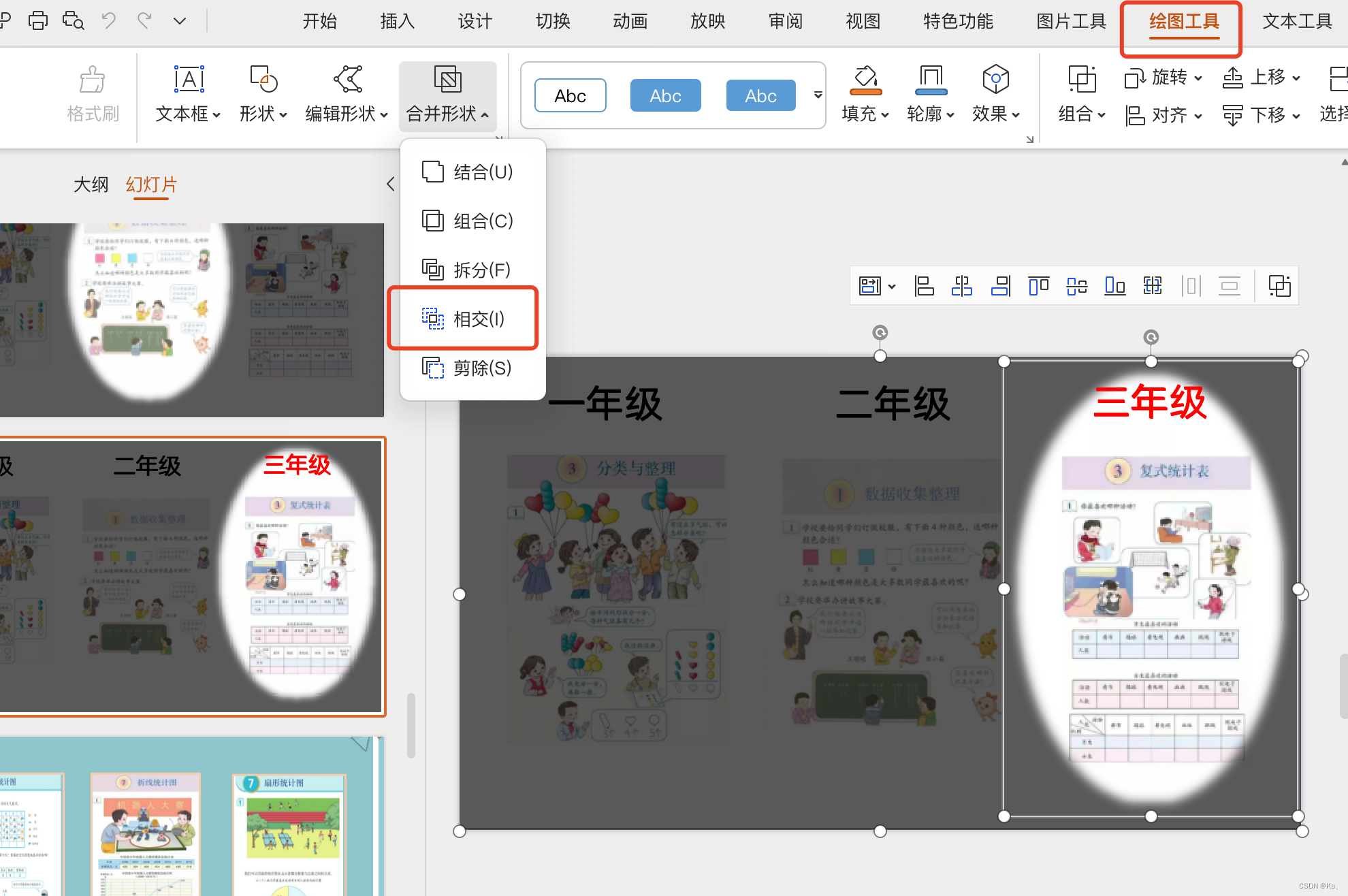
ppt聚光灯效果
1.放入三张图片内容或其他 2.全选复制成图片 3.设置黑色矩形,透明度30% 4.粘贴复制后的图片,制定图层 5.插入椭圆,先选中矩形,再选中椭圆,点击绘图工具,选择相交即可(关键)...

图文解析 Nacos 配置中心的实现
目录 一、什么是 Nacos 二、配置中心的架构 三、Nacos 使用示例 (一)官方代码示例 (二)Properties 解读 (三)配置项的层级设计 (四)获取配置 (五)注册…...

P1918 保龄球
Portal. 记录每一个瓶子数对应的位置即可。 注意到值域很大( a i ≤ 1 0 9 a_i\leq 10^9 ai≤109),要用 map 存储。 #include <bits/stdc.h> using namespace std;map<int,int> p;int main() {int n;cin>>n;for(int i…...
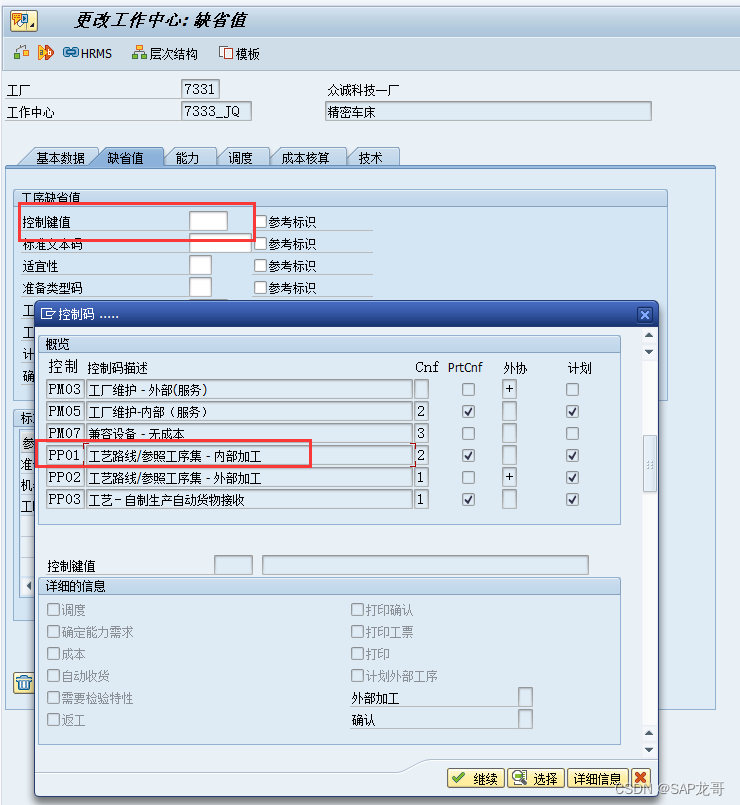
SAP-PP-报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在
创建工艺路线时报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在, 这是因为在创建工作中心时未维护控制键值导致的...
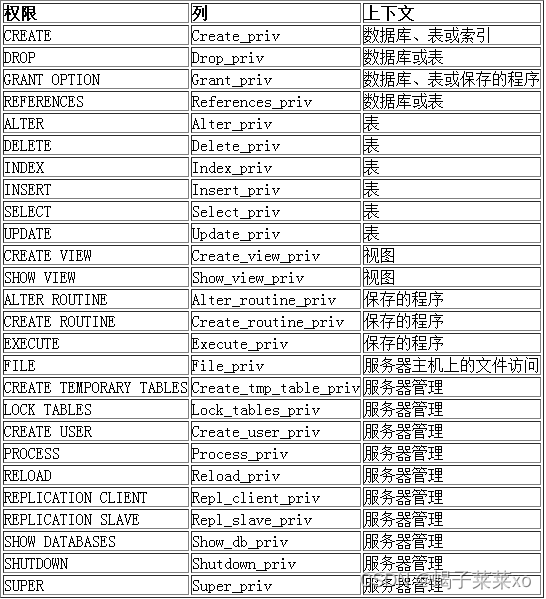
MySQL -- 用户管理
MySQL – 用户管理 文章目录 MySQL -- 用户管理一、用户1.用户信息2.创建用户3.删除用户4.远端登录MySQL5.修改用户密码6.数据库的权限 一、用户 1.用户信息 MySQL中的用户,都存储在系统数据库mysql的user表中: host: 表示这个用户可以从…...

IOS浏览器不支持对element ui table的宽度设置百分比
IOS浏览器不支持对element ui table的宽度设置百分比 IOS浏览器会把百分号识别成px,所以我们可以根据屏幕宽度将百分比转换成px getColumnWidth(data) {const screenWidth window.innerWidth;const desiredPercentage data;const widthInPixels (screenWidth *…...
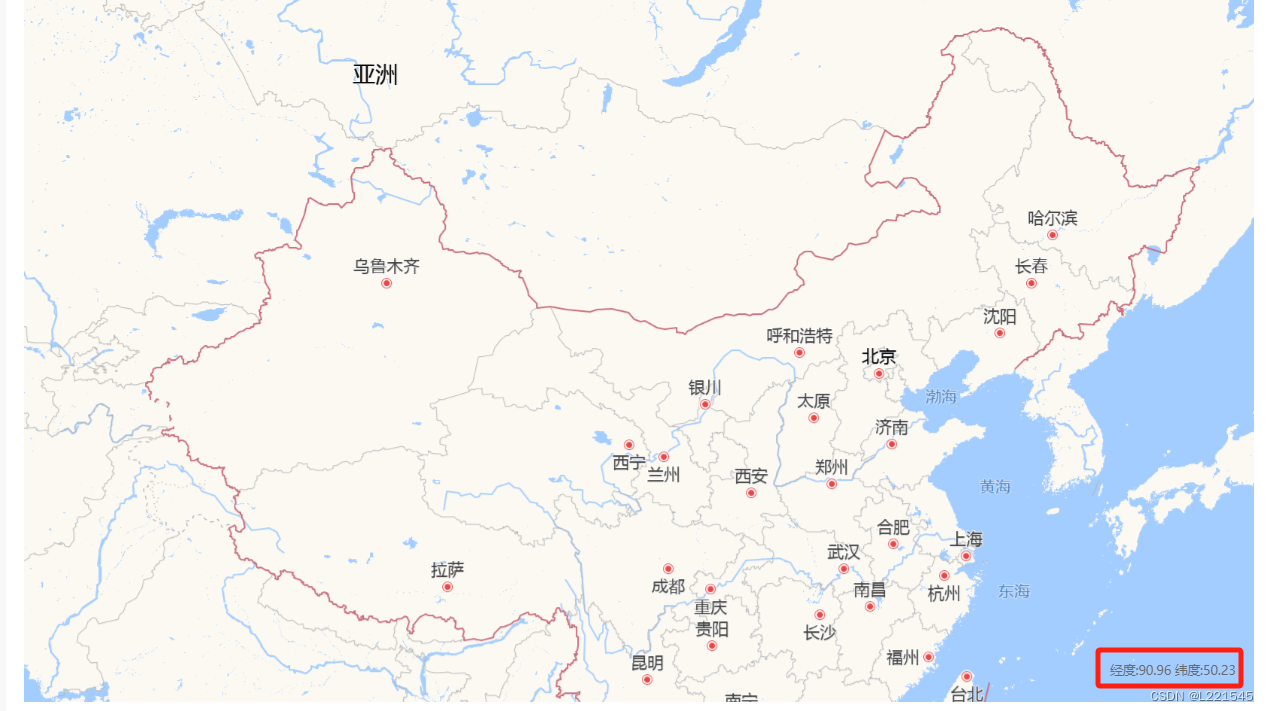
Vue+OpenLayers 创建地图并显示鼠标所在经纬度
1、效果 2、创建地图 本文用的是高德地图 页面 <div class"map" id"map"></div><div id"mouse-position" class"position_coordinate"></div>初始化地图 var gaodeLayer new TileLayer({title: "高德地…...

01-编码-H264编码原理
1.整体概念 编码的含义就是压缩,将摄像头采集的YUV或RGB数据压缩成H264。 压缩的过程就是去除信息冗余的过程,一般视频有如下的冗余信息。 (1)空间冗余:在同一个画面中,相邻的像素点之间的变化很小,因而可以用一个特定大小的矩阵来描述相邻的这些像素。 (2)时间冗余:…...
RxJava/RxAndroid的操作符使用(二)
文章目录 一、创建操作1、基本创建2、快速创建2.1 empty2.2 never2.3 error2.4 from2.5 just 3、定时与延时创建操作3.1 defer3.2 timer3.3 interval3.4 intervalRange3.5 range3.6 repeat 二、过滤操作1、skip/skipLast2、debounce3、distinct——去重4、elementAt——获取指定…...
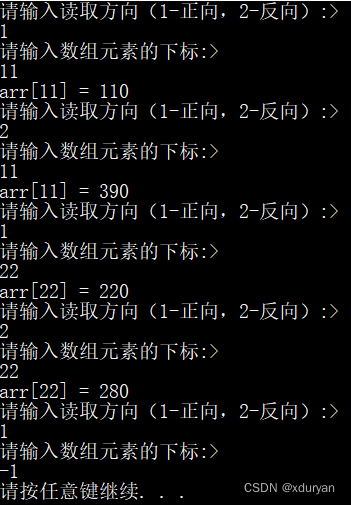
【C语法学习】20 - 文件访问顺序
文章目录 0 前言1 文件位置指示符2 rewind()函数2.1 函数原型2.2 参数2.3 返回值2.4 使用说明 3 ftell()函数3.1 函数原型3.2 参数3.3 返回值 4 fseek()函数4.1 函数原型4.2 参数4.3 返回值 5 示例5.1 示例15.2 示例2 0 前言 C语言文件访问分为顺序文件访问和随机文件访问。 …...
,让你的老显卡焕发新生)
无损缩放小黄鸭下载使用教程(Lossless Scaling),让你的老显卡焕发新生
Lossless Scaling(小黄鸭)是一款Steam上的AI插帧与无损缩放工具,通过LSFG 3.1算法为窗口化或无边框程序补帧,可将30帧画面提升至60帧甚至更高,并支持多种缩放算法锐化低分辨率画面,很适合低配硬件。 软件最…...
)
P1832 A+B Problem(再升级)
记录110 #include<bits/stdc.h> using namespace std; long long dp[1010];//注意longlong bool f(int x){//判断素数 if(x<2) return false;for(int i2;i*i<x;i){if(x%i0) return false;}return true; } int main(){//完全背包 int n; cin>>n;dp[0]1;//d…...

061-基于51单片机无线抢答器【Proteus仿真+Keil程序+报告+原理图】
061-基于51单片机无线抢答器一、系统总体硬件架构 本系统硬件整体由51 单片机最小系统、NRF24L01 无线通信模块、AT24C02 掉电存储芯片、LCD1602 液晶显示模块、按键控制电路、蜂鸣器以及 LED 状态指示灯共同组成。 二、核心硬件功能设计 系统选用STC89C51单片机作为主控核心&a…...

深度解析:如何用UE Viewer高效处理虚幻引擎1-4代游戏资源
深度解析:如何用UE Viewer高效处理虚幻引擎1-4代游戏资源 【免费下载链接】UEViewer Viewer and exporter for Unreal Engine 1-4 assets (UE Viewer). 项目地址: https://gitcode.com/gh_mirrors/ue/UEViewer UE Viewer是一款强大的开源虚幻引擎资源查看与导…...

基于安卓的社区儿童托管预约平台毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在设计并实现一款基于安卓平台的社区儿童托管预约系统以解决当前城市社区中儿童托管服务供需失衡与管理效率低下等问题。随着我国城市化进程加速及双职工…...

推荐 win11 可用的 SVN 版本:64位,下载最新的 TortoiseSVN 1.14.x 版本
【Win11兼容SVN工具推荐】推荐使用64位TortoiseSVN 1.14.x最新版本,完美适配Win11系统。该工具直接集成到资源管理器,提供右键快捷操作,完全免费且支持中文界面。安装时需注意:选择对应系统位数的安装包(推荐64位&…...
)
部署与可视化系统:模型部署:YOLOv10 转 ONNX + 使用 ONNXRuntime 推理(CPU/GPU)
这是CSDN 2026年最硬核、最完整、最落地的「YOLOv10→ONNX→ONNXRuntime推理」一站式攻略,没有之一。从.pt模型到CPU/GPU双模推理,全部代码、全部参数、全部避坑点、全部架构设计,一次讲透!建议收藏,迟早会用! 一、开篇:为什么你需要掌握YOLOv10 ONNX部署? 1.1 部署能…...

三步搞定百度文库付费文档:专业工具助你高效获取纯净内容
三步搞定百度文库付费文档:专业工具助你高效获取纯净内容 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常遇到百度文库中需要付费或积分才能查看完整内容的文档?…...

多项式逻辑回归原理与Python实践指南
1. 多项式逻辑回归概述逻辑回归是机器学习中最基础也最常用的分类算法之一。标准的逻辑回归(二项逻辑回归)适用于二分类问题,通过Sigmoid函数将线性回归的输出映射到(0,1)区间,表示样本属于正类的概率。但在实际应用中,…...

AudioSep音频分离终极指南:用自然语言描述分离任何声音
AudioSep音频分离终极指南:用自然语言描述分离任何声音 【免费下载链接】AudioSep Official implementation of "Separate Anything You Describe" 项目地址: https://gitcode.com/gh_mirrors/au/AudioSep 你是否曾为从嘈杂录音中提取清晰人声而烦…...