scrapy案例教程
文章目录
- 1 scrapy简介
- 2 创建项目
- 3 自定义初始化请求url
- 4 定义item
- 5 定义管道
1 scrapy简介
- scrapy常用命令
|命令 | 格式 |说明|
|–|–|–|
|startproject |scrapy startproject <项目名> |创建一个新项目|
|genspider| scrapy genspider <爬虫文件名> <域名> |新建爬虫文件。
|runspider| scrapy runspider <爬虫文件> |运行一个爬虫文件,不需要创建项目。
|crawl| scrapy crawl |运行一个爬虫项目,必须要创建项目。
|list |scrapy list |列出项目中所有爬虫文件。
|view| scrapy view <url地址>| 从浏览器中打开 url 地址。
|shell| csrapy shell <url地址> |命令行交互模式。
|settings |scrapy settings |查看当前项目的配置信息。 - 项目的目录树结构

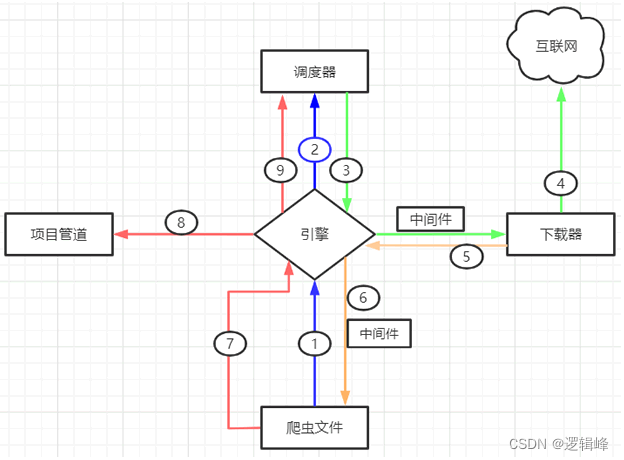
- Scrapy 五大组件
| 名称 | 作用说明 |
|---|---|
| Engine(引擎) | 整个 Scrapy 框架的核心,主要负责数据和信号在不同模块间传递。 |
| Scheduler(调度器) | 用来维护引擎发送过来的 request 请求队列。 |
| Downloader(下载器) | 接收引擎发送过来的 request 请求,并生成请求的响应对象,将响应结果返回给引擎。 |
| Spider(爬虫程序) | 处理引擎发送过来的 response, 主要用来解析、提取数据和获取需要跟进的二级URL,然后将这些数据交回给引擎。 |
| Pipeline(项目管道) | 用实现数据存储,对引擎发送过来的数据进一步处理,比如存 MySQL 数据库等。 |
- 两大中间件
- 下载器中间件,位于引擎和下载器之间,主要用来包装 request 请求头,比如 UersAgent、Cookies 和代理 IP 等
- 蜘蛛中间件,位于引擎与爬虫文件之间,它主要用来修改响应对象的属性。
- 工作流程图
2 创建项目
# 创建项目
scrapy startproject Medical
# 进入项目
cd Medical
# 创建爬虫文件
scrapy genspider medical www.baidu.com
3 自定义初始化请求url
import scrapy
import json
from scrapy.http import Response
from Medical.items import MedicalItem
from tqdm import tqdm'''
具体的爬虫程序
'''class MedicalSpider(scrapy.Spider):name = "medical"allowed_domains = ["beian.cfdi.org.cn"]# start_urls = ["https://beian.cfdi.org.cn/CTMDS/pub/PUB010100.do?method=handle05&_dt=20231101162330"]# 重写第一次请求处理函数def start_requests(self):start_url = 'https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle05&_dt=20231101162330'# 发送post请求data = {'pageSize': '1353','curPage': '1',}yield scrapy.FormRequest(url=start_url, formdata=data, callback=self.parse)def parse(self, response):# 转换为jsonjsonRes = json.loads(response.body)# 查看响应状态码status = jsonRes['success']# 如果状态为Trueif status:# 获取数据dataList = jsonRes['data']# 调用详细方法,发起请求(循环发起)for row in tqdm(dataList,desc='爬取进度'):# 请求详情页urlurlDetail = f"https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle04&compId={row['companyId']}"# 发起请求yield scrapy.Request(url=urlDetail, callback=self.parseDetail, meta={'row': row})def parseDetail(self, response: Response):# new 一个MedicalItem实例item = MedicalItem()# 获取上次请求的数据源row = response.meta['row']item['companyId'] = row['companyId']item['linkTel'] = row['linkTel']item['recordNo'] = row['recordNo']item['areaName'] = row['areaName']item['linkMan'] = row['linkMan']item['address'] = row['address']item['compName'] = row['compName']item['recordStatus'] = row['recordStatus']item['cancelRecordTime'] = row.get('cancelRecordTime', '')# 获取备案信息divTextList = response.xpath("//div[@class='col-md-8 textlabel']/text()").extract()# 去空白divtextList = [text.strip() for text in divTextList]compLevel = ''if len(divtextList) > 2:compLevel = divtextList[2]recordTime = ''if len(divtextList) > 5:recordTime = divtextList[6]item['compLevel'] = compLevelitem['recordTime'] = recordTime# 获取其他机构地址divListOther = response.xpath("//div[@class='col-sm-8 textlabel']/text()").extract()# 去空白divtextListOther = [text.strip() for text in divListOther]otherOrgAdd = ','.join(divtextListOther)item['otherOrgAdd'] = otherOrgAdd# 获取备案专业和主要研究者信息trList = response.xpath("//table[@class='table table-striped']/tbody/tr")tdTextList = [tr.xpath("./td/text()").extract() for tr in trList]item['tdTextList'] = tdTextList# 返回itemyield item
4 定义item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapyclass MedicalItem(scrapy.Item):# define the fields for your item here like:# 省份/地区areaName = scrapy.Field()# 公司idcompanyId = scrapy.Field()# 公司名称compName = scrapy.Field()# 公司等级compLevel = scrapy.Field()# 联系人linkMan = scrapy.Field()# 联系电话linkTel = scrapy.Field()# 备案号recordNo = scrapy.Field()# 地址address = scrapy.Field()# 备案状态recordStatus = scrapy.Field()# 取消备案时间cancelRecordTime = scrapy.Field()# 备案时间recordTime = scrapy.Field()# 其他机构地址otherOrgAdd = scrapy.Field()# 子表详情(矩阵)tdTextList = scrapy.Field()
5 定义管道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysqlfrom Medical.items import MedicalItemclass MedicalPipeline:# 开始def open_spider(self, spider):# 初始化数据库self.db = pymysql.connect(host='localhost',port=3306,user='root',password='logicfeng',database='test2')# 创建游标对象self.cursor = self.db.cursor()def process_item(self, item, spider):companyId = item['companyId']linkTel = item['linkTel']recordNo = item['recordNo']areaName = item['areaName']linkMan = item['linkMan']address = item['address']compName = item['compName']recordStatus = item['recordStatus']cancelRecordTime = item.get('cancelRecordTime', '')compLevel = item.get('compLevel', '')recordTime = item.get('recordTime', '')otherOrgAdd = item.get('otherOrgAdd', '')tdTextList = item['tdTextList']sql1 = "insert INTO medical_register(company_id,area_name,record_no,comp_name,address,link_man,link_tel,record_status,comp_level,record_time,cancel_record_time,other_org_add) "sql2 = f"values('{companyId}','{areaName}','{recordNo}','{compName}','{address}','{linkMan}','{linkTel}','{recordStatus}','{compLevel}','{recordTime}','{cancelRecordTime}','{otherOrgAdd}')"sql3 = sql1 + sql2# 执行sqlself.cursor.execute(sql3)# 提交self.db.commit()for tdText in tdTextList:tdText.insert(0,companyId)# 插入数据库sql4 = "insert into medical_register_sub (company_id,professional_name,principal_investigator,job_title) values(%s,%s,%s,%s)"self.cursor.execute(sql4, tdText)# 提交到数据库self.db.commit()return itemdef close_spider(self, spider):self.cursor.close()self.db.close()print("关闭数据库!")
相关文章:
scrapy案例教程
文章目录 1 scrapy简介2 创建项目3 自定义初始化请求url4 定义item5 定义管道 1 scrapy简介 scrapy常用命令 |命令 | 格式 |说明| |–|–|–| |startproject |scrapy startproject <项目名> |创建一个新项目| |genspider| scrapy genspider <爬虫文件名> <域名…...
1-3 docker 安装 prometheus
一、环境 1、环境准备 安装Docker 镜像加速 安装 docker 检查版本 安装Docker-compose 二、Docker-compose 安装 Prometheus 1、【方式一】手动创建 docker-compose 和 配置文件 创建prometheus监控的文件夹 创建alertmanager的配置文件 - config.yml 新建grafana的…...
Mac使用brew搭建kafka集群
1. 第一步:单机搭建 单机搭建: 安装完后,默认自动安装对应版本zookeeper brew install kafka2.第二步:修改配置文件: 配置3个Kafka 第一个(使用默认配置) vi /opt/homebrew/etc/kafka/server.propertie…...
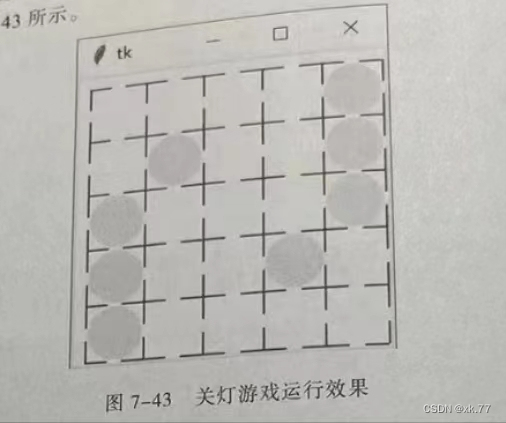
图形界面应用案例——关灯游戏(以及扩展)(python)
7.8 图形界面应用案例——关灯游戏 题目: [案例]游戏初步——关灯游戏。 关灯游戏是很有意思的益智游戏,玩家通过单击关掉(或打开)一盏灯。如果关(掉(或打开)一个电灯,其周围(上下左右)的电灯也会触及开关,成功地关掉所有电灯即可过关。 图7-43 关灯游戏运行效…...

Android平台上执行C/C++可执行程序,linux系统编程开发,NDK开发前奏。
Android平台上执行C/C可执行程序,linux系统编程开发,NDK开发前奏准备。 1.下载NDK,搭建NDK开发环境 下载地址 https://developer.android.com/ndk/downloads 下载过程中点击下面箭头的地方,点击鼠标右键,复制好下载…...

elasticsearch 基本使用,ES8.10
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html ES版本:8.10 By default, Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure…...

pytorch中常用的损失函数
1 损失函数的作用 损失函数是模型训练的基础,并且在大多数机器学习项目中,如果没有损失函数,就无法驱动模型做出正确的预测。 通俗地说,损失函数是一种数学函数或表达式,用于衡量模型在某些数据集上的表现。损失函数在…...

申克SCHENCK动平衡机显示器维修CAB700系统控制面板
适用电枢转子的卧式平衡机,高测量率,自动测量循环,自动定标完整的切槽计数可选项,CAB700动平衡测量系统两种皮带驱动方式(上置式或下置式)适用于站立或坐姿操作的人性化工作台设计。 动平衡机申克控制器面板维修型号:V…...

【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数
【论文阅读】PSDF Fusion:用于动态 3D 数据融合和场景重建的概率符号距离函数 Abstract1 Introduction3 Overview3.1 Hybrid Data Structure3.2 3D Representations3.3 Pipeline 4 PSDF Fusion and Surface Reconstruction4.1 PSDF Fusion4.2 Inlier Ratio Evaluati…...

React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化
React 测试笔记 03 - 测试 Redux 中 Reducer 状态变化 这段时间都在重构代码,把本来奇奇怪怪(singleton)的实现改成用 redux 的实现,然后就突然想到……即然 redux 的改变不涉及到 UI 的改变,那么是不是说可以单独写 redux 的测试……&#…...
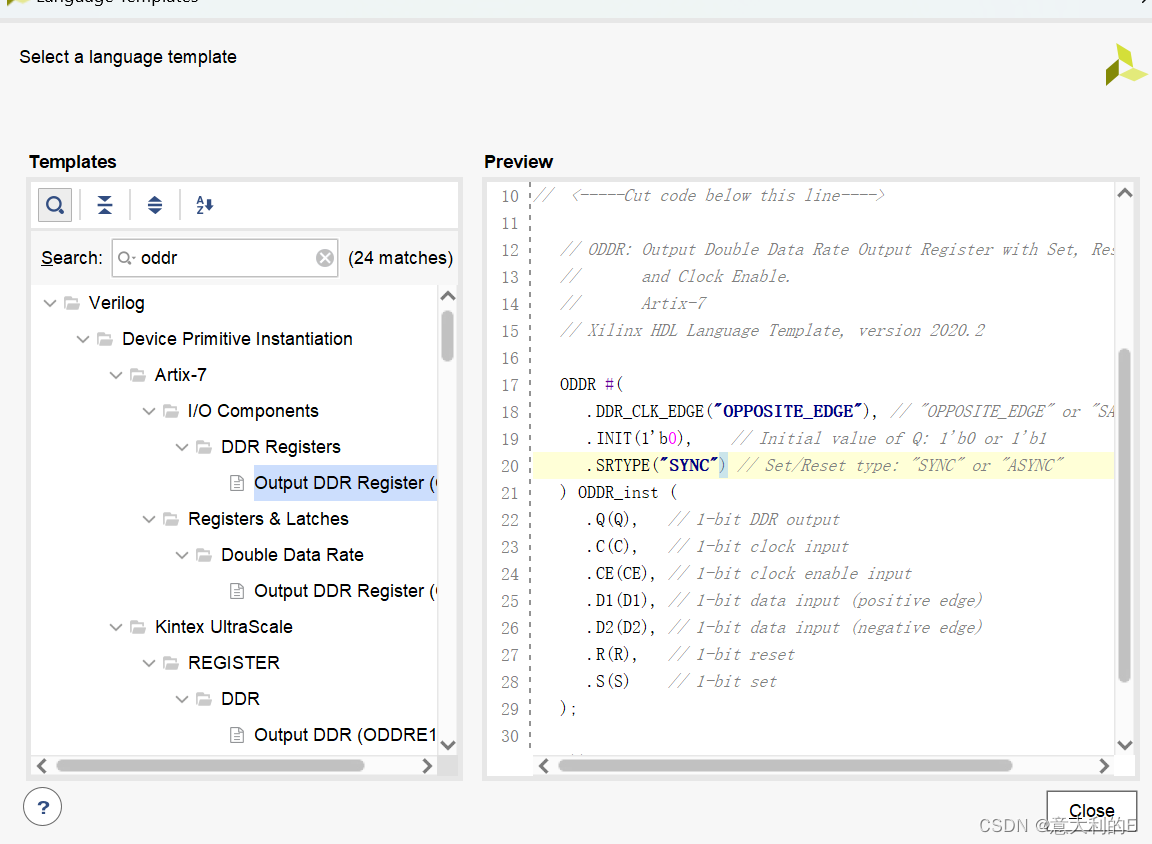
xilinx primitives(原语)
Xilinx的原语分为10类,包括:计算组件,IO端口组件,寄存器/锁存器,时钟组件,处理器组件,移位寄存器,配置和检测组件,RAM/ROM组件,Slice/CLB组件,G-t…...

机器学习 - DBSCAN聚类算法:技术与实战全解析
目录 一、简介DBSCAN算法的定义和背景聚类的重要性和应用领域DBSCAN与其他聚类算法的比较 二、理论基础密度的概念核心点、边界点和噪声点DBSCAN算法流程邻域的查询聚类的形成过程 参数选择的影响 三、算法参数eps(邻域半径)举例说明:如何选择…...
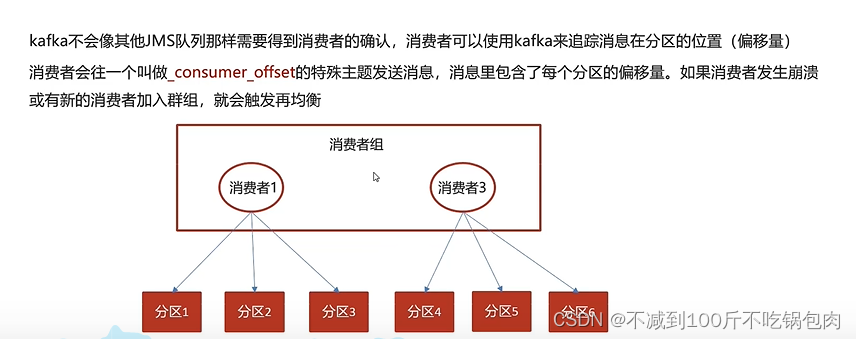
kafka微服务学习
消息中间件对比: 1、吞吐、可靠性、性能 Kafka安装 Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper Docker安装zookeeper 下载镜像: docker pull zookeeper:3.4.14创建容器 do…...
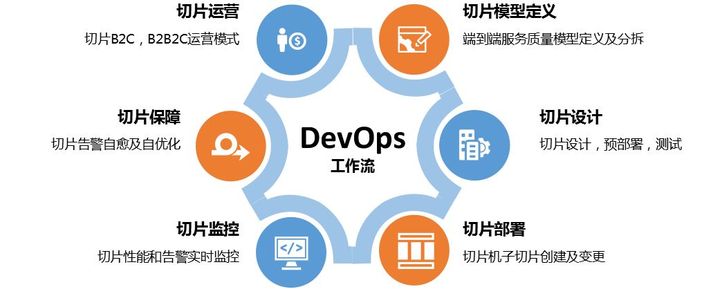
5G网络切片,到底是什么?
网络切片,是5G引入的一个全新概念。 一看到切片,首先想到的,必然是把一个完整的东西切成薄片。于是,切面包或者切西瓜这样的画面,映入脑海。 添加图片注释,不超过 140 字(可选) 然而…...

linux安装nodejs
写在前面 因为工作需要,需要使用到nodejs,所以这里简单记录下学习过程。 1:安装 wget https://nodejs.org/dist/v14.17.4/node-v14.17.4-linux-x64.tar.xz tar xf node-v14.17.4-linux-x64.tar.xz mkdir /usr/local/lib/node // 这一步骤根…...

第1天:Python基础语法(一)
** 1、Python简介 ** Python是一种高级、通用的编程语言,由Guido van Rossum于1989年创造。它被设计为易于阅读和理解,具有简洁而清晰的语法,使得初学者和专业开发人员都能够轻松上手。 Python拥有丰富的标准库,提供了广泛的功…...
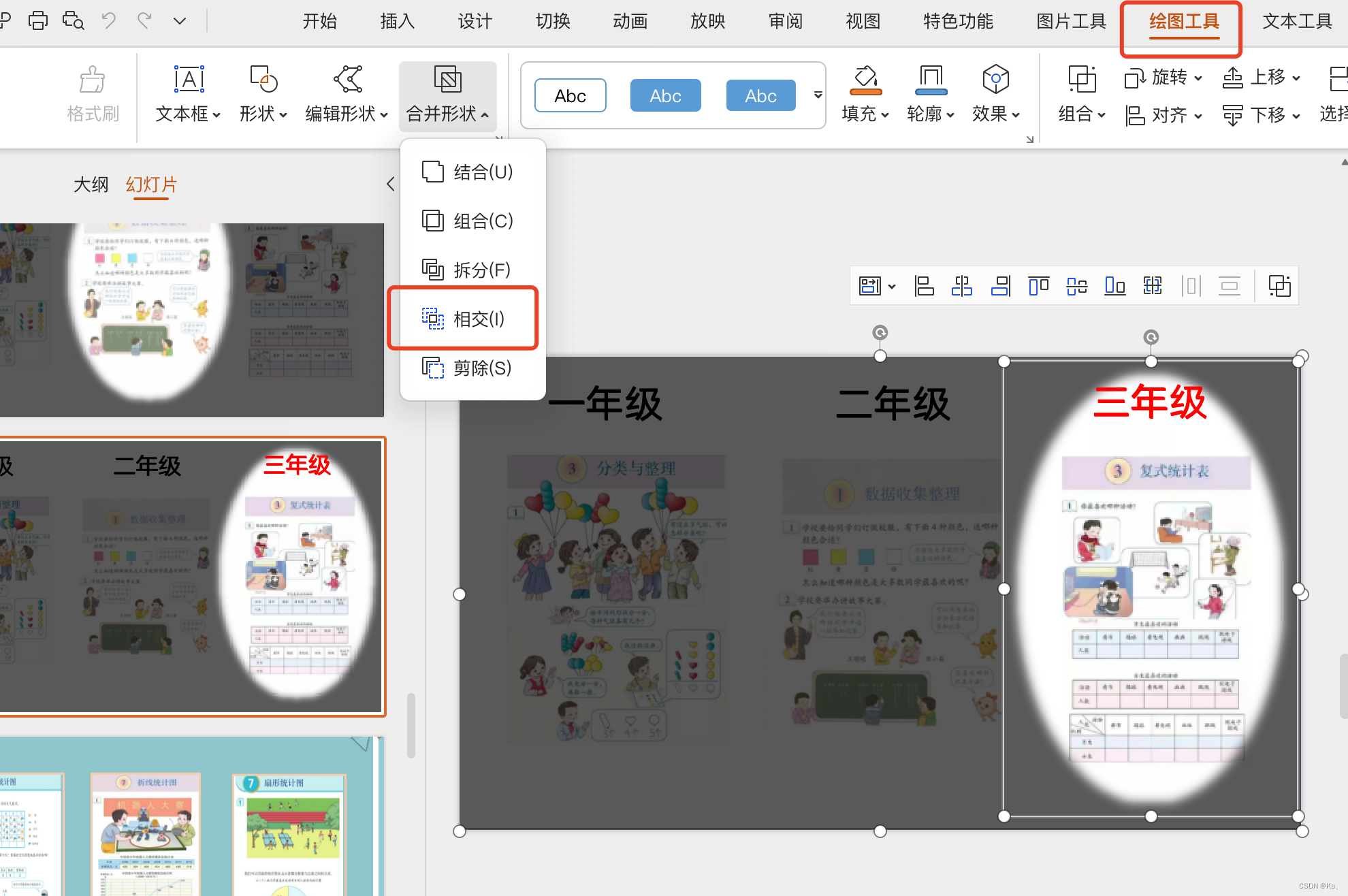
ppt聚光灯效果
1.放入三张图片内容或其他 2.全选复制成图片 3.设置黑色矩形,透明度30% 4.粘贴复制后的图片,制定图层 5.插入椭圆,先选中矩形,再选中椭圆,点击绘图工具,选择相交即可(关键)...

图文解析 Nacos 配置中心的实现
目录 一、什么是 Nacos 二、配置中心的架构 三、Nacos 使用示例 (一)官方代码示例 (二)Properties 解读 (三)配置项的层级设计 (四)获取配置 (五)注册…...

P1918 保龄球
Portal. 记录每一个瓶子数对应的位置即可。 注意到值域很大( a i ≤ 1 0 9 a_i\leq 10^9 ai≤109),要用 map 存储。 #include <bits/stdc.h> using namespace std;map<int,int> p;int main() {int n;cin>>n;for(int i…...
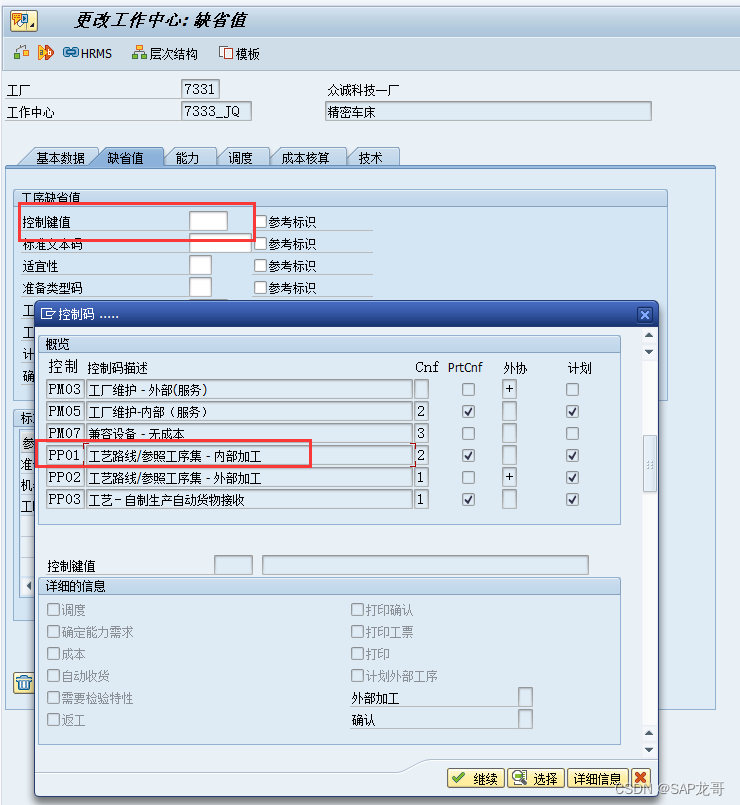
SAP-PP-报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在
创建工艺路线时报错:工作中心 7333_JQ 工厂 7331 对任务清单类型 N 不存在, 这是因为在创建工作中心时未维护控制键值导致的...

FileMeta:让Windows文件元数据管理效率提升300%的专业工具
FileMeta:让Windows文件元数据管理效率提升300%的专业工具 【免费下载链接】FileMeta Enable Explorer in Vista, Windows 7 and later to see, edit and search on tags and other metadata for any file type 项目地址: https://gitcode.com/gh_mirrors/fi/File…...

大路灯护眼灯是智商税吗?全光谱护眼大路灯品牌排名前十推荐
灯光是家里的点睛之笔,而一台好用的护眼大路灯能够让家里的光线在明亮的同时呈现舒适护眼的光线,成为目前很多有娃家庭必备的照明工具,不过现在市面上的护眼大路灯种类实在太多了,从造型到功能五花八门的,看得人眼花缭…...

模型莫名拦截输出背后真相,看懂风控底层逻辑学会高效破限
前言 很多人在用AI大模型时都遇到过这样的糟心情况,明明只是正常提问,做学术研究,开展专业教学或是分析影视剧情,模型却直接弹出拒绝话术,提示无法满足当前请求,任务被迫中途终止。 在各大AI使用交流社区中…...

Linux -- 信号量
信号量⭐:同步与互斥核心1. 作用解决进程 / 线程同步、互斥问题保护临界资源(同一时间只允许一个进程访问)2. 本质受保护的整数计数器操作是原子性的,不可中断3. 两种信号量二值信号量(0/1):互斥…...

2026届毕业生推荐的十大AI辅助论文网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 其核心在于,削弱机器生成的规律性特征,以此来降低AIGC(人…...

终极Windows更新修复指南:5分钟解决系统更新卡死问题
终极Windows更新修复指南:5分钟解决系统更新卡死问题 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool 你是否曾经遇…...

ComfyUI IPAdapter Plus:如何用一张图片重塑AI生成的艺术世界?
ComfyUI IPAdapter Plus:如何用一张图片重塑AI生成的艺术世界? 【免费下载链接】ComfyUI_IPAdapter_plus 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_IPAdapter_plus 你是否曾经遇到过这样的困境:想要AI生成一张特定风格的…...
)
Neuron | TEE 通过 ReExc-BLAInh 回路逆转情绪障碍_MCE(MedChemExpress)
近期,华中科技大学朱铃强、刘丹教授团队在 Neuron 杂志发表了题为“Noninvasive tactile stimulation engaging a thalamic-amygdala circuit ameliorates mood dysfunction in mouse models of depression-like behavior”的研究论文[1]。 高手过招研究人员建立…...

Windows 一键自动加入企业 AD 域的批处理脚本
一、脚本整体作用 这是一段Windows 一键自动加入企业 AD 域的批处理脚本,无需运维手动打开系统属性、一步步点击加域,全程图形化文字交互、自动调用 PowerShell 执行域加入命令、自动判断加域结果,失败可重试,适合企业运维批量部署办公电脑。 二、逐段代码逻辑解析 1. 基…...

学习笔记 - SCI/时钟与脉冲机制
1.核心基础概念1.1频率(Frequency,Hz)每秒发生多少次周期性变化1 Hz 1 次 / 秒 1 MHz 100万 次 / 秒本质描述“变化速度”1.2周期(Period,T)一次完整变化所需时间T 1/f常见换算频率周期1 MHz1 μs8 MHz0…...