【模型推理优化学习笔记】CUDA加速矩阵乘计算
矩阵乘可以利用gpu多线程并行的特点进行加速计算,但是传统简单的方法需要多次读取数据到寄存器中,增加耗时,因此利用gpu的共享内存可以被一个block内的所有线程访问到的特性,结合tiling技术进行加速计算。
理论部分不解释了,网上有很多,关键在于网上很多利用共享内存计算的代码存在错误(大部分只有在设置blockDim.x == blockDim.y 的时候,凑巧能对齐index给出正确的结果,若这俩不等,结果就错了),这里给出一个修正的版本:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
#include <assert.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#define M 32
#define K 32
#define N 32void initial(float *array, int size)
{for (int i = 0; i < size; i++){array[i] = (float)(1);}
}void printMatrix(float *array, int row, int col)
{float *p = array;for (int y = 0; y < row; y++){for (int x = 0; x < col; x++){printf("%.2f ", p[x]);}p = p + col;printf("\n");}return;
}__global__ void multiplicateMatrixOnDevice(float *array_A, float *array_B, float *array_C, int M_p, int K_p, int N_p)
{int ix = threadIdx.x + blockDim.x*blockIdx.x;//row numberint iy = threadIdx.y + blockDim.y*blockIdx.y;//col numberif (ix < N_p && iy < M_p){float sum = 0;for (int k = 0; k < K_p; k++){sum += array_A[iy*K_p + k] * array_B[k*N_p + ix];}array_C[iy*N_p + ix] = sum;}
}// Compute C = A * B
// M, K, K, N, M, N
__global__ void matrixMultiplyShared(float *A, float *B, float *C,int numARows, int numAColumns, int numBRows, int numBColumns, int numCRows, int numCColumns)
{//@@ Insert code to implement matrix multiplication here//@@ You have to use shared memory for this MP// 1. 相比网上代码,修改这里的index__shared__ float sharedM[8][16]; __shared__ float sharedN[16][8]; int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int row = by * blockDim.y + ty; int col = bx * blockDim.x + tx; float Csub = 0.0;// for (int i = 0; i < 2; ++i) for (int i = 0; i < (int)(ceil((float)numAColumns / blockDim.x)); i++){if (i*blockDim.x + tx < numAColumns && row < numARows)sharedM[ty][tx] = A[row*numAColumns + i*blockDim.x + tx];elsesharedM[ty][tx] = 0.0;// 2. 相比网上代码,修改这里的indexif (i*blockDim.x + tx < numBRows && col < numBColumns)sharedN[tx][ty] = B[(i*blockDim.x + tx)*numBColumns + col];elsesharedN[tx][ty] = 0.0;__syncthreads();// if (blockIdx.x == 0 && blockIdx.y == 1 && threadIdx.x == 0 && threadIdx.y ==0 ) {// printf("sharedM: \n");// for (int i = 0; i < 8; ++i) {// for (int j = 0; j < 16; ++j) {// printf("%f ", sharedM[i][j]);// }// printf("\n");// }// printf("sharedN: \n");// for (int i = 0; i < 16; ++i) {// for (int j = 0; j < 8; ++j) {// printf("%f ", sharedM[i][j]);// }// printf("\n");// }// }for (int j = 0; j < blockDim.x; j++)// 3. 相比网上代码,修改这里的indexCsub += sharedM[ty][j] * sharedN[j][ty];__syncthreads();}if (row < numCRows && col < numCColumns)C[row*numCColumns + col] = Csub;}int main(int argc, char **argv)
{clock_t start = 0, finish = 0;float time;int Axy = M * K;int Bxy = K * N;int Cxy = M * N;float *h_A, *h_B, *hostRef, *deviceRef;h_A = (float*)malloc(Axy * sizeof(float));h_B = (float*)malloc(Bxy * sizeof(float));int nBytes = M * N * sizeof(float);hostRef = (float*)malloc(Cxy * sizeof(float));deviceRef = (float*)malloc(Cxy * sizeof(float));initial(h_A, Axy);initial(h_B, Bxy);// printMatrix(h_A, M, K);float *d_A, *d_B, *d_C;cudaMalloc((void**)&d_A, Axy * sizeof(float));cudaMalloc((void**)&d_B, Bxy * sizeof(float));cudaMalloc((void**)&d_C, Cxy * sizeof(float));cudaMemcpy(d_A, h_A, Axy * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, Bxy * sizeof(float), cudaMemcpyHostToDevice);int dimx = 16;int dimy = 16;dim3 block(dimx, dimy);dim3 grid((M + block.x - 1) / block.x, (N + block.y - 1) / block.y);cudaEvent_t gpustart, gpustop;float elapsedTime = 0.0;cudaEventCreate(&gpustart);cudaEventCreate(&gpustop);cudaEventRecord(gpustart, 0);// multiplicateMatrixOnDevice<<<grid,block>>> (d_A, d_B, d_C, M, K, N);matrixMultiplyShared << < grid, block >> > (d_A, d_B, d_C, M, K, K, N, M, N);cudaDeviceSynchronize();cudaEventRecord(gpustop, 0);cudaEventSynchronize(gpustop);cudaEventElapsedTime(&elapsedTime, gpustart, gpustop);cudaEventDestroy(gpustart);cudaEventDestroy(gpustop);cudaMemcpy(deviceRef, d_C, Cxy * sizeof(float), cudaMemcpyDeviceToHost);printMatrix(deviceRef, M, N);return 0;
}
相关文章:

【模型推理优化学习笔记】CUDA加速矩阵乘计算
矩阵乘可以利用gpu多线程并行的特点进行加速计算,但是传统简单的方法需要多次读取数据到寄存器中,增加耗时,因此利用gpu的共享内存可以被一个block内的所有线程访问到的特性,结合tiling技术进行加速计算。 理论部分不解释了&#…...
第三届 “鹏城杯”(初赛)
第三届 “鹏城杯”(初赛) WEB Web-web1 反序列化tostring打Hack类 Payload:O%3A1%3A%22H%22%3A1%3A%7Bs%3A8%3A%22username%22%3BO%3A6%3A%22Hacker%22%3A2%3A%7Bs%3A11%3A%22%00Hacker%00exp%22%3BN%3Bs%3A11%3A%22%00Hacker%00cmd%22%3BN%3B%7D%7D…...

React Hooks为什么要在顶层使用?
为什么必须在函数顶层使用hooks? 使用过 hooks 的小伙伴应该都会发现,hooks只能在函数式组件的顶层使用,不能在循环,条件或嵌套函数中调用 Hook。 为什么呢? 查阅了很多答案,总结如下: hook…...
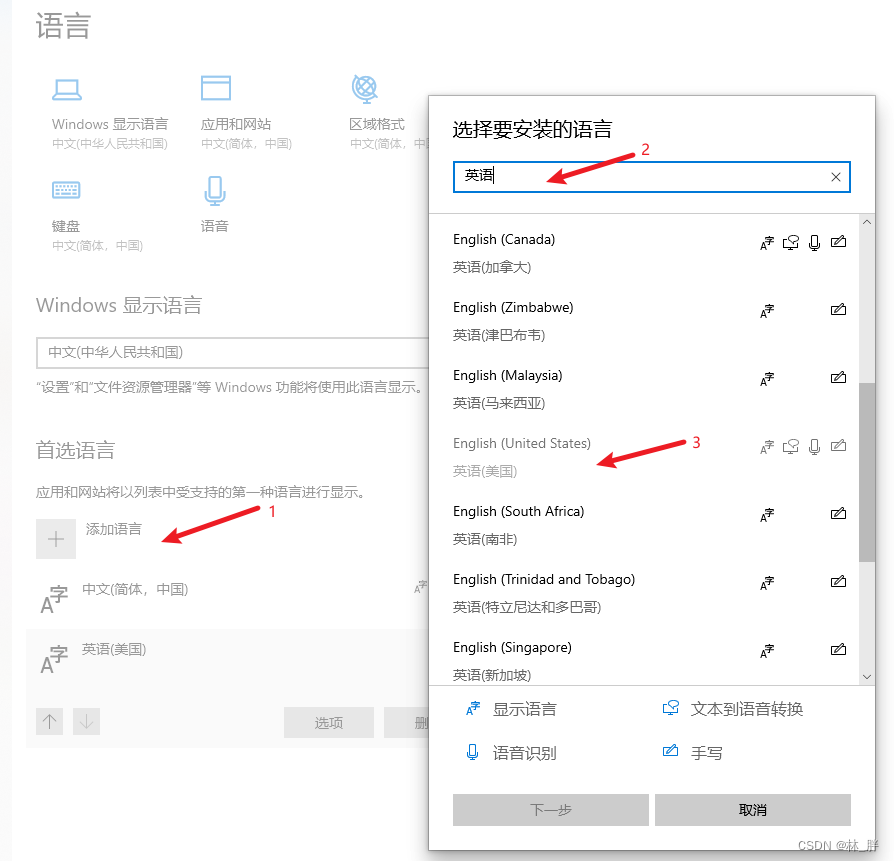
Vscode Vim自动切换
在VsCode里安装了Vim插件,由于Vim插件存在Normal和Insert两种模式,会需要经常性的按shift切换中英文,太过麻烦,本文介绍一下如何通过im-select来解决。 首先先确保自己的电脑里装有英文语言包,win10系统下可以使用Win…...

C语言初学1:详解#include <stdio.h>
一、概念 #include <stdio.h> 称为编译预处理命令,它在告诉C编译器在编译时包含stdio.h文件,如果在代码中,调用了这个头文件中的函数或者宏定义,则需引用该头文件。 二、作用 stdio.h是c语言中的标准输入输出的头文件&am…...
5 Tensorflow图像识别(下)模型构建
上一篇:4 Tensorflow图像识别模型——数据预处理-CSDN博客 1、数据集标签 上一篇介绍了图像识别的数据预处理,下面是完整的代码: import os import tensorflow as tf# 获取训练集和验证集目录 train_dir os.path.join(cats_and_dogs_filter…...
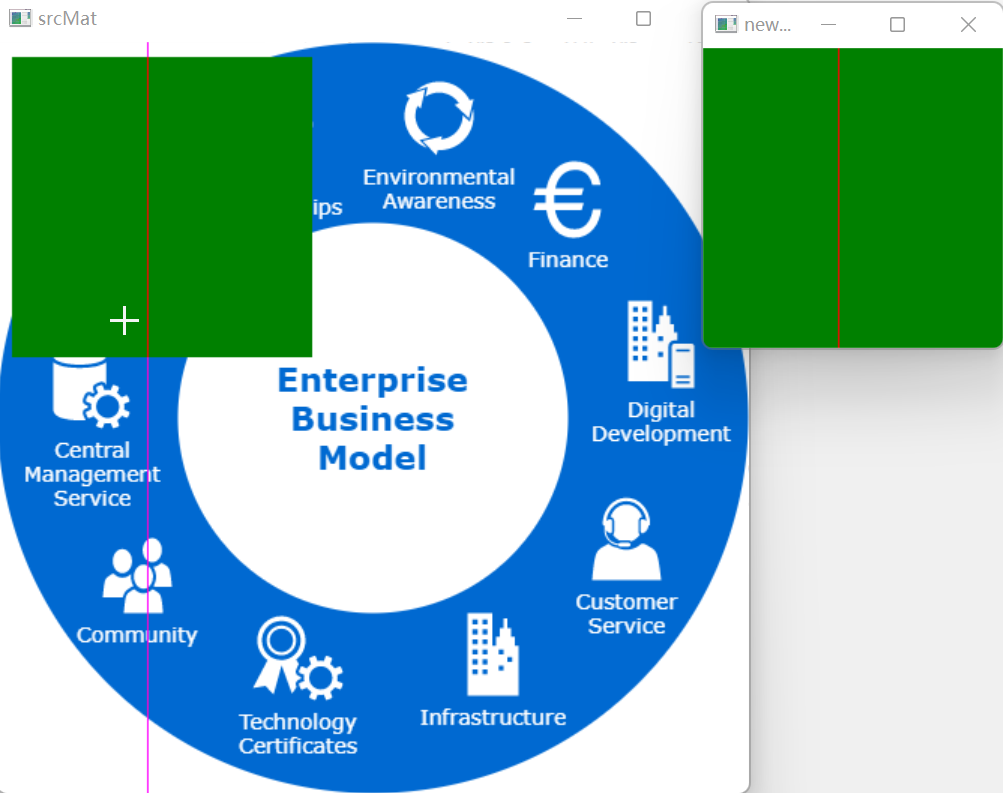
OpenCV 图像复制和图像区域读写
图像复制 共享数据, 使用 new Mat(srcMat, ...) 和 newMatsrcMat 生成新的Mat都和原Mat共享数据, 也就是说如果修改某一Mat,其他Mat也会随之改变复制全新的Mat, 使用CopyTo() 和 Clone() 方法将生成一个全新的Mat, 新Mat和原Mat不共享数据. 图像区域和点的读写 区域读取: 通过s…...
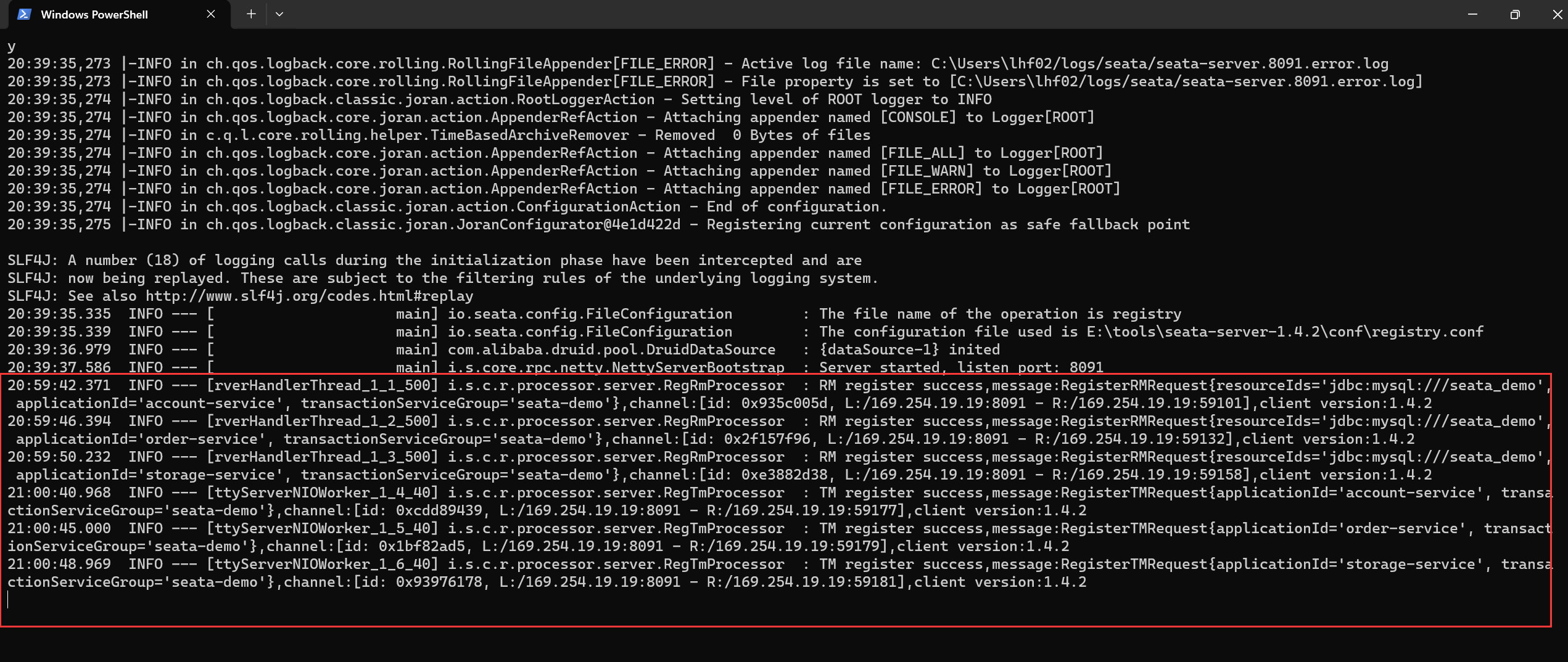
【分布式事务】初步探索分布式事务的概率和理论,初识分布式事的解决方案 Seata,TC 服务的部署以及微服务集成 Seata
文章目录 一、分布式服务案例1.1 分布式服务 demo1.2 演示分布式事务问题 二、分布式事务的概念和理论2.1 什么是分布式事务2.2 CAP 定理2.3 BASE 理论2.4 分布式事务模型 三、分布式事务解决方案 —— Seata3.1 什么是 Seata3.2 Seata 的架构3.3 Seata 的四种分布式事务解决方…...
es6过滤对象里面指定的不要的值filter过滤
//过滤出需要的值this.dataItemTypeSelectOption response.data.filter(ele > ele.dictValue tree||ele.dictValue float4);//过滤不需要的值this.dataItemTypeSelectOption response.data.filter((item) > {return item.dictValue ! "float4"&&it…...

Docker从入门到上天系列第二篇:传统虚拟机和容器的对比以及Docker的作用以及所解决的问题
大神推荐:作者有幸结识技术大神孙哥为好友获益匪浅,现在把孙哥作为朋友分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员。 本专栏简介:话不多说,让我们一起干翻Docker 本文章简介:话不多说,让我们讲清楚首先讲清楚Docker是什么 文章…...

共话医疗数据安全,美创科技@2023南湖HIT论坛,11月11日见
11月11日浙江嘉兴 2023南湖HIT论坛 如约而来 深入数据驱动运营管理、运营数据中心建设、数据治理和数据安全、数据资产“入表”等热点、前沿话题 医疗数据安全、数字化转型深耕者—— 美创科技再次深入参与 全新发布:医疗数据安全白皮书 深度探讨:数字…...

乐园要吸引儿童还是家长?万达宝贝王2000万会员的求精之路
2023年6月,万达宝贝王正式迈入“400店时代”。 万达宝贝王在全国200多座城市,以游乐设施、主题活动、成长课程服务10亿多用户,拥有2000多万名会员,是真正的国内儿童乐园领跑者。 当流量时代变成“留量”时代,用户增长…...

ps人像怎么做渐隐的效果?
photoshop怎么制作人像渐隐的图片效果?渐隐效果需要使用渐变来实现,下面我们就来看看详细的教程。 首先,我们打开Photoshop,点击屏幕框选的【打开】,打开一张背景图片。 下面,我们点击左上角【文件】——【…...

为什么IN操作符一般比OR操作符清单执行更快
IN操作符一般比OR操作符清单执行更快的主要原因有以下几点: 查询优化:数据库管理系统通常会针对IN操作符进行更好的查询优化。它可以使用哈希表或二叉搜索树等数据结构来更快地查找匹配的值,从而减少了搜索时间。而OR操作符需要逐个比较每个条…...
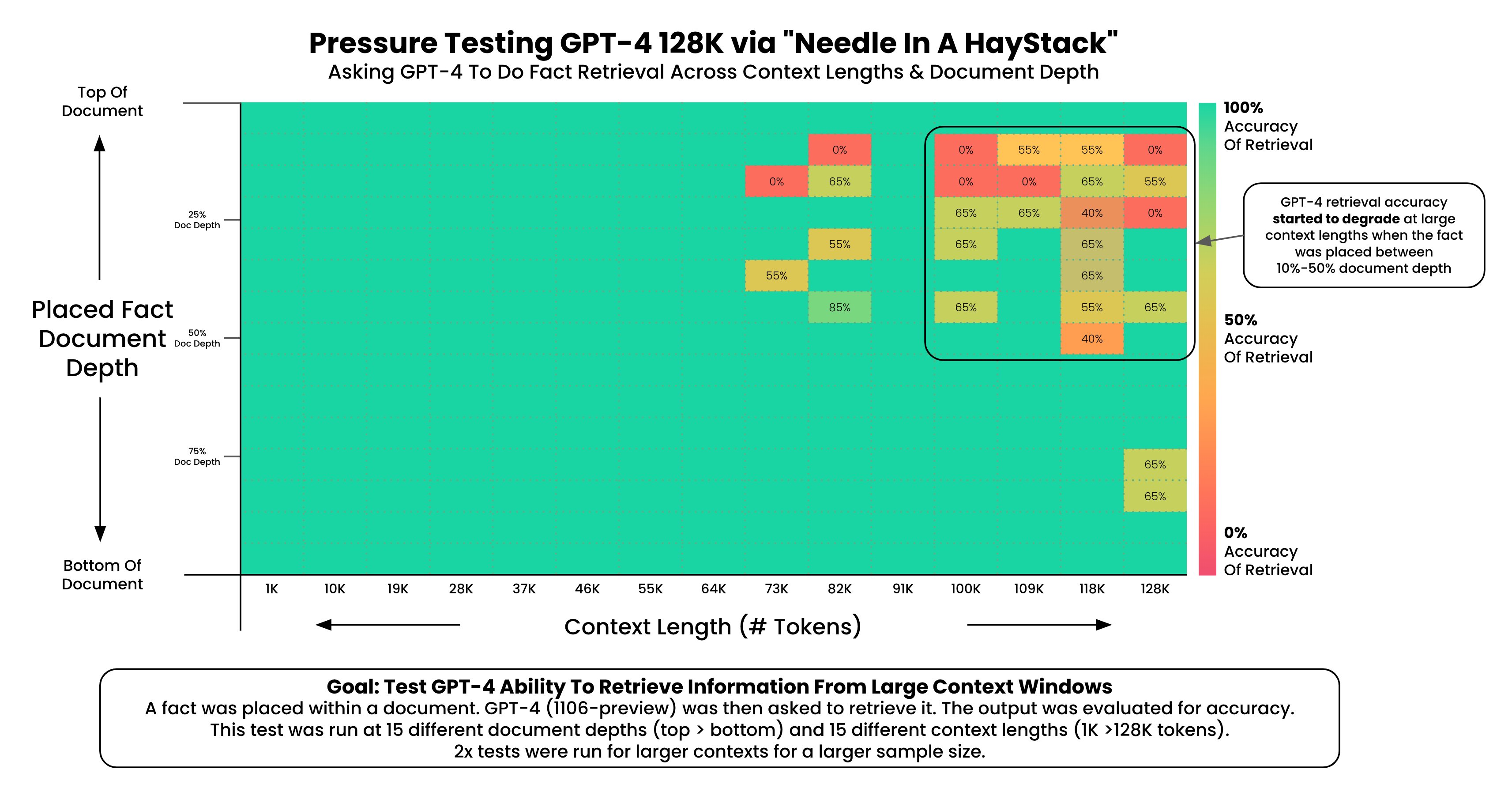
GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!
本文原文来自DataLearnerAI官方网站:GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699526438975 GPT-4 Turbo是OpenAI最新发布的号称…...
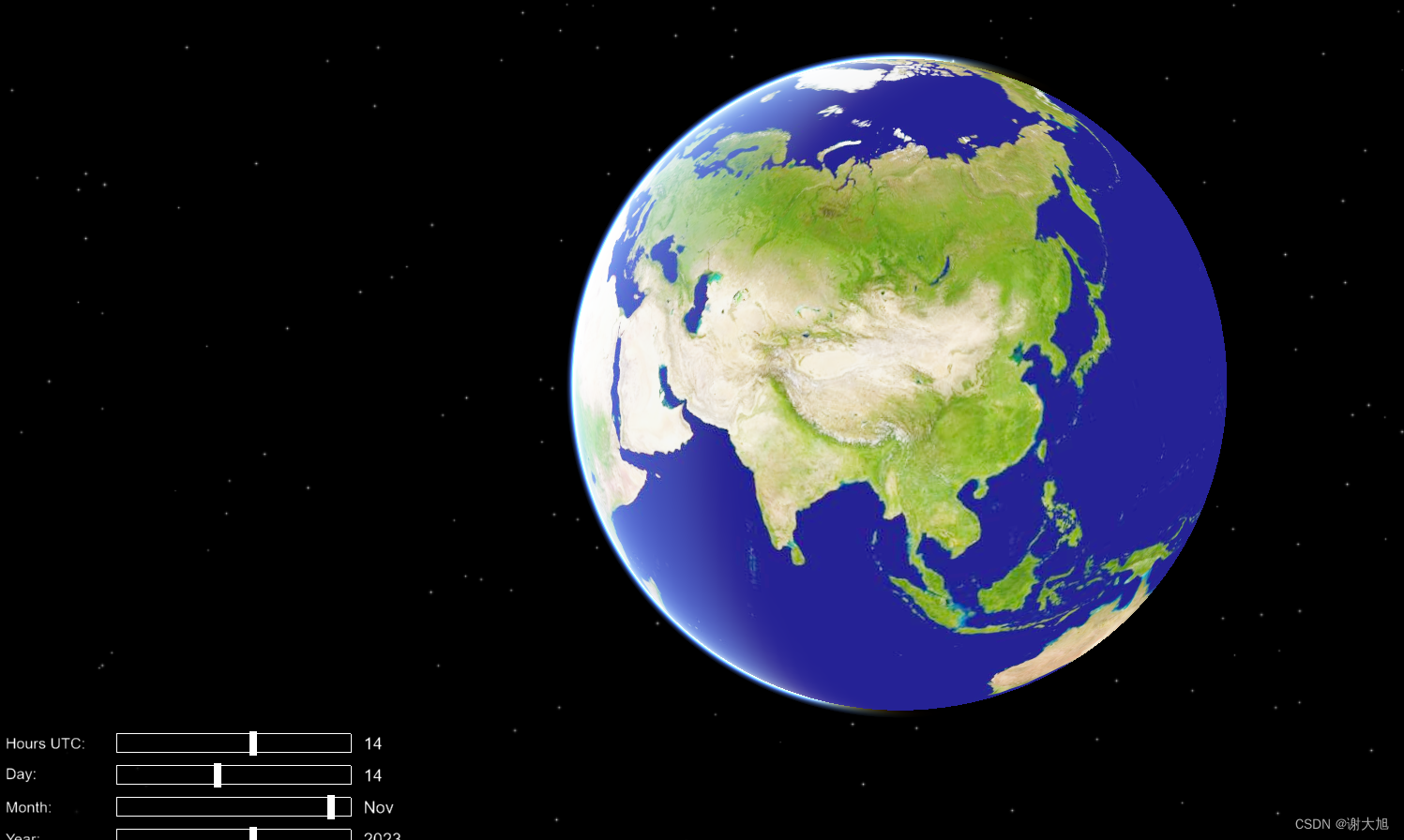
osg之黑夜背景地月系显示
目录 效果 代码 效果 代码 /** * Lights test. This application is for testing the LightSource support in osgEarth. * 灯光测试。此应用程序用于测试osgEarth中的光源支持。 */ #include "stdafx.h" #include <osgViewer/Viewer> #include <osgEarth/N…...

持续交付-Jenkinsfile 语法
实现 Pipeline 功能的脚本语言叫做 Jenkinsfile,由 Groovy 语言实现。Jenkinsfile 一般是放在项目根目录,随项目一起受源代码管理软件控制,无需像创建"自由风格"项目一样,每次可能需要拷贝很多设置到新项目,…...
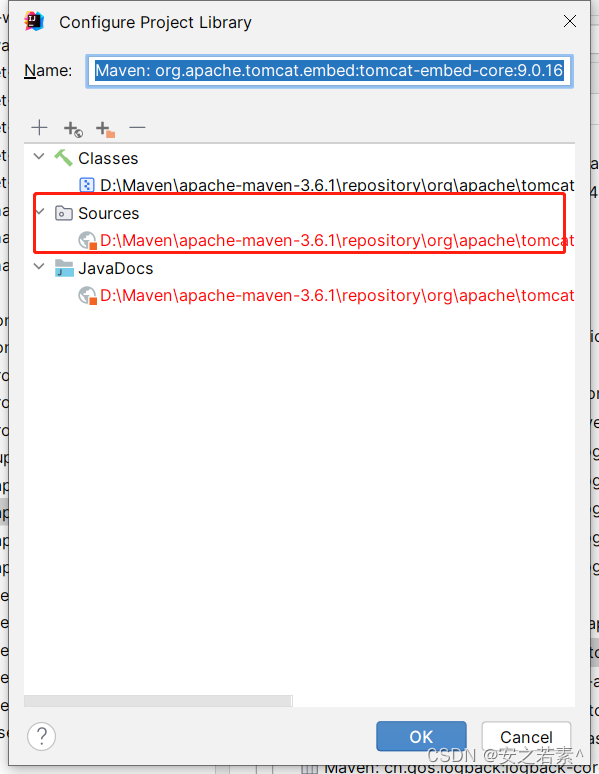
IDEA重新choose source
大概现状是这样:之前有个工程,依赖了别的模块基础包,但当时并没有依赖包的源码工程,因此,通过鼠标左键点进去,看到的是jar包里的class文件,注释什么的都去掉了的,不好看。后面有这个…...
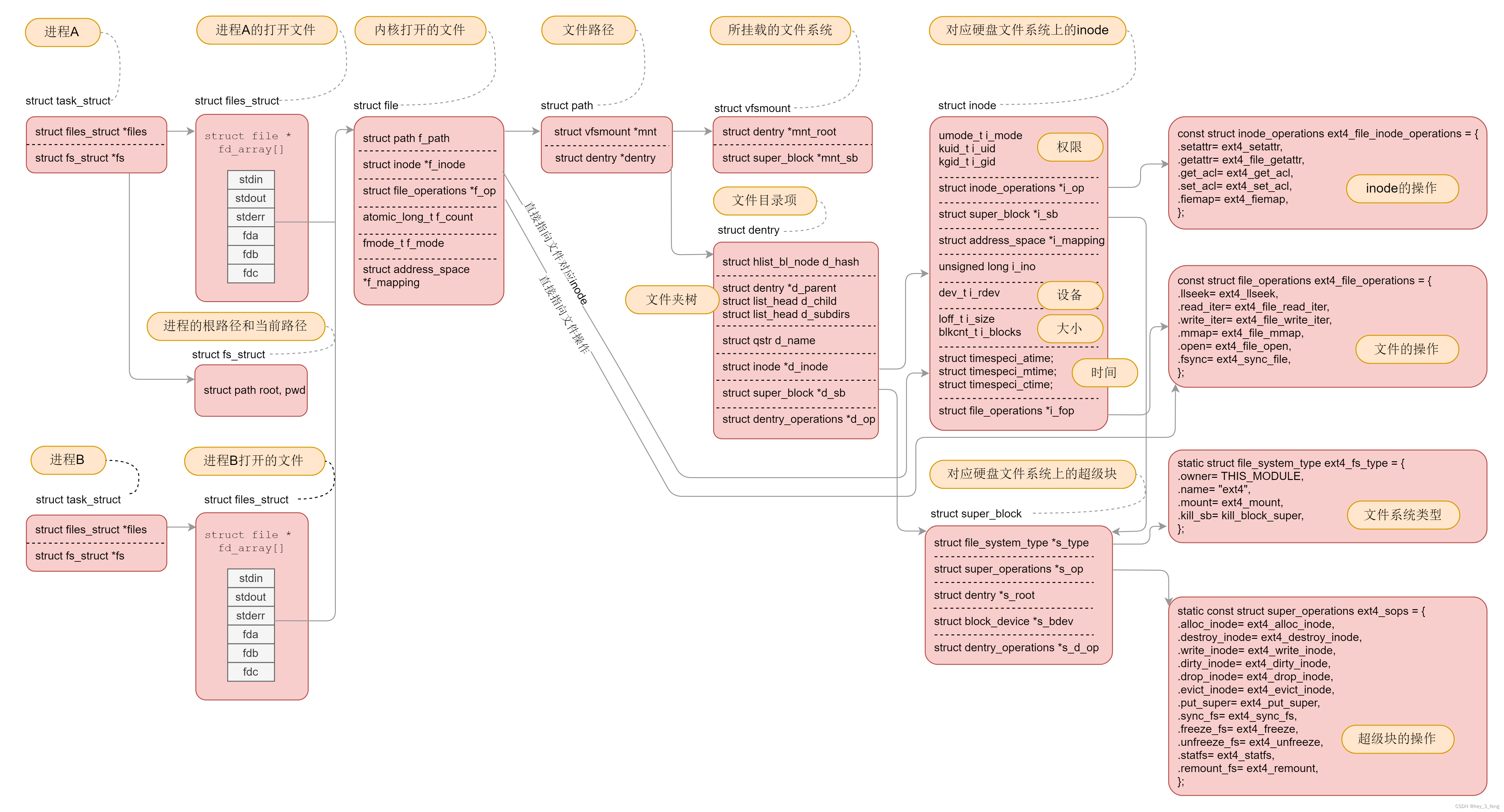
解析虚拟文件系统的调用
Linux 可以支持多达数十种不同的文件系统。它们的实现各不相同,因此 Linux 内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。它提供了常见的文件系统对象模型,例如 inode、directory entry、mount 等,以及…...
佳能相机拍出来的dat文件怎么修复为正常视频
3-3 佳能相机是普通人用得最多的相机之一,也有一些专业机会用于比较重要的场景,比如婚庆、会议录像、家庭录像使用等。 但作为电子产品,经常会出现一些奇怪的故障,最严重的应该就是拍出来的东西打不开了。 本文案例是佳能相机拍…...
)
【仅开放72小时】CUDA 13.3.1生产环境适配清单(含PyTorch 2.4/DeepSpeed 0.14/Triton 3.0兼容性矩阵+17个已验证patch)
更多请点击: https://intelliparadigm.com 第一章:CUDA 13编程与AI算子优化全景概览 CUDA 13 引入了对 Hopper 架构的深度支持、增强的 GPU 内存管理机制(如 Unified Memory 自适应预取)、以及面向 AI 算子开发的关键语言与工具链…...

iFEM深度解析:MATLAB自适应有限元方法框架的性能突破
iFEM深度解析:MATLAB自适应有限元方法框架的性能突破 【免费下载链接】ifem iFEM is a MATLAB software package containing robust, efficient, and easy-following codes for the main building blocks of adaptive finite element methods on unstructured simpl…...

解决方案:Open WebUI自托管AI平台 - 企业级私有化部署与安全AI交互指南
解决方案:Open WebUI自托管AI平台 - 企业级私有化部署与安全AI交互指南 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui Open WebUI是一款功能丰…...

QQ空间历史说说完整备份指南:GetQzonehistory让你一键保存青春记忆
QQ空间历史说说完整备份指南:GetQzonehistory让你一键保存青春记忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心那些记录青春的QQ空间说说会随着时间消失&…...
)
告别理论!用一张‘眼图’看懂你的GTX链路信号质量(误码率、抖动、噪声容限全解析)
从眼图诊断到链路优化:GTX信号质量实战解码手册 当示波器屏幕上那个神秘的"眼睛"缓缓睁开时,它正在向你诉说整个高速链路的健康状态。这张由无数比特流叠加而成的图形,远比任何参数表格都更直观地揭示了信号在时域和幅值域的完整故…...
)
保姆级教程:在RK3399 Android8.1上搞定LT9211 MIPI转LVDS驱动移植(附完整DTS配置)
RK3399平台LT9211芯片MIPI转LVDS驱动移植全流程实战指南 在嵌入式显示方案开发中,MIPI与LVDS接口的转换是常见需求。Rockchip RK3399作为高性能处理器,虽原生不支持LVDS输出,但通过LT9211等转换芯片可实现灵活适配。本文将完整呈现从硬件原理…...

3步构建你的专属音频空间:从基础调校到专业级系统音频优化
3步构建你的专属音频空间:从基础调校到专业级系统音频优化 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 想象一下,你正在享受最爱的音乐,但总觉得低音不够浑厚&…...

B站M4S转MP4终极指南:三分钟学会视频备份完整方案
B站M4S转MP4终极指南:三分钟学会视频备份完整方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾因B站视频突然下架而措手不…...
)
手把手教你用北太天元复现经典MATLAB三维绘图(附完整代码与对比图)
北太天元三维绘图实战:从MATLAB代码迁移到国产科学计算平台 第一次打开北太天元时,那种熟悉又陌生的感觉让我想起了十年前初学MATLAB的时光。作为一款由北京大学团队研发的国产科学计算软件,北太天元在语法和功能设计上对MATLAB的高度兼容&am…...

Oumuamua-7b-RP参数详解:max_length=512对日语长句生成完整性的影响
Oumuamua-7b-RP参数详解:max_length512对日语长句生成完整性的影响 1. 模型概述 Oumuamua-7b-RP是一款基于Mistral-7B架构的日语角色扮演专用大语言模型Web界面,专为沉浸式角色对话体验设计。该模型在日语长文本生成方面表现出色,特别适合需…...