机器学习模板代码(期末考试复习)自用存档
机器学习复习代码
利用sklearn实现knn

import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVdef model_selection(x_train, y_train):## 第一个是网格搜索## p是选择查找方式:1是欧式距离 2是曼哈顿距离params = {'n_neighbors': [3,5,7], 'p': [1,2]}model = KNeighborsClassifier()gs = GridSearchCV(model, params, verbose=2, cv=5)gs.fit(x_train, y_train)print("Best Model:", gs.best_params_, "Accuracy:", gs.best_score_)print(gs.best_estimator_)return gs.best_estimator_def read():filename = r"data/shuixianhua.xlsx"data = pd.read_excel(filename, header=None)## iloc[行,列]x1 = data.iloc[1:, [0, 1]].valuesx2 = data.iloc[1:, [3, 4]].values# print(x2)y1 = data.iloc[1:, 2].valuesy2 = data.iloc[1:, 5].valuesx = np.vstack((x1, x2)) # 竖向合并print("x:")print(x)y = np.hstack((y1, y2)) # 横向合并print("y:")print(y)## 这里是因为我把excel的y理解成string类型了,如果正常读可以不加这个## 将y转为数值的inty = y.astype(int)return x, yif __name__ == '__main__':x, y = read()best_model = model_selection(x, y)利用sklearn实现线性回归
数据集展示

import pandas as pd
from sklearn.linear_model import LinearRegression
import numpy as np
def MAE(y,y_pre):return np.mean(np.abs(y-y_pre))
def MSE(y,y_pred):return np.mean((y-y_pred)**2)
def RMSE(y,y_pred):return np.sqrt(MSE(y,y_pred))
def MAPE(y,y_pred):return np.mean(np.abs(y-y_pred)/y)
def R2(y,y_pred):u=np.sum((y-y_pred)**2)v=np.sum((y-np.mean(y_pred))**2)return 1-(u/v)
def judege(name,y,y_pre):mae=MAE(y,y_pre)mse=MSE(y,y_pre)rmse=RMSE(y,y_pre)mape=MAPE(y,y_pre)r2=R2(y,y_pre)print(f"{name}的MAE:{mae},MSE:{mse},RMSE:{rmse}.MAPE:{mape},R2:{r2}")def read():filename = r"../data/ComposePlot.xlsx"data=pd.read_excel(filename,header=None)x1 = data.iloc[2:, [0,]].valuesy1 = data.iloc[2:,1].valuesx2 = data.iloc[2:,[2,]].valuesy2 = data.iloc[2:,3].valuesx3 = data.iloc[2:,[4,]].valuesy3 = data.iloc[2:,5].valuesx4 = data.iloc[2:,[6,]].valuesy4 = data.iloc[2:,7].valuesreturn x1,y1,x2,y2,x3,y3,x4,y4def getModel(x,y):model = LinearRegression()model.fit(x,y)return modeldef main(x1, y1, x2, y2, x3, y3, x4, y4):model1 = getModel(x1,y1)model2 = getModel(x2, y2)model3 =getModel(x3,y3)model4 =getModel(x4,y4)judege("mode1",y1,model1.predict(x1))judege("mode2",y2,model2.predict(x2))judege("mode3",y3,model3.predict(x3))judege("mode4",y4,model4.predict(x4))if __name__ == '__main__':x1, y1, x2, y2, x3, y3, x4, y4 = read()main(x1, y1, x2, y2, x3, y3, x4, y4)
利用sklearn实现逻辑回归
数据集展示

import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegressiondef main(x,y):model=LogisticRegression()model.fit(x,y)print(model.predict(x))
def read():filename = "data/student.xlsx"data=pd.read_excel(filename,header=None)x=data.iloc[1:,[0,1]].valuesy=data.iloc[1:,2].valuesprint(x)print(y)return x,y
if __name__ =='__main__':x,y=read()main(x,y)
利用sklearn实现SVM(向量机)
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import numpy as np
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, \f1_scoredef load_data(): #导入的尾花data = load_iris()x, y = data.data, data.targetx_train, x_test, y_train, y_test = \train_test_split(x, y, test_size=0.3,shuffle=True, random_state=20)return x, y, x_train, x_test, y_train, y_test## 无脑写这个就行
def model_selection(x_train, y_train):model = SVC()paras = {'C': np.arange(1, 10, 5),# rbf:高斯核函数 linear:线性核函数 poly:多项式核函数'kernel': ['rbf', 'linear', 'poly'],'degree': np.arange(1, 10, 2),'gamma': ['scale', 'auto'],'coef0': np.arange(-10, 10, 5)}gs = GridSearchCV(model, paras, cv=3, verbose=2, n_jobs=3)gs.fit(x_train, y_train)print('best score:', gs.best_score_)print('best parameters:', gs.best_params_)return gs.best_params_def train(x_train, x_test, y_train, y_test, C, gamma, kernel):model = SVC(C=C, kernel=kernel, gamma=gamma)model.fit(x_train, y_train)y_pred = model.predict(x_test)# 生成混淆矩阵confusion = confusion_matrix(y_test, y_pred)print("混淆矩阵:\n", confusion)# 生成分类报告,包括准确率、精度、召回率和 F1 得分accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred, average='weighted')recall = recall_score(y_test, y_pred, average='weighted')f1 = f1_score(y_test, y_pred, average='weighted')print("准确率Accuracy:", accuracy)print("精度Precision:", precision)print("召回率Recall:", recall)print("FScore:", f1)if __name__ == '__main__':X, Y, x_train, x_test, y_train, y_test = load_data()best_params = model_selection(x_train, y_train)## 这步骤也是无脑写就行train(x_train, x_test, y_train, y_test, best_params["C"], best_params["gamma"], best_params["kernel"])小知识点扩展
将数据分成训练集和测试集
x_train, x_test, y_train, y_test = \train_test_split(x, y, test_size=0.3,shuffle=True, random_state=20)
来自chargpt的解释
是的,这段代码用于将数据集分成训练集和测试集。具体地说,它使用
train_test_split函数将输入的特征数据x和标签数据y分成四个部分:x_train(训练集的特征数据)、x_test(测试集的特征数据)、y_train(训练集的标签数据)和y_test(测试集的标签数据)。以下是这段代码的主要参数和作用:
x是特征数据。y是标签数据。test_size=0.3指定了测试集的比例,这里是总数据的30%将被用作测试集。shuffle=True表示在分割数据之前对数据进行洗牌,以确保数据的随机性。random_state=20是一个随机种子,用于确保每次运行代码时分割数据的结果都相同,这有助于复现实验结果。
综上所诉,只要背就好了,还有参数的意思
归一化
def hypo(x,w,b):z=np.matmul(x,w)+bh_x=1/(1+np.exp(-z))h_x=(h_x>=0.5)*1return h_x
书上p49,我也不太懂归一化的用法,其中z=wx+b
从0实现线性回归
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 添加归一化函数
def normalize_data(data):min_val = np.min(data)max_val = np.max(data)normalized_data = (data - min_val) / (max_val - min_val)return normalized_datadef prediction(X, W, bias):return np.matmul(X, W) + biasdef cost_function(X, y, W, bias):m, n = X.shapey_hat = prediction(X, W, bias)return 0.5 * (1 / m) * np.sum((y - y_hat) ** 2)def gradient_descent(X, y, W, bias, alpha):m, n = X.shapey_hat = prediction(X, W, bias)grad_w = -(1 / m) * np.matmul(X.T, (y - y_hat))grad_b = -(1 / m) * np.sum(y - y_hat)W = W - alpha * grad_wbias = bias - alpha * grad_breturn W, biasdef train(X, y, ite=200):m, n = X.shapeW, b, alpha, costs = np.random.randn(n, 1), 0.1, 0.2, []for i in range(ite):costs.append(cost_function(X, y, W, b))W, b = gradient_descent(X, y, W, b, alpha)return costsdef read():filename = r"../../data/easy_test.xlsx"data = pd.read_excel(filename, header=None)x = data.iloc[2:, [0, ]].valuesy = data.iloc[2:, 1].values# 对特征数据 x 进行归一化x_normalized = normalize_data(x)return x_normalized, yif __name__ == '__main__':x, y = read()costs = train(x, y)# print(costs)# 绘制损失曲线plt.figure()plt.plot(range(len(costs)), costs, marker='o', linestyle='-', color='b', label='Training Loss')plt.xlabel('Iteration')plt.ylabel('Cost')plt.title('Training Loss')plt.legend()plt.grid(True)plt.show()
从0实现逻辑回归
相关文章:
机器学习模板代码(期末考试复习)自用存档
机器学习复习代码 利用sklearn实现knn import numpy as np import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import GridSearchCVdef model_selection(x_train, y_train):## 第一个是网格搜索## p是选择查找方式:1是欧…...

使用sizeof()和strlen()去计算【数组】和【指针】的大小
文章目录 一、知识回顾1、回顾sizeof()、strlen的作用:2、数组和指针3、数组名 二、sizeof()、strlen()的使用区别1、注意区别:2、一维数组与一级指针3、二维数组与二级指针 三、总结回顾 一、知识回顾 1、回顾sizeof()、strlen的作用: siz…...
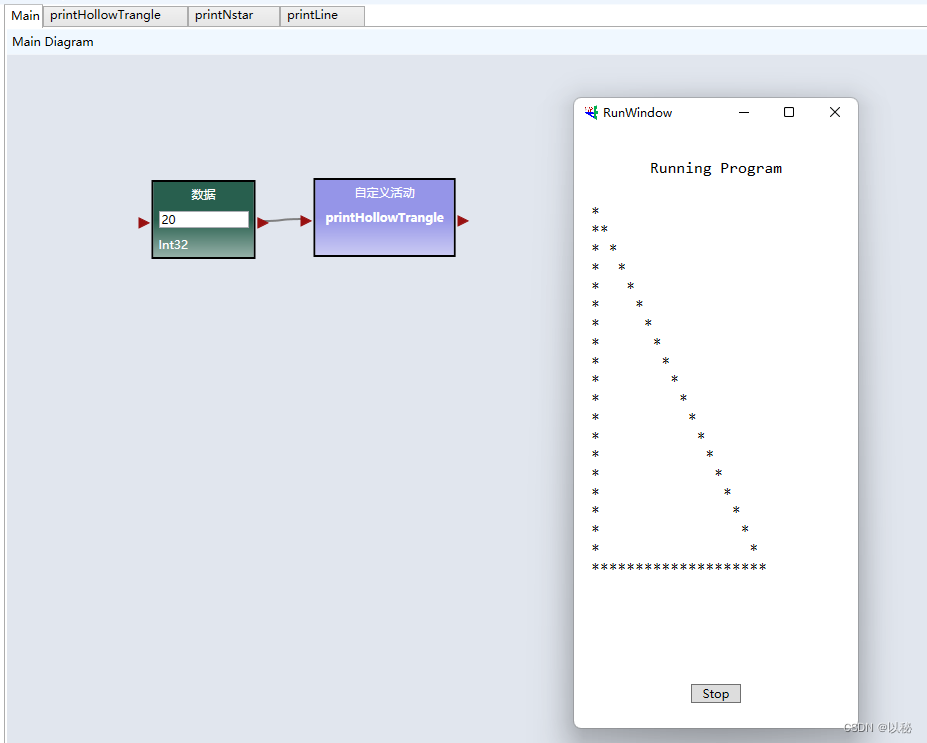
viple进阶4:打印空心三角形
题目:根据用户输入的行数n打印空心三角形,下图分别为n3、n4、n5和n10的效果图 第一步:观察效果图 输入的行数为3,打印结果就有3行;输入的行数为4,则打印结果就有4行;以此类推,输入的…...

Oauth2.0的内容
OAuth 2.0是一个授权协议,用于允许第三方应用程序访问用户在另一个应用程序上存储的受保护资源,而不需要将用户名或密码公开给第三方应用程序。 OAuth2.0基于客户端-服务器模型,通常需要三个主体:客户端、资源所有者和授权服务器…...
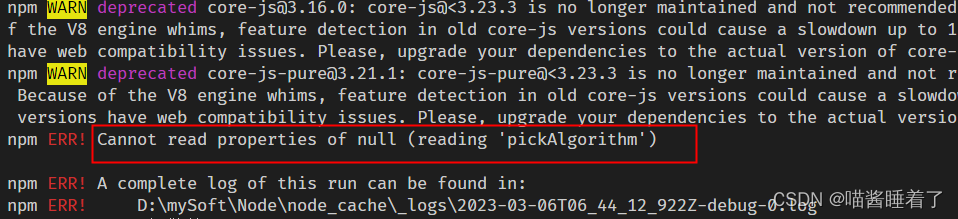
npm 下载包失败解决方案
1.【问题描述】使用 npm 下载vue项目依赖包时失败,版本不一致。 【解决方法】使用 npm install --force npm install --force 是一个命令行指令,用于在 Node.js 环境中使用 npm(Node Package Manager)安装包或模块。–force 参数表…...

C语言---插入排序、希尔排序、冒泡排序、选择排序、快速排序简单介绍
文章目录 插入排序希尔排序冒泡排序选择排序快速排序 本文主要介绍用C语言实现的一些排序方法,有插入排序、希尔排序、冒泡排序、选择排序和快速排序,文章中给出的例子都是按照升序排列的。 插入排序 若数组只有一个元素,自然不用排序&#…...

撸视频号收益这个副业靠谱吗?
我是卢松松,点点上面的头像,欢迎关注我哦! 昨天有个人问我说做视频号能月入过万吗? 我的回复是:99%的人不能。 但为什么会经常有人这么问呢,松松思考了一下,原因是最近很多人在晒视频号撸收益的项目&am…...

2、数组、Map+HashMap、Set+Hashset、Char和Character类、String类和Char类、Math类
数组 \\一个普通的长度为1的整数数组 Integer[] arr new Integer[1];\\一个普通长度为1的同时元素初始化为1的整数数组。 Integer[] arr new Integer[]{1};\\一个长度为0的空数组 Integer[] arr new Integer[0];Map 常见方法 void clear( ) 从此映射中移除所有映射关系&#…...

ESP8266 WiFi模块快速入门指南
ESP8266是一种低成本、小巧而功能强大的WiFi模块,非常适合于物联网和嵌入式系统应用。本指南将为您提供关于ESP8266 WiFi模块的快速入门步骤和基本知识。 第一步:硬件准备 首先,您需要将ESP8266 WiFi模块与您的开发板连接。通常情况下&#…...
微信小程序将后端返回的图片文件流解析显示到页面
说明 由于请求接口后端返回的图片格式不是一个完整的url,也不是其他直接能显示的图片格式,是一张图片 后端根据模板与二维码生成图片,返回二进制数据 返回为文件流的格式,用wx.request请求的时候,就自动解码成为了下面这样的数据数据格式,这样的数据没…...
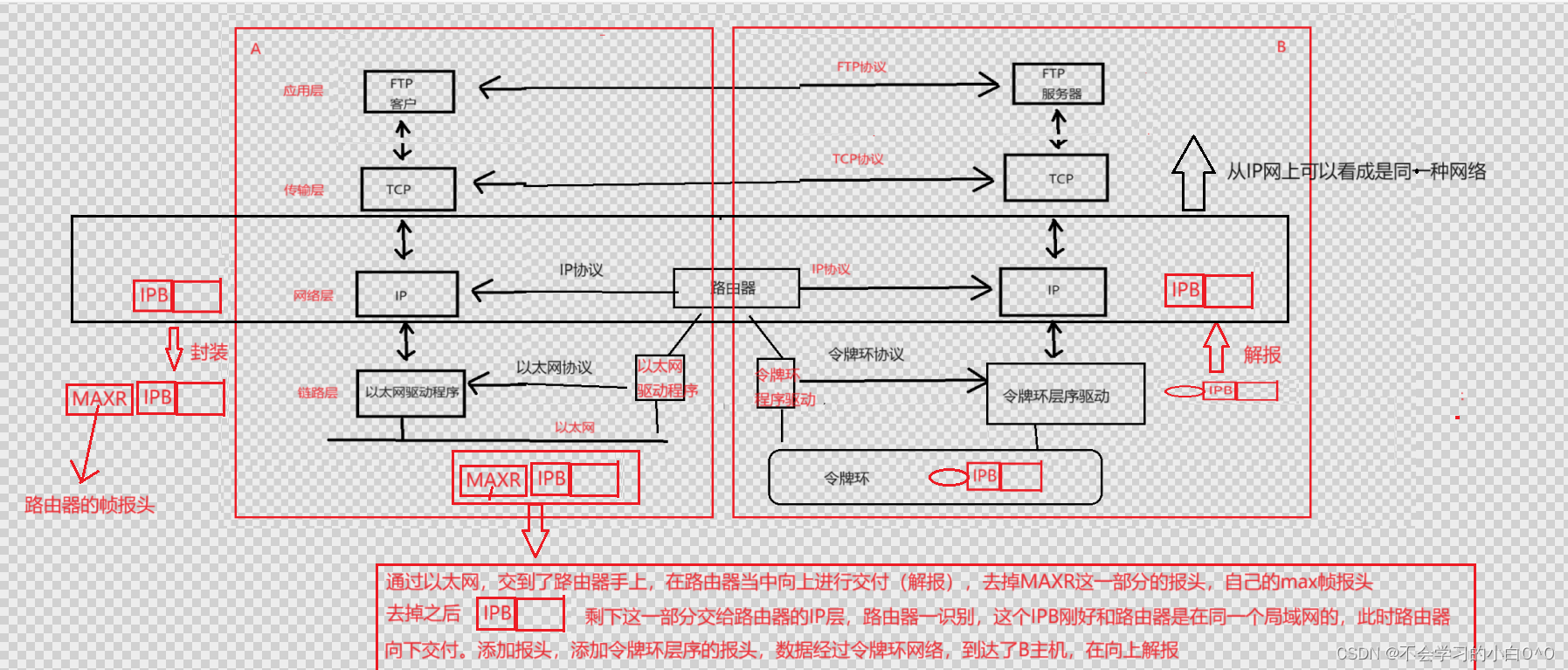
网络基础(1)
目录: 1.了解局域网(LAN)和广域网(WAN) 2.认识“协议” 3.浅谈OSI七层模型 4.网络传输的基本流程 5.路由器这个设备 ---------------------------------------------------------------------------------------…...

flink的AggregateFunction,merge方法作用范围
背景 AggregateFunction接口是我们经常用的窗口聚合函数,其中有一个merge方法,我们一般情况下也是实现了的,但是你知道吗,其实这个方法只有在你使用会话窗口需要进行窗口合并的时候才需要实现 AggregateFunction.merge方法调用时…...
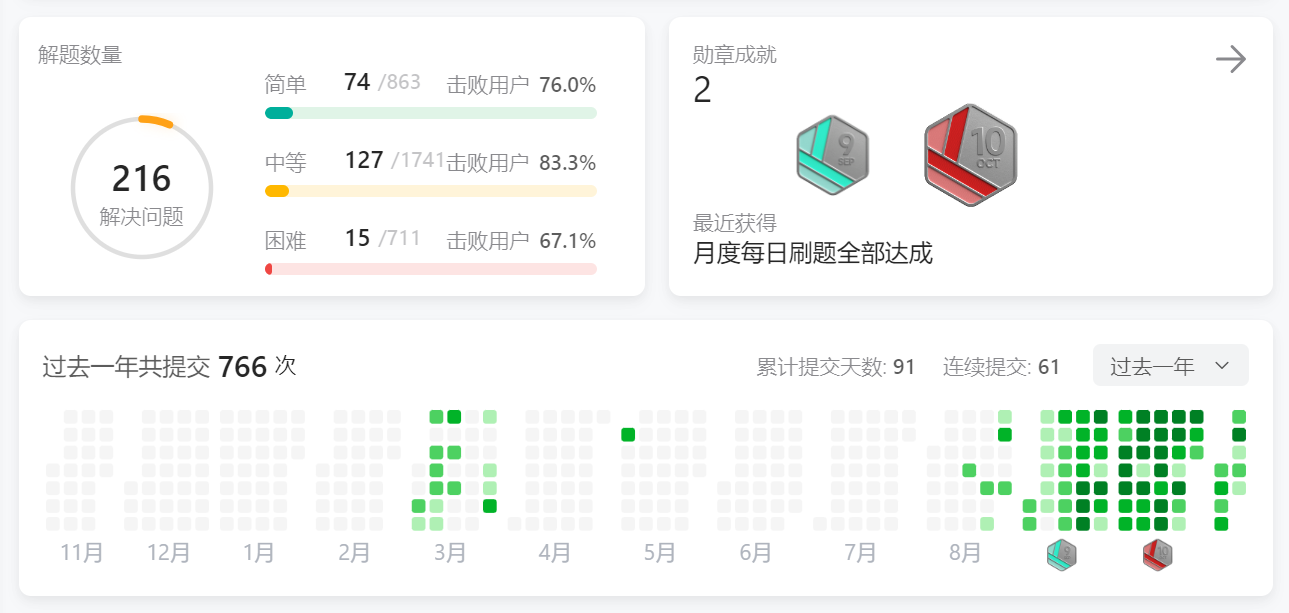
Day25力扣打卡
打卡记录 寻找旋转排序数组中的最小值(二分) 链接 由于是旋转排序数组,所以整个数组有两部分是递增的,选取右侧最后元素,即可将整个数组分为大于该元素和小于该元素,碰头地段即为最小值。 class Solutio…...

SpringCloud - OpenFeign 参数传递和响应处理(全网最详细)
目录 一、OpenFeign 参数传递和响应处理 1.1、feign 客户端参数传递 1.1.1、零散类型参数传递 1. 例如 querystring 方式传参 2. 例如路径方式传参 1.1.2、对象参数传递 1. 对象参数传递案例 1.1.3、数组参数传递 1. 数组传参案例 1.1.4、集合类型的参数传递…...

Postgresql数据类型-布尔类型
前面介绍了PostgreSQL支持的数字类型、字符类型、时间日期类型,这些数据类型是关系型数据库的常规数据类型,此外PostgreSQL还支持很多非常规数据类型,比如布尔类型、网络地址类型、数组类型、范围类型、json/jsonb类型等,从这一节…...

SPASS-交叉表分析
导入数据 修改变量测量类型 分析->描述统计->交叉表 表中显示行、列变量通过卡方检验给出的独立性检验结果。共使用了三种检验方法。上表各种检验方法显著水平sig.都远远小于0.05,所以有理由拒绝实验准备与评价结果是独立的假设,即认为实验准备这个评价指标是…...

用Python的requests库来模拟爬取地图商铺信息
由于谷歌地图抓取商铺信息涉及到API使用和反爬虫策略,直接爬取可能会遇到限制。但是,我们可以使用Python的requests库来模拟爬取某个网页,然后通过正则表达式或其他文本处理方法来提取商铺信息。以下是一个简单的示例: # 导入requ…...

使用EvoMap/Three.js模拟无人机灯光秀
一、创建地图对象 首先我们需要创建一个EM.Map对象,该对象代表了一个地图实例,并设置id为"map"的文档元素作为地图的容器。 let map new EM.Map("map",{zoom:22.14,center:[8.02528, -29.27638, 0],pitch:71.507,roll:2.01,maxPit…...
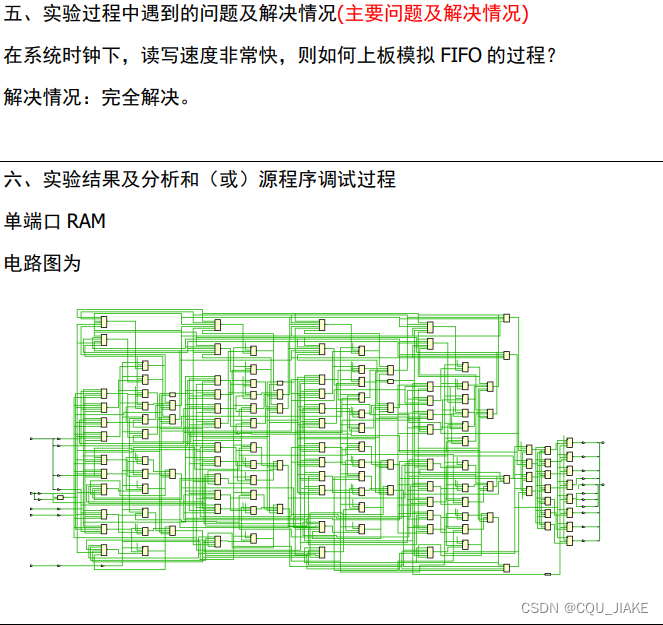
11.9存储器实验总结(单ram,双ram,FIFO)
实验设计 单端口RAM实现 双端口RAM实现 FIFO实现 文件结构为...
安装并使用scrcpy)
linux(ubuntu)安装并使用scrcpy
scrcpy 是一款开源的在计算机上显示和控制 Android 设备的工具。要在 Ubuntu 上使用 scrcpy,你可以按照以下步骤进行安装: 通过命令行安装 scrcpy: 安装 scrcpy: 打开终端(Terminal)并执行以下命令来安装…...

把 AI Agent 真正部署到 SAP BTP:基于 Cloud Foundry 与 SAP AI Core 的企业级落地实战
很多开发者一提到 AI 应用,脑子里浮现出来的还是一个最小可运行的 Hello World:输入一句话,调一下模型接口,页面上回一段文本,任务就算完成了。这样的示例当然有价值,它能帮你在最短时间里摸清模型调用链路。但一旦场景切到企业软件,问题立刻就变了:谁能访问这个 Agent…...

Metso Valmet A413045中央控制器模块
Metso Valmet A413045 中央控制器模块产品概述A413045是Metso Valmet DNA分布式控制系统的高性能中央控制器模块,专为造纸、冶金、电力等重工业场景打造,支持硬实时控制与多任务并行处理。核心特点四核处理器:ARM Cortex-A72架构,…...

OpenSim肌肉模型详解:Hill-Type模型背后的生理学原理与参数调优实战
OpenSim肌肉模型详解:Hill-Type模型背后的生理学原理与参数调优实战 在运动生物力学研究中,肌肉模型的精确度直接决定了仿真结果的可靠性。当你在OpenSim中反复调整F0M、l0M等参数却始终无法匹配实测数据时,问题的根源往往不在于软件操作&…...

边缘重构智慧城市:FPGA SoM如何破解视频系统 “重而慢”
智慧城市这几年有一个挺明显的悖论:摄像头越装越多,平台越做越“智能”,但真正能在现场把问题解决掉的系统,并没有按比例变多。更现实的情况是——城市里“看见”的能力已经很强,但“看懂并立刻行动”的能力࿰…...

不平衡数据集分类评估:ROC与PR曲线对比分析
1. 不平衡数据集分类评估的困境与挑战在机器学习分类任务中,我们常常会遇到类别分布严重不均衡的数据集。比如在信用卡欺诈检测中,正常交易可能占99.9%,而欺诈交易仅占0.1%;在医疗诊断场景中,健康样本可能远多于患病样…...
)
阿里云ECS实战:从零部署AKShare HTTP接口到外网访问(含防火墙、安全组避坑指南)
阿里云ECS实战:从零部署AKShare HTTP接口到外网访问(含防火墙、安全组避坑指南) 在数据驱动的时代,能够快速获取和处理金融数据对于个人开发者和中小团队来说至关重要。AKShare作为一款优秀的开源金融数据接口库,通过P…...
)
Windows10运行OpenClaw 安装配置一站式教程(含最新版安装包)
OpenClaw 小龙虾 Windows10 专属一键部署教程|10分钟搞定本地AI数字员工适配系统:Windows10 64位(纯小白友好版) 核心优势:免命令行、免环境配置、解压即装,内置所有运行依赖,全程可视化操作&am…...

【限时解密】VSCode 1.89+版本性能断崖式下降真相:electron 25迁移引发的配置兼容性危机
更多请点击: https://intelliparadigm.com 第一章:VSCode 1.89性能断崖的现场还原与归因定位 自 VSCode 1.89 版本起,大量用户报告在开启大型 TypeScript 工作区(含 >5k 文件)时,编辑器响应延迟显著上升…...

angular-formly实战教程:构建企业级复杂表单的完整流程
angular-formly实战教程:构建企业级复杂表单的完整流程 【免费下载链接】angular-formly JavaScript powered forms for AngularJS 项目地址: https://gitcode.com/gh_mirrors/an/angular-formly angular-formly是一个基于AngularJS的强大表单构建库…...

3步搞定大众点评全站数据采集:破解动态字体加密,轻松获取30+餐饮数据维度
3步搞定大众点评全站数据采集:破解动态字体加密,轻松获取30餐饮数据维度 【免费下载链接】dianping_spider 大众点评爬虫(全站可爬,解决动态字体加密,非OCR)。持续更新 项目地址: https://gitcode.com/gh…...