6-爬虫-scrapy解析数据(使用css选择器解析数据、xpath 解析数据)、 配置文件
1 scrapy解析数据
1.1 使用css选择器解析数据
1.2 xpath 解析数据
2 配置文件
3 整站爬取博客–》爬取详情–》数据传递
scrapy 爬虫框架补充
# 1 打码平台---》破解验证码-数字字母:ddddocr-计算题,滑块,成语。。。-云打码,超级鹰:demo---》request携带图片发送请求# 2 通过打码平台登录打码平台-浏览器 缩放调100%-mac: 坐标都乘以2# 3 自动登录(京东,12306)---》扫码登录---》拿到二维码---》在本地把二维码弹出来,让用户扫码,可能有很多手机---》每个手机扫一遍---》登录很多账号---》存到cookie池中---》给其他程序用# 4 12306抢票-没有任何第三方 是官方授权的抢票---》第三方全是爬虫-高铁管家(只有一个好用---跨站搜索)-登录---》输入你的用户名和密码--(1 加载了12306网页 2 用户名密码输入)---》拿到你的cookie-cookie池(2000条cookie)-有些登录才能访问的接口:随机从cookie拿一条cookie-候补补票# 4 selenium 爬取京东商品信息-需要登录
# 5 scrapy 爬虫框架
# 6 架构引擎爬虫调度器下载器存储pipline# 命令scrapy startproject 项目名scrapy genspider 爬虫名 爬取地址scrapy crawl 爬虫# 目录结构
1 scrapy解析数据
##### 运行爬虫
scrapy crawl cnblogs##### 可以项目目录下写个main.py
from scrapy.cmdline import execute
execute(['scrapy','crawl','cnblogs','--nolog'])#### 重点
1 response对象有css方法和xpath方法-css中写css选择器 response.css('')-xpath中写xpath选择 response.xpath('')
2 重点1:-xpath取文本内容'.//a[contains(@class,"link-title")]/text()'-xpath取属性'.//a[contains(@class,"link-title")]/@href'-css取文本'a.link-title::text'-css取属性'img.image-scale::attr(src)'
3 重点2:.extract_first() 取一个.extract() 取所有
1.1 使用css选择器解析数据
def parse(self, response):article_list = response.css('article.post-item')# print(type(article_list)) # <class 'scrapy.selector.unified.SelectorList'>for article in article_list:title = article.css('a.post-item-title::text').extract_first()# print(name)author = article.css('a.post-item-author>span::text').extract_first()# print(author)url = article.css('a.post-item-title::attr(href)').extract_first()img = article.css('img.avatar::attr(src)').extract_first()desc = article.css('p.post-item-summary::text').extract() # 文本内容可能放在第二个位置desc_content = desc[0].replace('\n', '').replace(' ', '')if not desc_content:desc_content = desc[1].replace('\n', '').replace(' ', '')print(f"""文章标题:{title}文章作者:{author}链接地址:{url}图片:{img}文章摘要:{desc_content}""")1.2 xpath 解析数据
def parse(self, response):article_list = response.xpath('//article[@class="post-item"]')for article in article_list:name = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()# name = article.xpath('./section/div/a/text()').extract_first()author = article.xpath('.//a[@class="post-item-author"]/span/text()').extract_first()url = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()img = article.xpath('./section/div/p/a/img/@src').extract_first()desc = article.xpath('./section/div/p/text()').extract() # 文本内容可能放在第二个位置desc_content = desc[0].replace('\n', '').replace(' ', '')if not desc_content:desc_content = desc[1].replace('\n', '').replace(' ', '')print('''文章标题:%s文章作者:%s文章地址:%s头像:%s摘要:%s''' % (name, author, url, img, desc_content))
2 配置文件
#### 基础配置
# 项目名
BOT_NAME = "scrapy_demo"
# 爬虫所在路径
SPIDER_MODULES = ["scrapy_demo.spiders"]
NEWSPIDER_MODULE = "scrapy_demo.spiders"# 记住 日志级别
LOG_LEVEL='ERROR'# 请求头中的 USER_AGENT
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"# 是否遵循爬虫协议
ROBOTSTXT_OBEY = False# 默认请求头
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}#爬虫中间件
#SPIDER_MIDDLEWARES = {
# "scrapy_demo.middlewares.ScrapyDemoSpiderMiddleware": 543,
#}# 下载中间件
#DOWNLOADER_MIDDLEWARES = {
# "scrapy_demo.middlewares.ScrapyDemoDownloaderMiddleware": 543,
#}# 持久化相关
#ITEM_PIPELINES = {
# "scrapy_demo.pipelines.ScrapyDemoPipeline": 300,
#}### 高级配置(提高爬取效率)
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100#2 提高日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s
3 整站爬取cnblogs–》爬取详情–》数据传递
# 整站爬取:爬取所有页-解析出下一页 yield Request(url=next, callback=self.parse)爬取文章详情-解析出详情地址:yield Request(url=url, callback=self.detail_parser)多个Request之间数据传递yield Request(url=url,meta={'item':item})在解析的 response中 response.meta.get('item')
def parse(self, response):article_list = response.xpath('//article[@class="post-item"]')for article in article_list:name = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()# name = article.xpath('./section/div/a/text()').extract_first()author = article.xpath('.//a[@class="post-item-author"]/span/text()').extract_first()url = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()img = article.xpath('./section/div/p/a/img/@src').extract_first()desc = article.xpath('./section/div/p/text()').extract() # 文本内容可能放在第二个位置desc_content = desc[0].replace('\n', '').replace(' ', '')if not desc_content:desc_content = desc[1].replace('\n', '').replace(' ', '')# print('''# 文章标题:%s# 文章作者:%s# 文章地址:%s# 头像:%s# 摘要:%s# ''' % (name, author, url, img, desc_content))# 详情地址:url ----》想继续爬取详情item={'name':name,'url':url,'img':img,'text':None}yield Request(url=url, callback=self.detail_parser,meta={'item':item})#### 继续爬取下一页# next='https://www.cnblogs.com'+response.css('div.pager>a:last-child::attr(href)').extract_first()next = 'https://www.cnblogs.com' + response.xpath('//div[@class="pager"]/a[last()]/@href').extract_first()print(next)yield Request(url=next, callback=self.parse)# 逻辑---》起始地址:https://www.cnblogs.com---》回到了parse---》自己解析了(打印数据,继续爬取的地址)---》yield Request对象---》第二页---》爬完后又回到parser解析def detail_parser(self, response):print(len(response.text))item=response.meta.get('item')text=response.css('#cnblogs_post_body').extract_first()item['text']=text# 我们想把:上一个请求解析出来的 标题,摘要,图片 和这个请求解析出来的 文本合并到一起# 这个text 无法和 上面 parse解析出的文章标题对应上print(item)
相关文章:
6-爬虫-scrapy解析数据(使用css选择器解析数据、xpath 解析数据)、 配置文件
1 scrapy解析数据 1.1 使用css选择器解析数据 1.2 xpath 解析数据 2 配置文件 3 整站爬取博客–》爬取详情–》数据传递 scrapy 爬虫框架补充 # 1 打码平台---》破解验证码-数字字母:ddddocr-计算题,滑块,成语。。。-云打码,超…...
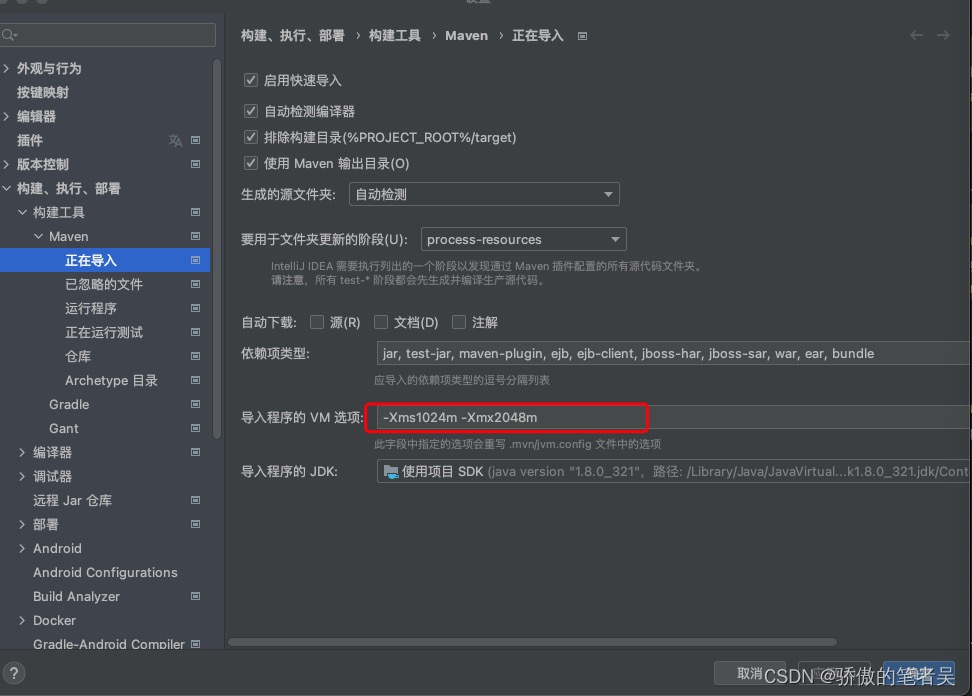
idea 一直卡在maven正在解析maven依赖
修改maven Importing的jvm参数 -Xms1024m -Xmx2048m...
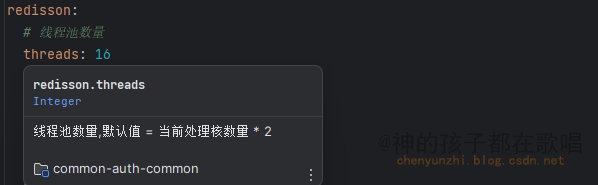
警告:未配置spring boot 配置注解处理器
前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 问题 我再使用ConfigurationProperties(prefix “redisson”)去加载配置文件中的属性的时候,发现idea有个警告 并且配…...

详解虚拟DOM的原理
Virtual DOM(虚拟DOM)是一种编程概念,它是对真实DOM的轻量级抽象表示。在前端开发中,直接操作真实DOM是昂贵的,尤其是当涉及到大量的DOM更新时。Virtual DOM的出现,为优化和提高Web应用的性能提供了一个有效…...
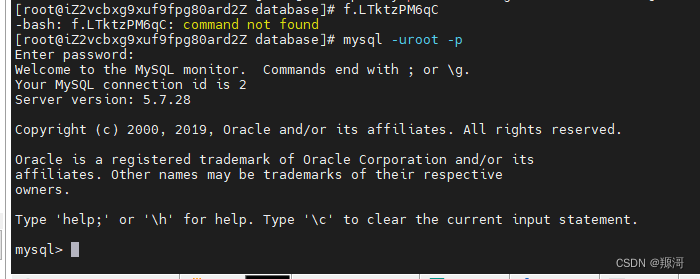
开设自己的网站系类03安装数据库(centos版)
编者买了一个服务器打算自己构建一个网站,用于记录生活。网站大概算是一个个人博客吧。记录创建过程的一些步骤。 前面已经讲过配置服务器的程序运行环境 网站运行还需要数据库,本篇文章则是安装数据库的内容。 卸载mariadb 查看是否有安装 mariadb&…...

Flutter StreamBuilder 实现局部刷新 Widget
Stream 就是事件流或者管道,是基于事件流驱动设计代码,然后监听订阅事件,并针对事件变换处理响应。 Stream 分单订阅流和广播流,单订阅流在发送完成事件之前只允许设置一个监听器,并且只有在流上设置监听器后才开始产生事件&…...
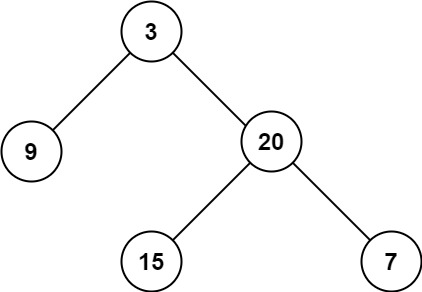
【代码随想录】算法训练营 第十六天 第六章 二叉树 Part 3
104. 二叉树的最大深度 题目 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例: 输入:root [3,9,20,null,null,15,7] 输出:3 思路 用递归来做,…...

【C++数据结构】顺序存储结构的抽象实现
文章目录 前言一、目标二、SeqList实现要点三、SeqList函数实现3.1 get函数3.2 set函数3.3 insert函数带2个参数的insert带一个参数的insert 3.4 remove函数3.5 clear函数3.6 下标运算符重载函数无const版本const版本 3.7 length函数 总结 前言 当谈到C数据结构时,…...

LeetCode75——Day31
文章目录 一、题目二、题解 一、题目 206. Reverse Linked List Given the head of a singly linked list, reverse the list, and return the reversed list. Example 1: Input: head [1,2,3,4,5] Output: [5,4,3,2,1] Example 2: Input: head [1,2] Output: [2,1] Exa…...
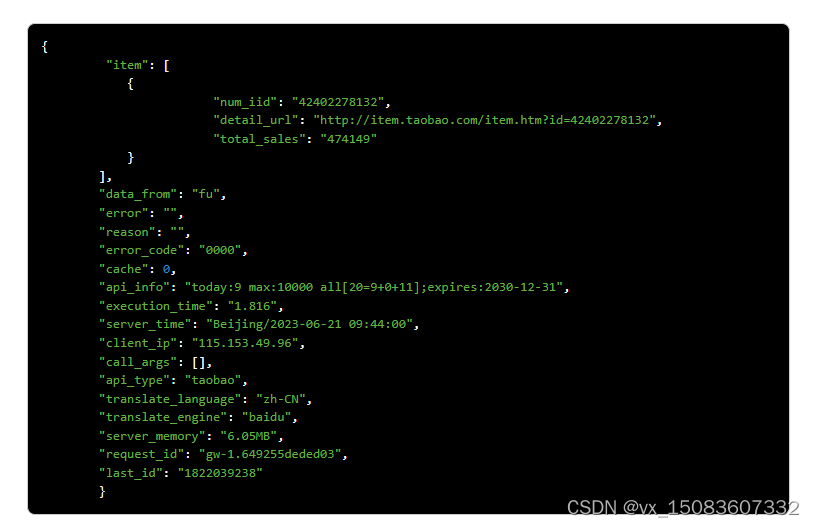
小白学爬虫:通过商品ID或商品链接封装接口获取淘宝商品销量数据接口|淘宝商品销量接口|淘宝月销量接口|淘宝总销量接口
淘宝商品销量接口是淘宝开放平台提供的一种API接口,通过该接口,商家可以获取到淘宝平台上的商品销量数据。使用淘宝商品销量接口的步骤如下: 1、在淘宝开放平台注册并创建应用,获取API Key和Secret Key等必要的信息。 2、根据淘宝…...

AI:75-基于生成对抗网络的虚拟现实场景增强
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
【MySQL数据库】| 索引以及背后的数据结构
🎗️ 主页:小夜时雨 🎗️ 专栏:MySQL数据库 🎗️ 如何优雅的活着,是我找寻的方向 目录 1. 基本知识2. 索引背后的数据结构总结 1. 基本知识 概念 索引是一种特殊的文件,包含着对数据表里所有…...
家用电脑做服务器,本地服务器搭建,公网IP申请,路由器改桥接模式,拨号上网
先浇一盆冷水! 我不知道其他运营商是什么情况。联通的运营商公网IP端口 80、8080、443 都会被屏蔽掉,想要开放必须企业备案(个人不行)才可以。也就是说,只能通过其他端口进行showtime了。 需要哪些东西? 申…...

原神游戏干货分享:探索璃月的宝箱秘密,提高游戏资源获取效率!
《原神》是一款备受玩家喜爱的开放世界冒险游戏,而在游戏中获取资源是提升角色实力的重要途径。在这篇实用干货分享中,我们将介绍一些探索璃月地区的宝箱秘密,帮助你提高游戏资源获取的效率。 首先,璃月地区的宝箱分为普通宝箱和精…...
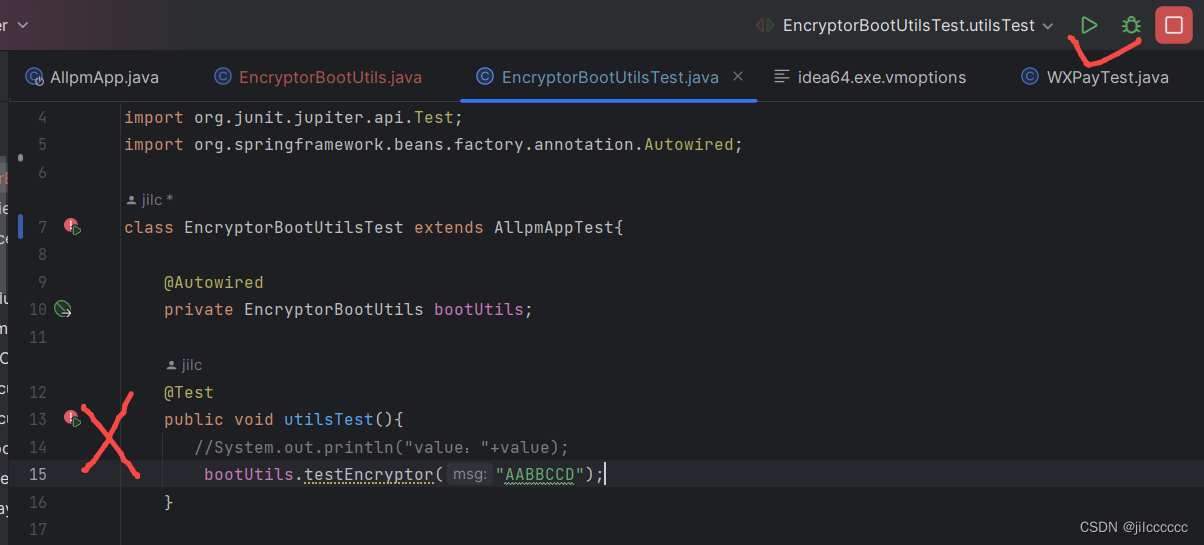
idea 2023 设置启动参数、单元测试启动参数
找到上方的editconfigration, 如下图,如果想在启动类上加,就选择springboot,如果想在单元测试加,就选择junit 在参数栏设置参数,多个参数以空格隔开 如果没有这一栏,就选择就可以了。 然后&…...
)
RSA加密算法(后端)
public class RSA {private static final String RSA_ALGORITHM "RSA";/*** 生成RSA密钥对** return RSA密钥对*/public static KeyPair generateKeyPair() throws NoSuchAlgorithmException {KeyPairGenerator keyPairGenerator KeyPairGenerator.getInstance(RSA…...
挑战100天 AI In LeetCode Day08(热题+面试经典150题)
挑战100天 AI In LeetCode Day08(热题面试经典150题) 一、LeetCode介绍二、LeetCode 热题 HOT 100-102.1 题目2.2 题解 三、面试经典 150 题-103.1 题目3.2 题解 一、LeetCode介绍 LeetCode是一个在线编程网站,提供各种算法和数据结构的题目&…...
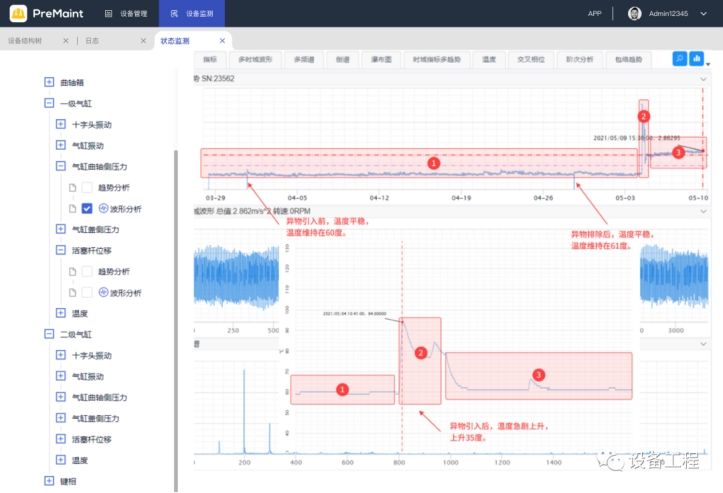
地铁机电设备健康管理现状及改善方法
轨道交通和我们的生活息息相关,从火车到地铁再到轻轨,给人们的出行带来了很大的便利。因此,保障轨道交通的的正常运行和安全至关重要,需要运维人员及时排查设备的问题,解决故障,保证轨道交通的安全运行。本…...

安卓NDK开发
1、jni:java native interface 作用:用于java代码和C、c代码的交互(代码混编); 分类使用:Jni静态注册、jni动态注册 2、静态注册 1).绑定java方法和C/C方法的方式之一; …...
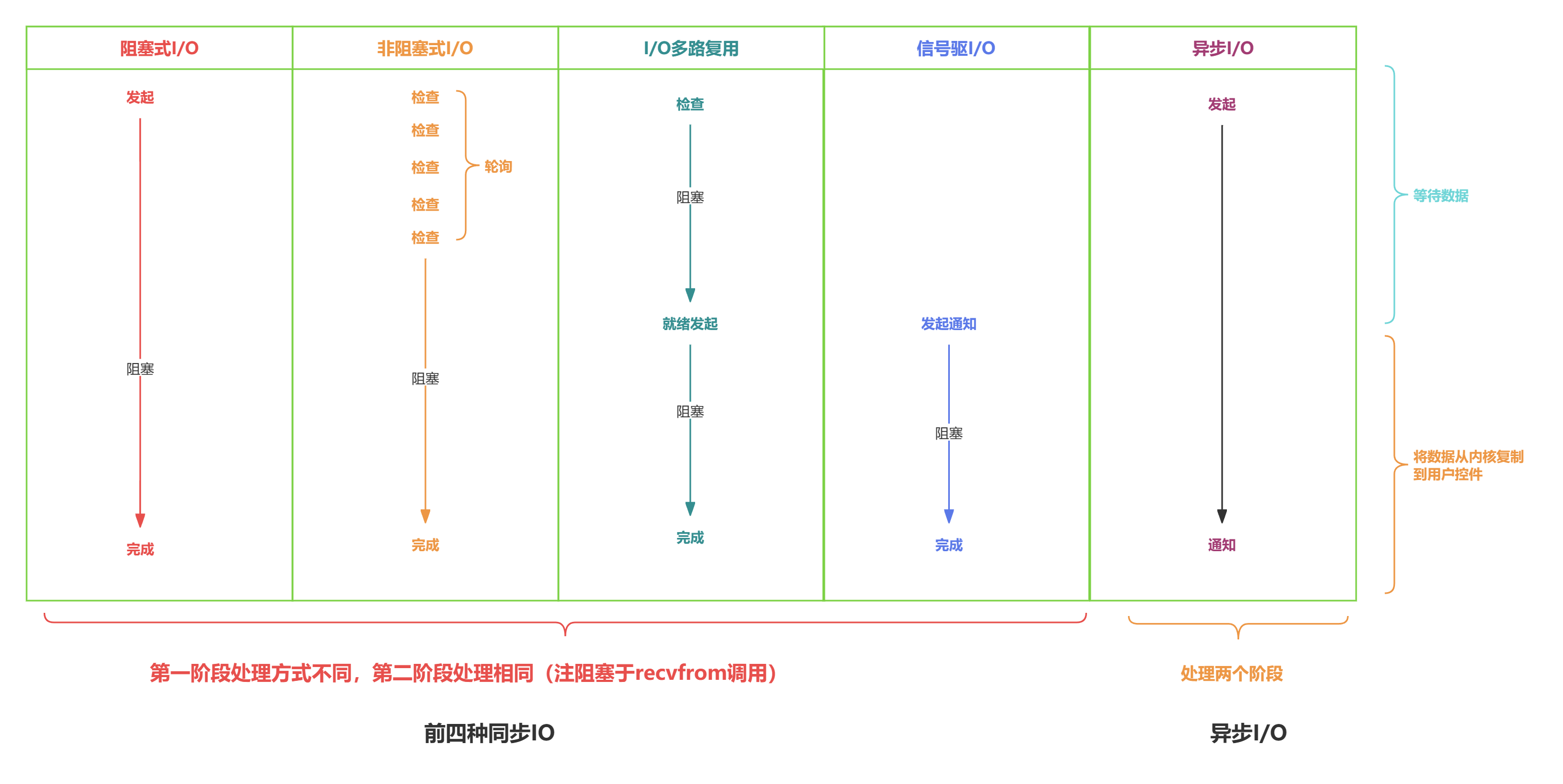
高性能网络编程 - 解读5种I/O模型
文章目录 服务端处理网络请求流程图基础概念阻塞调用 vs 非阻塞调用同步处理 vs 异步处理阻塞、非阻塞 和 同步、异步的区别recvfrom 函数 五种I/O模型I/O模型1:阻塞式 I/O 模型(blocking I/O)I/O模型2:非阻塞式 I/O 模型(non-blocking I/O&a…...
里控制垂直同步的那几行代码)
从‘画面撕裂’到‘自适应同步’:聊聊游戏图形API(OpenGL/DirectX)里控制垂直同步的那几行代码
从‘画面撕裂’到‘自适应同步’:游戏图形API中的垂直同步实战解析 第一次在屏幕上看到自己编写的3D场景动起来时,那种兴奋感至今难忘。但当镜头快速旋转,画面突然出现一道明显的水平裂痕——就像有人用刀划开了显示屏——我才意识到图形编程…...
工具:从基础随机到可控艺术化分布)
【进阶指南】3dMax散布(Scatter)工具:从基础随机到可控艺术化分布
1. 理解Scatter工具的核心逻辑 3dMax的Scatter工具本质上是一个空间分布控制器,它解决的不仅是"如何放"的问题,更是"如何放得好看"的问题。很多人在使用这个工具时容易陷入两个极端:要么完全依赖默认的随机分布ÿ…...

C语言学习笔记 - 15.C编程预备计算机专业知识 - CPU 内存条 硬盘 显卡 主板 显示器 之间的关系
一、计算机核心硬件组成计算机程序运行的核心硬件包含以下组件,所有组件通过主板完成物理连接与数据通信:CPU(中央处理器):计算机的运算与控制核心。内存条(内存):程序运行时的临时数…...

PS 抠完图怎么加外描边?超简单 3 种方法,零基础秒学会
做设计、电商配图、海报制作时,抠图只是基础步骤。给抠好的人物、产品、素材添加描边,既能强化主体轮廓、区分画面层次,还能提升整体视觉质感。但很多 PS 新手抠完图后,不知道怎么快速加描边,容易出现边缘锯齿、描边遮…...

MarkDown时序图进阶:巧用并行、条件与循环构建复杂交互逻辑
1. Markdown时序图的核心价值与应用场景 第一次接触Markdown时序图时,我被它的简洁性惊艳到了。相比传统UML工具繁琐的拖拽操作,用几行文本就能描述复杂的系统交互,这简直就是程序员的福音。在实际项目中,我经常用它来梳理微服务间…...

代谢组学找差异物别再只画火山图了!试试用R语言做OPLS-DA,VIP筛选更精准
代谢组学差异分析进阶:用OPLS-DA和VIP值突破火山图局限 在代谢组学研究中,找到真正有生物学意义的差异代谢物就像大海捞针。传统火山图虽然直观,但往往漏掉关键信号或混杂过多噪声。最近处理一批尿液代谢组数据时,我反复对比发现…...

专业级DOCX转LaTeX终极指南:docx2tex的完整高效解决方案
专业级DOCX转LaTeX终极指南:docx2tex的完整高效解决方案 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 在学术写作和技术文档创作中,Microsoft Word和LaTeX代表了两种…...
)
老项目复活记:解决那些年我们遇到的Gradle SSL连接重置问题(附多种环境配置)
老项目复活指南:全方位攻克Gradle SSL连接重置难题 接手一个尘封多年的Android或Flutter项目时,最令人头疼的莫过于构建过程中突然跳出的SSL连接错误。那些红色报错信息仿佛在嘲笑我们与时代脱节的开发环境。本文将带您深入剖析这一经典问题的根源&#…...

UE5行为树避坑指南:从‘选择器’与‘序列’的逻辑陷阱,到‘简单并行’节点的正确用法
UE5行为树避坑指南:从‘选择器’与‘序列’的逻辑陷阱,到‘简单并行’节点的正确用法 当你在UE5中构建一个看似完美的AI行为树,却发现NPC总在关键时刻做出匪夷所思的决策——这可能不是代码的错,而是行为树节点的逻辑陷阱在作祟。…...

当U-Net遇上注意力机制:拆解DNANet如何让‘暗淡’的红外小目标无处遁形
DNANet:当密集连接遇见注意力机制,如何点亮红外图像中的隐匿目标 红外小目标检测一直是计算机视觉领域的特殊挑战——那些在热成像中仅占几个像素的微弱信号,往往隐藏在复杂的背景噪声中。传统方法就像在暴风雪中寻找萤火虫,而DNA…...