6 Hive引擎集成Apache Paimon
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
在实际工作中,我们通查会使用Flink计算引擎去读写Paimon,但是在批处理场景中,更多的是使用Hive去读写Paimon,这样操作起来更加方便。
前面我们在Flink代码里面,借助于Hive Catalog,实现了在Flink中创建Paimon表,写入数据,并且把paimon的元数据信息保存在Hive Metastore里面,这样创建的表是可以被Hive识别并且操作的。
但是最直接的肯定是在Hive中直接创建Paimon类型的表,并且读写数据。
Paimon目前可以支持Hive 3.1, 2.3, 2.2, 2.1 and 2.1-cdh-6.3这些版本的操作。
但是需要注意,如果Hive的执行引擎使用的是Tez,那么只能读取Paimon,无法向Paimon中写入数据。如果Hive的执行引擎使用的是MR,那么读写都是支持的。
在Hive中配置Paimon依赖
想要在Hive中操作Paimon,首先需要在Hive中配置Paimon的依赖,此时我们需要用到一个jar包:paimon-hive-connector。
我们目前使用的Hive是3.1.2版本的,所以需要下载对应版本的paimon-hive-connector jar包。
https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-hive-connector-3.1/0.5.0-incubating/paimon-hive-connector-3.1-0.5.0-incubating.jar
将这个jar包上传到bigdata04机器(hive客户端机器)的hive安装目录中:
[root@bigdata04 ~]# cd /data/soft/apache-hive-3.1.2-bin/
[root@bigdata04 apache-hive-3.1.2-bin]# mkdir auxlib
[root@bigdata04 apache-hive-3.1.2-bin]# cd auxlib/
[root@bigdata04 auxlib]# ll
total 34128
-rw-r--r--. 1 root root 34945743 Sep 13 2023 paimon-hive-connector-3.1-0.5.0-incubating.jar
注意:需要在hive安装目录中创建auxlib目录,然后把jar包上传到这个目录中,这样会被自动加载。
如果我们在操作Hive的时候使用的是beeline客户端,那么在Hive中配置好Paimon的环境之后,需要重启HiveServer2服务。
在Hive中读写Paimon表
咱们之前在Flink引擎代码中使用Hive Catalog的时候创建了一个表:p_h_t1,这个表的元数据在Hive Metastore也有存储,之前我们其实也能查看到,只是在hive中查询这个表中数据的时候报错了,其实就是因为缺少paimon-hive-connector这个jar包,现在我们再查询就可以了。
在这里我们使用Hive的beeline客户端。
注意:需要先启动HiveServer2服务。
[root@bigdata04 ~]# cd /data/soft/apache-hive-3.1.2-bin/
[root@bigdata04 apache-hive-3.1.2-bin]# bin/hiveserver2
查看hive中目前都有哪些表:
[root@bigdata04 apache-hive-3.1.2-bin]# bin/beeline -u jdbc:hive2://localhost:10000 -n root
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://localhost:10000> SHOW TABLES;
+--------------------+
| tab_name |
+--------------------+
| flink_stu |
| orders |
| p_h_t1 |
| p_h_par |
| s1 |
| student_favors |
| student_favors_2 |
| student_score |
| student_score_bak |
| t1 |
+--------------------+
9 rows selected (1.663 seconds)
此时可以看到之前通过Hive Catalog写入的表:p_h_t1。
查询这个表中的数据:
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t1;
+--------------+-------------+
| p_h_t1.name | p_h_t1.age |
+--------------+-------------+
| jack | 18 |
| tom | 20 |
+--------------+-------------+
2 rows selected (5.853 seconds)
此时就可以正常查询了。
接着我们尝试在Hive中向这个Paimon表中插入一条数据:
0: jdbc:hive2://localhost:10000> INSERT INTO p_h_t1(name,age) VALUES('jessic',19);
重新查询这个表中的最新数据:
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t1;
+--------------+-------------+
| p_h_t1.name | p_h_t1.age |
+--------------+-------------+
| jack | 18 |
| jessic | 19 |
| tom | 20 |
+--------------+-------------+
3 rows selected (0.737 seconds)
在通过Hive进行查询的时候,默认查询的是表中最新快照的数据,我们也可以通过时间旅行这个特性来控制查询之前的数据。
举个例子,查询指定快照版本中的数据:
0: jdbc:hive2://localhost:10000> SET paimon.scan.snapshot-id=1;
No rows affected (0.011 seconds)
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t1;
+--------------+-------------+
| p_h_t1.name | p_h_t1.age |
+--------------+-------------+
| jack | 18 |
| tom | 20 |
+--------------+-------------+
2 rows selected (0.752 seconds)
0: jdbc:hive2://localhost:10000> SET paimon.scan.snapshot-id=2;
No rows affected (0.009 seconds)
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t1;
+--------------+-------------+
| p_h_t1.name | p_h_t1.age |
+--------------+-------------+
| jack | 18 |
| jessic | 19 |
| tom | 20 |
+--------------+-------------+
3 rows selected (0.692 seconds)
这样就可以实现查询历史数据的查询了。
在Hive中创建Paimon表
前面我们操作的p_h_t1这个表其实是借助于Flink引擎创建的。
下面我们来看一下在Hive中如何创建Piamon表:
0: jdbc:hive2://localhost:10000> SET hive.metastore.warehouse.dir=hdfs://bigdata01:9000/paimon;
0: jdbc:hive2://localhost:10000> CREATE TABLE IF NOT EXISTS p_h_t2(name STRING,age INT,PRIMARY KEY (name) NOT ENFORCED
)STORED BY 'org.apache.paimon.hive.PaimonStorageHandler';
这样表就创建好了,下面我们可以在Hive中测试一下读写数据:
0: jdbc:hive2://localhost:10000> INSERT INTO p_h_t2(name,age) VALUES('tom',20);
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t2;
Error: java.io.IOException: java.lang.RuntimeException: Fails to read snapshot from path hdfs://bigdata01:9000/paimon/default.db/p_h_t2/snapshot/snapshot-2 (state=,code=0)
注意:此时查询报错是因为找不到snapshot-2这份快照数据,目前这个表中只添加了一次数据,所以只有snapshot-1。
那为什么会查找
snapshot-2呢?
因为我们前面在这个会话中设置了SET paimon.scan.snapshot-id=2;,这个配置在当前会话有效。
正常情况下我们在hive中执行SET paimon.scan.snapshot-id=null;其实就可以了:
0: jdbc:hive2://localhost:10000> SET paimon.scan.snapshot-id=null;
No rows affected (0.008 seconds)
0: jdbc:hive2://localhost:10000> SET paimon.scan.snapshot-id;
+-------------------------------+
| set |
+-------------------------------+
| paimon.scan.snapshot-id=null |
+-------------------------------+
1 row selected (0.009 seconds)
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t2;
Error: java.io.IOException: java.lang.RuntimeException: Fails to read snapshot from path hdfs://bigdata01:9000/paimon/default.db/p_h_t2/snapshot/snapshot-2 (state=,code=0)
但是发现他还是会找snapshot-2。
我们尝试重新开启一个新的会话查询也不行,就算重启hiveserver2也还是不行。
后来发现这可能是一个bug,当我们在hive会话中设置了paimon.scan.snapshot-id=2,那么之后创建的表默认就只会查询snapshot-2了,那也就意味着建表的时候会把这个参数带过去。
为了验证这个猜想,我们在flink代码中查询这个Paimon表的详细建表语句,不要在hive命令行中查看(在Hive命令行中看不到详细的参数信息)。
创建package:tech.xuwei.paimon.hivepaimon
创建object:FlinkSQLReadFromPaimo
完整代码如下:
package tech.xuwei.paimon.cdcingestionimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 使用FlinkSQL从Paimon表中读取数据* Created by xuwei*/
object FlinkSQLReadFromPaimon {def main(args: Array[String]): Unit = {//创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH(| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//读取Paimon表中的数据,并且打印输出结果tEnv.executeSql("""|SHOW CREATE TABLE p_h_t2;|""".stripMargin).print()}
}
在idea中执行代码,查看结果:
CREATE TABLE `paimon_catalog`.`default`.`p_h_t2` (`name` VARCHAR(2147483647),`age` INT
) WITH ('path' = 'hdfs://bigdata01:9000/paimon/default.db/p_h_t2','totalSize' = '0','numRows' = '0','rawDataSize' = '0','scan.snapshot-id' = '2','COLUMN_STATS_ACCURATE' = '{"BASIC_STATS":"true","COLUMN_STATS":{"age":"true","name":"true"}}','numFiles' = '0','bucketing_version' = '2','storage_handler' = 'org.apache.paimon.hive.PaimonStorageHandler'
)
在这里发现建表语句中有一个参数:'scan.snapshot-id' = '2',所以它默认会读取第2个快照。
想要解决这个问题,有两个办法。
- 1:在hive中删除这个表,然后执行
SET paimon.scan.snapshot-id=null;,再创建这个表就行了。 - 2:如果不想删除这个表,可以在Flink代码中修改这个表,移除
scan.snapshot-id属性即可,这个功能我们之前讲过。
第一种办法简单粗暴,不再演示,我们来看一下第二种办法:
创建object:FlinkSQLAlterPaimonTable
完整代码如下:
package tech.xuwei.paimon.hivepaimonimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 修改Paimon表属性* Created by xuwei*/
object FlinkSQLAlterPaimonTable {def main(args: Array[String]): Unit = {//创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH(| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//移除表中的scan.snapshot-id属性tEnv.executeSql("""|ALTER TABLE p_h_t2 RESET ('scan.snapshot-id')|""".stripMargin)//查看最新的表属性信息tEnv.executeSql("""|SHOW CREATE TABLE p_h_t2|""".stripMargin).print()}
}
执行此代码,可以看到如下结果:
CREATE TABLE `paimon_catalog`.`default`.`p_h_t2` (`name` VARCHAR(2147483647),`age` INT
) WITH ('path' = 'hdfs://bigdata01:9000/paimon/default.db/p_h_t2','totalSize' = '0','numRows' = '0','rawDataSize' = '0','COLUMN_STATS_ACCURATE' = '{"BASIC_STATS":"true","COLUMN_STATS":{"age":"true","name":"true"}}','numFiles' = '0','bucketing_version' = '2','storage_handler' = 'org.apache.paimon.hive.PaimonStorageHandler'
)
此时表中就没有scan.snapshot-id属性了。
这个时候我们再回到hive命令行中查询这个表:
0: jdbc:hive2://localhost:10000> SELECT * FROM p_h_t2;
+--------------+-------------+
| p_h_t2.name | p_h_t2.age |
+--------------+-------------+
| tom | 20 |
+--------------+-------------+
1 row selected (0.46 seconds)
这样就可以正常查询了。
注意:如果此时我们在hive中删除这个表,那么对应的paimon中这个表也会被删除。
0: jdbc:hive2://localhost:10000> drop table p_h_t2;
No rows affected (0.33 seconds)
到hdfs中确认一下这个paimon表是否存在:
[root@bigdata04 ~]# hdfs dfs -ls /paimon/default.db/p_h_t2
ls: `/paimon/default.db/p_h_t2': No such file or directory
这样就说明paimon中这个表不存在了。
不过在hdfs中会多一个这个目录,这属于一个临时目录,没什么影响,可以手工删除,不处理也没影响。
[root@bigdata04 ~]# hdfs dfs -ls /paimon/default.db/_tmp.p_h_t2
针对Paimon中已经存在的表,我们想要在hive中进行访问,应该如何实现呢?
此时可以借助于Hive的外部表特性来实现。
相当于是在hive中创建一个外部表,通过location指向paimon表的hdfs路径即可。
我们使用前面cdc数据采集中创建的Paimon表:cdc_chinese_code,在hive中创建一个外部表映射到这个表:
0: jdbc:hive2://localhost:10000> CREATE EXTERNAL TABLE p_h_external
STORED BY 'org.apache.paimon.hive.PaimonStorageHandler'
LOCATION 'hdfs://bigdata01:9000/paimon/default.db/cdc_chinese_code';
然后就可以在hive中查询这个表了:
0: jdbc:hive2://localhost:10000> select * from p_h_external;
+------------------+--------------------+
| p_h_external.id | p_h_external.name |
+------------------+--------------------+
| 1 | 张三 |
| 2 | 李四 |
+------------------+--------------------+
此时如果我们在hive中删除这个外部表,不会影响paimon中的cdc_chinese_code表。
0: jdbc:hive2://localhost:10000> drop table p_h_external;
到hdfs中确认一下,cdc_chinese_code这个paimon表还是存在的:
[root@bigdata04 ~]# hdfs dfs -ls /paimon/default.db/cdc_chinese_code
Found 4 items
drwxr-xr-x - root supergroup 0 2029-02-27 11:32 /paimon/default.db/cdc_chinese_code/bucket-0
drwxr-xr-x - root supergroup 0 2029-02-27 11:32 /paimon/default.db/cdc_chinese_code/manifest
drwxr-xr-x - root supergroup 0 2029-02-27 11:26 /paimon/default.db/cdc_chinese_code/schema
drwxr-xr-x - root supergroup 0 2029-02-27 11:32 /paimon/default.db/cdc_chinese_code/snapshot
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
相关文章:

6 Hive引擎集成Apache Paimon
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html 在实际工作中,我们通查会使用Flink计算引擎去读写Paimon,但是在批处理场景中,更多的是使用Hive去读写Paimon,这样操作起来更加方便。 前面我们…...

发布版本自动化记录版本功能方法
# 安装commitizennpm install --save-dev commitizen# 初始化Conventional Commits规范适配器npx commitizen init cz-conventional-changelog --save-dev --save-exact最后一步,需要在package.json中添加一个script"scripts": {..., // 此处省略其它配置…...
Elastic Stack 8.11:引入一种新的强大查询语言 ES|QL
作者:Tyler Perkins, Ninoslav Miskovic, Gilad Gal, Teresa Soler, Shani Sagiv, Jason Burns Elastic Stack 8.11 引入了数据流生命周期、一种配置数据流保留和降采样(downsampling) 的简单方法(技术预览版)…...

wx:for-item wx:for-index wx:for-key
wx:for-item wx:for-item , 数组当前项的变量名,默认为 item 作用:使用 (当前项变量名.属性名) 取得属性值每一项 <view wx:for"{{array}}"><view>{{item.name item.age }}</view> </view>等同于 &…...

老师还不会评课?这里有你需要的解决方案
优点: 1.课件制作: 老师的PPT设计得很新颖,插入的音乐视频都非常贴合课堂内容,看得出老师非常用心地进行了设计。 2.教师素养:老师的语言丰富、朗读能力很出色、板书设计很工整。 3.教师风格: xx老师上课激情澎湃/非常有亲和力…...

Talk | 马里兰大学博士生吴曦旸:分布式多智能体强化学习在复杂交通轨迹规划中的应用
本期为TechBeat人工智能社区第545期线上Talk! 北京时间11月09日(周四)20:00,马里兰大学博士生—吴曦旸的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “分布式多智能体强化学习在复杂交通轨迹规划中的应用”,介…...
2023年下半年架构案例真题及答案
案例的考点: 大数据架构 Lambda架构和Kappa架构 jwt特点 数据持久层,Redis数据丢失,数据库读写分离方案 Hibernat架构 SysML七个关系,填需求图 大数据的必选题: 某网作为某电视台在互联网上的大型门户入口&#…...
Java必考面试题,谈谈你对 Spring AOP 的理解
大家好,我是伍六七。 今天我们来学习 Spring 框架中最重要的概念之一:AOP。 这是一个 Java 程序员必考的面试题,大家好好理解。我们开始正文。 AOP 的概念 Spring AOP 是 Java 程序员们面试经常被问到的一个问题,但 AOP&#…...

BERT和ChatGPT简单对比
OpenAI发布了第一个版本的GPT(Generative Pretrained Transformer)模型在2018年6月。 谷歌的BERT模型(Bidirectional Encoder Representations from Transformers)是在2018年10月发布的。 BERT和ChatGPT都是由人工智能研究实验室…...

又一重要合作,创邻科技华为云联营产品正式发布
近日,创邻科技旗下的“Galaxybase高性能图平台”正式入驻华为云云商店联营商品,创邻科技成为华为云在数据库与缓存领域的联营联运合作伙伴。通过联营联运模式,双方合作能够深入产品、生态、解决方案等多个领域,助力各行业用户数字…...

PHP+Swoole应用示例
**Swoole是一个C编写的基于异步事件驱动和协程的并行网络通信引擎,为PHP提供高性能网络编程支持** ## ⚙️ 快速启动 可以直接使用 [Docker](https://github.com/swoole/docker-swoole) 来执行Swoole的代码,例如: bash docker run --rm php…...

3线硬件SPI+DMA驱动 HX8347 TFT屏
3线硬件SPIDMA驱动 HX8347 TFT屏,实现用DMA清屏。 参考:基于stm32 标准库spi驱动st7789彩屏TFT(使用DMA)-技术天地-深圳市修德电子有限公司 一、源码 HX8347.h #ifndef USER_HX8347_H_ #define USER_HX8347_H_#define SPI_hardware #define SPI_hardw…...

实验语音学的基本概念
语音学 实验语音学只是语音学的一个分支,那么语音学到底是研究什么的呢?我们先有一个大致了解。 语音学是研究语言声音体系的学科。语音学的任务是研究说明语音的性质,内部结构和单位,语音的分类和组合,语音的产生、…...

市场上ios签名公司做什么的?
iOS签名公司是提供iOS应用程序签名服务的公司。它们为开发者提供了一种简单的方式来将他们的应用程序发布到iOS设备上,同时也为用户提供了一种下载和安装这些应用程序的方法。这些公司提供的签名服务包括苹果企业签名和开发者签名,其中企业签名是为企业开…...

12. 一文快速学懂常用工具——docker 命令
本章讲解知识点 Docker 引擎Docker 常用命令Docker 生命周期详解Containerd 与 Docker 命令对比本专栏适合于软件开发刚入职的学生或人士,有一定的编程基础,帮助大家快速掌握工作中必会的工具和指令。本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。如专栏内容有错…...
API低代码开发应用场景
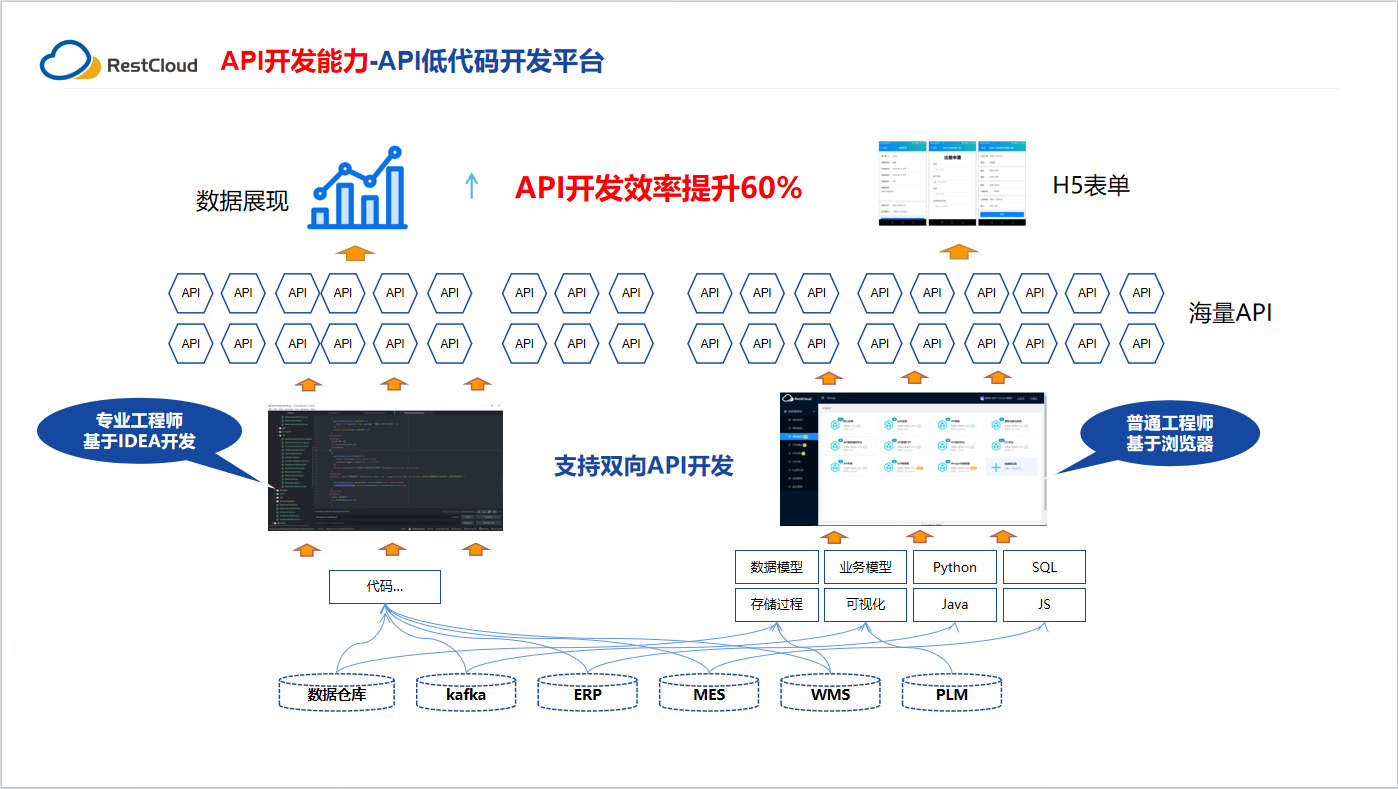
什么是API低代码开发平台 API低代码开发平台是一种基于低代码开发的技术平台,它可以帮助企业快速构建和部署API应用程序。该平台通过提供可视化的开发工具、预定义的组件和模板、自动化的代码生成等功能,使得开发者可以在不需要编写大量代码的情况下&am…...

从零开始搭建React+TypeScript+webpack开发环境-性能优化
前言 当我们开发React应用时,性能始终是一个重要的考虑因素。随着应用规模的增长,React组件的数量和复杂性也会相应增加,这可能会导致性能问题的出现。在这篇博文中,我们将探讨如何通过一系列的技巧和最佳实践来优化React应用的性…...

sCrypt 现在支持 Ordinals 了
比特币社区对 1Sat Ordinals 的接受度正在迅速增加,已有超过 4800 万个铭文被铸造,这一新创新令人兴奋不已。 尽管令人兴奋,但 Ordinals 铭文的工具仍然不发达,这使得使用 Ordinals 进行构建具有挑战性。 更具体地说,缺…...

乌班图搭建 LAMP
搭建 LAMP(Linux、Apache、MySQL、PHP)堆栈是在 Ubuntu 上构建 Web 服务器的常见任务。以下是一些步骤,指导如何在 Ubuntu 上搭建 LAMP 环境: 步骤: 更新系统软件包: 在终端中执行以下命令,确…...

【Unity细节】Unity中的Transform.SetParent还有你不知道的细节
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...

Docker 27集群节点宕机后自动愈合全过程:从故障检测、服务漂移到状态同步的7步闭环策略
第一章:Docker 27集群自动愈合机制概览 Docker 27(代号“Harmony”)引入了原生集群级自动愈合(Self-Healing)能力,不再依赖外部编排器即可在节点故障、容器崩溃或网络分区场景下实现服务状态的自主恢复。该…...
)
Ubuntu上Snap进程CPU飙升100%?别慌,三步排查清理搞定(附df -h详解)
Ubuntu上Snap进程CPU飙升100%?三步诊断与深度清理指南 上周三凌晨两点,我的Ubuntu工作站突然像被灌了铅——编译任务卡在fatal error: cant write PCH file: 设备上没有空间,VSCode的响应延迟飙到令人发指的程度。作为常年与Linux打交道的开发…...

如何快速构建WebRTC实时通信平台:Lynckia Licode完整指南
如何快速构建WebRTC实时通信平台:Lynckia Licode完整指南 【免费下载链接】licode Open Source Communication Provider based on WebRTC and Cloud technologies 项目地址: https://gitcode.com/gh_mirrors/li/licode Licode是一个基于WebRTC和云技术的开源…...

邮件骚扰取证分析:digital-forensics-lab Email_Harassment 案例研究
邮件骚扰取证分析:digital-forensics-lab Email_Harassment 案例研究 【免费下载链接】digital-forensics-lab Free hands-on digital forensics labs for students and faculty 项目地址: https://gitcode.com/gh_mirrors/dig/digital-forensics-lab digita…...

华为VRP网络运维:从零到精通的命令实战指南
1. 华为VRP平台入门:认识你的网络操作系统 第一次接触华为VRP(Versatile Routing Platform)时,我完全被满屏的命令行吓到了。但后来发现,这就像学开车要先熟悉方向盘和档位一样,掌握几个基础命令就能让设备…...
)
安卓位置模拟进阶:除了KEEP打卡,Fakelocation还能这样玩(附专业版功能解析)
安卓位置模拟技术深度应用指南:从开发调试到创新场景实践 在移动应用开发与测试领域,位置模拟技术早已超越了简单的"打卡签到"工具定位,成为开发者工具箱中不可或缺的利器。Fakelocation作为一款专业的位置模拟工具,其价…...

生产覆膜白卡公司推荐
在当今的商业社会中,各类卡片的使用场景愈发广泛,覆膜白卡作为其中一种重要的卡片类型,其质量和适用性备受关注。如果你正在寻找一家可靠的覆膜白卡生产公司,那么广州杰众智能科技有限公司绝对值得考虑。一、公司实力与信誉有保障…...

CCHP经济优化运行与多能源系统优化的MATLAB程序
冷热电联供系统CCHP经济优化运行多能源系统优化MATLAB程序 (1)该程序为冷热电联供系统CCHP经济优化运行,多能源系统优化,硕士学位论文源程序,配有该论文。(2)通过该程序可得到冷热电联供系统的经…...

QModMaster:如何用开源方案解决工业ModBus通信的三大技术挑战
QModMaster:如何用开源方案解决工业ModBus通信的三大技术挑战 【免费下载链接】qModbusMaster Fork of QModMaster (https://sourceforge.net/p/qmodmaster/code/ci/default/tree/) 项目地址: https://gitcode.com/gh_mirrors/qm/qModbusMaster 在工业自动化…...

Lumerical FDTD/MODE蒙特卡洛分析实战:如何评估环形谐振器制造误差对性能的影响?
Lumerical FDTD/MODE蒙特卡洛分析实战:环形谐振器工艺容差量化评估指南 光子芯片制造中的纳米级误差可能导致环形谐振器关键性能指标显著偏离设计预期。本文将深入解析如何利用Lumerical的蒙特卡洛分析方法,建立完整的工艺容差评估流程,为器件…...