FCOS难点记录
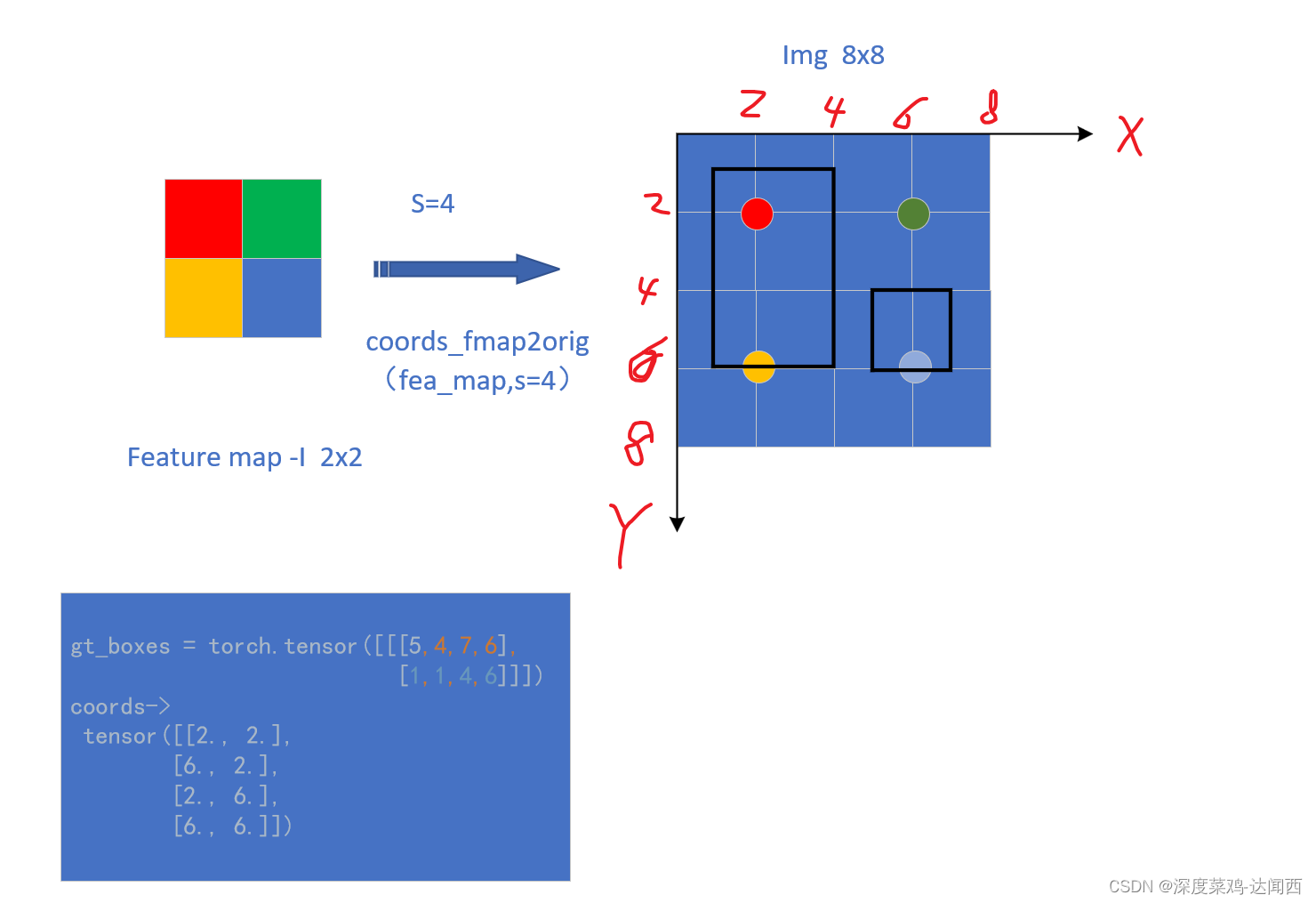
FCOS 中有计算 特征图(Feature map中的每个特征点到gt_box的左、上、右、下的距离)
1、特征点到gt_box框的 左、上、右、下距离计算
x = coords[:, 0] # h*w,2 即 第一列y = coords[:, 1] l_off = x[None, :, None] - gt_boxes[..., 0][:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m]t_off = y[None, :, None] - gt_boxes[..., 1][:, None, :]r_off = gt_boxes[..., 2][:, None, :] - x[None, :, None]b_off = gt_boxes[..., 3][:, None, :] - y[None, :, None]ltrb_off = torch.stack([l_off, t_off, r_off, b_off], dim=-1) # [batch_size,h*w,m,4]areas = (ltrb_off[..., 0] + ltrb_off[..., 2]) * (ltrb_off[..., 1] + ltrb_off[..., 3]) # [batch_size,h*w,m]off_min = torch.min(ltrb_off, dim=-1)[0] # [batch_size,h*w,m]off_max = torch.max(ltrb_off, dim=-1)[0] # [batch_size,h*w,m]
根据上边的画的图可以看出,假设对应的 feature map 大小为 2x2,stride=4,原始图片为8x8。将特征图中的每个特征点映射回去,可以得到相应的 4个(h*w个)坐标。对应图中的 红色a,绿色b,黄色c和蓝色d的点。
print(x,"\n",y,x.shape)
'''
tensor([2., 6., 2., 6.])
tensor([2., 2., 6., 6.]) torch.Size([4])
'''print(x[None,:,None]) # [1,4,1]
'''
tensor([[[2.],[6.],[2.],[6.]]])
'''print(gt_boxes) # [1,2,4] batch=1, 两个框,每个框左上角和右下角坐标
'''
tensor([[[5, 4, 7, 6],[1, 1, 4, 6]]])
'''print(gt_boxes[...,0],gt_boxes[...,0][:,None,:])
'''
tensor([[5, 1]]) tensor([[[5, 1]]])
'''
l_off = [2,2]-[5,1]=[-3,1] 以此类推print(l_off,"\n", l_off.shape)'''
**第一列代表,所有的点abcd横坐标与第一个框的左边偏移量。第二列代表到第二个框的偏移量**
tensor([[[-3., 1.],[ 1., 5.],[-3., 1.],[ 1., 5.]]]) torch.Size([1, 4, 2])'''print(ltrb_off)
'''
第一列代表,所有的投影点abcd,到两个框的左边偏移量。第一行第二行分别代表两个框。
tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]]) torch.Size([1, 4, 2, 4]) #[batch_size,h*w,m,4]
'''print(ltrb_off[...,0])
'''tensor([[[-3., 1.],[ 1., 5.],[-3., 1.],[ 1., 5.]]]) torch.Size([1, 4, 2])
'''print(areas)
'''
areas: tensor([[[ 4., 15.],[ 4., 15.],[ 4., 15.],[ 4., 15.]]])
'''torch.return_types.min(
values=tensor([[[-3., 1.],[-2., -2.],[-3., 0.],[ 0., -2.]]]),
indices=tensor([[[0, 0],[1, 2],[0, 3],[3, 2]]])) torch.return_types.max(
values=tensor([[[5., 4.],[4., 5.],[5., 5.],[2., 5.]]]),
indices=tensor([[[2, 3],[3, 0],[2, 1],[1, 0]]]))2、确定该特征点在哪一个框内,是否在该FPN特征层进行尺寸判断并进行后续预测
off_min = torch.min(ltrb_off, dim=-1)[0] # [batch_size,h*w,m] # off_min 找出所有 特征点 到 每个框的 四条边 最小的距离
off_max = torch.max(ltrb_off, dim=-1)[0] # [batch_size,h*w,m] #off_max 找出所有 特征点 到 每个框的 四条边 最大的距离mask_in_gtboxes = off_min > 0
mask_in_level = (off_max > limit_range[0]) & (off_max <= limit_range[1]) # 锁定在这个limit range上的所有的特征的点
print("ltrf_off",ltrb_off)
print("off_min",off_min,"\n","off_max",off_max)
print("mask_in_gtboxes-->",mask_in_gtboxes)
print("mask_in_level-->",mask_in_level)'''
ltrf_off tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二个框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]])off_min
tensor([[[-3., 1.], # a点到第一个框最小距离-3, a点到第二个框的最小偏移距离 1[-2., -2.], #b点到第一个框最小距离-2, b点到第二个框的最小偏移距离 -2[-3., 0.], # c点到第一个框最小距离-3, a点到第二个框的最小偏移距离 0[ 0., -2.]]]) # d点到第一个框最小距离0, a点到第二个框的最小偏移距离 -2off_max tensor([[[5., 4.],[4., 5.],[5., 5.],[2., 5.]]])mask_in_gtboxes--> # 判断了 特征点是否在框内
tensor([[[False, True], # a点到第一个框四边最小偏移距离小于0,所以,a点不属于第一个框,为false;以此类推。[False, False],[False, False],[False, False]]]) # [batch,h*w,m]mask_in_level--> # 锁定在这个limit range上的所有的特征的点
tensor([[[True, True], # 锁定了a 在这个level中[True, True], # 锁定了b[True, True], # 锁定了c[True, True]]])# 锁定了d 都在这个FPN级别上 [batch,h*w,m]
'''
3、特征点是否在框中心的范围内,用来判断是否为正样本
radiu = stride * sample_radiu_ratio # 4*1.15 = 4.6gt_center_x = (gt_boxes[..., 0] + gt_boxes[..., 2]) / 2gt_center_y = (gt_boxes[..., 1] + gt_boxes[..., 3]) / 2c_l_off = x[None, :, None] - gt_center_x[:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m]c_t_off = y[None, :, None] - gt_center_y[:, None, :]c_r_off = gt_center_x[:, None, :] - x[None, :, None]c_b_off = gt_center_y[:, None, :] - y[None, :, None]c_ltrb_off = torch.stack([c_l_off, c_t_off, c_r_off, c_b_off], dim=-1) # [batch_size,h*w,m,4]c_off_max = torch.max(c_ltrb_off, dim=-1)[0]mask_center = c_off_max < radiu
print("c_ltrb_off",c_ltrb_off)
print("c_off_max",c_off_max)
print("mask_center",mask_center)'''
c_ltrb_off
tensor([[[[-4.0000, -3.0000, 4.0000, 3.0000], # 同上边一样,a到 第一个框 小的中心框四边 的距离[-0.5000, -1.5000, 0.5000, 1.5000]], # a到 第二个框 小的中心框四边 的距离[[ 0.0000, -3.0000, 0.0000, 3.0000], # b到 第一个框 小的中心框四边 的距离[ 3.5000, -1.5000, -3.5000, 1.5000]], # # b到 第二个框 小的中心框四边 的距离[[-4.0000, 1.0000, 4.0000, -1.0000],[-0.5000, 2.5000, 0.5000, -2.5000]],[[ 0.0000, 1.0000, 0.0000, -1.0000],[ 3.5000, 2.5000, -3.5000, -2.5000]]]])c_off_max tensor([[[4.0000, 1.5000], # 找到a特征点到第一个框中心框和第二个框的中心框的 最大距离[3.0000, 3.5000],[4.0000, 2.5000],[1.0000, 3.5000]]]) # [batch,h*w,m] 4个特征点(a,b,c,d) x 框的个数2个(第一个框,第二个框)mask_center tensor([[[True, True], # 判断是否在这个框里中心点里边 正样本[True, True],[True, True],[True, True]]]) ## [batch,h*w,m]
'''3、制定mask,根据上边的 gt_box、fpn_level、mask_center
‘’’
mask_pos 是三个约束条件的交集,分别是特征点在gt中,特征点在level中,以及特征点距离Gt中的center小于指定的范围
‘’’
mask_pos = mask_in_gtboxes & mask_in_level & mask_center # [batch_size,h*w,m]areas[~mask_pos] = 99999999
areas_min_ind = torch.min(areas, dim=-1)[1] # [batch_size,h*w]
mask_pos = mask_in_gtboxes & mask_in_level & mask_center # [batch_size,h*w,m]
print("pre_areas:",areas)
areas[~mask_pos] = 99999999
areas_min_ind = torch.min(areas, dim=-1)[1] # [batch_size,h*w] # 返回索引,注意和上边的区别,上边返回值,比大小
# torch.max() or torch.min() dim=0 找列,dim=1 找行
print("mask_pos-->",mask_pos)
print("post_ares",areas)
print("areas_min_ind",areas_min_ind)'''
mask_in_gtboxes-->
tensor([[[False, True],[False, False],[False, False],[False, False]]])
mask_in_level-->
tensor([[[True, True],[True, True],[True, True],[True, True]]])
mask_center
tensor([[[True, True],[True, True],[True, True],[True, True]]])mask_pos-->
tensor([[[False, True], # 只有a点在第二个框在这个fpn这个level, 同时满足这三个条件[False, False],[False, False],[False, False]]])post_ares
tensor([[[1.0000e+08, 1.5000e+01],[1.0000e+08, 1.0000e+08],[1.0000e+08, 1.0000e+08],[1.0000e+08, 1.0000e+08]]]) # #[batch_size,h*w,m] 将 满足要求的 保持面积不面,其他设置为很大的值areas_min_ind tensor([[1, 0, 0, 0]]) # [batch_size,h*w] min[1]返回的是对应的indices 找到最小的面积,返回索引。'''4、

reg_targets = ltrb_off[torch.zeros_like(areas, dtype=torch.bool)
.scatter_(-1, areas_min_ind.unsqueeze(dim=-1), 1)] # [batch_size*h*w,4]
reg_targets = torch.reshape(reg_targets, (batch_size, -1, 4)) # [batch_size,h*w,4]
scatter_的用法:参考 https://blog.csdn.net/weixin_43496455/article/details/103870889
scatter(dim, index, src)将src中数据根据index中的索引按照dim的方向进行填充。dim=0
'''
areas:
tensor([[[ 4., 15.],[ 4., 15.],[ 4., 15.],[ 4., 15.]]]) [1,4,2]
扩展维度之后 [1,4] --> torch.Size([1, 4, 1]) ===> [[[1,0,0,0]]]
torch.zeros_like(areas, dtype=torch.bool)
tensor([[[False, False],[False, False],[False, False],[False, False]]])after scatter_-->
tensor([[[False, True],[ True, False],[ True, False],[ True, False]]]) # [1,4,2]ltrf_off
tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二个框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]])reg_targets1
tensor([[ 1., 1., 2., 4.], # a 点 第二个框[ 1., -2., 1., 4.], # b 点 第一个框[-3., 2., 5., 0.], # c 点 第一个框[ 1., 2., 1., 0.]])# d 点 第一个框# torch.Size([4, 4])reg_targets2 tensor([[[ 1., 1., 2., 4.],[ 1., -2., 1., 4.],[-3., 2., 5., 0.],[ 1., 2., 1., 0.]]]) # torch.Size([1, 4, 4])
'''
相关文章:
FCOS难点记录
FCOS 中有计算 特征图(Feature map中的每个特征点到gt_box的左、上、右、下的距离) 1、特征点到gt_box框的 左、上、右、下距离计算 x coords[:, 0] # h*w,2 即 第一列y coords[:, 1] l_off x[None, :, None] - gt_boxes[..., 0][:, No…...
java通过FTP跨服务器动态监听读取指定目录下文件数据
背景: 1、文件数据在A服务器(windows)(不定期在指定目录下生成),项目应用部署在B服务器(Linux); 2、项目应用在B服务器,监听A服务器指定目录,有新…...

5G边缘计算网关的功能及作用
5G边缘计算网关具有多种功能。 首先,它支持智能云端控制,可以通过5G/4G/WIFI等无线网络将采集的数据直接上云,实现异地远程监测控制、预警通知、报告推送和设备连接等工作。 其次,5G边缘计算网关可以采集各种数据,包…...
阿里云AIGC小说生成【必得京东卡】
任务步骤 此文真实可靠不做虚假宣传,绝对真实,可截图为证。 领取任务 链接(复制到wx打开):#小程序://ITKOL/1jw4TX4ZEhykWJd 教程实践 打开函数计算控制台 应用->创建应用->人工智能->通义千问 AI 助手-…...
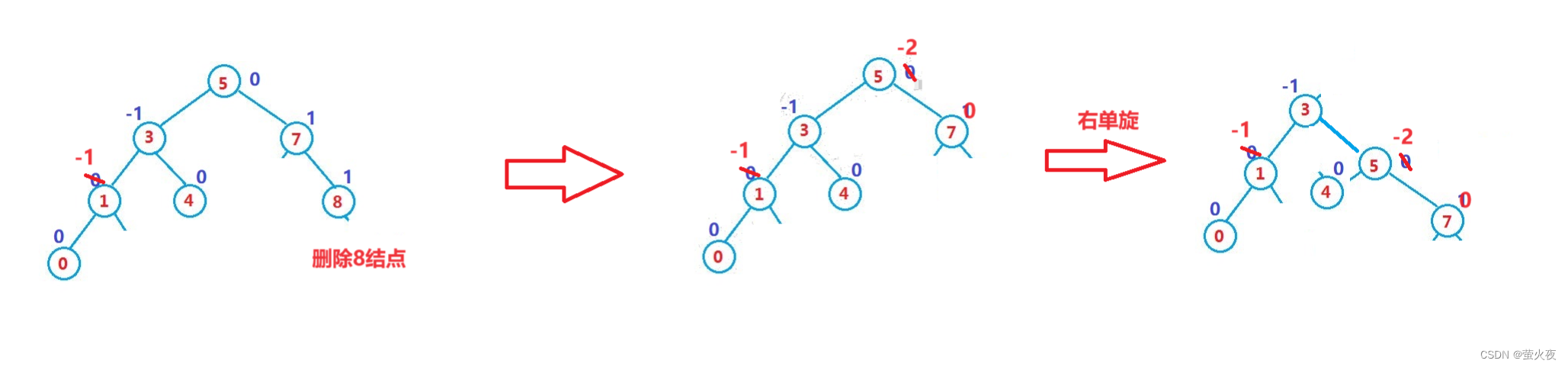
数据结构之AVL树
map/multimap/set/multiset这几个容器有个共同点是: 其底层都是按照二叉搜索树来实现的,但是普通的二叉搜索树有其自身的缺陷, 假如往树中插入的元素有序或者接近有序, 二叉搜索树就会退化成单支树, 时间复杂度会退化成O(N),因此map、set等关联式容器的底层结构是对二叉树进行了…...
如何用Java实现一个基于机器学习的情感分析系统,用于分析文本中的情感倾向
背景:练习两年半(其实是两周半),利用工作闲余时间入门一下机器学习,本文没有完整的可实施的案例,由于知识体系不全面,目前代码只能运行,不能准确的预测 卡点: 1 由于过…...

开发聚合支付的的意义
开发聚合支付的意义在于整合各种支付方式,为消费者和商家提供便捷高效的支付体验,同时满足商家的多元化支付需求,提高支付效率和用户体验。 具体来说,聚合支付具有以下意义: 方便快捷:聚合支付整合了多种…...
ChatGPT生产力|中科院学术ChatGPT优化配置
资源链接:GitHub - binary-husky/gpt_academic b站配置讲解链接:chatgpt-academic 新手运行官方精简指南(科研chatgpt拓展) 某知配置图文讲解:图文详解:在windows中部署ChatGPT学术版 - 知乎 (zhihu.com) 一…...
)
语音播报speechSynthesis最简单的例子(亲测有用)
最简单的例子,在chrome上亲测有效: const utterThis new SpeechSynthesisUtterance(我来试试呀); const synth window.speechSynthesis; synth.speak(utterThis);加入配置,可以配置语言、音量、语速、音高,继续玩: …...

呆头鹅-全自动视频混剪,批量剪辑批量剪视频,探店带货系统,精细化顺序混剪,故事影视解说,视频处理大全,精细化顺序混剪,多场景裂变,多视频混剪
视频闪闪-全自动视频混剪,探店带货系统,多视频混剪,让你成为视频处理大师! 一、全自动视频混剪 www.shipinshanshan.com 你是否曾经厌烦于冗长的视频剪辑过程?是否曾经为了一个短短的混剪视频而熬夜加班?现…...
)
牛客竞赛网(爱吃素)
题目描述 牛妹是一个爱吃素的小女孩,所以很多素数都害怕被她吃掉。 一天,两个数字aaa和bbb为了防止被吃掉,决定和彼此相乘在一起,这样被吃掉的风险就会大大降低,但仍有一定的可能被吃掉,请你判断他们相乘后…...

基于高效多分支卷积神经网络的生长点精确检测与生态友好型除草
Eco-friendly weeding through precise detection ofgrowing points via efficient multi-branch convolutional neural networks 摘要1、介绍2、相关工作2.1 杂草检测,高效除草2.2 用于密集预测任务的编解码网络2.3 语义图形是一种有效的标签方法3、总结摘要 在本研究中,我…...

11月9日,每日信息差
今天是2023年11月09日,以下是为您准备的17条信息差 第一、中国电信在进博会上与诺基亚、爱立信、英特尔、戴尔、三星达成采购合作意向。采购范围涵盖无线、数据和传输、固网终端、服务器、CPU、手机终端等设备及服务 第二、马斯克称SpaceX明年将每两天发射一次火箭…...

什么是 eCPM?它与 CPM 有何不同?
目录 eCPM 什么是 eCPM?它与 CPM 有何不同? 如何计算 eCPM? 该指标的主要优势有哪些? eCPM 底价 eCPM 达到多少比较合适? eCPM 每千人有效成本 (eCPM) 是指发行商(App 开发者)在 App 中每…...

Power Automate-创建和运行
网站:Microsoft Power Automate 根据自己需求选择创建 选择需要的触发方式,以即时云端流为例,点击触发流 点击添加新步骤 可以选择多种微软应用或者自定义应用连接 此处以向SharePoint列表追加项为例,要提前创建好SharePoint列表…...

【STM32 开发】| INA219采集电压、电流值
目录 前言1 原理图2 IIC地址说明3 寄存器地址说明4 开始工作前配置5 程序代码1)驱动程序2)头文件3) 测试代码 前言 INA219 是一款具备 I2C 或 SMBUS 兼容接口的分流器和功率监测计。该器件监测分流器电压降和总线电源电压,转换次数和滤波选项…...

蓝桥杯每日一题203.11.7
题目描述 题目分析 使用dp思维,当前位置是否可行是有上一位置推来,计算出最大的可行位置即可 #include <stdio.h> #include <string.h>#define N 256 int f(const char* s1, const char* s2) {int a[N][N];int len1 strlen(s1);int len2 …...
ESP32建立TCP连接
ESP32建立TCP连接 1.搭建ESP-IDF开发环境 搭建开发环境直接从官网下载即可。 https://docs.espressif.com/projects/esp-idf/zh_CN/v5.1.1/esp32s3/index.html https://dl.espressif.com/dl/esp-idf/?idf4.4 使用官方的下载器下载好,就可以自动安装࿰…...

普华永道成功举办《国有基金高质量发展提效创效服务》主题分享活动,助力国有基金提效创效
上海,2023年11月10日 —今天普华永道在上海中国国际进口博览会(以下简称“进博会”)现场举办《为“国”出力,“普”实有“华”—— 普华永道国有基金高质量发展提效创效服务》主题分享活动,就国有基金监督、管理、投资…...
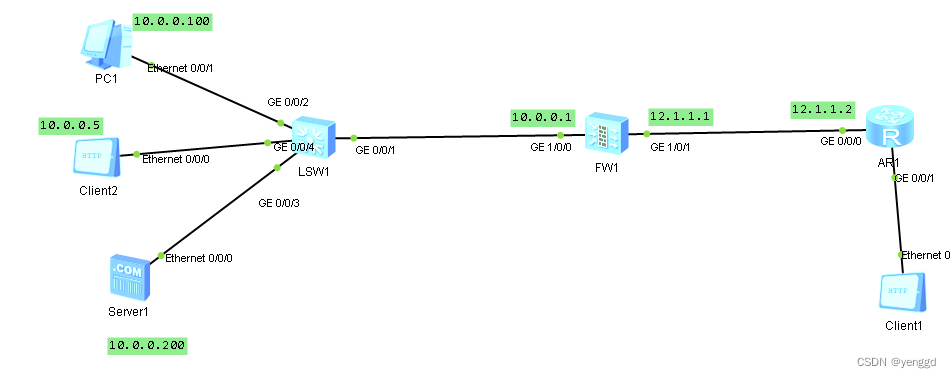
黑洞路由的几种应用场景
第一种在内网中产生环路: 这种核心交换机上肯定写一条默认路由 0.0.0.0 0 10.0.0.1 出口路由要写一条192.168.0.0 16 10.0.0.2 如果出口路由访问一条不存在的内网网段,又或者访问的那台终端停机了,那就会产生三层环路,数据包在…...

Windows 11 窗口美化终极指南:让所有应用焕发 Mica 质感
Windows 11 窗口美化终极指南:让所有应用焕发 Mica 质感 【免费下载链接】MicaForEveryone Mica For Everyone is a tool to enable backdrop effects on the title bars of Win32 apps on Windows 11. 项目地址: https://gitcode.com/gh_mirrors/mi/MicaForEvery…...

从PCB Layout到负载电容计算:手把手教你搞定25MHz以太网PHY晶振电路设计
25MHz以太网PHY晶振电路设计实战:从理论计算到PCB布局的完整指南 在工业通信和车载以太网系统中,25MHz晶振电路的稳定性直接决定了整个网络的传输质量。我曾在一个智能工厂项目中遇到过这样的案例:由于晶振负载电容计算偏差导致PHY芯片时钟漂…...

从原料到品质,生升农业如何筑牢全国品牌根基?
在农业产业链中,原料是产品品质的第一道防线,也是品牌全国化的核心底气。生升农业深耕育苗基质、营养土领域多年,之所以能覆盖全国20余个省市、服务超10万家种植户,关键在于其构建了覆盖全国的标准化原料供应链体系,从…...

终极指南:如何使用PS2EXE将PowerShell脚本一键转换为EXE可执行文件
终极指南:如何使用PS2EXE将PowerShell脚本一键转换为EXE可执行文件 【免费下载链接】PS2EXE Module to compile powershell scripts to executables 项目地址: https://gitcode.com/gh_mirrors/ps/PS2EXE 你是否曾经想过将PowerShell脚本变成独立的可执行文件…...

避开定时器分频的坑:STM32 CubeMX ADC欠采样配置中的精度损失与应对策略
STM32 CubeMX ADC欠采样实战:破解非整数分频下的定时器精度困局 当我们需要用100kHz采样率捕获1MHz信号时,传统方案往往束手无策。欠采样技术通过巧妙的时间间隔设计,让低速ADC也能采集高频信号。但当你将采样间隔设置为1.1μs时,…...
)
别再乱选了!电动两轮车BMS高边/低边、同口/分口方案实战对比(附TI BQ76952配置)
电动两轮车BMS架构深度解析:高边/低边与同口/分口方案实战指南 当你在深夜调试一块突然锁死的BMS板时,最令人崩溃的往往不是某个元件的故障,而是发现当初的架构选型埋下了致命隐患——这种痛,只有经历过量产返修的工程师才懂。在电…...
)
别再一关了之!手把手教你配置SELinux宽容模式,让服务跑起来(附CentOS 8/RHEL 8实战)
SELinux实战:从权限拒绝到精准配置的完整指南 当你在Linux服务器上部署新服务时,是否经常遇到各种"Permission denied"错误?面对SELinux的拦截,很多管理员的第一反应是直接禁用这个安全模块。但今天我要告诉你ÿ…...
)
小红书Dots.OCR实战:如何用1.7B小模型搞定多语言文档解析(附Demo体验)
小红书Dots.OCR实战:1.7B小模型的多语言文档解析全攻略 第一次接触Dots.OCR时,我正在处理一个跨国项目的多语言文档归档需求。面对几十页混杂着中文、英文和东南亚小语种的PDF文件,传统OCR工具要么识别率低得可怜,要么根本无法保持…...
)
手把手教你用STM32CubeMX配置SAI接口驱动MEMS麦克风(PDM转PCM实战)
STM32CubeMX实战:SAI接口驱动MEMS麦克风的PDM转PCM全流程解析 在嵌入式音频开发领域,MEMS数字麦克风因其体积小、抗干扰强等优势,正逐步取代传统模拟麦克风。但对于开发者而言,如何高效实现PDM到PCM的转换仍是一个技术难点。本文将…...

3分钟快速上手:PotPlayer百度翻译插件终极使用指南
3分钟快速上手:PotPlayer百度翻译插件终极使用指南 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 想要观看外语视频却苦于…...