【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]
什么是机器学习中的特征提取?
特征提取是数据分析和机器学习中的基本概念,是将原始数据转换为更适合分析或建模的格式过程中的关键步骤。特征,也称为变量或属性,是我们用来进行预测、对对象进行分类或从数据中获取见解的数据点的特定特征或属性。
本质上,特征提取涉及以增强给定任务的数据质量和相关性的方式选择、转换或创建这些特征。
它是干什么用的?
由于多种原因,它是一项不可或缺的技术:
- 降维:在许多数据集中,可能存在许多特征,这可能导致一种称为维数灾难的现象。高维数据可能具有挑战性,并可能导致机器学习模型过度拟合。特征提取技术有助于减少维数,同时保留基本信息。
- 降噪:原始数据通常包含噪声或不相关的信息,可能会影响模型的准确性。特征提取方法旨在滤除噪声并突出数据中最有意义的方面。
- 可解释性:通过特征提取简化数据可以使分析更具可解释性。它帮助我们关注最重要的变量并理解它们的关系。
- 提高模型性能:有效的特征提取可以通过为机器学习算法提供更清晰、信息更丰富的输入来增强模型性能。这在分类、回归和聚类等任务中尤其重要。
特征提取方法有多种形式,从用于降维的主成分分析 (PCA) 等统计技术,到从文本、图像或其他数据类型中提取相关信息的特定领域方法。
特征提取的简单示例
让我们从使用词袋(BoW)技术进行特征提取的简单的基于文本的示例开始。

输入文本数据:假设您有三个短文本文档的集合:
- “I like cats and dogs.”
- “Dogs are great pets.”
- “I prefer cats over dogs.”
第 1 步:Tokenization
通过将文本分解为单独的单词或标记来对文本进行标记。标记化后,您将得到一个单词列表:
- [“I”, “like”, “cats”, “and”, “dogs.”]
- [“Dogs”, “are”, “great”, “pets.”]
- [“I”, “prefer”, “cats”, “over”, “dogs.”]
第 2 步:创建词汇表
通过识别整个文档集合中的唯一单词来创建词汇表:
词汇:[“I”, “like”, “cats”, “and”, “dogs”, “are”, “great”, “pets”, “prefer”, “over”]
步骤 3:文档-术语矩阵(特征提取)
构建文档术语矩阵 (DTM) 或词袋表示,其中每行对应一个文档,每列对应词汇表中的一个单词。DTM 中的值表示各个文档中每个单词的频率:
| Document | I | like | cats | and | dogs | are | great | pets | prefer | over |
|---|---|---|---|---|---|---|---|---|---|---|
| Document 1 | 1 | 1 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| Document 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| Document 3 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
第四步:特征表示
文档术语矩阵 (DTM) 是您的特征表示。每个文档现在都表示为词频向量。
例如,文档1可以表示为特征向量[1,1,1,1,2,0,0,0,0,0]。
这些特征向量可用于各种文本分析任务,例如文本分类、情感分析或聚类。BoW 技术将文本数据转换为数字表示,使其适合机器学习算法来处理和分析基于文本的信息。
机器学习中的 9 大特征提取技术和算法
特征提取包含多种技术,可大致分为降维方法和增强特征质量和相关性的策略。在这里,我们探讨了各种数据分析和机器学习应用程序中使用的一些最常见的特征提取技术:
1. 主成分分析(PCA):
- 目的: PCA 是一种降维技术,用于将数据集转换为新的坐标系,其中称为主成分的维度是正交的,并捕获数据中的最大方差。
- 用例: 降低高维数据集的维数,同时保留尽可能多的信息。
2. 线性判别分析(LDA):
- 目的: LDA 是一种降维技术,专注于通过将数据投影到低维空间来最大化分类问题中类之间的可分离性。
- 用例: 类别区分至关重要的分类任务的特征提取。
3. t-分布随机邻域嵌入(t-SNE):
- 目的: t-SNE 主要用于通过降低数据维数同时保留数据点之间的局部关系来进行可视化和特征提取。
- 使用案例: 可视化高维数据,尤其是在聚类任务中。
4. 特征缩放和标准化:
- 目的: 缩放和标准化特征可确保不同特征具有可比较的尺度,这对于许多机器学习算法至关重要。
- 使用案例: 预处理数据以避免对特征尺度敏感的模型出现偏差,例如KNN和SVM。
5. 特征工程:
- 目的: 特征工程涉及创建新特征或转换现有特征以增强模型可用的信息。这可以包括数学运算、特定领域的知识或交互术语。
- 用例: 针对特定问题定制功能并提高模型性能。
6. 非负矩阵分解(NMF):
- 目的: NMF 将数据矩阵分解为两个低维矩阵,通常表示部分及其组合。它有助于找到可解释的特征。
- 使用案例: 文本数据、图像分割和信号处理中的主题建模。
7. 独立成分分析(ICA):
- 目的: ICA 将多变量信号分离为可加的独立分量。它通常用于分离混合信号。
- 使用案例: 信号处理和一些生物医学应用中的盲源分离。
8.小波变换:
- 目的: 小波变换将数据分解为多个尺度的不同频率分量,揭示不同分辨率下的特征。
- 使用案例: 图像和信号处理、时频分析中的特征提取。
9.自编码器:
- 目的: 自动编码器是学习将数据编码为低维表示的神经网络架构。网络的编码器部分充当特征提取机制。
- 使用案例: 通用降维和特征提取,通常用于深度学习。
这些常见的特征提取技术为数据科学家和机器学习从业者提供了一个工具箱,可以根据项目的具体要求有效地预处理数据、降低维度并提高特征质量。技术的选择应以数据的性质以及分析或建模任务的目标为指导。
深度学习特征提取
深度学习特征提取是指使用预先训练的深度神经网络从原始数据(通常是图像、文本或其他类型的高维数据)中自动提取信息特征。深度学习模型,特别是用于图像数据的卷积神经网络 (CNN) 和用于文本等序列数据的循环神经网络 (RNN),可以学习数据中复杂的模式和表示。
以下是深度学习特征提取及其应用的概述:
1.用于图像特征提取的卷积神经网络(CNN):
- 在图像方面,CNN 通过自动学习分层和空间相关特征,彻底改变了特征提取。
- VGG、ResNet 和 Inception 等深度 CNN 架构在包含数百万张图像的大型图像数据集(例如 ImageNet)上预先训练了模型。这些模型可以进行微调或用作特定图像相关任务的特征提取器。
- 这些网络的最后一层通常包含可用作通用图像表示的高级特征,并且这些特征可以输入到其他机器学习模型中。
2.用于文本特征提取的循环神经网络(RNN):
- RNN,特别是长短期记忆(LSTM)和门控循环单元(GRU)网络已广泛用于文本数据。
- 预训练的 RNN 模型(例如Word2Vec、GloVe)和基于Transformer的模型(例如 BERT)用于从文本数据中提取特征。这些模型从文本文档中捕获语义和上下文信息。
- 从这些模型中提取的特征可用于各种自然语言处理 (NLP) 任务,例如情感分析、命名实体识别或文本分类。
3. 特征提取的迁移学习:
- 迁移学习是深度学习中的一种广泛使用的技术,其中预训练的模型针对特定任务进行了微调。特征提取可能是迁移学习的重要组成部分。
- 使用预先训练的模型作为特征提取器,即使您的数据集很小或特定,您也可以利用从大型且多样化的数据集中学到的知识。
- 针对新任务微调预训练模型的最后几层,同时保持较低层固定是一种常见的方法。
深度学习在特征提取中的应用
- 图像分类:深度学习特征提取用于图像分类任务,其中提取的特征被传递到分类器以区分对象或场景。
- 对象检测:深度学习模型提取特征来检测和定位图像中的对象。
- 文本分类:对于垃圾邮件检测或情感分析等任务,从文本数据中提取深度学习特征至关重要。
- 异常检测:从原始数据中提取的深层特征可以帮助识别各个领域的异常或异常值,例如欺诈检测或质量控制。
深度学习特征提取很有价值,因为它允许数据科学家和机器学习从业者利用深度神经网络的暗示能力,即使他们从头开始训练模型的数据或资源有限。通过使用预先训练的模型,您可以节省时间和资源,同时在各种任务中实现最先进的性能。
十大 NLP 文本特征提取技术
自然语言处理 (NLP) 中的特征提取涉及将文本数据转换为可输入机器学习模型的数字表示。NLP 特征提取对于广泛的 NLP 任务至关重要,例如文本分类、情感分析、命名实体识别和机器翻译。以下是 NLP 特征提取的一些常用技术:
1. 词袋(BoW):
- BoW 将文档表示为词频或二进制值的向量。它丢弃文本的顺序和结构,但捕获特定单词的存在或不存在。
- BoW 可以扩展为包含n元语法(n 个单词的序列)来捕获一些本地上下文。
2. 词频-逆文本频率(TF-IDF):
- TF-IDF 是一种数值统计量,反映文档中单词相对于文档集合(语料库)的重要性。
- 它为文档中频繁出现但在语料库中罕见的单词分配更高的分数。
3. 词嵌入:
- 词嵌入将词表示为固定维空间中的密集、连续值向量。常用的技术有 Word2Vec、GloVe 和 FastText。
- 词嵌入捕获词之间的语义关系,并可用于通过聚合词向量(例如求平均或加权和)来导出文档的向量表示。
4. 预训练语言模型:
- 预训练语言模型,如 BERT、GPT-2 和 RoBERTa,因 NLP 特征提取而闻名。
- 这些模型提供上下文嵌入,考虑到周围的单词,并且能够捕获复杂的语义和句法信息。
5. 词性(POS)标记:
- 词性标注识别句子中每个单词的语法类别,例如名词、动词、形容词等。这些信息可以用作各种 NLP 任务中的特征。
6.命名实体识别(NER):
- NER 从文本中提取实体(例如人名、组织、位置),识别出的实体可以用作特征。
7.情感分析:
- 情感分析的功能通常包括情感词典,它提供单词列表及其相关的情感分数。
- 还可以提取与否定、强化词和情绪转变相关的特征。
8. 用词频或序列长度表示文本:
- 基本特征,例如文档中的单词数量或特定单词或短语的频率,可以用作特定 NLP 任务的特征。
9.基于语法的特征:
- 从文本句法结构派生的特征(例如解析树或语法关系)可用于涉及语法或句法分析的任务。
10. 文档嵌入:
- Doc2vec这样的技术可以通过考虑文档中单词的上下文来获取整个文档的向量表示。
NLP 中特征提取技术的选择取决于具体任务、数据集和可用资源。尝试不同的技术并执行特征工程来提高 NLP 模型的性能是很常见的。此外,随着 NLP 研究的不断发展,预训练的语言模型因其提供丰富的上下文嵌入的能力而受到欢迎,并显着提高了各种 NLP 任务的现有技术水平。
9 大自动特征提取技术
自动特征提取,通常称为自动特征工程或特征学习,是让机器学习算法或模型从原始数据中发现并生成相关特征而无需人工干预的过程。当处理高维数据或难以用手工特征捕获的复杂模式时,这种方法非常有利。自动特征提取方法包括:
1.特征学习的深度学习
深度神经网络,特别是深度自动编码器和卷积神经网络(CNN)可以自动从原始数据中学习特征。自动编码器通过将数据编码到低维空间然后将其解码回来来学习紧凑的表示。CNN 从图像中学习分层特征,这对于各种计算机视觉任务很有帮助。
2.迁移学习
迁移学习利用预训练模型(例如,BERT ResNet 等预训练深度学习模型)从新数据集或领域中提取特征。这些模型在大量数据集上学习到的特征可以针对特定任务进行微调。
3. 主成分分析(PCA)
PCA 是一种降维技术,可将数据转换为新的坐标系,其中维度(主成分)捕获最大方差。它可以被认为是一种在保留基本信息的同时降低维度的自动特征提取方法。
4.非负矩阵分解(NMF)
NMF 将数据矩阵分解为两个低维矩阵,表示部分及其组合。它提取可解释且对各种应用程序有用的特征。
5.独立成分分析(ICA)
ICA 将混合信号分离成独立的分量,可用于各种应用,包括信号处理中的盲源分离。
6.词嵌入和语言模型
在自然语言处理 (NLP) 中,词嵌入(例如 Word2Vec、GloVe)捕获单词之间的语义关系,允许模型自动学习单词的向量表示。预训练的语言模型(例如 BERT、GPT)可以学习上下文嵌入并从文本数据中提取特征。
7.进化算法
进化算法,例如遗传编程,可以进化数学表达式或特征组合来优化特定的目标函数。
8. AutoML 平台
TPOT和Auto-Sklearn等自动机器学习 (AutoML) 平台可自动执行特征选择和工程过程,使用各种技术来识别给定机器学习任务的信息最丰富的特征。
9.深度特征选择:
深度特征选择方法使用神经网络从输入数据中排序或选择最相关的特征,针对特定任务对其进行优化。
自动特征提取可以显着减少对领域专业知识和手动特征工程的需求,这使得在涉及大型、复杂数据集时特别有价值。它允许机器学习模型发现和利用数据中的复杂模式,从而提高各种任务的性能。
如何在Python示例中实现特征提取
让我们考虑使用流行的 CIFAR-10 数据集在图像数据上下文中进行特征提取的实际示例。CIFAR-10 数据集由 10 个不同类别的 60,000 张 32×32 彩色图像组成,每个类别有 6,000 张图像。在这里,我们将使用主成分分析 (PCA) 执行图像分类的特征提取:
第 1 步:数据预处理
首先,您将加载并预处理图像数据。对于 CIFAR-10,您需要读取图像并将其转换为合适的格式(例如,NumPy 数组)。您还可以对像素值进行标准化,以确保它们在同一范围内(例如,[0, 1])。
第 2 步:使用 PCA 进行特征提取
对图像数据应用主成分分析。PCA 旨在找到信息最丰富的正交方向(主成分),沿着该方向数据方差最大化。这有效地降低了数据的维度。
import numpy as np
from sklearn.decomposition import PCA# Assuming 'X' is your preprocessed image data
X = X.reshape(X.shape[0], -1) # Flatten images into 1D arrays# Specify the number of principal components you want to retain
n_components = 100 # You can choose the number based on your needs# Apply PCA
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)应用 PCA 后, X_pca 将包含转换为低维表示的图像数据,每个图像由一组减少的特征表示。这些特征是原始像素值的线性组合,捕获数据中最显着的变化。
第 3 步:模型训练和评估
您可以使用简化的特征表示 ( X_pca ) 来训练图像分类的机器学习模型。例如,您可以使用支持向量机 (SVM) 或神经网络等分类器将图像分类到各自的类别中。
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.2, random_state=42)# Train a Support Vector Machine (SVM) classifier
svm_classifier = SVC()
svm_classifier.fit(X_train, y_train)# Make predictions on the test set
y_pred = svm_classifier.predict(X_test)# Evaluate the model's accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")在此示例中,PCA 用于降低图像数据的维度,同时保留最重要的信息。然后使用通过 PCA 获得的低维特征来训练用于图像分类的机器学习模型。这只是特征提取的一个实例;相同的概念可以应用于各种数据类型和任务。
如何在 BERT 中实现特征提取
BERT(来自 Transformers 的双向编码器表示)是 Google 开发的强大的预训练语言模型,可用于广泛的自然语言处理 (NLP) 任务。BERT 捕获上下文信息和单词之间的关系,使其成为从文本中提取特征的宝贵工具。要从 BERT 中提取特征,可以按照以下步骤操作:
1、预处理:
在从 BERT 中提取特征之前,您需要准备文本数据。使用 BERT 预训练期间使用的相同分词器将文本分词为子词。大多数 BERT 模型都带有分词器。
2. 使用预训练的 BERT 模型:
选择适合您任务的预训练 BERT 模型。“bert-base-uncased”和“bert-large-uncased”等模型通常用于英语文本。
3.加载BERT模型:
您可以使用流行的 NLP 库(例如 Python 中的 Hugging Face 的 Transformers 库)来加载预训练的 BERT 模型。例如:
from transformers import BertModel, BertTokenizermodel_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)4. 代币化:
使用 BERT 分词器对文本数据进行分词。这会将您的文本转换为 BERT 可以理解的标记。
text = "Your text goes here."
tokens = tokenizer(text, padding=True, truncation=True, return_tensors="pt")5.特征提取:
通过 BERT 模型传递标记化输入以获得嵌入或特征。BertModel 将返回隐藏状态,在某些情况下,还会返回池表示。对于特征提取,您通常可以使用隐藏状态。下面是如何从 BERT 获取特征的示例:
with torch.no_grad():output = model(**tokens)hidden_states = output.last_hidden_statehidden_states 包含输入文本中每个标记的上下文嵌入。您可以通过对这些嵌入进行平均或池化或根据任务需要选择特定层或标记来提取特征。
6、后处理:
根据您的具体用例,您可能需要对功能进行后处理。例如,您可以对嵌入进行平均或池化以获得整个输入文本的单个向量表示。
7. 功能使用:
您可以将提取的特征用于各种 NLP 任务,例如文本分类、情感分析、命名实体识别等。
请记住,BERT 是一个具有多层的深度神经网络,从不同层获得的特征可能会捕获文本的其他方面。尝试使用层和技术来提取最适合您的特定 NLP 任务的特征。此外,Hugging Face Transformers 库为 BERT 和其他预训练模型提供了方便的接口,使特征提取更加容易。
如何在 CNN 中实现特征提取
卷积神经网络 (CNN) 主要设计用于图像处理任务,但它们也可用于从图像中提取特征。CNN 在学习图像中的层次和空间相关特征方面特别有效。以下是使用 CNN 执行特征提取的方法:
1、预处理:
通过调整大小、标准化和预处理来准备图像数据。您可以使用 OpenCV 或 PIL 等库来加载和操作图像。
2.加载预训练的CNN模型:
选择适合您的特征提取需求的预训练 CNN 模型。常见的选择包括 VGG、ResNet、Inception 或 MobileNet 等模型。这些模型已经在大型图像数据集上进行了训练,可以从图像中提取信息特征。
3. 加载模型并删除顶层:
使用 TensorFlow 或 PyTorch 等深度学习库加载预训练的 CNN 模型。从模型中删除完全连接的层(顶层),因为您只需要特征提取部分。
例如,如果您使用 TensorFlow 和 VGG16 模型:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.applications.vgg16 import preprocess_inputbase_model = VGG16(weights='imagenet', include_top=False)4.特征提取:
将图像数据传递给 CNN 模型,以从中间层之一提取特征。这些层在完全连接的层之前捕获分层和抽象特征。
# Assuming 'images' is a list of preprocessed image data
features = []
for image in images:image = np.expand_dims(image, axis=0)image = preprocess_input(image)feature = base_model.predict(image)features.append(feature)5、后处理:
根据您的具体任务,您可以展平、平均或池化提取的特征。您还可以对它们进行标准化,以确保它们处于一致的范围内。
6. 功能使用:
提取的特征可用于各种计算机视觉任务,例如图像分类、对象检测或图像相似性分析。
通过使用预先训练的 CNN 模型进行特征提取,您可以受益于该模型自动学习和捕获信息丰富的图像特征的能力。如果您的标记数据数量有限或想要利用从大量图像数据集中学到的知识,这尤其有用。用于特征提取的特定 CNN 架构和层的选择取决于您的任务和数据的性质。尝试不同的模型和层,找到最适合您的应用程序的功能。
挑战和考虑因素
特征提取是数据预处理和机器学习的基本步骤,但它也带来了挑战和考虑因素。了解这些挑战对于在特征提取过程中做出明智的决策至关重要。以下是一些常见的挑战和重要的考虑因素:
1.维度诅咒
高维数据可能导致计算效率低下、内存使用增加以及数据可视化和解释困难。解决这一挑战通常需要使用 PCA 等降维技术。
2. 数据质量
输入数据的质量直接影响特征提取。嘈杂或不一致的数据可能导致提取不相关或误导性的特征。数据预处理和清理对于缓解这一挑战至关重要。
3. 特征相关性
确定哪些特征与问题相关可能具有挑战性。提取太多或不相关的特征可能会导致过度拟合,而缺少相关部分可能会导致欠拟合。
4. 特征工程复杂性
创建和设计功能可能是一个耗时且迭代的过程。设计有效的功能通常需要领域知识和创造力,这使得这个过程变得更加复杂。
5. 数据分发
数据的分布会影响特征提取。某些技术可能更适合具有特定分布的数据,并且应考虑有关数据分布的假设。
6. 可解释性与复杂性
虽然复杂的特征提取技术可以产生较高的预测性能,但它们可能会降低模型的可解释性。根据用例,在模型复杂性和可解释性之间取得平衡至关重要。
7. 数据不平衡
在分类任务中,不平衡的类别分布可能会带来挑战。特征提取可能需要考虑解决数据不平衡和防止模型偏差的策略。
8. 缩放
某些特征提取技术可能无法很好地适应大型数据集。考虑处理大数据时特征提取所需的计算资源。
9. 异构数据
处理异构数据类型,例如文本、图像和结构化数据,可能需要多种特征提取技术和不同来源的集成。
10. 跨域泛化
从一个领域提取的特征可能无法很好地推广到另一个领域。将从一种环境中学到的特征应用于不同环境时要小心。
11. 模型依赖
机器学习模型的选择可能会影响特征提取的有效性。为一种模型提取的特征对于另一种模型可能没有那么丰富的信息。
12.计算资源
特征提取,尤其是深度学习模型的特征提取,计算成本可能很高。选择特征提取技术时请考虑可用的硬件和计算资源。
13. 评估功能影响
了解各个特征对模型性能的实际影响可能具有挑战性。特征重要性分析等技术可以提供帮助,但它们并不总是那么简单。
14. 实验
特征提取通常是一个涉及实验和微调的迭代过程。准备好探索多种技术并验证其有效性。
在特征提取过程中应对这些挑战并考虑这些因素对于提高特征质量并最终提高机器学习模型的性能和可解释性至关重要。特征提取是从原始数据到可操作的见解的关键一步,深思熟虑这些挑战对于其成功至关重要。
结论
总之,特征提取是数据预处理和机器学习的基本步骤,在提高模型的质量、可解释性和性能方面发挥着至关重要的作用。从原始数据中提取相关且信息丰富的特征是一项关键任务,需要仔细考虑各种技术、领域知识和具体挑战。以下是关键要点的摘要:
- 特征提取是从原始数据中选择、转换或创建相关特征,以提高机器学习模型的效率和准确性。
- 常见的特征提取技术包括降维(例如 PCA)、词嵌入(例如 Word2Vec)、预训练语言模型(例如 BERT)和图像 CNN。
- 特征提取在高维数据、具有复杂模式的数据以及利用特定领域的知识来增强特征集时尤其有价值。
- 特征提取的最佳实践包括理解问题域、数据预处理、降维和特征工程。
- 特征提取的挑战包括维数灾难、数据质量、特征相关性以及可解释性和复杂性之间的权衡。
- 考虑因素包括数据分布、不平衡、计算资源和模型依赖性。
- 特征提取是一个迭代过程,通常需要实验和验证。
在实践中,有效的特征提取可以提高模型性能、模型可解释性和更准确的预测。它是更广泛的机器学习管道的重要组成部分,用于从原始数据中获取可行的见解。通过遵循最佳实践并考虑挑战和注意事项,数据科学家和机器学习从业者可以释放数据的潜力并构建更强大和更准确的模型。
相关文章:
【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]
什么是机器学习中的特征提取? 特征提取是数据分析和机器学习中的基本概念,是将原始数据转换为更适合分析或建模的格式过程中的关键步骤。特征,也称为变量或属性,是我们用来进行预测、对对象进行分类或从数据中获取见解的数据点的…...
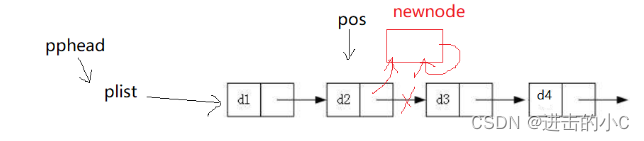
数据结构-单链表
1 链表的概念及结构 概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。 从以上图片可以看出: 1.链式结构在逻辑上是连续的,但在物理上不一定是连续的。 2.现实中的节…...
红队系列-IOT安全深入浅出
红队专题 设备安全概述物联网设备层次模型设备通信模型 渗透测试信息收集工具 实战分析漏洞切入点D-link 850L 未授权访问 2017 认证绕过认证绕过 D-link DCS-2530Ltenda 系列 路由器 前台未授权RTSP 服务未授权 访问 弱口令命令注入思科 路由器 固件二进制 漏洞 IoT漏洞-D-Lin…...

亚数受邀参加“长三角G60科创走廊量子密码应用创新联盟(中心)”启动仪式
11月8日,在第六届中国国际进口博览会2023长三角G60科创走廊高质量发展要素对接大会上,亚数信息科技(上海)有限公司CEO翟新元作为密码企业代表之一受邀参加“长三角G60科创走廊量子密码应用创新联盟(中心)”…...

直方图学习
直方图均衡化(Histogram Equalization)是一种用于增强图像对比度的图像处理技术,通过重新分配图像的像素值,使图像中的亮度级别更加均匀,以改善图像的视觉质量。下面是进行直方图均衡化的一般步骤: 计算原始…...
Java / Android 多线程和 synchroized 锁
s AsyncTask 在Android R中标注了废弃 synchronized 同步 Thread: thread.start() public synchronized void start() {/*** This method is not invoked for the main method thread or "system"* group threads created/set up by the VM. Any new functionali…...

基于51单片机的万年历-脉搏计仿真及源程序
一、系统方案 1、本设计采用51单片机作为主控器。 2、DS1302采集年月日时分秒送到液晶1602显示。 3、按键年月日时分秒,心率报警上下限。 4、红外对接管传感器采集心率送到液晶1602显示。 5、心率低于下限或高于上限,蜂鸣器报警。 二、硬件设计 原理图如…...

【ARFoundation学习笔记】点云与参考点
写在前面的话 本系列笔记旨在记录作者在学习Unity中的AR开发过程中需要记录的问题和知识点。主要目的是为了加深记忆。其中难免出现纰漏,更多详细内容请阅读原文以及官方文档。 汪老师博客 文章目录 点云新建点云 参考点参考点的工作原理何时使用参考点使用参考点…...
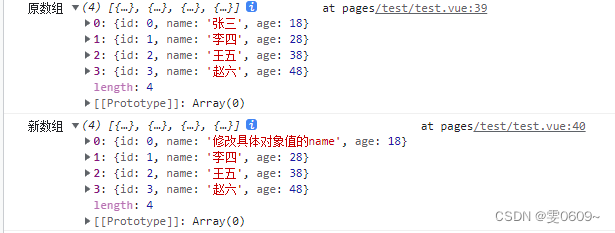
uni-app:js实现数组中的相关处理-数组复制
一、slice方法-浅拷贝 使用分析 创建一个原数组的浅拷贝,对新数组的修改不会影响到原数组slice() 方法创建了一个原数组的浅拷贝,这意味着新数组和原数组中的对象引用是相同的。因此,当你修改新数组中的对象时,原数组中相应位置的…...
所有函数的介绍及使用)
8 STM32标准库函数 之 实时时钟(RTC)所有函数的介绍及使用
8 STM32标准库函数 之 实时时钟(RTC)所有函数的介绍及使用 1. 图片有格式2 文字无格式二、RTC库函数固件库函数预览2.1 函数RTC_ITConfig2.2 函数RTC_EnterConfigMode2.3 函数RTC_ExitConfigMode2.4 函数RTC_GetCounter.2.5 函数RTC_SetCounter2.6 函数RTC_SetPrescaler2.7 函…...

ARMday04(开发版简介、LED点灯)
开发版简介 开发板为stm32MP157AAA,附加一个拓展版 硬件相关基础知识 PCB PCB( Printed Circuit Board),中文名称为印制电路板,又称印刷线路板,是重要的电子部件,是电子元器件的支撑体,是电子…...

国际腾讯云:云服务器疑似被病毒入侵问题解决方案!!!
云服务器可能由于弱密码、开源组件漏洞的问题被黑客入侵,本文介绍如何判断云服务器是否被病毒入侵,及其解决方法。 问题定位 使用 SSH 方式 或 使用 VNC 方式 登录实例后,通过以下方式进行判断云服务器是否被病毒入侵: rc.loca…...

Perl语言用多线程爬取商品信息并做可视化处理
首先,我们需要使用Perl的LWP::UserAgent模块来发送HTTP请求。然后,我们可以使用HTML::TreeBuilder模块来解析HTML文档。在这个例子中,我们将使用BeautifulSoup模块来解析HTML文档。 #!/usr/bin/perl use strict; use warnings; use LWP::User…...
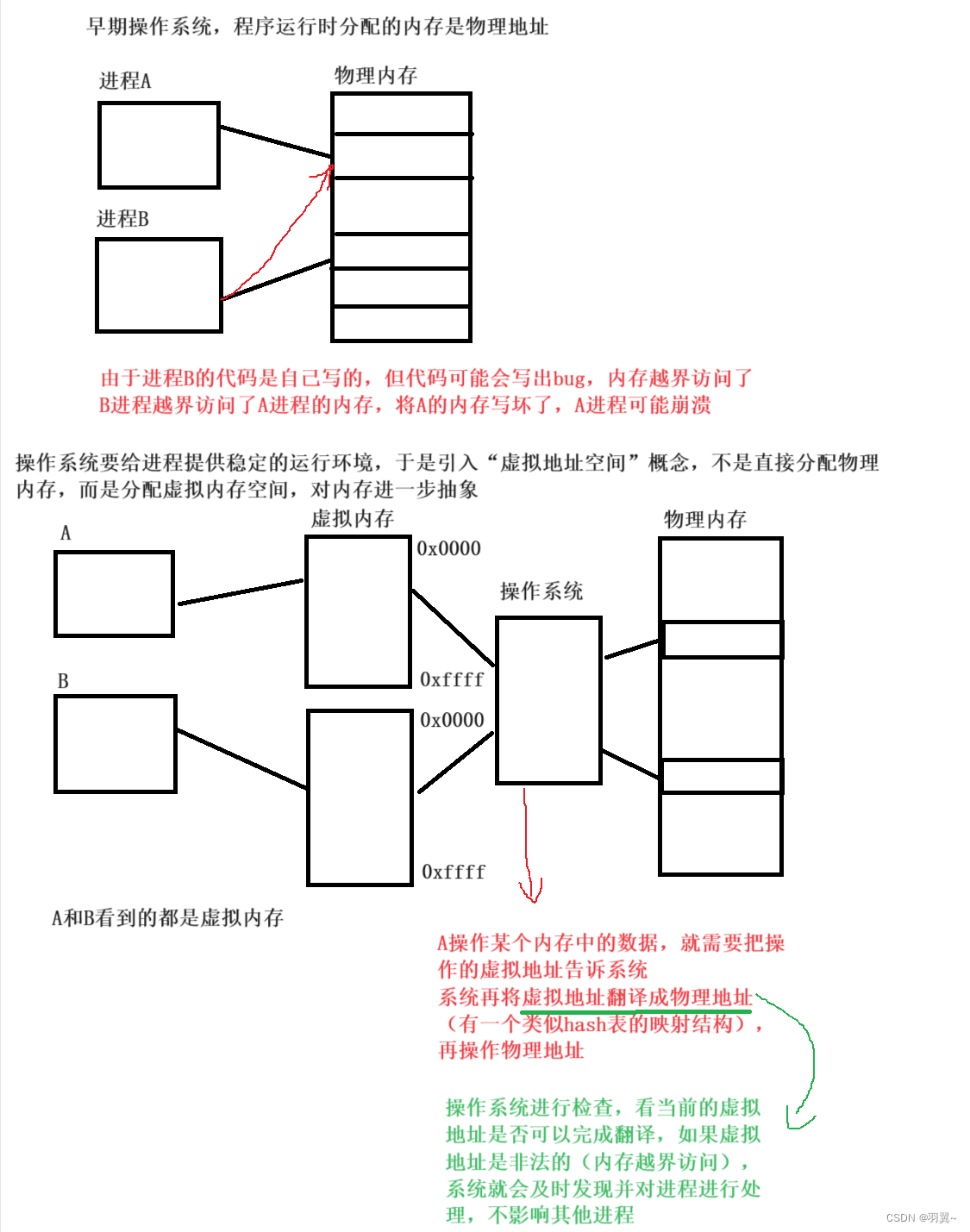
认识计算机-JavaEE初阶
文章目录 一、计算机的发展史二、冯诺依曼体系(Von Neumann Architecture)三、CPU基本工作流程3.1 算术逻辑单元(ALU)3.2 寄存器(Register)和内存(RAM)3.3 控制单元(CU)3…...

you-get - 使用代码下载视频
文章目录 关于 you-get代码调用报错处理 源码简单分析 关于 you-get github : https://github.com/soimort/you-get you-get 是一个有名的开源视频下载工具包,这里不赘述。 代码调用 you-get 提供了命令行的方式下载视频,这里介绍使用 Python 调用源代…...
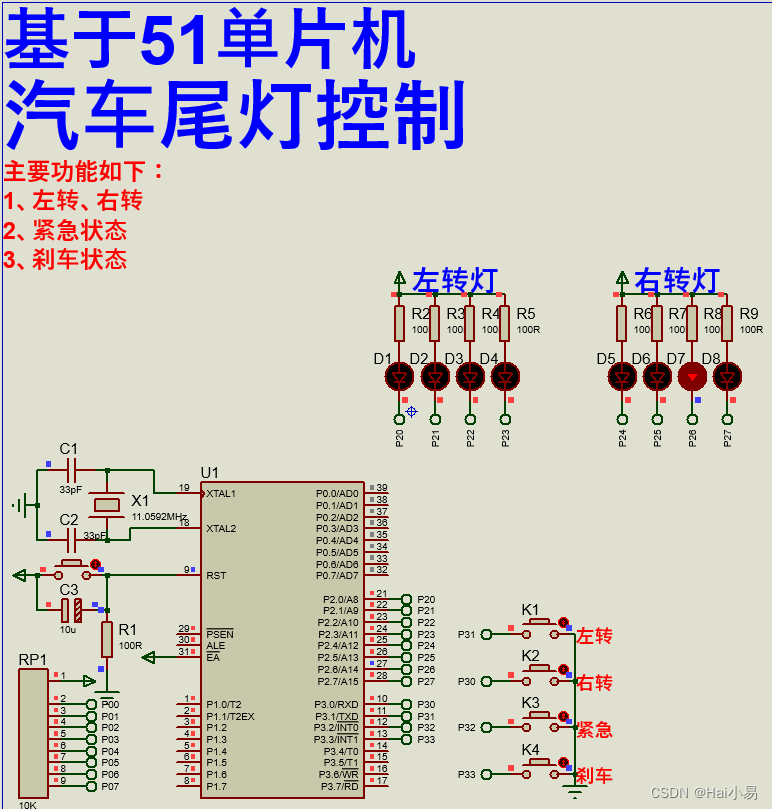
【Proteus仿真】【51单片机】汽车尾灯控制设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用按键、LED模块等。 主要功能: 系统运行后,系统运行后,系统开始运行,K1键控制左转向灯;…...

浙大恩特客户资源管理系统任意文件上传漏洞复现
0x01 产品简介 浙大恩特客户资源管理系统是一款针对企业客户资源管理的软件产品。该系统旨在帮助企业高效地管理和利用客户资源,提升销售和市场营销的效果。 0x02 漏洞概述 浙大恩特客户资源管理系统中fileupload.jsp接口处存在文件上传漏洞,未经身份认…...

史上第一款AOSP开发的IDE (支持Java/Kotlin/C++/Jni/Native/Shell/Python)
ASFP Study 史上第一款AOSP开发的IDE (支持Java/Kotlin/C/Jni/Native/Shell/Python) 类似于Android Studio,可用于开发Android系统源码。 Android studio for platform,简称asfp(爱上富婆)。 背景&下载&使用 背景 由…...
GCC + Vscode 搭建 nRF52xxx 开发环境
在 Windows 下使用 GCC Vscode 搭建 nRF52xxx 开发环境 ...... by 矜辰所致前言 最近有遇到项目需求,需要使用到 Nordic 的 nRF52xxx 芯片,还记得当初刚开始写博文的时候的写的 nRF52832 学习笔记,现在看当时笔记毫无逻辑可言,…...
Linux应用开发基础知识——Framebuffer 应用编程(四)
前言: 在 Linux 系统中通过 Framebuffer 驱动程序来控制 LCD。Frame 是帧的意 思,buffer 是缓冲的意思,这意味着 Framebuffer 就是一块内存,里面保存着 一帧图像。Framebuffer 中保存着一帧图像的每一个像素颜色值,假设…...

DEBIX Model A单板计算机评测:边缘AI与工业应用实战
1. DEBIX Model A单板计算机概述DEBIX Model A是一款基于NXP i.MX 8M Plus处理器的单板计算机(SBC),采用类似树莓派4和3 Model B的外形设计。这款板卡最大的亮点在于集成了2.3 TOPS算力的AI加速器,使其成为边缘AI应用的理想选择。作为嵌入式开发者&#…...

JDK 17强封装性引发的‘血案’:ShardingSphere/MyBatis项目升级踩坑实录与一劳永逸的配置
JDK 17强封装性引发的技术适配困境:ShardingSphereMyBatis深度调优指南 当Java生态迈入模块化时代,JDK 17带来的强封装特性像一把双刃剑,在提升安全性的同时,也让许多依赖反射机制的传统框架陷入适配困境。最近在将ShardingSphere…...
技术效果服务商排名对比列表)
AI搜索优化(GEO/AEO)技术效果服务商排名对比列表
AI搜索优化(GEO/AEO)技术效果服务商排名对比列表 一、全栈技术头部 拓世网络 核心技术:TSPR-4 生成式引擎(TWLH四元结构),主打概率化递推算法与DIVJSON-LD双层结构化。 优势:逻辑自洽、可…...

终极Boss-Key老板键:如何一键隐藏窗口保护你的数字隐私?
终极Boss-Key老板键:如何一键隐藏窗口保护你的数字隐私? 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在现代数字…...

nli-MiniLM2-L6-H768入门必看:无需训练、纯本地的零样本文本分类工具
nli-MiniLM2-L6-H768入门必看:无需训练、纯本地的零样本文本分类工具 1. 工具概述 nli-MiniLM2-L6-H768是一款基于cross-encoder/nli-MiniLM2-L6-H768轻量级NLI模型开发的本地零样本文本分类工具。它彻底改变了传统文本分类需要大量标注数据和训练过程的繁琐流程&…...
)
【限时开放】Java 25虚拟线程高并发调优手册(含Arthas动态注入vthread堆栈、Prometheus自定义指标采集脚本)
第一章:Java 25虚拟线程高并发调优全景概览Java 25正式将虚拟线程(Virtual Threads)从预览特性转为标准特性,并深度整合进JVM线程调度、监控与诊断体系。相比传统平台线程,虚拟线程以极低内存开销(约1KB栈空…...
电路设计实战:从差分走线到射频干扰滤波,一个电阻引发的灵敏度问题)
手机耳机麦克风(ECM)电路设计实战:从差分走线到射频干扰滤波,一个电阻引发的灵敏度问题
手机耳机麦克风电路设计实战:从差分走线到射频干扰的精细调控 在智能手机的音频系统中,耳机麦克风电路设计往往被工程师视为"简单任务",直到产品测试阶段出现灵敏度不足、噪声干扰等问题时才意识到其复杂性。驻极体电容麦克风(ECM)…...

GSE高级宏编译器:3分钟掌握魔兽世界技能自动化的终极指南
GSE高级宏编译器:3分钟掌握魔兽世界技能自动化的终极指南 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Com…...
Windows任务栏美化革命:用TranslucentTB解锁桌面个性化新维度
Windows任务栏美化革命:用TranslucentTB解锁桌面个性化新维度 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 厌倦了Windows任…...

别再只调sklearn的LogisticRegression了!用statsmodels做Python逻辑回归,解读OR值和P值更香
用statsmodels解锁逻辑回归的统计深度:OR值与P值的业务解读实战 在信贷风控和医学研究中,我们常常需要回答这样的问题:"年龄每增加一岁,违约概率会如何变化?"或者"吸烟者患肺癌的几率是非吸烟者的多少倍…...