数据库 高阶语句
目录
数据库 高阶语句
使用select 语句,用order by来对进行排序
区间判断查询和去重查询
如何对结果进行分组查询group by语句
limit 限制输出的结果记录,查看表中的指定行
通配符
设置别名:alias 简写就是 as
使用select 语句,用order by来对进行排序
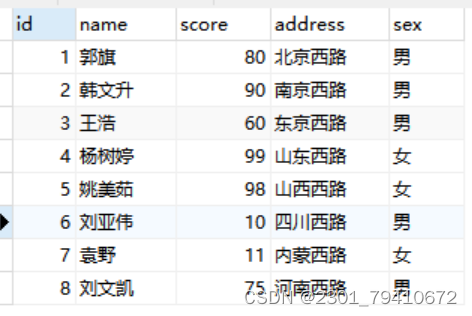
数据库的权限一般是很小的,我们在工作使用最多的场景是查id int(4) primary key,
name varchar(10) not null,
score decimal(5,2),
address varchar(20),
sex char(3) not NULL
);select * from info;使用select 语句,用order by来对进行排序
ASC
#升序排列,默认就是升序,可以不加
desc
#降序排列,需要添加格式 举例
select id,name from info order by id;
#升序查看id那一列select id,name from info order by id desc;
#降序查看id那一列select id,name,score from info order by name desc;
#最好用数据排序比较合适,但不绝对order by 结合where 条件过滤select name,score from info where address='南京西路' order by score desc;
#根据名字,成绩查询地址那一列是南京西路,降序过滤,只有第一个参数出现相同值时,第二个才会按照要求排序#举例:查id姓名成绩,根据性别都是女,按照id进行降序排列
select id,name,score from info where sex='女' order by id desc;区间判断查询和去重查询
AND / or
#且 或select * from info where score > 70 and score <=90;
#例 查询score 列 大于70 且 小于等于90 的数据举例
#大于80或者小于90
select * from info where score > 80 AND score <90;
#查询score列大于80且小于90的数据
select * from info where score > 80 or score <90;
#大于80或小于90嵌套条件select * from info where score > 70 and ( score >75 and score <90 );
#大于70且大于75且小于90
select * from info where score > 70 or ( score >75 and score <90 );
#大于70或大于75且小于90#嵌套条件,满足性别是男,然后进行筛选成绩 80-90
select * from info where sex='男' and (score >80 and score <90);#去重查询
select distinct address from info;
select distinct sex from info;#根据地址address去重,然后过滤成绩=90且性别是男
select distinct address from info where sex='男' and score =90;如何对结果进行分组查询group by语句
对结果进行分组查询group by语句,一般是结合聚合函数一块使用
count() 统计有多少行
sum()列的值相加,求和
avg() 列的值求平均数
max() 过滤出列的最大值
min() 过滤出列的最小值
分组的时候可以按照一个字段,也可以按照多个字段对结果进项分组处理
select * from info;举例格式
select count(name),sex from info group by sex;
#统计name 列 对结果进行分组查询#根据where 条件删选,score >= 80
select count(name),sex,score from info where score >= 80 group by sex;#求和;以地址为分组,对score求和
select sum(score),address from info group by address;#算出男生女生平均成绩
select avg(score),sex from info group by sex;#分别求出男生组和女生组的成绩最低的姓名
select min(score),sex from info group by sex;#group by 实现条件过滤,后面跟上having语句实现条件过滤
select avg(score),address from info group by address having avg(score) >按照地址分组,求成绩的平均值,然后>50,按照id的降序排列
select avg(score),address,id from info group by address having avg(score) >50 order by id desc;select avg(score),address,id from info group by address having avg(score) >50 order by id desc;
统计name 的行数,计算出学生的个数把成绩也查出来按照统计出来的学生个数升序排列按照地址分组,学生的成绩大于等于70分select count(name),score,address from info group by address having score >= 70 order by count(name);
按照性别分组,求出男生和女生的最大成绩,最大成绩是否超过75分,满足条件的过滤出来select max(score),sex from info group by sex having max(score) > 75;
使用聚合函数必须要加group by 要选用有多个重复值的列,group by的过滤条件要用having语句过滤limit 限制输出的结果记录,查看表中的指定行
select * from info;select * from info limit 3;
#只看前三行#看2行到5行
select * from info limit 1,4;#看6到7行
select * from info limit 5,3;select * from info order by id desc limit 3;
#快速查询后几行,将最后几行降序方式到前几行,再用limit只查看前三行通配符
#通配符主要用于替换字符串中的部分字符,通过部分字符的匹配向相关的结果查询出来
#通配符和like一起使用,使用where语句一起来完成查询
# % 表示0个,1个或者多个
# _ 表示单个字符select * from info where address like '山%';
#以山为结尾select * from info where address like '%路';
#以路为结尾select * from info where address like '%山%';
#中间有山select * from info where name like '杨_婷';select * from info where name like '%婷';select * from info where address like '山%__';
#通配符可以结合在一块使用设置别名:alias 简写就是 as
#设置别名的目的是在mysql查询时,表的名字或者字段名太长,可以使用别名替代,方便书写,也可以增加可读性
#可以给表起别名,但是要注意别名不能和数据库其他的表名互相冲突
#列的别名在结果中可以显示,但是表的别名在结果中没有显示,只能用于查询格式 举例
select name as 姓名, score as 成绩 from info;select name 姓名,score 成绩 from info;
#可以不加ascreate table test as select * from info;
#创建了一个表,叫test ,test的数据结构完整的从info复制过来,但是约束不会被复制desc test;
#使用as复制表,约束不会被复制过来。create table test1 as select * from info where score >=60;
#创建一个表,通过as复制info表,但只有score那列 大于等于60 才会被复制#以这种方式创建的表主键在不在,外键在不在,索引在不在?
#都不在
#通过as创建,主键没了,外键没了,外键在不在,索引在不在?
#都不在相关文章:
数据库 高阶语句
目录 数据库 高阶语句 使用select 语句,用order by来对进行排序 区间判断查询和去重查询 如何对结果进行分组查询group by语句 limit 限制输出的结果记录,查看表中的指定行 通配符 设置别名:alias 简写就是 as 使用select 语句&#x…...
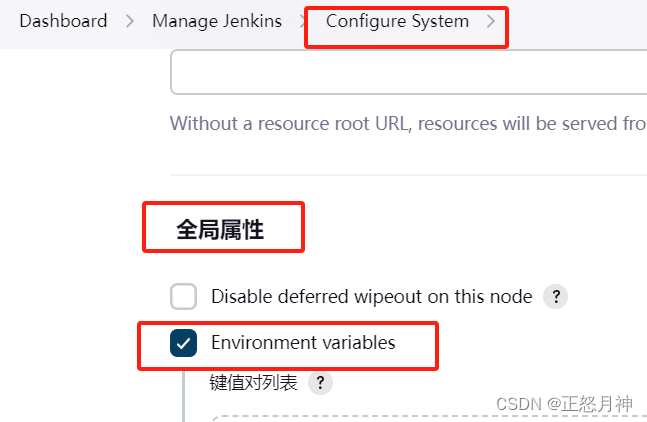
jenkins Java heap space
jenkins Java heap space,是内存不够。 两个解决方案: 一,修改配置文件 windows系统中,找到Jenkins的安装路径, 修改jenkins.xml 将 -Xmx256m 改为 -Xmx1024m 或者更大 重启jenkins服务。 二,jenkins增…...

OpenCV校准棋盘集合
棋盘格可以与相机校准工具一起使用,例如ROS的camera_calibration包。您可以通过单击下面的任何链接免费下载 PDF 格式的各种棋盘,没有水印或广告。此外,还添加了基于 JavaScript 的棋盘生成器,允许您生成自定义尺寸。 提示&#…...

使用git将本地项目推送到远程仓库github
总结:本地项目通过git上传到github 1)、在本地创建一个版本库(即文件夹),通过 git init 把它变成Git仓库; 2)、把项目复制到这个文件夹里面,再通过 git add . 把项目添加到仓库; 3)、再通过 gi…...
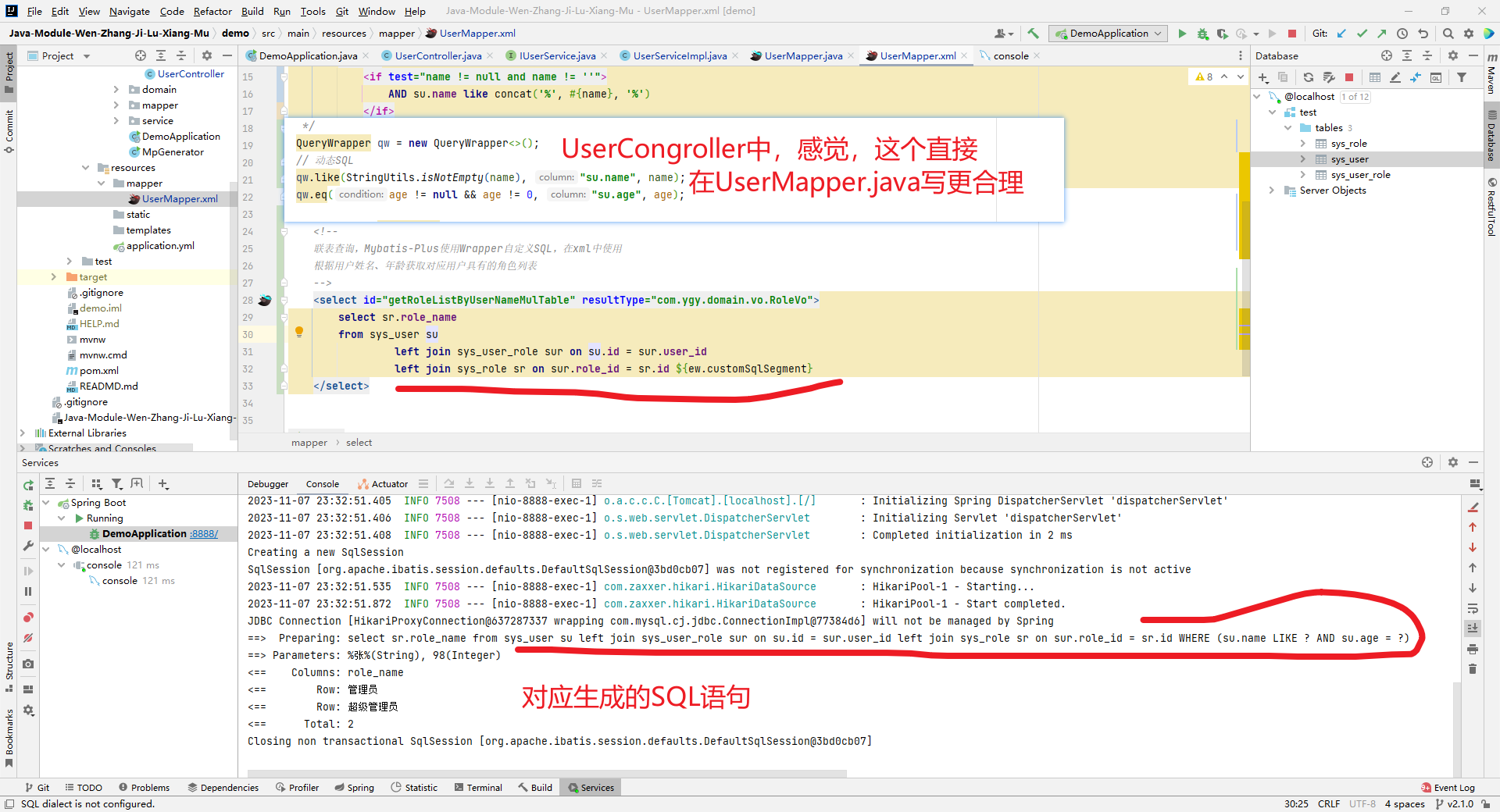
Mybatis-Plus使用Wrapper自定义SQL
文章目录 准备工作Mybatis-Plus使用Wrapper自定义SQL注意事项目录结构如下所示domain层Controller层Service层ServiceImplMapper层UserMapper.xml 结果如下所示:单表查询条件构造器单表查询,Mybatis-Plus使用Wrapper自定义SQL联表查询不用,My…...
仿mudou库one thread one loop式并发服务器
目录 1.实现目标 2.HTTP服务器 实现高性能服务器-Reactor模型 模块划分 SERVER模块: HTTP协议模块: 3.项目中的子功能 秒级定时任务实现 时间轮实现 正则库的简单使用 通⽤类型any类型的实现 4.SERVER服务器实现 日志宏的封装 缓冲区Buffer…...

二十三种设计模式全面解析-组合模式与装饰器模式的结合:实现动态功能扩展
在前文中,我们介绍了组合模式的基本原理和应用,以及它在构建对象结构中的价值和潜力。然而,组合模式的魅力远不止于此。在本文中,我们将继续探索组合模式的进阶应用,并展示它与其他设计模式的结合使用,以构…...
智慧城市建设解决方案分享【完整】
文章目录 第1章 前言第2章 智慧城市建设的背景2.1 智慧城市的发展现状2.2 智慧城市的发展趋势 第3章 智慧城市“十二五”规划要点3.1 国民经济和社会发展“十二五”规划要点3.2 “十二五”信息化发展规划要点 第4章 大数据:智慧城市的智慧引擎4.1 大数据技术—智慧城…...

unity - Blend Shape - 变形器 - 实践
文章目录 目的Blend Shape 逐顶点 多个混合思路Blender3Ds maxUnity 中使用Project 目的 拾遗,备份 Blend Shape 逐顶点 多个混合思路 blend shape 基于: vertex number, vertex sn 相同,才能正常混合、播放 也就是 vertex buffer 的顶点数…...
asp.net core mvc之路由
一、默认路由 (Startup.cs文件) routes.MapRoute(name: "default",template: "{controllerHome}/{actionIndex}/{id?}" ); 默认访问可以匹配到 https://localhost:44302/home/index/1 https://localhost:44302/home/index https:…...

前端设计模式之【访问者模式】
文章目录 前言介绍实现优缺点应用场景后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&#…...
通过docker-compose部署elk日志系统,并使用springboot整合
ELK是一种强大的分布式日志管理解决方案,它由三个核心组件组成: Elasticsearch:作为分布式搜索和分析引擎,Elasticsearch能够快速地存储、搜索和分析大量的日志数据,帮助用户轻松地找到所需的信息。 Logstash…...

【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]
什么是机器学习中的特征提取? 特征提取是数据分析和机器学习中的基本概念,是将原始数据转换为更适合分析或建模的格式过程中的关键步骤。特征,也称为变量或属性,是我们用来进行预测、对对象进行分类或从数据中获取见解的数据点的…...
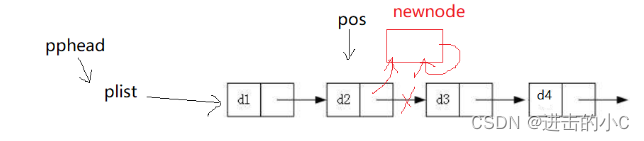
数据结构-单链表
1 链表的概念及结构 概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。 从以上图片可以看出: 1.链式结构在逻辑上是连续的,但在物理上不一定是连续的。 2.现实中的节…...
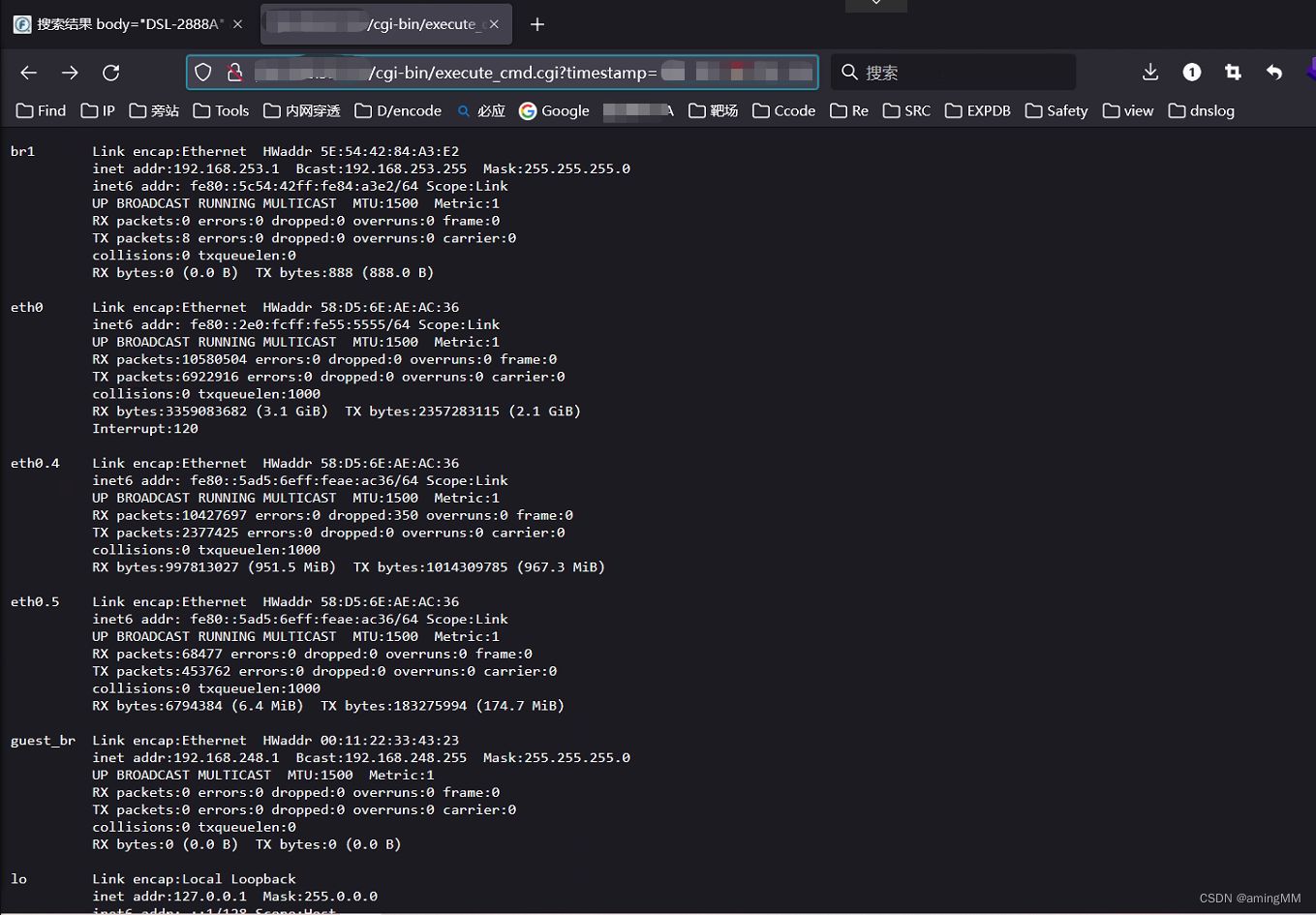
红队系列-IOT安全深入浅出
红队专题 设备安全概述物联网设备层次模型设备通信模型 渗透测试信息收集工具 实战分析漏洞切入点D-link 850L 未授权访问 2017 认证绕过认证绕过 D-link DCS-2530Ltenda 系列 路由器 前台未授权RTSP 服务未授权 访问 弱口令命令注入思科 路由器 固件二进制 漏洞 IoT漏洞-D-Lin…...

亚数受邀参加“长三角G60科创走廊量子密码应用创新联盟(中心)”启动仪式
11月8日,在第六届中国国际进口博览会2023长三角G60科创走廊高质量发展要素对接大会上,亚数信息科技(上海)有限公司CEO翟新元作为密码企业代表之一受邀参加“长三角G60科创走廊量子密码应用创新联盟(中心)”…...

直方图学习
直方图均衡化(Histogram Equalization)是一种用于增强图像对比度的图像处理技术,通过重新分配图像的像素值,使图像中的亮度级别更加均匀,以改善图像的视觉质量。下面是进行直方图均衡化的一般步骤: 计算原始…...
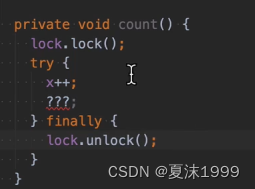
Java / Android 多线程和 synchroized 锁
s AsyncTask 在Android R中标注了废弃 synchronized 同步 Thread: thread.start() public synchronized void start() {/*** This method is not invoked for the main method thread or "system"* group threads created/set up by the VM. Any new functionali…...

基于51单片机的万年历-脉搏计仿真及源程序
一、系统方案 1、本设计采用51单片机作为主控器。 2、DS1302采集年月日时分秒送到液晶1602显示。 3、按键年月日时分秒,心率报警上下限。 4、红外对接管传感器采集心率送到液晶1602显示。 5、心率低于下限或高于上限,蜂鸣器报警。 二、硬件设计 原理图如…...

【ARFoundation学习笔记】点云与参考点
写在前面的话 本系列笔记旨在记录作者在学习Unity中的AR开发过程中需要记录的问题和知识点。主要目的是为了加深记忆。其中难免出现纰漏,更多详细内容请阅读原文以及官方文档。 汪老师博客 文章目录 点云新建点云 参考点参考点的工作原理何时使用参考点使用参考点…...

Qwen3.5-2B智能运维实践:利用Python脚本实现系统监控告警
Qwen3.5-2B智能运维实践:利用Python脚本实现系统监控告警 1. 运维工程师的日常痛点 运维工程师小李每天的工作是这样的:早上9点打开电脑,先检查几十台服务器的CPU、内存、磁盘使用情况,然后查看各种日志文件寻找异常,…...
)
手把手调试:用Wireshark抓包分析SIP REFER实现呼叫转移的完整流程(含NOTIFY消息解读)
手把手调试:用Wireshark抓包分析SIP REFER实现呼叫转移的完整流程(含NOTIFY消息解读) 在VoIP和实时通信系统中,SIP(Session Initiation Protocol)作为核心信令协议,其REFER方法在实现呼叫转移功…...

从CT设备数据流中断到容器网络修复,Docker医疗调试黄金6小时响应流程全披露
第一章:从CT设备数据流中断到容器网络修复,Docker医疗调试黄金6小时响应流程全披露当医院影像科CT设备突然停止向PACS系统推送DICOM影像,后台日志显示“connection refused to 10.244.3.17:4242”,而该IP正是运行DICOM网关服务的D…...
)
企业级AI落地标杆!Spring AI + Skill架构,手把手搭建可生产金融智能体(附完整代码+架构全解析)
大家好,我是直奔標杆!专注于分享企业级AI落地实战经验,今天给大家带来一篇干货满满的实战教程——从0到1搭建基于JavaSpring AISkill架构的金融智能体,全程干货无废话,包含完整架构图、接口定义、核心代码、启动流程&a…...

构建跨设备游戏流媒体技术栈:Sunshine自托管服务器全解析与实践指南
构建跨设备游戏流媒体技术栈:Sunshine自托管服务器全解析与实践指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一个开源的自托管游戏流媒体服务器&…...

别再傻傻分不清:Linux里的TTY、PTS和PTY到底啥关系?一个SSH登录就讲明白
从SSH登录解密Linux终端:TTY、PTS与PTY的协作之谜 当你通过SSH连接到Linux服务器,输入who命令看到pts/0时,是否好奇过这个标识背后的技术逻辑?终端窗口左上角显示的tty1与远程会话中的pts/0究竟有何不同?这些看似简单的…...

Phi-3.5-Mini-Instruct惊艳效果展示:7GB显存下媲美Qwen2.5的逻辑与代码能力
Phi-3.5-Mini-Instruct惊艳效果展示:7GB显存下媲美Qwen2.5的逻辑与代码能力 1. 开篇亮点 Phi-3.5-Mini-Instruct作为微软最新推出的轻量级大模型,在仅需7GB显存的条件下,展现出令人惊叹的逻辑推理和代码生成能力。这款专为本地运行优化的模…...

3个实用场景告诉你为什么需要UserAgent-Switcher浏览器扩展
3个实用场景告诉你为什么需要UserAgent-Switcher浏览器扩展 【免费下载链接】UserAgent-Switcher A User-Agent spoofer browser extension that is highly configurable 项目地址: https://gitcode.com/gh_mirrors/us/UserAgent-Switcher 你是否曾经遇到过网站检测到你…...

从入门到精通:Emoji符号的编码原理与跨平台应用指南
1. Emoji的前世今生:从笑脸符号到全球通用语言 2008年,苹果公司在iOS 2.2中首次引入Emoji键盘,这个看似简单的功能更新却彻底改变了数字通信的方式。你可能不知道的是,最早的Emoji其实诞生于1999年,由日本电信运营商NT…...

手机号逆向查询QQ号:3步快速实现的完整Python解决方案
手机号逆向查询QQ号:3步快速实现的完整Python解决方案 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字身份管理领域,手机号查QQ已成为众多开发者和企业用户的刚性需求。phone2qq项目提供了一个无需登录…...