最详细的LightGBM参数介绍与深入分析
前言
我使用LightGBM有一段时间了,它一直是我处理大多数表格数据问题的首选算法。它有很多强大的功能,如果你还没有看过的话,我建议你去了解一下。
但我一直对了解哪些参数对性能影响最大,以及如何调整LightGBM参数以发挥最大作用很感兴趣。
我决定进行一些研究,深入了解LightGBM的参数,并分享我的经验。
1.梯度增强方法
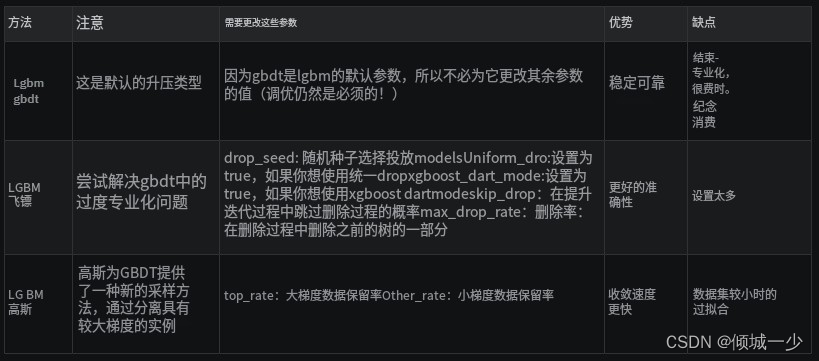
使用 LightGBM,您可以运行不同类型的梯度增强方法。 您有:GBDT、DART 和 GOSS,可以使用 boosting 参数指定。
在接下来的部分中,我将解释并比较这些方法。
1.1 lgbm gbdt(梯度提升决策树)
该方法是本文首次提出的传统梯度提升决策树,也是 XGBoost 和 pGBRT 等一些优秀库背后的算法。
如今,gbdt 因其准确性、高效性和稳定性而被广泛使用。
它基于三个重要原则:
- 弱学习器(决策树)
- 梯度优化
- 升压技术
所以在gbdt方法中我们有很多决策树(弱学习器)。 这些树是按顺序构建的:
- 第一棵树学习如何适应目标变量
- 第二棵树学习如何适应第一棵树的预测和地面实况之间的残差(差异)
- 第三棵树学习如何拟合第二棵树的残差,依此类推。
所有这些树都是通过在整个系统中传播误差梯度来训练的。
gbdt 的主要缺点是在每个树节点中找到最佳分割点是一项耗时且消耗内存的操作,其他 boosting 方法试图解决该问题。
1.2 dart 梯度提升
在这篇出色的论文论文论文中,您可以了解有关 DART 梯度提升的所有知识,这是一种使用神经网络标准 dropout 的方法,以改进模型正则化并处理其他一些不太明显的问题。
也就是说,gbdt 存在过度专业化的问题,这意味着在后续迭代中添加的树往往只会影响少数实例的预测,而对其余实例的贡献可以忽略不计。 添加 dropout 使得后续迭代中的树更难专门处理那些少数样本,从而提高模型性能。
1.3 lgbm goss(基于梯度的一侧采样)
事实上,将该方法命名为lightgbm的最重要原因是使用了基于本文的Goss方法。 Goss 是更新且更轻的 GBDT 实现(因此是“轻”GBM)。
标准 GBDT 很可靠,但在大型数据集上速度不够快。 因此,戈斯提出了一种基于梯度的采样方法,以避免搜索整个搜索空间。 我们知道,对于每个数据实例,当梯度很小时,意味着不用担心数据经过良好训练,而当梯度很大时,应该再次重新训练。 所以我们这里有两个方面,即具有大梯度和小梯度的数据实例。 因此,goss 保留所有具有大梯度的数据,并对具有小梯度的数据进行随机采样(这就是为什么它被称为单侧采样)。 这使得搜索空间更小,goss 可以更快地收敛。 最后,为了更深入地了解 goss,
让我们将这些差异放在表格中:
2.正则化
我将介绍 lightgbm 的一些重要的正则化参数。 显然,这些是您需要调整以对抗过度拟合的参数。
应该意识到,对于小型数据集(<10000 条记录),lightGBM 可能不是最佳选择。 调整 lightgbm 参数可能对您没有帮助。
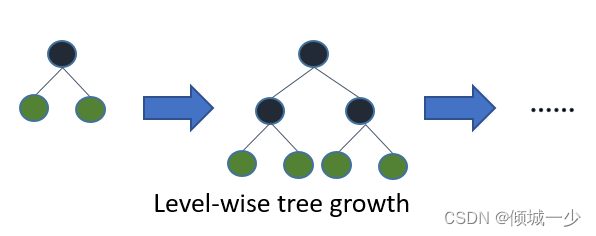
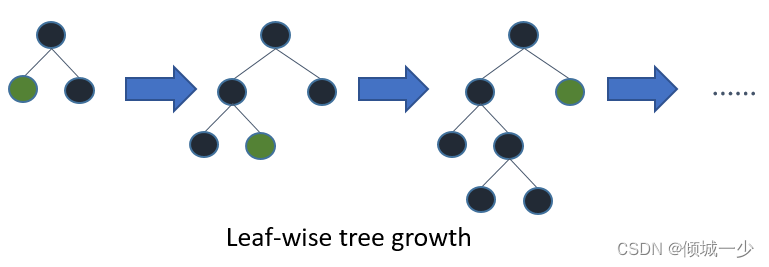
另外,lightgbm使用leaf-wise树生长算法,而XGBoost使用深度wise树生长算法。 Leaf-wise方法允许树更快地收敛,但过度拟合的机会增加。
根据 lightGBM 文档,当面临过度拟合时,您可能需要进行以下参数调整:
- 使用较小的 max_bin
- 使用小的 num_leaves
- 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf
- 通过设置 bagging_fraction 和 bagging_freq 使用 bagging
- 通过设置feature_fraction来使用特征子采样
- 使用更大的训练数据
- 尝试 lambda_l1、lambda_l2 和 min_gain_to_split 进行正则化
- 尝试 max_depth 以避免树长得很深
在下面的部分中,我将更详细地解释每个参数。
2.1 lambda_l1
Lambda_l1(和 lambda_l2)对 l1/l2 的控制以及 min_gain_to_split 用于对抗过度拟合。 我强烈建议您使用参数调整(在后面的部分中探讨)来找出这些参数的最佳值。
2.2 num_leaves
当然,"num_leaves" 绝对是控制模型复杂度的最重要参数之一。通过这个参数,你设定了每个弱学习器的最大叶子节点数。较大的 "num_leaves" 可以提高在训练集上的准确性,但同时也增加了过拟合的风险。根据文档的描述,一种简单的设置方式是 num_leaves = 2^(max_depth),然而,考虑到在LightGBM中,基于叶子节点的树比基于层级的树更深,因此你需要谨慎处理过拟合问题!因此,有必要将 "num_leaves" 与 "max_depth" 一起进行调整。
2.3 subsample
使用 subsample (或 bagging_fraction),您可以指定每次树构建迭代使用的行的百分比。 这意味着将随机选择一些行来适合每个学习器(树)。 这提高了泛化能力,也提高了训练速度。
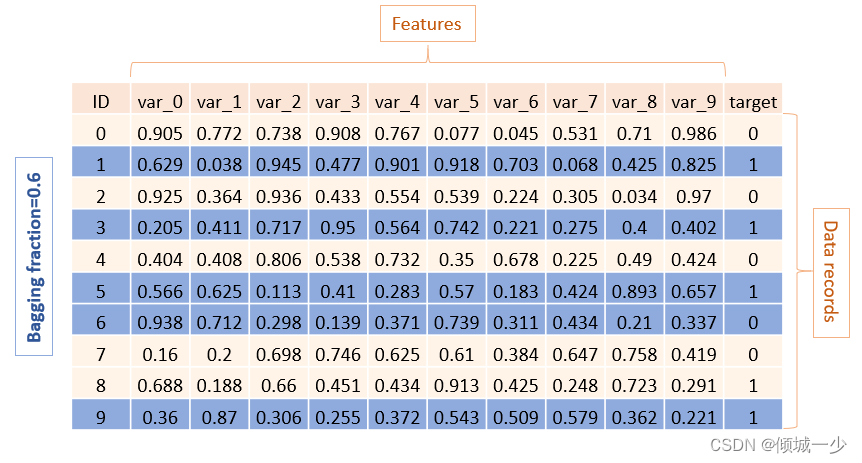
我建议对基线模型使用较小的子样本值,然后在完成其他实验(不同的特征选择、不同的树结构)时增加该值。
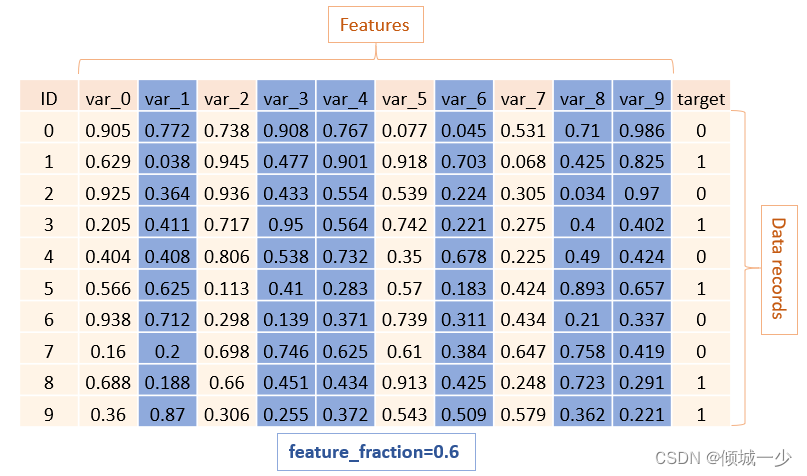
2.4 feature_fraction
特征分数或 sub_feature 处理列采样,LightGBM 将在每次迭代(树)上随机选择特征子集。 例如,如果将其设置为 0.6,LightGBM 将在训练每棵树之前选择 60% 的特征。
该功能有两种用途:
- 可用于加速训练
- 可以用来处理过拟合
2.5 max_depth
该参数控制每个训练树的最大深度,并将影响:
- num_leaves 参数的最佳值
- 模型性能
- 训练时间
注意如果您使用较大的 max_depth 值,您的模型可能会过度拟合训练集。
2.6 max_bin
分箱是一种以离散视图(直方图)表示数据的技术。 Lightgbm 使用基于直方图的算法来找到最佳分割点,同时创建弱学习器。 因此,每个连续的数字特征(例如视频的观看次数)应分为离散的容器。

max_bin 对 CPU 和 GPU 的影响如下图:
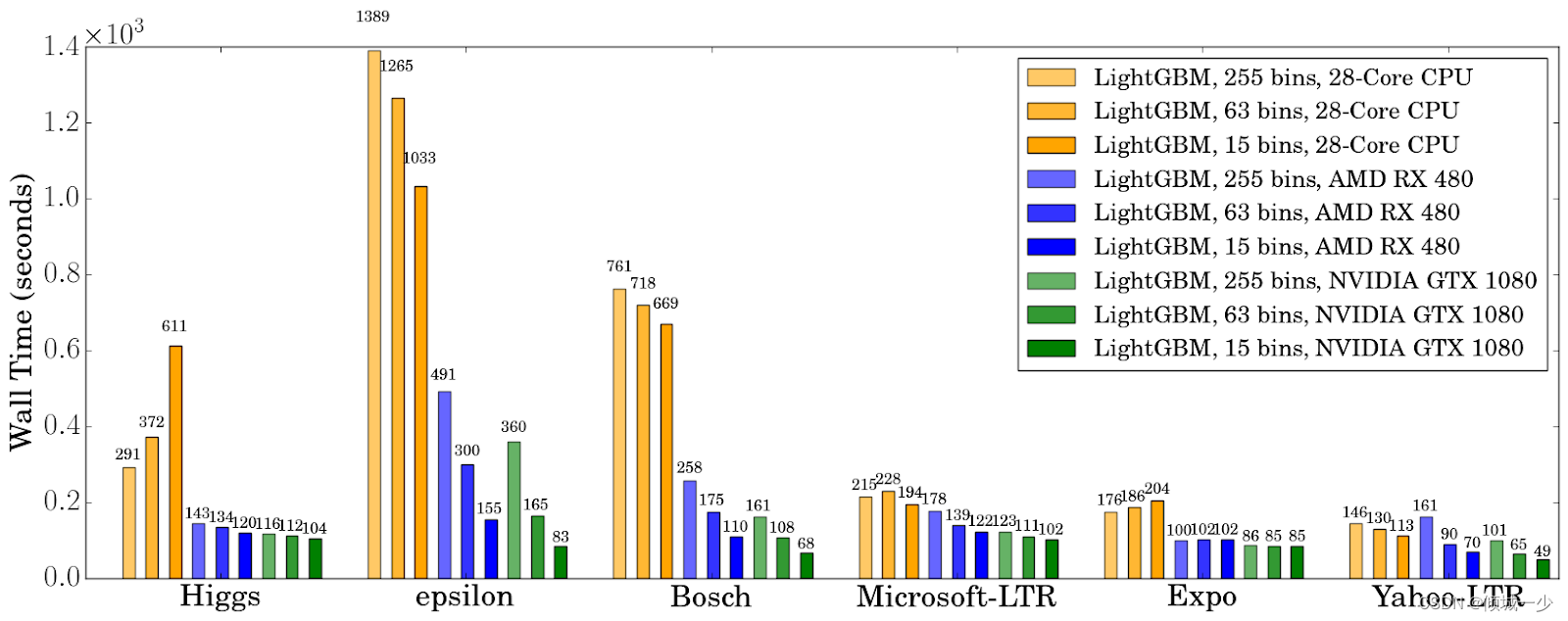
如果将 max_bin 定义为 255,则意味着每个特征最多可以有 255 个唯一值。 那么较小的 max_bin 会导致更快的速度,而较大的值会提高准确性。
3.训练参数
当您想使用 lightgbm 训练模型时,训练 lightgbm 模型时可能会出现的一些典型问题是:
- 训练是一个耗时的过程
- 处理计算复杂性(CPU/GPU RAM 限制)
- 处理分类特征
- 数据集不平衡
- 自定义指标的需求
- 需要针对分类或回归问题进行的调整
3.1 num_iterations
Num_iterations 指定提升迭代(要构建的树)的数量。 您构建的树越多,模型就越准确,但代价是:
- 训练时间更长
- 过拟合的可能性更高
建议使用较小的learning_rate和较大的num_iterations。 另外,如果您选择更高的 num_iterations 来在没有学习到任何有用的东西时停止训练,则应该使用 Early_stopping_rounds .
3.2 early_stopping_rounds
如果验证指标在最后一轮提前停止后没有改善,则该参数将停止训练。 这应该与多次迭代一起定义。 如果将其设置得太大,则会增加过度拟合的机会(但您的模型可以更好)。
经验法则是让它占 num_iterations 的 10%。
3.3 lightgbm categorical_feature
使用lightgbm的优点之一是它可以很好地处理分类特征。 是的,这个算法非常强大,但是你必须小心如何使用它的参数。 lightgbm 使用特殊的整数编码方法(由 Fisher 提出)来处理分类特征
实验表明,该方法比常用的 one-hot 编码具有更好的性能。
它的默认值是“auto”,这意味着:让 lightgbm 决定,这意味着 lightgbm 将推断哪些特征是分类的。
它并不总是工作得很好(一些实验说明了为什么在这里和这里),我强烈建议您使用此代码手动设置分类特征
cat_col = dataset_name.select_dtypes(‘object’).columns.tolist()但是幕后发生了什么以及 lightgbm 如何处理分类特征?
根据lightgbm的文档,我们知道树学习器不能很好地使用一种热门的编码方法,因为它们在树中生长得很深。 在所提出的替代方法中,树学习器是最优构造的。 例如,对于具有 k 个不同类别的一个特征,有 2^(k-1) – 1 个可能的分区,并且使用 Fisher 方法,可以通过在值的排序直方图上找到最佳分割方式来改进为 k * log(k) 在分类特征中。
3.4 lightgbm is_unbalance vs scale_pos_weight
在二元分类问题中您可能面临的问题之一是如何处理不平衡的数据集。 显然,您需要平衡正/负样本,但是在 lightgbm 中到底如何做到这一点呢?
lightgbm中有两个参数可以让你处理这个问题is_unbalance和scale_pos_weight,但是它们之间有什么区别以及如何使用它们呢?
当您设置 Is_unbalace: True 时,算法将尝试自动平衡主导标签的权重(与训练集中的 pos/neg 分数)
如果您想在数据集不平衡的情况下更改scale_pos_weight(默认为1,这意味着假设正标签和负标签相等),您可以使用以下公式(基于lightgbm存储库上的此问题)来正确设置它
sample_pos_weight = number of negative samples / number of positive samples3.5 lgbm feval
有时您想要定义自定义评估函数来衡量模型的性能,您需要创建 feval 函数。
Feval 函数应接受两个参数:
- preds
- train_data
并返回
- eval_name
- eval_result
- is_higher_better
让我们逐步创建一个自定义指标函数。定义一个单独的Python函数
def feval_func(preds, train_data):# Define a formula that evaluates the resultsreturn ('feval_func_name', eval_result, False)使用此函数作为参数:
print('Start training...')
lgb_train = lgb.train(...,metric=None,feval=feval_func)3.6 classification 参数 vs regression 参数
我之前提到的大多数内容对于分类和回归都是正确的,但有些事情需要调整。
具体来说,您应该:
| 名称 | 分类注意事项 | 回归注意事项 |
| objective | Set it binary or multiclass | Set it regression |
| metric | Binary_logloss or AUC or etc. | RMSE or mean_absolute_error and or etc. |
| is_unbalance | True or false | – |
| scale_pos_weight | used only in binary and multi class applications | – |
| num_class | used only in multi-class classification application | – |
| reg_sqrt | – | Used to fit sqrt(label) instead of original values for large range label |
4. 最重要的lightgbm参数
我们在前面的部分中回顾并了解了一些有关 lightgbm 参数的知识,但是如果不提及 Laurae 令人难以置信的基准,任何增强树文章都是不完整的 。
您可以了解 lightGBM 和 XGBoost 的许多问题的最佳默认参数。
您可以在这里查看,但一些最重要的要点是:
| 参数名称 | 默认值 | 范围 | 参数类型r | 别名 | 约束或注释 | 用途 |
| objective | regression | regression, binary | enum | objective_type, app | when you change it affects other parameters | specify the type of ML model |
| metric | null | +20 different metrics | multi-enum | metrics, metric_types | null means that metric corresponding to specified objective will be used | specify metric, support multiple metrics |
| boosting | gbdt | gbdt, rf, dart, goss | enum | boosting_type | if you set it RF, that would be a bagging approach | method of boosting |
| lambda_l1 | 0.0 | [0, ∞] | double | reg_alpha | lambda_l1 >= 0.0 | regularization |
| bagging_fraction | 1.0 | [0, 1] | double | subsample | 0.0 < bagging_fraction <= 1.0 | randomly select part of data without resampling |
| bagging_freq | 0.0 | [0, ∞] | int | subsample_freq | to enable bagging, bagging_fraction should be set to value smaller than 1.0 as well | 0 means disable bagging; k means perform bagging at every k iteration |
| num_leaves | 31 | [1, ∞] | int | num_leaf | 1 < num_leaves <= 131072 | max number of leaves in one tree |
| feature_fraction | 1.0 | [0,1] | double | sub_feature | 0.0 < feature_fraction <= 1.0 | if you set it to 0.8, LightGBM will select 80% of features |
| max_depth | -1 | [-1, ∞] | int | max_depth | larger is usually better, but overfitting speed increases | limit the max depth for tree model |
| max_bin | 255 | [2, ∞] | int | histogram binning | max_bin > 1 | eal with over-fitting |
| num_iterations | 100 | [1, ∞] | int | num_boost_round, n_iter | num_iterations >= 0 | number of boosting iterations |
| learning_rate | 0.1 | [0, 1] | double | eta | learning_rate > 0.0Typical: 0.05 | in dart, it also affects on normalization weights of dropped trees |
| early_stopping _round | 0 | [0, ∞] | double | early_stopping _round | will stop training if validation doesn’t improve in last early_stopping _round | model performance, number of iterations, training time |
| categorical_feature | empty string | specify a number for a column index | multi-int or string | cat_feature | – | handle categorical features |
| bagging_freq | 0.0 | [0, ∞] | int | subsample_freq | 0 means disable bagging; k means perform bagging at every k iteration | to enable bagging, bagging_fraction should be set to value smaller than 1.0 as well |
| verbosity | 0 | [-∞, ∞] | int | verbose | < 0: Fatal, = 0: Error (Warning), = 1: Info, > 1: Debug | useful for debging |
| min_data_in_leaf | 20 | min_data | int | min_data | min_data_in_leaf >= 0 | can be used to deal with over-fitting |
5.python中的Lightgbm参数调整示例
最后,在解释了所有重要参数之后,是时候进行一些实验了!
我将使用流行的 Kaggle 竞赛之一:桑坦德客户交易预测(Santander Customer Transaction Prediction. )。
- 我将使用这篇文章解释如何在 Python 中对任何脚本运行超参数调整。
- 在我们开始之前,有一个重要问题! 我们应该调整哪些参数?
注意你想要解决的问题,例如桑坦德数据集是高度不平衡的,在你的调整中应该考虑到这一点! Laurae2,lightgbm 的贡献者之一,在这里对此做了很好的解释。
有些参数是相互依赖的,必须一起调整或一项一项调整。 例如,min_data_in_leaf 取决于训练样本的数量和 num_leaves。
注意:最好为超参数创建两个字典,一个包含您不想调整的参数和值,另一个包含您想要调整的参数和值范围。
SEARCH_PARAMS = {'learning_rate': 0.4,'max_depth': 15,'num_leaves': 20,'feature_fraction': 0.8,'subsample': 0.2}FIXED_PARAMS={'objective': 'binary','metric': 'auc','is_unbalance':True,'boosting':'gbdt','num_boost_round':300,'early_stopping_rounds':30}5.1 结果分析
这里我一步一步解释如何调整超参数的值。创建基线训练代码:
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import train_test_split
import neptunecontrib.monitoring.skopt as sk_utils
import lightgbm as lgb
import pandas as pd
import neptune
import skopt
import sys
import osSEARCH_PARAMS = {'learning_rate': 0.4,'max_depth': 15,'num_leaves': 32,'feature_fraction': 0.8,'subsample': 0.2}FIXED_PARAMS={'objective': 'binary','metric': 'auc','is_unbalance':True,'bagging_freq':5,'boosting':'dart','num_boost_round':300,'early_stopping_rounds':30}def train_evaluate(search_params):# you can download the dataset from this link(https://www.kaggle.com/c/santander-customer-transaction-prediction/data)# import Dataset to play with itdata= pd.read_csv("sample_train.csv")X = data.drop(['ID_code', 'target'], axis=1)y = data['target']X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)train_data = lgb.Dataset(X_train, label=y_train)valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)params = {'metric':FIXED_PARAMS['metric'],'objective':FIXED_PARAMS['objective'],**search_params}model = lgb.train(params, train_data,valid_sets=[valid_data],num_boost_round=FIXED_PARAMS['num_boost_round'],early_stopping_rounds=FIXED_PARAMS['early_stopping_rounds'],valid_names=['valid'])score = model.best_score['valid']['auc']return score
Use the hyperparameter optimization library of your choice (for example scikit-optimize):neptune.init('mjbahmani/LightGBM-hyperparameters')
neptune.create_experiment('lgb-tuning_final', upload_source_files=['*.*'],tags=['lgb-tuning', 'dart'],params=SEARCH_PARAMS)SPACE = [skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),skopt.space.Integer(1, 30, name='max_depth'),skopt.space.Integer(10, 200, name='num_leaves'),skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')
]
@skopt.utils.use_named_args(SPACE)
def objective(**params):return -1.0 * train_evaluate(params)monitor = sk_utils.NeptuneMonitor()
results = skopt.forest_minimize(objective, SPACE,n_calls=100, n_random_starts=10,callback=[monitor])
sk_utils.log_results(results)neptune.stop()尝试不同类型的配置并在 Neptune 应用程序中跟踪您的结果。
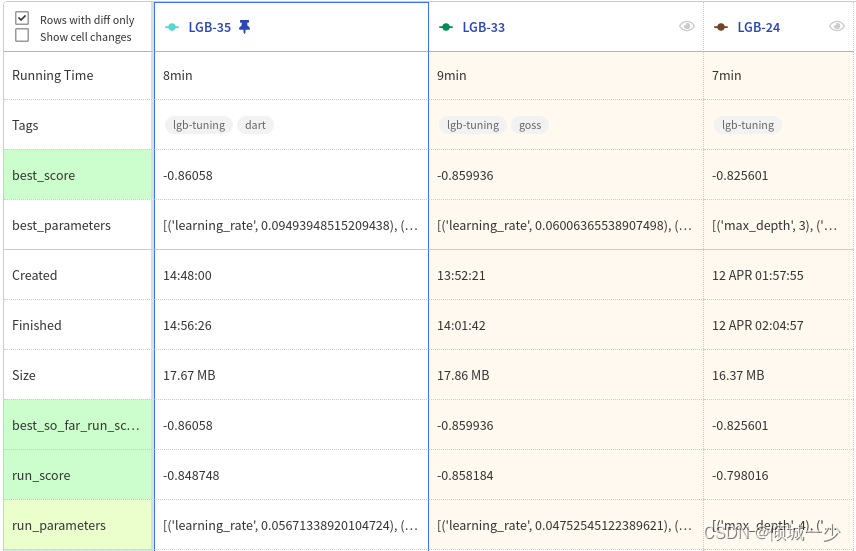
最后,在下表中,您可以看到参数发生了哪些变化。
| 超参数 | 微调前 | 微调后 |
| learning_rate | 0.4 | 0.094 |
| max_depth | 15 | 10 |
| num_leaves | 32 | 12 |
| feature_fraction | 0.8 | 0.1 |
| subsample | 0.2 | 0.75 |
| boosting | gbdt | dart |
| Score(auc) | 0.8256 | 0.8605 |
总结
长话短说,本博客您了解到:
- lightgbm的主要参数是什么
- 如何使用 feval 函数创建自定义指标
- 主要参数的默认值是多少
- 看到了如何调整 lightgbm 参数以提高模型性能的示例
相关文章:
最详细的LightGBM参数介绍与深入分析
前言 我使用LightGBM有一段时间了,它一直是我处理大多数表格数据问题的首选算法。它有很多强大的功能,如果你还没有看过的话,我建议你去了解一下。 但我一直对了解哪些参数对性能影响最大,以及如何调整LightGBM参数以发挥最大作用…...

blender动画制作全流程软件
blender官网下载地址 Download — blender.org Blender是一款功能强大的免费开源的3D动画制作软件。它具有广泛的功能和工具,适用于从简单的2D动画到复杂的3D渲染和特效的各种需求。 以下是Blender的一些主要特点: 建模工具:Blender提供了一…...
mac的可清除空间(时间机器)
看到这个可用82GB(458.3MB可清除) 顿时感觉清爽,之前的还是可用82GB(65GB可清除),安装个xcode都安装不上,费解半天,怎么都解决不了这个问题,就是买磁盘情理软件也解决不了…...

【深度学习】可交互讲解图神经网络GNN
在正式开始前,先找准图神经网络GNN(Graph Neural Network)的位置。 图神经网络GNN是深度学习的一个分支。 深度学习的四个分支对应了四种常见的数据格式,前馈神经网络FNN处理表格数据,表格数据可以是特征向量,卷积神经网络CNN处理…...

网工内推 | 运维工程师,软考认证优先,全额社保
01 北京中科网威信息技术有限公司 招聘岗位:运维工程师 职责描述: 1 熟悉网络安全标准,等级保护管理制度 2 负责等级保护管理制度的的企业管理要求编写; 3 熟系网络组网和相关安全产品; 4 负责用户需求挖掘、分析和…...
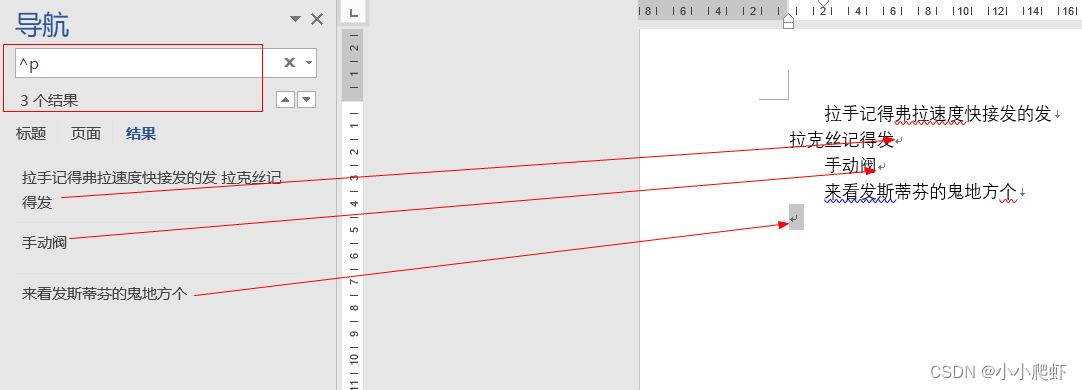
查找或替换excel换行符ctrl+j和word中的换行符^p,^l
一、excel中 直接上图。使用ctrlh调出替换,查找内容里按ctrlj(会出现一个闪的小点),即为换行符。 二、word中 在word中,^p和^l分别代表换行符(enter)和手动换行符(使用shiftenter&…...

pytorch_神经网络构建5
文章目录 生成对抗网络自动编码器变分自动编码器重参数GANS自动编码器变分自动编码器gans网络Least Squares GANDeep Convolutional GANs 生成对抗网络 这起源于一种思想,假如有一个生成器,从原始图片那里学习东西,一个判别器来判别图片是真实的还是生成的, 假如生成的东西能以…...
)
安卓常见设计模式5------桥接模式(Kotlin版)
1. W1 是什么,什么是桥接模式? 桥接模式是一种结构性模式。 桥接模式旨在将抽象与实现解耦,使它们可以独立地变化。可以这么理解,面向对象编程是单继承多实现的,如果我们有一个可扩展类,和多个相关的可扩展…...

tomcat web.xml文件中的session-config
<session-config>这个元素为该应用中创建的所有session定义默认超时时间,单位是分钟。这个值必须是整数。如果是0或者负数,表示不超时。如果该元素没有设置,容器设置一个默认值。 例如: <session-config><session…...
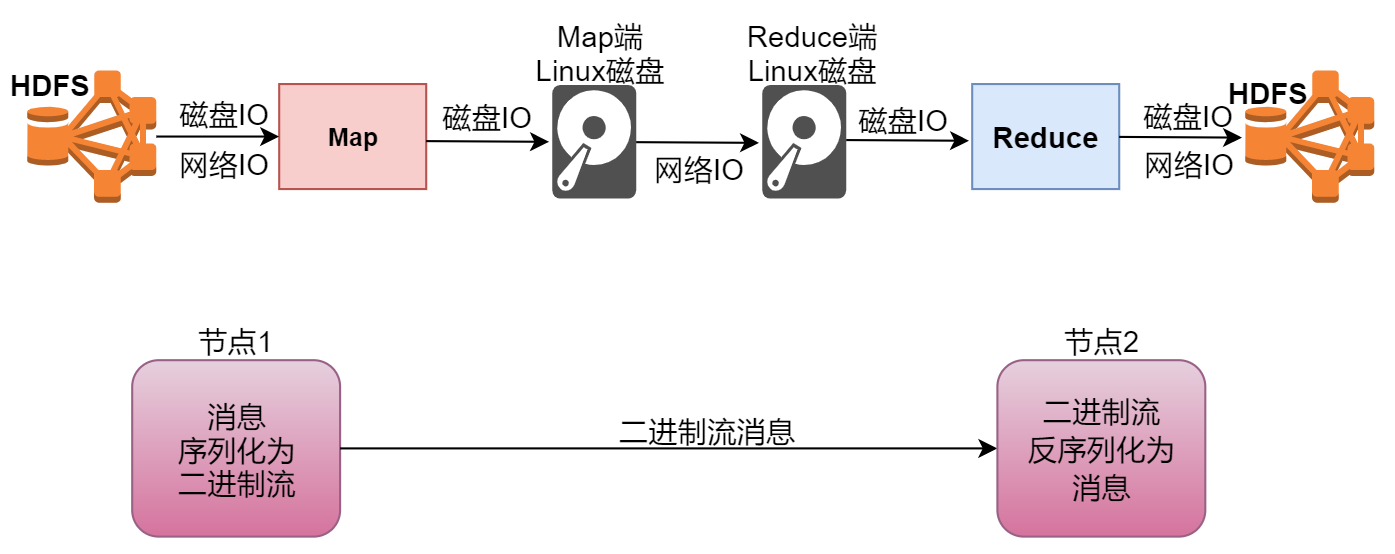
Hadoop知识点全面总结
文章目录 什么是HadoopHadoop发行版介绍Hadoop版本演变历史Hadoop3.x的细节优化Hadoop三大核心组件介绍HDFS体系结构NameNode介绍总结 SecondaryNameNode介绍DataNode介绍DataNode总结 MapReduce介绍分布式计算介绍MapReduce原理剖析MapReduce之Map阶段MapReduce之Reduce阶段 实…...
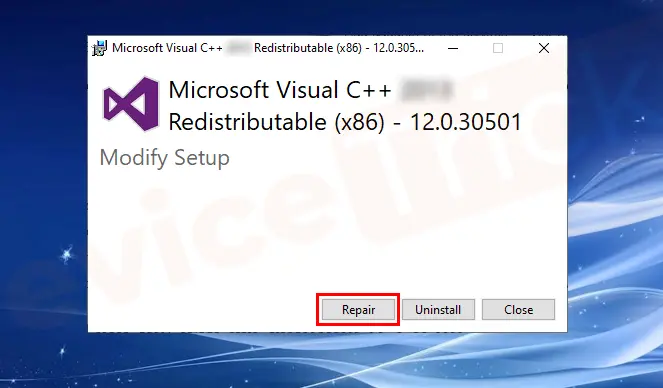
MSVCP140_CODECVT_IDS.dll丢失怎么办?推荐三个解决方法帮你解决
MSVCP140_CODECVT_IDS.dll是Microsoft Visual C 2015 Redistributable的一个组件,它包含了一些运行时库文件。当您在运行某些程序时,可能会遇到“msvcp140_codecvt_ids.dll丢失”的错误提示。为了解决这个问题,您可以尝试以下三种方法&#x…...
问题描述:64位计算机的寻址能力是多少TB
问题描述:64位计算机的寻址能力是多少TB 我在看到一个32位电脑的寻址能力计算时,看到是这么计算的。 虚拟内存的大小受到计算机地址位数的限制, 那么32位电脑的寻址能力计算应该是这样 为什么网上百度到的是16TB呢,如下图所示 中…...

【算法 | 数论 No.1】AcWing1246. 等差数列
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【AcWing算法提高学习专栏】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程&a…...
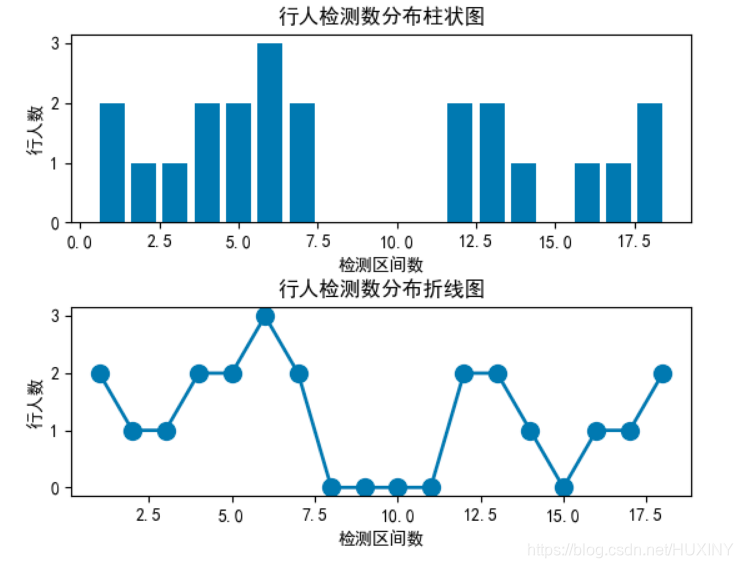
竞赛 目标检测-行人车辆检测流量计数
文章目录 前言1\. 目标检测概况1.1 什么是目标检测?1.2 发展阶段 2\. 行人检测2.1 行人检测简介2.2 行人检测技术难点2.3 行人检测实现效果2.4 关键代码-训练过程 最后 前言 🔥 优质竞赛项目系列,今天要分享的是 行人车辆目标检测计数系统 …...

秋招进入尾声了,还有哪些公司和岗位可以投递?
24届秋招基本已经进入尾声了,接下来就是秋招补录了,最近在微信群看到一些同学再问哪些公司还在招人的。 在这里跟大家分享一份2024届秋招信息汇总表,目前已更新2000家,不仅有互联网公司,还有外企、国企、各类研究所&am…...

CSS 文字溢出省略号显示
1. 单行文本溢出显示省略号 需要满足三个条件,添加对应的代码: (1)先强制一行内显示文本; (2)超出的部分隐藏; (3)文字用省略号来替代省略的部分…...

POD创建与删除简单描述
创建一个 Pod 的过程可以分为以下几个步骤: 用户使用 kubectl create 命令或 YAML 文件向 API 服务器发送创建 Pod 的请求。API 服务器将请求转换为 Kubernetes 的内部对象,并将 Pod 的状态设置为 Pending。调度器根据 Pod 的资源需求和节点的资源情况&…...
)
AndroidStudio打包报错记录(commons-logging,keystore password was incorrect)
场景: AndroidStudio2022打包APK的时报错 1.commons-logging依赖冲突 报错主要信息如下 Error: commons-logging defines classes that conflict with classes now provided by Android. 通过报错信息可以看出,项目中的commons-logging与Android系统自带…...

如何构建企业数据资产?数据资产如何入资产负债表 ?
一、构建企业数据资产 1. 数据收集 需要从多渠道收集数据,包括企业内部系统、市场调研、社交媒体、客户反馈等。在收集数据时,需要注意数据的真实性、完整性和可靠性。同时,需要考虑如何将不同渠道的数据进行整合和标准化,以便后…...

代码随想录算法训练营Day 47 || 198.打家劫舍、213.打家劫舍II、337.打家劫舍 III
198.打家劫舍 力扣题目链接(opens new window) 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系…...
)
别再被cout坑了!C++浮点数输出精度控制保姆级教程(含fixed/unsetf用法)
别再被cout坑了!C浮点数输出精度控制保姆级教程 刚接触C时,你一定遇到过这样的场景:计算好的金额12.3456在输出时变成了12.3457,或者科学计算中的0.0000123456莫名其妙显示为1.23456e-05。这不是你的代码有问题,而是co…...

如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定!
如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定! 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否曾经想重温经典的Flash游戏,却发现现…...

5分钟实战指南:如何让微信网页版在Chrome、Edge和Firefox中重新可用
5分钟实战指南:如何让微信网页版在Chrome、Edge和Firefox中重新可用 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无法…...

LinkSwift:3分钟快速上手,免费解锁八大网盘高速下载终极方案
LinkSwift:3分钟快速上手,免费解锁八大网盘高速下载终极方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中…...

以练代学:用竞赛真题学算法——暴力
先上题目,出自蓝桥杯省赛真题题目描述四平方和定理,又称为拉格朗日定理:每个正整数都可以表示为至多 4 个正整数的平方和。如果把 0 包括进去,就正好可以表示为 4 个数的平方和。比如:5 0 0 1 27 1 1 1 2对于一…...

为什么说 2026 年,是企业 AI Agent 落地的关键一年?——从工具到执行,深度解析 2026 数字化分水岭下的实在Agent技术解决方案
2026年,全球企业数字化转型正式进入“智能执行”的深水区。 与过去两年大模型侧重于“对话”和“生成”不同, 今年的核心命题在于:如何让AI从一个“聊天机器人” 进化为能够自主规划、调用工具并完成复杂业务闭环的AI Agent(智能体…...
脉冲压缩系统)
从MATLAB仿真到FPGA实现:手把手搭建线性调频(LFM)脉冲压缩系统
从MATLAB仿真到FPGA实现:手把手搭建线性调频(LFM)脉冲压缩系统 雷达系统的核心挑战之一是如何在保持高距离分辨率的同时实现远距离探测。传统脉冲雷达面临一个根本性矛盾:缩短脉冲宽度可以提高分辨率,但会降低探测距离…...

**发散创新:基于角色权限模型的动态访问控制实现与实战优化**在现代软件系统中
发散创新:基于角色权限模型的动态访问控制实现与实战优化 在现代软件系统中,权限管理已不再是简单的“用户-角色-资源”映射,而是需要支持细粒度、可配置、高扩展性的动态访问控制机制。本文以 Python Flask RBAC(基于角色的访问…...

倾斜光栅的参数优化及公差分析
摘要 对于背光系统、光内连器和近眼显示器等许多应用来说,将光高效地耦合到引导结构中是一个重要的问题。对于这种应用,倾斜光栅以能够高效地耦合单色光而闻名。在本例中,提出了利用严格傅里叶模态方法(FMM,也称为RCWA…...
)
保姆级教程:用PyTorch 2.0复现WDCNN轴承故障诊断模型(附CWRU数据集实战代码)
从零实现WDCNN轴承故障诊断:PyTorch 2.0实战指南 轴承作为机械设备的核心部件,其健康状态直接影响整个系统的运行安全。传统故障诊断方法依赖专家经验,而深度学习技术让自动化诊断成为可能。WDCNN(Wide Deep Convolutional Neural…...