Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4)

文章目录
- Abstract
- Introduction
- 引入问题
- 1) Sample level imbalance
- 2) Feature level imbalance
- 3) Objective level imbalance
- 进行解决
- 贡献
- Related Work(他人的work,捎带与我们的对比)
- Model architectures for object detection(跳)
- Balanced learning for object detection
- Sample level imbalance
- Feature level imbalance
- Objective level imbalance
- Methodology
- IoU-balanced Sampling
- Balanced Feature Pyramid
- Obtaining balanced semantic features
- Refining balanced semantic features
- Balanced L1 Loss
- Experiments
- 数据集和评估指标
- 实现细节
- 主要成果与思考
- 消融实验
- Conclusion
论文链接
源代码
Abstract
与模型架构相比,训练过程在目标检测中受到的关注相对较少,而训练过程也是检测器成功的关键。在这项工作中,我们仔细地回顾了检测器的标准训练实践,发现检测性能往往受到训练过程中不平衡的限制,这种不平衡通常包括三个层面——样本层面、特征层面和目标层面。为了减轻由此带来的不利影响,我们提出了Libra R-CNN,这是一个简单但有效的平衡学习框架,用于目标检测。它集成了三个新颖的组件:IoU平衡采样、平衡特征金字塔和平衡L1损耗,分别用于减少样本、特征和客观层面的不平衡
得益于整体平衡设计,Libra R-CNN显著提高了检测性能。在MSCOCO上,它的平均精度(AP)比FPN Faster R-CNN和RetinaNet分别高出2.5和2.0
Introduction
引入问题
现代检测框架大多遵循共同的训练范式,即采样区域,从中提取特征,然后在标准多任务目标函数的指导下共同识别类别并精炼位置
基于这一范式,目标检测器训练的成功取决于三个关键方面:
(1)所选区域样本是否具有代表性
(2)提取的视觉特征是否得到充分利用
(3)设计的目标函数是否最优
不平衡包括(a)样本水平(b)特征水平和©目标水平,这使得设计良好的模型架构无法得到充分利用
然而,我们的研究表明,典型的训练过程在所有这些方面都存在显著的不平衡。这种不平衡问题阻碍了设计良好的模型体系结构的能力得到充分利用,从而限制了整体性能如图1所示。下面,我们依次描述这些问题
1) Sample level imbalance
当训练一个目标检测器时,硬样本特别有价值,因为它们更有效地提高检测性能。然而,随机抽样方案往往导致被选择的样本被容易的样本所支配,因此,这个问题需要更优雅地解决
2) Feature level imbalance
骨干网中的深层高层特征具有更多的语义含义,而浅层低层特征更多的是内容描述性特征。近年来,FPN和PANet中通过横向连接进行特征集成,推动了目标检测的发展。这些方法使我们认识到,在目标检测中,低级信息和高级信息是相辅相成的,如何利用它们来整合金字塔表示的方法决定了检测性能。
但是,将它们集成在一起的最佳方法是什么?我们的研究表明,综合特征应该具有平衡每个分辨率的信息。但是,上述方法中的顺序方式会使集成特征更多地关注相邻分辨率,而较少关注其他分辨率。在信息流中,每融合一次,包含在非相邻层次的语义信息就会被稀释一次
3) Objective level imbalance
检测器需要完成两项任务,即分类和定位。因此,两个不同的目标被纳入了培训目标,如果它们没有得到适当的平衡,一个目标可能会受到损害,从而导致整体性能不理想。在训练过程中涉及的样本也是如此。如果它们没有得到适当的平衡,容易的样品产生的小梯度可能会淹没在困难的样品产生的大梯度中,从而限制了它们的细化。因此,我们需要重新平衡所涉及的任务和样本,以达到最优收敛
进行解决
为了减轻这些问题造成的不利影响,我们提出了Libra R-CNN,这是一个简单但有效的目标检测框架,可以明确地在上述三个级别强制执行平衡,该框架集成了三个新组件:
(1) IoU平衡取样法,即根据硬样品的IoU和指定的地面真值进行开采
(2)平衡特征金字塔,利用同一深度集成的平衡语义特征加强多层次特征
(3)平衡L1损失,促进关键梯度,平衡所涉及的分类、整体定位和准确定位
在MS COCO[21]上,Libra R-CNN的平均精度(AP)比FPN Faster R-CNN和RetinaNet分别高出2.5分和2.0分。在[9]的1倍调度下,Libra R-CNN使用基于ResNet-50和ResNeXt-101-64x4d的FPN Faster R-CNN分别可以获得38.7和43.0 AP
贡献
我们总结了我们的主要贡献
(1)我们系统地回顾了检测器的训练过程。我们的研究揭示了三个层次上的不平衡问题限制了检测性能
(2)我们提出了Libra R- CNN框架,该框架通过结合三个新的组件来重新平衡训练过程:IoU平衡采样、平衡特征金字塔和平衡L1损失
(3)我们在MSCOCO上测试了提议的框架,不断获得比最先进的探测器(包括单阶段和两阶段探测器)的显著改进
Related Work(他人的work,捎带与我们的对比)
Model architectures for object detection(跳)
近年来,目标检测得到了两级检测器和单级检测器的推广。两阶段检测器最早是由R-CNN推出的。逐步衍生的SPP[11]、Fast R-CNN[7]和Faster R-CNN[28]进一步促进了发展。Faster R-CNN提出了区域生成网络,以提高检测器的效率,并允许检测器端到端进行训练。在这个有意义的里程碑之后,从不同的角度引入了许多方法来增强Faster R-CNN
另一方面,单级检测器被YOLO和SSD推广。它们比两级探测器更简单、更快,但在引入视网膜网[20]之前,其准确性一直落后。CornetNet[18]引入了一个见解,即边界框可以作为一对关键点来预测。其他方法侧重于级联过程[24]、重复去除[14,13]、多尺度[2,1,31,30]、对抗学习[37]和更多情境[36]。他们都从不同的方面取得了重大进展
Balanced learning for object detection
缓解目标检测训练过程中的不平衡是实现最优训练和充分挖掘模型架构潜力的关键
Sample level imbalance
OHEM和focal loss是目前针对目标检测中样本水平不平衡的主要解决方案。常用的OHEM根据其置信度自动选择硬样品。然而,这个过程会导致额外的内存和速度成本,使训练过程变得臃肿。此外,OHEM还受到噪音标签的影响,因此它不能在所有情况下都正常工作。焦损用一种优雅的损耗公式解决了单级检测器中额外的前景-背景类不平衡问题,但由于不平衡情况的不同,焦损对两级检测器通常只带来很少的增益或没有增益。与这些方法相比,我们的方法大大降低了成本,并且优雅地解决了问题
Feature level imbalance
利用多层次特征生成判别金字塔表示对检测性能至关重要。FPN提出横向连接,通过自上而下的途径丰富浅层的语义信息。之后,PANet引入了自下而上的路径,进一步增加了深层的低层信息。Kong等人([17])提出了一种基于SSD的新型高效金字塔,该金字塔以高度非线性的方式集成了特征
与这些方法不同的是,我们的方法依靠集成的平衡语义特征来增强原始特征。通过这种方式,金字塔中的每个分辨率都从其他分辨率获得连续的信息,从而平衡信息流并使特征更具判别性
Objective level imbalance
Kendall等人[16]已经证明了基于多任务学习的模型的性能强烈依赖于每个任务损失之间的相对权重。但以往的方法[28,19,20]主要关注如何增强模型架构的识别能力。最近,UnitBox[34]和IoU- Net[15]引入了一些新的与IoU相关的目标函数,以提高定位精度。与之不同的是,我们的方法重新平衡了所涉及的任务和样本,以达到更好的收敛性
Methodology
Libra R-CNN的整体流水线如图2所示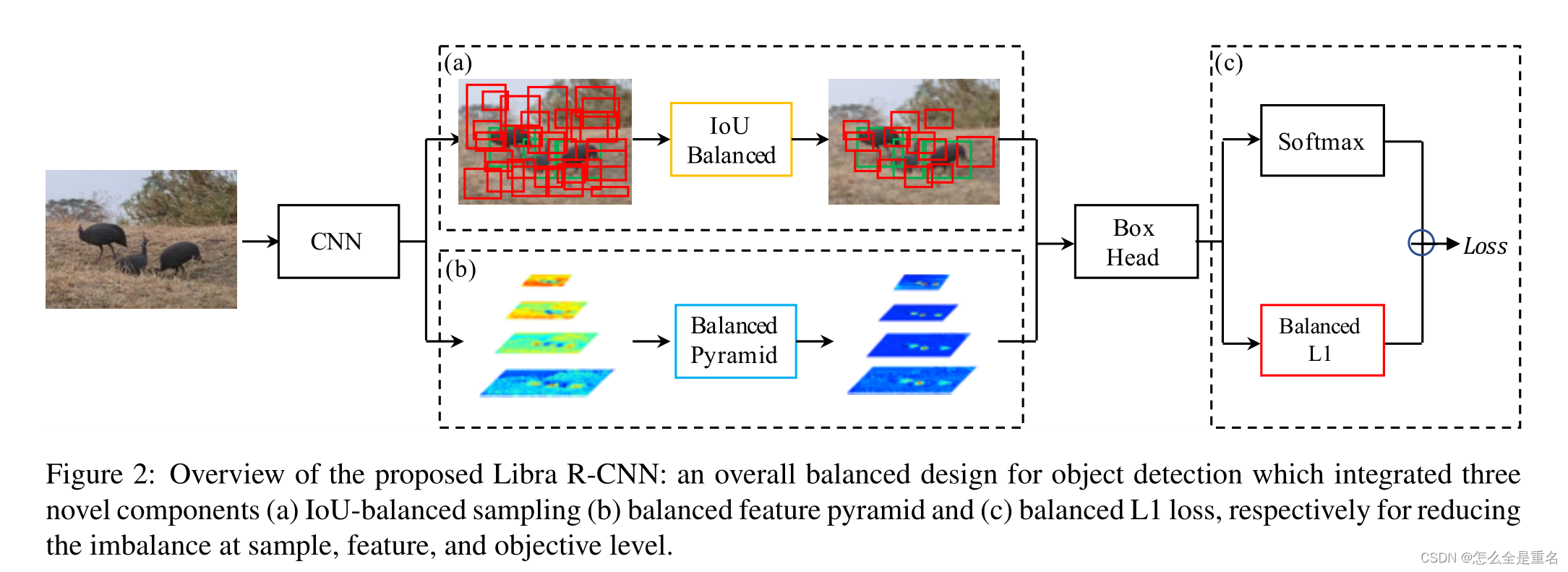
集成了三个新组件(a) iou平衡采样(b)平衡特征金字塔和©平衡L1损耗,分别用于减少样本,特征和目标水平的不平衡
我们的目标是使用整体平衡设计来缓解检测器训练过程中存在的不平衡,从而尽可能地利用模型架构的潜力
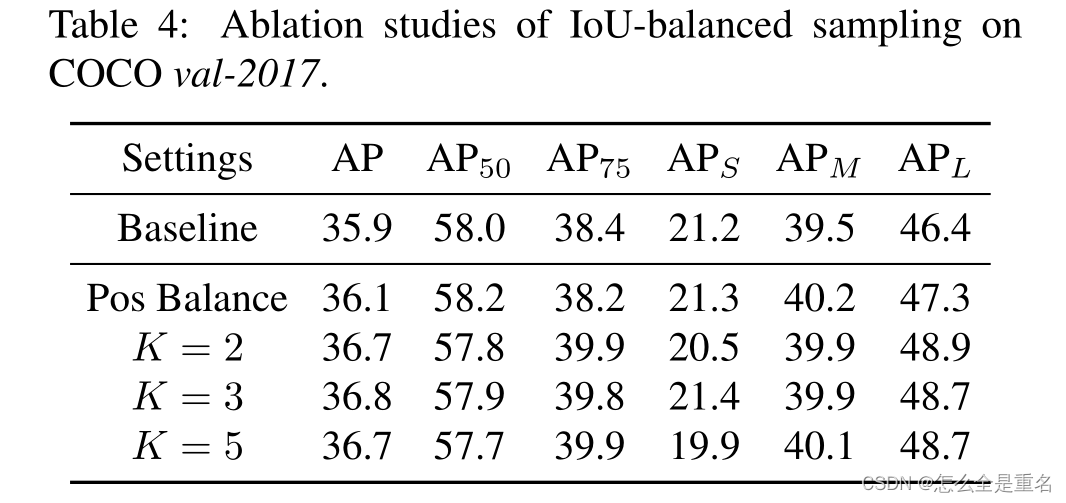
IoU-balanced Sampling
让我们从最基本的问题开始:训练样本与其相应的基础真值之间的重叠是否与其难度相关?为了回答这个问题,我们进行实验来寻找背后的真相。结果如图3所示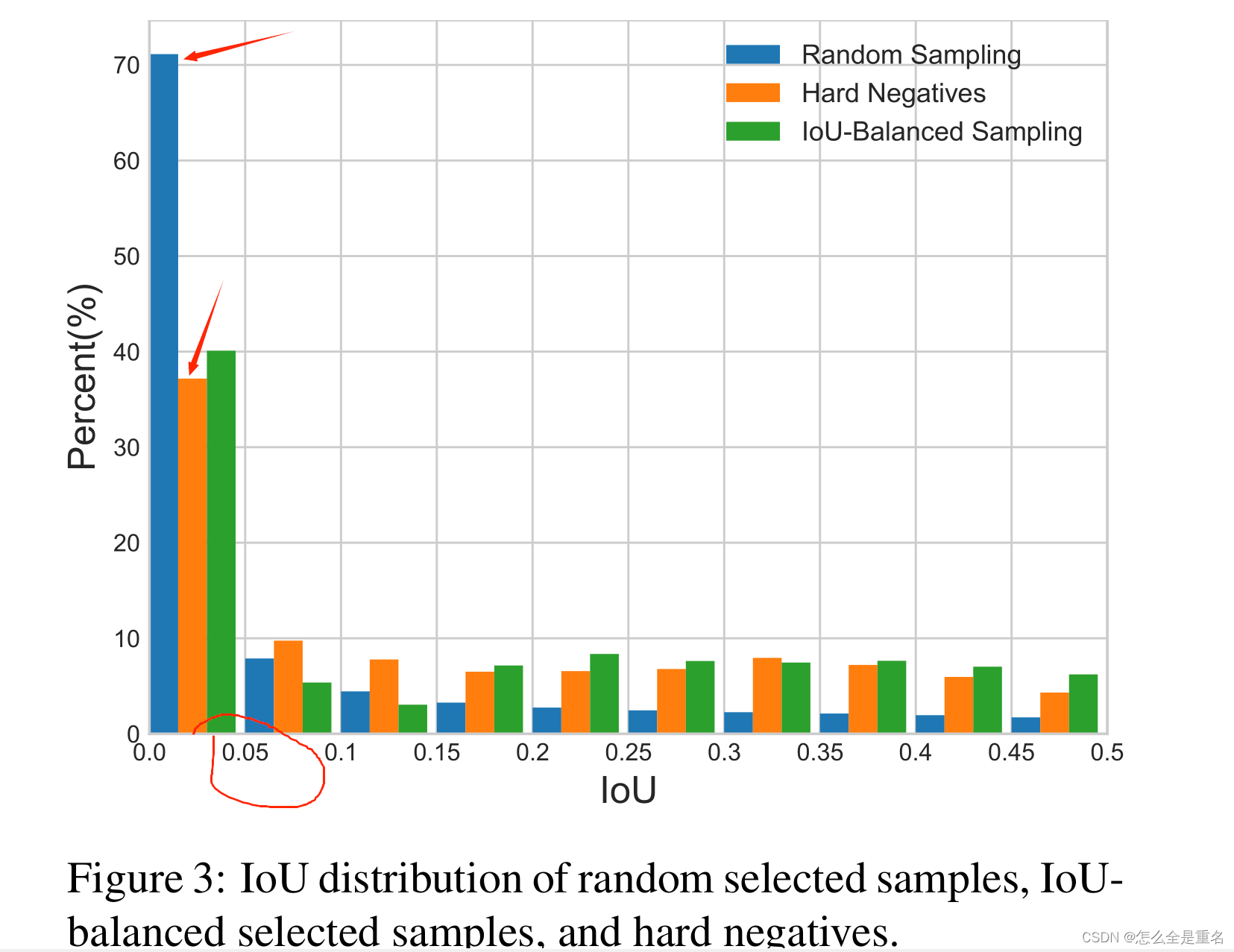
我们主要考虑困难负样本,这是已知的主要问题
我们发现超过60%的硬阴性有大于0.05的重叠,但是随机抽样只提供给我们30%大于相同阈值的训练样本。这种极端的样本不平衡将许多硬样本埋在数千个简单样本中
基于这一观察结果,我们提出了iou平衡采样:一种简单但有效的硬采矿方法,无需额外成本。假设我们需要从M个对应的候选样本中抽取N个负样本,在随机抽样下,每个样本所选择的概率为:
为了提高困难负样本的选择概率,我们根据IoU将采样间隔均匀地分成K个箱子。N个需要的负样本被均匀地分配到每个箱中。然后均匀地从中选择样本。因此,我们得到了iou平衡抽样下的选择概率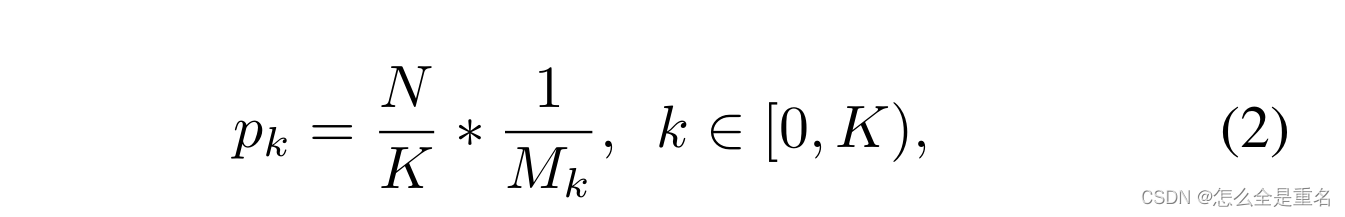
Mk为对应区间内的采样候选者个数,在我们的实验中,K默认设置为3
采用iou平衡采样的采样直方图如图3中绿色所示。可以看出,我们的iou平衡抽样可以引导训练样本的分布接近于困难负样本的分布。实验还表明,只要选择IoU较高的样品,性能对K值不敏感
此外,值得注意的是,该方法也适用于困难正样本。然而,在大多数情况下,没有足够的样本候选者将这一程序扩展到阳性样本。为了使平衡抽样过程更全面,我们为每个基础真值抽样相等的正样本作为一种替代方法
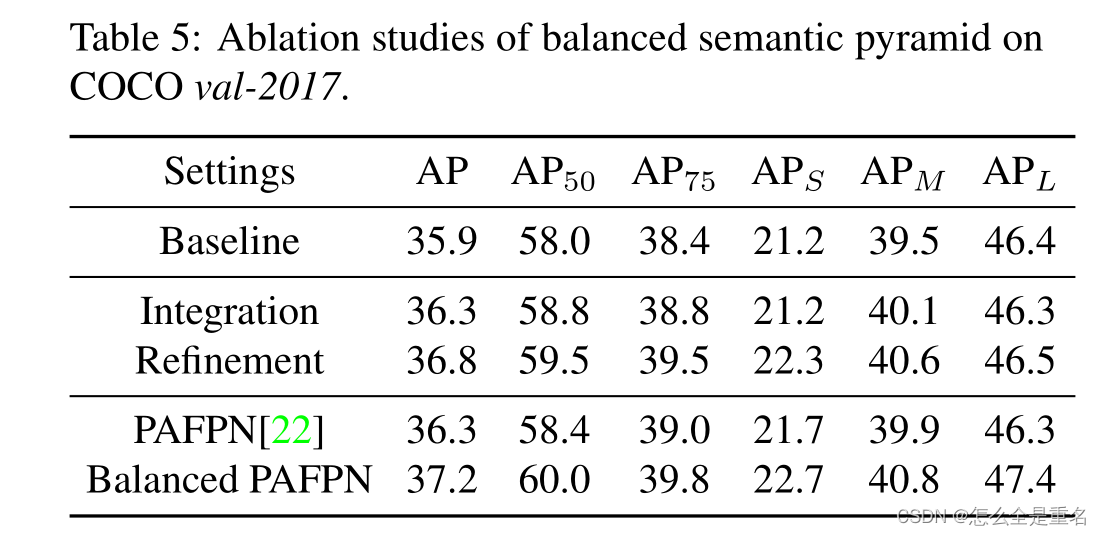
Balanced Feature Pyramid
与以前使用横向连接整合多层次特征的方法不同,我们的关键思想是使用相同的深度集成平衡语义特征来强化多层次特征。管道如图4所示。它包括rescaling、整合、精炼和强化四个步骤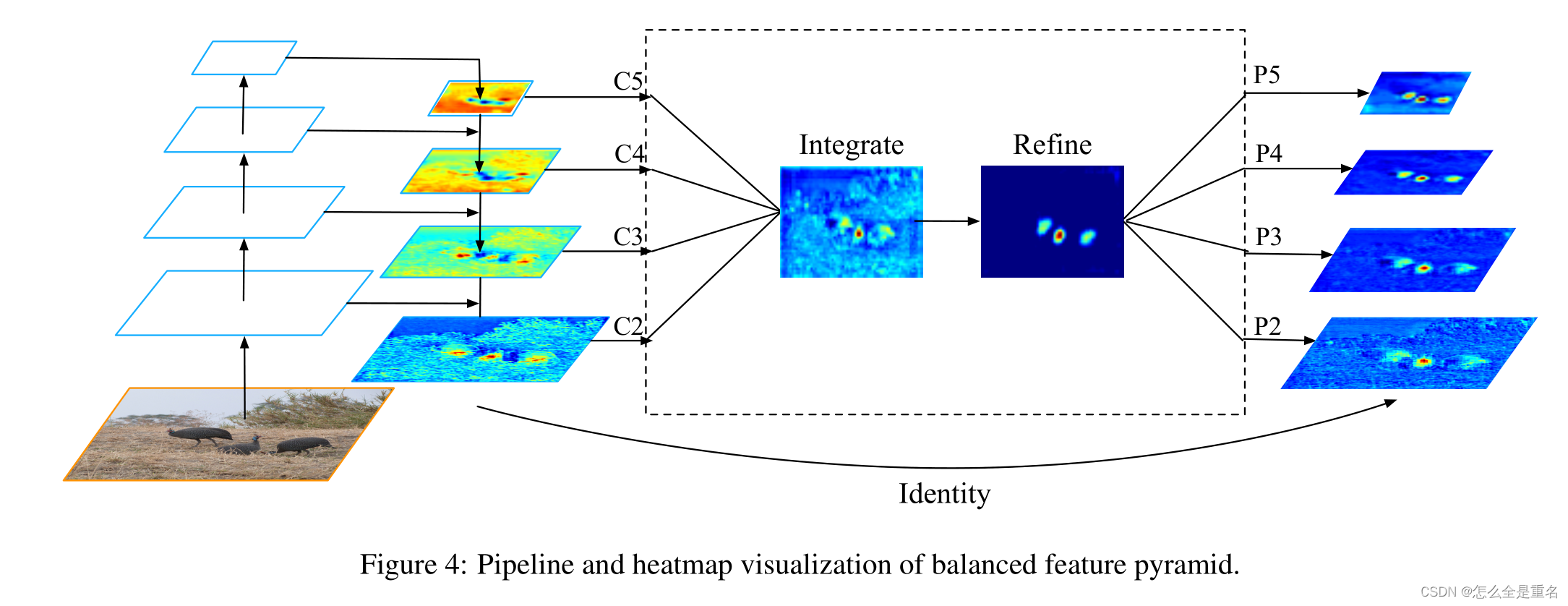
Obtaining balanced semantic features
分辨率级别为l的特征记为Cl,多层次特征的个数记为l,涉及的最低和最高层次的指标记为l min和l max。在图4中,c2具有最高的分辨率。为了整合多层次特征并同时保持它们的语义层次结构,我们首先将多层次特征{c2, c3, c4, c5}调整到一个中等大小,即与c4大小相同,分别使用插值和最大池化。一旦特征被重新缩放,通过简单的平均得到平衡的语义特征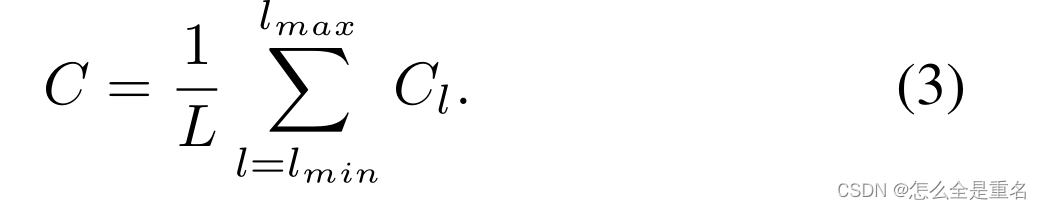
然后使用相同但相反的过程重新缩放获得的特征以增强原始特征。在这个过程中,每个决议从其他决议获得相等的信息。注意,这个过程不包含任何参数。我们观察到这种非参数方法的改进,证明了信息流的有效性
Refining balanced semantic features
平衡的语义特征可以进一步细化,使其更具有辨别力。我们发现直接卷积的改进和非局部模块[32]都能很好地工作。但非本地模块工作更稳定。因此,我们在本文中使用嵌入的高斯非局部注意作为默认值。细化步骤有助于我们增强集成功能,进一步改善结果
利用该方法,可以同时对从低级到高级的特征进行聚合。输出{p2, p3, p1, p5}用于对象检测,遵循FPN中的相同管道。值得一提的是,我们的平衡特征金字塔可以与最近的解决方案(如FPN和PAFPN)互补,而不会产生任何冲突
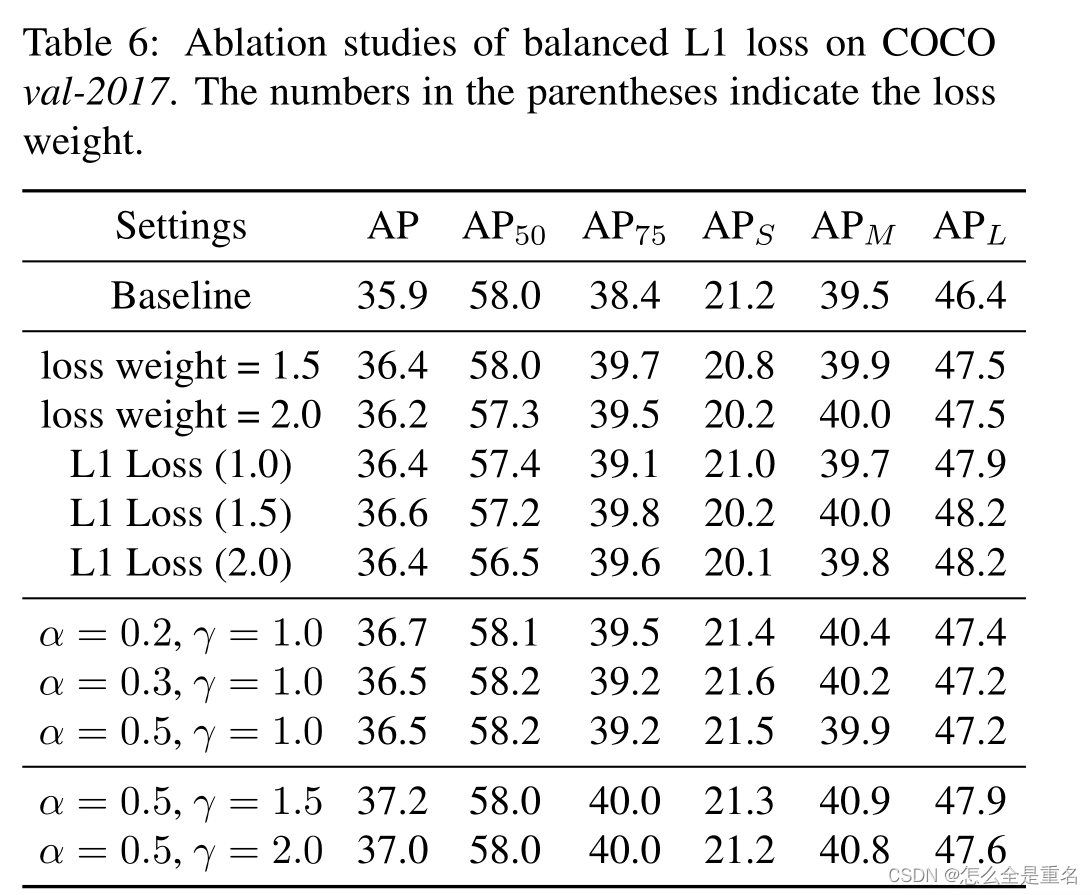
Balanced L1 Loss
自Fast R-CNN[以来,在多任务损失的指导下,分类和定位问题同时解决,定义为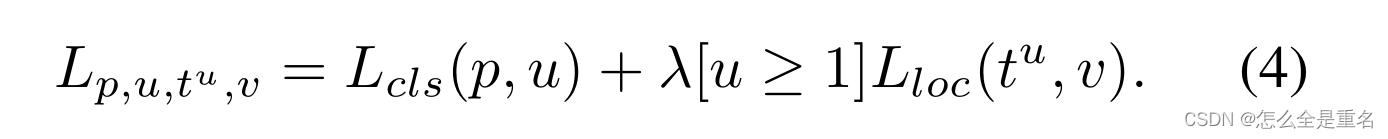
L cls和L loc分别是对应于识别和定位的目标函数,L类中的预测和目标分别记为p和u,其中u为与u类对应的回归结果,v为回归目标。λ用于调整多任务学习下的损失权重。我们称损失大于或等于1.0的样本为异常值。其他样本称为内层
我们提出平衡L1损失,记为Lb
平衡L1 loss来源于传统的smooth L1 loss,其中设置一个拐点来分隔内线和轮廓线,并截取离群点产生的大梯度,最大值为1.0,如图5-(a)中的虚线所示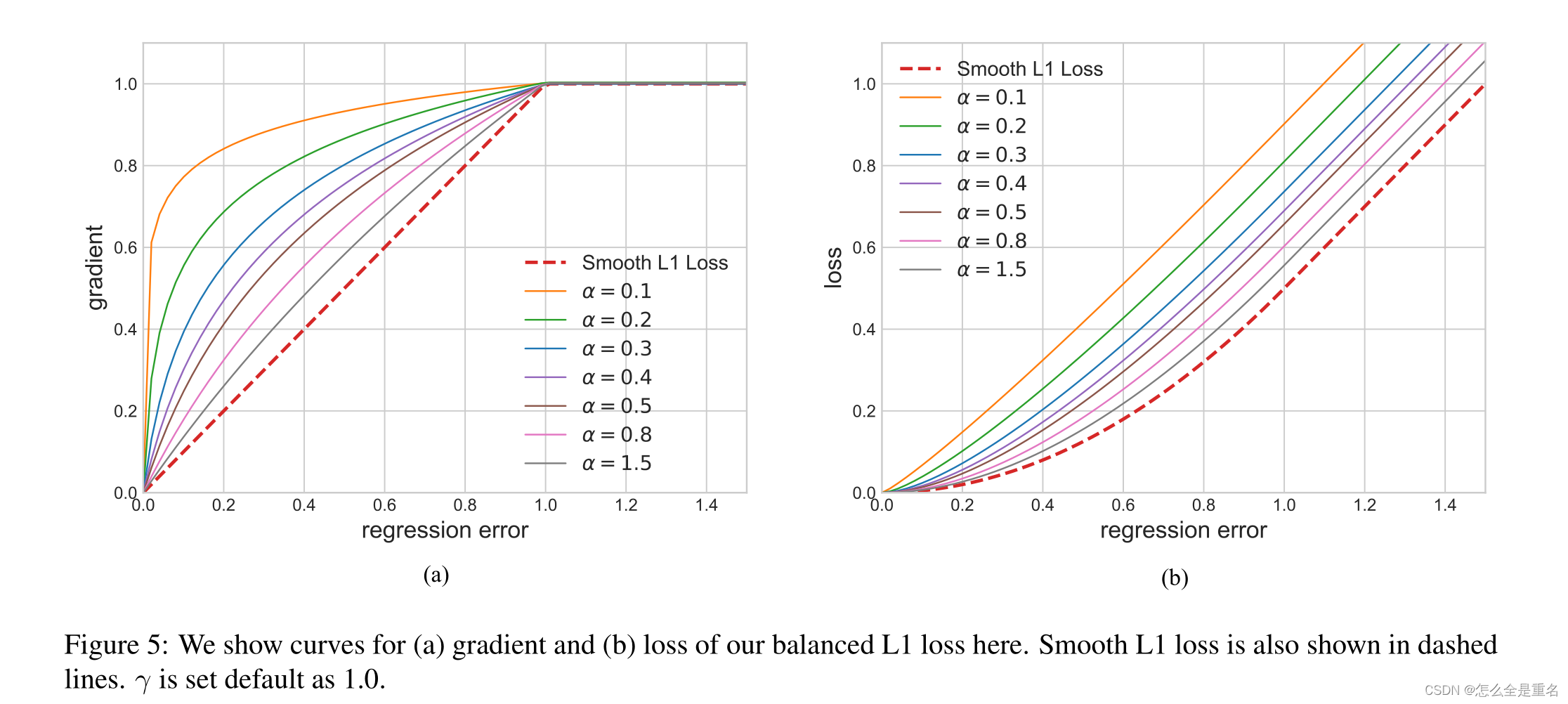
平衡L1损失的关键思想是促进关键的回归梯度,即来自内层(准确样本)的梯度,重新平衡所涉及的样本和任务,从而实现分类、整体定位和精确定位内更平衡的训练。局域化损耗L loc使用平衡L1损耗定义为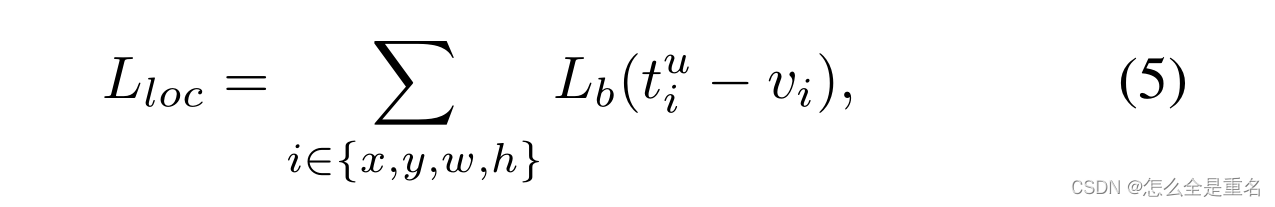
其相应的梯度公式如下
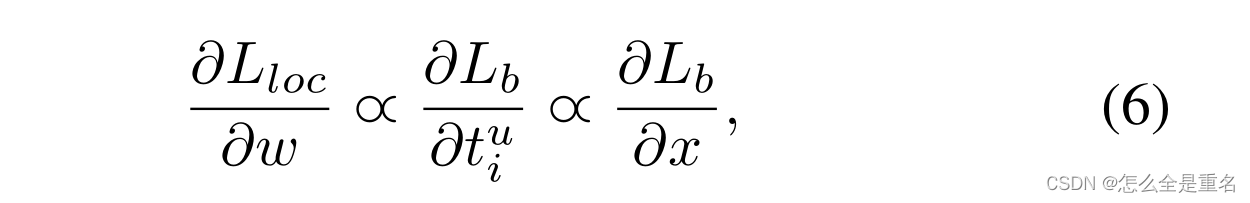
基于上述公式,我们设计了一个改进的梯度公式为
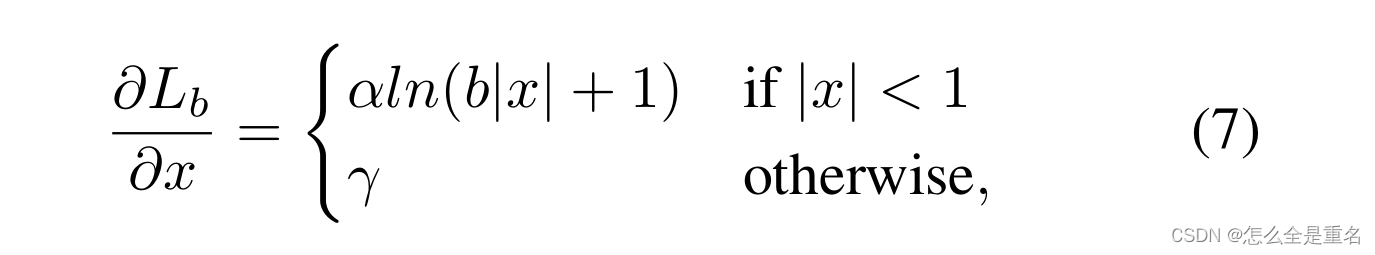
图5-(a)显示,在一个因子α的控制下,我们的平衡L1损耗增加了内层的梯度。小的α增加了内值的梯度,但离群值的梯度不受影响。此外,还引入了由γ控制的整体提升放大倍数来调节回归误差的上界,使目标函数更好地平衡所涉及的任务。控制不同方面的两个因素相互增强,达到更平衡的训练,b用于确保L b (x = 1)对于式(8)中的两个公式具有相同的值
通过对上面的梯度公式积分,我们可以得到平衡的L1 loss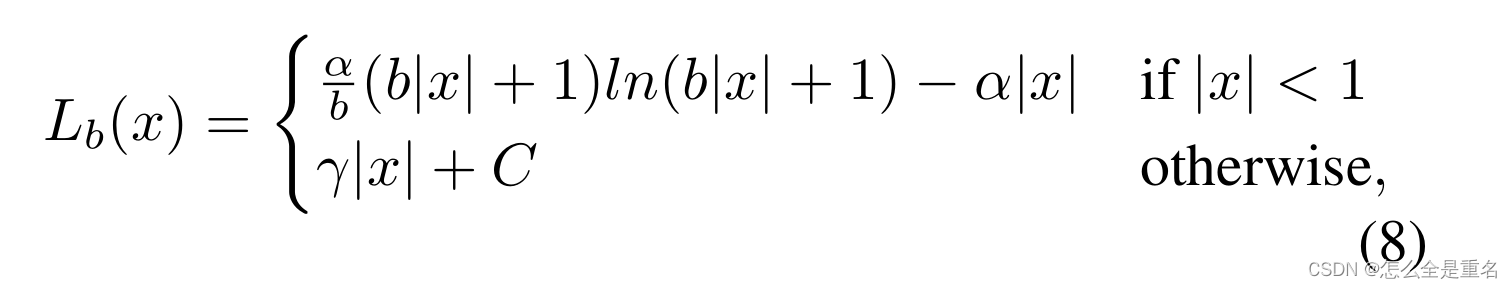
其中,参数γ, α和b受到约束
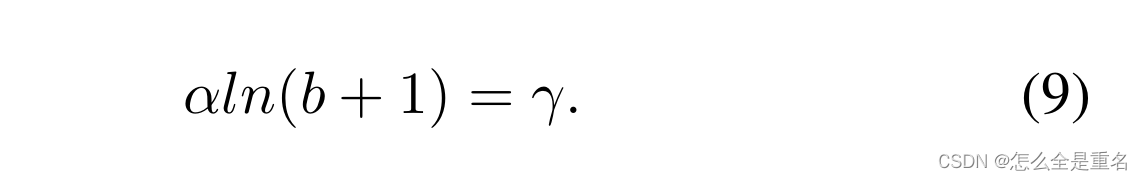
在我们的实验中,默认参数设置为α = 0.5和γ = 1.5
Experiments
数据集和评估指标
实现细节
主要成果与思考
通过整体均衡设计,Libra R-CNN在ResNet-50下达到38.7 AP,比FPN Faster R-CNN高出2.5个AP。与ResNeXt-101-64x4d(一个更强大的特征提取器)Libra R-CNN实现43.0 AP,在没有附加功能的情况下,Libra RetinaNet的ResNet-50 AP提高了2.0,达到37.8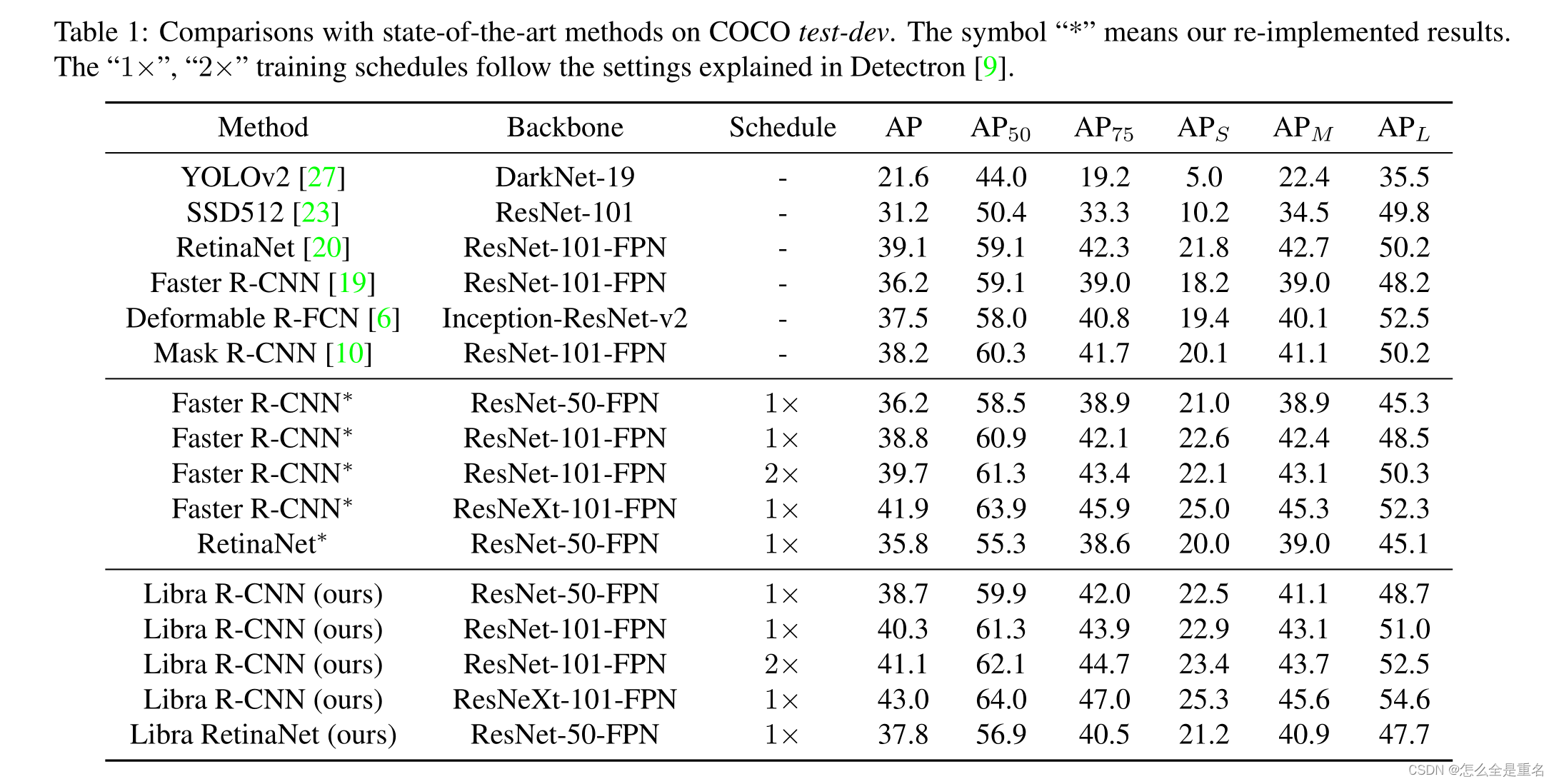


消融实验
Conclusion
在本文中,我们系统地回顾了检测器的训练过程,并发现由于训练过程中存在的不平衡问题,模型体系结构的潜力没有得到充分利用
借助简单而有效的成分,即IoU平衡采样、平衡特征金字塔和平衡L1损失,Libra R-CNN在具有挑战性的MS COCO数据集上带来了显著的改进。大量实验表明,Libra R-CNN可以很好地推广到两阶段检测器和单阶段检测器的各种backbone
相关文章:
Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4)
文章目录 AbstractIntroduction引入问题1) Sample level imbalance2) Feature level imbalance3) Objective level imbalance进行解决贡献 Related Work(他人的work,捎带与我们的对比)Model architectures for object detection&a…...
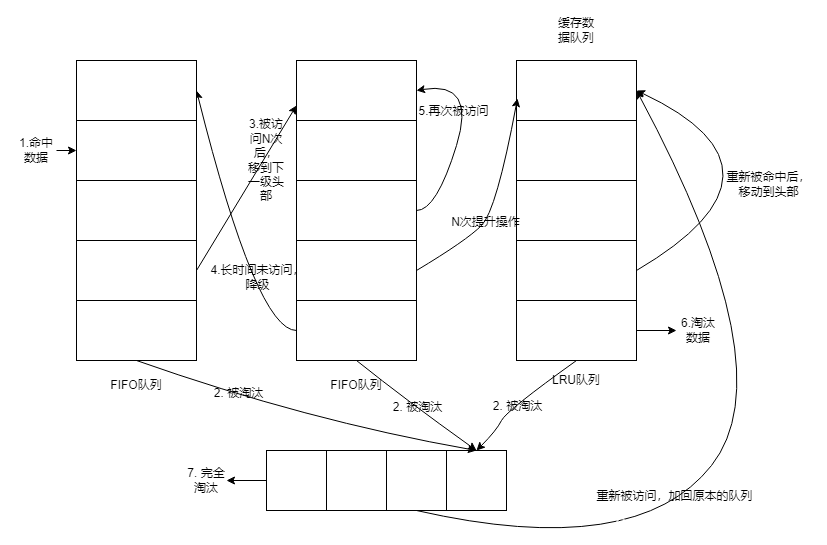
Redis的内存淘汰策略分析
概念 LRU 是按访问时间排序,发生淘汰的时候,把访问时间最久的淘汰掉。LFU 是按频次排序,一个数据被访问过,把它的频次 1,发生淘汰的时候,把频次低的淘汰掉。 几种LRU策略 以下集中LRU测率网上有很多&am…...

git命令之遭遇 ignore罕见问题解决
我先来讲讲背景 我的一些文件在ignore了,不会被提交到远程仓库,这时候我的远程仓库中是没有这几个文件的,这时候我如果使用 git reset 的话这时候除了那几个 ignore 的文件以外都被更新的,但是如果我不需要这几个被 ignore 的文件…...

torch DDP多卡训练教程记录
参考 简明教程看这里 --> pytorch分布式训练 和这篇: [PyTorch]> DDP系列第一篇:入门教程 --》 详细解答了pipeline DDP原理篇 --> DDP系列第二篇:实现原理与源代码解析 --》 主要讲 all_reduce 和 sample 的实现 减少GPU占用看这里…...
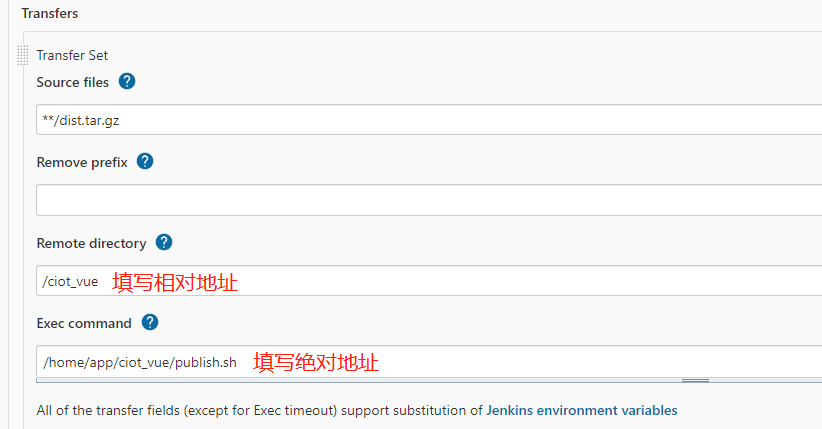
Jenkins CICD过程常见异常
1 Status [126] Exception when publishing, exception message [Exec exit status not zero. Status [126] 1.1 报错日志 SSH: EXEC: STDOUT/STDERR from command [/app/***/publish.sh] ... bash: /app/***/publish.sh: Permission denied SSH: EXEC: completed after 200…...

Java11新增特性
前言 在前面的文章中,我们已经介绍了 Java9的新增特性 和 Java10的新增特性 ,下面我们书接上文,来介绍一下Java11的新增特性 版本简介 Java 11 是 Java 平台的最新版本,于2018年9月25日发布。这个版本是自Java 8以来最重要的更新之一&…...
)
安卓常见设计模式13------过滤器模式(Kotlin版)
W1 是什么,什么是过滤器模式? 过滤器模式(Filter Pattern)是一种常用的结构型设计模式,用于根据特定条件过滤和筛选数据。 2. W2 为什么,为什么需要使用过滤器模式,能给我们编码带来什么好处…...

使用spark进行递归的可行方案
在实际工作中会遇到,最近有需求将产品炸开bom到底层,但是ERP中bom数据在一张表中递归存储的,不循环展开,是无法知道最底层原材料是什么。 在ERP中使用pl/sql甚至sql是可以进行炸BOM的,但是怎么使用spark展开࿰…...
Spring -Spring之依赖注入源码解析(下)--实践(流程图)
IOC依赖注入流程图 注入的顺序及优先级:type-->Qualifier-->Primary-->PriOriry-->name...

前端设计模式之【单例模式】
文章目录 前言介绍实现单例模式优缺点?后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出…...

设备零部件更换ar远程指导系统加强培训效果
随着科技的发展,AR技术已经成为了一种广泛应用的新型技术。AR远程指导系统作为AR技术的一种应用,具有非常广泛的应用前景。 一、应用场景 气象监测AR教学软件适用于多个领域,包括气象、环境、地理等。在教学过程中,软件可以帮助学…...

文本生成高精准3D模型,北京智源AI研究院等出品—3D-GPT
北京智源AI研究院、牛津大学、澳大利亚国立大学联合发布了一项研究—3D-GPT,通过文本问答方式就能创建高精准3D模型。 据悉,3D-GPT使用了大语言模型的多任务推理能力,通过任务调度代理、概念化代理和建模代理三大模块,简化了3D建模的开发流程…...
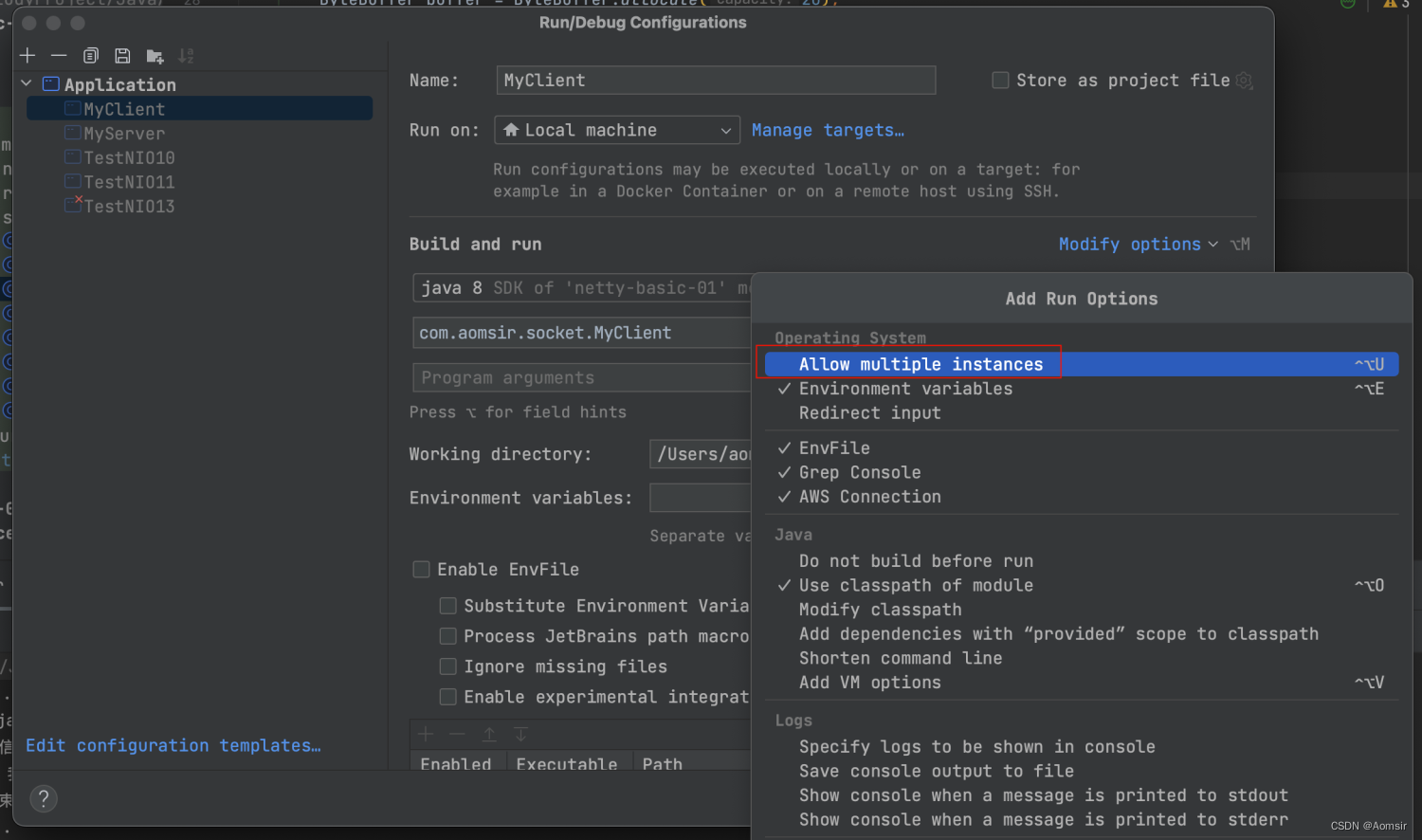
Netty入门指南之NIO 网络编程
作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者! 个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客 当前专栏:Netty应用专栏_Aomsir的博客-CSDN博客 文章目录 参考文献前言基础扫…...
LeetCode(6)轮转数组【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 189. 轮转数组 1.题目 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1…...
华为云Ascend310服务器使用
使用华为云服务器 cpu: 16vCPUs Kunpeng 920 内存:16GiB gpu:4* HUAWEI Ascend 310 cann: 20.1.rc1 操作系统:Ubuntu aarch64目的 使用该服务器进行docker镜像编译,测试模型。 已知生产环境:mindx版本为3.0.rc3&a…...
【poi导出excel模板——通过建造者模式+策略模式+函数式接口实现】
poi导出excel模板——通过建造者模式策略模式函数式接口实现 poi导出excel示例优化思路代码实现补充建造者模式策略模式 poi导出excel示例 首先我们现看一下poi如何导出excel,这里举个例子:目前想要导出一个Map<sex,List>信息,sex作为…...

自适应模糊PID控制器在热交换器温度控制中的应用
热交换器是一种常见的热能传递设备,广泛应用于各个工业领域。对热交换器温度进行有效控制具有重要意义,可以提高能源利用效率和产品质量。然而,受到热传导特性和外部环境变化等因素的影响,热交换器温度控制难度较大。本文提出一种…...
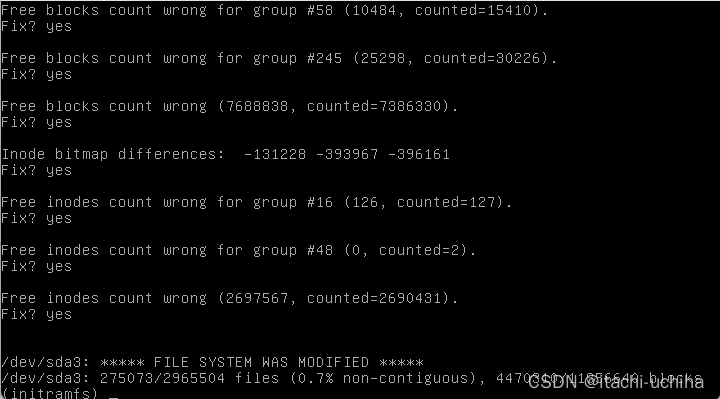
【系统救援】 Ubuntu重启失败,报错:UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY
问题定位及处理 查看错误信息:/dev/sda3 contains a file system with errors, check forced. /dev/sda3: Inodes that were part of a corrupted orphan linked list found. /dev/sda3: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY. (i.e., without -a or -p o…...
【数据结构】树与二叉树(八):二叉树的中序遍历(非递归算法NIO)
文章目录 5.2.1 二叉树二叉树性质引理5.1:二叉树中层数为i的结点至多有 2 i 2^i 2i个,其中 i ≥ 0 i \geq 0 i≥0。引理5.2:高度为k的二叉树中至多有 2 k 1 − 1 2^{k1}-1 2k1−1个结点,其中 k ≥ 0 k \geq 0 k≥0。引理5.3&…...

第九章 排序【数据结构】【精致版】
第九章 排序【数据结构】【精致版】 前言版权第九章 排序9.1 概述9.2 插入类排序9.2.1 直接插入排序**1-直接插入排序.c** 9.2.2 折半插入排序**2-折半插入排序.c** 9.2.3 希尔排序 9.3 交换类排序9.3.1冒泡排序**4-冒泡排序.c** 9.3.2 快速排序**5-快速排序.c** 9.4 选择类排…...

山东楼顶广告字技术白皮书:从选材到安装的完整实践指南
楼顶广告字的行业地位与价值在户外广告领域,山东楼顶广告字作为城市天际线的重要组成部分,不仅承担着商业宣传的功能,更成为区域经济发展的风向标。这类广告字通常安装在建筑物顶部,具有视野开阔、传播范围广的特点。随着城市建设…...

PZEM-004T v3.0 Arduino库终极指南:轻松实现精准电力监控的完整方案
PZEM-004T v3.0 Arduino库终极指南:轻松实现精准电力监控的完整方案 【免费下载链接】PZEM-004T-v30 Arduino library for the Updated PZEM-004T v3.0 Power and Energy meter 项目地址: https://gitcode.com/gh_mirrors/pz/PZEM-004T-v30 你是否曾为家庭电…...

快速免费解决B站视频无法播放问题:m4s-converter终极指南
快速免费解决B站视频无法播放问题:m4s-converter终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵…...

Display Driver Uninstaller终极指南:5分钟彻底解决显卡驱动冲突问题
Display Driver Uninstaller终极指南:5分钟彻底解决显卡驱动冲突问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driver…...

Spliit:免费开源的分摊费用神器,彻底告别AA制烦恼
Spliit:免费开源的分摊费用神器,彻底告别AA制烦恼 【免费下载链接】spliit Free and Open Source Alternative to Splitwise. Share expenses with your friends and family. 项目地址: https://gitcode.com/gh_mirrors/sp/spliit 你是否曾在朋友…...

清音听真企业部署案例:Qwen3-ASR-1.7B集成至CRM系统实现通话记录自动归档
清音听真企业部署案例:Qwen3-ASR-1.7B集成至CRM系统实现通话记录自动归档 1. 项目背景与需求分析 在现代企业客户关系管理中,通话记录是宝贵的业务资产。传统的通话记录管理方式存在几个痛点: 人工记录效率低:客服人员需要边通…...

G-Helper:重新定义华硕笔记本性能控制的轻量级革命
G-Helper:重新定义华硕笔记本性能控制的轻量级革命 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar,…...

完全掌握G-Helper:华硕笔记本终极轻量级控制中心完全指南
完全掌握G-Helper:华硕笔记本终极轻量级控制中心完全指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...

如何用RyzenAdj解锁AMD笔记本隐藏性能?实用电源管理技巧大揭秘
如何用RyzenAdj解锁AMD笔记本隐藏性能?实用电源管理技巧大揭秘 【免费下载链接】RyzenAdj Adjust power management settings for Ryzen APUs 项目地址: https://gitcode.com/gh_mirrors/ry/RyzenAdj RyzenAdj是一款专为AMD Ryzen移动处理器设计的开源电源管…...
)
手把手教你用命令行搞定ESXi主机维护模式失败(附排查清单)
命令行实战:ESXi主机维护模式失败排查全指南 引言 在虚拟化环境中,ESXi主机的维护模式是系统管理员进行硬件更换、软件升级或故障排查时的关键操作。然而,当虚拟机状态异常或DRS功能关闭时,主机可能拒绝进入维护模式,此…...