EXPLAIN详解(MySQL)
EXPLAIN概述
EXPLAIN语句提供MySQL如何执行语句的信息。EXPLAIN与SELECT, DELETE, INSERT, REPLACE和UPDATE语句一起工作。
EXPLAIN返回SELECT语句中使用的每个表的一行信息。它按照MySQL在处理语句时读取表的顺序列出了输出中的表。MySQL使用嵌套循环连接方法解析所有连接。这意味着MySQL从第一个表中读取一行,然后在第二个表、第三个表中找到匹配的行,以此类推。当处理完所有表后,MySQL输出选中的列,并回溯表列表,直到找到一个有更多匹配行的表。从这个表中读取下一行,然后继续处理下一个表。
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈。在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL。
官方文档
MySQL官网
MySQL环境
版本:mysql5.7.35
示例表
DROP TABLE IF EXISTS `role`;
CREATE TABLE `role` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of role
-- ----------------------------
INSERT INTO `role` VALUES (1, 'admin');
INSERT INTO `role` VALUES (2, 'teset');-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,`age` int(11) NULL DEFAULT NULL,`create_time` datetime NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, 'zhangsan', 24, '2023-11-10 10:42:14');
INSERT INTO `user` VALUES (2, 'wanglei', 23, '2023-11-10 10:42:32');-- ----------------------------
-- Table structure for user_role
-- ----------------------------
DROP TABLE IF EXISTS `user_role`;
CREATE TABLE `user_role` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` int(11) NOT NULL,`role_id` int(11) NOT NULL,`remark` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_user_role_id`(`user_id`, `role_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of user_role
-- ----------------------------
INSERT INTO `user_role` VALUES (1, 1, 1, NULL);
INSERT INTO `user_role` VALUES (2, 2, 2, NULL);
基本语法
EXPLAIN SELECT * FROM `user`

在查询中的每个表会输出一行,如果有两个表通过 join 连接查询,那么会输出两行。
如果我们再explain语句后马上执行一条show warnings语句,会展示mysql对上面这条sql优化后的语句,通过这个我们可以大概了解mysql给我们sql语句做的一些优化,当然mysql优化的语句不一定都能直接执行。
EXPLAIN SELECT * FROM `user`;
show warnings;

EXPLAIN 输出的列
| 列名 | 描述 |
|---|---|
| id | id列是select的序列号 |
| select_type | 查询类型 |
| table | 表名 |
| partitions | 分区信息 |
| type | 关联类型或访问类型 |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 索引字节数 |
| ref | 这一列显示了在key列记录的索引中,表查找值所用到的列或常量。 |
| rows | 预估读取的行数 |
| filtered | 估算出将要和 explain 中前一个表进行连接的行数 |
| Extra | 额外信息 |
1)id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
2)select_type列
select_type 表示对应行是简单还是复杂的查询。
simple: 简单查询。查询不包含子查询和union
EXPLAIN SELECT * FROM role WHERE id = 1

primary: 复杂查询中最外层的 select
subquery: 包含在 select 中的子查询(不在 from 子句中)
EXPLAIN SELECT *,(SELECT count(1) FROM `user`) FROM role WHERE id = 1

derived: 包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
union: 在 union 中的第二个和随后的 select
explain select 1 union all select 1;

3)table列
这一列表示 explain 的一行正在访问哪个表。
4)partitions列
如果查询是基于分区表的话,partitions 字段会显示查询将访问的分区。
5)type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL,一般来说,得保证查询达到range级别,最好达到ref。
NULL: mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表。
EXPLAIN SELECT max(id) FROM role

const、system: mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。system是const的特例,表里只有一条元组匹配时为system。
EXPLAIN SELECT * FROM `user` WHERE id = 1

eq_ref: primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在 const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
EXPLAIN SELECT * FROM user_role ur LEFT JOIN role r on r.id = ur.role_id

ref: 相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
EXPLAIN SELECT * FROM role WHERE `name` = 'admin'

range: 范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
EXPLAIN SELECT * FROM role WHERE id >3

index: 扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
EXPLAIN SELECT * FROM role

ALL: 即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
EXPLAIN SELECT * FROM `user`

6)possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
7)key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
8)key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
9)ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:user.id)
10)rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
11)filtered 列
该列是一个百分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
11)Extra列
这一列展示的是额外信息。常见的重要值如下:
Using index: 使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值。
EXPLAIN SELECT user_id FROM user_role WHERE user_id = 1

Using where: 使用 where 语句来处理结果,并且查询的列未被索引覆盖。
EXPLAIN SELECT * FROM `user` WHERE `name` = 'wanglei'

Using index condition: 查询的列不完全被索引覆盖,where条件中是一个前导列的范围。
EXPLAIN SELECT * FROM user_role WHERE user_id >3

Using temporary: mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
EXPLAIN SELECT DISTINCT `name` FROM `user`

Using filesort: 将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
EXPLAIN SELECT * FROM `user` ORDER BY `name`

Select tables optimized away: 使用某些聚合函数(比如 max、min)来访问存在索引的某个字段时。
EXPLAIN SELECT max(id) FROM `user`

相关文章:
EXPLAIN详解(MySQL)
EXPLAIN概述 EXPLAIN语句提供MySQL如何执行语句的信息。EXPLAIN与SELECT, DELETE, INSERT, REPLACE和UPDATE语句一起工作。 EXPLAIN返回SELECT语句中使用的每个表的一行信息。它按照MySQL在处理语句时读取表的顺序列出了输出中的表。MySQL使用嵌套循环连接方法解析所有连接。…...
[PyTorch][chapter 61][强化学习-免模型学习 off-policy]
前言: 蒙特卡罗的学习基本流程: Policy Evaluation : 生成动作-状态轨迹,完成价值函数的估计。 Policy Improvement: 通过价值函数估计来优化policy。 同策略(one-policy):产生 采样轨迹的策略 和要改…...

【服务器学习】 iomanager IO协程调度模块
iomanager IO协程调度模块 以下是从sylar服务器中学的,对其的复习; 参考资料 继承自协程调度器,封装了epoll,支持为socket fd注册读写事件回调函数 IO协程调度还解决了调度器在idle状态下忙等待导致CPU占用率高的问题。IO协程调…...

前端设计模式之【迭代器模式】
文章目录 前言介绍实现接口优缺点应用场景后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&a…...

Linux-用户与用户组,权限
1.用户组管理(以下命令需root用户执行) ①创建用户组 groupadd 用户组名 ②删除用户组 groupdel 用户组名 2.用户管理(以下命令需root用户执行) ①创建用户 useradd [-g -d] 用户名 >-g:指定用户的组,不…...

使用nvm-windows在Windows下轻松管理多个Node.js版本
Node.js是一个非常流行的JavaScript运行时环境,许多开发者在开发过程中可能需要在不同的Node.js版本之间进行切换。在Windows操作系统下,我们可以使用nvm-windows来轻松管理多个Node.js版本。本文将详细介绍如何安装和使用nvm-windows。 什么是nvm-wind…...

2023.11.10 hadoop,hive框架概念,基础组件
目录 分布式和集群的概念: hadoop架构的三大组件:Hdfs,MapReduce,Yarn 1.hdfs 分布式文件存储系统 Hadoop Distributed File System 2.MapReduce 分布式计算框架 3.Yarn 资源调度管理框架 三个组件的依赖关系是: hive数据仓库处理工具 hive的大体流程: Apache hive的…...
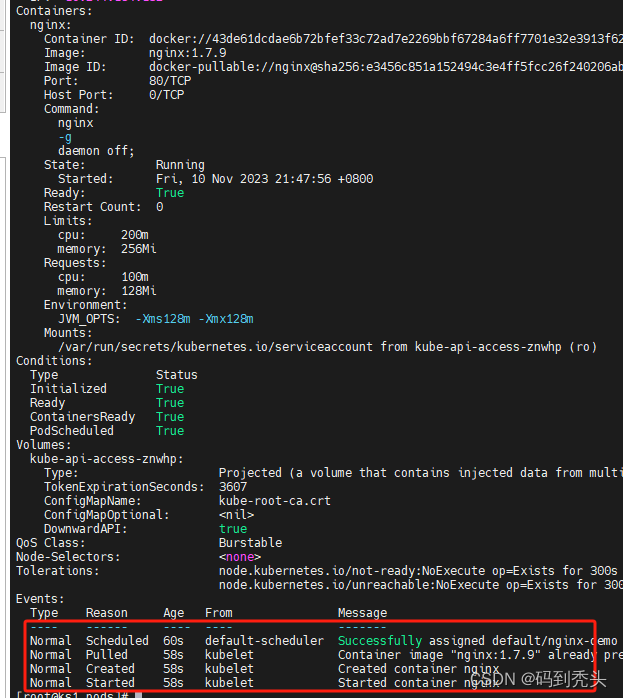
Kubernetes 创建pod的yaml文件-简单版-nginx
apiVersion: v1 #api文档版本 kind: Pod # 资源类型 Deployment,StatefulSet之类 metadata: #pod元数据 描述信息 name: nginx-demo labels: type: app #自定义标签 version: 1.0.0 # 自定义pod版本 namespace: default spec: #期望Pod按照这里的描述创建 cont…...
Git的进阶操作,在idea中部署gie
🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《git》。🎯🎯 🚀无论你是编程小白,还是有一定基础的程序员,这…...
)
设计模式-迭代器模式(Iterator)
设计模式-迭代器模式(Iterator) 一、迭代器模式概述1.1 什么是迭代器模式1.2 简单实现迭代器模式1.3 使用迭代器模式的注意事项 二、迭代器模式的用途三、迭代器模式实现方式3.1 使用Iterator接口实现迭代器模式3.2 使用Iterable接口和Iterator接口实现迭…...
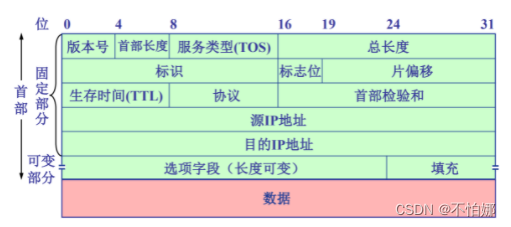
【计算机网络笔记】Internet网络的网络层——IP协议之IP数据报的结构
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...
【Git】Git的GUI图形化工具ssh协议IDEA集成Git
一、GIT的GUI图形化工具 1、介绍 Git自带的GUI工具,主界面中各个按钮的意思基本与界面文字一致,与git的命令差别不大。在了解自己所做的操作情况下,各个功能点开看下就知道是怎么操作的。即使不了解,只要不做push操作,…...

Java中抽象类
1 抽象方法必须包含在抽象类中 package charactor; public abstract class Hero { String name; float hp;float armor;int moveSpeed;public static void main(String[] args) {}// 抽象方法attack // Hero的子类会被要求实现attack方法 public abstract void attack();} …...

18 Linux 阻塞和非阻塞 IO
一、阻塞和非阻塞 IO 1. 阻塞和非阻塞简介 这里的 IO 指 Input/Output(输入/输出),是应用程序对驱动设备的输入/输出操作。当应用程序对设备驱动进行操作的时候,如果不能获取到设备资源,那么阻塞式 IO 就会将对应应用…...

多因素验证如何让企业邮箱系统登录更安全?
企业邮箱系统作为基础的办公软件之一,既是企业内外沟通的重要工具,也是连接企业多个办公平台的桥梁,往往涉及到客户隐私、业务信息、企业机密等等。为了保护邮箱账户的安全,设置登陆密码无疑是保护账户安全的常用措施之一。然而随…...

投票助手图文音视频礼物打赏流量主小程序开源版开发
投票助手图文音视频礼物打赏流量主小程序开源版开发 图文投票:用户可以发布图文投票,选择相应的选项进行投票。 音视频投票:用户可以发布音视频投票,观看音视频后选择相应的选项进行投票。 礼物打赏:用户可以在投票过…...

黑客(网络安全)技术——高效自学1.0
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学 今天给大家分享一下,很多人上来就说想学习黑客,但是连方向都没搞清楚就开始学习…...
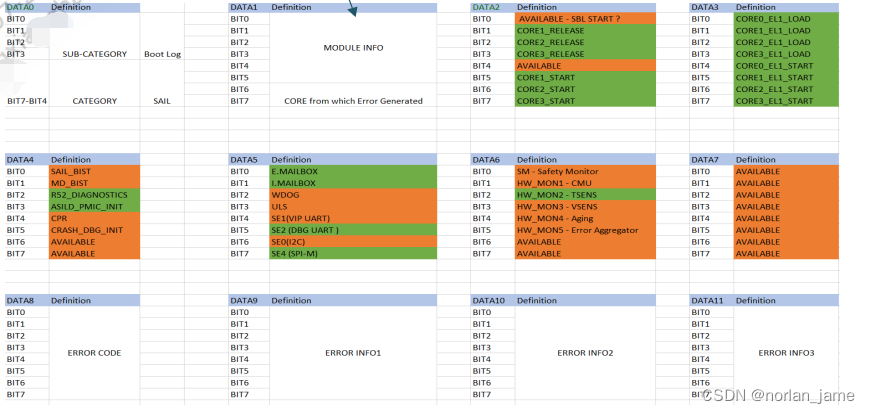
8255 boot介绍及bring up经验分享
这篇文章会简单的介绍8255的启动流程,然后着重介绍8255在实际项目中新硬件上的bring up工作,可以给大家做些参考。 8255 boot介绍 下面这些信息来自文档:《QAM8255P IVI Boot and CoreBSP Architecture Technical Overview》 80-42847-11 R…...
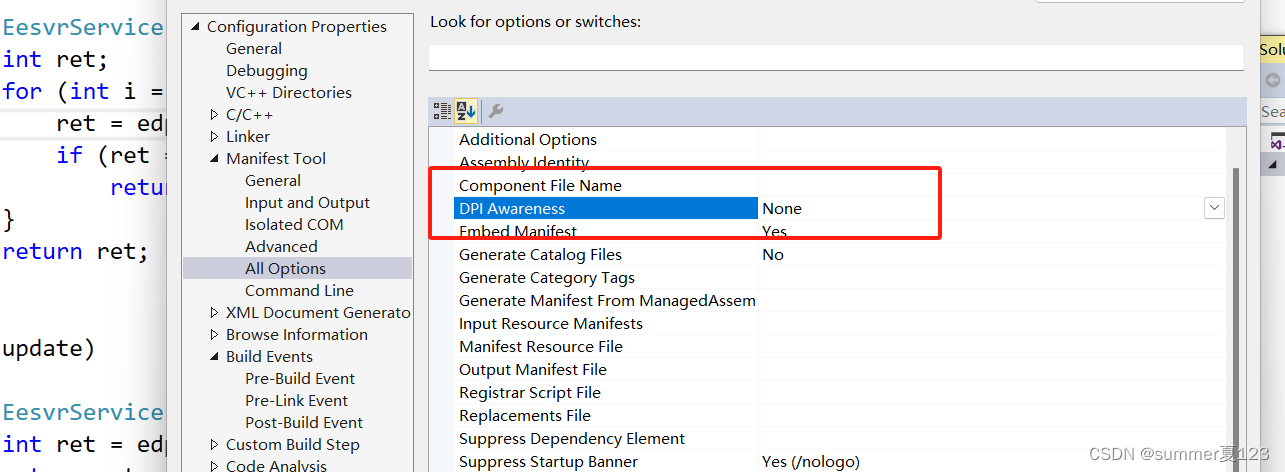
visual studio 启用DPI识别功能
在开发widow程序时,有时必须将电脑 设置-->显示-->缩放与布局-->更改文本、应用项目的大小-->100%后,程序的画面才能正确运行,居说这是锁定了dpi的原因,需要启dpi识别功能。设置方法如下: 或者...

一题三解(暴力、二分查找算法、单指针):鸡蛋掉落
涉及知识点 暴力、二分查找算法、单指针 题目 给你 k 枚相同的鸡蛋,并可以使用一栋从第 1 层到第 n 层共有 n 层楼的建筑。 已知存在楼层 f ,满足 0 < f < n ,任何从 高于 f 的楼层落下的鸡蛋都会碎,从 f 楼层或比它低的…...

从Pad Limit到Core Limit:一次流片失败复盘,聊聊芯片面积估算里的那些‘坑’
从Pad Limit到Core Limit:一次流片失败复盘与芯片面积估算实战指南 那是个周五的深夜,当我收到Foundry发来的最终面积报告时,咖啡杯直接从手中滑落——芯片面积比预算超标23%。这意味着要么接受每片晶圆成本增加40%的残酷现实,要…...

PyTorch DataLoader内存优化实战:num_workers和batch_size到底怎么调才不会崩?
PyTorch DataLoader内存优化实战:num_workers和batch_size到底怎么调才不会崩? 当你深夜盯着屏幕上突然出现的Killed报错,看着训练了3天的模型戛然而止,这种崩溃感每个深度学习开发者都懂。内存溢出就像悬在头上的达摩克利斯之剑—…...

Navigation源码编译踩坑实录:从Amcl报错到完美运行的完整避坑指南
Navigation源码编译实战:从依赖解析到系统集成的深度指南 当你第一次尝试在ROS Melodic环境下从源码编译Navigation堆栈时,那种期待与忐忑交织的感觉我至今记忆犹新。作为一个长期依赖二进制包安装的开发者,转向源码编译不仅意味着对系统更深…...
)
“Webinar Replay: Modern Component Design with Spring” 指的是一场已录制回放的网络研讨会(Webinar)
“Webinar Replay: Modern Component Design with Spring” 指的是一场已录制回放的网络研讨会(Webinar),主题聚焦于使用 Spring 框架进行现代组件化设计。该活动通常由 Spring 官方团队、Pivotal(现属 VMware)或 Spri…...
)
齿轮箱零部件及其装配质检中的TVA技术突破(9)
前沿技术背景介绍:AI 智能体视觉检测系统(Transformer-based Vision Agent,缩写:TVA),是依托 Transformer 架构与“因式智能体”算法所构建的高精度智能体。它区别于传统机器视觉与早期 AI 视觉,…...

Voron 2.4开源项目:重新定义高速高精度3D打印的模块化解决方案
Voron 2.4开源项目:重新定义高速高精度3D打印的模块化解决方案 【免费下载链接】Voron-2 Voron 2 CoreXY 3D Printer design 项目地址: https://gitcode.com/gh_mirrors/vo/Voron-2 Voron 2.4是一款完全开源的CoreXY架构3D打印机设计,代表着桌面级…...
)
别再死记硬背了!用Python+Matplotlib可视化理解高斯定理(附代码)
用PythonMatplotlib动态可视化高斯定理:从抽象公式到直观理解 在物理学的课堂上,高斯定理常常是让学生们头疼的一个难点——那些抽象的电场线、闭合曲面和电通量概念,仅靠静态的教科书图示和数学推导很难真正理解。但如果我们换一种方式&…...
)
别再手动示教了!用RobotStudio的Offs函数搞定ABB机器人复杂码垛(附完整RAPID代码)
告别示教噩梦:用RobotStudio的Offs函数实现ABB机器人智能码垛 在工业自动化领域,码垛作业是最常见也最耗时的任务之一。传统的手动示教方式需要工程师逐个点位进行示教,不仅效率低下,而且容易出错。想象一下,面对一个3…...
)
运维工程师的浪漫:手把手教你用特殊字符在服务器上“画画”(从/etc/motd到Banner全攻略)
服务器上的艺术:用ASCII与Unicode打造个性化运维环境 1. 技术人的创意表达新维度 在大多数人眼中,服务器运维是冰冷命令行与枯燥配置的代名词。但当我们打开终端,登录系统时,那些跳动的字符其实可以成为展现个性的画布。从简单的A…...

从“对话工具”到“自主智能体”:彻底搞懂AI Agent的核心定义、本质边界与落地实践
你是不是也经常听到「AI Agent」这个词,却始终分不清它和普通聊天机器人、加了插件的大模型到底有什么本质区别? 是不是见过太多号称「Agent」的产品,用起来却还是和ChatGPT没两样,只是多了几个功能入口? 这篇文章&…...