进阶课6——基于Seq2Seq的开放域生成型聊天机器人的设计和开发流程
情感聊天机器人通常属于开放领域,用户可以与机器人进行各种话题的互动。例如,微软小冰和早期的AnswerBus就是这种类型的聊天机器人。基于检索的开放领域聊天机器人需要大量的语料数据,其开发流程与基于任务型的聊天机器人相似,而基于深度学习的生成类型聊天机器人则具有处理开发领域的先天优势。其中,以Seq2Seq模型为基础的闲聊机器人已经在机器翻译领域取得了成功的应用。
Seq2Seq模型是NLP中的一个经典模型,最初由Google开发,并用于机器翻译。它基于RNN网络模型构建,能够支持且不限于的应用包括:语言翻译、人机对话、内容生成等。Seq2Seq,就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。Seq2Seq属于Encoder-Decoder的大范畴,主要是一个由编码器(encoder)和一个解码器(decoder)组成的网络。编码器将输入项转换为包含其特征的相应隐藏向量,解码器反转该过程,将向量转换为输出项,解码器每次都会使用前一个输出作为其输入。不断重复此过程,直到遇到结束字符。
1.基于Seq2Seq的聊天机器人开发流程
我们将基于TensorFlow深度学习框架,介绍以Seq2Seq为基础的聊天机器人的开发流程。
1.语料准备
首先是语料准备,先准备基于开放域聊天语料进行模型训练。在我们的聊天语料中,奇数行是问题,偶数行对应的回答。
1 聊点么好呢?2 那我们随便聊聊吧3 你是什么人?4 我是智能客服5 有人在吗6 小宝一直会在这里诚心为您服务基于生成方式的开放领域聊天机器人需要充足的聊天语料,聊天语料需要覆盖大部分的话题,才能保证回答的多样性和语句的通顺。然后我们通过对所有的聊天语料进行预处理,进行字典统计。
python
def create_vocabulary(vocabulary_path, data_path, max_vocabulary_size, tokenizer=None, normalize_digits=True): if not gfile.Exists(vocabulary_path): print("Creating vocabulary %s from data %s" % (vocabulary_path, data_path)) vocab = {} with gfile.GFile(data_path, mode="rb") as f: counter = 0 for line in f: counter += 1 if counter % 100000 == 0: print("processing line %d" % counter) line = tf.compat.as_bytes(line) tokens = tokenizer(line) if tokenizer else basic_tokenizer(line) for win tokens: word = _DIGIT_RE.sub(b"0", w) if normalize_digits else w if word in vocab: vocab[word] += 1 else: vocab[word] = 1 vocab_list = _START_VOCAB + sorted(vocab, key=vocab.get, reverse=True) if len(vocab_list) > max_vocabulary_size: vocab_list = vocab_list[:max_vocabulary_size] with gfile.GFile(vocabulary_path, mode="wb") as vocab_file: for win vocab_list: vocab_file.write(w + b"\n")根据统计的词频和字典,我们为聊天语料建立Token Id,比如“聊点什么好呢”这句话,根据每个词在词组中的位置[“聊”:0,“点”:1,“什么”:2,“好”:3,“呢”:4]可以表征为[0,1,2,3,4]。
python
def data_to_token_ids(data_path, target_path, vocabulary_path, tokenizer=None, normalize_digits=True): """将数据文件进行分词并转换为token-ids,使用给定的词汇文件。此函数逐行加载来自data_path的数据文件,调用上述sentence_to_token_ids,并将结果保存在target_path中。有关token-ids格式的详细信息,请参阅sentence_to_token_ids的注释。 Args: data_path (str): 数据文件的路径,格式为每行一句。 target_path (str): 将创建的文件token-ids的路径。 vocabulary_path (str): 词汇文件的路径。 tokenizer: 用于对每个句子进行分词的函数;如果为None,将使用basic_tokenizer。 normalize_digits (bool): 如果为True,则将所有数字替换为O。 """ if not gfile.Exists(target_path): print("正在对位于 {} 的数据进行分词".format(data_path)) vocab = initialize_vocabulary(vocabulary_path) with gfile.GFile(data_path, mode="rb") as data_file: with gfile.GFile(target_path, mode="w") as tokens_file: counter = 0 for line in data_file: try: line = line.decode('utf8', 'ignore') except Exception as e: print(e, line) continue counter += 1 if counter % 100000 == 0: print("正在对第 {} 行进行分词".format(counter)) token_ids = sentence_to_token_ids(tf.compat.as_bytes(line), vocab, tokenizer, normalize_digits) tokens_file.write(" ".join([str(tok) for tok in token_ids]) + "\n")
1.2定义Encoder和Decoder
根据Seq2Seq的结构,需要首先定义Cell,选择GRU或者LSTM的Cell,并确定Size。然后利用Tensorflow中tf_Seq2Seq.embedding_attention_Seq2Seq这个函数来构架Encoder和Decoder模型,在训练模式下,Decoder的输入是真实的Target序列。
def single_cel1(): return tf.contrib.rnn.GRUCell(size) if use_lstm else tf.contrib.rnn.BasicLSTMCell(size) def single_cell(): return tf.contrib.rnn.BasicLSTMCell(size) cell = single_cel1() if num_layers > 1 else single_cell()
cell = tf.contrib.rnn.MultiRNNCell([single_cell() for _ in range(num_layers)]) # The seq2seg function: we use embedding for the input and attention.
def seq2seq_f(encoder_inputs, decoder_inputs, feed_previous): return tf_seq2seq.embedding_attention_seq2seq( encoder_inputs, decoder_inputs, cell, num_encoder_symbols=source_vocab_size, num_decoder_symbols=target_vocab_size, embedding_size=size, output_projection=output_projection, feed_previous=feed_previous, dtype=dtype)
# Training outputs and losses, if forward_only:
self.outputs, self.losses, self.encoder_state = tf_seq2seq.model_with_buckets( self.encoder_inputs, self.decoder_inputs, targets, self.target_weights, buckets, lambda x, y: seq2seq_f(x, y, True), softmax_loss_function=softmax_loss_function
) # If we use output projection, we need to project outputs for decoding.
if output_projection is not None: for b in xrange(len(buckets)): self.outputs[b] = [ tf.matmul(output, output_projection[0]) + output_projection[1] for output in self.outputs[b] ]
else: self.outputs, self.losses, self.encoder_state = tf_seq2seq.model_with_buckets( self.encoder_inputs, self.decoder_inputs, targets, self.target_weights, buckets, lambda x, y: seq2seq_f(x, y, False), softmax_loss_function=softmax_loss_function )1.3模型训练和评估模块
对于训练阶段,首先定义Encoder和Decoder的网络结构(12.3.2节),然后对输入进行预处理(12.3.1节),最后通过Get_Batch将数据分成多个Batch,并利用Session进行训练。此外每次Epoch都要通过对模型生成语句的困惑度进行计算,来评估生成回答语句是否通顺。
python
def det_train(args): print("Preparing dialog data in to", args.model_name, args.data_dir) setup_workpath(workspace*args.workspace) train_data, dev_data, _ = data_utils.prepare_dialog_data(args.data_dir, args.vocab_size) if args.reinforce_learn: args.batch_size = # is decode one sentence at a time gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction*args.gpu_usage) with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess: # Create model, print("Creating id layers of hd units.") model = seq2seq_model_utils.create_model(sess, args.forward_only-False) # Read data into buckets and compute their sizes, print("Reading development and training data (limit: %d)," % args.max_train_data_size) dev_set = data_utils.read_data(dev_data, args.buckets*args.rev_model) train_set = data_utils.read_data(train_data, args.buckets, args.max_train_data_size, args.rev_model) #Tev mode train_bucket_sizes = [len(train_set[b]) for b in range(len(args.buckets))] train_total_size = float(sum(train_bucket_sizes)) train_buckets_scale = [sum(train_bucket_sizes[:i + 1]) / train_total_size for i in range(len(train_bucket_sizes))] # This is the training loop step_time, loss = 0.0, 0.0 # current step and loss so far previous_losses = [] # to keep track of the losses in every epoch # Load vocabularies vocab_path = os.path.join(args.data_dir, "rocabid.%d" % args.vocab_size) vocab, rev_vocab = data_utils.initialize_vocabulary(vocab_path) while True: random_number = np.random.random() # random number between 0 and 1 bucket_id = min([i for i in range(len(train_buckets_scale)) if train_buckets_scale[i] > random_number]) # find the bucket id based on the random number # Get a batch and make a step start_time = time.time() # record the start time of this batch encoder_inputs, decoder_inputs, target_weights = model.get_batch(train_set, bucket_id) # get a batch from the selected bucket id if args.reinforce_learn: step_loss = model.step_rf(args, sess, encoder_inputs, decoder_inputs, target_weights, bucket_id, rev_vocab) # make a step using the reinforcement learning loss function else: step_loss = model.step(sess, encoder_inputs, decoder_inputs, target_weights, bucket_id=bucket_id, forward_only=False) # make a step using the default loss function # update the loss and current step after each batch/step finishs (in the end of this loop) loss += step_loss / (time.time() - start
1.4模型预测和Beam Search模块
在预测模块,对应生成对话,我们需要利用Beam Search来寻找最优解。通过对Beam Size的控制可以保证输出语句的多样性。此外我们也可以加入强化学习,对于不同的机器人回答进行及时的人工反馈,通过Reinforcement Learning不断优化模型。
python
Get output logits for the sentence
beams, now_beams, results = [(1.0, 0.0, i'eos': 0.0, 'dec inp': decoder_inputs, 'prob': 1.0, 'prob_ts': 1.0, 'prob_t': 4.0))]. []. [ Adjusted probability all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) Normal seg2seg if debug: print(' '.join([dict_lookup(rev_vocab, w) for w in cand['dec_inp']])) if cand[eos']: results += [(prob, 0, cand)] continue Adjusted probability all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) Adjusted probability all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) Adjusted probability all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id)
]
all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None
all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id)
all_prob_ts = model_step(encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) if args.antilm else None
all_prob_t = model_step(dummy_encoder_inputs, cand['dec_inp'], dptr, target_weights, bucket_id) all_prob = all_prob_ts - args.antilm * all_prob_t #+ args.n_bonus * dptr + random() * 1e-50
all_prob = all_prob_ts - args.antilm * all_prob_t
if args.n_bonus != 0: all_prob += args.n_bonus * dptr Suppress copy-cat (respond the same as input)
if dptr < len(input_token_ids): all_prob[input_token_ids[dptr]] = all_prob[input_token_ids[dptr]] * 0.01 if return_raw: return all_prob, all_prob_ts, all_prob_t # beam search for c in np.argsort(all_prob)[::-1][:args.beam_size]:
new_cand "
gos dec_inp" (c - data_utils.EOS_ID), [(np.array([c]) if i -- (dptr+1) else k)
for i, k in enumerate(cand['dec_inp'])]
prob_ts cand['prob_ts *all_prob_ts[c]
prob prob cand['prob _ cand['prob ] * all_prob t[c]
new_cand = (new_cand['prob'], random(). new_cand) # stuff a randon to prevent comparing new_cand
if len (new_beams) < args.beam_size:
heapq. heappush(new_beams, new cand)
elif (new cando[0] > new _beams[0][0]):
heapq. heapreplace(new _beams, new _cand)
except Exception as e:
print("[Error]', e)
print(" ----[new _beams]-- ")
print("-ines _cand]\n", new _cand) -\n". new _beams)
results += new _cands # flush last cands post-process results res _cands
for prob, _ in sorted(results, reverse=True):
cand['dec _inp']l- res _cands. append(cand) join([dict _lookup(rev _vocab. w) for w in cand['dec _inp']l]) retugn res _cands[:args. beam _size]往期精彩文章:
基础课22——云服务(SaaS、Pass、laas、AIaas)-CSDN博客文章浏览阅读47次。云服务是一种基于互联网的计算模式,通过云计算技术将计算、存储、网络等资源以服务的形式提供给用户,用户可以通过网络按需使用这些资源,无需购买、安装和维护硬件设备。云服务具有灵活扩展、按需使用、随时随地访问等优势,可以降低用户成本,提高资源利用效率。随着云计算技术的不断发展,云服务的应用范围也将越来越广泛。https://blog.csdn.net/2202_75469062/article/details/134212001?spm=1001.2014.3001.5501
基础课20——智能客服系统的使用维护-CSDN博客文章浏览阅读72次。智能客服系统在上线后,仍然需要定期的维护和更新。这是因为智能客服系统是一个复杂的软件系统,涉及到多个组件和功能,需要不断优化和改进以满足用户需求和保持市场竞争力。https://blog.csdn.net/2202_75469062/article/details/134211359?spm=1001.2014.3001.5501
相关文章:
进阶课6——基于Seq2Seq的开放域生成型聊天机器人的设计和开发流程
情感聊天机器人通常属于开放领域,用户可以与机器人进行各种话题的互动。例如,微软小冰和早期的AnswerBus就是这种类型的聊天机器人。基于检索的开放领域聊天机器人需要大量的语料数据,其开发流程与基于任务型的聊天机器人相似,而基…...

Java面试题04
1.Array 和 ArrayList 有何区别? Array是固定长度的,元素类型可以是基本类型,创建后大小不可改变;ArrayList是可变长 度的,只能存储对象,可以动态添加和删除元素。 区别1: 存储类型不同 …...
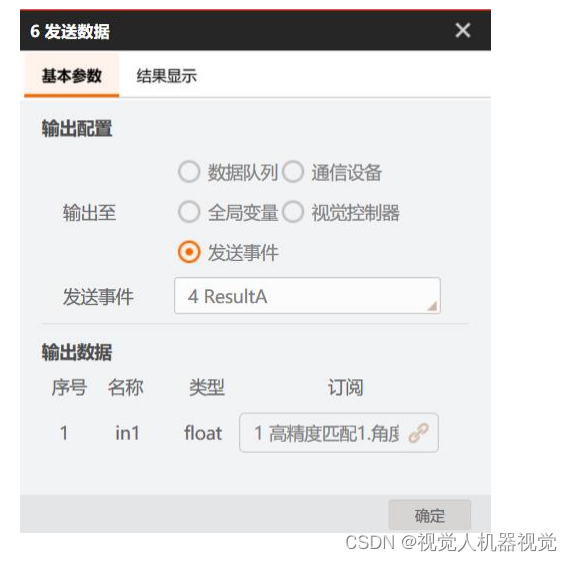
海康Visionmaster-通讯管理:使用 Modbus TCP 通讯 协议与流程交互
使用 Modbus TCP 通讯协议与视觉通讯,当地址为 0000 的保持型寄存器(4x 寄存器)变为 1 时,触发视觉流程执行一次,同时视觉将地址为 0000 的寄存器复位(也即写为 0),视觉流程执行完成后,将结果数…...

assimp中如何判断矩阵是否是单位矩阵
对于一个矩阵元素为浮点型的矩阵,你是否还在使每个元素跟1.0f或0.0f进行比较,如果这样,只能说你的结果不一定正确,那我们看看assimp中是如何做的。 template <typename TReal> AI_FORCE_INLINE bool aiMatrix4x4t<TReal…...

大数据Doris(二十):数据导入(Broker Load)介绍
文章目录 数据导入(Broker Load)介绍 一、适用场景...

Docker快速安装kafka
创建zk docker run -d --name zookeeper-server \-e ALLOW_ANONYMOUS_LOGINyes \bitnami/zookeeper:latest创建kafka docker run -d --name kafka-server \-p 9092:9092 \-e ALLOW_PLAINTEXT_LISTENERyes \-e KAFKA_CFG_ZOOKEEPER_CONNECTzookeeper-server:2181 \-e KAFKA_CF…...
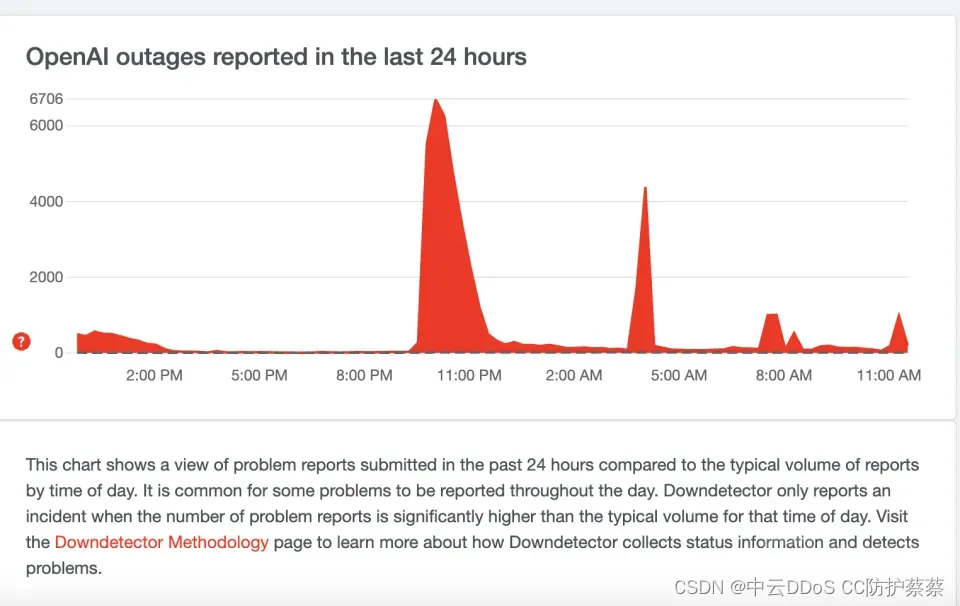
ChatGPT是什么?黑客试图淹没其服务
上线2个月,月活跃用户破亿,媒体人用它编辑文案,学生用它写作业,程序员用它编辑代码, 它是谁呢? 它就是火爆全网(chatgpt),chatgpt是什么呢,chatgpt是美国研发的一款人工…...

【Java 进阶篇】Java Web 开发之 Listener 篇:ServletContextListener 使用详解
欢迎大家来到 Java Web 开发的学习之旅!在前面的博客中,我们已经学习了 Servlet、JSP、Filter 等重要的概念和技术。今天,我们将深入探讨 Java Web 开发中另一个重要的组成部分——Listener(监听器),具体来…...

[C/C++]数据结构 链表OJ题:环形链表(如何判断链表是否有环)
题目描述: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置&…...

c#流程控制
c#分支语句 namespace ConsoleApp1 {internal class Program{static void Main(string[] args){Console.WriteLine("请输入学生成绩");string sConsole.ReadLine();int aint.Parse(s);//将字符类型强制转换为int类型if (a > 90){ Console.WriteLine("成绩优…...

基于SSM的学生二手书籍交易平台的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

xcode-工程设置
build settings Deployment Postprocessing 用于指定是否在构建完成后进行一些部署相关的处理。 当你在 Xcode 中构建你的应用程序时,构建设置决定了一些行为,其中一项是是否启用 Deployment Postprocessing。这个选项的主要作用是在构建完成后&#…...
Milvus Cloud——LLM Agent 现阶段出现的问题
LLM Agent 现阶段出现的问题 由于一些 LLM(GPT-4)带来了惊人的自然语言理解和生成能力,并且能处理非常复杂的任务,一度让 LLM Agent 成为满足人们对科幻电影所有憧憬的最终答案。但是在实际使用过程中,大家逐渐发现了通…...

百度智能云千帆大模型平台再升级,SDK版本开源发布!
SDK 前言一、SDK的优势二、千帆SDK:快速落地LLM应用三、如何快速上手千帆SDK1、SDK快速启动快速安装平台鉴权如何获取AK/SK以“Chat 对话”为调用示例 2. SDK进阶指引3. 通过Langchain接入千帆SDK为什么选择Langchain 开源社区 前言 百度智能云千帆大模型平台再次升…...

按键精灵中的数据类型转换
按键精灵中的数据类型有:整型、浮点数、布尔类型、字符串、数组这几种类型,主要的转换方式有以下这几种方式: 1. 转布尔类型 CBool Dim A 5 Dim B CBool(A)TracePrint B // true 2. 转字符串类型 CStr Dim MyInteger 437Dim MyStr…...

Golang Gorm 连接数据库
连接数据库 为了连接数据库,你首先要导入数据库驱动程序。例如: import _ "github.com/go-sql-driver/mysql"import ("gorm.io/driver/mysql""gorm.io/gorm" ) GORM 已经包含了一些驱动程序,为了方便的去记住…...
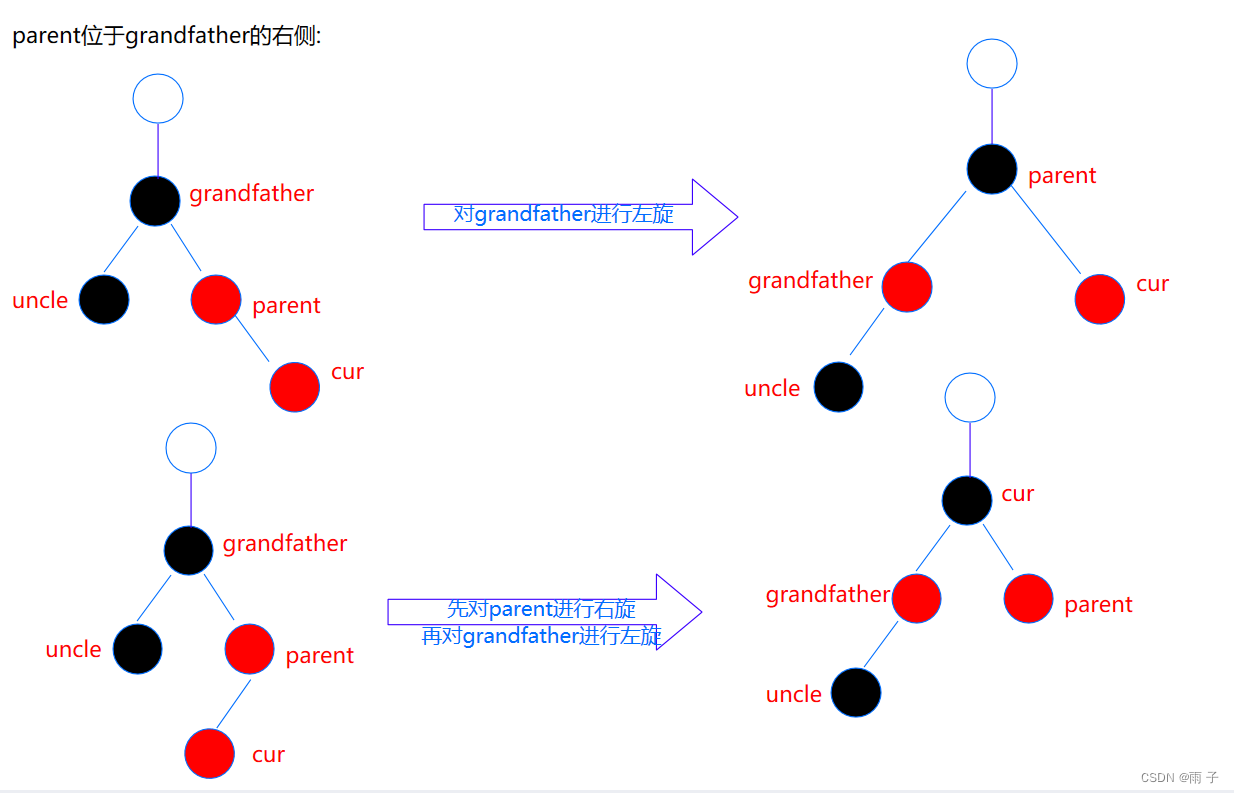
[C++随笔录] 红黑树
红黑树 红黑树的特点红黑树的模拟实现红黑树的底层结构insert的实现实现思路更新黑红比例的逻辑insert的完整代码 insert的验证 源码 红黑树的特点 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是 Red或 Black。…...

C 和 C++ 可变参数介绍
文章目录 前言概念C 的可变参数参数列表 #va_list 4组宏 C 的可变参数参数列表 #va_list 4组宏初始化列表 initializer_list<> 类模板可变参数模板 总结参考资料作者的话 前言 C 和 C 可变参数介绍。 概念 可变(长)/不定(长ÿ…...
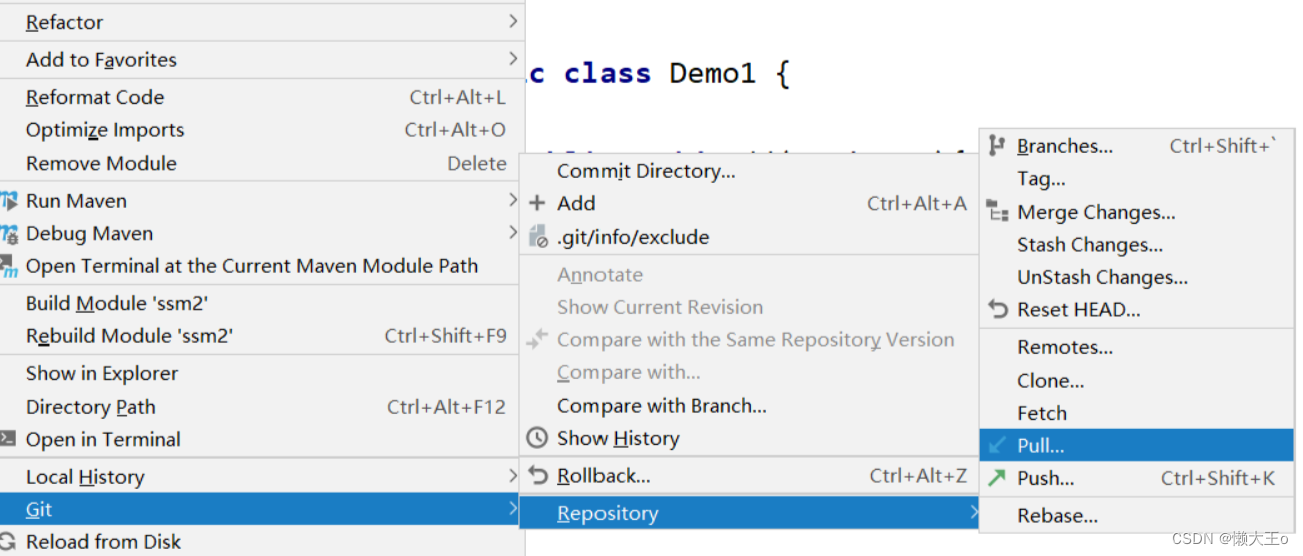
【Git】gui图形化界面的使用、ssh协议以及idea集成Git
目录 gui图形化界面的使用 介绍 特点 gui图形的使用 ssh协议 介绍 步骤及概念 ssh协议的使用 配置公钥 idea集成Git idea配置git IDEA安装gitee IDEA中登入Git 编辑 项目分享 克隆分享的项目 编辑 编辑 idea上传远程 gui图形化界面的使用 介绍 GUI(…...
C语言之文件操作(详解版)
不知不觉我们已经学到C语言的文件操作部分了,这部分内容其实很有意思,因为它可以直接把我们代码中的数据写入硬盘,而不是我们关掉这个程序,代码就没有了,让我们开始学习吧! 目录 1.为什么使用文件 2.什么…...

Connexion高级特性探索:10个提升开发效率的隐藏功能
Connexion高级特性探索:10个提升开发效率的隐藏功能 【免费下载链接】connexion Connexion is a modern Python web framework that makes spec-first and api-first development easy. 项目地址: https://gitcode.com/gh_mirrors/co/connexion Connexion是一…...

当代码几乎免费时,程序员还剩下什么?
这是一个正在发生的转变:写出“能跑的代码”成本正无限趋近于零,但写出“正确的系统”依然是昂贵的。本文将探讨在 AI 编程时代,工程师真正的护城河在哪里,以及我们应该如何重塑自己的工作方式。 🧱 一、现状ÿ…...

别再只盯着5G了!从BBU、RRU到AAU,一文看懂你家附近基站到底长啥样
从铁塔到芯片:解码现代基站的技术演进与视觉识别指南 每天通勤路上,那座耸立在写字楼顶端的灰色铁塔总是格外醒目——它顶部排列着几排白色长方形面板,侧面挂着几个金属盒子,底部延伸出密密麻麻的线缆。这些看似简单的装置&#x…...

Rust的闭包捕获语义分析与内存管理在长期存活闭包中的最佳实践
Rust的闭包捕获语义分析与内存管理在长期存活闭包中的最佳实践 Rust以其独特的所有权系统和内存安全特性著称,而闭包作为函数式编程的核心概念,在Rust中同样扮演着重要角色。闭包的捕获语义和内存管理在长期存活的场景下(例如异步任务或事件…...
)
go语言学习(分支语句与循环语句)
判断语句if 标准if语句 输入年龄,程序根据年龄判断状态: 未出生:age < 0儿童:age < 18成年人:age < 30中年人:age < 50老年人:age > 50 package mainimport "fmt"func…...
)
为什么92%的AGI项目在记忆对齐阶段失败?——2026奇点大会实测数据揭示5大认知断层与3步修复协议(含开源Memory-LLM v0.9预览版)
第一章:2026奇点智能技术大会:AGI与记忆系统 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将“记忆系统”确立为AGI架构的核心支柱,而非传统意义上的辅助模块。研究者指出,具备可演化、可检索、可因果回溯的长期记…...

从ZkClient到Curator:Spring Boot项目里ZooKeeper客户端选型与实战避坑指南
从ZkClient到Curator:Spring Boot项目中ZooKeeper客户端的技术选型与实战指南 在分布式系统架构设计中,服务协调与状态管理一直是核心挑战之一。作为分布式协调服务的经典解决方案,ZooKeeper凭借其强一致性、高可用性和丰富的通知机制&#x…...

JavaScript正则表达式实战:从EDUCODER关卡解析到日常开发应用
JavaScript正则表达式实战:从EDUCODER关卡解析到日常开发应用 正则表达式就像程序员的瑞士军刀,能在文本处理中解决各种棘手问题。第一次接触正则时,那些看似神秘的符号组合让我望而生畏,直到在EDUCODER平台通过实战关卡逐步掌握…...

别再只会用WinDbg了!试试微软官方的Application Verifier,内存泄漏和双重释放一抓一个准
超越WinDbg:Application Verifier在内存问题排查中的实战指南 当你在深夜调试一个偶发性崩溃时,WinDbg的复杂命令和模糊错误信息是否让你感到沮丧?微软其实还隐藏着一款被低估的神器——Application Verifier(简称AppVerif&#x…...
)
SENT vs PWM vs CAN:为你的汽车电子项目选对通信协议(成本/速度/复杂度全对比)
SENT vs PWM vs CAN:为你的汽车电子项目选对通信协议(成本/速度/复杂度全对比) 在汽车电子系统的设计中,选择合适的通信协议往往决定了项目的成败。面对SENT、PWM、CAN等不同方案,工程师需要在成本、速度、抗干扰性和实…...