SpringData、SparkStreaming和Flink集成Elasticsearch
本文代码链接:https://download.csdn.net/download/shangjg03/88522188
1 Spring Data框架集成
1.1 Spring Data框架介绍
Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。 Spring Data可以极大的简化JPA(Elasticsearch…)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
Spring Data的官网:Spring Data
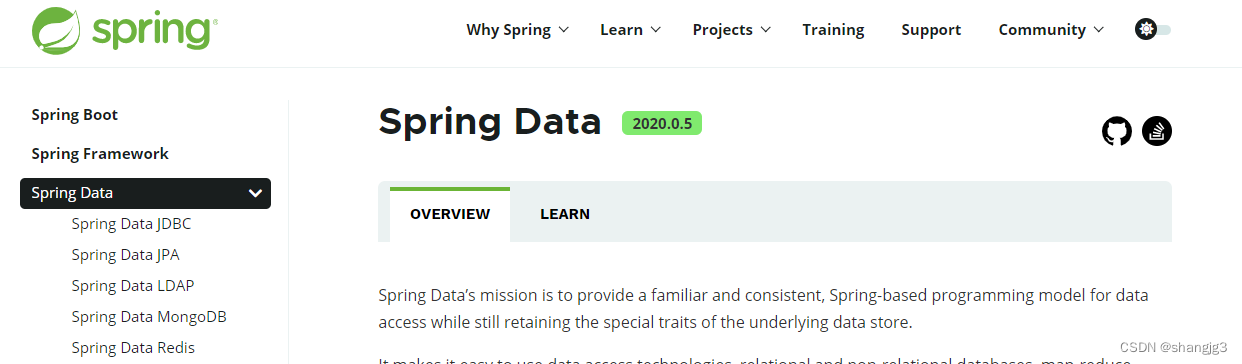
Spring Data常用的功能模块如下:
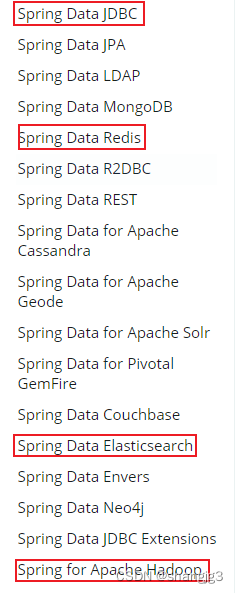
1.2 Spring Data Elasticsearch介绍
Spring Data Elasticsearch 基于 spring data API 简化 Elasticsearch操作,将原始操作Elasticsearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储索引库数据访问层。
官方网站: https://spring.io/projects/spring-data-elasticsearch

1.3 Spring Data Elasticsearch版本对比
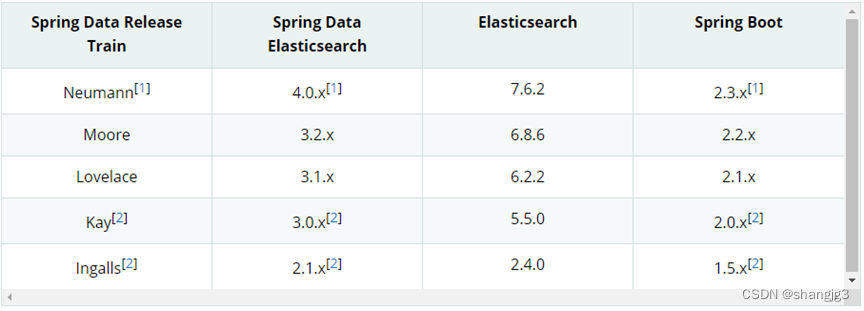
目前最新springboot对应Elasticsearch7.6.2,Spring boot2.3.x一般可以兼容Elasticsearch7.x
1.4 框架集成
- 创建Maven项目
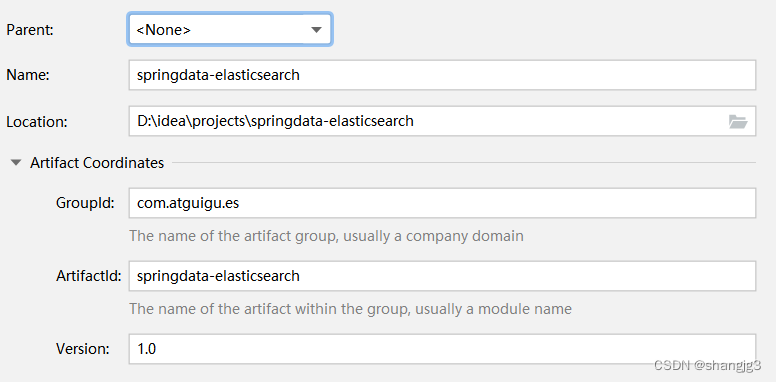
- 修改pom文件,增加依赖关系
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.6.RELEASE</version><relativePath/></parent><groupId>com.shangjack.es</groupId><artifactId>springdata-elasticsearch</artifactId><version>1.0</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-test</artifactId></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId></dependency></dependencies>
</project>- 增加配置文件
在resources目录中增加application.properties文件
# es服务地址
elasticsearch.host=127.0.0.1
# es服务端口
elasticsearch.port=9200
# 配置日志级别,开启debug日志
logging.level.com.shangjack.es=debug
- SpringBoot主程序
package com.shangjack.es;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class SpringDataElasticSearchMainApplication {public static void main(String[] args) {SpringApplication.run(SpringDataElasticSearchMainApplication.class,args);}
}
数据实体类
package com.shangjack.es;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Product {private Long id;//商品唯一标识private String title;//商品名称private String category;//分类名称private Double price;//商品价格private String images;//图片地址}
- 配置类
- ElasticsearchRestTemplate是spring-data-elasticsearch项目中的一个类,和其他spring项目中的template类似。
- 在新版的spring-data-elasticsearch中,ElasticsearchRestTemplate代替了原来的ElasticsearchTemplate。
- 原因是ElasticsearchTemplate基于TransportClient,TransportClient即将在8.x以后的版本中移除。所以,我们推荐使用ElasticsearchRestTemplate。
- ElasticsearchRestTemplate基于RestHighLevelClient客户端的。需要自定义配置类,继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
package com.shangjack.es;import lombok.Data;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;@ConfigurationProperties(prefix = "elasticsearch")
@Configuration
@Data
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {private String host ;private Integer port ;//重写父类方法
@Overridepublic RestHighLevelClient elasticsearchClient() {RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);return restHighLevelClient;}
}
- DAO数据访问对象
package com.shangjack.es;import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;@Repository
public interface ProductDao extends ElasticsearchRepository<Product,Long> {}
- 实体类映射操作
package com.shangjack.es;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Document(indexName = "shopping", shards = 3, replicas = 1)
public class Product {//必须有id,这里的id是全局唯一的标识,等同于es中的"_id"
@Idprivate Long id;//商品唯一标识/*** type : 字段数据类型* analyzer : 分词器类型* index : 是否索引(默认:true)* Keyword : 短语,不进行分词*/ @Field(type = FieldType.Text, analyzer = "ik_max_word")private String title;//商品名称
@Field(type = FieldType.Keyword)private String category;//分类名称
@Field(type = FieldType.Double)private Double price;//商品价格
@Field(type = FieldType.Keyword, index = false)private String images;//图片地址
}
- 索引操作
package com.shangjack.es;import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.test.context.junit4.SpringRunner;@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESIndexTest {//注入ElasticsearchRestTemplate
@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;//创建索引并增加映射配置
@Testpublic void createIndex(){//创建索引,系统初始化会自动创建索引System.out.println("创建索引");} @Testpublic void deleteIndex(){//创建索引,系统初始化会自动创建索引boolean flg = elasticsearchRestTemplate.deleteIndex(Product.class);System.out.println("删除索引 = " + flg);}
}
- 文档操作
package com.shangjack.es;import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.test.context.junit4.SpringRunner;import java.util.ArrayList;
import java.util.List;@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESProductDaoTest {
@Autowiredprivate ProductDao productDao;/*** 新增*/
@Testpublic void save(){Product product = new Product();product.setId(2L);product.setTitle("华为手机");product.setCategory("手机");product.setPrice(2999.0);product.setImages("http://www.shangjack/hw.jpg");productDao.save(product);}//修改
@Testpublic void update(){Product product = new Product();product.setId(1L);product.setTitle("小米2手机");product.setCategory("手机");product.setPrice(9999.0);product.setImages("http://www.shangjack/xm.jpg");productDao.save(product);}//根据id查询
@Testpublic void findById(){Product product = productDao.findById(1L).get();System.out.println(product);}//查询所有
@Testpublic void findAll(){Iterable<Product> products = productDao.findAll();for (Product product : products) {System.out.println(product);}}//删除
@Testpublic void delete(){Product product = new Product();product.setId(1L);productDao.delete(product);}//批量新增
@Testpublic void saveAll(){List<Product> productList = new ArrayList<>();for (int i = 0; i < 10; i++) {Product product = new Product();product.setId(Long.valueOf(i));product.setTitle("["+i+"]小米手机");product.setCategory("手机");product.setPrice(1999.0+i);product.setImages("http://www.shangjack/xm.jpg");productList.add(product);}productDao.saveAll(productList);}//分页查询
@Testpublic void findByPageable(){//设置排序(排序方式,正序还是倒序,排序的id)Sort sort = Sort.by(Sort.Direction.DESC,"id");int currentPage=0;//当前页,第一页从0开始,1表示第二页int pageSize = 5;//每页显示多少条//设置查询分页PageRequest pageRequest = PageRequest.of(currentPage, pageSize,sort);//分页查询Page<Product> productPage = productDao.findAll(pageRequest);for (Product Product : productPage.getContent()) {System.out.println(Product);}}
}
- 文档搜索
package com.shangjack.es;import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.test.context.junit4.SpringRunner;@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESSearchTest {
@Autowiredprivate ProductDao productDao;/*** term查询* search(termQueryBuilder) 调用搜索方法,参数查询构建器对象*/
@Testpublic void termQuery(){TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> products = productDao.search(termQueryBuilder);for (Product product : products) {System.out.println(product);}}/*** term查询加分页*/
@Testpublic void termQueryByPage(){int currentPage= 0 ;int pageSize = 5;//设置查询分页PageRequest pageRequest = PageRequest.of(currentPage, pageSize);TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> products = productDao.search(termQueryBuilder,pageRequest);for (Product product : products) {System.out.println(product);}}}
2 Spark Streaming框架集成
2.1 Spark Streaming框架介绍
Spark Streaming是Spark core API的扩展,支持实时数据流的处理,并且具有可扩展,高吞吐量,容错的特点。 数据可以从许多来源获取,如Kafka,Flume,Kinesis或TCP sockets,并且可以使用复杂的算法进行处理,这些算法使用诸如map,reduce,join和window等高级函数表示。 最后,处理后的数据可以推送到文件系统,数据库等。 实际上,您可以将Spark的机器学习和图形处理算法应用于数据流。

2.2 框架集成
- 创建Maven项目
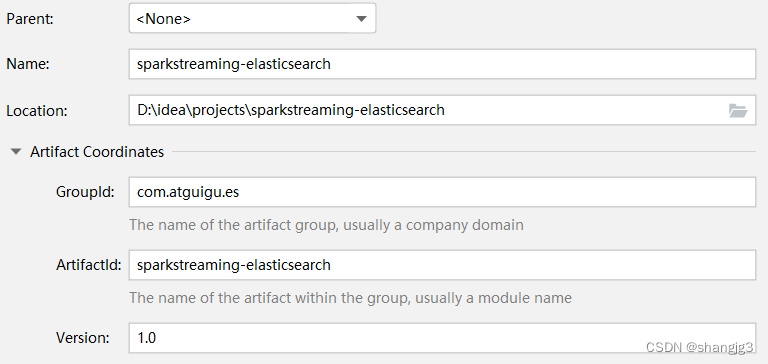
- 修改pom文件,增加依赖关系
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.shangjack.es</groupId><artifactId>sparkstreaming-elasticsearch</artifactId><version>1.0</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!-- elasticsearch的客户端 --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.8.0</version></dependency><!-- elasticsearch依赖2.x的log4j --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency>
<!-- <dependency>-->
<!-- <groupId>com.fasterxml.jackson.core</groupId>-->
<!-- <artifactId>jackson-databind</artifactId>-->
<!-- <version>2.11.1</version>-->
<!-- </dependency>-->
<!-- <!– junit单元测试 –>-->
<!-- <dependency>-->
<!-- <groupId>junit</groupId>-->
<!-- <artifactId>junit</artifactId>-->
<!-- <version>4.12</version>-->
<!-- </dependency>--></dependencies>
</project>- 功能实现
package com.shangjack.esimport org.apache.http.HttpHost
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.indices.CreateIndexRequest
import org.elasticsearch.client.{RequestOptions, RestClient, RestHighLevelClient}
import org.elasticsearch.common.xcontent.XContentTypeimport java.util.Dateobject SparkStreamingESTest {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("ESTest")val ssc = new StreamingContext(sparkConf, Seconds(3))val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)ds.foreachRDD(rdd => {println("*************** " + new Date())rdd.foreach(data => {val client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 新增文档 - 请求对象val request = new IndexRequest();// 设置索引及唯一性标识val ss = data.split(" ")println("ss = " + ss.mkString(","))request.index("sparkstreaming").id(ss(0));val productJson =s"""| { "data":"${ss(1)}" }|""".stripMargin;// 添加文档数据,数据格式为JSON格式request.source(productJson,XContentType.JSON);// 客户端发送请求,获取响应对象val response = client.index(request, RequestOptions.DEFAULT);System.out.println("_index:" + response.getIndex());System.out.println("_id:" + response.getId());System.out.println("_result:" + response.getResult());client.close()})})ssc.start()ssc.awaitTermination()}
}
3 Flink框架集成
3.1 Flink框架介绍

Apache Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Apache Spark掀开了内存计算的先河,以内存作为赌注,赢得了内存计算的飞速发展。但是在其火热的同时,开发人员发现,在Spark中,计算框架普遍存在的缺点和不足依然没有完全解决,而这些问题随着5G时代的来临以及决策者对实时数据分析结果的迫切需要而凸显的更加明显:
- 数据精准一次性处理(Exactly-Once)
- 乱序数据,迟到数据
- 低延迟,高吞吐,准确性
- 容错性
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。在Spark火热的同时,也默默地发展自己,并尝试着解决其他计算框架的问题。
慢慢地,随着这些问题的解决,Flink慢慢被绝大数程序员所熟知并进行大力推广,阿里公司在2015年改进Flink,并创建了内部分支Blink,目前服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。
3.2 框架集成
- 创建Maven项目
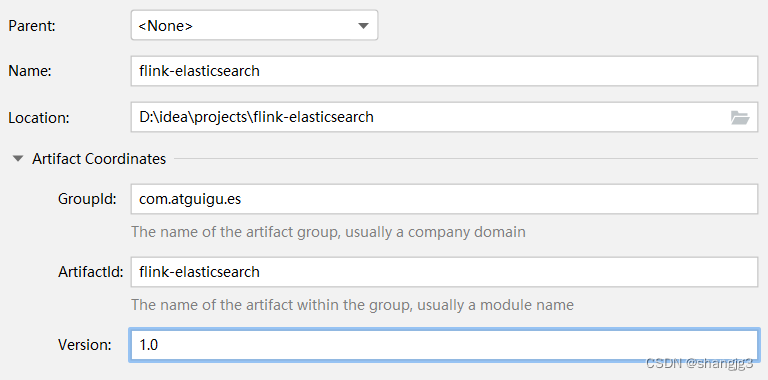
- 修改pom文件,增加相关依赖类库
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.shangjack.es</groupId><artifactId>flink-elasticsearch</artifactId><version>1.0</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7_2.11</artifactId><version>1.12.0</version></dependency><!-- jackson --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.11.1</version></dependency></dependencies>
</project>
- 功能实现
package com.shangjack.es;import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class FlinkElasticsearchSinkTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.socketTextStream("localhost", 9999);List<HttpHost> httpHosts = new ArrayList<>();httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"));//httpHosts.add(new HttpHost("10.2.3.1", 9200, "http"));// use a ElasticsearchSink.Builder to create an ElasticsearchSinkElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(httpHosts,new ElasticsearchSinkFunction<String>() {public IndexRequest createIndexRequest(String element) {Map<String, String> json = new HashMap<>();json.put("data", element);return Requests.indexRequest().index("my-index")//.type("my-type").source(json);} @Overridepublic void process(String element, RuntimeContext ctx, RequestIndexer indexer) {indexer.add(createIndexRequest(element));}});// configuration for the bulk requests; this instructs the sink to emit after every element, otherwise they would be bufferedesSinkBuilder.setBulkFlushMaxActions(1);// provide a RestClientFactory for custom configuration on the internally created REST client
// esSinkBuilder.setRestClientFactory(
// restClientBuilder -> {
// restClientBuilder.setDefaultHeaders(...)
// restClientBuilder.setMaxRetryTimeoutMillis(...)
// restClientBuilder.setPathPrefix(...)
// restClientBuilder.setHttpClientConfigCallback(...)
// }
// );source.addSink(esSinkBuilder.build());env.execute("flink-es");}
}
相关文章:
SpringData、SparkStreaming和Flink集成Elasticsearch
本文代码链接:https://download.csdn.net/download/shangjg03/88522188 1 Spring Data框架集成 1.1 Spring Data框架介绍 Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快…...

中国电子学会2023年09月份青少年软件编程Python等级考试试卷六级真题(含答案)
2023-09 Python六级真题 分数:100 题数:38 测试时长:60min 一、单选题(共25题,共50分) 1. 以下选项中,不是tkinter变量类型的是?(D )(2分) A.IntVar() B.StringVar() C.Do…...
)
基于STM32设计的智能水母投喂器(华为云IOT)
基于STM32设计的智能水母养殖系统 一、设计简述 1.1 项目背景 水母是一种非常美丽和神秘的生物,在许多人的眼中,它不仅是一种宽广的海洋世界中的一道美丽的风景线,同时也是一种珍贵的实验动物和养殖资源。随着水母的养殖需求不断增多,一个高效、智能、可控的水母养殖系统…...
合成数据加速机器视觉学习
虽然机器学习在基于视觉的自动化中的应用正在增长,但许多行业都面临着挑战,并难以在其计算机视觉应用中实施它。这在很大程度上是由于需要收集许多图像,以及与准确注释这些图像中的不同产品相关的挑战。 该领域的最新趋势之一是利用合成数据…...
物业管理服务预约小程序的效果如何
物业所涵盖的场景比较多,如小区住宅、办公楼、医院、度假区等,而所涵盖的业务也非常广,而在实际管理中,无论对外还是对内也存在一定难题: 1、品牌展示难、内部管理难 物业需求度比较广,设置跨区域也可以&…...

ORA-00257: Archiver error. Connect AS SYSDBA only until resolved错误解决
错误的原因:是因为服务器分配空间不足,数据库归档日志满导致系统数据库登陆失败。 解决办法:1.删除以前的日志 2.增大归档日志的容量 3.关闭归档模式 一、删除以前的容量 1.登录账号后,查看ORACLE_BASE目录 【oraclelocalhost~】$…...
)
backbone:从AlexNet到...(持续补充ing)
文章目录 Introduction(前言知识)代码参考卷积、池化输出退化1*1卷积减少或增加通道数自然的减少计算量解决了什么问题,达到了什么样的效果AlexNet整体结构如下VGGNet网络结构如下,D、E分别代表VGG-16、VGG-19下图为VGG-16ResNet结构如下DenseNet结构如下Dense Block——特…...

FiRa标准——MAC实现(二)
在IEEE 802.15.4z标准中,最关键的就是引入了STS(加扰时间戳序列),实现了安全测距,大大提高了测距应用的安全性能。在FiRa的实现中,其密钥派生功能是非常重要的一个部分,本文首先对FiRa MAC中加密…...

oracle中分组函数LISTAGG
前言 Oracle中的 GROUP_CONCAT 函数用于将多行数据合并为一行,并以指定的分隔符分隔各个值。在Oracle中,没有直接的GROUP_CONCAT函数,但可以使用 LISTAGG 函数来实现类似的功能。 如何使用 1、使用SELECT语句选择需要合并的列,…...
深度学习pytorch之hub模块
pytorchhub模块里面有很多模型 https://pytorch.org/hub/ github网址:https://github.com/pytorch/pytorch import torch model torch.hub.load(pytorch/vision:v0.10.0, fcn_resnet50, pretrainedTrue) # or # model torch.hub.load(pytorch/vision:v0.10.0, fc…...
LeetCode 2258. 逃离火灾:BFS
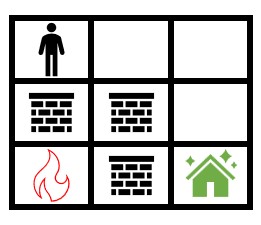
【LetMeFly】2258.逃离火灾 力扣题目链接:https://leetcode.cn/problems/escape-the-spreading-fire/ 给你一个下标从 0 开始大小为 m x n 的二维整数数组 grid ,它表示一个网格图。每个格子为下面 3 个值之一: 0 表示草地。1 表示着火的格…...
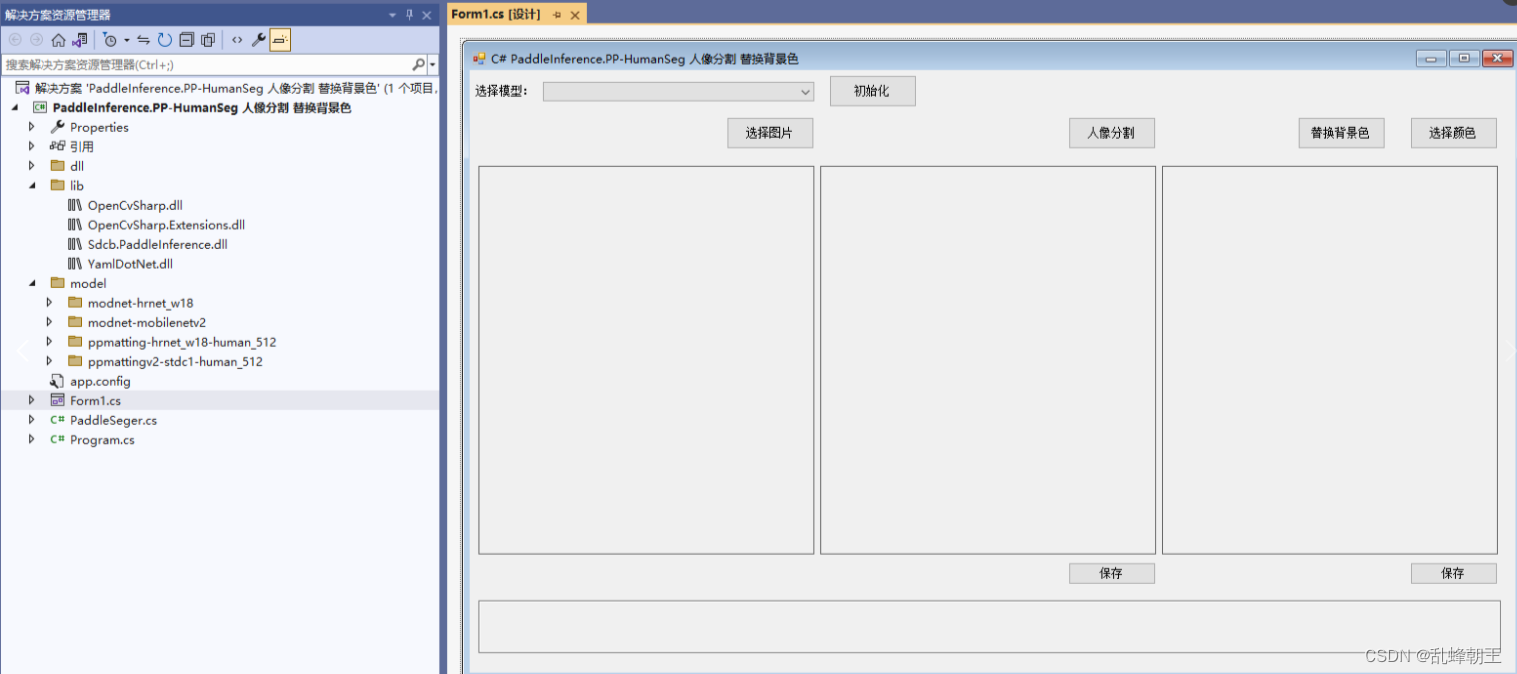
C# PaddleInference.PP-HumanSeg 人像分割 替换背景色
效果 项目 VS2022.net4.8OpenCvSharp4Sdcb.PaddleInference 包含4个分割模型 modnet-hrnet_w18 modnet-mobilenetv2 ppmatting-hrnet_w18-human_512 ppmattingv2-stdc1-human_512 代码 using OpenCvSharp; using Sdcb.PaddleInference; using System; using System.Col…...

Java 变量初始化的两种方式和优缺点比较
第一种初始化方式:(优先推荐) String fileRename null; File fileToSave null; 这种方式将变量的作用域限定在循环外部,即在整个代码块中都可以使用这些变量。初始值为null表示变量在开始时没有具体的数值。 这种方式更好的…...

15.三数之和
题目来源: leetcode题目,网址:15. 三数之和 - 力扣(LeetCode) 解题思路: 1.三重循环暴力遍历,超时原因,三重循环复杂度太高 2.双重循环哈希表,超时原因,哈…...

竞赛选题 深度学习疲劳驾驶检测 opencv python
文章目录 0 前言1 课题背景2 实现目标3 当前市面上疲劳驾驶检测的方法4 相关数据集5 基于头部姿态的驾驶疲劳检测5.1 如何确定疲劳状态5.2 算法步骤5.3 打瞌睡判断 6 基于CNN与SVM的疲劳检测方法6.1 网络结构6.2 疲劳图像分类训练6.3 训练结果 7 最后 0 前言 🔥 优…...
PROFINET和UDP、MODBUS-RTU通信速度对比实验
这篇博客我们介绍PROFINET 和MODBUS-RTU通信实验时的数据刷新速度,以及这种速度不同对控制系统带来的挑战都有哪些,在介绍这篇对比实验之前大家可以参考下面的文章链接: S7-1200PLC和SMART PLC的PN智能从站通信 S7-200 SMART 和 S7-1200PLC进行PROFINET IO通信-CSDN博客文…...
CSS3 多媒体查询、网格布局
一、CSS3多媒体查询: CSS3 多媒体查询继承了CSS2多媒体类型的所有思想,取代了查找设备的类型。CSS3根据设置自适应显示。 多媒体查询语法: media not|only mediatype and (expressions) { CSS 代码...; } not: not是用来排除掉某些特定…...
-- 配置文件优先级)
SpringBoot基础(九)-- 配置文件优先级
目录 1. 3种格式的配置文件的优先级 2. 案例演示 小结: 3. 小技巧:自动提示功能消失解决方案...
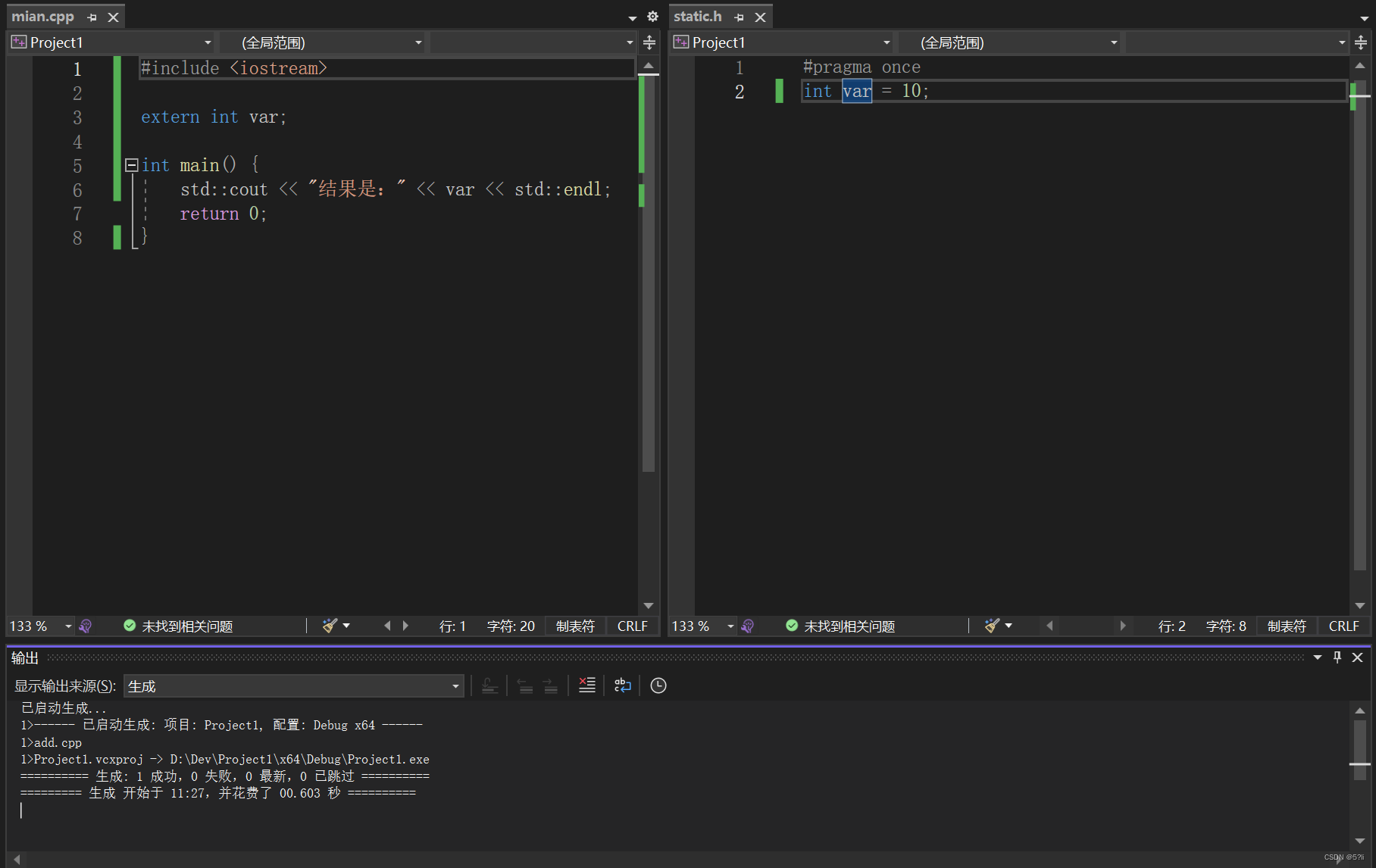
C++ static关键字
C static关键字 1、概述2、重要概念解释3、分情况案例解释3.1 static在类内使用3.2 static在类外使用案例一:案例二:案例三 1、概述 static关键字分为两种情况: 1.在类内使用 2.在类外使用 2、重要概念解释 (1)翻译…...

Anaconda Powershell Prompt和Anaconda Prompt的区别
先说结论:主要功能应该一样。区别在于powershell支持的命令更多。比如查询路径的命令pwd和列表命令ls。 Anaconda PowerShell Prompt和Anaconda Prompt是Anaconda发行版中两个不同的命令提示符工具。 Anaconda Prompt是Anaconda发布的默认命令提示符工具࿰…...

解决PyTorch那个恼人的CUDA断言错误:一个真实数据清洗案例复盘
解决PyTorch那个恼人的CUDA断言错误:一个真实数据清洗案例复盘 那是一个周五的深夜,办公室里只剩下我和咖啡机还在运转。我正在为下周要交付的图像分类模型做最后的训练,突然屏幕上跳出了那个让所有PyTorch开发者都心头一紧的错误:…...

Cats Blender插件实战指南:3步解决VRChat模型导入与优化的常见痛点
Cats Blender插件实战指南:3步解决VRChat模型导入与优化的常见痛点 【免费下载链接】cats-blender-plugin :smiley_cat: A tool designed to shorten steps needed to import and optimize models into VRChat. Compatible models are: MMD, XNALara, Mixamo, DAZ/P…...

QQ音乐加密音频解密完全指南:qmcdump让你的音乐重获自由播放权
QQ音乐加密音频解密完全指南:qmcdump让你的音乐重获自由播放权 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump …...

QMCDecode:3分钟快速解锁QQ音乐加密文件的终极指南
QMCDecode:3分钟快速解锁QQ音乐加密文件的终极指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换…...

vLLM-v0.17.1部署指南:阿里云ECS + vLLM + NAS共享模型存储
vLLM-v0.17.1部署指南:阿里云ECS vLLM NAS共享模型存储 1. vLLM框架简介 vLLM是一个专为大语言模型(LLM)设计的高性能推理和服务库,由加州大学伯克利分校的天空计算实验室(Sky Computing Lab)开发,现已发展为社区驱动的开源项目。它通过多…...

如何用Python快速获取同花顺问财数据:3步实现金融数据自动化
如何用Python快速获取同花顺问财数据:3步实现金融数据自动化 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 你是否曾经为了获取股票数据而手动翻找各种金融网站?是否因为数据格式不统一而…...
)
告别复制卡!手把手教你用92HID623CPU V5.00系统给小区门禁卡加密发卡(附防锁卡指南)
92HID623CPU V5.00系统实战:打造防复制门禁卡的完整指南 最近不少物业管理员都在头疼一个问题——传统IC卡太容易被复制了。随便找个街边小店,花个十块钱就能复制一张门禁卡,小区的安全性形同虚设。我去年接手的一个高端小区就遇到过这种情况…...

SITS2026 AGI原型系统性能数据全曝光,98.7%任务自闭环率,为什么传统评估基准已失效?
第一章:SITS2026 AGI原型系统性能数据全曝光 2026奇点智能技术大会(https://ml-summit.org) SITS2026 AGI原型系统于2026年3月在ML Summit实验室完成全栈基准测试,覆盖推理延迟、多模态对齐精度、长程记忆检索吞吐及能源效率四大核心维度。所有测试均在…...

Windows系统优化终极指南:用Winhance轻松提升电脑性能30%以上
Windows系统优化终极指南:用Winhance轻松提升电脑性能30%以上 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winh…...

软件泛化管理中的模板元编程
软件泛化管理中的模板元编程:解锁高效开发新范式 在当今快速迭代的软件开发领域,如何提升代码复用性、降低维护成本成为团队的核心挑战。模板元编程(Template Metaprogramming, TMP)作为泛型编程的高级形态,通过在编译…...