【神经网络】Transformer基础问答
1.Transforme与LSTM的区别
transformer和LSTM最大的区别就是LSTM的训练是迭代的,无法并行训练,LSTM单元计算完T时刻信息后,才会处理T+1时刻的信息,T +1时刻的计算依赖 T-时刻的隐层计算结果。而transformer的训练是并行了,就是所有字是全部同时训练的,这样就大大加快了计算效率,transformer使用了位置嵌入(positional encoding)来理解语言的顺序,使用自注意力机制和全连接层进行计算。
2.Transforme与CNN的区别
相较于CNN依靠step的卷积,Transformer其能直接获取全局信息。
3.Transformer中的Multi-head Attention
从直观讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。论文原文如下:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
举例说明different representation subspaces。如图所示,在颜色方面更加关注鲜艳亮丽的文字,而在字体方面会去注意大的、粗体的文字。

这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位强调的内容。使用多头注意力,也就是综合利用各方面的信息/特征。
4.Transformer在训练什么
Transformer在训练时就是不断的在优化自己的多头注意力层,不断调整输入与输出之间的隐层特征,调整Q、K、V的权重矩阵,使其能够学习到复杂映射关系。
5.Q、K矩阵相乘为什么最后要除以√dk
当 √dk 特别小的时候,其实除不除无所谓。无论编码器还是解码器Q、K矩阵其实本质是一个相同的矩阵。Q、K相乘其实相等于Q乘以Q的转置,这样造成结果会很大或者很小。小了还好说,大的话会使得后续做softmax继续被放大造成梯度消失,不利于梯度反向传播。
6.Transformer如何实现并行化
Transformer之所以能支持Decoder部分并行化训练,是基于以下两个关键点:
①teacher force
对于teacher force,是指在每一轮预测时,不使用上一轮预测的输出,而强制使用正确的单词,过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度,而Transformer采用这个方法,为并行化训练提供了可能,因为每个时刻的输入不再依赖上一时刻的输出,而是依赖正确的样本,而正确的样本在训练集中已经全量提供了。值得注意的一点是:Decoder的并行化仅在训练阶段,在测试阶段,因为我们没有正确的目标语句,t时刻的输入必然依赖t-1时刻的输出,这时跟之前的seq2seq就没什么区别了。
②masked self attention
多头注意力意味着多组KQV进行self-attention运算,不同于LSTM中的一步步的按部就班的运算,而是KQV的运算可以是同时计算的(这是因为每QKV的线性变换不同,计算互不影响)
注意transformer的运算复杂度,乘法运算不一定比LSTM少,但因为可以进行同步运算,因而可以依靠硬件加速。
7.Transformer在GPT和BERT中的应用?
GPT 中训练的是单向语言模型,其实就是直接应用 Transformer Decoder; Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分,不过在 Encoder 基础上还做了 Masked 操作。
BERT Transformer 使用双向 self-attention,双向 self-attention的意思就是计算的att是针对整个句子。而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。
8.为何Transformer中使用LN而不用BN?
BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。
形象点来说,假设有一个二维矩阵。列为batch-size,行为样本特征。那么BN就是竖着归一化,LN就是横着归一化。
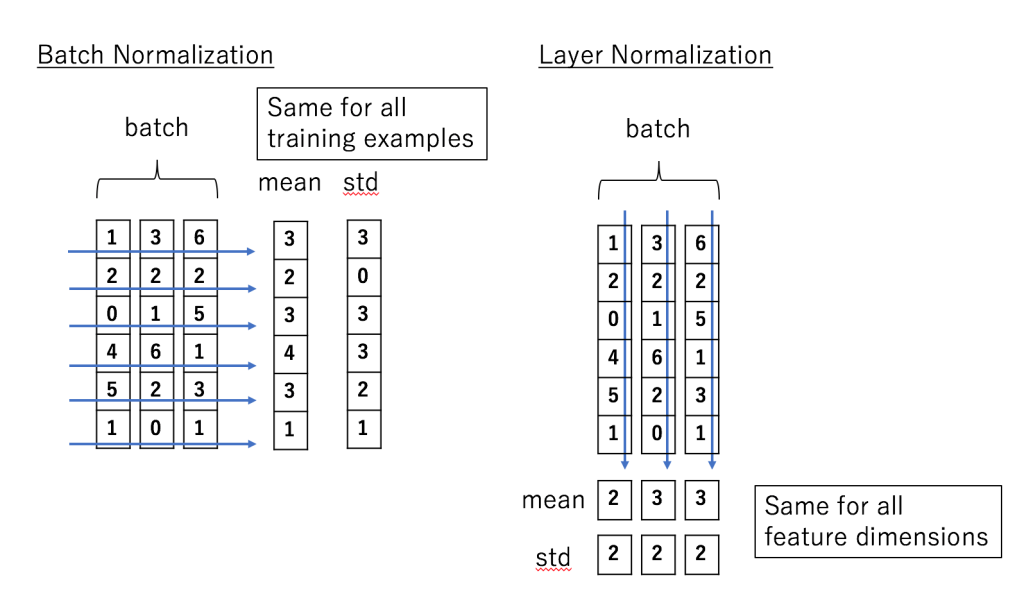
它们的出发点都是让该层参数稳定下来,避免梯度消失或者梯度爆炸,方便后续的学习。但是也有侧重点。如果特征依赖于不同样本间的统计参数,那BN更有效。因为它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系。(CV领域)而在NLP领域,LN就更加合适。因为它抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。对于NLP或者序列任务来说,一条样本的不同特征,其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的。
9.Transformer是自回归模型还是自编码模型?
自回归模型。
所谓自回归,即使用当前自己预测的字符再去预测接下来的信息。Transformer在预测阶段(机器翻译任务)会先预测第一个字,然后在第一个预测的字的基础上接下来再去预测后面的字,是典型的自回归模型。Bert中的Mask任务是典型的自编码模型,即根据上下文字符来预测当前信息。
10.Transformer中三个 Multi-Head Attention 单元的差异
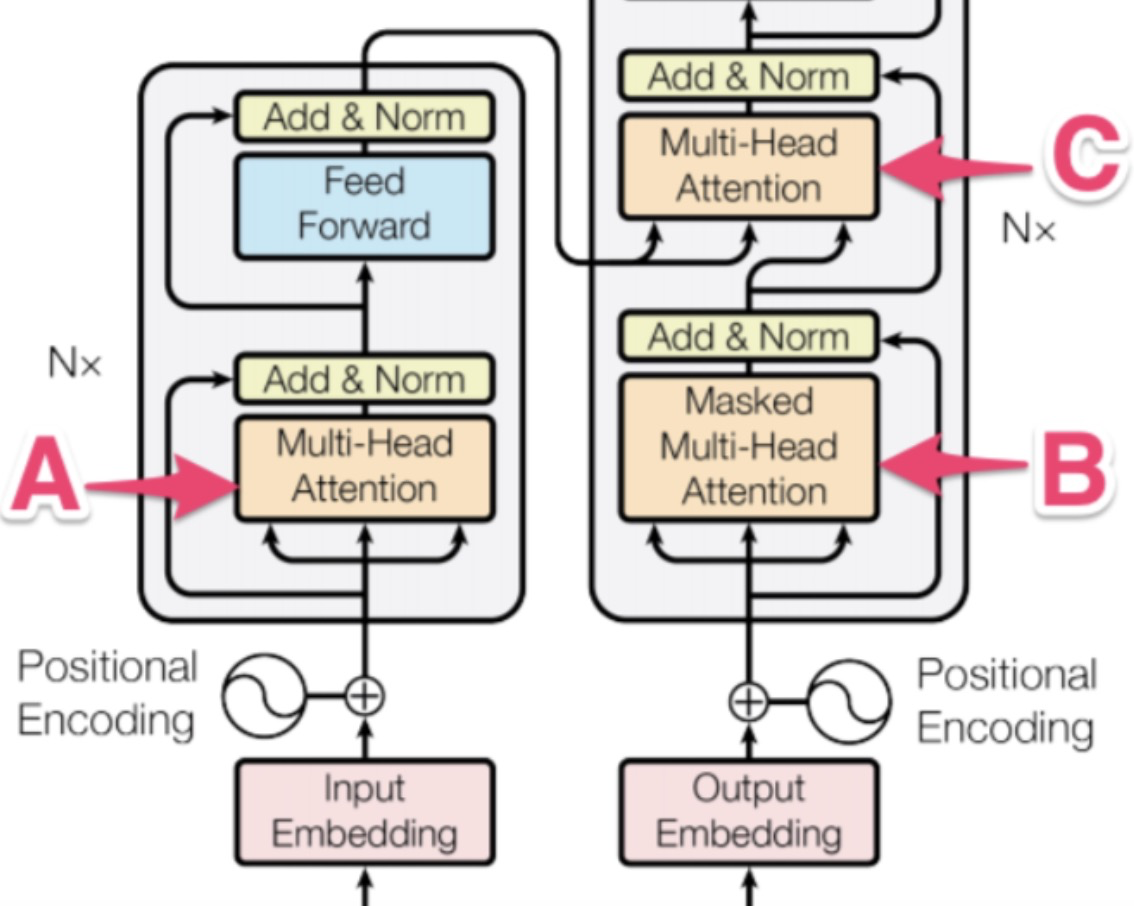
Transformer中有三个多头自注意力层,编码器中有一个,解码器中有两个。
A: 编码器中的多头自注意力层的作用是将原始文本序列信息做整合,转换后的文本序列中每个字符都与整个文本序列的信息相关。Encoder 的 Multi-Head Attention 中K=V=Q,都是输入序列的 embedding 矩阵。
B: 解码器的第一个多头自注意力层比较特殊,原论文给其起名叫Masked Multi-Head-Attention。其一方面也有上图介绍的作用,即对输入文本做整合(对与翻译任务来说,编码器的输入是翻译前的文本,解码器的输入是翻译后的文本)。另一个任务是做掩码,防止信息泄露。拓展解释一下就是在做信息整合的时候,第一个字符其实不应该看到后面的字符,第二个字符也只能看到第一个、第二个字符的信息,以此类推。Decoder 中提取 Outputs 序列 Multi-Head Attention。他的Q、K、V都是相同的。但是相比于 A 的 Attention,他多了 Mask 单元来防止 Outputs 序列发生泄漏。
C :解码器的第二个多头自注意力层与编码器的第一个多头自注意力层功能是完全一样的。不过输入需要额外强调下,我们都知道多头自注意力层是通过计算QKV三个矩阵最后完成信息整合的。在这里,Q是解码器整合后的信息,KV两个矩阵是编码器整合后的信息,是两个完全相同的矩阵。QKV矩阵相乘后,翻译前与翻译后的文本也做了充分的交互整合。至此最终得到的向量矩阵用来做后续下游工作。Decoder 中将输入序列与 Outputs 序列交叉的部分,所以他的上下文矩阵Q来自上一个 Decoder 的 Multi-Head Attention 单元的输出,K,V来自 encoder 的输出矩阵。
11.Transformer和seq2seq的差异
seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。
Transformer不但对seq2seq模型这两点缺点有了实质性的改进(多头交互式attention模块),而且还引入了self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力,并且Transformer并行计算的能力远远超过了seq2seq系列模型。
相关文章:
【神经网络】Transformer基础问答
1.Transforme与LSTM的区别 transformer和LSTM最大的区别就是LSTM的训练是迭代的,无法并行训练,LSTM单元计算完T时刻信息后,才会处理T1时刻的信息,T 1时刻的计算依赖 T-时刻的隐层计算结果。而transformer的训练是并行了࿰…...

制定防火墙策略的步骤和建议
制定防火墙策略是保护企业网络环境安全的关键一步。下面是一些制定防火墙策略的步骤和建议,供参考: 识别网络资产:确定企业网络环境中所有的网络资产,包括服务器、应用程序、数据库、移动设备和终端用户设备等,并进行…...
新必应(New Bing)国内申请与使用教程
微软的新必应(New Bing)基于GPT4模型,比ChatGPT的GPT3.5模型领先半个世代。并且集成了Edge浏览器的数据资源,功能更加强大。经过不断的踩坑,终于申请到了New Bing的使用权限,且国内网络也能够正常使用&…...
博客系统——项目测试报告
目录 前言 博客系统——项目介绍 1、测试计划 1.1、功能测试 1.1.1、编写测试用例 1.1.2、实际执行步骤 1.2、使用Selenium进行Web自动化测试 1.2.1、引入依赖 1.2.2、提取共性,实现代码复用 1.2.3、创建测试套件类 1.2.4、博客登录页自动化测试 1.2.5、…...
Macbook M1 安装PDI(Kettle) 9.3
Macbook M1 安装PDI(Kettle) 9.3 当前 PDI(Kettle)最新版为9.3,依赖Java JDK 11。因为没有专门用于 M1的程序,需要下载并安装x86_64架构的JDK及依赖软件,并 “强制在Intel模式下运行shell” 的方式来实现 Kettle 的正…...
机器学习——模型评估
在学习得到的模型投放使用之前,通常需要对其进行性能评估。为此,需使用一个“测试集”(testing set)来测试模型对新样本的泛化能力,然后以测试集上的“测试误差( tootino error)作为泛化误差的近似。我们假设测试集是从样本真实分…...
react react-redux学习记录
react react-redux学习记录1.原理2.怎么用呢2.1 容器组件2.2UI组件2.3 App.jsx3.简化3.1简写mapDispatch3.2 Provider组件的使用3.3整合UI组件和容器组件1.原理 UI组件:不能使用任何redux的api,只负责页面的呈现、交互等。 容器组件:负责和redux通信&…...
nodejs环境配置
啥是node.js 简单理解就是js运行环境 啥是npm 简单理解就是nodejs包管理工具,全称Node Package Manager 啥是cnpm npm的开源镜像,在国内使用cnpm替代npm可以起到加速的效果 https://npmmirror.com/ ①安装node.js https://nodejs.org/en/download/ 下载…...

数据治理之元数据管理Atlas
数据治理之元数据管理的利器——Atlas 一、数据治理与元数据管理 1.1 背景 为什么要做数据治理? 业务繁多,数据繁多,业务数据不断迭代。人员流动,文档不全,逻辑不清楚,对于数据很难直观理解,…...

15 Nacos客户端实例注册源码分析
Nacos客户端实例注册源码分析 实例客户端注册入口 流程图: 实际上我们在真实的生产环境中,我们要让某一个服务注册到Nacos中,我们首先要引入一个依赖: <dependency><groupId>com.alibaba.cloud</groupId>&l…...

C++将派生类赋值给基类(向上转型)
1.将派生类对象赋值给基类对象 #include <iostream> using namespace std;//基类 class A{ public:A(int a); public:void display(); public:int m_a; }; A::A(int a): m_a(a){ } void A::display(){cout<<"Class A: m_a"<<m_a<<endl; }//…...

使用Platform Designer创建Nios II 最小系统
Nios II简介 Nios II 软核处理器十多年前就有了,它和xilinx的MicroBlaze类似,性能相比硬核处理器要差得多,工程应用也不是很多,那还有必须学习一下吗?我个人认为了解一下Nios II开发流程,对intel FPGA开…...
CD销售管理系统
技术:Java、JSP等摘要:二十一世纪是一个集数字化,网络化,信息化的,以网络为核心的社会。中国的网民充分领略到“畅游天地间,网络无极限” 所带来的畅快。随着Internet的飞速发展,使得网络的应用…...

华为OD机试模拟题 用 C++ 实现 - 玩牌高手(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明玩牌高手题目输入输出描述示例一输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为…...

Hive 的Stage如何划分?
Hive 的Stage如何划分,也是Hive SQL需要优化的一个点,这个问题,我也是在实际的工作中遇到的。所以我查询了网络的解答并记录下来,以便日后复习。以下是主要内容,enjoy~~~ 一个 Hive 任务会包含一个或多个 stage&#…...

《嵌入式应用开发》实验一、开发环境搭建与布局(上)
1. 搭建开发环境 去官网(https://developer.android.google.cn/studio)下载 Android Studio。 安装SDK(默认Android 7.0即可) 全局 gradle 镜像配置 在用户主目录下的 .gradle 文件夹下面新建文件 init.gradle,内容为…...
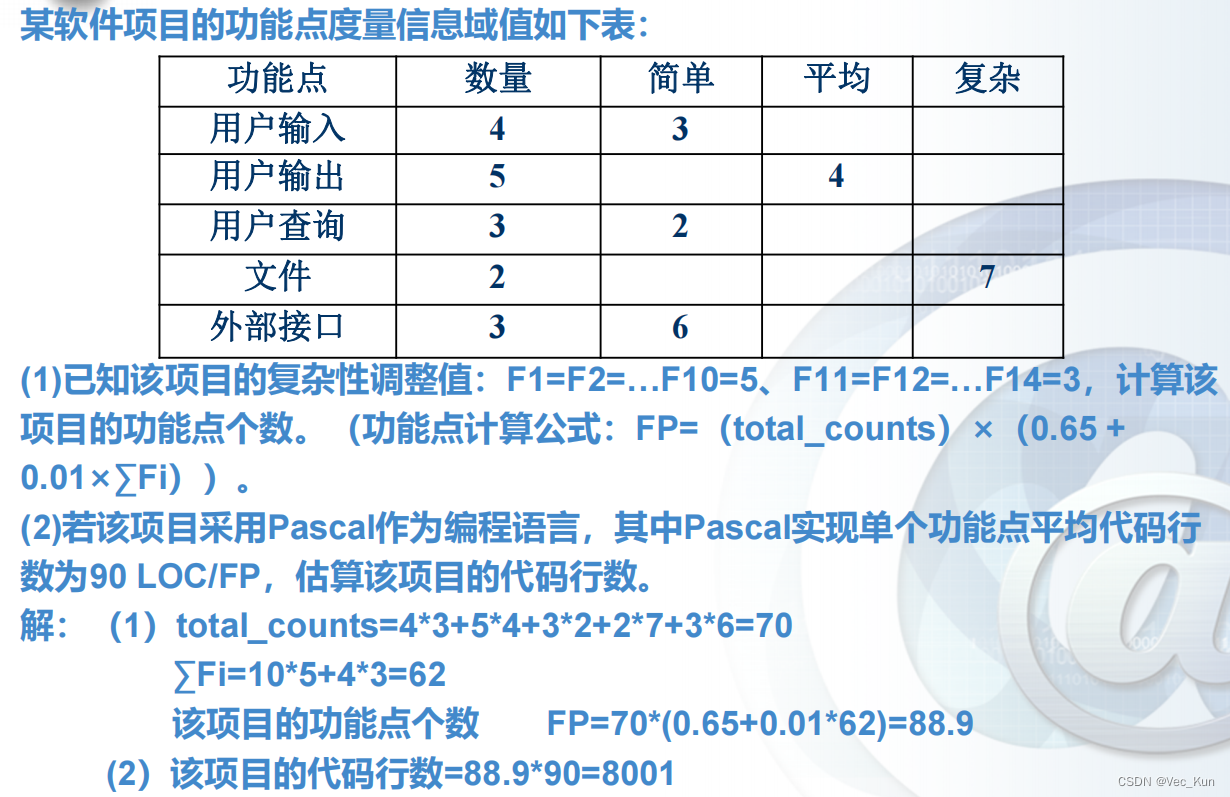
电子科技大学软件工程期末复习笔记(五):生产率和工作度量
目录 前言 重点一览 软件产品度量 测量软件生产率的两种方法 基于LOC测量 例题: 优点 缺点 基于功能点测量 例题: 本章小结 前言 本复习笔记基于王玉林老师的课堂PPT与复习大纲,供自己期末复习与学弟学妹参考用。 重点一览 这一部分内…...
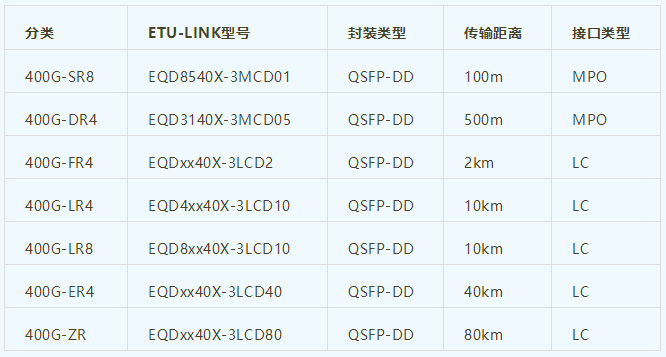
400G光模块知识大全
400G光模块是目前高速传输领域中的一种先进产品,被广泛应用于高性能数据中心、通信网络、大规模计算、云计算等领域。本文将从400G光模块的定义、技术、产品型号、应用场景以及未来发展方向进行详细介绍。一、什么是400G光模块?400G光模块是指传输速率达…...
【Linux】零成本在家搭建自己的私人服务器解决方案
我这个人自小时候以来就特喜欢永久且免费的东西,也因此被骗过(花巨款买了永久超级会员最后就十几天)。 长大后骨子里也是喜欢永久且免费的东西,所以我不买服务器,用GitHubPage或者GiteePage搭建自己的静态私人博客&…...

Python 多线程、多进程和协程
一、多线程 threading 模块 threading 模块对象 对象描述Thread表示一个执行线程的对象Lock锁原语对象(与 thread 模块中的锁一样)RLock可重入锁对象,使单一线程可以(再次)获得已持有的锁(递归锁&#x…...
)
第53节:倾斜模型osgb转3dtiles(免费工具)
1、下载cesiumlab工具 下载地址 2、启动cesiumlab,进行登录访问(网页版) 没有账号的可以用手机号注册一个 3、 选择倾斜模型切片 4、选择倾斜模型数据路径 5、设置空间参考、零点坐标 如果选择完osgb数据后能自动带出来则不用设置&…...

开源轻量CRM系统skill-twenty-crm技术解析与全栈部署指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫devchaudhary24k/skill-twenty-crm。光看这个名字,你可能会有点懵,这“Skill Twenty CRM”到底是个啥?作为一个在软件开发和团队协作领域摸爬滚打多年的老手&#x…...

别再让电池充不满!用CN3791芯片设计太阳能充电电路,这几个调试坑我帮你踩了
太阳能充电电路实战:CN3791芯片调试避坑指南 当阳光洒在太阳能板上,理论上我们应该获得源源不断的清洁能源。但现实往往比理想骨感得多——尤其当你发现精心设计的CN3791充电电路始终无法将锂电池充满时。这不是芯片的错,而是我们在参数设置和…...

LLM应用开发资源导航:从Awesome List到实战项目构建
1. 项目概述:当“Awesome”遇见LLM应用如果你最近在GitHub上逛过,或者对大型语言模型(LLM)的应用开发感兴趣,那么“Shubhamsaboo/awesome-llm-apps”这个仓库大概率已经躺在你的浏览器书签或者GitHub星标列表里了。它不…...

晶圆为何是圆形而芯片是方形?揭秘半导体制造的工程智慧
1. 项目概述:一个看似简单却充满工程智慧的谜题“为什么晶圆是圆的,而芯片是方的?” 这个问题,乍一听像是半导体行业里一个有趣的脑筋急转弯,但它背后却串联起了从材料科学、物理化学到精密制造、经济学乃至数学几何的…...

Taotoken的Token Plan套餐相比按量计费能为长期项目节省多少
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐相比按量计费能为长期项目节省多少 对于需要长期、稳定调用大模型API的项目而言,成本的可预测…...

树莓派驱动MAX31855热电偶传感器:从SPI通信到高精度测温实践
1. 项目概述:从热电偶到Python读数在嵌入式开发、工业监控或者任何需要精确测温的项目里,热电偶(Thermocouple)往往是工程师们的首选传感器。它结构简单、皮实耐用,而且测温范围能从零下两百多度一直覆盖到上千度&…...


5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南
5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南 【免费下载链接】BACnet4J BACnet/IP stack written in Java. Forked from http://sourceforge.net/projects/bacnet4j/ 项目地址: https://gitcode.com/gh_mirrors/ba/BACnet4J 在智能建筑和工业…...

深度学习立体匹配:从MC-CNN架构解析到工程实践优化
1. 项目概述:从传统到深度,立体匹配的范式革新在计算机视觉领域,立体匹配是一个经典且核心的问题,它的目标是从一对经过校正的左右图像中,为每个像素找到其在另一幅图像中的对应点,从而计算出场景的深度信息…...