使用ResponseSelector实现校园招聘FAQ机器人
本文主要介绍使用ResponseSelector实现校园招聘FAQ机器人,回答面试流程和面试结果查询的FAQ问题。FAQ机器人功能分为业务无关的功能和业务相关的功能2类。
一.data/nlu.yml文件
与普通意图相比,ResponseSelector训练数据中的意图采用group/intent格式(检索意图)。比如,普通意图intent: greet,而后者intent: faq/notes。如下所示:
version: "3.1"
nlu:- intent: goodbyeexamples: |- 拜拜- 再见- 拜- 退出- 结束- intent: greetexamples: |- 你好- 您好- hello- hi- 喂- 在么- intent: faq/notesexamples: |- 应聘ACME校园招聘职位的注意事项?- intent: faq/work_locationexamples: |- 校园招聘录取的应届生主要工作地点在哪里?- intent: faq/max_job_requestexamples: |- 最多申请几个职位?- intent: faq/auditexamples: |- 各阶段审核说明- intent: faq/write_exam_participateexamples: |- 怎样参加笔试?- intent: faq/write_exam_locationexamples: |- 笔试考试地点如何安排?- intent: faq/write_exam_againexamples: |- 笔试只安排一次吗?我笔试当天没有参加,是否还有再次笔试的机会?- intent: faq/write_exam_with-out-offerexamples: |- 如果我没有收到笔试通知,但我很想进入ACME,能否直接进入考场参加考试?- intent: faq/interview_arrangementexamples: |- 面试什么时候开始?会提前多少天通知面试安排?- intent: faq/interview_timesexamples: |- 一般会安排几次面试?- intent: faq/interview_fromexamples: |- 面试的形式是怎样的?是单独面试还是小组面试?- intent: faq/interview_clothingexamples: |- 对面试的服装有什么具体的要求?- intent: faq/interview_paperworkexamples: |- 面试时需要携带什么资料?- intent: faq/interview_resultexamples: |- 如何查询面试结果?
二.data/responses.yml文件
主要是根据相关intent来进行相应的response。比如,utter_faq/notes的response对应于意图faq/notes。如下所示:
version: "3.1"
responses:utter_faq/notes:- text: 1、登在校园招聘板块内的职位信息才适用于应届毕业生招聘,请所有的应届毕业生去校园招聘的版块寻找您感兴趣的职位。2、列出的每个职位的要求是该职位的最低要求,为了保证您应聘的成功率,希望您严格按照职位的要求考虑您的选择。3、提交成功后,在招聘结束前,您将不能修改或再次提交简历,因此,请于仔细确认填写信息后提交简历。utter_faq/work_location:- text: 招聘信息中包含各职位的工作地点内容,请参考各职位内容的详细介绍。utter_faq/max_job_request:- text: 对于校园招聘,最多申请2个职位。utter_faq/audit:- text: 1、简历审核:应聘者需要通过ACME网站,填写并提交个人简历,ACME的招聘专员将对收取的简历进行认真的审查和筛选。了解应聘者的情况,并筛选出符合职位要求的简历,同时确认简历记载内容是否属实。2、笔试审核:ACME技术类测试主要针对应聘者的专业技能进行检查和评价。3、面试审核:经过实施评价应聘者基本素质的第一阶段面试和评价专业知识的第二阶段面试,对应聘者是否符合ACME人才理念以及应聘者的工作能力做出客观的综合评价,从而决定是否录用该应聘者。utter_faq/write_exam_participate:- text: 通过简历审核的应聘者,我们将采用短信、e-mail、ACME公告栏以及电话通知的方式告知您utter_faq/write_exam_location:- text: 笔试地点将根据您在简历中填写的学校所在城市进行统筹安排utter_faq/write_exam_again:- text: 校园招聘的大规模的笔试仅安排一次,请收到笔试通知的同学认真对待笔试机会。utter_faq/write_exam_with-out-offer:- text: 由于我们是按照严格的招聘流程筛选出的笔试名单,所以非常抱歉,对于没有收到笔试通知的同学,就不能参加本次校园招聘的笔试。utter_faq/interview_arrangement:- text: 不同的职位面试进度安排不同,除特殊安排外,笔试结束一周左右会安排面试。utter_faq/interview_times:- text: 一般情况下,业务部门和人力资源部会同时或者分别安排一次面试。个别特殊职位需要2次及以上的面试。utter_faq/interview_from:- text: 面试一般以单独面试的形式进行,但根据各公司的面试安排,也会进行小组面试。utter_faq/interview_clothing:- text: 面试着装没有统一要求,但建议您尽量穿着较为正式的职业装参加。utter_faq/interview_paperwork:- text: 面试时,请您携带可以证明您身份的有效证件,有特殊要求的职位请携带好能证明您专业水平的证书原件以及复印件。utter_faq/interview_result:- text: 我们会通过邮件或电话的形式,通知您面试结果。
三.data/stories.yml文件
story即场景编排,如下所示:
version: "3.1"
stories:- story: greetsteps:- intent: greet- action: utter_greet- story: say goodbyesteps:- intent: goodbye- action: utter_goodbye
四.data/rules.yml文件
定义了规则名"respond to FAQs",当检索意图是faq时,执行utter_faq,如下所示:
version: "3.1"
rules:- rule: respond to FAQssteps:- intent: faq- action: utter_faq
五.domain.yml文件
该文件主要包含intents、responses和actions等信息,如下所示:
version: "3.1"session_config:session_expiration_time: 60carry_over_slots_to_new_session: true
intents:- goodbye- greet- faq
responses:utter_greet:- text: 你好,我是 Silly,我是一个基于 Rasa 的 FAQ 机器人utter_goodbye:- text: 再见!utter_default:- text: 系统不明白您说的话
actions:- utter_goodbye- utter_greet- utter_default- utter_faq
六.config.yml文件
主要是pipeline和policies设置。前者基本思路是分词、特征化、意图识别和实体抽取,后者定义各种策略。特别注意,FAQ机器人需要将ResponseSelector组件加入NLU的流水线,并且还需要启用RulePolicy和设置rule(参考四.data/rules.yml文件)。如下所示:
recipe: default.v1
language: "zh"pipeline:
- name: JiebaTokenizer
- name: LanguageModelFeaturizermodel_name: "bert"
# model_weights: "bert-base-chinese"model_weights: "L:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese"
- name: "DIETClassifier"epochs: 100tensorboard_log_directory: ./loglearning_rate: 0.001
- name: "ResponseSelector"policies:
- name: MemoizationPolicy
- name: TEDPolicy
- name: RulePolicy
assistant_id: 20231109-225257-frayed-branch
七.endpoints.yml文件
action_endpoint、tracker_store和event_broker通常使用默认配置,如下所示:
# This file contains the different endpoints your bot can use.# Server where the models are pulled from.
# https://rasa.com/docs/rasa/user-guide/running-the-server/#fetching-models-from-a-server/#models:
# url: http://my-server.com/models/default_core@latest
# wait_time_between_pulls: 10 # [optional](default: 100)# Server which runs your custom actions.
# https://rasa.com/docs/rasa/core/actions/#custom-actions/action_endpoint:url: "http://localhost:5055/webhook"# Tracker store which is used to store the conversations.
# By default the conversations are stored in memory.
# https://rasa.com/docs/rasa/api/tracker-stores/#tracker_store:
# type: redis
# url: <host of the redis instance, e.g. localhost>
# port: <port of your redis instance, usually 6379>
# db: <number of your database within redis, e.g. 0>
# password: <password used for authentication>#tracker_store:
# type: mongod
# url: <url to your mongo instance, e.g. mongodb://localhost:27017>
# db: <name of the db within your mongo instance, e.g. rasa>
# username: <username used for authentication>
# password: <password used for authentication># Event broker which all conversation events should be streamed to.
# https://rasa.com/docs/rasa/api/event-brokers/#event_broker:
# url: localhost
# username: username
# password: password
# queue: queue
八.模型训练和运行Rasa服务器
1.模型训练
rasa train
2.运行Rasa服务器
rasa run --cors "*"
3.开启http server服务
python -m http.server
说明:测试FAQ机器人可以通过Web页面,还可通过命令行rasa shell --debug。
九.PyCharm调试Rasa代码
1.Rasa中的DAG
Rasa中DAG图节点可能是NLP组件,也可能是Policy组件,本质上都可以抽象为Graph Component。如下所示:
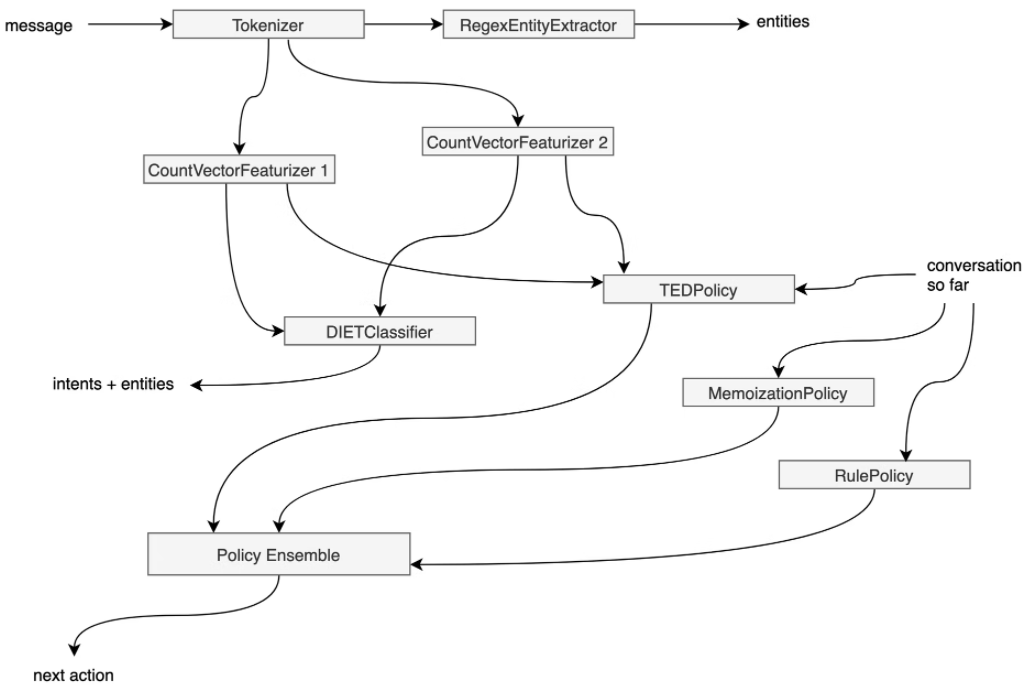
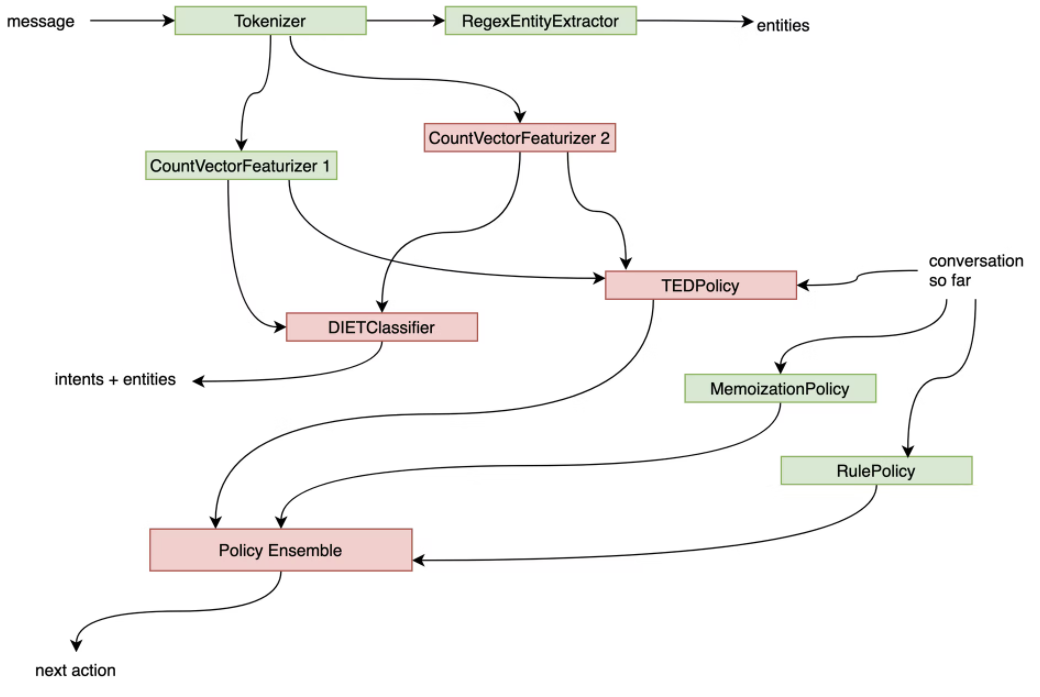
Rasa会把训练过的Component缓存到磁盘中,当某个Component发生变化的时候,比如CountVectorizer,只会把依赖CountVectorizer的组件(DIETClassifier、TEDPolicy和Policy Ensemble)再训练,而其它的组件不变。如下所示:
2.PyCharm调试Rasa代码
PyCharm调试Rasa源码也比较方便,主要是设置脚本路径、参数和工作目录,如下所示:
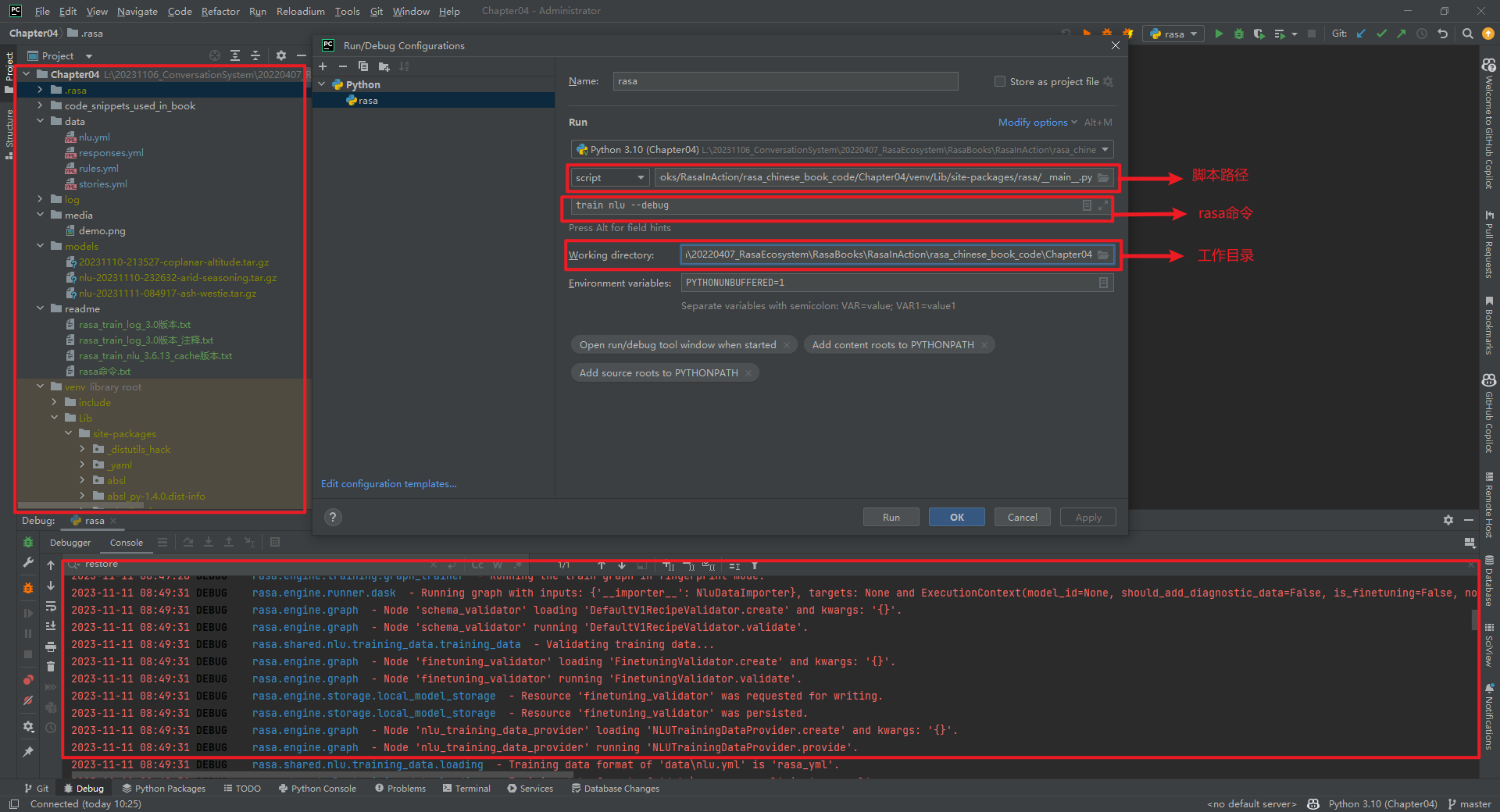
然后就可以调试训练数据是如何被处理的,DAG是如何被构建的,Component是如何被加载和运行的,最终模型文件是如何被存储的等。Rasa中的fingerprint_key可能是唯一标识的意思。
3.rasa train nlu --debug日志
通过控制台输出日志,可辅助理解Rasa执行过程,以及源码调试,如下所示:
L:\20231106_ConversationSystem\20220407_RasaEcosystem\RasaBooks\RasaInAction\rasa_chinese_book_code\Chapter04\venv\Scripts\python.exe "D:/Program Files/JetBrains/PyCharm 2023.1.3/plugins/python/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 38019 --file L:\20231106_ConversationSystem\20220407_RasaEcosystem\RasaBooks\RasaInAction\rasa_chinese_book_code\Chapter04\venv\Lib\site-packages\rasa\__main__.py train nlu --debug
Connected to pydev debugger (build 232.9559.58)2023-11-10 23:24:32 DEBUG h5py._conv - Creating converter from 7 to 5
2023-11-10 23:24:32 DEBUG h5py._conv - Creating converter from 5 to 72023-11-10 23:26:17 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\nlu.yml' is 'rasa_yml'. # nul.yml文件(rasa_yml数据格式)
2023-11-10 23:26:17 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\responses.yml' is 'rasa_yml'. # responses.yml文件(rasa_yml数据格式)
2023-11-10 23:26:17 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\rules.yml' is 'unk'. # rules.yml文件(unk数据格式)
2023-11-10 23:26:17 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\stories.yml' is 'unk'. # stories.yml文件(unk数据格式)2023-11-10 23:26:33 DEBUG rasa.telemetry - Skipping telemetry reporting: no license hash found. # 跳过telemetry报告:找不到许可证哈希。
2023-11-10 23:27:24 DEBUG rasa.engine.training.graph_trainer - Starting training. # 开始训练2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'train_JiebaTokenizer0' loading 'FingerprintComponent.create' and kwargs: '{}'. # train_JiebaTokenizer0
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'run_JiebaTokenizer0' loading 'FingerprintComponent.create' and kwargs: '{}'. # run_JiebaTokenizer0
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'run_LanguageModelFeaturizer1' loading 'FingerprintComponent.create' and kwargs: '{}'. # run_LanguageModelFeaturizer1
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'train_DIETClassifier2' loading 'FingerprintComponent.create' and kwargs: '{}'. # train_DIETClassifier2
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'train_ResponseSelector3' loading 'FingerprintComponent.create' and kwargs: '{}'. # train_ResponseSelector3
2023-11-10 23:27:24 DEBUG rasa.engine.training.graph_trainer - Running the train graph in fingerprint mode. # 在fingerprint模式下运行训练图。
2023-11-10 23:27:24 DEBUG rasa.engine.runner.dask - Running graph with inputs: {'__importer__': NluDataImporter}, targets: None and ExecutionContext(model_id=None, should_add_diagnostic_data=False, is_finetuning=False, node_name=None).
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'schema_validator' loading 'DefaultV1RecipeValidator.create' and kwargs: '{}'. # schema_validator
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'schema_validator' running 'DefaultV1RecipeValidator.validate'. # schema_validator
2023-11-10 23:27:24 DEBUG rasa.shared.nlu.training_data.training_data - Validating training data... # 验证训练数据...
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'finetuning_validator' loading 'FinetuningValidator.create' and kwargs: '{}'. # finetuning_validator
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'finetuning_validator' running 'FinetuningValidator.validate'. # finetuning_validator
2023-11-10 23:27:24 DEBUG rasa.engine.storage.local_model_storage - Resource 'finetuning_validator' was requested for writing. # finetuning_validator
2023-11-10 23:27:24 DEBUG rasa.engine.storage.local_model_storage - Resource 'finetuning_validator' was persisted. # finetuning_validator
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'nlu_training_data_provider' loading 'NLUTrainingDataProvider.create' and kwargs: '{}'. # nlu_training_data_provider
2023-11-10 23:27:24 DEBUG rasa.engine.graph - Node 'nlu_training_data_provider' running 'NLUTrainingDataProvider.provide'. # nlu_training_data_provider
2023-11-10 23:27:24 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\nlu.yml' is 'rasa_yml'. # nul.yml文件(rasa_yml数据格式)
2023-11-10 23:27:25 DEBUG rasa.shared.nlu.training_data.loading - Training data format of 'data\responses.yml' is 'rasa_yml'. # responses.yml文件(rasa_yml数据格式)
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'train_JiebaTokenizer0' running 'FingerprintComponent.run'. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '963f41cf1cdb9cadc8914a14e070fb8e' for class 'JiebaTokenizer'. # 计算类'JiebaTokenizer'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'run_JiebaTokenizer0' running 'FingerprintComponent.run'. # run_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key 'ae36d2dae4cc78840b153d44fee8f81a' for class 'JiebaTokenizer'. # 计算类'JiebaTokenizer'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'run_LanguageModelFeaturizer1' running 'FingerprintComponent.run'. # run_LanguageModelFeaturizer1
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key 'f2bfce545dd2c1c12fb895b075954315' for class 'LanguageModelFeaturizer'. # 计算类'LanguageModelFeaturizer'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'train_DIETClassifier2' running 'FingerprintComponent.run'. # train_DIETClassifier2
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '1d3616cf6980e5f0f38aa9ceb51f1e7a' for class 'DIETClassifier'. # 计算类'DIETClassifier'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'train_ResponseSelector3' running 'FingerprintComponent.run'. # train_ResponseSelector3
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key 'b91434757a05a4178cdc7f7882cfd9aa' for class 'ResponseSelector'. # 计算类'ResponseSelector'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.training.graph_trainer - Running the pruned train graph with real node execution. # 使用真实节点执行修剪的训练图。
2023-11-10 23:27:25 DEBUG rasa.engine.runner.dask - Running graph with inputs: {'__importer__': NluDataImporter}, targets: None and ExecutionContext(model_id=None, should_add_diagnostic_data=False, is_finetuning=False, node_name=None).
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'nlu_training_data_provider'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'nlu_training_data_provider'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '1fbfa24243412736ce1002efbeba382f' for class 'NLUTrainingDataProvider'. # 计算类'NLUTrainingDataProvider'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'nlu_training_data_provider' loading 'PrecomputedValueProvider.create' and kwargs: '{}'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'nlu_training_data_provider' running 'PrecomputedValueProvider.get_value'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'nlu_training_data_provider'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'nlu_training_data_provider'. # nlu_training_data_provider
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'train_JiebaTokenizer0'. # train_JiebaTokenizer0
2023-11-10 23:27:25 INFO rasa.engine.training.hooks - Starting to train component 'JiebaTokenizer'. # 开始训练组件'JiebaTokenizer'。
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'train_JiebaTokenizer0'. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '963f41cf1cdb9cadc8914a14e070fb8e' for class 'JiebaTokenizer'. # 计算类'JiebaTokenizer'的指纹密钥
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'train_JiebaTokenizer0' loading 'JiebaTokenizer.create' and kwargs: '{}'. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Node 'train_JiebaTokenizer0' running 'JiebaTokenizer.train'. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'train_JiebaTokenizer0'. # train_JiebaTokenizer0
2023-11-10 23:27:25 INFO rasa.engine.training.hooks - Finished training component 'JiebaTokenizer'. # 完成训练组件'JiebaTokenizer'。
2023-11-10 23:27:25 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'train_JiebaTokenizer0'. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.training.hooks - Caching 'Resource' with fingerprint_key: '963f41cf1cdb9cadc8914a14e070fb8e' and output_fingerprint '141a681b80024953b9b7865284b9fece'.
2023-11-10 23:27:25 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_JiebaTokenizer0' was requested for reading. # train_JiebaTokenizer0
2023-11-10 23:27:25 DEBUG rasa.engine.storage.resource - Skipped caching resource 'train_JiebaTokenizer0' as no persisted data was found. # 跳过缓存资源'train_JiebaTokenizer0',因为找不到持久化数据。
2023-11-10 23:27:25 DEBUG rasa.engine.caching - Caching output of type 'Resource' succeeded. # 缓存类型为'Resource'的输出成功。
2023-11-10 23:27:26 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'run_JiebaTokenizer0'. # run_JiebaTokenizer0
2023-11-10 23:27:26 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'run_JiebaTokenizer0'. # run_JiebaTokenizer0
2023-11-10 23:27:26 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '496a8741f1dfb458bbfedb535d343623' for class 'JiebaTokenizer'. # 计算类'JiebaTokenizer'的指纹密钥
2023-11-10 23:27:26 DEBUG rasa.engine.graph - Node 'run_JiebaTokenizer0' loading 'JiebaTokenizer.load' and kwargs: '{'resource': Resource(name='train_JiebaTokenizer0', output_fingerprint='141a681b80024953b9b7865284b9fece')}'.
2023-11-10 23:27:26 DEBUG rasa.engine.graph - Node 'run_JiebaTokenizer0' running 'JiebaTokenizer.process_training_data'. # run_JiebaTokenizer0# jieba分词
Building prefix dict from the default dictionary ...
2023-11-10 23:27:26 DEBUG jieba - Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
2023-11-10 23:27:26 DEBUG jieba - Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.116 seconds.
2023-11-10 23:27:27 DEBUG jieba - Loading model cost 1.116 seconds.
Prefix dict has been built successfully.
2023-11-10 23:27:27 DEBUG jieba - Prefix dict has been built successfully.2023-11-10 23:27:27 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'run_JiebaTokenizer0'.
2023-11-10 23:27:27 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'run_JiebaTokenizer0'.
2023-11-10 23:27:27 DEBUG rasa.engine.training.hooks - Caching 'TrainingData' with fingerprint_key: '496a8741f1dfb458bbfedb535d343623' and output_fingerprint '1baa8435dc0351e013e3b8f3635e83d6'.
2023-11-10 23:27:27 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'run_LanguageModelFeaturizer1'.
2023-11-10 23:27:27 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'run_LanguageModelFeaturizer1'.
2023-11-10 23:27:27 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key 'de5a4adf999a20fb8e5716903003508c' for class 'LanguageModelFeaturizer'.
2023-11-10 23:27:27 DEBUG rasa.engine.graph - Node 'run_LanguageModelFeaturizer1' loading 'LanguageModelFeaturizer.load' and kwargs: '{}'.
2023-11-10 23:27:28 DEBUG rasa.nlu.featurizers.dense_featurizer.lm_featurizer - Loading Tokenizer and Model for bert2023-11-10 23:27:32 DEBUG rasa.engine.graph - Node 'run_LanguageModelFeaturizer1' running 'LanguageModelFeaturizer.process_training_data'.
2023-11-10 23:27:41 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'run_LanguageModelFeaturizer1'.
2023-11-10 23:27:41 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'run_LanguageModelFeaturizer1'.
2023-11-10 23:27:41 DEBUG rasa.engine.training.hooks - Caching 'TrainingData' with fingerprint_key: 'de5a4adf999a20fb8e5716903003508c' and output_fingerprint '1192d8329eb2a6d87f6e965765d10871'.
2023-11-10 23:27:41 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'train_DIETClassifier2'.
2023-11-10 23:27:41 INFO rasa.engine.training.hooks - Starting to train component 'DIETClassifier'.
2023-11-10 23:27:41 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'train_DIETClassifier2'.
2023-11-10 23:27:41 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '7d66b69a551ffbc2a45237a02ffc5aa7' for class 'DIETClassifier'.
2023-11-10 23:27:41 DEBUG rasa.engine.graph - Node 'train_DIETClassifier2' loading 'DIETClassifier.create' and kwargs: '{}'.2023-11-10 23:27:41 DEBUG rasa.engine.graph - Node 'train_DIETClassifier2' running 'DIETClassifier.train'.
2023-11-10 23:27:41 DEBUG rasa.nlu.classifiers.diet_classifier - No label features found. Computing default label features.
2023-11-10 23:27:41 DEBUG rasa.nlu.classifiers.diet_classifier - You specified 'DIET' to train entities, but no entities are present in the training data. Skipping training of entities.
2023-11-10 23:27:42 DEBUG rasa.nlu.classifiers.diet_classifier - Following metrics will be logged during training:
2023-11-10 23:27:42 DEBUG rasa.nlu.classifiers.diet_classifier - t_loss (total loss)
2023-11-10 23:27:42 DEBUG rasa.nlu.classifiers.diet_classifier - i_acc (intent acc)
2023-11-10 23:27:42 DEBUG rasa.nlu.classifiers.diet_classifier - i_loss (intent loss)
2023-11-10 23:27:42 DEBUG rasa.utils.tensorflow.data_generator - The provided batch size is a list, this data generator will use a linear increasing batch size.Epochs: 0%| | 0/100 [00:00<?, ?it/s]
Epochs: 100%|██████████| 100/100 [01:26<00:00, 1.15it/s, t_loss=0.258, i_loss=0.0123, i_acc=1]
2023-11-10 23:29:09 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_DIETClassifier2' was requested for writing.
2023-11-10 23:29:09 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_DIETClassifier2' was persisted.
2023-11-10 23:29:09 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'train_DIETClassifier2'.
2023-11-10 23:29:09 INFO rasa.engine.training.hooks - Finished training component 'DIETClassifier'.
2023-11-10 23:29:09 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'train_DIETClassifier2'.
2023-11-10 23:29:09 DEBUG rasa.engine.training.hooks - Caching 'Resource' with fingerprint_key: '7d66b69a551ffbc2a45237a02ffc5aa7' and output_fingerprint '9a50714386a54eebbd0b5eb4ab2fd23c'.
2023-11-10 23:29:09 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_DIETClassifier2' was requested for reading.
2023-11-10 23:29:09 DEBUG rasa.engine.caching - Caching output of type 'Resource' succeeded.
2023-11-10 23:29:11 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_before_node' running for node 'train_ResponseSelector3'.
2023-11-10 23:29:11 INFO rasa.engine.training.hooks - Starting to train component 'ResponseSelector'.
2023-11-10 23:29:11 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_before_node' running for node 'train_ResponseSelector3'.
2023-11-10 23:29:11 DEBUG rasa.engine.training.fingerprinting - Calculated fingerprint_key '0e102b0ba0b459b1556ae9eb4aaac987' for class 'ResponseSelector'.
2023-11-10 23:29:11 DEBUG rasa.engine.graph - Node 'train_ResponseSelector3' loading 'ResponseSelector.create' and kwargs: '{}'.
2023-11-10 23:29:11 DEBUG rasa.engine.graph - Node 'train_ResponseSelector3' running 'ResponseSelector.train'.
2023-11-10 23:29:11 INFO rasa.nlu.selectors.response_selector - Retrieval intent parameter was left to its default value. This response selector will be trained on training examples combining all retrieval intents.
2023-11-10 23:29:11 DEBUG rasa.nlu.classifiers.diet_classifier - No label features found. Computing default label features.
2023-11-10 23:29:11 DEBUG rasa.nlu.selectors.response_selector - Following metrics will be logged during training:
2023-11-10 23:29:11 DEBUG rasa.nlu.selectors.response_selector - t_loss (total loss)
2023-11-10 23:29:11 DEBUG rasa.nlu.selectors.response_selector - r_acc (response acc)
2023-11-10 23:29:11 DEBUG rasa.nlu.selectors.response_selector - r_loss (response loss)
2023-11-10 23:29:11 DEBUG rasa.utils.tensorflow.data_generator - The provided batch size is a list, this data generator will use a linear increasing batch size.
Epochs: 100%|██████████| 300/300 [00:39<00:00, 7.55it/s, t_loss=2.93, r_loss=1.17, r_acc=1]
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_ResponseSelector3' was requested for writing.
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_ResponseSelector3' was persisted.
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_ResponseSelector3' was requested for writing.
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_ResponseSelector3' was persisted.
2023-11-10 23:29:51 DEBUG rasa.engine.graph - Hook 'LoggingHook.on_after_node' running for node 'train_ResponseSelector3'.
2023-11-10 23:29:51 INFO rasa.engine.training.hooks - Finished training component 'ResponseSelector'.
2023-11-10 23:29:51 DEBUG rasa.engine.graph - Hook 'TrainingHook.on_after_node' running for node 'train_ResponseSelector3'.
2023-11-10 23:29:51 DEBUG rasa.engine.training.hooks - Caching 'Resource' with fingerprint_key: '0e102b0ba0b459b1556ae9eb4aaac987' and output_fingerprint '300fbcfe9f004bf2a6870e283e7b4f92'.
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Resource 'train_ResponseSelector3' was requested for reading.
2023-11-10 23:29:51 DEBUG rasa.engine.caching - Caching output of type 'Resource' succeeded.
2023-11-10 23:29:51 DEBUG rasa.engine.storage.local_model_storage - Start to created model package for path 'models\nlu-20231110-232632-arid-seasoning.tar.gz'.
2023-11-10 23:29:58 DEBUG rasa.engine.storage.local_model_storage - Model package created in path 'models\nlu-20231110-232632-arid-seasoning.tar.gz'.
Your Rasa model is trained and saved at 'models\nlu-20231110-232632-arid-seasoning.tar.gz'.
2023-11-10 23:29:58 DEBUG rasa.telemetry - Skipping telemetry reporting: no license hash found.Process finished with exit code 0
参考文献:
[1]《Rasa实战》
相关文章:
使用ResponseSelector实现校园招聘FAQ机器人
本文主要介绍使用ResponseSelector实现校园招聘FAQ机器人,回答面试流程和面试结果查询的FAQ问题。FAQ机器人功能分为业务无关的功能和业务相关的功能2类。 一.data/nlu.yml文件 与普通意图相比,ResponseSelector训练数据中的意图采用group/intent格…...

ENVI IDL:如何基于气象站点数据进行反距离权重插值?
01 前言 仅仅练习,大可使用ArcGIS或者已经封装好的python模块进行插值,此处仅仅从底层理解如何从公式和代码理解反距离权重插值的过程,从而更深刻的理解IDL的使用和插值的理解。 02 函数说明 2.1 Read_CSV()函数 官方语法如下:…...
实战Leetcode(四)
Practice makes perfect! 实战一: 这个题由于我们不知道两个链表的长度我们也不知道它是否有相交的节点,所以我们的方法是先求出两个链表的长度,长度长的先走相差的步数,使得两个链表处于同一起点,两个链…...
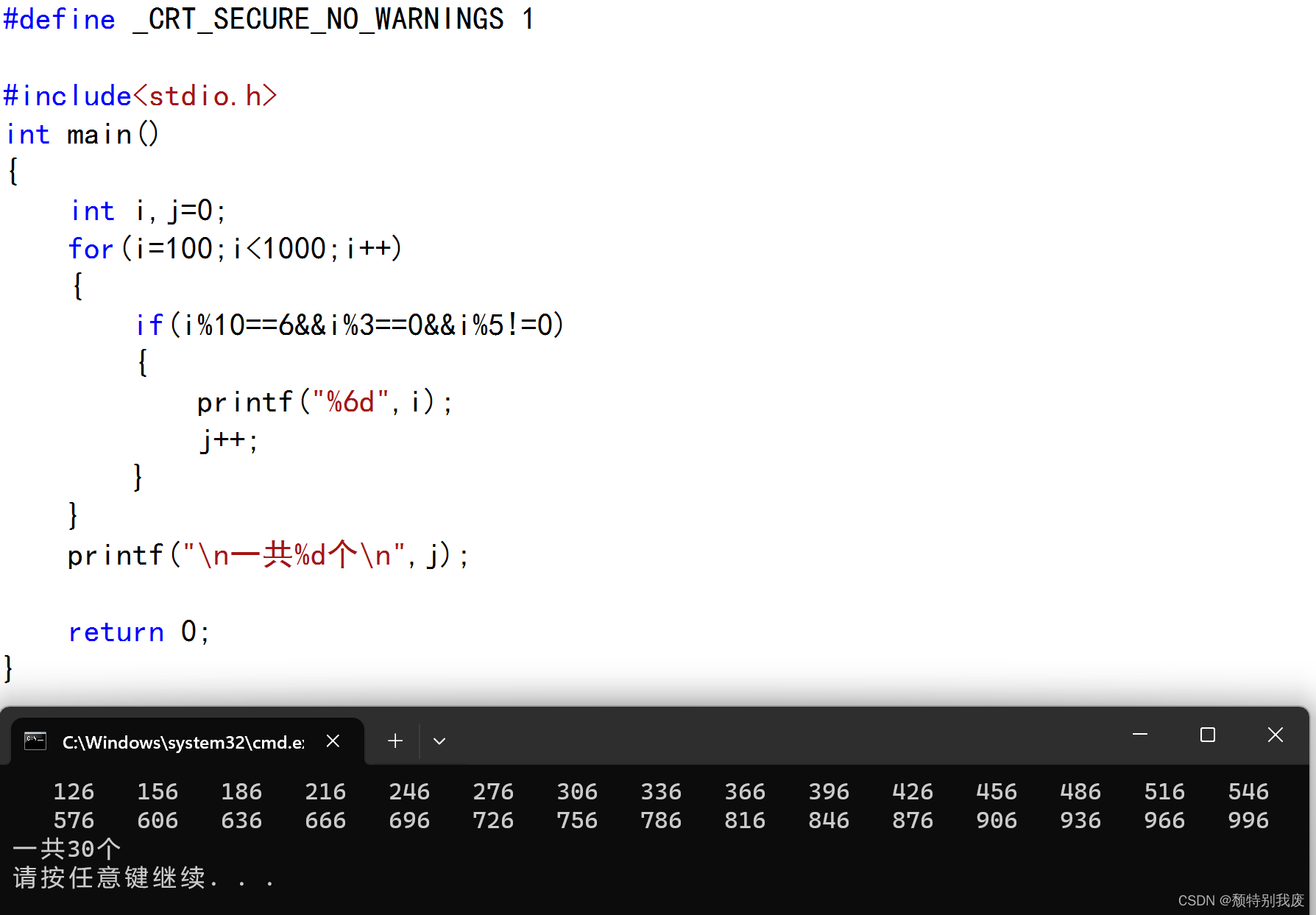
C语言——个位数为 6 且能被 3 整除但不能被 5 整除的三位自然数共有多少个,分别是哪些?
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> int main() {int i,j0;for(i100;i<1000;i) {if(i%106&&i%30&&i%5!0){printf("%6d",i); j;}}printf("\n一共%d个\n",j);return 0; } %6d起到美化输出格式的作用ÿ…...

基于Docker容器DevOps应用方案
文章目录 基于docker容器DevOps应用方案环境基础配置1.所有主机永久关闭防火墙和selinux2.配置yum源3.docker的安装教程 配置主机名与IP地址解析部署gitlab.server主机1.安装gitlab2.配置gitlab3.破解管理员密码4.验证web页面 部署jenkins.server主机1.部署tomcat2.安装jenkins…...
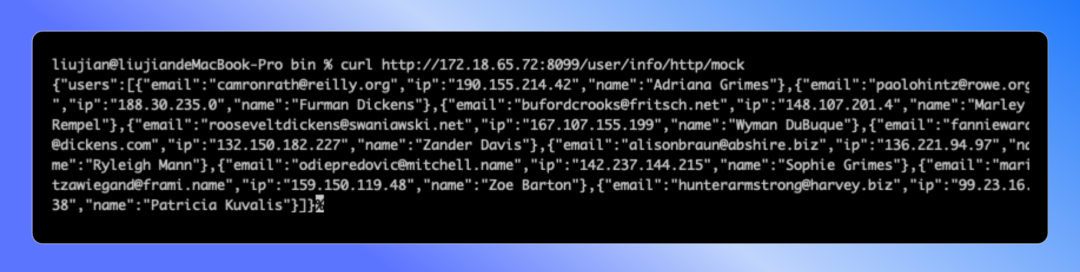
Apinto 网关进阶教程,使用 API Mock 生成模拟数据
什么是 API Mock ? API Mock 是一种技术,它允许程序员在不依赖后端数据的情况下,模拟 web服务器端 API 的响应。通常使用 API Mock 来测试前端应用程序,而无需等待后端程序构建完成。API Mock 可以模拟任何 HTTP 请求方法&#x…...
笔记:AI量化策略开发流程-基于BigQuant平台(一)
从本文开始,按照AI策略开发的完整流程(共七步),上手在BigQuant平台上快速构建AI策略。本文首先介绍如何使用证券代码模块指定股票范围和数据起止日期。重要的事情说三遍:模块的输入端口有提示需要连线的上游数据类型&a…...

Spring Cloud 微服务入门篇
文章目录 什么是微服务架构 Microservice微服务的发展历史微服务的定义微小的服务微服务 微服务的发展历史1. 微服务架构的发展历史2. 微服务架构的先驱 微服务架构 Microservice 的优缺点1. 微服务 e Microservice 优点2. 微服务 Microservice 缺点微服务不是银弹:…...

使用Go语言搭建区块链基础
引言 随着区块链技术的发展,越来越多的人开始关注并使用这一技术,其中,比特币和以太坊等区块链项目正在成为人们关注的焦点。而Go语言作为一种高效、简洁的编程语言,越来越多的区块链项目也选择使用Go语言来搭建其底层基础。本文…...
)
手搓MyBatis框架(原理讲解)
你在学完MyBatis框架后会不会觉得很神奇,为什么我改一个配置文件就可以让程序识别和执行不同的sql语句操作数据库? SqlSessionFactoryBuilder,SqlSessionFactory和SqlSession对象到底是怎样执行的? 如果你有这些问题看就完事了 …...

FRC-EP系列--你的汽车数据一站式管家
FRC-EP系列产品主要面向汽车动力总成测试的客户,主要应用方向为残余总线仿真及网关。本文将详细介绍FRC-EP的产品特性和应用场景。 应用场景: 汽车电子生成研发过程中,需要对汽车各个控制器进行仿真测试,典型的测试对象有&#…...

【ARM Trace32(劳特巴赫) 使用介绍 3 - trace32 访问运行时的内存】
请阅读【ARM Coresight SoC-400/SoC-600 专栏导读】 文章目录 1.1 trace32 访问运行时的内存1.1.1 侵入式 运行时内存访问1.1.2 非侵入式运行时访问1.1.3 缓存一致性的非侵入式运行时访问 1.2 Trace32 侵入式和非侵入式 运行时访问1.2.1 侵入式访问1.2.2 非侵入式运行时访问 1…...
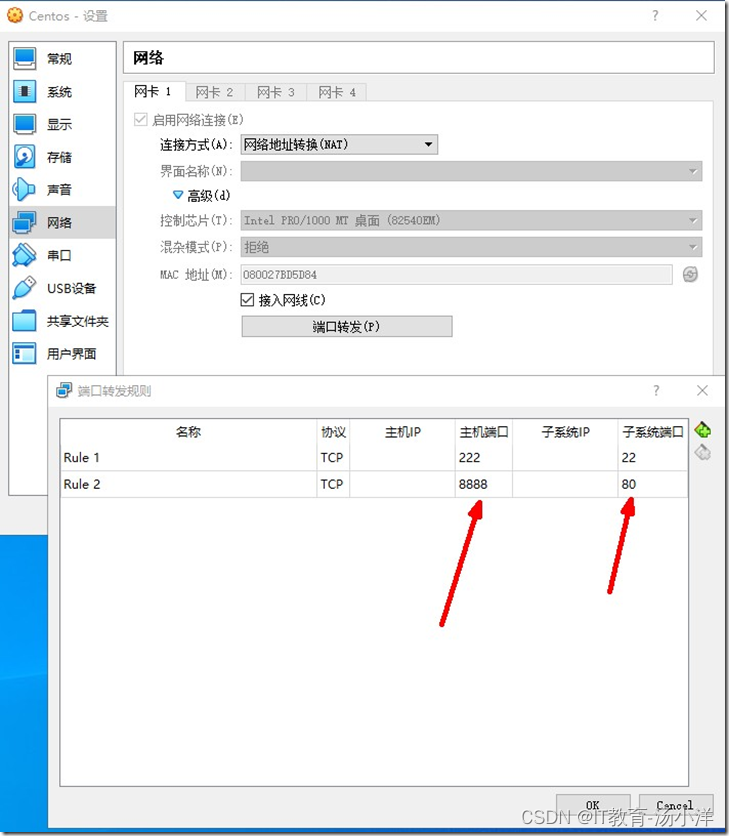
VirtualBox网络地址转换(NAT),宿主机无法访问虚拟机的问题
问题:NAT模式下,默认只能从内访问外面,而不能从外部访问里面,所以只能单向ping通,虚拟机的ip只是内部ip。 PS:桥接则是与主机公用网卡,有独立的外部ip。 解决:NAT模式可以通过配置 …...

【操作系统】考研真题攻克与重点知识点剖析 - 第 2 篇:进程与线程
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

总结:利用原生JDK封装工具类,解析properties配置文件以及MF清单文件
总结:利用原生JDK封装工具类,解析properties配置文件以及MF清单文件 一背景描述:1.在不同的项目中,项目使用的开发框架都不一样,甚至是JDK原生开发模式。此时解析配置文件以及jar包中的清单文件,就只能利用…...

openGauss学习笔记-119 openGauss 数据库管理-设置数据库审计-设置文件权限安全策略
文章目录 openGauss学习笔记-119 openGauss 数据库管理-设置数据库审计-设置文件权限安全策略119.1 背景信息119.2 数据库程序目录及文件权限119.3 建议 openGauss学习笔记-119 openGauss 数据库管理-设置数据库审计-设置文件权限安全策略 119.1 背景信息 数据库在安装过程中…...

不可否认程序员的护城河已经越来越浅了
文章目录 那些在冲击程序员护城河低代码/无代码开发平台自动化测试和部署工具AI辅助开发工具在线学习和教育平台 面临冲击,程序员应该怎么做深入专业知识:不断学习全栈技能开发解决问题的能力建立人际网络管理和领导技能 推荐阅读 技术和应用的不断发展对…...
黑客技术-小白自学
前言 一、什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防…...
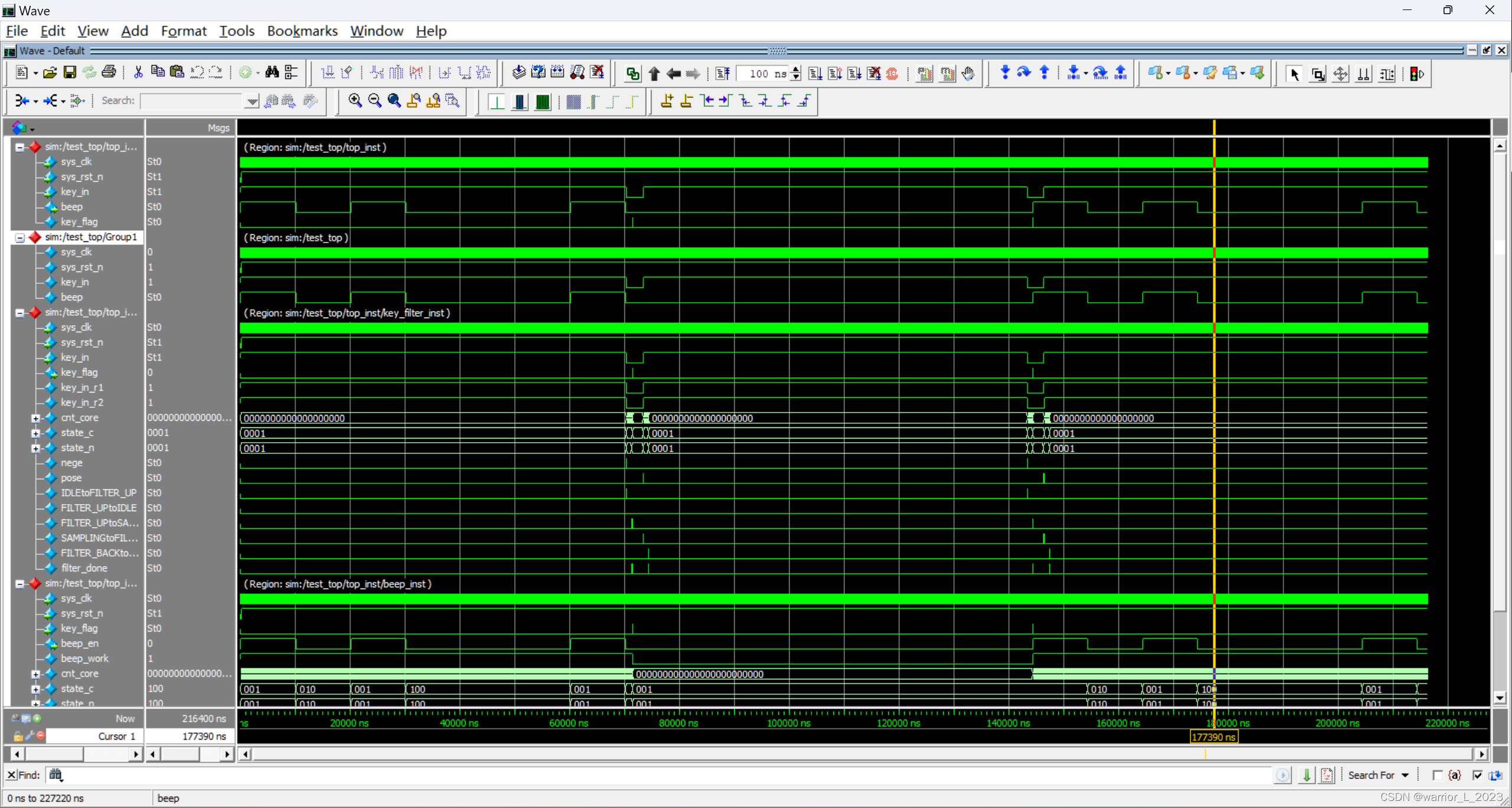
ZYNQ_project:key_beep
通过按键控制蜂鸣器工作。 模块框图: 时序图: 代码: /*1位按键消抖 */ module key_filter (input wire sys_clk ,input wire sys_rst_n ,input wire key_in ,output …...

css3文字环绕旋转
目录 固定数量文字环绕旋转不固定数量文字环绕旋转效果图 固定数量文字环绕旋转 <!-- 文字旋转测试 --> <template><div class"page"><div><div v-for"(item, index) in [...Array(20).keys()]" :key"index" style&…...
 工控主板怎么选?协议适配与通信稳定性详解)
工业现场总线 (PROFINET/Modbus) 工控主板怎么选?协议适配与通信稳定性详解
工业现场总线是连接工业现场设备和控 制 系统的桥梁,是工业自动化系统的重要组成部分。目前,市场上存在多种工业现场总线标准,其中 PROFINET 和 Modbus 是应用很广泛的两种。PROFINET 作为新一代的工业以太网总线,以其高速、实时、…...
)
STM32实战:AD2S1210旋转变压器驱动全攻略(含代码解析与常见问题排查)
STM32实战:AD2S1210旋转变压器驱动全攻略(含代码解析与常见问题排查) 旋转变压器(Resolver)作为高可靠性角度传感器,在工业伺服、航空航天等领域具有不可替代的优势。AD2S1210作为ADI公司推出的数字转换芯片…...

AndroRAT客户端架构揭秘:Java实现远程控制的终极指南
AndroRAT客户端架构揭秘:Java实现远程控制的终极指南 【免费下载链接】AndroRAT A Simple android remote administration tool using sockets. It uses java on the client side and python on the server side 项目地址: https://gitcode.com/gh_mirrors/an/And…...

Qwen-Image-Lightning部署教程:Mac M系列芯片Metal后端适配进展
Qwen-Image-Lightning部署教程:Mac M系列芯片Metal后端适配进展 1. 前言:当极速文生图遇上苹果芯 如果你是一名Mac用户,特别是使用M系列芯片的Mac用户,可能已经习惯了在AI绘画这件事上“望洋兴叹”。很多强大的文生图模型&#…...

如何专业优化Windows系统音频:Equalizer APO实战配置完全指南
如何专业优化Windows系统音频:Equalizer APO实战配置完全指南 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否厌倦了Windows系统音质平淡无力,玩游戏时听不清敌人脚步声&a…...

mT5中文-base零样本增强模型应用场景:中文OCR识别后文本纠错与语义补全
mT5中文-base零样本增强模型应用场景:中文OCR识别后文本纠错与语义补全 1. 模型介绍与核心能力 mT5中文-base零样本增强模型是一个专门针对中文文本处理优化的AI模型,它在原有mT5模型基础上进行了重要改进。这个模型最大的特点是使用了海量中文数据进行…...

团队协作最小的良性开发闭环
问题陈述 现状:团队成员个人能力不差,但在「一起开发同一套系统」时,整体效率偏低、质量不稳;产品需求更新频繁、节奏快,且缺少前置规划与边界。 表层问题:产品、开发、测试对同一功能在「做什么、做到什么…...

免费数据恢复软件推荐:Wise Data Recovery 6.2.0 激活版使用指南
原文作者:程序视点 转载自:https://cloud.tencent.com/developer/article/2550182 数据恢复需求:为什么需要专业软件? 在日常使用电脑时,误删文件、清空回收站、格式化磁盘等情况时有发生。此时,专业的数…...

AUV增量PID轨迹跟踪与USV路径跟随的MATLAB仿真
AUV 增量PID轨迹跟踪 水下机器人无人船无人艇 USV路径跟随 MATLAB仿真AUV 圆轨迹跟踪增量 PID 控制系统——功能说明书(基于 MATLAB 仿真框架)一、系统定位本仿真包为“Infante”型 AUV 提供一套可即插即用的圆轨迹跟踪解决方案。核心算法采用“增量式…...

MCP协议如何重塑前端开发工作流
前言 2026年,AI与前端开发的融合进入新阶段。MCP(Model Context Protocol)协议作为Anthropic推出的开放标准,正在彻底改变我们构建AI驱动应用的方式。本文将深入探讨MCP在前端工程中的实战应用。 正文 一、MCP协议核心概念 MCP协议…...