剑指JUC原理-16.读写锁
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring源码、JUC源码
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- ReentrantReadWriteLock
- 应用之缓存
- 缓存更新策略
- 先清缓存
- 读写锁实现一致性缓存
- 读写锁原理
- t1 w.lock,t2 r.lock
- t3 r.lock,t4 w.lock
- t1 w.unlock
- t2 r.unlock,t3 r.unlock
- StampedLock
ReentrantReadWriteLock
其定义就是支持冲入的读写锁,本质上也就是基于 ReentrantLock 实现的
当读操作远远高于写操作时,这时候使用 读写锁 让 读-读 可以并发,提高性能。
类似于数据库中的 select … from … lock in share mode
提供一个 数据容器类 内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
class DataContainer {private Object data;private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();private ReentrantReadWriteLock.ReadLock r = rw.readLock();private ReentrantReadWriteLock.WriteLock w = rw.writeLock();public Object read() {log.debug("获取读锁...");r.lock();try {log.debug("读取");sleep(1);return data;} finally {log.debug("释放读锁...");r.unlock();}}public void write() {log.debug("获取写锁...");w.lock();try {log.debug("写入");sleep(1);} finally {log.debug("释放写锁...");w.unlock();}}
}
测试 读锁-读锁 可以并发
DataContainer dataContainer = new DataContainer();new Thread(() -> {dataContainer.read();}, "t1").start();new Thread(() -> {dataContainer.read();}, "t2").start();
输出结果,从这里可以看到 Thread-0 锁定期间,Thread-1 的读操作不受影响
14:05:14.341 c.DataContainer [t2] - 获取读锁...
14:05:14.341 c.DataContainer [t1] - 获取读锁...
14:05:14.345 c.DataContainer [t1] - 读取
14:05:14.345 c.DataContainer [t2] - 读取
14:05:15.365 c.DataContainer [t2] - 释放读锁...
14:05:15.386 c.DataContainer [t1] - 释放读锁...
测试 读锁-写锁 相互阻塞
DataContainer dataContainer = new DataContainer();new Thread(() -> {dataContainer.read();}, "t1").start();Thread.sleep(100);new Thread(() -> {dataContainer.write();}, "t2").start();
输出结果
14:04:21.838 c.DataContainer [t1] - 获取读锁...
14:04:21.838 c.DataContainer [t2] - 获取写锁...
14:04:21.841 c.DataContainer [t2] - 写入
14:04:22.843 c.DataContainer [t2] - 释放写锁...
14:04:22.843 c.DataContainer [t1] - 读取
14:04:23.843 c.DataContainer [t1] - 释放读锁...
写锁-写锁 也是相互阻塞的,这里就不测试了
注意事项
- 读锁不支持条件变量
ReentrantReadWriteLock 中的读锁不支持条件变量,主要是因为读锁在 ReentrantReadWriteLock 中是共享的,多个线程可以同时持有读锁来访问共享资源。条件变量通常用于在多线程环境下实现线程间的协调和通信,而读锁的共享特性可能导致条件变量的信号在多个线程之间产生歧义或不确定性。
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待
r.lock();try {// ...w.lock();try {// ...} finally{w.unlock();}} finally{r.unlock();}
- 重入时降级支持:即持有写锁的情况下去获取读锁
// 下面以ReentrantReadWriteLock 的 CachedData 类来说明,这段代码主要是使用读写锁来实现对缓存数据的并发访问,以提高并发读取操作的性能。class CachedData {Object data;// 是否有效,如果失效,需要重新计算 datavolatile boolean cacheValid;final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();void processCachedData() {// 先加读锁,判断缓存是否失效,如果没有失效,那么可以直接返回即可。使用完了将读锁解开即可rwl.readLock().lock();if (!cacheValid) {// 如果失效了,释放读锁,然后获得写锁,重新对其进行计算// 获取写锁前必须释放读锁rwl.readLock().unlock();rwl.writeLock().lock();try {// 判断是否有其它线程已经获取了写锁、更新了缓存, 避免重复更新/*在上述代码中,两次检查 cacheValid 的作用是为了在获取写锁之前和获取写锁后再次确认缓存的有效性。让我来详细解释一下:第一次检查 cacheValid 发生在首次获取写锁之前。这是为了避免出现竞态条件(race condition)的情况,即在当前线程释放读锁后,有可能其他线程已经获取了写锁并更新了缓存。如果没有进行第一次检查,当前线程获取写锁后可能会重复更新缓存,造成不必要的计算和数据更新。第二次检查 cacheValid 发生在获取写锁之后。虽然在第一次检查时缓存无效,但在当前线程获取写锁之前,可能有其他线程已经更新了缓存并将 cacheValid 设置为有效。因此,在获取写锁后再次检查 cacheValid 可以避免重复更新缓存,确保只有一个线程更新缓存数据。通过这样的双重检查机制,可以有效地避免多个线程同时更新缓存数据,确保在并发环境下对缓存的更新操作是正确且高效的。此外,结合读写锁的降级操作,可以使得在缓存有效时多个线程能够同时读取数据,从而提高系统的并发性能。*/if (!cacheValid) {data = ...cacheValid = true;}/*锁的降级,写锁释放开,但是我还想同时持有它的读锁,这是为了释放开的那个瞬间,其他线程的读取权限就ok了加读锁的目的也是为了你在读的的时候不受其他的写的线程的干扰*/// 降级为读锁, 释放写锁, 这样能够让其它线程读取缓存rwl.readLock().lock();} finally {rwl.writeLock().unlock();}}// 自己用完数据, 释放读锁 try {use(data);} finally {rwl.readLock().unlock();}}
}
应用之缓存
缓存更新策略
更新时,是先清缓存还是先更新数据库
先清缓存
读操作的速度是大于写操作的

先更新数据库

补充一种情况,假设查询线程 A 查询数据时恰好缓存数据由于时间到期失效,或是第一次查询

这种情况的出现几率非常小
读写锁实现一致性缓存
使用读写锁实现一个简单的按需加载缓存(核心:写操作 加 写锁;读操作 加 读锁)
class GenericCachedDao<T> {// HashMap 作为缓存非线程安全, 需要保护HashMap<SqlPair, T> map = new HashMap<>();ReentrantReadWriteLock lock = new ReentrantReadWriteLock();GenericDao genericDao = new GenericDao();public int update(String sql, Object... params) {SqlPair key = new SqlPair(sql, params);// 加写锁, 防止其它线程对缓存读取和更改lock.writeLock().lock();try {int rows = genericDao.update(sql, params);map.clear();return rows;} finally {lock.writeLock().unlock();}}public T queryOne(Class<T> beanClass, String sql, Object... params) {SqlPair key = new SqlPair(sql, params);// 加读锁, 防止其它线程对缓存更改lock.readLock().lock();try {T value = map.get(key);if (value != null) {return value;}} finally {lock.readLock().unlock();}// 加写锁, 防止其它线程对缓存读取和更改lock.writeLock().lock();try {// get 方法上面部分是可能多个线程进来的, 可能已经向缓存填充了数据// 为防止重复查询数据库, 再次验证T value = map.get(key);if (value == null) {// 如果没有, 查询数据库value = genericDao.queryOne(beanClass, sql, params);map.put(key, value);}return value;} finally {lock.writeLock().unlock();}}// 作为 key 保证其是不可变的class SqlPair {private String sql;private Object[] params;public SqlPair(String sql, Object[] params) {this.sql = sql;this.params = params;}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}SqlPair sqlPair = (SqlPair) o;return sql.equals(sqlPair.sql) &&Arrays.equals(params, sqlPair.params);}@Overridepublic int hashCode() {int result = Objects.hash(sql);result = 31 * result + Arrays.hashCode(params);return result;}}
}
注意
以上实现体现的是读写锁的应用,保证缓存和数据库的一致性,但有下面的问题没有考虑:
- 适合读多写少,如果写操作比较频繁,以上实现性能低
- 没有考虑缓存容量
- 没有考虑缓存过期
- 只适合单机
- 并发性还是低,目前只会用一把锁
- 更新方法太过简单粗暴,清空了所有 key(考虑按类型分区或重新设计 key)
读写锁原理
读写锁用的是同一个 Sycn 同步器,因此等待队列、state 等也是同一个
t1 w.lock,t2 r.lock

其实该流程和 ReentrantLock 几乎是一样的,但是还是有一些区别的,比如state不太一样,因为state既要给读锁用,也要给写锁用,所以要将state分成两部分。
t1 成功上锁,流程与 ReentrantLock 加锁相比没有特殊之处,不同是写锁状态占了 state 的低 16 位,而读锁
使用的是 state 的高 16 位。
其实t1肯定是能加上锁,接下来分析一下源码:
ctrl + f12 找到 writelock 里面的lock方法:
public void lock() {sync.acquire(1);
}public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
/*首先会调用tryAcquire 尝试加锁,如果成功了那么后续的代码就不执行了,如果加锁失败了,才会进入这个队列*/
protected final boolean tryAcquire(int acquires) {/** Walkthrough:* 1. If read count nonzero or write count nonzero* and owner is a different thread, fail.* 2. If count would saturate, fail. (This can only* happen if count is already nonzero.)* 3. Otherwise, this thread is eligible for lock if* it is either a reentrant acquire or* queue policy allows it. If so, update state* and set owner.*/Thread current = Thread.currentThread();// 首先拿到整个state状态int c = getState();int w = exclusiveCount(c);// 如果不等于0,意味着既有可能其他线程加了读锁,也有可能是其他线程加了写锁// 因为高16位不等于0或者低16位不等于0都有可能导致 不等于0if (c != 0) {// (Note: if c != 0 and w == 0 then shared count != 0)// w == 0 代表 加的读锁部分 而 往后执行代表着 可能加的写锁,但是这个写锁是不是自己加的呢?比如先加的写锁,发生了重入,又加了一次写锁if (w == 0 || current != getExclusiveOwnerThread())return false;// 如果写锁部分 再加 1超过写锁的最大范围了 65535 2的16次方if (w + exclusiveCount(acquires) > MAX_COUNT)throw new Error("Maximum lock count exceeded");// Reentrant acquire// 可以理解为发生了可重入setState(c + acquires);return true;}// 如果能往下走,说明c是等于0的,代表别的线程都没有加锁,首先判断写锁是否需要阻塞,其实就意味着公平非公平,如果是非公平锁 就 总会返回false,公平锁会检查这个队列。然后就接着往后面走 是否能compareAndSetStateif (writerShouldBlock() ||!compareAndSetState(c, c + acquires))return false;// 将对应线程设置成 ownersetExclusiveOwnerThread(current);return true;}
接下来看 加 读锁的lock方法
public void lock() {sync.acquireShared(1);}public final void acquireShared(int arg) {// 尝试去获取这个读锁if (tryAcquireShared(arg) < 0)doAcquireShared(arg);}
t2 执行 r.lock,这时进入读锁的 sync.acquireShared(1) 流程,首先会进入 tryAcquireShared 流程。如果有写
锁占据,那么 tryAcquireShared 返回 -1 表示失败
tryAcquireShared 返回值表示
- -1 表示失败
- 0 表示成功,但后继节点不会继续唤醒(0或者1会在后面的信号量章节介绍)
- 正数表示成功,而且数值是还有几个后继节点需要唤醒,读写锁返回 1
protected final int tryAcquireShared(int unused) {Thread current = Thread.currentThread();int c = getState();// 检查写锁部分是否不为0 此时t1已经将其变为1了,去检查加写锁的是不是当前线程呢?// 这种情况其实就是 t2 已经加了写锁,然后又加了读锁,这里是应该成功的,因为这是锁降级的过程// 最终我们当前的情况来看,t2 其实就是返回-1了。if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return -1;int r = sharedCount(c);if (!readerShouldBlock() &&r < MAX_COUNT &&compareAndSetState(c, c + SHARED_UNIT)) {if (r == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;}return 1;}return fullTryAcquireShared(current);}

返回-1,这时会进入 sync.doAcquireShared(1) 流程,首先也是调用 addWaiter 添加节点,不同之处在于节点被设置为Node.SHARED 模式而非 Node.EXCLUSIVE 模式,注意此时 t2 仍处于活跃状态

private void doAcquireShared(int arg) {// 唤醒的时候,判断的逻辑稍有不同final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {// 死循环,去找t2 有没有前驱节点final Node p = node.predecessor();// 如果前驱节点是 head,那么说明其是 第二个节点,是有资格争抢锁的if (p == head) {// 调用tryAcquireShared 返回-1表示失败,返回0或者1表示成功int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}// 如果返回-1,说明并没有释放锁,那么就会走到这个逻辑,和ReentrantLock逻辑一致,走park shouldParkAfterFailedAcquire将其前驱节点设置成-1,然后 重新for循环,设置为parkif (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}

t3 r.lock,t4 w.lock
这种状态下,假设又有 t3 加读锁和 t4 加写锁,这期间 t1 仍然持有锁,就变成了下面的样子

t2 t3都是读锁,所以状态都是 SHARED,而t4是写锁,所以状态是EXCLUSIVE
t1 w.unlock
这时会走到写锁的 sync.release(1) 流程,调用 sync.tryRelease(1) 成功,变成下面的样子
public void unlock() {sync.release(1);}public final boolean release(int arg) {// 如果return true呢,就会执行后续的逻辑if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}protected final boolean tryRelease(int releases) {if (!isHeldExclusively())throw new IllegalMonitorStateException();// 首先在原来的基础上减1int nextc = getState() - releases;// 然后去查看写锁部分是不是减成0了boolean free = exclusiveCount(nextc) == 0;if (free)setExclusiveOwnerThread(null);// 如果没有减成0 代表着这事一次锁的重入setState(nextc);return free;}

接下来执行唤醒流程 sync.unparkSuccessor,即让老二恢复运行,这时 t2 在 doAcquireShared 内
parkAndCheckInterrupt() 处恢复运行
这回再来一次 for (;😉 执行 tryAcquireShared 成功则让读锁计数加一
private void doAcquireShared(int arg) {final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {// 此时进入到这个条件中// 替换头结点setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}if (shouldParkAfterFailedAcquire(p, node) &&// 此时这里唤醒了,就可以继续运行了,然后再循环parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}// 返回-1表示失败,返回0或者1表示成功
protected final int tryAcquireShared(int unused) {Thread current = Thread.currentThread();int c = getState();// 返回-1的之前分析过了,就不再做分析了if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return -1;// 获取读锁,也就是高16位int r = sharedCount(c);// 不应该被阻塞住if (!readerShouldBlock() &&// 没有超过最大基数r < MAX_COUNT &&// 对于高位来讲,不是加1,是加了65536compareAndSetState(c, c + SHARED_UNIT)) {// 如果都符合,代表后续读锁加锁成功了if (r == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;}return 1;}return fullTryAcquireShared(current);}

这时 t2 已经恢复运行,接下来 t2 调用 setHeadAndPropagate(node, 1),它原本所在节点被置为头节点

// 替换头结点
private void setHeadAndPropagate(Node node, int propagate) {Node h = head; // Record old head for check belowsetHead(node);if (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {// 拿到当前节点的下一个 Node s = node.next;// 如果节点的状态是 shared的话,if (s == null || s.isShared())doReleaseShared();}}
事情还没完,在 setHeadAndPropagate 方法内还会检查下一个节点是否是 shared,如果是则调用
doReleaseShared() 将 head 的状态从 -1 改为 0 并唤醒老二,这时 t3 在 doAcquireShared 内parkAndCheckInterrupt() 处恢复运行
private void doReleaseShared() {for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {// 在这里会将节点的状态从 -1 改成 0if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue; // loop to recheck cases// 对头结点的后继结点又要去唤醒,这就接上了 此时就唤醒t3的parkunparkSuccessor(h);}else if (ws == 0 &&!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}}

private void doAcquireShared(int arg) {final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head) {// 又再次来到了 tryAcquireShared方法,和前面的流程是一样的int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}if (shouldParkAfterFailedAcquire(p, node) &&// 此时t3 被唤醒了,和之前的流程是一样的parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}protected final int tryAcquireShared(int unused) {Thread current = Thread.currentThread();int c = getState();// 返回-1的之前分析过了,就不再做分析了if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return -1;// 获取读锁,也就是高16位int r = sharedCount(c);// 不应该被阻塞住if (!readerShouldBlock() &&// 没有超过最大基数r < MAX_COUNT &&// 对于高位来讲,不是加1,是加了65536compareAndSetState(c, c + SHARED_UNIT)) {// 如果都符合,代表后续读锁加锁成功了if (r == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;}return 1;}return fullTryAcquireShared(current);}
这回再来一次 for (;😉 执行 tryAcquireShared 成功则让读锁计数加一

这时 t3 已经恢复运行,接下来 t3 调用 setHeadAndPropagate(node, 1),它原本所在节点被置为头节点

// 替换头结点
private void setHeadAndPropagate(Node node, int propagate) {Node h = head; // Record old head for check belowsetHead(node);if (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {// 拿到当前节点的下一个 Node s = node.next;// 如果节点的状态是 shared的话,if (s == null || s.isShared())doReleaseShared();}}
下一个节点不是 shared 了,因此不会继续唤醒 t4 所在节点
t2 r.unlock,t3 r.unlock
t2 进入 sync.releaseShared(1) 中,调用 tryReleaseShared(1) 让计数减一,但由于计数还不为零

public void unlock() {sync.releaseShared(1);}public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}protected final boolean tryReleaseShared(int unused) {Thread current = Thread.currentThread();if (firstReader == current) {// assert firstReaderHoldCount > 0;if (firstReaderHoldCount == 1)firstReader = null;elsefirstReaderHoldCount--;} else {HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))rh = readHolds.get();int count = rh.count;if (count <= 1) {readHolds.remove();if (count <= 0)throw unmatchedUnlockException();}--rh.count;}for (;;) {int c = getState();// 获取状态,减去高位的1int nextc = c - SHARED_UNIT;if (compareAndSetState(c, nextc))// Releasing the read lock has no effect on readers,// but it may allow waiting writers to proceed if// both read and write locks are now free.return nextc == 0;}}
t3 进入 sync.releaseShared(1) 中,调用 tryReleaseShared(1) 让计数减一,这回计数为零了,进入
doReleaseShared() 将头节点从 -1 改为 0 并唤醒老二,即

private void doReleaseShared() {for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue; // loop to recheck cases// 本质上唤醒t4unparkSuccessor(h);}else if (ws == 0 &&!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}}
之后 t4 在 acquireQueued 中 parkAndCheckInterrupt 处恢复运行,再次 for (;😉 这次自己是老二,并且没有其他
竞争,tryAcquire(1) 成功,修改头结点,流程结束

StampedLock
该类自 JDK 8 加入,是为了进一步优化读性能,它的特点是在使用读锁、写锁时都必须配合【戳】使用
这里对优化性能部分做了专门的解读:
之前学读写锁,其实已经看到了读读可以并发,已经很快了,但是还不够快,读读并发的时候,底层还是用cas的方式去修改它的状态,读锁的高16位去修改它的状态,它还是性能上比不上不加锁,如果希望读取的性能达到这种极致,那么就可以使用StampedLock。
加解读锁
long stamp = lock.readLock();
lock.unlockRead(stamp);
加解写锁
long stamp = lock.writeLock();
lock.unlockWrite(stamp);
乐观读,StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通
过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
// 这里面没有加任何的锁
long stamp = lock.tryOptimisticRead();
// 验戳
if(!lock.validate(stamp)){// 锁升级
}
提供一个 数据容器类 内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
class DataContainerStamped {private int data;private final StampedLock lock = new StampedLock();public DataContainerStamped(int data) {this.data = data;}public int read(int readTime) {long stamp = lock.tryOptimisticRead();log.debug("optimistic read locking...{}", stamp);sleep(readTime);if (lock.validate(stamp)) {log.debug("read finish...{}, data:{}", stamp, data);return data;}// 锁升级 - 读锁log.debug("updating to read lock... {}", stamp);try {stamp = lock.readLock();log.debug("read lock {}", stamp);sleep(readTime);log.debug("read finish...{}, data:{}", stamp, data);return data;} finally {log.debug("read unlock {}", stamp);lock.unlockRead(stamp);}}public void write(int newData) {long stamp = lock.writeLock();log.debug("write lock {}", stamp);try {sleep(2);this.data = newData;} finally {log.debug("write unlock {}", stamp);lock.unlockWrite(stamp);}}
}
测试 读-读 可以优化
public static void main(String[] args) {DataContainerStamped dataContainer = new DataContainerStamped(1);new Thread(() -> {dataContainer.read(1);}, "t1").start();sleep(0.5);new Thread(() -> {dataContainer.read(0);}, "t2").start();}
输出结果,可以看到实际没有加读锁
15:58:50.217 c.DataContainerStamped [t1] - optimistic read locking...256
15:58:50.717 c.DataContainerStamped [t2] - optimistic read locking...256
15:58:50.717 c.DataContainerStamped [t2] - read finish...256, data:1
15:58:51.220 c.DataContainerStamped [t1] - read finish...256, data:1
测试 读-写 时优化读补加读锁
public static void main(String[] args) {DataContainerStamped dataContainer = new DataContainerStamped(1);new Thread(() -> {dataContainer.read(1);}, "t1").start();sleep(0.5);new Thread(() -> {dataContainer.write(100);}, "t2").start();}
输出结果
15:57:00.219 c.DataContainerStamped [t1] - optimistic read locking...256
15:57:00.717 c.DataContainerStamped [t2] - write lock 384
15:57:01.225 c.DataContainerStamped [t1] - updating to read lock... 256
15:57:02.719 c.DataContainerStamped [t2] - write unlock 384
15:57:02.719 c.DataContainerStamped [t1] - read lock 513
15:57:03.719 c.DataContainerStamped [t1] - read finish...513, data:1000
15:57:03.719 c.DataContainerStamped [t1] - read unlock 513
注意
- StampedLock 不支持条件变量
- StampedLock 不支持可重入
相关文章:
剑指JUC原理-16.读写锁
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...

文件改名:避免繁琐操作,利用筛选文件批量重命名技巧优化文件管理
在我们的日常生活和工作中,我们经常需要处理大量的文件,从文档、图片到音频和视频等。在这些情况下,一个高效的文件管理策略至关重要。文件重命名的必要性主要体现在两个方面。首先,对于大量文件,手动进行重命名不仅费…...
【CocoaPods安装环境和流程以及各种情况】
CocoaPods 环境HomebrewRubyrbenvRubyGems 和 Bundler安装Ruby管理Ruby更新Ruby替换Ruby镜像方式1方式2 CocoaPods安装CocoaPodsCocoaPods使用安装的一些问题单元测试引用问题 参考的链接 环境 Homebrew $ brew --config *可以发现打印有下面一行: Homebrew Ruby: …...

canvas与svg区别与实际应用
Canvas和SVG都是HTML5中的绘图技术。但是两者的实现方式和使用场景有所不同。 Canvas是HTML5中的绘图API,它提供了一套基于像素的绘图工具,可以通过JavaScript来实现动态的图形和动画。Canvas提供的绘图功能强大,可以绘制出复杂的图像和动画…...
rasa train nlu详解:1.1-train_nlu()函数
本文使用《使用ResponseSelector实现校园招聘FAQ机器人》中的例子,主要详解介绍train_nlu()函数中变量的具体值。 一.rasa/model_training.py/train_nlu()函数 train_nlu()函数实现,如下所示: def train_nlu(config: Text,nlu_data: Op…...
使用ResponseSelector实现校园招聘FAQ机器人
本文主要介绍使用ResponseSelector实现校园招聘FAQ机器人,回答面试流程和面试结果查询的FAQ问题。FAQ机器人功能分为业务无关的功能和业务相关的功能2类。 一.data/nlu.yml文件 与普通意图相比,ResponseSelector训练数据中的意图采用group/intent格…...

ENVI IDL:如何基于气象站点数据进行反距离权重插值?
01 前言 仅仅练习,大可使用ArcGIS或者已经封装好的python模块进行插值,此处仅仅从底层理解如何从公式和代码理解反距离权重插值的过程,从而更深刻的理解IDL的使用和插值的理解。 02 函数说明 2.1 Read_CSV()函数 官方语法如下:…...
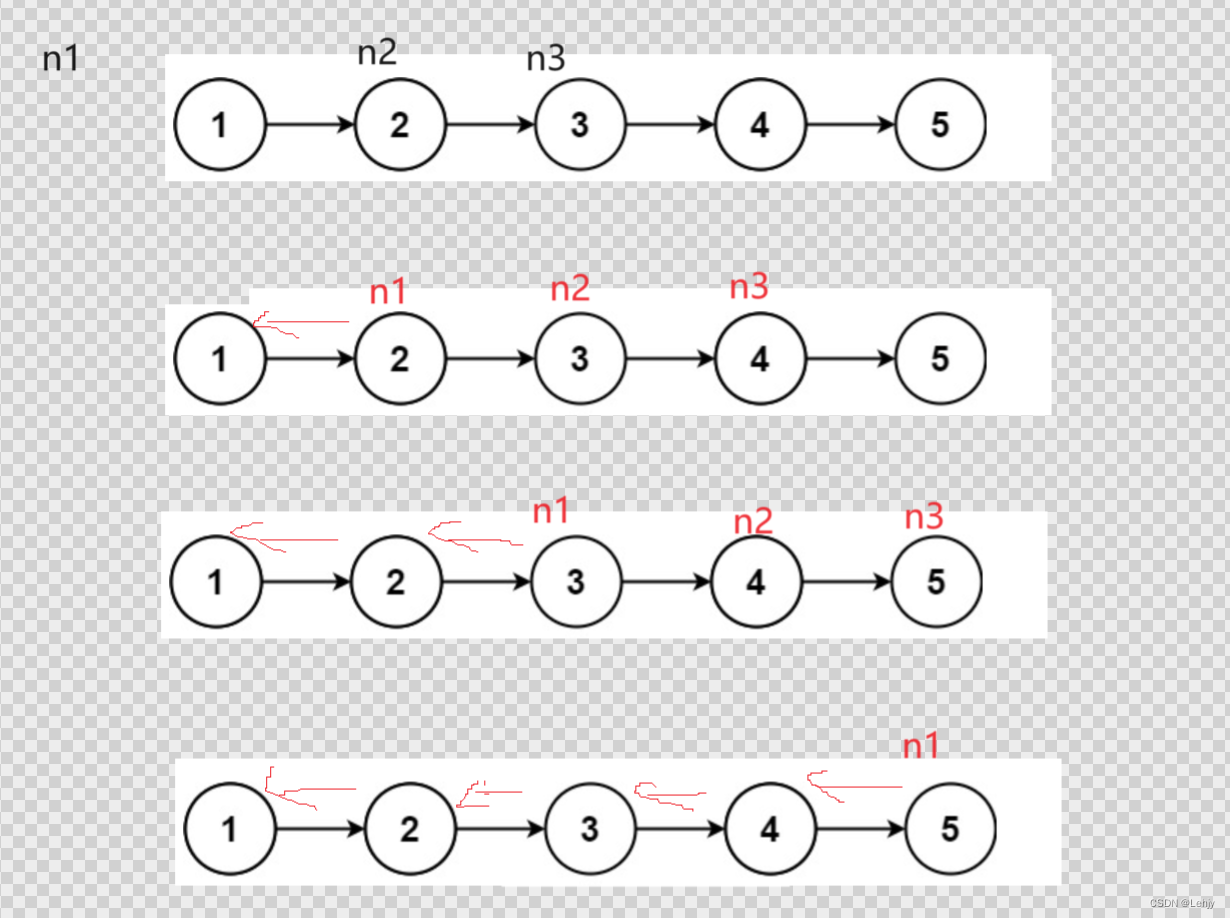
实战Leetcode(四)
Practice makes perfect! 实战一: 这个题由于我们不知道两个链表的长度我们也不知道它是否有相交的节点,所以我们的方法是先求出两个链表的长度,长度长的先走相差的步数,使得两个链表处于同一起点,两个链…...
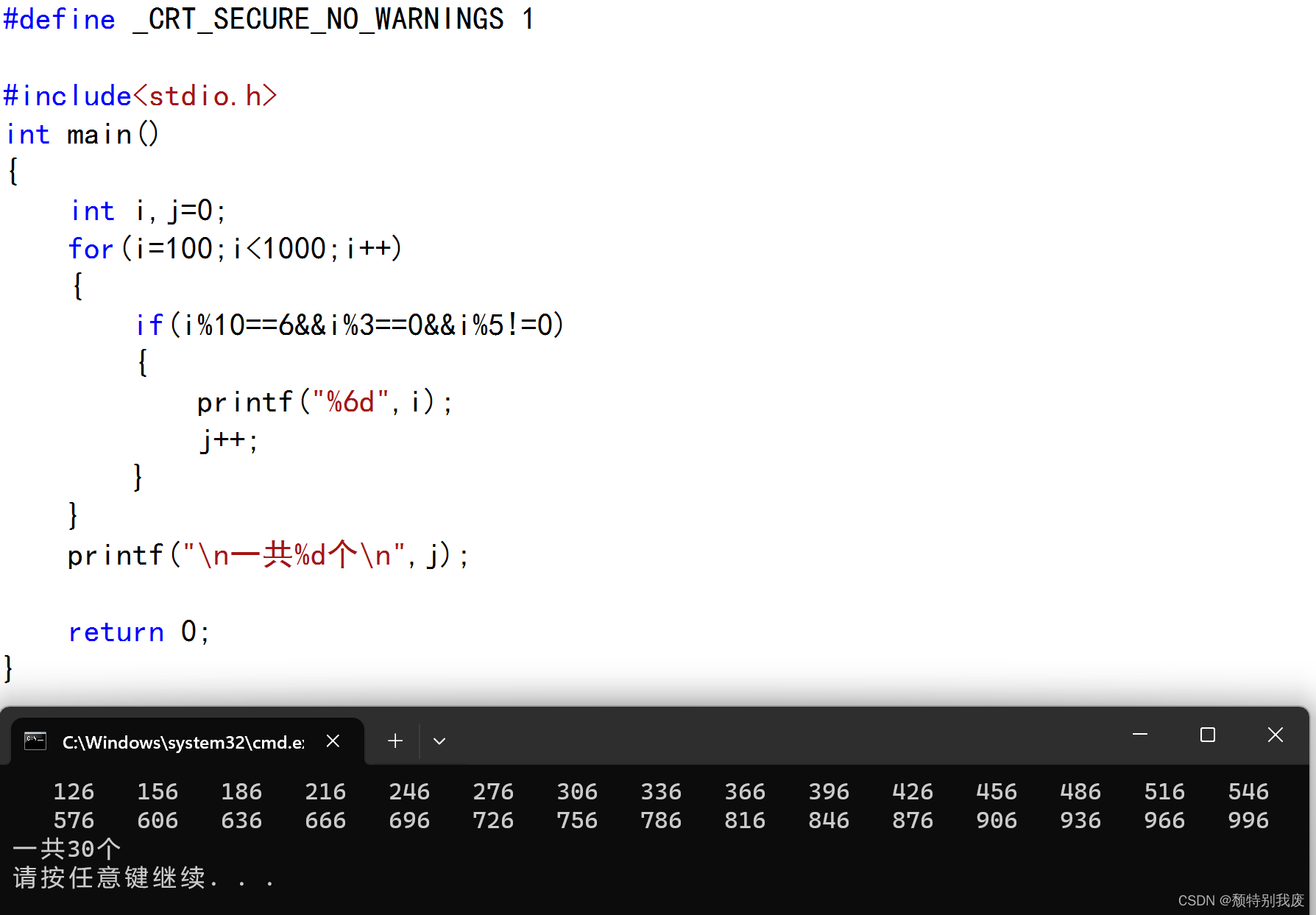
C语言——个位数为 6 且能被 3 整除但不能被 5 整除的三位自然数共有多少个,分别是哪些?
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> int main() {int i,j0;for(i100;i<1000;i) {if(i%106&&i%30&&i%5!0){printf("%6d",i); j;}}printf("\n一共%d个\n",j);return 0; } %6d起到美化输出格式的作用ÿ…...

基于Docker容器DevOps应用方案
文章目录 基于docker容器DevOps应用方案环境基础配置1.所有主机永久关闭防火墙和selinux2.配置yum源3.docker的安装教程 配置主机名与IP地址解析部署gitlab.server主机1.安装gitlab2.配置gitlab3.破解管理员密码4.验证web页面 部署jenkins.server主机1.部署tomcat2.安装jenkins…...
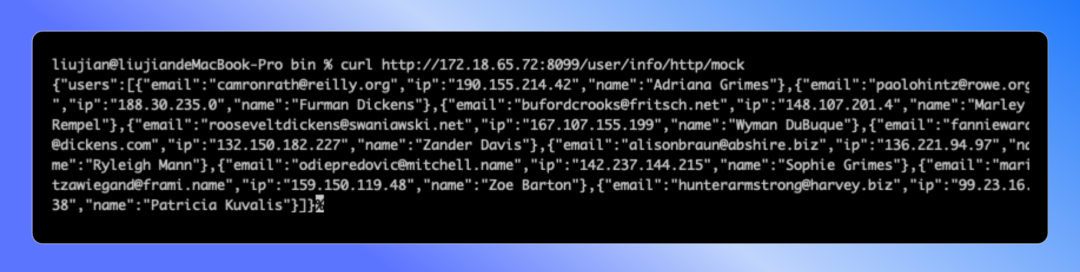
Apinto 网关进阶教程,使用 API Mock 生成模拟数据
什么是 API Mock ? API Mock 是一种技术,它允许程序员在不依赖后端数据的情况下,模拟 web服务器端 API 的响应。通常使用 API Mock 来测试前端应用程序,而无需等待后端程序构建完成。API Mock 可以模拟任何 HTTP 请求方法&#x…...
笔记:AI量化策略开发流程-基于BigQuant平台(一)
从本文开始,按照AI策略开发的完整流程(共七步),上手在BigQuant平台上快速构建AI策略。本文首先介绍如何使用证券代码模块指定股票范围和数据起止日期。重要的事情说三遍:模块的输入端口有提示需要连线的上游数据类型&a…...

Spring Cloud 微服务入门篇
文章目录 什么是微服务架构 Microservice微服务的发展历史微服务的定义微小的服务微服务 微服务的发展历史1. 微服务架构的发展历史2. 微服务架构的先驱 微服务架构 Microservice 的优缺点1. 微服务 e Microservice 优点2. 微服务 Microservice 缺点微服务不是银弹:…...

使用Go语言搭建区块链基础
引言 随着区块链技术的发展,越来越多的人开始关注并使用这一技术,其中,比特币和以太坊等区块链项目正在成为人们关注的焦点。而Go语言作为一种高效、简洁的编程语言,越来越多的区块链项目也选择使用Go语言来搭建其底层基础。本文…...
)
手搓MyBatis框架(原理讲解)
你在学完MyBatis框架后会不会觉得很神奇,为什么我改一个配置文件就可以让程序识别和执行不同的sql语句操作数据库? SqlSessionFactoryBuilder,SqlSessionFactory和SqlSession对象到底是怎样执行的? 如果你有这些问题看就完事了 …...

FRC-EP系列--你的汽车数据一站式管家
FRC-EP系列产品主要面向汽车动力总成测试的客户,主要应用方向为残余总线仿真及网关。本文将详细介绍FRC-EP的产品特性和应用场景。 应用场景: 汽车电子生成研发过程中,需要对汽车各个控制器进行仿真测试,典型的测试对象有&#…...

【ARM Trace32(劳特巴赫) 使用介绍 3 - trace32 访问运行时的内存】
请阅读【ARM Coresight SoC-400/SoC-600 专栏导读】 文章目录 1.1 trace32 访问运行时的内存1.1.1 侵入式 运行时内存访问1.1.2 非侵入式运行时访问1.1.3 缓存一致性的非侵入式运行时访问 1.2 Trace32 侵入式和非侵入式 运行时访问1.2.1 侵入式访问1.2.2 非侵入式运行时访问 1…...
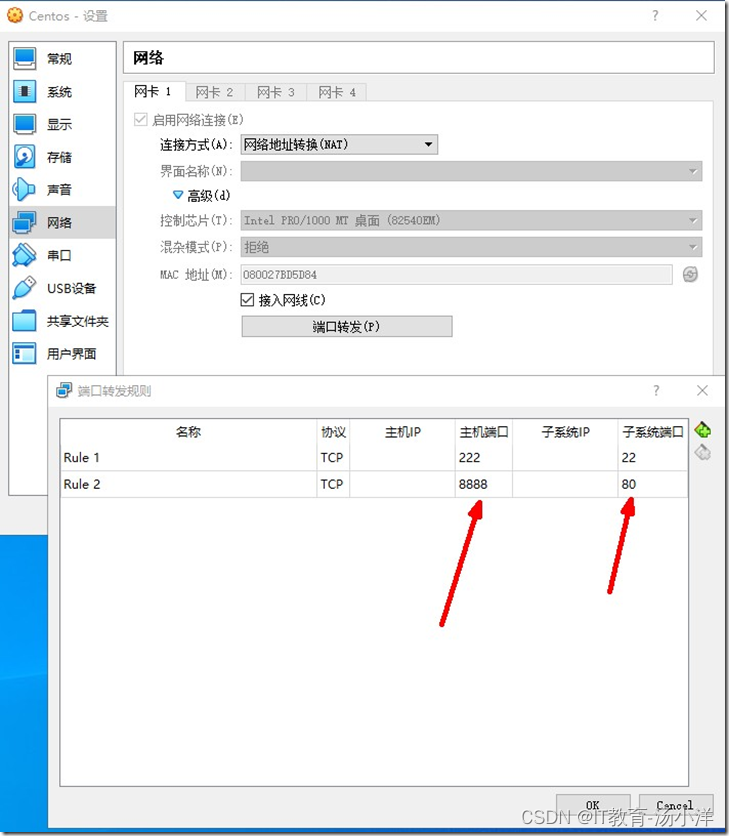
VirtualBox网络地址转换(NAT),宿主机无法访问虚拟机的问题
问题:NAT模式下,默认只能从内访问外面,而不能从外部访问里面,所以只能单向ping通,虚拟机的ip只是内部ip。 PS:桥接则是与主机公用网卡,有独立的外部ip。 解决:NAT模式可以通过配置 …...

【操作系统】考研真题攻克与重点知识点剖析 - 第 2 篇:进程与线程
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

总结:利用原生JDK封装工具类,解析properties配置文件以及MF清单文件
总结:利用原生JDK封装工具类,解析properties配置文件以及MF清单文件 一背景描述:1.在不同的项目中,项目使用的开发框架都不一样,甚至是JDK原生开发模式。此时解析配置文件以及jar包中的清单文件,就只能利用…...

35岁后端转AI应用开发1年我想说的是……
35岁后端8年,从Java到微服务,本以为资深能安稳,去年彻底慌了。 转型1年的经历、坑和建议,35后端转Al直接抄作业,少走弯路! 一、35岁必转AI应用的原因 被逼破局,而非跟风: 1.年龄…...

【泛微】动态联动控制:主表字段变化触发明细行智能增删与内容同步
1. 动态联动控制的业务价值 在OA系统的日常使用中,主表和明细表的联动操作是最让业务人员头疼的场景之一。想象一下这样的画面:采购员在创建采购单时,每次选择不同品类后,都要手动清空原有明细、重新添加对应物料,这种…...

吊耳承载力与钢丝绳选型计算软件开发-集成吊耳受力分析工具及钢丝绳匹配计算器
温馨提示:文末有资源获取方式高效解决钢结构吊装难题的智能计算工具在大型建筑项目中,钢柱与钢梁的吊装环节至关重要。 面对不确定使用何种规格吊耳的情况,工程师常常面临安全与效率的双重挑战。 为此,我们开发了集吊耳承重计算与…...

百元电视盒子如何变身高性能Linux服务器?Armbian系统刷机全攻略
百元电视盒子如何变身高性能Linux服务器?Armbian系统刷机全攻略 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l,…...

NVIDIA Jetson Orin系列:人形机器人边缘AI计算的革命性突破
1. 为什么人形机器人需要NVIDIA Jetson Orin? 当你看到波士顿动力Atlas机器人后空翻时,可能不会想到背后需要多少算力支持。传统机器人主控芯片在实时处理高清摄像头、激光雷达、惯性测量单元等多传感器数据时常常力不从心,就像用老年机玩3A游…...

智能体评测基础:能力、稳定性、安全性评估标准
文章目录前言一、智能体评测:为什么传统方法彻底失效?1.1 智能体 vs 传统软件:本质差异1.2 2026年智能体评测的核心原则(行业标准)1.3 评测的三层核心目标(2026 CLASSic框架)二、能力评估&#…...
的AI功能,轻松实现数学建模论文的复现与自动化排版)
使用爱毕业(aibiye)的AI功能,轻松实现数学建模论文的复现与自动化排版
还在为论文写作头痛?特别是数学建模的优秀论文复现与排版,时间紧、任务重,AI工具能帮上大忙吗?今天,我们评测10款热门AI论文写作工具,帮你精准筛选最适合的助手。 aibiye:专注于语法润色与结构…...
)
手把手教你为STM32F407添加USB2.0高速支持(含PHY选型与ULPI接线详解)
STM32F407 USB2.0高速通信实战指南:从PHY选型到性能优化 在嵌入式系统开发中,USB2.0高速接口(480Mbps)的实现一直是工程师面临的技术挑战之一。不同于USB1.1全速设备(12Mbps),高速USB对信号完整…...
_kaic)
spring boot社区养老保障系统小程序(文档+源码)_kaic
第五章 系统实现 5.1老人家属前台功能模块(前端) 社区养老保险系统小程序登录界面,通过填写账号、密码等信息进行登录,如图5-1所示。 图5-1登录界面图 注册,通过填写账号、密码、昵称、手机、邮箱、身份等信息&…...

Phi-4-mini-reasoning助力Java面试:算法与系统设计题智能解析
Phi-4-mini-reasoning助力Java面试:算法与系统设计题智能解析 1. 模型能力概览 Phi-4-mini-reasoning作为一款专注于代码生成与逻辑推理的AI模型,在Java技术面试准备中展现出独特价值。不同于通用编程助手,它能同时处理算法实现、系统设计思…...