bs4介绍和遍历文档树、搜索文档树、案例:爬美女图片、 bs4其它用法、css选择器
bs4介绍和遍历文档树
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,解析库
需要安装模块:pip install beautifulsoup4
使用
解析库可以使用 lxml,速度快(必须安装) 可以使用python内置的
# html_doc爬出的网页text
soup = BeautifulSoup(html_doc, 'html.parser')
重点:遍历文档树
遍历文档树:即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个
- 用法:通过
.遍历# 拿到 以下的第一个title res=soup.html.head.title# 拿到第一个p res=soup.p
- 取标签的名称
res=soup.html.head.title.name res=soup.p.name
- 获取标签的属性
# 标签的所有属性 res=soup.body.a.attrs # 所有属性放到字典中 :{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}# 获取第一个属性值 res=soup.body.a.attrs.get('href') res=soup.body.a.attrs['href'] res=soup.body.a['href']
- 获取标签的内容
res=soup.body.a.text res=soup.p.text# 这个标签有且只有文本,才取出来,如果有子孙,就是None res=soup.a.string res=soup.p.strings
- 嵌套选择
就是通过.嵌套
- 子节点、子孙节点
#p下所有子节点 print(soup.p.contents)#得到一个迭代器,包含p下所有子节点 print(list(soup.p.children)) #获取子子孙节点,p下所有的标签都会选择出来 print(list(soup.p.descendants))
- 父节点、祖先节点
#获取a标签的父节点 print(soup.a.parent)#找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲... print(list(soup.a.parents) )
- 兄弟节点
print(soup.a.next_sibling) #下一个兄弟 print(soup.a.previous_sibling) #上一个兄弟 print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象 print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
搜索文档树
find_all:找所有 列表find:找一个 Tag类的对象
find和find_all
五种过滤器: 字符串、正则表达式、列表、True、方法
字符串
可以按标签名,可以按属性,可以按文本内容
无论按标签名,按属性,按文本内容 都是按字符串形式查找
# 找到类名叫 story的p标签
p=soup.find('p')# 可以按标签名,可以按属性,可以按文本内容
p=soup.find(name='p',class_='story')
obj=soup.find(name='span',text='lqz')
obj=soup.find(href='http://example.com/tillie')# 属性可以写成这样
obj=soup.find(attrs={'class':'title'})
正则
无论按标签名,按属性,按文本内容 都是按正则形式查找
import re# 找到所有名字以b开头的所有标签
obj=soup.find_all(name=re.compile('^b'))# 以y结尾
obj=soup.find_all(name=re.compile('y$'))obj=soup.find_all(href=re.compile('^http:'))
obj=soup.find_all(text=re.compile('i'))
列表
无论按标签名,按属性,按文本内容 都是按列表形式查找
# 所有a标签和标签放到一个列表里
obj=soup.find_all(name=['p','a'])
obj = soup.find_all(class_=['sister', 'title'])
True
无论按标签名,按属性,按文本内容 都是按布尔形式查找
obj=soup.find_all(id=True)
obj=soup.find_all(href=True)
obj=soup.find_all(name='img',src=True)
方法
无论按标签名,按属性,按文本内容 都是按方法形式查找
## 有class但没有id
def has_class_but_no_id(tag):return tag.has_attr('class') and not tag.has_attr('id')print(soup.find_all(name=has_class_but_no_id))
案例:爬美女图片
import requests
from bs4 import BeautifulSoupres = requests.get('https://pic.netbian.com/tupian/32518.html')
res.encoding = 'gbk'soup = BeautifulSoup(res.text, 'html.parser')ul = soup.find('ul', class_='clearfix')
img_list = ul.find_all(name='img', src=True)for img in img_list:try:url = img.attrs.get('src')if not url.startwith('http'):url = 'https://pic.netbian.com' + urlres1 = requests.get('url')name = url.split('-')[-1]with open('./img/%s' % name, 'wb') as f:for line in res1.iter_content():f.write(line)except Exception as e:continue
bs4其它用法
-
遍历,搜索文档树 ⇢ \dashrightarrow ⇢ bs4还可以修改xml
- java的配置文件一般喜欢用xml写
- .conf
- .ini
- .yaml
- .xml
-
find_all 其他参数
limit=数字找几条 ,如果写1 ,就是一条recursive:默认是True,如果改False,在查找时只查找子节点标签,不再去子子孙孙中寻找
-
搜索文档树和遍历文档树可以混用,找属性,找文本跟之前学的一样
css选择器
- id选择器:
#id号 - 标签选择器:
标签名 - 类选择器:
.类名 - 属性选择器
需要记住的
#id.sisterheaddiv>a:# div下直接子节点adiv a:div下子子孙孙节点a
一旦会了css选择器的用法 ⇢ \dashrightarrow ⇢ 以后所有的解析库都可以使用css选择器去找
查找:p=soup.select('css选择器')
复制参考:https://www.runoob.com/cssref/css-selectors.html
案例
import requests
from bs4 import BeautifulSoupres = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005896.html')
soup = BeautifulSoup(res.text, 'html.parser')# 以后直接复制即可
p = soup.select('a[title="下载哔哩哔哩视频"]')[0].attrs.get('href')
print(p)
相关文章:

bs4介绍和遍历文档树、搜索文档树、案例:爬美女图片、 bs4其它用法、css选择器
bs4介绍和遍历文档树 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,解析库 需要安装模块:pip install beautifulsoup4 使用 解析库可以使用 lxml,速度快(必须安装) 可以使用python内置的 # html…...
微服务-开篇-个人对微服务的理解
从吃饭说起 个人理解新事物的时候喜欢将天上飞的理念转换成平常生活中的实践,对比理解这些高大上的名词,才能让我们减少恐慌的同时加深理解。废话不多说,我们从吃饭开始说起,逐渐类比出微服务的思想。 (个人见解&…...

机器学习算法-集成学习
概念 集成学习是一种机器学习方法,它通过构建并结合多个机器学习器(基学习器)来完成学习任务。集成学习的潜在思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成学习通常被视为一种元算法&…...

LINUX入门篇【4】开发篇--开发工具vim的使用
前言: 从这一篇开始,我们将正式进入使用LINUX进行写程序和开发的阶段,可以说,由此开始,我们才开始真正去使用LINUX。 介绍工具: 1.LINUX软件包管理器yum: 1.yum的介绍: 在LINUX…...

代码随想录算法训练营Day 50 || 309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费
309.最佳买卖股票时机含冷冻期 力扣题目链接 给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票): 你不能同时…...

【C语言】【数据结构】【环形链表判断是否带环并返回进环节点】有数学推导加图解
1.判断是否带环: 用快慢指针 slow指针一次走一步,fast指针一次走两步 当两个指针相遇时,链表带环;两个指针不能相遇时,当fast走到倒数第一个节点或为空时,跳出循环返回空指针。 那么slow指针一次走一步&a…...
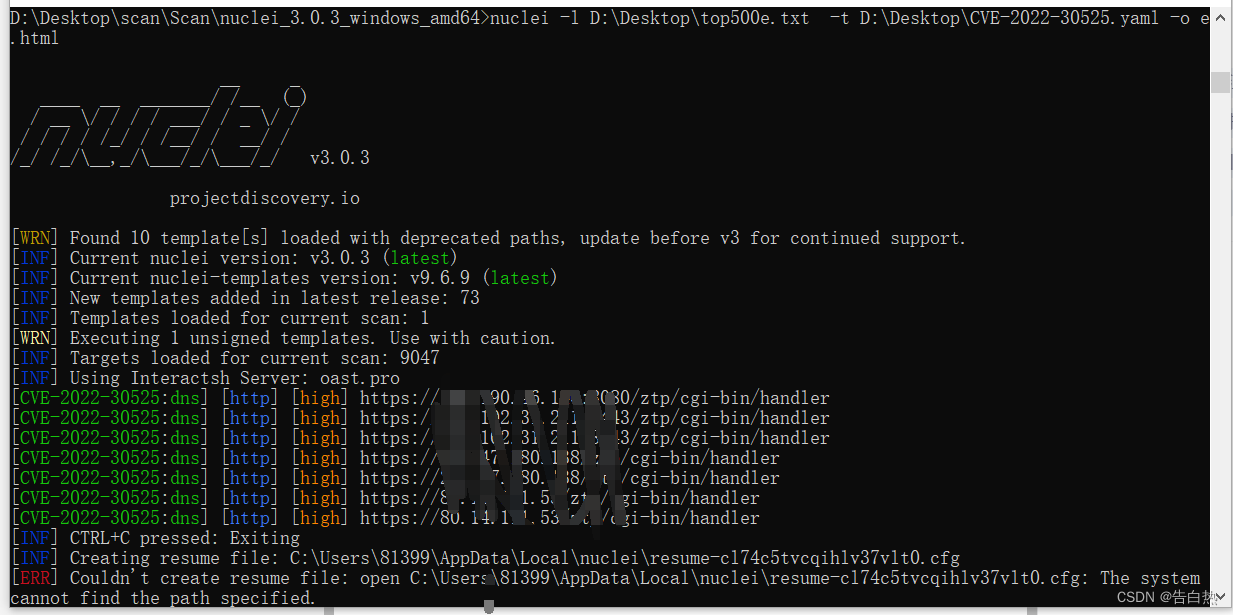
漏洞扫描-nuclei-poc编写
0x00 nuclei Nuclei是一款基于YAML语法模板的开发的定制化快速漏洞扫描器。它使用Go语言开发,具有很强的可配置性、可扩展性和易用性。 提供TCP、DNS、HTTP、FILE 等各类协议的扫描,通过强大且灵活的模板,可以使用Nuclei模拟各种安全检查。 …...

SpringBoot 自动配置
Condition 自定义条件: 定义条件类:自定义类实现Condition接口,重写 matches 方法,在 matches 方法中进行逻辑判断,返回boolean值 。 matches 方法两个参数: context:上下文对象,可…...
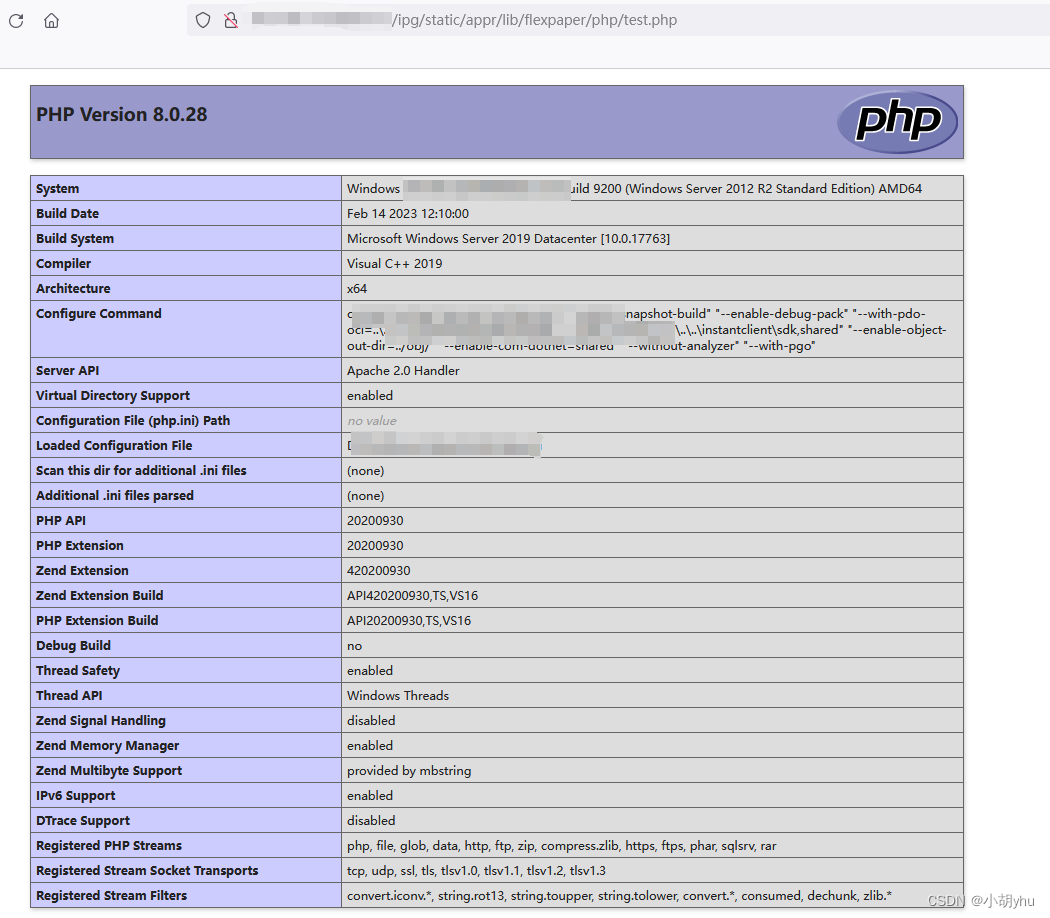
IP-guard WebServer 远程命令执行漏洞
IP-guard WebServer 远程命令执行漏洞 免责声明漏洞描述漏洞影响漏洞危害网络测绘Fofa: app"ip-guard" 漏洞复现1. 构造poc2. 访问文件3. 执行命令 免责声明 仅用于技术交流,目的是向相关安全人员展示漏洞利用方式,以便更好地提高网络安全意识和技术水平。 任何人不…...
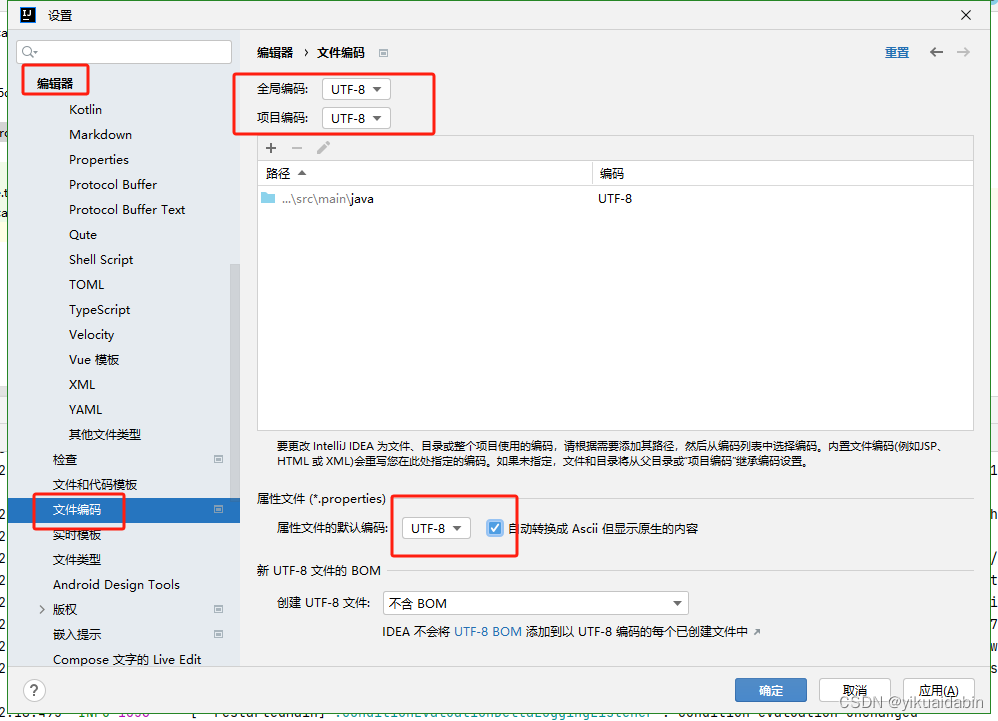
每次重启完IDEA,application.properties文件里的中文变成?
出现这种情况,在IDEA打开Settings-->Editor-->File Encodings 然后,你需要将问号改为你需要的汉字。 重启IDEA,再次查看你的.properties文件就会发现再没有变成问号了...
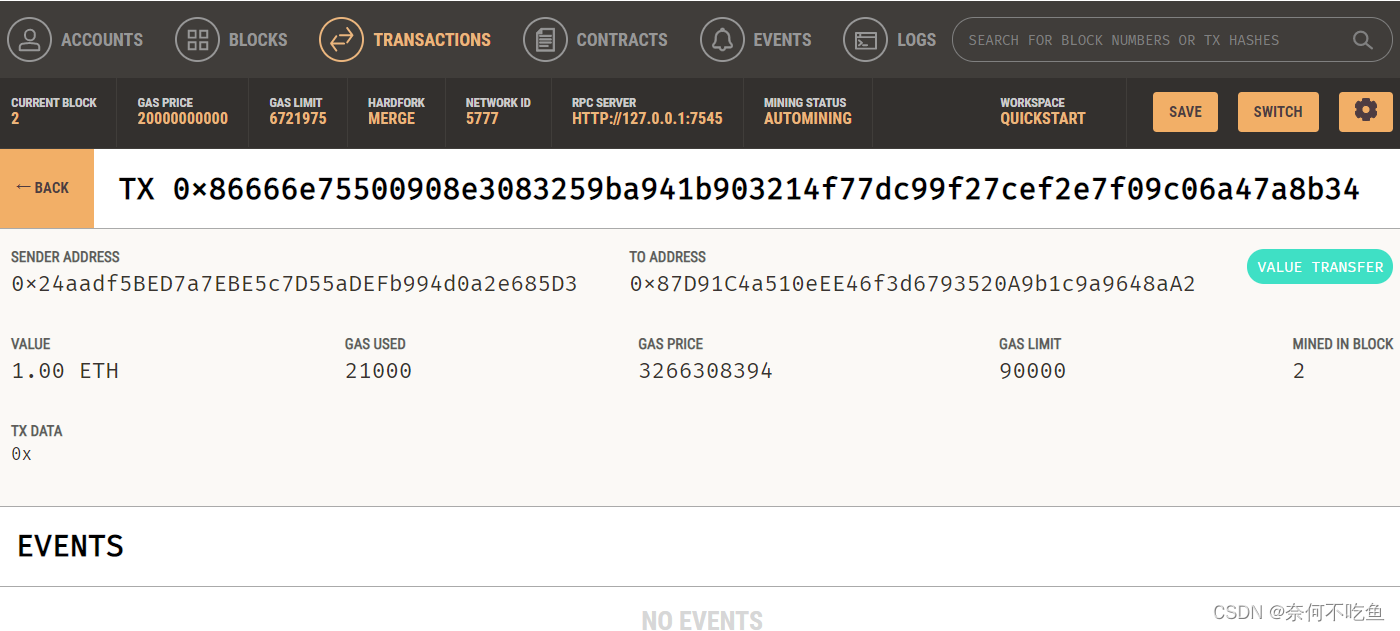
【Truffle】四、通过Ganache部署连接
目录 一、下载安装 Ganache: 二、在本地部署truffle 三、配置ganache连接truffle 四、交易发送 除了用Truffle Develop,还可以选择使用 Ganache, 这是一个桌面应用,他同样会创建一个个人模拟的区块链。 对于刚接触以太坊的同学来说&#x…...
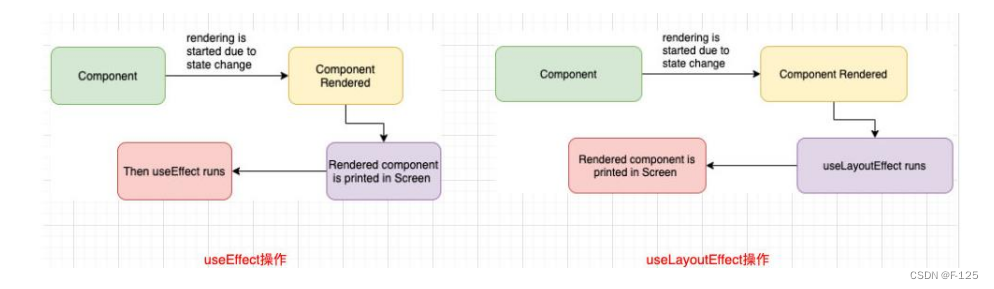
React 其他常用Hooks
1. useImperativeHandle 在react中父组件可以通过forwardRef将ref转发到子组件;子组件拿到父组件创建的ref,绑定到自己的某个元素; forwardRef的做法本身没有什么问题,但是我们是将子组件的DOM直接暴露给了父组件,某下…...
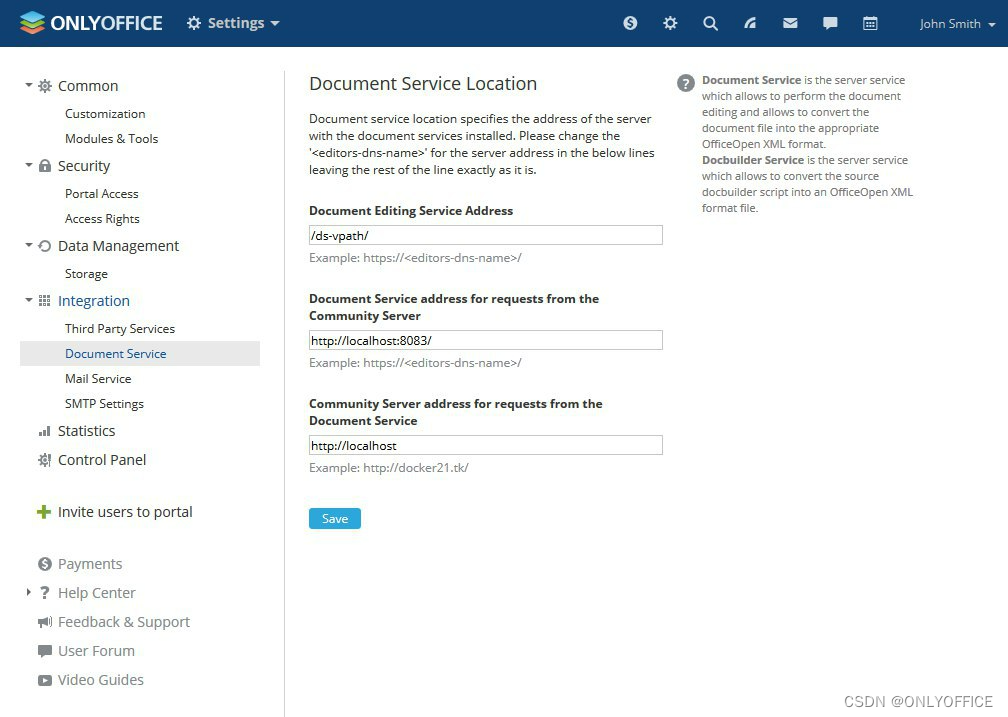
将 ONLYOFFICE 文档编辑器与 С# 群件平台集成
在本文中,我们会向您展示 ONLYOFFICE 文档编辑器与其自有的协作平台集成。 ONLYOFFICE 是一款开源办公套件,包括文本文档、电子表格和演示文稿编辑器。这款套件支持用户通过文档编辑组件扩展第三方 web 应用的功能,可直接在应用的界面中使用。…...

使用电脑时提示msvcp140.dll丢失的5个解决方法
“计算机中msvcp140.dll丢失的5个解决方法”。在我们日常使用电脑的过程中,有时会遇到一些错误提示,其中之一就是“msvcp140.dll丢失”。那么,什么是msvcp140.dll呢?它的作用是什么?丢失它会对电脑产生什么影响呢&…...

VR全景如何应用在房产行业,VR看房有哪些优势
导语: 在如今的数字时代,虚拟现实(VR)技术的迅猛发展为许多行业带来了福音,特别是在房产楼盘行业中。通过利用VR全景技术,开发商和销售人员可以为客户提供沉浸式的楼盘浏览体验,从而带来诸多优…...

11月份 四川汽车托运报价已经上线
中国人不骗中国人!! 国庆小长假的高峰期过后 放假综合症的你还没痊愈吧 今天给大家整理了9条最新线路 广州到四川的托运单价便宜到💥 核算下来不过几毛钱💰 相比起自驾的漫长和疲惫🚗 托运不得不说真的很省事 - 赠送保险 很多客户第一次运车 …...
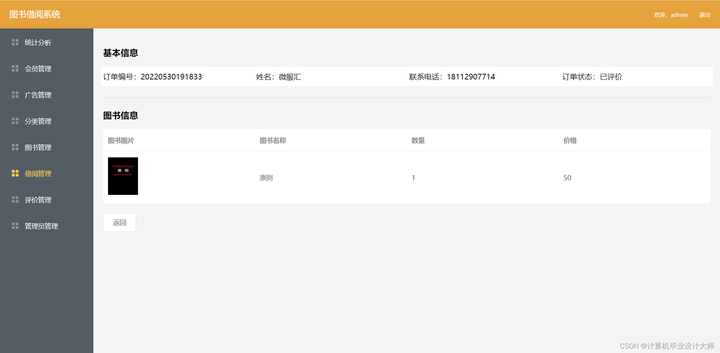
springcloud图书借阅管理系统源码
开发说明: jdk1.8,mysql5.7,nodejs,idea,nodejs,vscode springcloud springboot mybatis vue elementui 功能介绍: 用户端: 登录注册 首页显示搜索图书,轮播图&…...

主题模型LDA教程:LDA主题数选取:困惑度preplexing
文章目录 LDA主题数困惑度1.概率分布的困惑度2.概率模型的困惑度3.每个分词的困惑度 LDA主题数 LDA作为一种无监督学习方法,类似于k-means聚类算法,需要给定超参数主题数K,但如何评价主题数的优劣并无定论,一般采取人为干预、主题…...

Docker快速入门
Docker是一个用来快速构建、运行和管理应用的工具。 Docker技术能够避免对服务器环境的依赖,减少复杂的部署流程,有了Docker以后,可以实现一键部署,项目的部署如丝般顺滑,大大减少了运维工作量。 即使你对Linux不熟…...
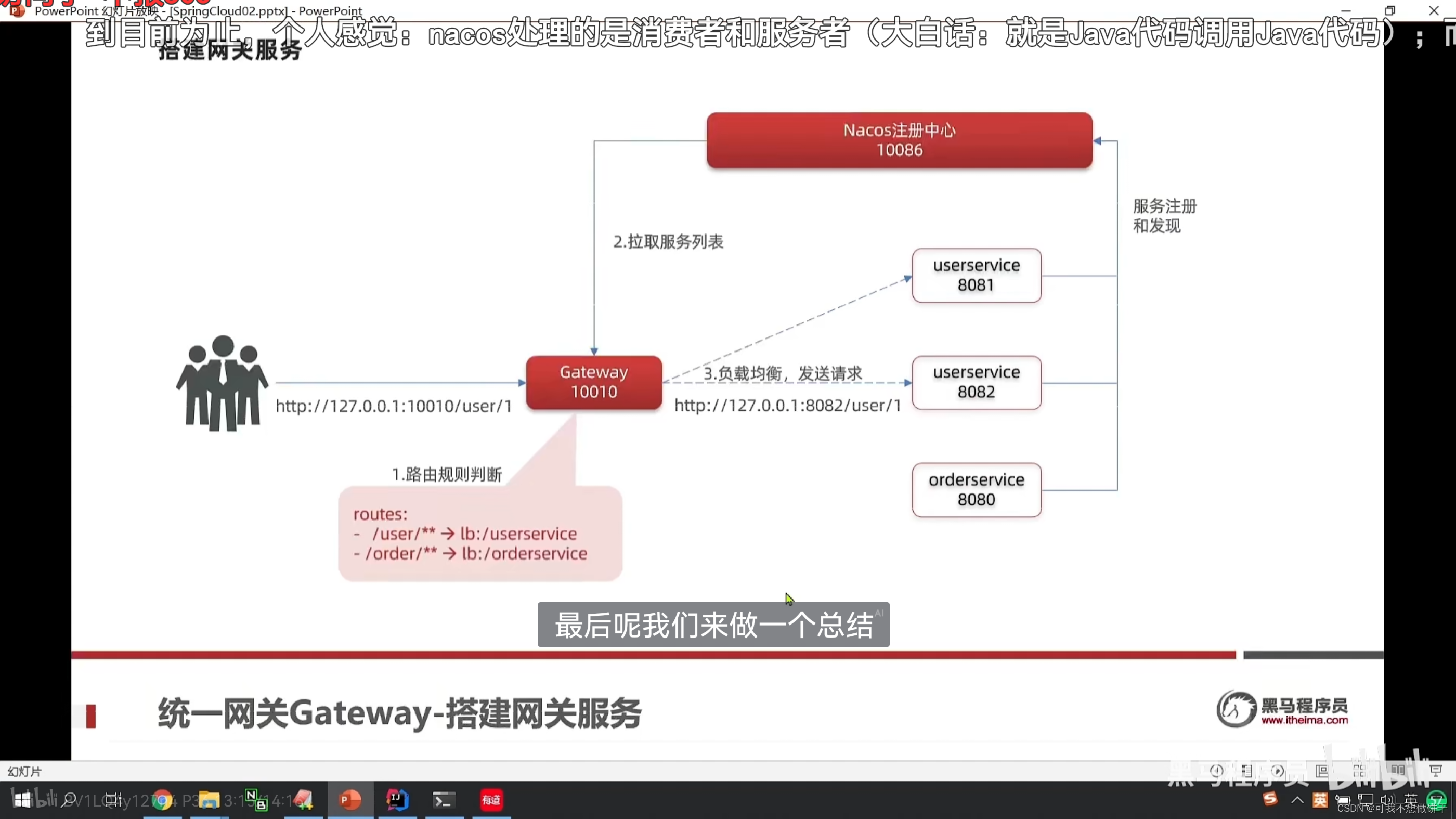
36 Gateway网关 快速入门
3.Gateway服务网关 Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式…...

AI教材生成神器,一键编写低查重教材,开启高效创作模式
AI助力教材写作:高效工具全解析 在编写教材的过程中,总是能深刻感受到“慢节奏”的所有烦恼。尽管框架和资料已经准备妥当,却总是卡在内容的撰写上——有一句话琢磨了半个小时,依然觉得表述不够准确;章节间的衔接&…...

微信群消息自动流转:3分钟搭建你的智能同步系统
微信群消息自动流转:3分钟搭建你的智能同步系统 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 你是否厌倦了在多个微信群之间手动转发重要消息?是否曾因信息同步不及…...
Windows任务栏透明化革命:TranslucentTB如何重新定义你的桌面体验
Windows任务栏透明化革命:TranslucentTB如何重新定义你的桌面体验 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否曾盯…...

AD20隐藏技巧:把Mooretronics矢量图标当“字”用,丝印管理从此清爽了
AD20高阶技巧:用Mooretronics矢量图标构建企业级丝印管理系统 在PCB设计领域,丝印层的规范管理往往被低估,直到团队协作时才发现图标风格不一、大小参差的问题。Mooretronics字体图标库提供了一种革命性的解决方案——将常用标识转化为可统一…...

蓝牙BR/EDR链路监控超时机制解析与应用场景
1. 蓝牙BR/EDR链路监控超时机制是什么? 当你用蓝牙耳机听歌时,有没有遇到过音乐突然中断的情况?这很可能和Link Supervision Timeout机制有关。简单来说,这是蓝牙BR/EDR技术中的"心跳检测"功能,用来判断设备…...

UniApp多商户小程序SaaS化部署:用Jenkins+miniprogram-ci搞定批量自动发布
UniApp多商户小程序SaaS化批量发布实战:Jenkinsminiprogram-ci架构设计与工程实践 当你的业务需要同时管理数十个甚至上百个独立微信小程序时,每次功能迭代带来的发布工作量会呈指数级增长。我们曾经历过为50家连锁门店更新小程序时,手动操作…...
)
国标GBT 28181实战解析:第三方呼叫控制在跨平台历史视音频回放中的关键实现(GB/T28181-2022)
1. 第三方呼叫控制机制在GB/T28181-2022中的核心价值 第一次接触国标GB/T28181的开发者,往往会被其复杂的协议栈和交互流程吓退。但当我真正在跨厂商视频监控项目中实施第三方呼叫控制时,才发现这套机制的精妙之处。想象一下这样的场景:某大型…...

软件可维护性的修改扩展与理解难度
软件可维护性的修改扩展与理解难度 在软件开发的生命周期中,可维护性是衡量软件质量的重要指标之一。随着业务需求的不断变化和技术的迭代更新,软件需要频繁修改和扩展,而代码的可维护性直接影响开发团队的工作效率。理解难度则是可维护性的…...

QMCDecode终极指南:轻松破解QQ音乐加密格式,实现跨平台播放
QMCDecode终极指南:轻松破解QQ音乐加密格式,实现跨平台播放 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

【DeepSeek】ELF 中的PT_LOAD
在 ELF(Executable and Linkable Format)文件格式中,PT_LOAD 是程序头表中最重要的段类型。以下是对 PT_LOAD 的定义、具体包含的种类以及与其类似的其他段类型的完整解析。1. 什么是 PT_LOAD? 定义: PT_LOAD 表示一个…...