111111111111111
全局锁
就是对整个数据库进行加锁,加锁之后整个数据库就处于只读状态,后续的DML写语句,DDL语句,以及对更新事务的提交操作都会被阻塞,典型地使用场景就是做整个数据库的逻辑备份,对所有的表进行锁定,从而获取到一致性视图,保证数据的完整性,是锁粒度最大的锁,只能进行查询操作
就是将我们数据库中的数据,放到一个文件里面做数据备份
加全局锁:flush tables with read lock;
进行数据备份:mysqldump -uroot -p12503487 数据库名> D:/mysql.sql
释放锁:unlock tables;
表级锁:每一次操作直接进行锁住整张表,锁的粒度大,锁冲突的概率比较高,并发性是最低的,应用在MYISM,INNDB引擎当中,对于表级锁,主要分成三类:
一.表锁:对于表锁,主要分为两类:
加锁操作:
lock tables 表名+read;表示加读锁
lock tables 表名+write;表示加写锁
解锁操作:
unlock tables;
1)表共享读锁:
所有操作只能读,不能写,所有客户端都可以读,都不可以写
1.1)首先客户端1对这张表加了一个读锁,就会把这张表锁住了,那么客户端1肯定是可以读取这张表的数据的,那么客户端1只能读取这张表里面的数据,是不能够写数据和操作事务
1.2)此时假设有一个客户端2想读取这张表的数据是可以的,但是想写数据和操作事务是不可以的
对于当前加读锁的客户端,进行更新操作直接会出现报错信息,对于其他客户端,想要操作这张表,即使输入SQL语句,也会阻塞等待,只有等到对应的加锁的客户端把所释放之后,之前阻塞的SQL语句才可以执行成功
2)表共享写锁:metadata
当前加写锁的客户端既能进行读,也可以进行写操作,但是别的客户端既不可以读,也是不可以写的,就会阻塞等待,一直阻塞到表锁释放为止
二:元数据锁:元数据锁,无需进行显式使用,在我们访问一张表的时候会自动加上,也就是说某一张表存在未提交的事务,我们是不能修改这张表的表结构,如果输入了对应的SQL语句,就会出现阻塞状态,为了防止DDL和DML语句冲突,保证数据读写的正确性
当我们对一张表进行增删改查的时候,加上MDL读锁(共享锁)-----兼容
当我们对表结构进行变更的时候,会加上MDL写锁(排它锁)
1)比如说咱们的客户端1开启了一个事务,现在进行查询select * from student,咱们的客户端2想要进行修改这个表结构:alert table add column Java int,这个客户端就会出现阻塞状态
2)一直阻塞到事务提交
元数据锁可以认为就是认为是一张表的结构;
三:意向锁:是给表中的行加锁的时候(顺便加上的)
1)假设我们没有意向锁,那么客户端1对表加上了行锁之后,客户端二如何给表进行加锁呢?
2)我们对于一个客户端1,开启一个事务,进行数据的更新操作DML语句,在进行更新的时候,会给涉及到的行进行加锁,客户端2想要对这张表进行加锁的时候,会检查当前表中是否有对应的行锁,如果说没有,就进行添加表锁,
3)此时就会从第一行数据,检查到最后一行数据,效率很低
意向共享锁(IS):由select ......lock in share mode 添加,和表级共享锁(read)兼容,和表级排它锁互斥(write);
1)select * from score where id=1 lock in share mode; 表示给这一行数据加上一个行锁的共享锁,还会给这一张score表加上一个意向共享锁,咱们现在的侧重点是给这张表加上意向共享锁 2)其他会话进行给整张表进行加锁的时候:lock table score read;//表示给表加锁成功,因为意向共享锁和(给表加读锁)是兼容的 3)如果说其他会话加上了lock table score write;//表示加锁失败,因为意向共享锁是(和给表加写锁)是互斥的,一直处于阻塞状态意向排它锁:由insert update delete,select.....for update进行添加,和表级共享锁(read)和表级排它锁互斥(write),但是意向锁之间不会互斥;
当我们顺便给一行进行加锁的时候: update student set username="A"; 1)此时就会给表锁自动加上一个意向排它锁,那么此时别的客户端 进行给整张表加读锁和写锁都会失败 2)因为此时InnoDB引擎会自动进行判断当前表是否有意向锁,有的话,是意向排它锁还是意向共享锁,再决定和当前给表加读锁和写锁是否互斥
1)客户端1在进行执行DML语句操作的时候,会对涉及到的行进行加锁,同时也会对该表进行加锁(意向锁)
2)而其他的客户端,在对这张表加上表锁的时候,会先根据给表曾经加上的意向锁来进行判定是否可以成功的加上表锁,而不用再判断行锁情况了
3)而意向锁的种类以及是否最终表锁最终是否会添加成功,完全取决于加行锁的时候的行为
一旦我们的事务提交了,那么最终我们的意向共享锁,意向排它锁都会进行释放
行级锁:
1)行级锁是每一次操作都会锁住对应的行数据,锁的粒度最小,发生锁冲突的概率最低并发最高,应用在InnoDB引擎当中
2)InnoDB引擎是基于索引来进行组织的,行锁是针对索引上面的索引项来进行加锁实现的,而不是针对记录进行加锁
一:行锁:
锁住单个行记录的锁,防止其他事务进行update和delete,在read commited 和reapitable read都支持:
在InnoDB引擎里面我们进行提供了两种类型的行锁:
1)共享锁:S共享锁和共享锁之间是兼容的,共享锁和排它锁之间是互斥的,事务A可以获取到这一行数据的共享锁,事务B可以获取到这个数据行的共享锁
2)排它锁S:某一个事务获取到了某一行数据的排它锁,就不能在获取到这一行数据的共享锁和排它锁了,排它锁和排它锁都是互斥的
常用的对数据进行增删改查的加行锁操作:
1)insert update delete 会自动加上排它锁
2)select 不会加上任何锁
3)select+对应的SQL语句+lock+in+share++mode;----会自动加上共享锁
4)select+for+update会自动加上排它锁
假设现在客户端1进行给行数据加上共享锁: 1)select * from stu where userID=1 lock in share model; 现在客户端2进行操作: 1)update set username="Java" where userID=3;//这条语句将会被正常执行,因为之前共享锁所得是id=1的叶子节点的数据,但是id=3的叶子节点的数据并没有被锁住 2)update set username="C++" where userID=1;//这个就会失败,之前在第一个客户端已经给id=1的行数据加上了共享锁,而此时还想加排它锁,那么此时就会出现不兼容的情况,就会出现堵塞等待此时我们在进行举一个例子: 1)客户端1进行修改操作: update student set username="" where id=1; 2)当我们的第二个客户端也进行操作更新的时候,就会失败: update userInfo set username="admin" where userID=6;此时执行着一条语句的时候就会尝试给这一行加上排它锁,但是之前已经加过排它锁了,排它锁和排它锁之间互斥,所以会一直进行阻塞等待 3)我们的第二个客户端再去执行:select * from userInfo; 4)select * from userInfo where userID=6 lock in share mode;此时我们想查询这一行数据,会自动加上共享锁,共享锁和排它锁之间会互斥注意:
1)当我们对唯一索引进行检索的时候,对已经存在的记录进行等值匹配的时候,会被自动优化成行锁
2)InnoDB的行锁是针对索引来进行加的锁,不通过索引来进行检索数据,那么InnoDB引擎会对表中所有的记录进行加锁,此时就会升级成表锁,当我们针对索引字段进行更新操作,就可以避免行锁升级成表锁的情况
3)此时我们开启一个事务update student set username="Java" where username="Java",此时我们并没有针对name字段进行建立索引,此时我们但是根据name字段来进行查询,就会出现直接给整张表加锁
4)此时我们进行对整张表的任意一个字段,都会失败
二:间隙锁(Gap)
间隙锁是直接锁住索引间隙记录(不会包含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行插入操作,产生幻读,在可重复读的事务隔离级别下支持
间隙锁Gap,左右都是开区间,间隙锁+行锁合称next-key lock,每个 next-key lock 是前开后闭区间。间隙锁和next-key lock的引入帮我们解决幻读问题。
三:临键锁:行锁和间隙锁进行组合,不仅锁住对应的行,还锁住了前面的间隙(RR下支持)
默认情况下:InnoDB使用repeatable read事务隔离级别来进行运行,InnoDb使用临建锁来进行搜索和索引扫描:
1)当我们进行索引上面的等值查询的时候,给不存在的记录进行加锁的时候,优化成间隙锁,会优化成两端区间的间隙加锁
1)select * from stu; +----+------+----------+ | id | name | password | +----+------+----------+ | 1 | A | 1234 | | 4 | B | 8899 | +----+------+----------+ 2 rows in set (0.00 sec) 2)mysql> create index nameIndex on stu(name);//我们给他建立唯一索引 3)pdate stu set name="Java" where id=2;现在我们进行数据的更新操作 此时客户端2进行开启事务,进行尝试在1和4之间插入数据: insert into stu values(3,"N","777888"); 此时就会插入失败2)当我们进行加锁的时候,我们是针对索引来进行加锁的,而索引是一个B+树,而B+树的叶子结点是一个有序的双向链表,
1)当前假设是唯一索引,那么我对18这个记录进行操作的时候,是不会插入一条记录是18的数据的
2)但是此时是非唯一索引,有可能在18之后进行加锁,也有可能对18到29之间继续加锁,那么会向后遍历一个值不满足需求的时候,临建锁会退化成间隙锁,会对18-29和16-18这段空隙进行加锁
3)我们接下来进行演示一下:
客户端1: //1.先创建一张表create table stu(id int,username varchar(50),password varchar(50),age varchar(40)); //2.进行插入语句:select * from stu; +------+----------+----------+------+ | id | username | password | age | +------+----------+----------+------+ | 1 | A | 126 | 1 | | 2 | B | 89 | 3 | | 3 | C | 90 | 10 | +------+----------+----------+------+ //3.进行查询:针对age字段创建普通索引:create index age on stu(age); //4.开启事务:start transcation; //5.进行更新操作: update stu set password="90" where age=3; 客户端2: 开启事务进行插入操作: insert into stu values(2,"D","ooo",2);失败 客户端3: 开启事务进行插入操作: insert into stu values(2,"D","ooo",8);失败 //因为此时年龄字段,已经对1-3和3-10这段区间进行加上了间隙锁3)索引上面的范围查询,会进行访问到不满足条件的第一个值为止:
start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from stu where age>4 lock in share mode; +------+----------+----------+------+ | id | username | password | age | +------+----------+----------+------+ | 3 | C | 90 | 10 | | 2 | D | ooo | 12 | +------+----------+----------+------+ 此时就在年龄4以后加了间隙锁,以后的其他客户端不允许在
相关文章:
111111111111111
全局锁 就是对整个数据库进行加锁,加锁之后整个数据库就处于只读状态,后续的DML写语句,DDL语句,以及对更新事务的提交操作都会被阻塞,典型地使用场景就是做整个数据库的逻辑备份,对所有的表进行锁定&#x…...
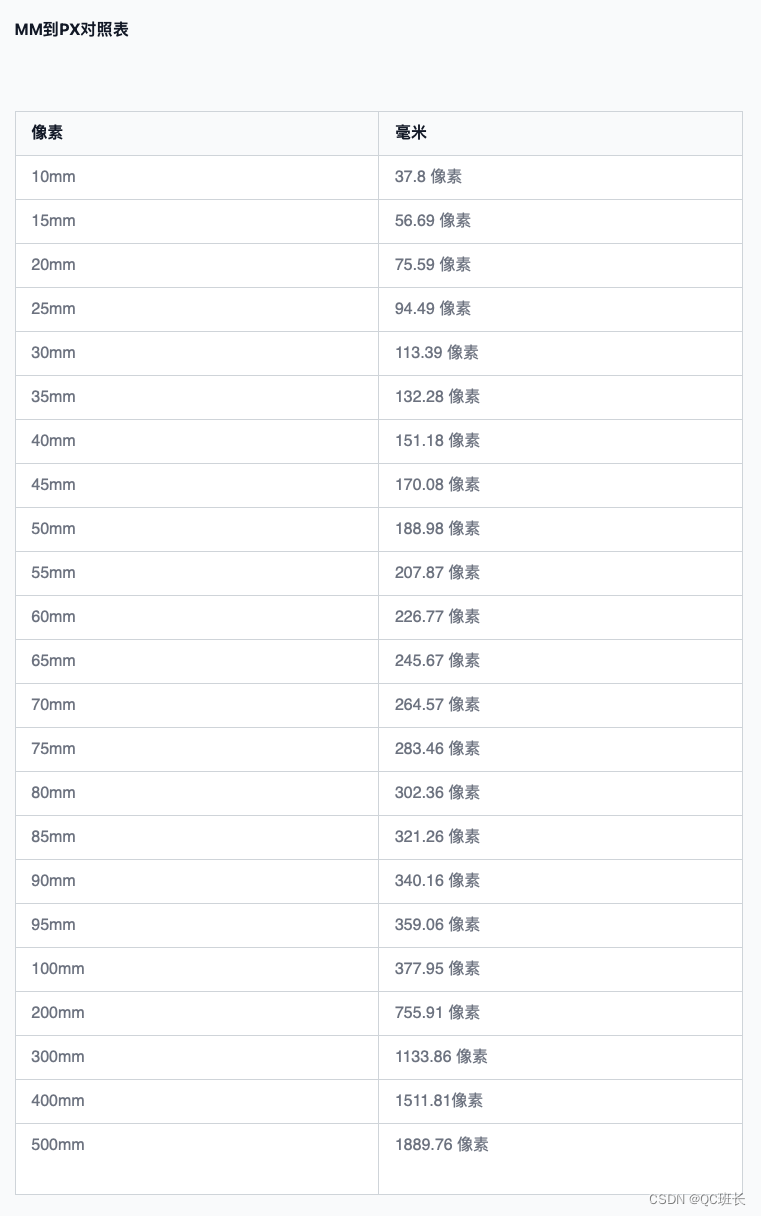
React动态生成二维码和毫米(mm)单位转像素(px)单位
一、使用qrcode.react生成二维码,qrcode.react - npm 很简单,安装依赖包,然后引用就行了 npm install qrcode.react或者 yarn add qrcode.react直接上写好的代码 import React, {useEffect, useState} from react; import QRCode from qr…...
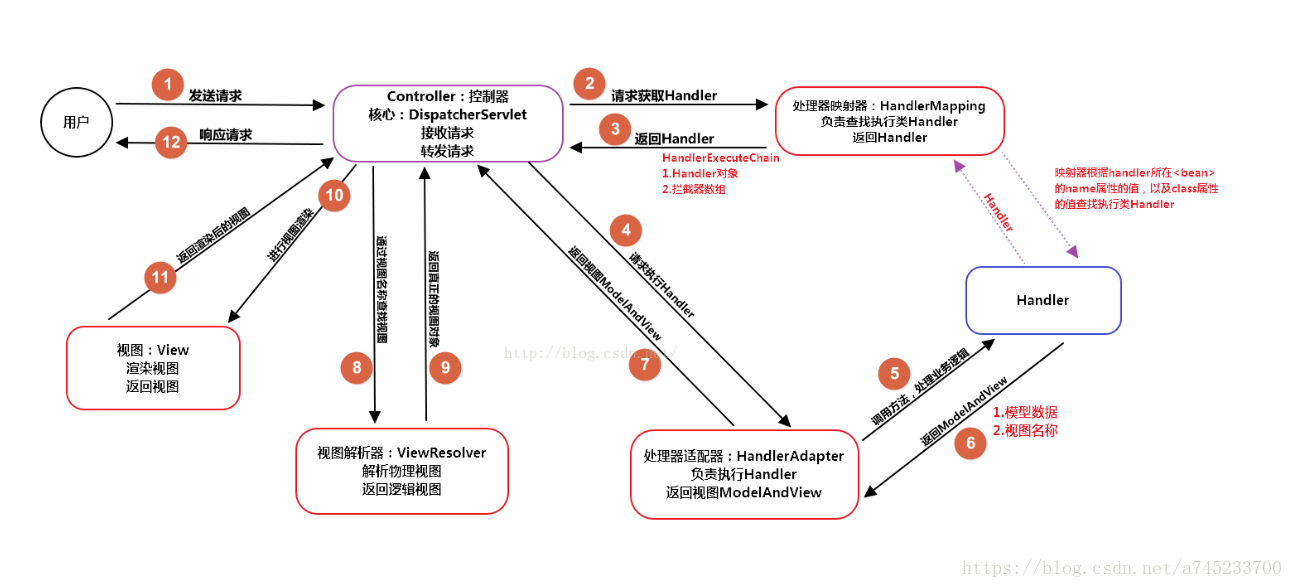
SpringMvc 常见面试题
1、SpringMvc概述 1.1、什么是Spring MVC ?简单介绍下你对springMVC的理解? Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦&am…...
jmeter接口自动化测试工具在企业开展实际的操作
在企业使用jmeter开展实际的接口自动化测试工具,建议按如下操作流程, 可以使整个接口测试过程更规范,更有效。 接口自动化的流程: 1、获取到接口文档:swagger、word、excel ... 2、熟悉接口文档然后设计测试用例&am…...
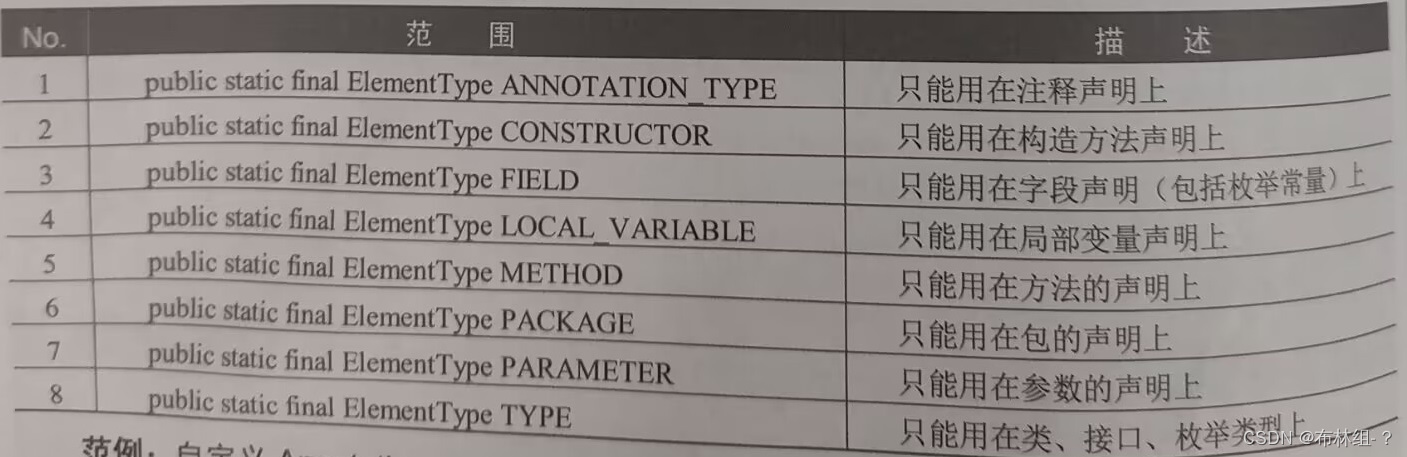
第17章 反射机制
通过本章需要理解反射机制操作的意义以及Class类的作用,掌握反射对象实例化操作,并且可以深刻理解反射机制与工厂模式结合意义。掌握类结构反射操作的实现,并且可以通过反射实现类中构造方法、普通方法、成员属性的操作。掌握反射机制与简单J…...
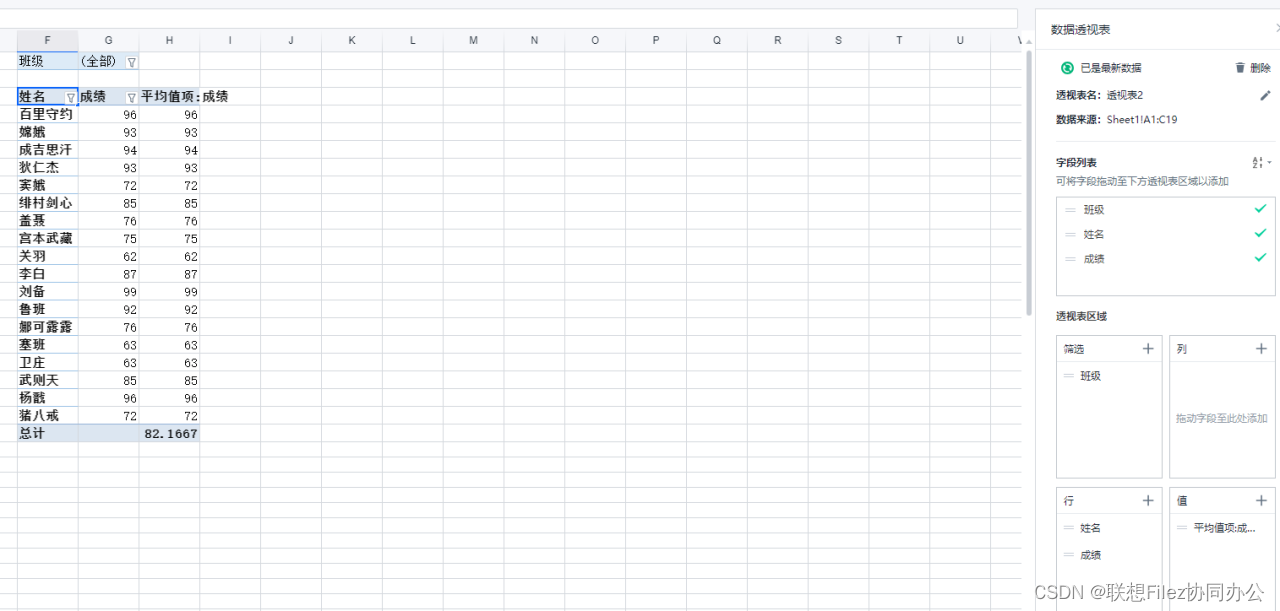
如何在在线Excel文档中对数据进行统计
本次我们将用zOffice表格的公式与数据透视表分析样例(三个班级的学生成绩)。zOffice表格内置了大量和Excel相同的统计公式,可以进行各种常见的统计分析,如平均值、标准差、相关性等。同时,zOffice也有数据透视表功能&a…...
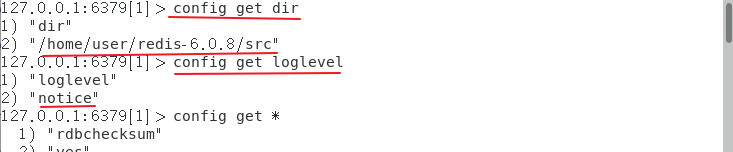
redis配置文件详解
一、配置文件位置 以配置文件启动 Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf ( Windows名为redis.windows. conf) 例: # 这里要改成你自己的安装目录 cd ./redis-6.0.8 vim redis.conf redis对配置文件对大小写不敏感 二、配置文件 1、获取当前服务的…...

前端设计模式之【工厂模式】
文章目录 前言什么时候不用介绍工厂模式的流程例子优点缺陷后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。…...
Python与ArcGIS系列(一)ArcGIS中使用Python
目录 0 简述1 arcgis中的python窗口2 开始编写代码 0 简述 按照惯例,作为本系列专栏的第一篇,先简单地介绍下本系列文章的内容:通过python语言创建arcgis环境脚本、将脚本以工具箱形式存放在arcgis中、通过脚本自动执行地理处理、数据修复、…...
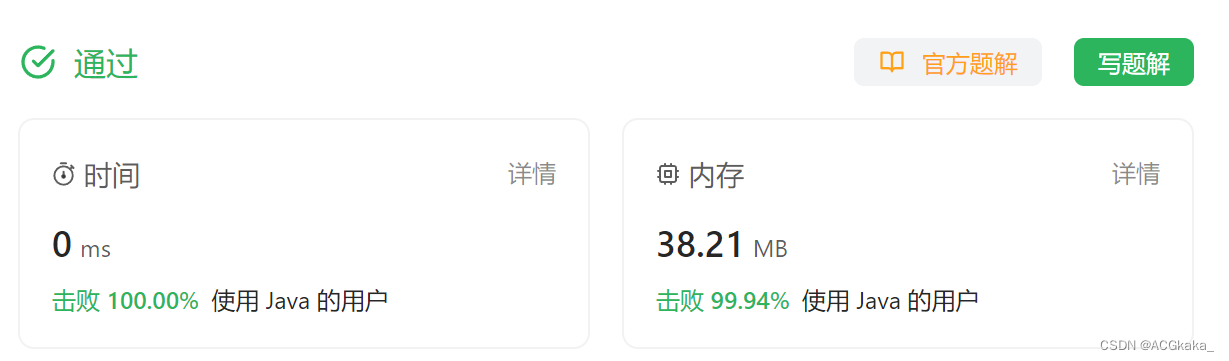
LeetCode(2)移除元素【数组/字符串】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 27. 移除元素 1.题目 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原…...
原型模式(创建型)
一、前言 原型模式是一种创建型设计模式,它允许在运行时通过克隆现有对象来创建新对象,而不是通过常规的构造函数创建。在原型模式中,一个原型对象可以克隆自身来创建新的对象,这个过程可以通过深度克隆或浅克隆来实现。简单说原型…...
之paste)
Linux命令(118)之paste
linux命令之paste 1.paste介绍 linux命令paste命令是把每个文件以列对列的方式,一列列地加以合并 2.paste用法 paste [参数] filename... paste参数 参数说明-d使用指定的分隔符进行合并-s以行来指定文件 3.实例 3.1.使用冒号(:)合并文件 命令: …...

使用零拷贝技术实现消息转发功能
零拷贝技术介绍:史上最全零拷贝总结-CSDN博客 这是一个简单的基于epoll的Linux TCP代理程序,通过匿名管道和零拷贝技术的splice函数,将两个TCP端口相互连接,并转发数据。 #define _GNU_SOURCE 1 #include <sys/socket.h> …...

【编程语言发展史】SQL的发展历史
目录 目录 SQL概述 SQL发展历史 SQL特点 SQL基本语句 SQL是结构化查询语言(Structure Query Language)的缩写,它是使用关系模型的数据库应用语言,由IBM在70年代开发出来,作为IBM关系数据库原型System R的原型关系语言,实现了…...

2023NOIP A层联测28-小猫吃火龙果
给你一个长为 n n n 的序列,每个位置是 A , B , C A,B,C A,B,C 三个中的一个物品。 A A A 吃 B B B, B B B 吃 C C C, C C C 吃 A A A。 现在有 m m m 次操作,每次操作有两种: 区间修改:给出 l , r…...

C# Dictionary与List的用法区别与联系
C#是一门广泛应用于软件开发的编程语言,其中Dictionary和List是两种常用的集合类型。它们在存储和操作数据时有着不同的特点和用途。本文将详细探讨C# Dictionary和List的用法区别与联系,并通过代码示例进行对比,以帮助读者更好地选择适合自己…...

Git应用(1)
一、Git Git(读音为/gɪt/。中文 饭桶 )是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。 了解更多可到GIT官网:Git - Downloads GIT一般工作流程如下: 1.从远程仓库中克隆 Git 资源作为本地…...

【Java】Netty创建网络服务端客户端(TCP/UDP)
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍Netty创建网络服务端客户端示例。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下次更…...

Android 设计模式--单例模式
一,定义 单例模式就是确保某一个类只有一个实例,而且自行实例化,并向整个系统提供这个实例 二,使用场景 确保某个类只有一个对象的使用场景,避免产生多个对象消耗过多的资源,或者某种类型的对象只应该有…...

语音识别与自然语言处理(NLP):技术前沿与未来趋势
语音识别与自然语言处理(NLP):技术前沿与未来趋势 随着科技的快速发展,语音识别与自然语言处理(NLP)技术逐渐成为人工智能领域的研究热点。这两项技术的结合,使得机器能够更好地理解和处理人类语…...

S/4 HANA Coding Block字段增强实战:从OXK3配置到CDS View生成的完整避坑指南
1. 为什么需要增强Coding Block字段? 在S/4 HANA项目实施过程中,财务模块的定制化需求几乎不可避免。我遇到过不少客户都提出过这样的需求:"能不能在会计凭证录入界面增加我们公司特有的字段?"比如有些制造业客户需要记…...

深入解析PX4开源飞控:从架构设计到固定翼实战开发的完整指南
深入解析PX4开源飞控:从架构设计到固定翼实战开发的完整指南 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4开源飞控系统作为全球领先的无人机自主飞行解决方案,为开发者…...
忻)
记录复现多模态大模型论文OPERA的一周工作()忻
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

Zotero Citation插件完整指南:三步搞定Word文献引用自动化
Zotero Citation插件完整指南:三步搞定Word文献引用自动化 【免费下载链接】zotero-citation Make Zoteros citation in Word easier and clearer. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-citation Zotero Citation插件是学术写作领域的革命性…...

解锁QQ音乐加密音频:qmc-decoder全面解决方案指南
解锁QQ音乐加密音频:qmc-decoder全面解决方案指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的加密音频文件无法在其他播放器或设备上播放…...

Kandinsky-5.0-I2V-Lite-5s开发入门:Anaconda虚拟环境配置与管理
Kandinsky-5.0-I2V-Lite-5s开发入门:Anaconda虚拟环境配置与管理 1. 为什么需要虚拟环境 在开始Kandinsky-5.0-I2V-Lite-5s这类AI项目开发前,有个问题经常困扰新手:为什么我的代码在别人电脑上能跑,在自己电脑上就报错ÿ…...

LaTeX公式转换Word终极指南:告别复制粘贴困扰的智能解决方案
LaTeX公式转换Word终极指南:告别复制粘贴困扰的智能解决方案 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为LaTeX公式迁移到W…...

13.56MHz NFC天线匹配实战:用Smith V2.00搞定线圈阻抗,手把手调出50欧姆
13.56MHz NFC天线匹配实战:用Smith V2.00搞定线圈阻抗,手把手调出50欧姆 第一次接触13.56MHz天线匹配的工程师,往往会被Smith圆图上那些复杂的曲线和公式吓退。但当你真正用Smith V2.00软件完成一次完整的匹配设计后,会发现这个过…...

福禄克DSX-602认证分析仪科普小知识
福禄克(FLUKE)DSX-602 是一款专业级的铜缆认证分析仪,专为 **Cat 6A(超六类)** 及以下网线的工程验收、性能认证和故障诊断设计。一、核心定位与参数 测试范围:Cat 3/Class C ~ Cat 6A/Class EA 双绞线铜缆…...
ClearerVoice-Studio企业级方案:基于SpringBoot的智能客服语音优化系统
ClearerVoice-Studio企业级方案:基于SpringBoot的智能客服语音优化系统 1. 引言 想象一下这样的场景:客服中心每天处理成千上万的客户来电,但通话质量却参差不齐。有的客户在嘈杂的街头打电话,背景是车水马龙的噪音;…...