数据分析实战 | 贝叶斯分类算法——病例自动诊断分析
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
八、模型评价
九、模型调参
十、模型预测
一、数据及分析对象
CSV文件——“bc_data.csv”
数据集链接:https://download.csdn.net/download/m0_70452407/88524905
该数据集主要记录了569个病例的32个属性,主要属性/字段如下:
(1)ID:病例的ID。
(2)Diagnosis(诊断结果):M为恶性,B为良性。该数据集共包含357个良性病例和212个恶性病例。
(3)细胞核的10个特征值,包括radius(半径)、texture(纹理)、perimeter(周长)、面积(area)、平滑度(smoothness)、紧凑度(compactness)、凹面(concavity)、凹点(concave points)、对称性(symmetry)和分形维数(fractal dimension)等。同时,为上述10个特征值分别提供了3种统计量,分别为均值(mean)、标准差(standard error)和最大值(worst or largest)。
二、目的及分析任务
理解机器学习方法在数据分析中的应用——采用朴素贝叶斯算法进行分类分析。
(1)以一定比例将数据集划分为训练集和测试集。
(2)利用训练集进行朴素贝叶斯算法的建模。
(3)使用朴素贝叶斯分类模型在测试集上对诊断结果进行预测。
(4)将朴素贝叶斯分类模型对诊断结果的分类预测与真实的诊断结果进行对比分析,验证朴素贝叶斯分类模型的有效性。
三、方法及工具
Python语言及scikit-learn包。
四、数据读入
import pandas as pd
df=pd.read_csv("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第4章 分类分析\\bc_data.csv",header=0)
df.head()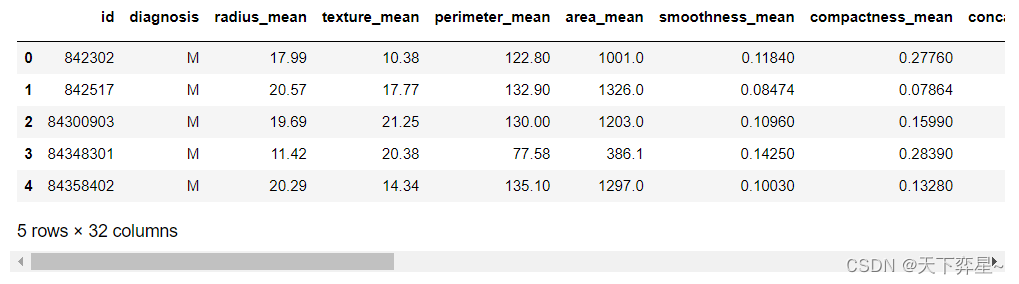
五、数据理解
查看数据集中是否存在缺失值,可以使用pandas包的isnull()方法判断数据是否存在空值,并结合any()方法查看每个特征中是否存在缺失值。
df.isnull().any()id False diagnosis False radius_mean False texture_mean False perimeter_mean False area_mean False smoothness_mean False compactness_mean False concavity_mean False concave points_mean False symmetry_mean False fractal_dimension_mean False radius_se False texture_se False perimeter_se False area_se False smoothness_se False compactness_se False concavity_se False concave points_se False symmetry_se False fractal_dimension_se False radius_worst False texture_worst False perimeter_worst False area_worst False smoothness_worst False compactness_worst False concavity_worst False concave_points_worst False symmetry_worst False fractal_dimension_worst False dtype: bool
从输出结果可以看出,数据集中不存在缺失值。
对数据框df进行探索性分析,这里采用的实现方式为调用pandas包中数据框的describe()方法。
df.describe()
除了describe()方法,还可以调用shape属性对数据框进行探索性分析。
df.shape(569, 32)
六、数据准备
本项目的分类任务属于二分类任务,需要将数据框df中诊断结果“diagnosis”的值转换为0和1的数值类型,这里使用scikit-learn包中preprocessing模块的LabelEncoder()方法。
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
df['diagnosis']=encoder.fit_transform(df['diagnosis'])
df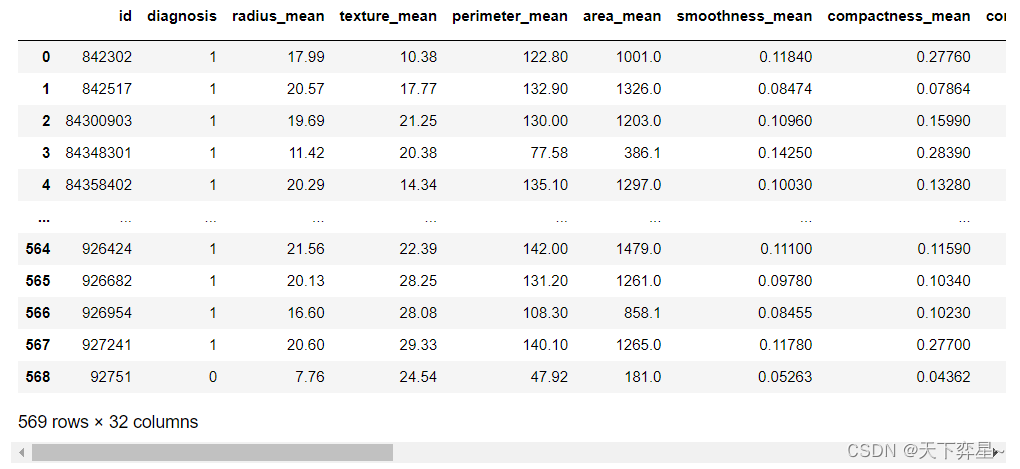
可以看出原先诊断结果diagnosis从M(表示恶性)和B(表示良性)转换成1(表示恶性)和0(表示良性)。
将数据集以7:3的比例分为训练集和测试集,这里首先将细胞核的特征集(即数据框df中除了前两列的数据集)赋值到变量x中,并将诊断结果赋值到变量y中以便后续使用。接着使用scikit-learn包中model_selection模块的train_test_split()方法进行数据集的划分。
from sklearn.model_selection import train_test_split
x=df.iloc[:,2:]
y=df['diagnosis']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=40,stratify=y)七、模型训练
scikit-learn包中naive_bayes模块里根据特征类型和分布提供了多个不同的模型,如GaussianNB、BernoulliNB以及MultinomialNB。其中:
(1)GaussianNB假设数据符合正态分布,是用于连续值较多的特征。
(2)BernoulliNB是用于二元离散值得特征。
(3)MultinomialNB是用于多元离散的特征。
这里的数据集的特征均为连续变量,因此使用GaussianNB进行模型的训练。
from sklearn.naive_bayes import GaussianNB
gnb_clf=GaussianNB()
gnb_clf.fit(x_train,y_train)GaussianNB()
八、模型评价
这里使用准确率、精确率、召回率和f1值对模型进行评价,scikit-learn中的metrics模块提供了accuracy_score()、precision_score(),recall_score(),f1_score()方法。
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
gnb_ypred=gnb_clf.predict(x_test)
print("准确率:%f,\n精确率:%f,\n召回率:%f,\nf1值:%f."%(accuracy_score(y_test,gnb_ypred),precision_score(y_test,gnb_ypred),recall_score(y_test,gnb_ypred),f1_score(y_test,gnb_ypred)))准确率:0.935673, 精确率:0.964912, 召回率:0.859375, f1值:0.909091.
九、模型调参
GaussianNB可输入两个参数prior和var_smoothing。prior用于定义样本类别的先验概率,默认情况下会根据数据集计算先验概率,因此一般不对prior进行设置。var_smoothing的默认值为1e-9,通过设置特征的最大方差,进而以给定的比例添加到估计的方差中,主要用于控制模型的稳定性。
这里调用scikit-learn包model_selection模块中的网络搜索功能,即GridSearchCV()方法对模型进行调参。先定义一个变量params来存储alpha的不同取值(这里假设var_smoothing的取值范围为[1e-7,1e-8,1e-9,1e-10.1e-11,1e-12])。
from sklearn.model_selection import GridSearchCV
params={'var_smoothing':[1e-7,1e-8,1e-9,1e-10,1e-11,1e-12]}
gnb_grid_clf=GridSearchCV(GaussianNB(),params,cv=5,verbose=2)
gnb_grid_clf.fit(x_train,y_train)Fitting 5 folds for each of 6 candidates, totalling 30 fits [CV] END ................................var_smoothing=1e-07; total time= 0.0s [CV] END ................................var_smoothing=1e-07; total time= 0.0s [CV] END ................................var_smoothing=1e-07; total time= 0.0s [CV] END ................................var_smoothing=1e-07; total time= 0.0s [CV] END ................................var_smoothing=1e-07; total time= 0.0s [CV] END ................................var_smoothing=1e-08; total time= 0.0s [CV] END ................................var_smoothing=1e-08; total time= 0.0s [CV] END ................................var_smoothing=1e-08; total time= 0.0s [CV] END ................................var_smoothing=1e-08; total time= 0.0s [CV] END ................................var_smoothing=1e-08; total time= 0.0s [CV] END ................................var_smoothing=1e-09; total time= 0.0s [CV] END ................................var_smoothing=1e-09; total time= 0.0s [CV] END ................................var_smoothing=1e-09; total time= 0.0s [CV] END ................................var_smoothing=1e-09; total time= 0.0s [CV] END ................................var_smoothing=1e-09; total time= 0.0s [CV] END ................................var_smoothing=1e-10; total time= 0.0s [CV] END ................................var_smoothing=1e-10; total time= 0.0s [CV] END ................................var_smoothing=1e-10; total time= 0.0s [CV] END ................................var_smoothing=1e-10; total time= 0.0s [CV] END ................................var_smoothing=1e-10; total time= 0.0s [CV] END ................................var_smoothing=1e-11; total time= 0.0s [CV] END ................................var_smoothing=1e-11; total time= 0.0s [CV] END ................................var_smoothing=1e-11; total time= 0.0s [CV] END ................................var_smoothing=1e-11; total time= 0.0s [CV] END ................................var_smoothing=1e-11; total time= 0.0s [CV] END ................................var_smoothing=1e-12; total time= 0.0s [CV] END ................................var_smoothing=1e-12; total time= 0.0s [CV] END ................................var_smoothing=1e-12; total time= 0.0s [CV] END ................................var_smoothing=1e-12; total time= 0.0s [CV] END ................................var_smoothing=1e-12; total time= 0.0s GridSearchCV(cv=5, estimator=GaussianNB(),param_grid={'var_smoothing': [1e-07, 1e-08, 1e-09, 1e-10, 1e-11,1e-12]},verbose=2)
这里在GridSearchCV()方法中传入了GaussianNB模型、需优化的参数取值变量params、交叉验证的参数cv(这里设置了五折交叉验证)以及显示训练日志参数verbose(verbose取值为0时不显示训练过程,取值为1时偶尔输出训练过程,取值>1时对每个子模型都输出训练过程。
接着使用GridSearchCV中的best_params_查看准确率最高的模型参数。
gnb_grid_clf.best_params_{'var_smoothing': 1e-10}
由此可知,在给定的var_smoothing取值范围内,当取值为1e-10时模型的准确率最高。
十、模型预测
模型的预测可通过训练好的模型的predict()方法使用,这里使用默认的情况下和调参后 的两个GaussianNB模型对测试集进行分类预测,并使用模型评价方法进行比较。
首先使用默认情况下的GaussianNB对测试集进行分类预测,然后将分类结果存储到变量gnb_ypred中,并输出模型的准确率、精确率、召回率以及f1值。
gnb_ypred=gnb_clf.predict(x_test)
print("准确率:%f,\n精确率:%f,\n召回率:%f,\nf1值:%f."%(accuracy_score(y_test,gnb_ypred),precision_score(y_test,gnb_ypred),recall_score(y_test,gnb_ypred),f1_score(y_test,gnb_ypred)))准确率:0.935673, 精确率:0.964912, 召回率:0.859375, f1值:0.909091.
接着,使用调参后的GaussianNB对测试集进行分类预测,然后将分类结果存储到tuned_ypred中,并输出模型的准确率、精确率、召回率以及f1值。
tuned_ypred=gnb_grid_clf.best_estimator_.predict(x_test)
print("准确率:%f,\n精确率:%f,\n召回率:%f,\nf1值:%f."%(accuracy_score(y_test,tuned_ypred),precision_score(y_test,tuned_ypred),recall_score(y_test,tuned_ypred),f1_score(y_test,tuned_ypred)))准确率:0.941520, 精确率:0.965517, 召回率:0.875000, f1值:0.918033.
tuned=GaussianNB(var_smoothing=1e-10)
tuned.fit(x_train,y_train)
tuned_ypred1=tuned.predict(x_test)
print("准确率:%f,\n精确率:%f,\n召回率:%f,\nf1值:%f."%(accuracy_score(y_test,tuned_ypred1),precision_score(y_test,tuned_ypred1),recall_score(y_test,tuned_ypred1),f1_score(y_test,tuned_ypred1)))tuned=GaussianNB(var_smoothing=1e-10) tuned.fit(x_train,y_train) tuned_ypred1=tuned.predict(x_test) print("准确率:%f,\n精确率:%f,\n召回率:%f,\nf1值:%f."%(accuracy_score(y_test,tuned_ypred1),precision_score(y_test,tuned_ypred1),recall_score(y_test,tuned_ypred1),f1_score(y_test,tuned_ypred1)))
可见,通过调参GaussianNB,在4个评价指标上均得到一定的提高。
相关文章:
数据分析实战 | 贝叶斯分类算法——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/d…...
实用技巧:嵌入式人员使用http服务模拟工具模拟http服务器测试客户端get和post请求
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/134305752 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬结…...

P9836 种树
容易想到分解因数。 对于一个数 p p p 的因数个数,假设它可以被分解质因数成 a 1 i 1 a 2 i 2 a 3 i 3 ⋯ a k c k a_1^{i_1} a_2^{i_2} a_3^{i_3}\cdots a_k^{c_k} a1i1a2i2a3i3⋯akck 的形式,则其因数个数为 ( i 1 1 ) ( i 2 1 )…...
C# 查询腾讯云直播流是否存在的API实现
应用场景 在云考试中,为防止作弊行为的发生,会在考生端部署音视频监控系统,当然还有考官方监控墙系统。在实际应用中,考生一方至少包括两路直播流: (1)前置摄像头:答题的设备要求使…...
JAVA开源项目 于道前端项目 启动步骤参考
1. 安装 启动过程有9个步骤: 1.1 安装 Node JS , V18版本的 (安装步骤省略) 1.2 安装 npm install -g yarn ,node JS里边好像自带npm ,通过npm的命令安装 yarn 1.3 切换到项目中去安装,npm install &a…...
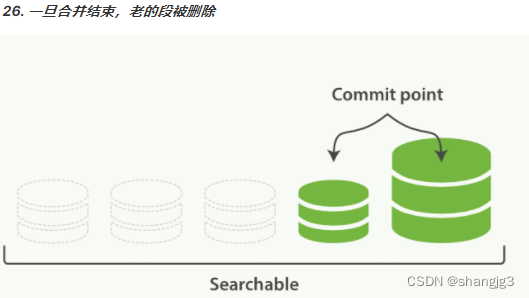
深入理解ElasticSearch分片
1. 路由计算 当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的&…...
【Python】AppUI自动化—appium自动化元素定位、元素事件操作(17)下
文章目录 前言一.Appium 元素定位1.定位方式种类2.如何定位2.1 id定位2.2 className定位2.3 content-desc 定位2.4 Android Uiautomator定位4.1 text定位4.2 text模糊定位4.3 text正则匹配定位4.4 resourceId定位4.5 resourceId正则匹配定位4.6 className定位4.7 className正则…...

SpringBoot使用MyBatis多数据源
SpringBoot使用MyBatis多数据源 我们以 Mybatis Xml和注解两种版本为例,给大家展示如何如何配置多数据源。 1、注解方式 数据库文件: DROP TABLE IF EXISTS users; CREATE TABLE users (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 主键id,userN…...
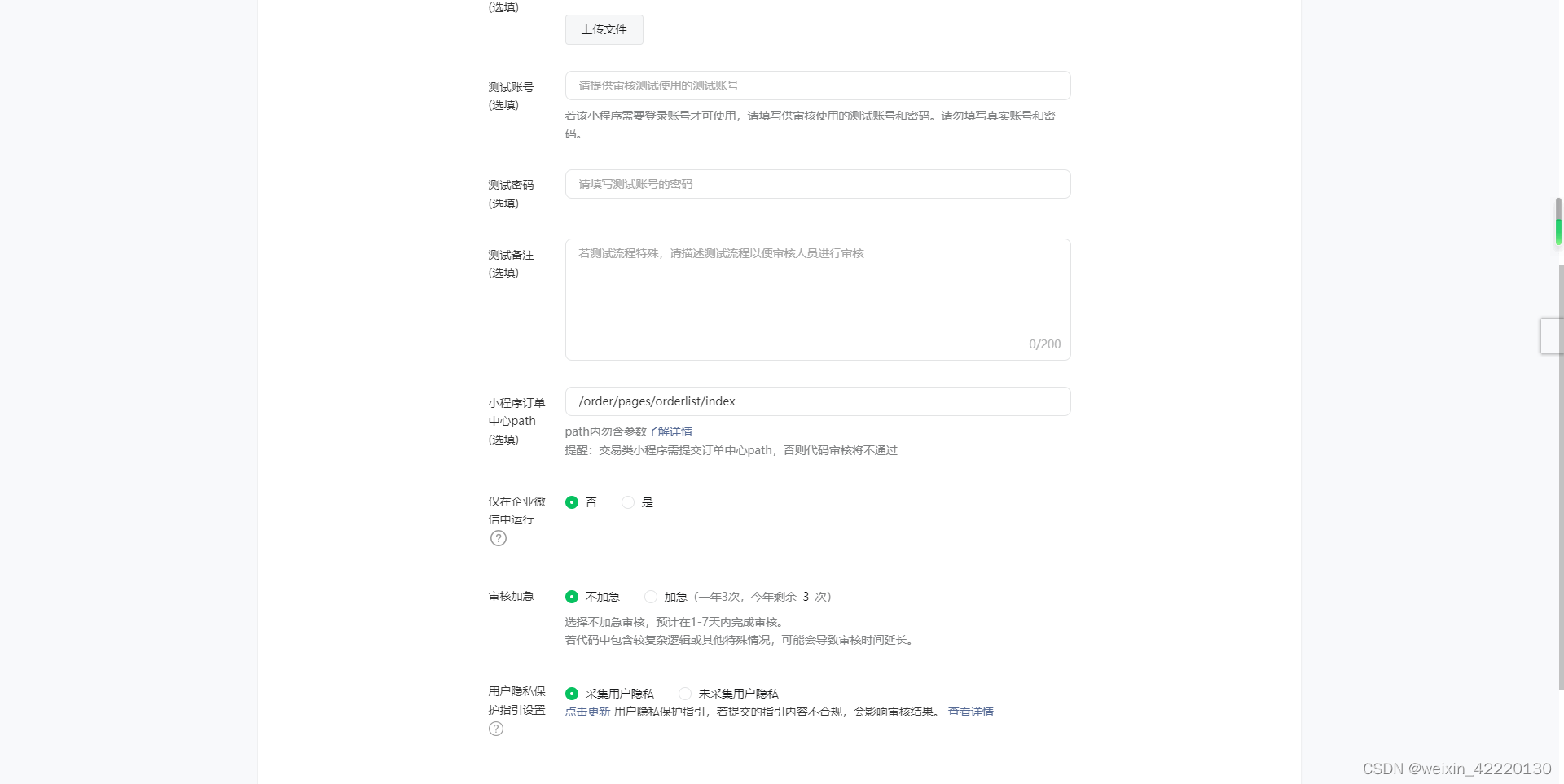
小程序版本审核未通过,需在开发者后台「版本管理—提交审核——小程序订单中心path」设置订单中心页path,请设置后再提交代码审核
小程序版本审核未通过,需在开发者后台「版本管理—提交审核——小程序订单中心path」设置订单中心页path,请设置后再提交代码审核 因小程序尚未发布,订单中心不能正常打开查看,请先发布小程序后再提交订单中心PATH申请 初次提交…...
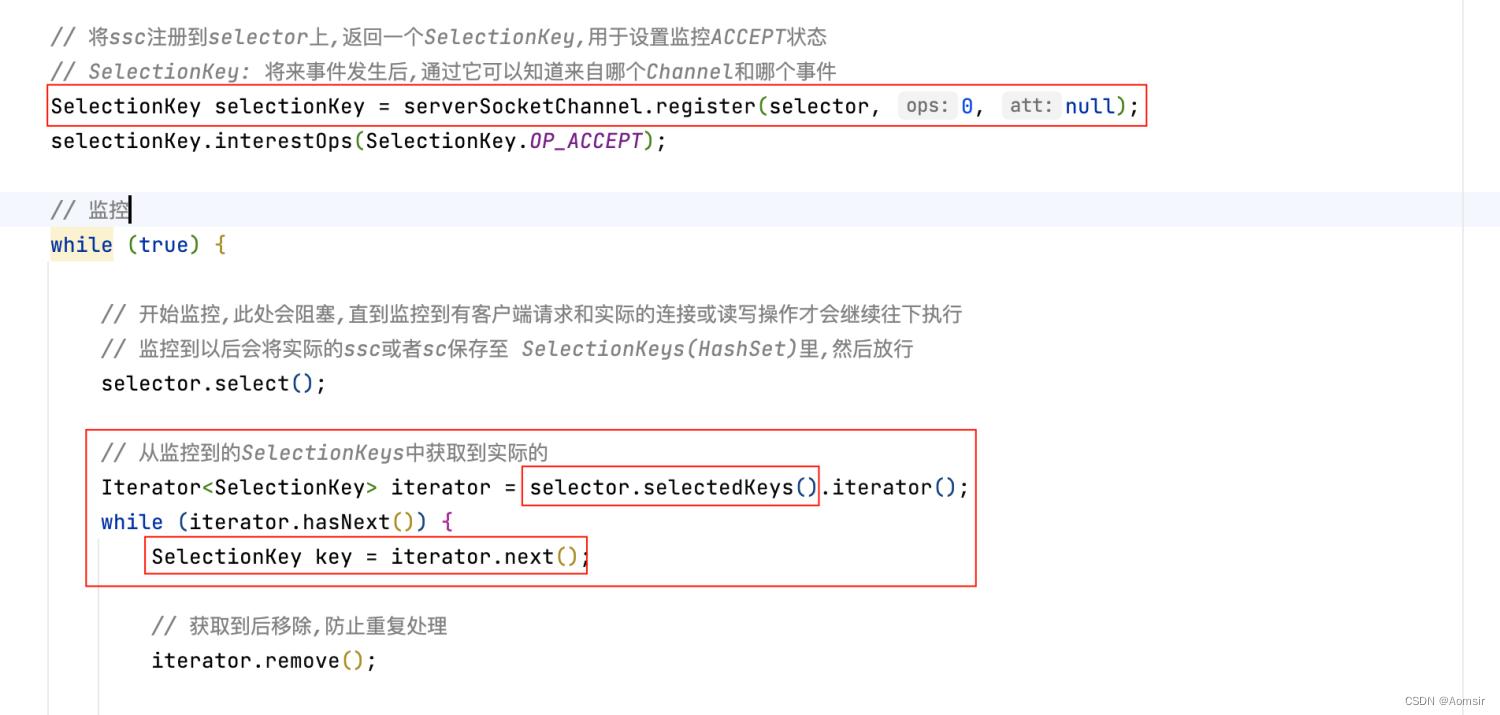
Netty入门指南之NIO Selector监管
作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者! 个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客 当前专栏:Netty应用专栏_Aomsir的博客-CSDN博客 文章目录 参考文献前言问题解…...

Spring Cloud学习(六)【统一网关 Gateway】
文章目录 网关的功能搭建网关服务路由断言工厂Route Predicate Factory路由过滤器 GatewayFilter过滤器执行顺序跨域问题处理 网关的功能 网关功能: 身份认证和权限校验服务路由、负载均衡请求限流 在SpringCloud中网关的实现包括两种: gatewayzuul …...

基于单片机的空调智能控制器的设计
**单片机设计介绍,基于单片机的空调智能控制器的设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机的空调智能控制器需要具备输入输出端口、定时器、计数器等模块,以便对空调进行精确控制。下…...
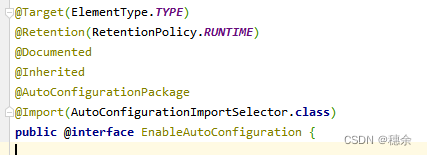
Spring Boot自动配置原理、实战、手撕自动装配源码
Spring Boot自动配置原理 相比较于传统的 Spring 应用,搭建一个 SpringBoot 应用,我们只需要引入一个注解 SpringBootApplication,就可以成功运行。 前面四个不用说,是定义一个注解所必须的,关键就在于后面三个注解&a…...

111111111111111
全局锁 就是对整个数据库进行加锁,加锁之后整个数据库就处于只读状态,后续的DML写语句,DDL语句,以及对更新事务的提交操作都会被阻塞,典型地使用场景就是做整个数据库的逻辑备份,对所有的表进行锁定&#x…...
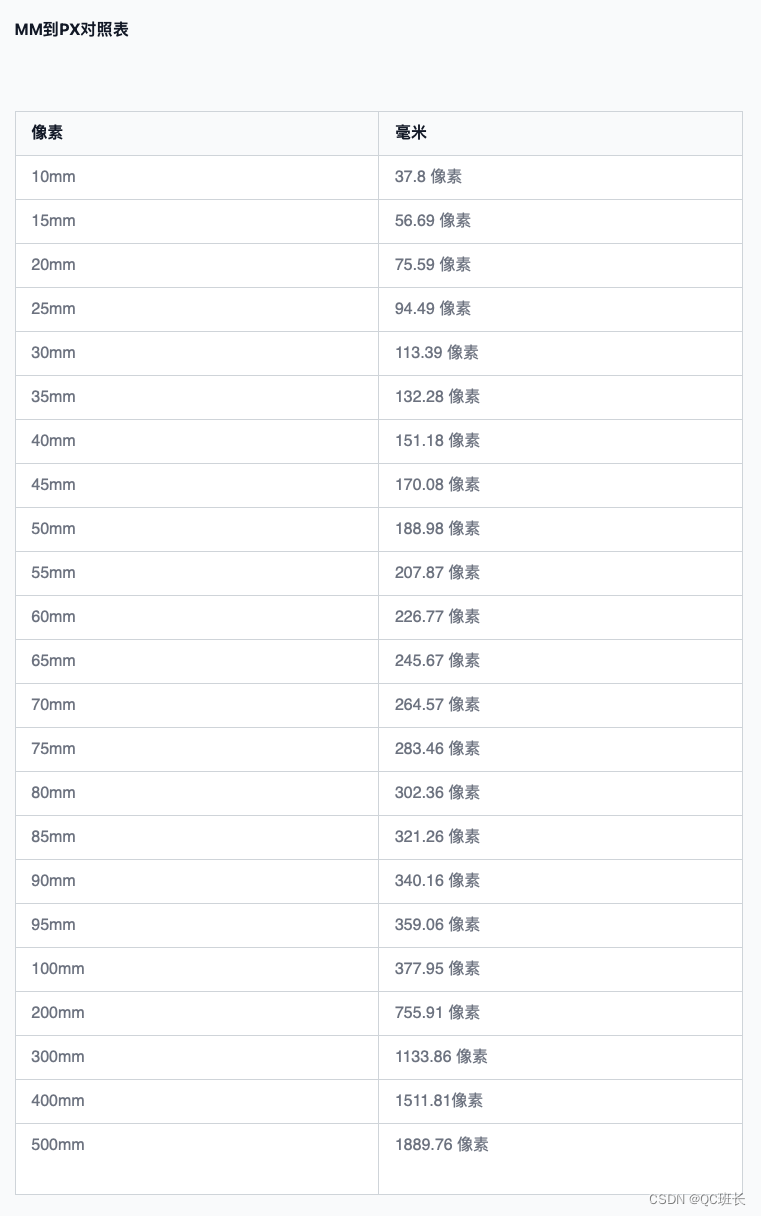
React动态生成二维码和毫米(mm)单位转像素(px)单位
一、使用qrcode.react生成二维码,qrcode.react - npm 很简单,安装依赖包,然后引用就行了 npm install qrcode.react或者 yarn add qrcode.react直接上写好的代码 import React, {useEffect, useState} from react; import QRCode from qr…...
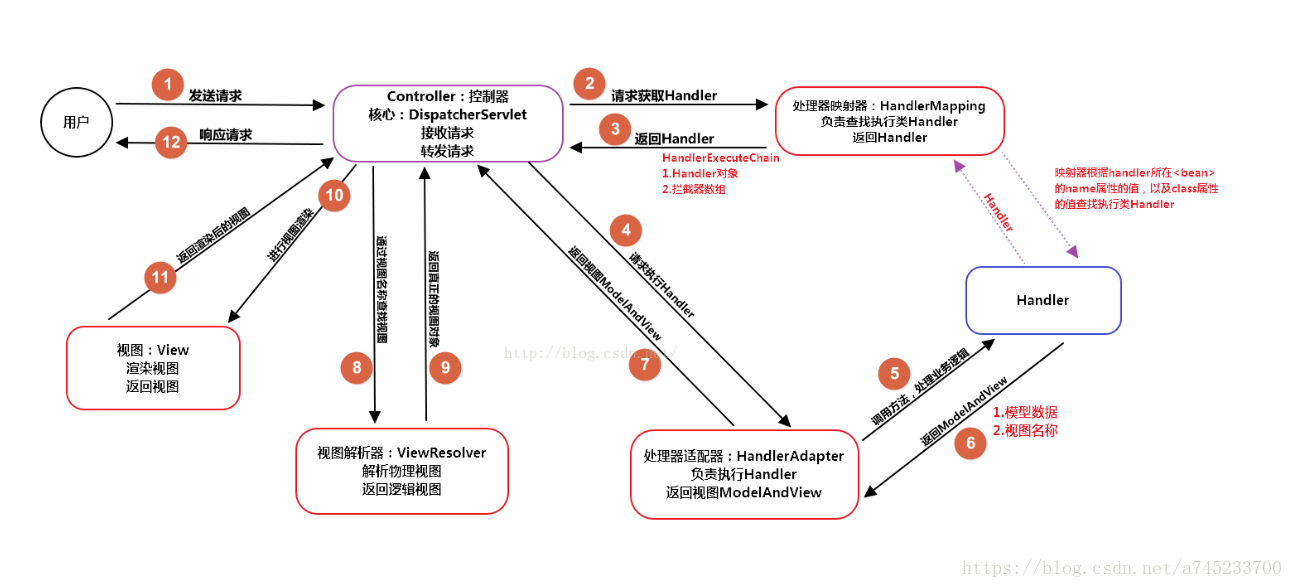
SpringMvc 常见面试题
1、SpringMvc概述 1.1、什么是Spring MVC ?简单介绍下你对springMVC的理解? Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦&am…...
jmeter接口自动化测试工具在企业开展实际的操作
在企业使用jmeter开展实际的接口自动化测试工具,建议按如下操作流程, 可以使整个接口测试过程更规范,更有效。 接口自动化的流程: 1、获取到接口文档:swagger、word、excel ... 2、熟悉接口文档然后设计测试用例&am…...
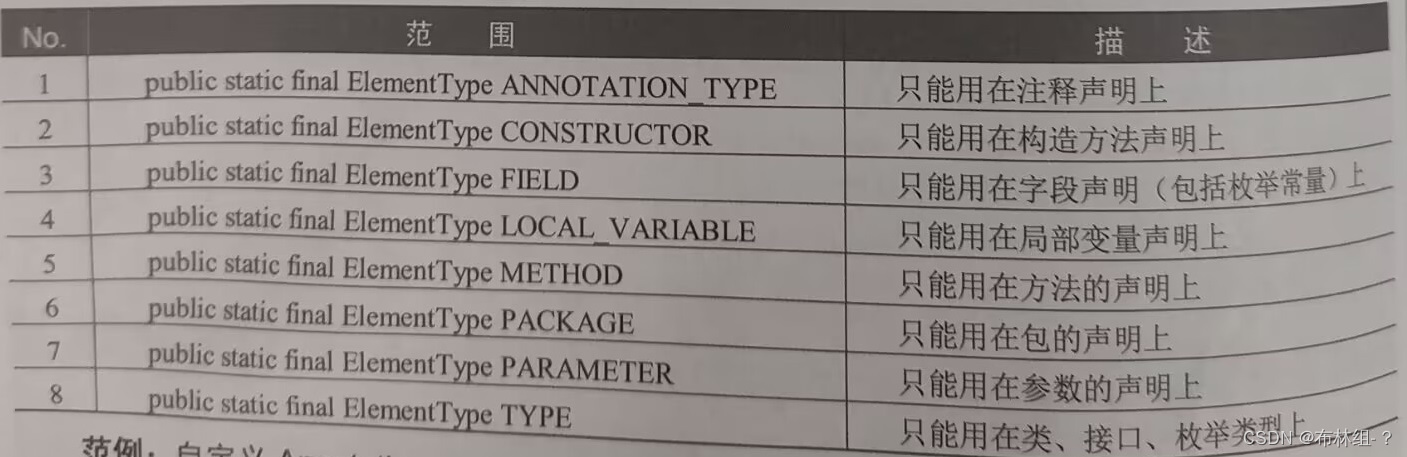
第17章 反射机制
通过本章需要理解反射机制操作的意义以及Class类的作用,掌握反射对象实例化操作,并且可以深刻理解反射机制与工厂模式结合意义。掌握类结构反射操作的实现,并且可以通过反射实现类中构造方法、普通方法、成员属性的操作。掌握反射机制与简单J…...
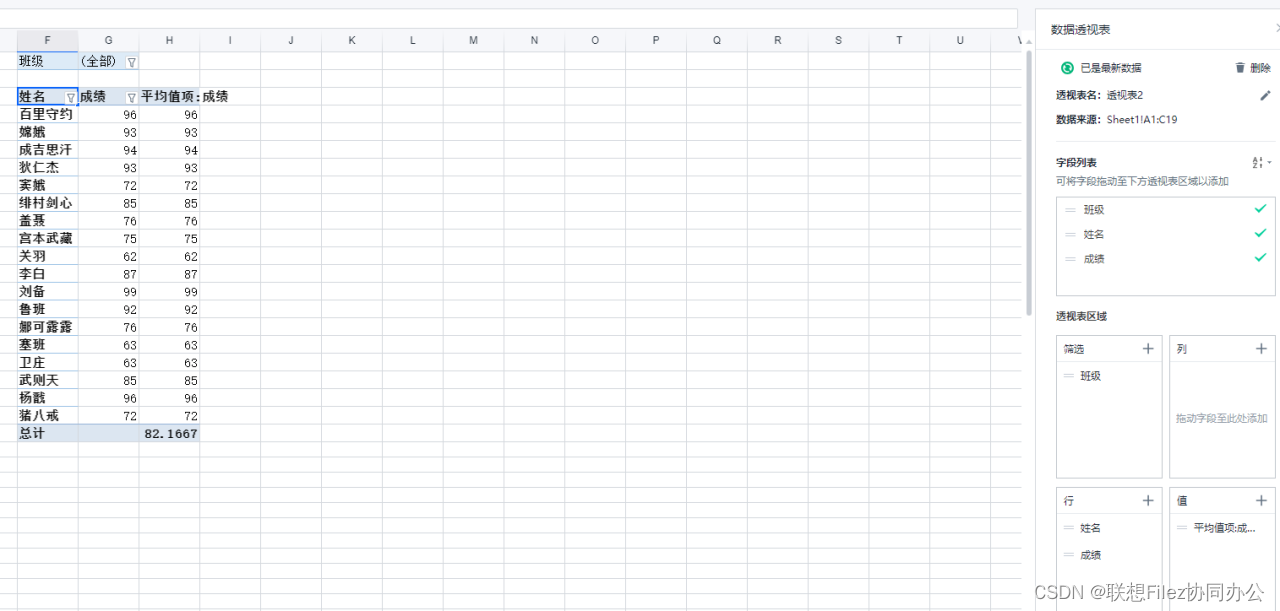
如何在在线Excel文档中对数据进行统计
本次我们将用zOffice表格的公式与数据透视表分析样例(三个班级的学生成绩)。zOffice表格内置了大量和Excel相同的统计公式,可以进行各种常见的统计分析,如平均值、标准差、相关性等。同时,zOffice也有数据透视表功能&a…...
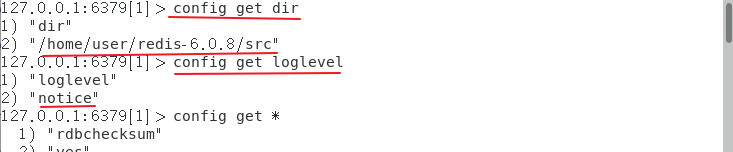
redis配置文件详解
一、配置文件位置 以配置文件启动 Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf ( Windows名为redis.windows. conf) 例: # 这里要改成你自己的安装目录 cd ./redis-6.0.8 vim redis.conf redis对配置文件对大小写不敏感 二、配置文件 1、获取当前服务的…...

5分钟彻底告别AutoCAD字体烦恼:免费智能插件FontCenter完整使用指南
5分钟彻底告别AutoCAD字体烦恼:免费智能插件FontCenter完整使用指南 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 还在为AutoCAD图纸中的字体缺失而头疼吗?每次打开同事发来的D…...

Stable Yogi Leather-Dress-Collection 多风格对比评测:写实、插画与概念艺术
Stable Yogi Leather-Dress-Collection 多风格对比评测:写实、插画与概念艺术 最近在尝试用AI生成一些时尚设计图,特别是皮革连衣裙这种对质感和风格要求都比较高的品类。我试用了好几个模型,发现Stable Yogi在处理这类主题时,风…...

Pogocache高级调优:如何通过配置参数优化性能和内存使用
Pogocache高级调优:如何通过配置参数优化性能和内存使用 【免费下载链接】pogocache Fast caching software with a focus on low latency and cpu efficiency. 项目地址: https://gitcode.com/gh_mirrors/po/pogocache Pogocache是一款专注于低延迟和CPU效率…...

Qwen3-VL-8B Web界面交互效果集:消息流加载动画与断线重连体验
Qwen3-VL-8B Web界面交互效果集:消息流加载动画与断线重连体验 1. 项目概述 Qwen3-VL-8B AI聊天系统是一个完整的Web端智能对话解决方案,基于通义千问大语言模型构建。系统采用现代化的前后端分离架构,为用户提供流畅、稳定的聊天体验。 这…...

人工智能Ai图像识别之纸箱破损图像识别 纸箱缺陷识别 纸箱潮湿识别 纸箱状态识别图像数据集 第10336期
纸箱缺陷图像识别数据集类别 Classes (4) 类别(4) carton box 纸箱 cracked carton box 破损的纸箱 opened carton box 打开的纸箱 wet carton box 湿纸箱数据集核心信息表信息类别具体内容数据集类别包含 4 类纸箱目标:carton box࿰…...

Java的java.lang.foreign访问模式
Java的java.lang.foreign访问模式是JDK 14引入的一项实验性功能,旨在提供一种更安全、高效的方式与本地代码和内存进行交互。传统JNI虽然强大,但存在性能开销大、易出错等问题。而java.lang.foreign通过MemorySegment、MemoryAddress等API,让…...

卡证检测矫正模型开箱即用体验:十分钟快速验证效果
卡证检测矫正模型开箱即用体验:十分钟快速验证效果 最近在做一个需要批量处理身份证、银行卡图片的项目,最头疼的就是用户上传的图片五花八门——有的歪了,有的反光,还有的带着手指头。手动一张张裁剪矫正,效率低不说…...

终极指南:如何免费使用CefFlashBrowser让经典Flash游戏重获新生
终极指南:如何免费使用CefFlashBrowser让经典Flash游戏重获新生 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 还在为无法重温童年Flash游戏而烦恼吗?当主流浏览器…...

PowerShell文件切割避坑指南:如何正确处理含中文的CSV大文件
PowerShell文件切割避坑指南:如何正确处理含中文的CSV大文件 在电商数据分析和用户行为研究的日常工作中,数据工程师经常需要处理动辄几十GB的CSV文件。这些文件往往包含大量中文内容,从商品名称到用户评论,编码问题成为数据处理的…...

Gartner Magic Quadrant for Data Center Switching 2025 | Gartner 数据中心交换魔力象限 2025
Gartner Magic Quadrant for Data Center Switching 2025 Gartner 魔力象限:数据中心网络交换机 2025 请访问原文链接:https://sysin.org/blog/gartner-magic-quadrant-data-center-switching-2025/ 查看最新版。原创作品,转载请保留出处。…...