5 Paimon数据湖之表数据查询详解
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
虽然前面我们已经讲过如何查询Paimon表中的数据了,但是有一些细节的东西还需要详细分析一下。
-
首先是针对Paimon中系统表的查询,例如
snapshots\schemas\options等等这些系统表。
其实简单理解就是我们可以通过sql的形式查询系统表来查看实体表的快照、schema等信息,这些信息我们也可以直接到hdfs中查看,只是不太方便。 -
在查询数据的时候,可以细分为批量读取和流式读取,因为Paimon可以同时支持批处理和流处理。
-
在查询数据的时候,如果想要从之前的某一个时间点开始查询数据,也就说任务启动的时候想要查询一些历史数据,则需要用到时间旅行这个特性,可以在SQL查询语句中通过动态表选项指定scan.mode参数来控制具体查询哪些历史数据。
Scan Mode的值可以有多种,不同的值代表不同的含义,下面我们来具体分析一下:

注意:在分析的时候,我们需要针对批处理和流处理这两种情况分别进行分析。
-
(1)default:如果我们在执行查询的时候,没有指定scan.mode参数,则默认是default。但是此时需要注意,如果我们也没有同时指定其他参数,例如:
timestamp-millis\snapshot-id等scan相关的参数,那么默认会执行latest-full策略。
所以说,我们在执行查询的时候,如果没有指定任何scan相关的参数,那么默认执行的策略就是latest-full。 -
(2)latest-full:和full是一样的效果,不过full这个参数已经被标记为过期了。针对批处理,表示只读取最新快照中的所有数据,读取完成以后任务就执行结束了。针对流处理,表示第一次启动时读取最新快照中的所有数据,然后继续读取后续新增的变更数据,这个任务会一直运行。
-
(3)latest:针对批处理,他的执行效果和latest-full是一样的,只会读取最新快照中的所有数据。但是针对流处理就不一样了,此时表示只读取最新的变更数据,也就是说任务启动之后,只读取新增的数据,之前的历史快照中的数据不读取。类似于kafka中消费者里面的latest消费策略。
-
(4)from-snapshot:使用此策略的时候,需要同时指定snapshot-id参数。针对批处理,表示只读取指定id的快照中的所有数据。针对流处理,表示从指定id的快照开始读取变更数据(注意:此时不是读取这个快照中的所有数据,而是读取此快照中的变更数据,也可以理解为这个快照和上一个快照相比新增的数据),当然,后续新增的变更数据也是可以读取到的,因为这个是流处理,他会一直执行读取操作。
-
(5)from-snapshot-full:使用此策略的时候,也需要同时指定snapshot-id参数。针对批处理,他的执行效果和from-snapshot是一样的。针对流处理,表示第一次启动时读取指定id的快照中的所有数据,然后继续读取后续新增的变更数据,此时任务会一直执行。
-
(6)from-timestamp:使用此策略的时候,需要同时指定timestamp-millis参数。针对批处理,表示只读取指定时间戳的快照中的所有数据。针对流处理,表示从指定时间戳的快照开始读取变更数据,(注意,这里也是读取这个快照中的变更数据,不是所有数据。),然后读取后续新增的变更数据。
-
(7)incremental:表示是增量查询,这个主要是针对批处理的,通过这种策略可以读取开始和结束快照之间的增量变化。开始和结束快照可以通过快照id或者是时间戳进行指定。
如果是使用快照id,则需要通过incremental-between参数指定。
如果是使用时间戳,则需要通过incremental-between-timestamp参数指定。 -
(8)compacted-full:想要使用这个参数有一个前提,Paimon表需要开启完全压缩(full compaction)。此时针对批处理,表示只读取最新完全压缩(full compaction)的快照中的所有数据。针对流处理,表示第一次启动时读取最新完全压缩(full compaction)的快照中的所有数据,然后继续读取后续新增的变更数据。
针对这里面的latest、latest-full、compacted-full这几种策略放在一起可能容易混淆,下面我们来通过一个图重新梳理一下:

首先看中间这条线,表示是数据的时间轴,左边是历史数据,右边是最新产生的数据。
中间这条线上面是批处理,下面是流处理。
我们首先来看批处理:
如果我们指定了scan.mode为latest-full或者是latest,则会读取最新的快照中的所有数据,也就是Last Snapshot中的数据。
如果我们指定了scan.mode为compacted-full,则会读取最新的完全压缩(full compaction)的快照中的数据,也就是Last Compact Snapshot中的数据。
接下来看一下流处理:
如果我们指定了scan.mode为latest-full,则会在任务第一次启动时读取最新快照中的所有数据,然后继续读取后续新增的变更数据。也就是第一次启动时先读取Last Snapshot中的所有数据,接着读取后续新产生的数据。
如果我们指定了scan.mode为latest,则此时只读取最新的变更数据,不读取LastSnapshot快照中的数据。
如果我们指定了scan.mode为compacted-full,则第一次启动时会读取最新完全压缩(full compaction)的快照中的所有数据,也就是Last Compact Snapshot中的数据,接着读取后续新产生的数据。
这就是这些策略在批处理和流处理中的执行流程。
(1)查询系统表
下面我们来通过具体的案例来演示一下前面提到的查询数据相关的用法。
首先创建一个向Paimon表中模拟写入数据的类,便于一会测试使用
创建package:tech.xuwei.paimon.query
创建object:FlinkSQLWriteToPaimon
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 通过FlinkSQL 向Paimon中模拟写入数据* Created by xuwei*/
object FlinkSQLWriteToPaimon {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//创建Paimon类型的表tEnv.executeSql("""|CREATE TABLE IF NOT EXISTS `query_table`(| name STRING,| age INT,| PRIMARY KEY (name) NOT ENFORCED|)|""".stripMargin)//写入数据tEnv.executeSql("INSERT INTO query_table(name,age) VALUES('jack',18)")tEnv.executeSql("INSERT INTO query_table(name,age) VALUES('tom',19)")tEnv.executeSql("INSERT INTO query_table(name,age) VALUES('mick',20)")}}
在idea中运行这个代码。
接下来创建一个类来查询一下Paimon中的系统表。
创建object:FlinkPaimonSystemTable
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 查询Paimon中的系统表* Created by xuwei*/
object FlinkPaimonSystemTable {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.BATCH)//使用批处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//snapshot信息表,对应的其实就是hdfs中表的snapshot目录下的snapshot-*文件信息println("====================snapshot信息表===========================")tEnv.executeSql("SELECT * FROM query_table$snapshots").print()//schema信息表,对应的其实就是hdfs中表的schema目录下的schema-*文件信息println("====================schema信息表===========================")tEnv.executeSql("SELECT * FROM query_table$schemas").print()//manifest信息表,对应的其实就是hdfs中表的manifest目录下的manifest-*文件信息println("====================manifest信息表===========================")tEnv.executeSql("SELECT * FROM query_table$manifests").print()//file信息表,对应的其实就是hdfs中表的bucket-*目录下的data-*文件信息println("====================file信息表===========================")tEnv.executeSql("SELECT * FROM query_table$files").print()//option信息表,对应的就是建表语句中with里面指定的参数信息,在表的schema-*文件中也能看到option信息println("====================option信息表===========================")tEnv.executeSql("SELECT * FROM query_table$options").print()//consumer信息表,在查询数据的sql语句中指定了consumer-id之后才能看到println("====================consumer信息表===========================")tEnv.executeSql("SELECT * FROM query_table$consumers").print()//audit log信息表,相当于是表的审核日志,可以看到表中每条数据的rowkind,也就是+I\-U\+U\-Dprintln("====================audit log信息表===========================")tEnv.executeSql("SELECT * FROM query_table$audit_log").print()}
}
运行代码。
注意:在本地执行flink sql中的print,会看到下面错误:
java.lang.IllegalStateException: MiniCluster is not yet running or has already been shut down.at org.apache.flink.util.Preconditions.checkState(Preconditions.java:193)at org.apache.flink.runtime.minicluster.MiniCluster.getDispatcherGatewayFuture(MiniCluster.java:1026)at org.apache.flink.runtime.minicluster.MiniCluster.runDispatcherCommand(MiniCluster.java:899)at org.apache.flink.runtime.minicluster.MiniCluster.getJobStatus(MiniCluster.java:823)at org.apache.flink.runtime.minicluster.MiniClusterJobClient.getJobStatus(MiniClusterJobClient.java:91)at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.isJobTerminated(CollectResultFetcher.java:210)at org.apache.flink.streaming.api.operators.collect.CollectResultFetcher.next(CollectResultFetcher.java:118)at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:106)at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.hasNext(CollectResultIterator.java:80)at org.apache.flink.table.planner.connectors.CollectDynamicSink$CloseableRowIteratorWrapper.hasNext(CollectDynamicSink.java:219)at org.apache.flink.table.utils.print.TableauStyle.print(TableauStyle.java:120)at org.apache.flink.table.api.internal.TableResultImpl.print(TableResultImpl.java:153)at tech.xuwei.paimon.query.FlinkPaimonSystemTable$.main(FlinkPaimonSystemTable.scala:35)at tech.xuwei.paimon.query.FlinkPaimonSystemTable.main(FlinkPaimonSystemTable.scala)
这个异常不影响程序执行,实际工作中我们不会写这种代码,一般都是在sql中写insert into select语句了,在这主要是为了方便测试,忽略这个异常即可。
如果感觉看起来比较乱,可以修改一下log4j.properties日志中的告警级别,改为error级别即可。
log4j.rootLogger=error,stdoutlog4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
重新运行代码,可以看到如下结果:
====================snapshot信息表===========================
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
| op | snapshot_id | schema_id | commit_user | commit_identifier | commit_kind | commit_time | total_record_count | delta_record_count | changelog_record_count | watermark |
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
| +I | 1 | 0 | 8f74d97b-bf6b-4ac7-bb47-3bb... | 9223372036854775807 | APPEND | 2023-07-28 17:35:22.859 | 1 | 1 | 0 | -9223372036854775808 |
| +I | 2 | 0 | 49412497-1749-4566-8bf8-1c5... | 9223372036854775807 | APPEND | 2023-07-28 17:35:24.802 | 2 | 1 | 0 | -9223372036854775808 |
| +I | 3 | 0 | e55e756d-e528-4b7c-97f0-a01... | 9223372036854775807 | APPEND | 2023-07-28 17:35:26.409 | 3 | 1 | 0 | -9223372036854775808 |
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
3 rows in set
====================schema信息表===========================
+----+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | schema_id | fields | partition_keys | primary_keys | options | comment |
+----+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 0 | [{"id":0,"name":"name","typ... | [] | ["name"] | {} | |
+----+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
1 row in set
====================manifest信息表===========================
+----+--------------------------------+----------------------+----------------------+----------------------+----------------------+
| op | file_name | file_size | num_added_files | num_deleted_files | schema_id |
+----+--------------------------------+----------------------+----------------------+----------------------+----------------------+
| +I | manifest-800ac729-22d3-494b... | 1665 | 1 | 0 | 0 |
| +I | manifest-61d14e4e-d2a0-42ac... | 1675 | 1 | 0 | 0 |
| +I | manifest-fd8e45b0-d456-467a... | 1673 | 1 | 0 | 0 |
+----+--------------------------------+----------------------+----------------------+----------------------+----------------------+
3 rows in set
====================file信息表===========================
+----+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+-------------+----------------------+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | partition | bucket | file_path | file_format | schema_id | level | record_count | file_size_in_bytes | min_key | max_key | null_value_counts | min_value_stats | max_value_stats | creation_time |
+----+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+-------------+----------------------+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | [] | 0 | data-6b23bcaf-3dbe-46c0-a67... | orc | 0 | 0 | 1 | 566 | [jack] | [jack] | {age=0, name=0} | {age=18, name=jack} | {age=18, name=jack} | 2023-07-28 17:35:22.453 |
| +I | [] | 0 | data-ce40f0df-aa2a-4682-8b6... | orc | 0 | 0 | 1 | 581 | [mick] | [mick] | {age=0, name=0} | {age=20, name=mick} | {age=20, name=mick} | 2023-07-28 17:35:26.257 |
| +I | [] | 0 | data-ac9bd895-2b8e-4efe-969... | orc | 0 | 0 | 1 | 572 | [tom] | [tom] | {age=0, name=0} | {age=19, name=tom} | {age=19, name=tom} | 2023-07-28 17:35:24.603 |
+----+--------------------------------+-------------+--------------------------------+--------------------------------+----------------------+-------------+----------------------+----------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+
3 rows in set
====================option信息表===========================
Empty set
====================tag信息表===========================
Empty set
====================consumer信息表===========================
Empty set
====================audit log信息表===========================
+----+--------------------------------+--------------------------------+-------------+
| op | rowkind | name | age |
+----+--------------------------------+--------------------------------+-------------+
| +I | +I | jack | 18 |
| +I | +I | mick | 20 |
| +I | +I | tom | 19 |
+----+--------------------------------+--------------------------------+-------------+
3 rows in set
(2)批量读取
下面演示一下如何在批量读取中使用时间旅行功能。
创建object:tech.xuwei.paimon.query.FlinkPaimonBatchQuery
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 批量读取* Created by xuwei*/
object FlinkPaimonBatchQuery {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//SET 'execution.runtime-mode' = 'batch';env.setRuntimeMode(RuntimeExecutionMode.BATCH)//使用批处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//批量查询数据tEnv.executeSql("""|SELECT * FROM query_table|-- /*+ OPTIONS('scan.mode'='latest-full') */ -- 默认策略,可以省略不写,只读取最新快照中的所有数据|-- /*+ OPTIONS('scan.mode'='latest') */ -- 在批处理模式下和latest-full的效果一致|-- /*+ OPTIONS('scan.mode'='from-snapshot','scan.snapshot-id' = '2') */ -- 只读取指定id的快照中的所有数据|-- /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '2') */ -- 在批处理模式下和from-snapshot的效果一致|-- /*+ OPTIONS('scan.mode'='from-timestamp','scan.timestamp-millis' = '1690536924802') */ -- 只读取指定时间戳的快照中的所有数据|-- /*+ OPTIONS('scan.mode'='incremental','incremental-between' = '1,3') */ -- 指定两个快照id,查询这两个快照之间的增量变化|-- /*+ OPTIONS('scan.mode'='incremental','incremental-between-timestamp' = '1690536922859,1690536926409') */ -- 指定两个时间戳,查询这两个快照之间的增量变化|""".stripMargin).print()}
}
运行代码,查看每一种策略的数据结果。
注意:在演示compacted-full这种策略的时候需要给表开启full-compaction。
所以重新创建一个新的表。
创建object:FlinkSQLWriteToPaimonForCompact
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 通过FlinkSQL 向Paimon中模拟写入数据* Created by xuwei*/
object FlinkSQLWriteToPaimonForCompact {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//创建Paimon类型的表tEnv.executeSql("""|CREATE TABLE IF NOT EXISTS `query_table_compact`(| name STRING,| age INT,| PRIMARY KEY (name) NOT ENFORCED|)WITH(| 'changelog-producer' = 'full-compaction',| 'full-compaction.delta-commits' = '1'|)|""".stripMargin)//写入数据tEnv.executeSql("INSERT INTO query_table_compact(name,age) VALUES('jack',18)")tEnv.executeSql("INSERT INTO query_table_compact(name,age) VALUES('tom',19)")tEnv.executeSql("INSERT INTO query_table_compact(name,age) VALUES('mick',20)")}}
运行代码。
再创建一个新的读取数据的类:
创建object:FlinkPaimonBatchQueryForCompact
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 批量读取* Created by xuwei*/
object FlinkPaimonBatchQueryForCompact {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//SET 'execution.runtime-mode' = 'batch';env.setRuntimeMode(RuntimeExecutionMode.BATCH)//使用批处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//批量查询数据tEnv.executeSql("""|SELECT * FROM query_table_compact|/*+ OPTIONS('scan.mode' = 'compacted-full') */ --表需要开启full-compaction,设置changelog-producer和full-compaction.delta-commits|""".stripMargin).print()}
}
运行代码,可以看到如下结果:
+----+--------------------------------+-------------+
| op | name | age |
+----+--------------------------------+-------------+
| +I | jack | 18 |
| +I | mick | 20 |
| +I | tom | 19 |
+----+--------------------------------+-------------+
由于目前每一次提交数据都会触发完全压缩,所以我们查询最新的完全压缩快照中的数据是可以获取到所有数据的。
此时可以通过系统表查看一下这个表的snapshot信息:
创建object:FlinkPaimonSystemTableForCompact
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 查询Paimon中的系统表* Created by xuwei*/
object FlinkPaimonSystemTableForCompact {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.BATCH)//使用批处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//snapshot信息表,对应的其实就是hdfs中表的snapshot目录下的snapshot-*文件信息println("====================snapshot信息表===========================")tEnv.executeSql("SELECT * FROM query_table_compact$snapshots").print()}
}
执行代码,可以看到如下结果
====================snapshot信息表===========================
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
| op | snapshot_id | schema_id | commit_user | commit_identifier | commit_kind | commit_time | total_record_count | delta_record_count | changelog_record_count | watermark |
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
| +I | 1 | 0 | 38d8f3a4-aeb3-4072-90cf-421... | 9223372036854775807 | APPEND | 2023-07-28 17:57:07.293 | 1 | 1 | 0 | -9223372036854775808 |
| +I | 2 | 0 | 38d8f3a4-aeb3-4072-90cf-421... | 9223372036854775807 | COMPACT | 2023-07-28 17:57:08.211 | 3 | 2 | 1 | -9223372036854775808 |
| +I | 3 | 0 | 84203720-0e42-40a6-8202-642... | 9223372036854775807 | APPEND | 2023-07-28 17:57:09.423 | 4 | 1 | 0 | -9223372036854775808 |
| +I | 4 | 0 | 84203720-0e42-40a6-8202-642... | 9223372036854775807 | COMPACT | 2023-07-28 17:57:09.641 | 8 | 4 | 1 | -9223372036854775808 |
| +I | 5 | 0 | 25d0f600-076a-407f-a07a-caf... | 9223372036854775807 | APPEND | 2023-07-28 17:57:11.500 | 9 | 1 | 0 | -9223372036854775808 |
| +I | 6 | 0 | 25d0f600-076a-407f-a07a-caf... | 9223372036854775807 | COMPACT | 2023-07-28 17:57:12.130 | 15 | 6 | 1 | -9223372036854775808 |
+----+----------------------+----------------------+--------------------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+------------------------+----------------------+
此时可以看到在commit_kind这一列中显示的有APPEND和COMPACT,表示这个快照是追加产生的还是完全压缩产生的。
由于我们配置的每一次提交数据都会触发完全压缩,所以对应的有3个完全压缩产生的快照。
为了便于验证,我们可以把最新的那个完全压缩的快照删除掉,再执行查询,看看结果是什么样的:
删除最新的完全压缩的快照:
[root@bigdata04 ~]# hdfs dfs -rm -r /paimon/default.db/query_table_compact/snapshot/snapshot-6
注意:这个删除操作建议大家在命令行执行,不要在web页面执行,在web页面删除可能会直接把这个表的目录删除掉!!!!!
然后再执行FlinkPaimonBatchQueryForCompact,结果如下:
+----+--------------------------------+-------------+
| op | name | age |
+----+--------------------------------+-------------+
| +I | jack | 18 |
| +I | tom | 19 |
+----+--------------------------------+-------------+
2 rows in set
注意:此时最新的完全压缩的快照就是snapshot-4了,这个快照中只有2条数据。
这就是批量读取中时间旅行参数的使用。
(3)流式读取
下面演示一下如何在流式读取中使用时间旅行功能。
创建object:FlinkPaimonStreamingQuery
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 流式读取* Created by xuwei*/
object FlinkPaimonStreamingQuery {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//SET 'execution.runtime-mode' = 'streaming';env.setRuntimeMode(RuntimeExecutionMode.STREAMING)//使用流处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//流式查询数据tEnv.executeSql("""|SELECT * FROM query_table|-- /*+ OPTIONS('scan.mode'='latest-full') */ -- 默认策略,可以省略不写,第一次启动时读取最新快照中的所有数据,然后继续读取后续新增的变更数据|-- /*+ OPTIONS('scan.mode'='latest') */ -- 只读取最新的变更数据|-- /*+ OPTIONS('scan.mode'='from-snapshot','scan.snapshot-id' = '2') */ -- 从指定id的快照开始读取变更数据(包含后续新增)|-- /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '2') */ -- 第一次启动时读取指定id的快照中的所有数据,然后继续读取后续新增的变更数据|-- /*+ OPTIONS('scan.mode'='from-timestamp','scan.timestamp-millis' = '1690536924802') */ -- 从指定时间戳的快照开始读取变更数据(包含后续新增)|""".stripMargin).print()}
}
(4)Consumer ID
最后我们在流式读取这里扩展一个知识点:Consumer ID,这个功能是针对流式读取设计的。
相当于我们在kafka消费者中指定一个groupid,这样可以通过groupid维护消费数据的偏移量信息,便于任务停止以后重启的时候继续基于之前的进度进行查询。
在这里Consumer ID的主要作用是为了方便记录每次查询到的数据快照的位置,他会把下一个还未读取的快照id记录到hdfs文件中。
当之前的任务停止以后,新启动的任务可以基于之前任务记录的快照id继续查询数据,不需要从状态中恢复位置信息。
这个特性目前属于实验特性,还没有经过大量生产环境的验证,大家可以先提前了解一下。
下面来结合一个案例演示一下:
具体的思路是这样的:
- 1:首先使用Consumer ID查询一次query_table表中的数据。
- 2:然后停止之前的查询任务,向query_table表中模拟产生1条数据。
- 3:重新启动第1步骤中的任务,验证一下是否只读取到了新增的那1条数据
创建object:FlinkPaimonStreamingQueryForConsumerid
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 流式读取* Created by xuwei*/
object FlinkPaimonStreamingQueryForConsumerid {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//SET 'execution.runtime-mode' = 'streaming';env.setRuntimeMode(RuntimeExecutionMode.STREAMING)//使用流处理模式val tEnv = StreamTableEnvironment.create(env)//注意:在流处理模式中,操作Paimon表时需要开启Checkpoint。env.enableCheckpointing(5000)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//流式查询数据tEnv.executeSql("""|SELECT * FROM query_table|/*+ OPTIONS('consumer-id'='con-1') */ -- 指定消费者id|""".stripMargin).print()}
}
注意:在这需要开启checkpoint,否则Consumer ID的功能无法正常触发。
第一次执行此代码,可以看到如下结果:
+----+--------------------------------+-------------+
| op | name | age |
+----+--------------------------------+-------------+
| +I | jack | 18 |
| +I | mick | 20 |
| +I | tom | 19 |
停止此代码。
此时其实可以到hdfs中查看一下维护的Consumer ID信息:
[root@bigdata04 ~]# hdfs dfs -cat /paimon/default.db/query_table/consumer/consumer-con-1
{"nextSnapshot" : 4
}
这里面记录的是下一次需要读取的快照id,数值为4,此时最新的快照id是3,因为快照id为3的快照已经读取过了,下一个快照id就是4了。
其实直接查询consumer系统表也是可以看到这些信息的。
创建object:FlinkPaimonSystemTableForConsumerid
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 查询Paimon中的系统表* Created by xuwei*/
object FlinkPaimonSystemTableForConsumerid {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.BATCH)//使用批处理模式val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//consumer信息表,在查询数据的sql语句中指定了consumer-id之后才能看到println("====================consumer信息表===========================")tEnv.executeSql("SELECT * FROM query_table$consumers").print()}
}
执行代码,可以看到如下结果:
====================consumer信息表===========================
+----+--------------------------------+----------------------+
| op | consumer_id | next_snapshot_id |
+----+--------------------------------+----------------------+
| +I | con-1 | 4 |
+----+--------------------------------+----------------------+
1 row in set
从这可以看出来,next_snapshot_id是4,查出来的结果是一样的。
接下来我们向query_table中新增一条数据。
创建object:FlinkSQLWriteToPaimonForConsumerid
代码如下:
package tech.xuwei.paimon.queryimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** 通过FlinkSQL 向Paimon中模拟写入数据* Created by xuwei*/
object FlinkSQLWriteToPaimonForConsumerid {def main(args: Array[String]): Unit = {//获取执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的CatalogtEnv.executeSql("""|CREATE CATALOG paimon_catalog WITH (| 'type'='paimon',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_catalog")//创建Paimon类型的表tEnv.executeSql("""|CREATE TABLE IF NOT EXISTS `query_table`(| name STRING,| age INT,| PRIMARY KEY (name) NOT ENFORCED|)|""".stripMargin)//写入数据tEnv.executeSql("INSERT INTO query_table(name,age) VALUES('jessic',30)")}}
执行代码。
最后,我们再重新启动FlinkPaimonStreamingQueryForConsumerid,可以看到如下结果:
+----+--------------------------------+-------------+
| op | name | age |
+----+--------------------------------+-------------+
| +I | jessic | 30 |
能看到这个结果,说明这个consumer id生效了,当我们第二次使用相同的consumer id读取这个表的时候,是可以基于之前的进度继续读取的。
停止此任务。
此时再执行FlinkPaimonSystemTableForConsumerid,查看最新的next_snapshot_id:
====================consumer信息表===========================
+----+--------------------------------+----------------------+
| op | consumer_id | next_snapshot_id |
+----+--------------------------------+----------------------+
| +I | con-1 | 5 |
+----+--------------------------------+----------------------+
1 row in set
此时next_snapshot_id变成了5,这是正确的。
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
相关文章:
5 Paimon数据湖之表数据查询详解
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html 虽然前面我们已经讲过如何查询Paimon表中的数据了,但是有一些细节的东西还需要详细分析一下。 首先是针对Paimon中系统表的查询,例如snapshots\schemas\options等等这些…...

时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
官方论文地址->官方论文地址 官方代码地址->官方代码地址 个人修改代码->个人修改的代码已经上传CSDN免费下载 一、本文介绍 本文给大家带来是DLinear模型,DLinear是一种用于时间序列预测(TSF)的简单架构,DLinear的核…...
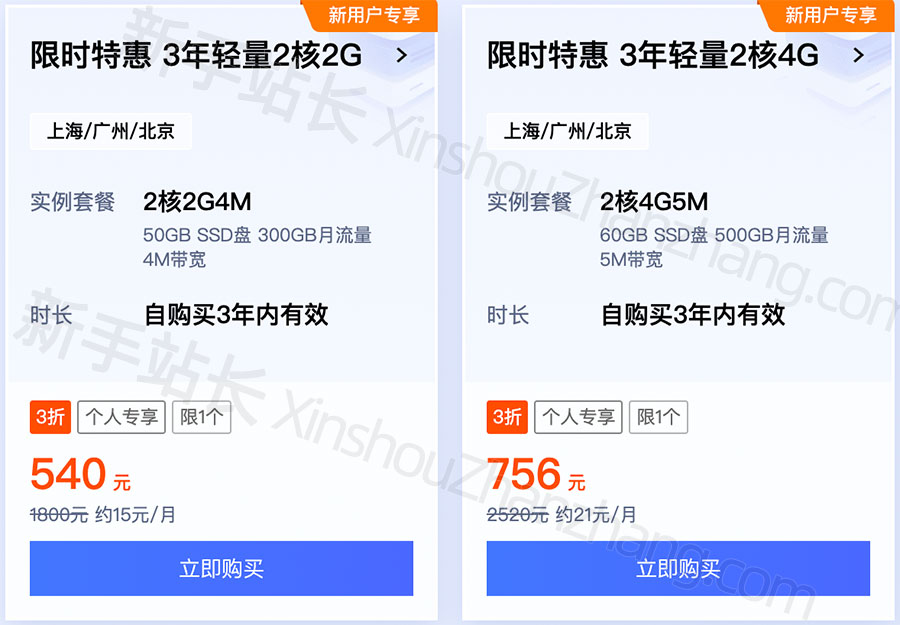
封神教程:腾讯云3年轻量应用服务器老用户购买方法
腾讯云轻量应用服务器特价是有新用户限制的,所以阿腾云建议大家选择3年期轻量应用服务器,一劳永逸,免去续费困扰。腾讯云轻量应用服务器3年优惠可以选择2核2G4M和2核4G5M带宽,3年轻量2核2G4M服务器540元,2核4G5M轻量应…...
 安装最新版的 cmake)
Ubuntu(WSL2) 安装最新版的 cmake
Ubuntu(WSL) 安装最新版的 cmake 具体流程如下: 步骤一:卸载原本的 cmake sudo apt-get remove cmake 步骤二: sudo apt-get update sudo apt-get install apt-transport-https ca-certificates gnupg software-properties-common wget 步…...
Android---内存泄漏的优化
内存泄漏是一个隐形炸弹,其本身并不会造成程序异常,但是随着量的增长会导致其他各种并发症:OOM,UI 卡顿等。 为什么要将 Activity 单独做预防? 因为 Activity 承担了与用户交互的职责,因此内部需要持有大…...
)
C/S架构学习之基于UDP的本地通信(客户机)
基于UDP的本地通信(客户机):创建流程:一、创建数据报式套接字(socket函数): int sock_fd socket(AF_UNIX,SOCK_DGRAM,0);if(-1 sock_fd){perror("socket error");exit(-1);}二、创建…...
【性能测试】服务端中间件docker常用命令解析整理(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、搜索 docker …...

【探索Linux】—— 强大的命令行工具 P.14(进程间通信 | 匿名管道 | |进程池 | pipe() 函数 | mkfifo() 函数)
阅读导航 引言一、进程间通信概念二、进程间通信目的三、进程间通信分类四、管道1. 什么是管道2. 匿名管道(1)创建和关闭⭕pipe() 函数⭕创建匿名管道⭕关闭匿名管道 (2)通信方式(3)用法示例(4&…...
图论12-无向带权图及实现
文章目录 带权图1.1带权图的实现1.2 完整代码 带权图 1.1带权图的实现 在无向无权图的基础上,增加边的权。 使用TreeMap存储边的权重。 遍历输入文件,创建TreeMap adj存储每个节点。每个输入的adj节点链接新的TreeMap,存储相邻的边和权重 …...
----数组--有序数组的平方)
每日一题(LeetCode)----数组--有序数组的平方
每日一题(LeetCode)----数组–有序数组的平方 1.题目([977. 有序数组的平方](https://leetcode.cn/problems/sqrtx/)) 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。…...

SpringCloud微服务:Eureka
目录 提供者与消费者 服务调用关系 eureka的作用 在Eureka架构中,微服务角色有两类 Eureka服务 提供者与消费者 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)服务消费者:一次业务中,调用其它微服务的服务。(调…...

19.删除链表的倒数第N个结点(LeetCode)
想法一 先用tail指针找尾,计算出节点个数,再根据倒数第N个指定删除 想法二 根据进阶的要求,只能遍历一遍链表,那刚刚想法一就做不到 首先,我们要在一遍内找到倒数第N个节点,所以我们设置slow和fast两个指…...

PyTorch技术和深度学习——三、深度学习快速入门
文章目录 1.线性回归1)介绍2)加载自由泳冠军数据集3)从0开始实现线性回归模型4)使用自动求导训练线性回归模型5)使用优化器训练线性回归模型 2.使用torch.nn模块构建线性回归模型1)使用torch.nn.Linear训练…...

360导航恶意修改浏览器启动页!我的chrome和IE均中招,如何解决?
0,关闭360等“安全”软件 1,按下组合键winR 2,输入regedit,回车 3,按下组合键ctrlF 4,输入http://hao.360.cn,查找下一个 5,查到一个注册表键值就删一个,一个不放过…...
RabbitMQ的高级特性
目录 数据导入 MQ的常见问题 消息可靠性问题 生产者确认机制 SpringAMQP实现生产者确认 消息持久化 消费者消息确认 失败重试机制 消费者失败消息处理策略 死信交换机 TTL 延时队列 安装插件 SpringAMQP使用插件 消息堆积问题 惰性队列 MQ的高可用 普通集群 …...
Java自学第10课:JavaBean和servlet基础
目录 目录 1 JavaBean (1)概念 (2)分类 (3)使用 2 servlet (1)代码结构 (2)常用接口 (3)如何开发 1 新建servlet 2 配置 1…...

AR打卡小程序:构建智能办公的新可能
【内容摘要】 随着技术的飞速发展,智能办公已不再是遥不可及的梦想。在这其中,AR打卡小程序以其独特的技术优势,正逐步成为新型办公生态的重要组成部分。本文将探讨AR打卡小程序的设计理念、技术实现以及未来的应用前景,并尝试深…...
Python环境安装、Pycharm开发工具安装(IDE)
Python下载 Python官网 Python安装 Python安装成功 Pycharm集成开发工具下载(IDE) PC集成开发工具 Pycharm集成开发工具安装(IDE) 安装完成 添加环境变量(前面勾选了Path不用配置) (1&…...
报时机器人的rasa shell执行流程分析
本文以报时机器人为载体,介绍了报时机器人的对话能力范围、配置文件功能和训练和运行命令,重点介绍了rasa shell命令启动后的程序执行过程。 一.报时机器人项目结构 1.对话能力范围 (1)能够识别欢迎语意图(greet)和拜拜意图(goodbye) (2)能够识别时间意…...
)
C#开发的OpenRA游戏之世界存在的属性UpdatesPlayerStatistics(2)
C#开发的OpenRA游戏之世界存在的属性UpdatesPlayerStatistics(2) 在文件OpenRA\mods\cnc\rules\ defaults.yaml里,可以看到这个配置,它的作用就是让这个单元可以被观察者查看到相关的信息。 UpdatesPlayerStatistics属性同样也是有两个类组成,一个叫做信息类UpdatesPlay…...

终极指南:incubator-pagespeed-ngx缓存机制深度剖析与性能优化技巧
终极指南:incubator-pagespeed-ngx缓存机制深度剖析与性能优化技巧 【免费下载链接】incubator-pagespeed-ngx 项目地址: https://gitcode.com/gh_mirrors/incu/incubator-pagespeed-ngx incubator-pagespeed-ngx是一个强大的Nginx模块,通过智能…...

Kimi-VL-A3B-Thinking应用场景:电商商品识别、教育答题与文档分析实操
Kimi-VL-A3B-Thinking应用场景:电商商品识别、教育答题与文档分析实操 1. 引言:当AI能“看懂”图片,你的工作会发生什么变化? 想象一下,你是一个电商运营,每天要处理上千张商品图片,手动打标签…...

这 12 个神级免费工具,我用了才知道白白多花了好几年冤枉钱!
🛠️这 12 个神级免费工具,我用了才知道白白多花了好几年冤枉钱!AI写作 / 视频剪辑 / 图片处理 / 效率提升全部免费可用,链接直接点,手机电脑都支持阅读约 6 分钟 强烈建议收藏转发很多人不知道:那些动辄几…...

MediaCrawler:如何构建企业级社交媒体情报系统
MediaCrawler:如何构建企业级社交媒体情报系统 【免费下载链接】MediaCrawler-new 项目地址: https://gitcode.com/GitHub_Trending/me/MediaCrawler-new 在信息爆炸的时代,企业如何从海量社交媒体内容中精准捕捉市场信号?传统的人工…...

2026国内AI镜像网站全景解析:技术、选型、合规与实战指南
2026年,AI大模型已成为开发者、内容创作者与企业运营的标配生产力工具,但ChatGPT、Gemini、Claude等海外顶尖模型仍面临国内访问壁垒、网络不稳定、支付繁琐等现实问题。在此背景下,国内AI镜像网站凭借“国内直连、一站式聚合、低门槛使用”的核心优势,成为行业刚需,相关关…...

uniapp中SQLite表缺失问题的排查与解决——以“no such table”错误为例
1. 初识"no such table"错误:从报错信息说起 第一次在uniapp开发中遇到SQLite的"no such table"错误时,我盯着控制台输出的-1404错误代码足足愣了三分钟。控制台清晰地显示着: { "code": -1404, "message…...

通义千问1.5-1.8B-Chat-GPTQ-Int4在STM32开发中的妙用:嵌入式C代码分析与调试建议生成
通义千问1.5-1.8B-Chat-GPTQ-Int4在STM32开发中的妙用:嵌入式C代码分析与调试建议生成 1. 引言:当嵌入式开发遇上轻量化大模型 如果你是一位嵌入式工程师,特别是和STM32这类MCU打交道的朋友,下面这个场景你一定不陌生࿱…...
)
LeetCode Hot 100 - 53. 最大子数组和(经典动态规划)
难度:中等 | 面试频率:⭐⭐⭐⭐⭐ 📝 题目描述 给你一个整数数组 nums,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 示例…...

中文语料分词+生成词表+词频排序
缘起 近日批改学生毕业论文,有篇初稿的话题是研究《红楼梦》文化负载词的汉英翻译,其研究方法一节有以下表述: This study adopts a random sampling method. Representative culture-loaded vocabulary is selected from the first 12 chap…...

如何利用Jbuilder构建优雅的JSON:探索Builder风格DSL的核心原理
如何利用Jbuilder构建优雅的JSON:探索Builder风格DSL的核心原理 【免费下载链接】jbuilder Jbuilder: generate JSON objects with a Builder-style DSL 项目地址: https://gitcode.com/gh_mirrors/jb/jbuilder Jbuilder是一个强大的Ruby库,它提供…...