CIFAR-100数据集的加载和预处理教程
一、CIFAR-100数据集介绍
CIFAR-100(Canadian Institute for Advanced Research - 100 classes)是一个经典的图像分类数据集,用于计算机视觉领域的研究和算法测试。它是CIFAR-10数据集的扩展版本,包含了更多的类别,用于更具挑战性的任务。
CIFAR-100包含了100个不同的类别,每个类别都包含600张32x32像素的彩色图像。
这100个类别被划分为20个大类别,每个大类别包含5个小类别。这个层次结构使得数据集更加丰富,包含了各种各样的对象和场景。每张图像的大小是32x32像素,包含RGB三个通道。

用途: CIFAR-100常被用于评估图像分类算法的性能。由于图像分辨率相对较低,它在实际中可能不太适用于一些复杂的计算机视觉任务,但对于学术研究和算法开发而言是一个常见的基准数据集。
二、下载并加载CIFAR-100数据集
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision
import torchvision.transforms as transformsdef get_train_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_training = torchvision.datasets.CIFAR100(root='./data', train=True, download=True,transform=transform_train)cifar100_training_loader = DataLoader(cifar100_training, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_training_loaderdef get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_test = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform_test)cifar100_test_loader = DataLoader(cifar100_test, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_test_loader
这里我们采用的是torchvision下载CIFAR-100数据集并将其保存到指定的路径,定义这两个函数 get_train_loader 和 get_val_loader 分别用于获取训练集和验证集的数据加载器,并进行了预处理和增强的操作。
三、检测数据加载情况
博主曾经在这上面吃过很多的亏,一般我们遇到维度不匹配的情况,通常会认为是网络的问题,但我会告诉你也有可能是数据加载的部分,这种开源数据集还好,我们项目上用的是自制的数据集,它的图片可能真的就是有些问题,比如你明明是用PIL加载图片,按理来说应该就是三通道无疑才对,但事实是就是存在通道为1的情况。
所以,为了让我们具备严谨的工程能力,为将来自己的项目打下基础,哪怕是开源数据集,我们也要进行测试。
一般来说,主要看到就是它的维度是否是正确的,还有它是否能够正确的显示。
在上面我们进行预处理操作,所以应该先进行反归一化:
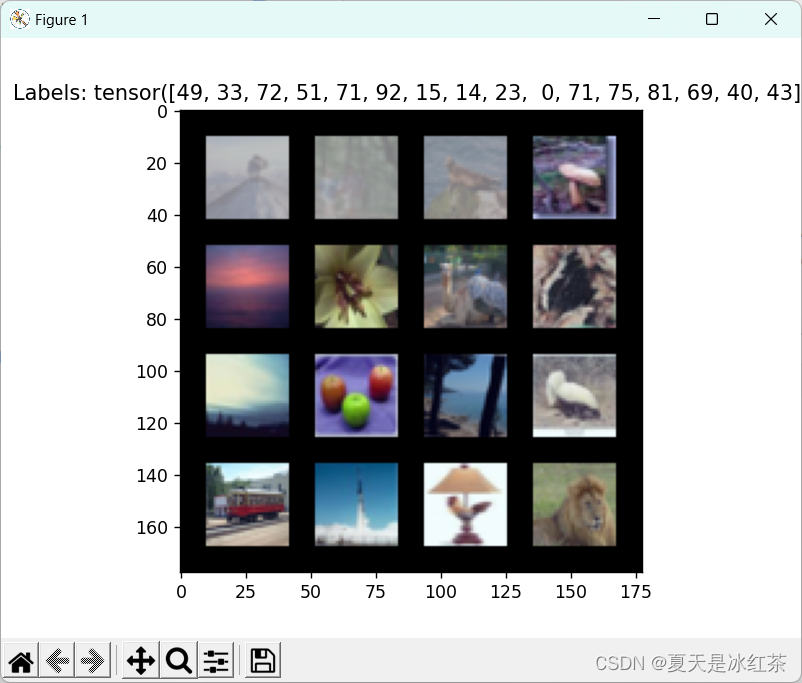
def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensor而要看如何正常的显示,我们当然不希望单张的显示,这样似乎太慢了,所以这里我们按照批量大小进行显示:
def show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, mean, std)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()测试代码:
if __name__=="__main__":import matplotlib.pyplot as pltfrom torchvision.utils import make_gridCIFAR100_TRAIN_MEAN = (0.5070751592371323, 0.48654887331495095, 0.4409178433670343)CIFAR100_TRAIN_STD = (0.2673342858792401, 0.2564384629170883, 0.27615047132568404)def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensormean = CIFAR100_TRAIN_MEANstd = CIFAR100_TRAIN_STDtest_loader = get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=False)def show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, mean, std)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()for images, labels in test_loader:show_batch(images, labels)# print(images.size(), labels)最后两行就是图片批量显示与维度检测的测试,这里最好是单独的测试,即两行中一行注释,一行正常运行。
四、自定义CIFAR-100的dataset类
dataset类的以下几个要点:
- dataset类需要继承import torch.utils.data.dataset。
- dataset的作用是将任意格式的数据,通过读取、预处理或数据增强后以tensor的形式输出。其中任意格式的数据指可能是以文件夹名作为类别的形式、或以txt文件存储图片地址的形式。而输出则指的是经过处理后的一个 batch的tensor格式数据和对应标签。
- dataset类需要重写的主要有三个函数要完成:__init__函数、__len__函数和__getitem__函数。
__init__(self, ...) 函数:初始化数据集。在这里,你通常会加载数据,设置转换(transformations)等。这个函数在数据集创建时调用。
__len__(self)函数:返回数据集的大小,即数据集中样本的数量。这个函数在调用len(dataset) 时调用。
__getitem__(self,index)函数:根据给定的索引返回数据集中的一个样本。这个函数允许你通过索引访问数据集中的单个样本,以便用于模型的训练和评估。
import os
import pickle
import numpy as npfrom torch.utils.data import Dataset,DataLoaderclass CIFAR100Dataset(Dataset):def __init__(self, path, transform=None, train=False):if train:sub_path = 'train'else:sub_path = 'test'with open(os.path.join(path, sub_path), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['fine_labels'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, label测试代码:
if __name__=="__main__":mean = CIFAR100_TRAIN_MEANstd = CIFAR100_TRAIN_STDtransform_train = transforms.Compose([transforms.ToPILImage(),transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])train_dataset = CIFAR100Dataset(path='./data/cifar-100-python', transform=transform_train)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)for images, labels in train_loader:show_batch(images, labels)# print(images.size(), labels)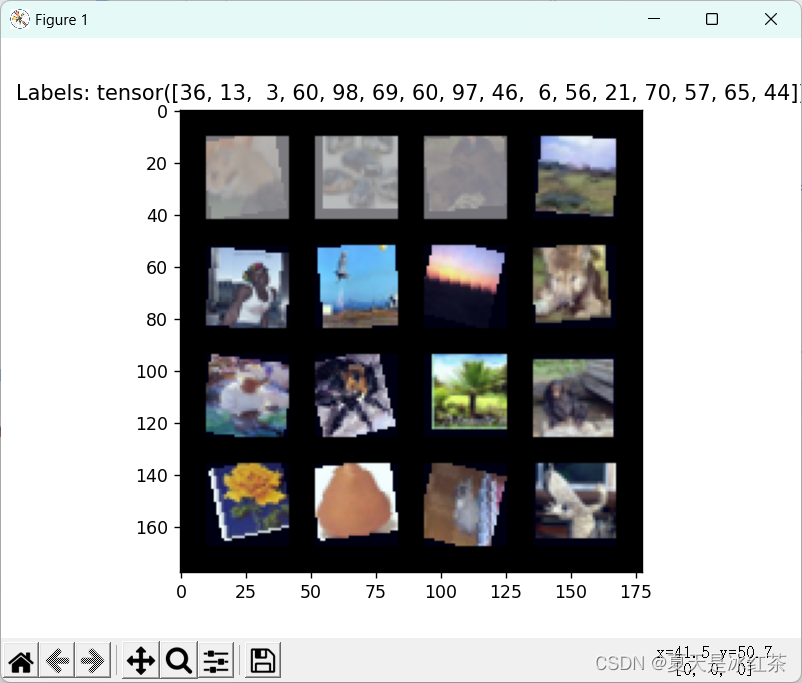
附录
本章节源码
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
import os
import pickle
import numpy as npCIFAR100_TRAIN_MEAN = (0.5070751592371323, 0.48654887331495095, 0.4409178433670343)
CIFAR100_TRAIN_STD = (0.2673342858792401, 0.2564384629170883, 0.27615047132568404)__all__ = ["get_train_loader", "get_val_loader", "CIFAR100Dataset"]class CIFAR100Dataset(Dataset):def __init__(self, path, transform=None, train=False):if train:sub_path = 'train'else:sub_path = 'test'with open(os.path.join(path, sub_path), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['fine_labels'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, labelclass CIFAR100Test(Dataset):def __init__(self, path, transform=None):with open(os.path.join(path, 'test'), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['data'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, labeldef get_train_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_training = torchvision.datasets.CIFAR100(root='./data', train=True, download=True,transform=transform_train)cifar100_training_loader = DataLoader(cifar100_training, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_training_loaderdef get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_test = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform_test)cifar100_test_loader = DataLoader(cifar100_test, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_test_loaderdef show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensordef main1():test_loader = get_val_loader(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD, batch_size=16, num_workers=2, shuffle=False)for images, labels in test_loader:show_batch(images, labels)# print(images.size(), labels)if __name__=="__main__":transform_train = transforms.Compose([transforms.ToPILImage(),transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)])train_dataset = CIFAR100Dataset(path='./data/cifar-100-python', transform=transform_train)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)for images, labels in train_loader:show_batch(images, labels)# print(images.size(), labels)相关文章:
CIFAR-100数据集的加载和预处理教程
一、CIFAR-100数据集介绍 CIFAR-100(Canadian Institute for Advanced Research - 100 classes)是一个经典的图像分类数据集,用于计算机视觉领域的研究和算法测试。它是CIFAR-10数据集的扩展版本,包含了更多的类别,用…...

C#,数值计算——函数计算,Eulsum的计算方法与源程序
1 文本格式 using System; namespace Legalsoft.Truffer { public class Eulsum { private double[] wksp { get; set; } private int n { get; set; } private int ncv { get; set; } public bool cnvgd { get; set; } pri…...
ChatGLM3 langchain_demo 代码解析
ChatGLM3 langchain_demo 代码解析 0. 背景1. 项目代码结构2. 代码解析2-1. utils.py2-2. ChatGLM3.py2-3. Tool/Calculator.py2-4. Tool/Weather.py2-5. main.py 0. 背景 学习 ChatGLM3 的项目内容,过程中使用 AI 代码工具,对代码进行解释,…...
asp.net学院网上报销系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net学院网上报销系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言 开发 asp.net学院网上报销系统 应用技术…...
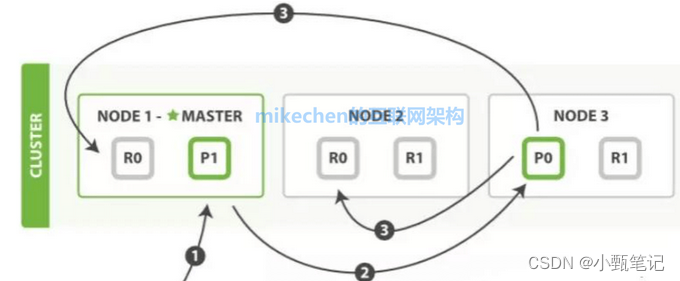
ElasticSearch知识点
什么是ElasticSearch ElasticSearch: 智能搜索,分布式的搜索引擎,是ELK的一个非常完善的产品,ELK代表的是: E就是ElasticSearch,L就是Logstach,K就是kibana Elasticsearch是一个建立在全文搜索引擎 Apache Lucene基础…...

STM32 GPIO
STM32 GPIO GPIO简介 GPIO(General Purpose Input Output)通用输入输出口,也就是我们俗称的IO口 根据使用场景,可配置为8种输入输出模式 引脚电平:0V~3.3V,部分引脚可容忍5V 数据0就是低电平,…...

Electron 开发页面应用
简介 Electron集成了包括chromium(理解为具备chrom浏览器的工具),nodejs,native apis chromium:支持最新特性的浏览器。 nodejs:js运行时,可实现文件读写等。 native apis :提供…...

CSDN写博文的128天
起因 为什么要写博文? 写博文是因为当我还是编程小白时,我那会啥也不懂,不懂函数调用,不懂指针,更不懂结构体,别更说Linux,平时不会也没有可以问的人,也幸好有CSDN,遇到…...
Linux学习教程(第二章 Linux系统安装)1
第二章 Linux系统安装 学习 Linux,首先要学会搭建 Linux 系统环境,也就是学会在你的电脑上安装 Linux 系统。 很多初学者对 Linux 望而生畏,多数是因为对 Linux 系统安装的恐惧,害怕破坏电脑本身的系统,害怕硬盘数据…...

vue2手机项目如何使用蓝牙功能
要在Vue2手机项目中使用蓝牙功能,你需要先了解基本的蓝牙知识和API。以下是一些基本的步骤: 确认你的手机设备支持蓝牙功能。在Vue2项目中安装蓝牙插件或库,例如vue-bluetooth或vue-bluetooth-manager。你可以通过npm安装它们。在Vue2项目中…...

魔兽服务器学习-笔记1
文章目录 一、环境准备1)依赖安装2)源码下载和编译 二、生成数据信息1)地图数据信息(客户端信息)2)数据库信息 三、启动服务器四、日志模块五、数据库模块六、场景模块1)地图管理2)A…...

代码随想录day60|84.柱状图中最大的矩形
84.柱状图中最大的矩形(找到右边第一个更小的元素) 1、对于每一个柱子:找到左边第一个比他矮的,再找到右边第一个比他矮的。 2、首尾加0: 为什么要在末尾加0:否则如果原数组就是单调递增的话,就…...
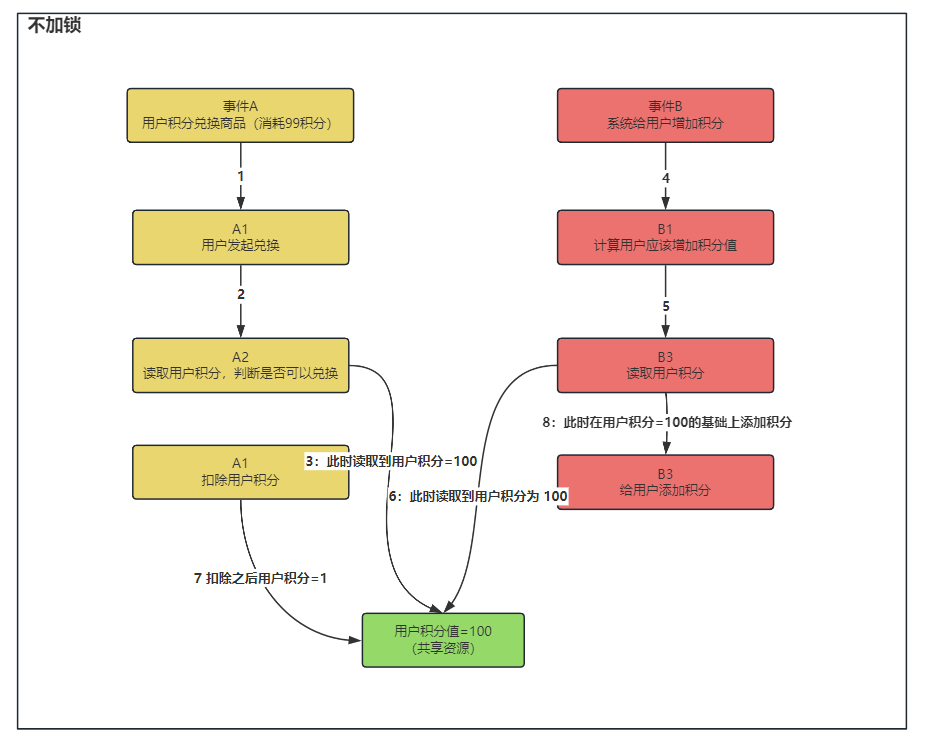
常见面试题-分布式锁
Redisson 分布式锁?在项目中哪里使用?多久会进行释放?如何加强一个分布式锁? 答: 什么时候需要使用分布式锁呢? 在分布式的场景下,使用 Java 的单机锁并不可以保证多个应用的同时操作共享资源…...

vue开发 安装一些工具
下载 node.js环境 nodeJs 官网 命令行输入 node -v 和 npm -v 出现版本号 代表nodejs 安装成功选择安装pnpm npm install -g pnpmpnpm -v 出现版本号即成功安装安装 scss vue3 组件库 Element Plus Element 官网 安装 pnpm install Element-Plus --save第一次使用开发v…...

Vue.js 组件 - 自定义事件
Vue.js 组件 - 自定义事件 父组件是使用 props 传递数据给子组件,但如果子组件要把数据传递回去,就需要使用自定义事件! 我们可以使用 v-on 绑定自定义事件, 每个 Vue 实例都实现了事件接口(Events interface),即: …...
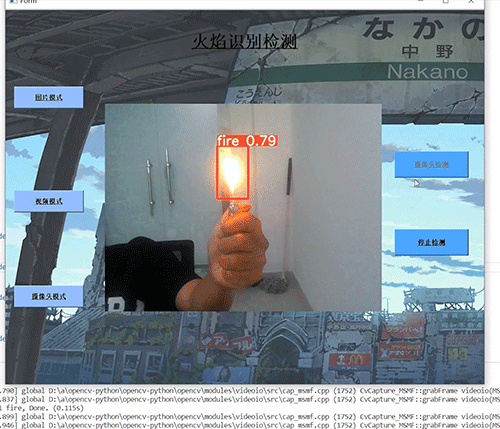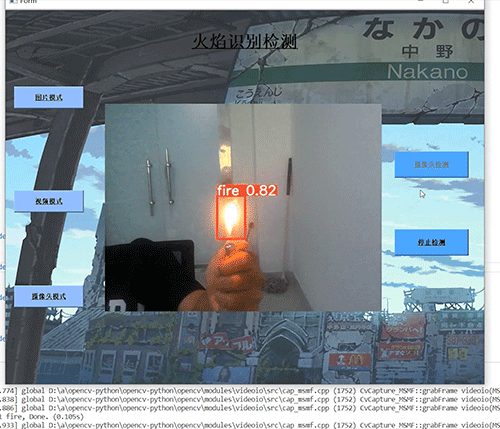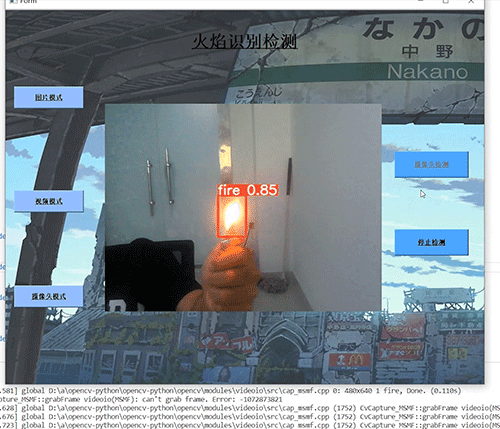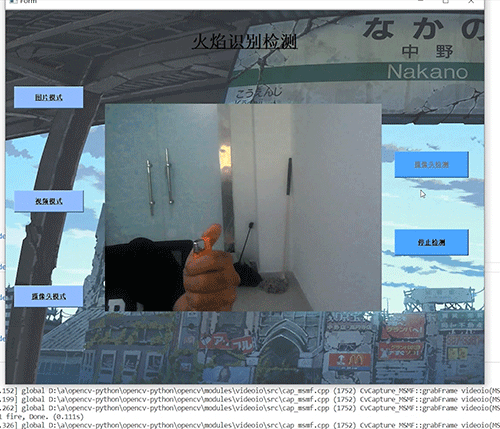
深度学习 python opencv 火焰检测识别 计算机竞赛
文章目录 0 前言1 基于YOLO的火焰检测与识别2 课题背景3 卷积神经网络3.1 卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV54.1 网络架构图4.2 输入端4.3 基准网络4.4 Neck网络4.5 Head输出层 5 数据集准备5.1 数…...

PHP中传值与引用的区别
在PHP中,变量的传递方式主要分为传值和传引用两种。这两种方式在操作中有一些重要的区别,影响着变量在函数调用或赋值操作中的表现。下面详细解释一下这两种传递方式的区别。 传值(By Value) 传值是指将变量的值复制一份传递给函…...
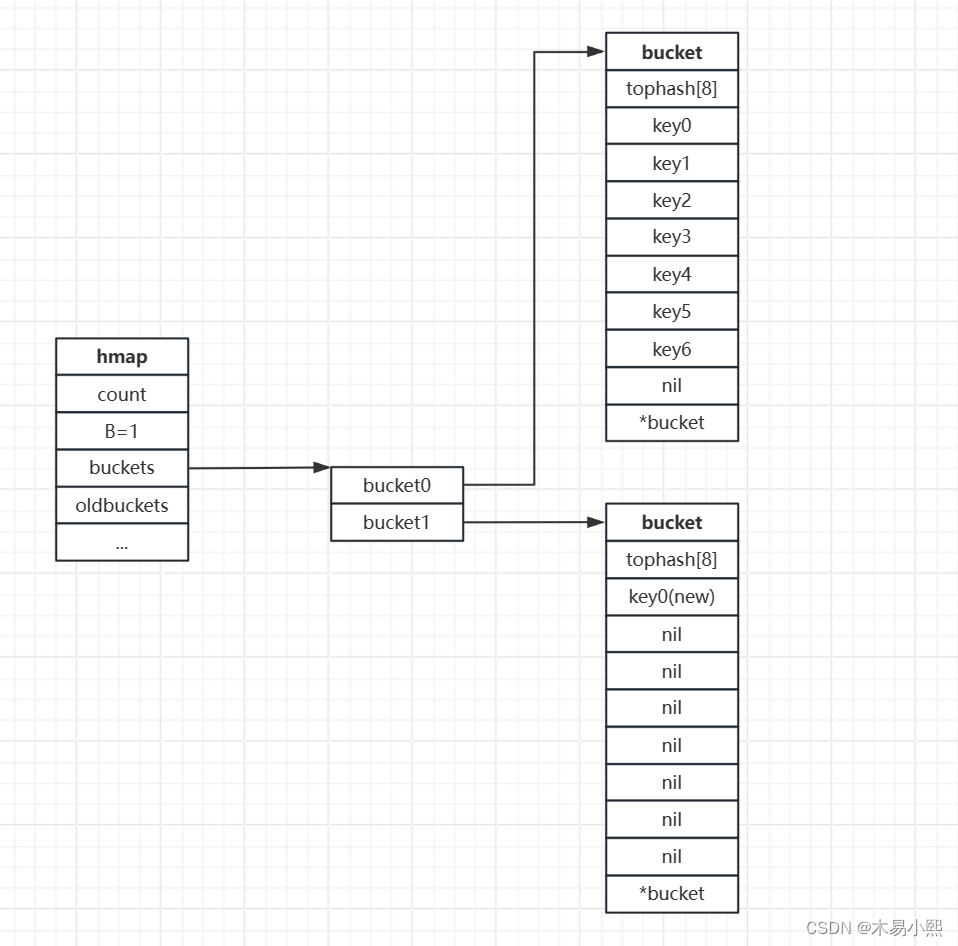
Go常见数据结构的实现原理——map
(一)基础操作 版本:Go SDK 1.20.6 1、初始化 map分别支持字面量初始化和内置函数make()初始化。 字面量初始化: m : map[string] int {"apple": 2,"banana": 3,}使用内置函数make()初始化: m …...
第二十五节——Vuex--历史遗留
文档地址 Vuex 是什么? | Vuex version V4.x 一、概念 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式 库。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。一个状态自管理应用包含以下几个部…...

大数据Doris(二十一):数据导入演示
文章目录 数据导入演示 一、启动zookeeper集群(三台节点都启动) 二、启动hdfs集群...

PHP终极指南:用SimpleXLSX轻松搞定Excel文件处理
PHP终极指南:用SimpleXLSX轻松搞定Excel文件处理 【免费下载链接】simplexlsx Parse and retrieve data from Excel XLSx files 项目地址: https://gitcode.com/gh_mirrors/si/simplexlsx 在PHP开发中,处理Excel文件常常是一项繁琐的任务。无论是…...

AlienFX Tools技术深度解析:解锁Alienware硬件的底层控制权
AlienFX Tools技术深度解析:解锁Alienware硬件的底层控制权 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 在Alienware用户群体中…...

QTableWidget 表格组件磷
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

Python敏感性分析的完整指南:SALib库的终极应用
Python敏感性分析的完整指南:SALib库的终极应用 【免费下载链接】SALib Sensitivity Analysis Library in Python. Contains Sobol, Morris, FAST, and other methods. 项目地址: https://gitcode.com/gh_mirrors/sa/SALib SALib是一个功能强大的Python库&am…...

告别熬夜与焦虑:AI辅助下的毕业论文全周期指南
深夜,宿舍灯还亮着,键盘敲击声里夹杂着叹息——这或许是许多毕业季学子共同的记忆。面对开题、查重、数据分析、答辩等一系列任务,你是否也曾在文献海洋中迷失,在重复率红线前焦虑? 夜深了,宿舍的灯还亮着。…...

JSP的了解和使用
文章目录1.概述2.本质3.核心组成4.优点5.缺点6.作用域1.概述 JSP 的全称是 Jakarta Server Pages(曾用名:JavaServer Pages),是一种用于开发动态网页的 Java Web 技术。它的核心思想是:在 HTML 页面中嵌入 Java 代码&a…...

Starward米家游戏启动器:3分钟快速上手,告别繁琐游戏管理
Starward米家游戏启动器:3分钟快速上手,告别繁琐游戏管理 【免费下载链接】Starward Game Launcher for miHoYo - 米家游戏启动器 项目地址: https://gitcode.com/gh_mirrors/st/Starward 还在为管理多个米哈游游戏而烦恼吗?每次都要打…...

Flowise入门必看:Flowise权限管理与多租户隔离配置指南
Flowise入门必看:Flowise权限管理与多租户隔离配置指南 1. 引言 想象一下,你刚刚用Flowise在10分钟内搭建了一个智能客服工作流,效果很棒。现在你想把它分享给团队其他成员一起使用,或者想为不同的客户创建独立的工作流环境&…...

如何永久保存微信聊天记录?WeChatMsg完整指南让记忆永不丢失
如何永久保存微信聊天记录?WeChatMsg完整指南让记忆永不丢失 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

itop3-基于rockylinux8的itsm工具安装部署
目录 1.LAMP环境部署 1.1准备工作 1.2下载安装脚本 1.3使用自动模式安装lamp 1.4运维信息 2.itop安装 2.1itop下载 2.2配置itop 1.LAMP环境部署 https://www.lamp.sh/autoinstall.html 1.1准备工作 [rootitop3 ~]# yum -y install wget git Upgraded: wget-1.19.5-1…...