Go常见数据结构的实现原理——map
(一)基础操作
版本:Go SDK 1.20.6
1、初始化
map分别支持字面量初始化和内置函数make()初始化。
字面量初始化:
m := map[string] int {"apple": 2,"banana": 3,}
使用内置函数make()初始化:
m := make(map[string]int,10) // 指定容量可以有效减少内存分配次数,有利于提升程序性能m["apple"] = 2m["banana"] = 3
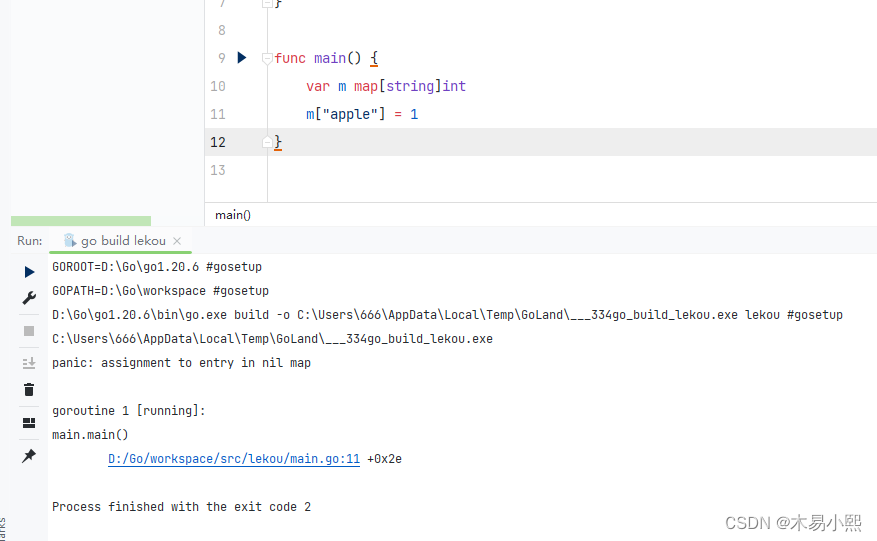
注意:未初始化的map变量的默认值为nil,向值为nil的map添加元素时会触发panic:assignment to entry in nil map(赋值给空的map),如:
var m map[string]intm["apple"] = 2 // 触发panic
2、增删改查
map的增删改查比较随意…
m := make(map[string]int,10)m["apple"] = 2 // 添加m["apple"] = 3 // 修改delete(m,"apple") // 删除v := m["apple"] // 查询v,exist := m["apple"] // 查询if exist {fmt.Println(v)}这里有几个需要注意的地方:
- 在上面的修改操作中,如果键"apple"不存在,则会直接执行添加操作。
- 删除元素使用内置函数delete()完成,delete()没有返回值,在map为nil或指定的键不存在的情况下,delete()也不会报错,相当于空操作。
- 如果使用的是第一种方式查询,当key不存在时,会返回value对应的零值,比如上面会返回0。当使用第二种时,第一个变量为值,第二个为bool类型的变量,用于指示是否存在指定的键,如果键不存在,那么第一个值为同样为对应零值。
- map操作不是原子的,当多个协程同时操作map时有可能会产生读写冲突,读写会触发panic
内置函数len()可以查询map的长度,该长度反应map中存储的键值对数。
(二)实现原理
1、数据结构
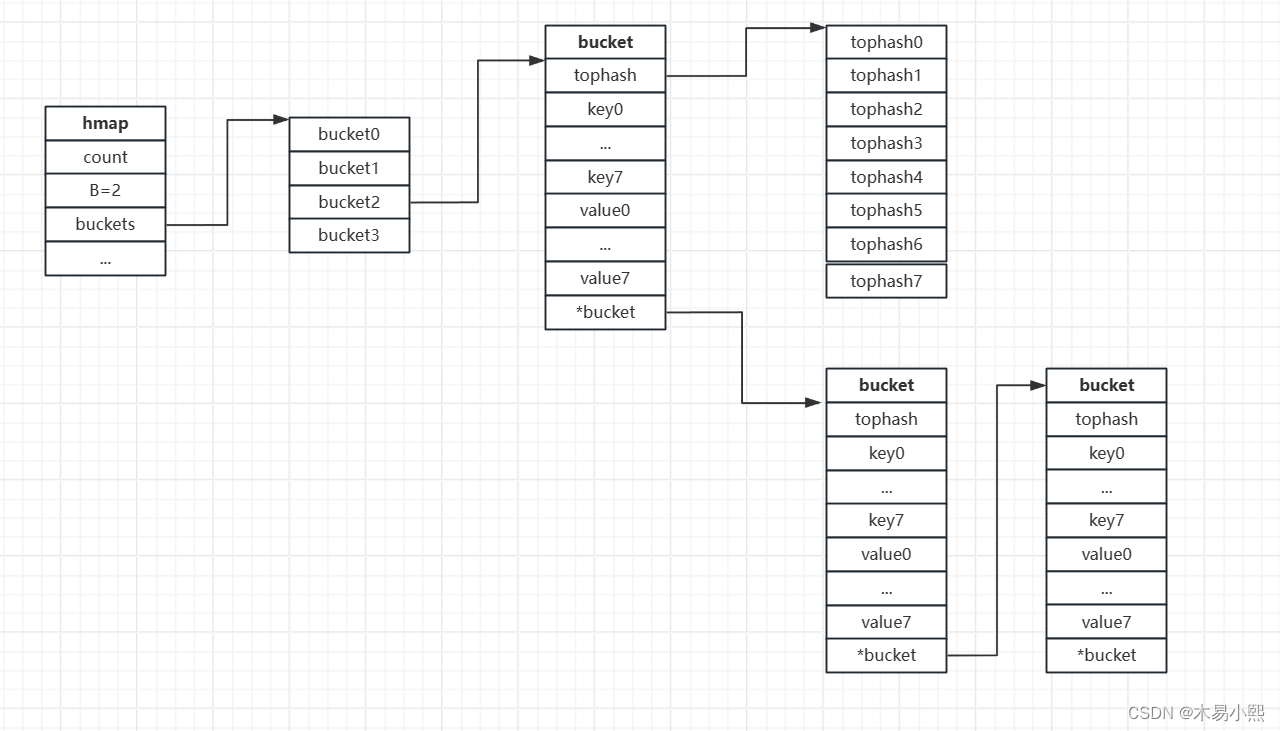
Go语言的map使用Hash表作为底层实现,一个Hash表里可以有多个bucket,而每个bucket保存了map中的一个或一组键值对。
(1)map的数据结构
map的数据结构由 runtime/map.go:hmap 定义:
type hmap struct {count int // 当前保存的元素个数flags uint8 // 状态标志B uint8 // bucket 数组的大小noverflow uint16 // 溢出桶的大概数量hash0 uint32 // 哈希种子buckets unsafe.Pointer // bucket 数组,数组的长度为2^Boldbuckets unsafe.Pointer // 老旧bucket数组,用于扩容nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成extra *mapextra // optional fields
}
下图展示了一个hmap.B=2t的map。

(2)bucket的数据结构
bucket(桶)数据结构由runtime/map.go:bmap定义
type bmap struct {tophash [bucketCnt]uint8 // 长度为8的数组
}
// 底层定义的常量
const (bucketCntBits = 3bucketCnt = 1 << bucketCntBits // 一个桶最多有8个位置
)
这是我在书上看到的bucket数据结构,并做出了如下解释:
bucket数据结构中的data和overflow成员并没有显示地在结构体中声明,运行时在访问bucket时直接通过指针的偏移量来访问这些虚拟成员
type bmap struct {tophash [8]uint8 // 存储Hash值的高8位data []byte // key value 数据:key/key/key/.../value/value/value...overflow *bmap // 溢出bucket的地址
}
每个bucket可以存储8个键值对
- tophash 是一个长度为8的整型数组,Hash值低位相同的键存入当前bucket时会将Hash值的高位存储在数组中,以方便后续匹配。
- data 区存放的是key-value数据,存放顺序是 key/key/key/…/value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。

所以tophash到底有什么用?
具体来说,如果两个键的哈希值的低位相同,但高位不同,它们可能会被映射到同一个桶位置。为了区分它们,可以将高位存储在 tophash[i] 数组中。这样,在查找时,可以首先比较低位哈希值,如果相等,再比较高位,以确保正确地匹配到相应的键。
在这种情况下,当添加元素时,如果 tophash[i] 中存储的哈希值与当前 key 的哈希值不相等,可能表示哈希冲突。这时,可能需要通过线性搜索或其他冲突解决方法在当前桶中查找匹配的键。在查找的过程中,可以利用 tophash[i] 数组中的高位信息来进一步确保正确匹配。
总体而言,这种做法是一种提高哈希表性能的优化策略,通过更多的信息来区分相同低位哈希值的键,以减少哈希冲突的影响。在实现哈希表时,具体的优化方法可能会因语言或库的不同而有所不同。
2、哈希冲突
当有两个或以上数量的键被“Hash”到同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决冲突。
关于哈希冲突的详细解释可以移步我的这篇博客哈希表是什么
3、负载因子
负载因子用于衡量一个Hash表冲突情况,公式为:
负载因子 = 键数量/bucket数量
负载因子过小或过大都不理想:
- 负载因子过小,说明空间利用率低。
- 负载因子,说明冲突严重,存取效率低
当Hash表的负载因子过大时,需要申请更多的bucket,并对所有的键值对重新组织,使其均匀地分布到这些bucket中,这个过程称为rehash。
4、扩容
(1)扩容条件
为了保证访问效率,降低负载因子,常用的手段是扩容,当新元素将要添加进map时,会判断是否需要扩容。
触发扩容需要满足以下任一条件:
- 平均负载因子大于6.5
- overflow的数量达到2^min(15,B)
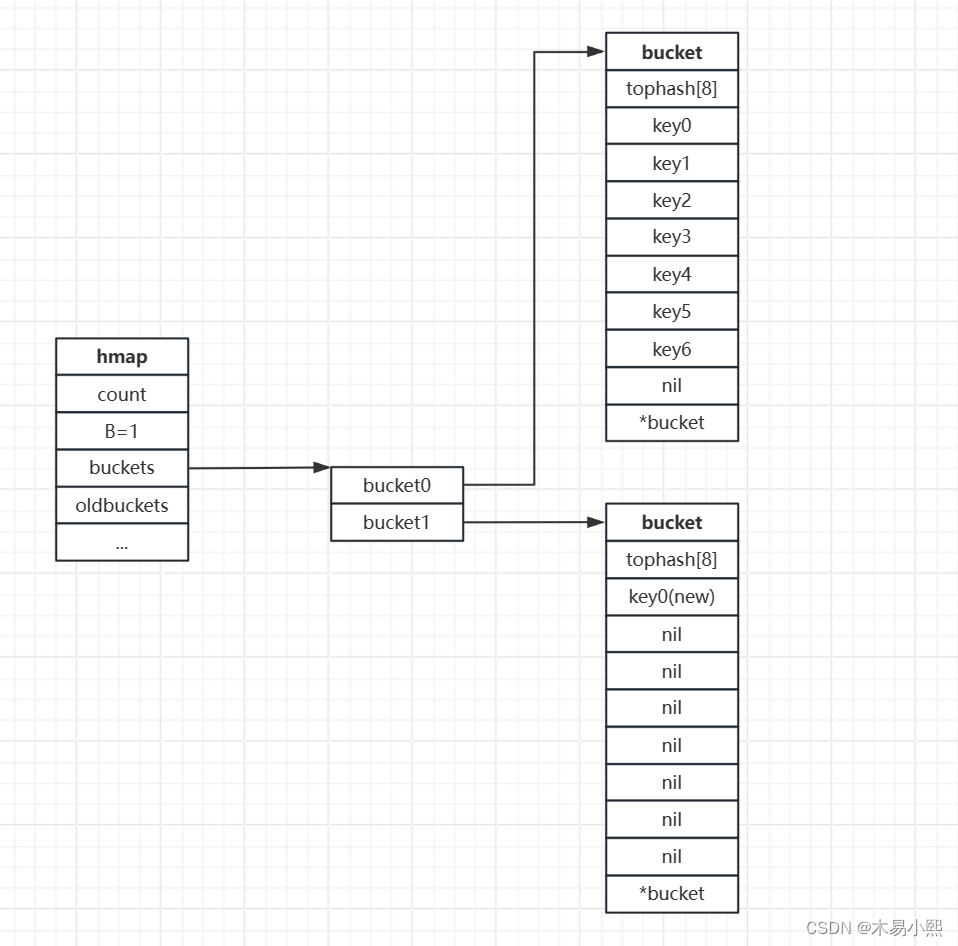
(2)增量扩容
当负载因子过大时,就新建一个bucket数组,新的bucket数组的长度为原来的2倍,然后旧bucket数组中的数据逐步搬迁到新的bucket数组中。
增量扩容的具体过程是这样的:
1、新建桶数组: 当触发增量扩容时,Go 会创建一个新的、更大的桶数组。
2、元素迁移: 然后,它会逐步将旧桶中的元素重新分配到新的桶数组中,避免一次性大规模的重新哈希。
3、渐进迁移: 在元素逐步迁移的过程中,新添加的元素会直接被放入新的桶数组中,而不会立即迁移。这保证了新元素的添加不会在迁移期间导致性能下降。
4、逐步替换: 最终,当所有元素都成功迁移到新的桶数组后,旧的桶数组会被废弃,新桶数组取而代之,完成了增量扩容的过程。
5、这种增量方式的扩容避免了在添加元素时出现大规模的哈希冲突或性能下降,因为它避免了在一次性扩容中发生的大量元素重新哈希的操作。这种方法相对于整体性地重新哈希整个 map 来说,更加有效和高效。
扩容后示意图:

搬迁完成后示意图:
5、增删改查
无论是元素的添加还是查询操作,都需要现根据键的Hash值确定一个bucket,并查询该bucket中是否存在指定的键。
- 对于查询操作而言,查到指定的键后获取值后就返回,否则返回类型的空值。
- 对于添加操作而言,查到指定的键意味着当前添加操作实际上是更新操作,否则在bucket中查找一个空余位置并插入。
(1)查找过程
查找过程简述如下:
- 计算 Hash 值: 对于给定的 key,通过哈希函数计算其对应的哈希值。
- 确定桶位置: 将计算得到的哈希值与当前 map 的桶数量 hmap.B 取模,以确定 key 应该放置在哪个桶中。这个桶就是存储相应 key-value 对的地方。
- 查找 TopHash: 从 tophash 数组中获取与当前桶位置对应的 tophash[i],其中 i 是 hash & (hmap.B - 1)。
- 比较 Hash 值: 如果 tophash[i] 中存储的哈希值与当前 key 的哈希值相等,那么表示可能找到了对应的桶,需要进一步检查。
- 比较实际值: 如果 tophash[i] 中存储的哈希值相等,接下来会比较实际的 key 值。如果找到了匹配的哈希值,但实际 key 不相等,这可能是碰撞,需要继续查找。
- 从桶中查找: 如果在当前桶中没有找到匹配的 key,就需要从溢出的桶中继续查找。溢出桶是因为哈希冲突导致多个 key 映射到同一个桶的情况。
- 返回结果: 如果找到匹配的 key,就返回对应的 value。如果遍历完所有相关的桶仍然没有找到匹配的 key,则返回相应类型的零值。
如果当前map处于搬迁过程中,则优先从oldbuckets数组中查找,查找到不再从新的buckets数组中查找。
(2)添加过程
新元素的添加过程简书如下:
- 根据key值算出Hash值
- 取Hash值低位与hmap.B取模来确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果该key不存在,则从该bucket中寻找空余位置并插入
如果当前map出于搬迁过程中,则新元素会直接添加到新的buckets数组中,但查找过程仍从oldbuckets数组中开始
(3)删除操作
删除元素实际上是先查找元素,如果元素存在则把元素从相应的bucket中清除,如果不存在则什么也不做
相关文章:
Go常见数据结构的实现原理——map
(一)基础操作 版本:Go SDK 1.20.6 1、初始化 map分别支持字面量初始化和内置函数make()初始化。 字面量初始化: m : map[string] int {"apple": 2,"banana": 3,}使用内置函数make()初始化: m …...
第二十五节——Vuex--历史遗留
文档地址 Vuex 是什么? | Vuex version V4.x 一、概念 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式 库。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。一个状态自管理应用包含以下几个部…...

大数据Doris(二十一):数据导入演示
文章目录 数据导入演示 一、启动zookeeper集群(三台节点都启动) 二、启动hdfs集群...
[100天算法】-面试题 04.01.节点间通路(day 72)
题目描述 节点间通路。给定有向图,设计一个算法,找出两个节点之间是否存在一条路径。示例1:输入:n 3, graph [[0, 1], [0, 2], [1, 2], [1, 2]], start 0, target 2 输出:true 示例2:输入:n 5, graph [[0, 1], …...
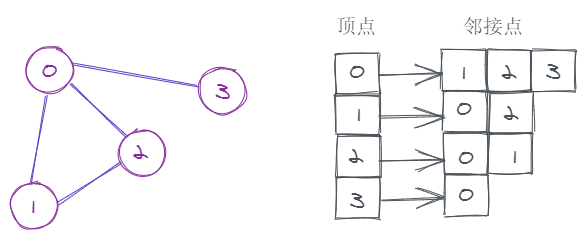
linux_day02
1、链接:LN 一个点表示当前工作目录,两个点表示上一层工作目录; 目录的本质:文件(该文件储存目录项,以链表的形式链接,每个结点都是目录项,创建文件相当于把目录项添加到链表中&…...
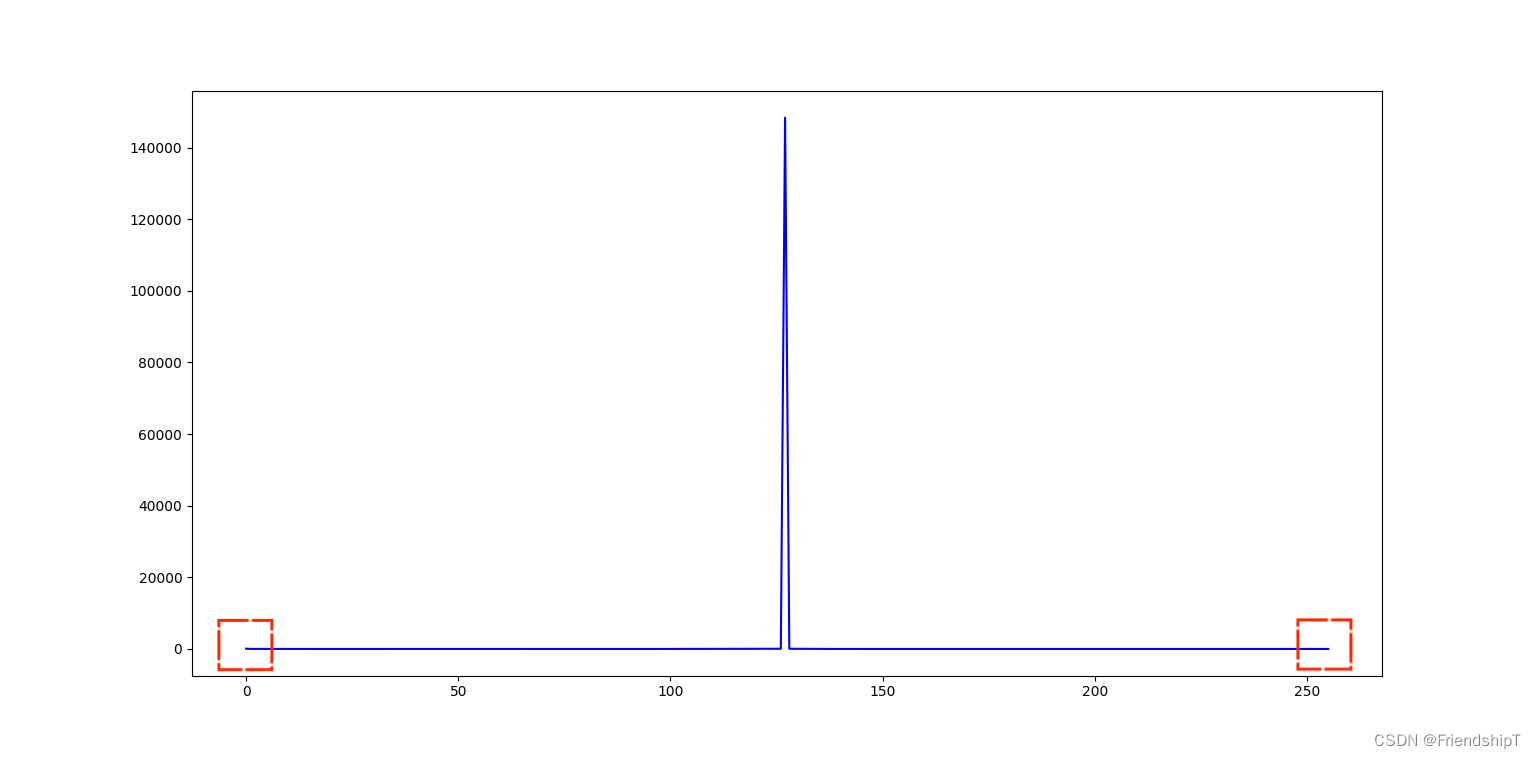
OpenCV-Python小应用(九):通过灰度直方图检测图像异常点
OpenCV-Python小应用(九):通过灰度直方图检测图像异常点 前言前提条件相关介绍实验环境通过灰度直方图检测图像异常点代码实现输出结果 参考 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容ÿ…...
关于el-table+el-input+el-propover的封装
一、先放图片便于理解 需求: 1、el-input触发focus事件,弹出el-table(当然也可以为其添加搜索功能、分页) 2、el-table中的复选共能转化成单选共能 3、选择或取消的数据在el-input中动态显示 4、勾选数据后,因为分页过多,原先选好…...

基于Python+OpenCV+SVM车牌识别系统-车牌预处理系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介简介系统流程系统优势 二、功能三、系统四. 总结 一项目简介 ## PythonOpenCVSVM车牌识别系统介绍 简介 PythonOpenCVSVM车牌识别系统是一种基于计算机视…...
 C++ 动态规划 附Java代码)
力扣第72题 编辑距离 (增 删 改) C++ 动态规划 附Java代码
题目 72. 编辑距离 中等 相关标签 字符串 动态规划 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 示例 1: 输入&a…...
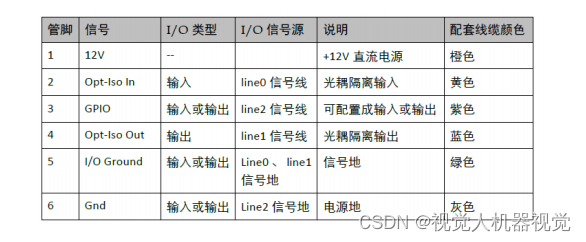
工业相机基本知识理解:工业相机IO接口,功耗和供电方式
I-input 相机接收外部信号,可用于触发相机(硬触发),也可用于定制不同的 功能,例如使用不同信号宽度来改变相机的曝光时间。主要用于现场设 备控制相机使用,常常配合各种传感器使用 O-output 相机输出信号&a…...

数据库设计
数据库设计特点 数据库建设的基本规律:三分技术,七分管理,十二分基础数据结构(数据)设计和行为(处理)设计相结合:数据库设计应该和应用系统设计相结合 数据库设计方法 新奥尔良方…...

【react.js + hooks】使用 useLoading 控制加载
在页面上 loading(加载)的效果十分常见,在某些场景下,一个页面上甚至可能有特别多的 loading 存在,此时为每一个 loading 专门创建一个 state 显然太过繁琐,不如试试写一个 useLoading 来集中管理ÿ…...
Cordova系列之化繁为简:打造全场景适用的Cordova组件
前言 在我之前的文章 Cordova初探 的开篇中说到了Cordova在Android应用开发中的一个显著的局限性就是我们的Activity必须继承其提供的CordovaActivity。这种设计对于那些追求个性化UI设计的项目而言,显得尤为受限。 其实也可以理解,Cordova主要旨在为前…...

Flink之Catalog
Catalog Catalog概述Catalog分类 GenericInMemoryCatalogJdbcCatalog下载JAR包及使用重启操作创建Catalog查看与使用Catalog自动初始化catalog HiveCatalog下载JAR包及使用重启操作hive metastore服务创建Catalog查看与使用CatalogFlink与Hive中操作自动初始化catalog 用户自定…...

计算机网络——物理层-传输方式(串行传输、并行传输,同步传输、异步传输,单工、半双工和全双工通信)
目录 串行传输和并行传输 同步传输和异步传输 单工、半双工和全双工通信 串行传输和并行传输 串行传输是指数据是一个比特一个比特依次发送的。因此在发送端和接收端之间,只需要一条数据传输线路即可。 并行传输是指一次发送n个比特,而不是一个比特&…...
男科医院服务预约小程序的作用是什么
医院的需求度从来都很高,随着技术发展,不少科目随之衍生出新的医院的,比如男科医院、妇科医院等,这使得目标群体更加精准,同时也赋能用户可以快速享受到服务。 当然相应的男科医院在实际经营中也面临痛点:…...
有没有实时检测微信聊天图片的软件,只要微信收到了有二维码的图片就把它提取出来?
10-2 如果你有需要自动并且快速地把微信收到的二维码图片保存到指定文件夹的需求,那本文章非常适合你,本文章教你如何实现自动保存微信收到的二维码图片到你指定的文件夹中,助你快速扫码,比别人领先一步。 首先需要准备好的材料…...

core-site.xml,yarn-site.xml,hdfs-site.xml,mapred-site.xml配置
core-site.xml <?xml version"1.0" encoding"UTF-8"?> <?xml-stylesheet type"text/xsl" href"configuration.xsl"?> <!--Licensed under the Apache License, Version 2.0 (the "License");you may no…...
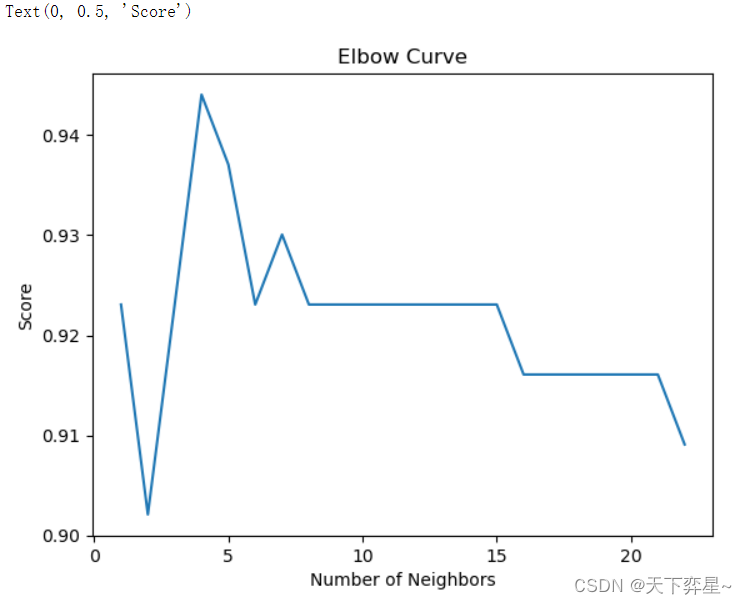
数据分析实战 | KNN算法——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型改进 十一、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://dow…...
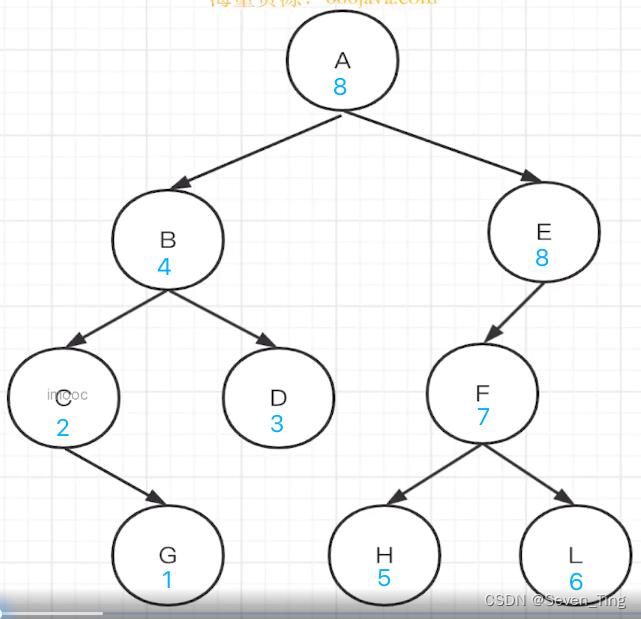
JS实现数据结构与算法
队列 1、普通队列 利用数组push和shif 就可以简单实现 2、利用链表的方式实现队列 class MyQueue {constructor(){this.head nullthis.tail nullthis.length 0}add(value){let node {value}if(this.length 0){this.head nodethis.tail node}else{this.tail.next no…...
|3种方法一步步教会你)
如何把PPT做成讲解视频(新手指南)|3种方法一步步教会你
很多人都有这样的需求:做课程讲解做培训视频做知识分享但卡在一个关键问题:👉 怎么把PPT变成“会讲解”的视频?注意,这里不是简单导出视频,而是:✅ 有讲解 ✅ 有节奏 ✅ 有字幕这篇文章…...

别再死记硬背了!用D触发器设计任意进制计数器的通用思路与Verilog实现
从状态机到Verilog:用D触发器构建任意进制计数器的通用方法论 在数字电路设计中,计数器就像乐高积木中的基础模块——看似简单却能构建出复杂系统。传统教学中,我们常被要求死记硬背特定进制(如12进制)的计数器设计&am…...
与Top-p调优指南)
Phi-3-mini-128k-instruct系统参数详解:温度(Temperature)与Top-p调优指南
Phi-3-mini-128k-instruct系统参数详解:温度(Temperature)与Top-p调优指南 刚接触Phi-3-mini这类大语言模型时,你可能会有这样的困惑:为什么同样的提示词,有时候模型回答得严谨专业,有时候又天…...

从零构建:Esp32+Esp-IDF驱动ST7789屏幕并集成LVGL图形库
1. 环境准备与工程创建 第一次玩ESP32ST7789屏幕的朋友可能会觉得有点懵,其实只要跟着步骤走,半小时就能点亮屏幕。我去年在智能家居项目里用了这个组合,实测稳定性比I2C屏幕强不少。先说说需要准备的东西: 硬件部分:E…...

2025.04.15【技术前沿】| scran:解锁单细胞RNA测序数据潜能的瑞士军刀
1. scran:单细胞数据分析的瑞士军刀 第一次接触单细胞RNA测序数据时,我被海量的基因表达矩阵弄得晕头转向。直到实验室的师兄推荐了scran,这个R包彻底改变了我的分析体验。就像瑞士军刀一样,scran把二十多种常用工具集成在一个包里…...

Windows终极解决方案:3步快速配置Coolapk-Lite UWP客户端,告别安卓模拟器
Windows终极解决方案:3步快速配置Coolapk-Lite UWP客户端,告别安卓模拟器 【免费下载链接】Coolapk-Lite 一个基于 UWP 平台的第三方酷安客户端精简版 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-Lite 还在为在Windows电脑上访问酷安社…...

【2024最危险的Agent设计陷阱】:CoT被高估?ReAct在长流程中失效率超63%?ToT的分支爆炸问题如何用动态剪枝破解
第一章:AIAgent架构模式:ReAct、CoT、ToT对比分析 2026奇点智能技术大会(https://ml-summit.org) AI Agent 的推理与决策能力高度依赖底层架构范式。ReAct(Reasoning Acting)、Chain-of-Thought(CoT)和Tr…...

建立班级相册?超简单,保姆级教你在PPT里建立班级“小红书”,3步打造有温度的班级小世界!
边听边看收获更多! 班级相册超简单,保姆级教你在PPT里建立班级“小红书”社区!你有搞班级相册吗? 是不是早已 “名存实亡”? 每次班级活动拍了几十张照片,最后都散落在微信群、QQ 群的聊天记录里 —— 想找…...

测试数据管理:AI解决方案大比拼
在数字化转型的浪潮中,软件测试从业者面临的核心挑战之一是高效管理测试数据。测试数据作为质量保障的基石,直接影响缺陷检出率、测试覆盖度和发布周期。传统方法依赖手动生成和脱敏,不仅耗时耗力,还常因数据多样性不足、安全风险…...

多平台直播自动录制系统:技术架构与实战部署指南
多平台直播自动录制系统:技术架构与实战部署指南 【免费下载链接】DouyinLiveRecorder 可循环值守和多人录制的直播录制软件,支持抖音、TikTok、Youtube、快手、虎牙、斗鱼、B站、小红书、pandatv、sooplive、flextv、popkontv、twitcasting、winktv、百…...