Flink之Catalog
Catalog
- Catalog
- 概述
- Catalog分类
- GenericInMemoryCatalog
- JdbcCatalog
- 下载JAR包及使用
- 重启操作
- 创建Catalog
- 查看与使用Catalog
- 自动初始化catalog
- HiveCatalog
- 下载JAR包及使用
- 重启操作
- hive metastore服务
- 创建Catalog
- 查看与使用Catalog
- Flink与Hive中操作
- 自动初始化catalog
- 用户自定义Catalog
- 实现Catalog
- 使用Catalog
- Catalog API
- 数据库操作
- 表操作
- 视图操作
- 分区操作
- 函数操作
Catalog
概述
Catalog提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过TableEnvironment注册的 UDF。 元数据也可以是持久化的,例如Hive Metastore中的元数据。
Catalog提供了一个统一的API,用于管理元数据,并使其可以从Table API和SQL查询语句中来访问。
Catalog分类
在Flink中,Catalog可以分为4类:
GenericInMemoryCatalog、JdbcCatalog、HiveCatalog、用户自定义Catalog
1.GenericInMemoryCatalog
GenericInMemoryCatalog是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。
2.JdbcCatalog
JdbcCatalog使得用户可以将Flink通过JDBC协议连接到关系数据库。Postgres Catalog和MySQL Catalog是目前 JDBC Catalog仅有的两种实现。
3.HiveCatalog
HiveCatalog有两个用途:作为原Flink元数据的持久化存储,以及作为读写现有Hive元数据的接口。
Hive Metastore以小写形式存储所有元数据对象名称。而GenericInMemoryCatalog区分大小写。
4.用户自定义Catalog
Catalog是可扩展的,用户可以通过实现Catalog接口来开发自定义Catalog。 想要在SQL CLI中使用自定义 Catalog,用户除了需要实现自定义的Catalog 之外,还需要为这个Catalog实现对应的CatalogFactory接口。
CatalogFactory定义了一组属性,用于SQL CLI启动时配置Catalog。 这组属性集将传递给发现服务,在该服务中,服务会尝试将属性关联到CatalogFactory并初始化相应的Catalog 实例。
GenericInMemoryCatalog
基于内存实现的Catalog,所有元数据只在session的生命周期(一个Flink任务运行生命周期内)内可用。默认自动创建名为
default_catalog的内存Catalog,这个Catalog默认只有一个名为default_database的数据库。
JdbcCatalog
JdbcCatalog使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog和MySQL Catalog是目前仅有的两种JDBC Catalog实现,将元数据存储在数据库中。
这里以JdbcCatalog-MySQL使用为例。
注意:JdbcCatalog不支持建表,只是打通flink与mysql的连接,可以去读写mysql现有的库表。
下载JAR包及使用
下载:flink-connector-jdbc
下载:mysql-connector-j
上传JAR包到flink/lib下
cp ./flink-connector-jdbc-3.1.0-1.17.jar /usr/local/program/flink/libcp ./mysql-connector-j-8.0.33.jar /usr/local/program/flink/lib
重启操作
重启flink集群和sql-client
bin/start-cluster.shbin/sql-client.sh
创建Catalog
JdbcCatalog支持以下选项:
name:必需,Catalog名称default-database:连接到的默认数据库username: Postgres/MySQL帐户的用户名password:帐号密码base-url:数据库的jdbc url(不含数据库名)Postgres Catalog:是"jdbc:postgresql://<ip>:<端口>"MySQL Catalog:是"jdbc: mysql://<ip>:<端口>"
CREATE CATALOG jdbc_catalog WITH('type' = 'jdbc','default-database' = 'demo','username' = 'root','password' = '123456','base-url' = 'jdbc:mysql://node01:3306'
);
查看与使用Catalog
查看Catalog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| jdbc_catalog |
+-----------------+
2 rows in set
使用指定Catalog
Flink SQL> use catalog jdbc_catalog;
[INFO] Execute statement succeed.
查看当前的CATALOG
Flink SQL> SHOW CURRENT CATALOG;
+----------------------+
| current catalog name |
+----------------------+
| jdbc_catalog |
+----------------------+
1 row in set
操作数据库表
Flink SQL> show current database;
+-----------------------+
| current database name |
+-----------------------+
| demo |
+-----------------------+
1 row in setFlink SQL> show tables;
+------------+
| table name |
+------------+
| tb_user |
+------------+
1 row in setFlink SQL> select * from tb_user;
[INFO] Result retrieval cancelled.Flink SQL> insert into tb_user values(0,'java',20);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 9d78ec378ad635d291bd730ba86245d8
自动初始化catalog
进入SQL客户端自动初始化catalo,创建vim sql-client-init.sql初始化脚本
SET sql-client.execution.result-mode = 'tableau';CREATE CATALOG jdbc_catalog WITH('type' = 'jdbc','default-database' = 'demo','username' = 'root','password' = '123456','base-url' = 'jdbc:mysql://node01:3306'
);use catalog jdbc_catalog;
进入客户端时指定初始化文件
bin/sql-client.sh -i ./sql-client-init.sql
再查看catalog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| jdbc_catalog |
+-----------------+
2 rows in set
HiveCatalog
HiveCatalog有两个用途:
单纯作为 Flink元数据的持久化存储作为读写现有Hive元数据的接口
注意:Hive MetaStore以小写形式存储所有元数据对象名称。Hive Metastore以小写形式存储所有元对象名称,而 GenericInMemoryCatalog会区分大小写。
下载JAR包及使用
下载:flink-sql-connector-hive
下载:mysql-connector-j
上传jar包到flink的lib
cp ./flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar /usr/local/program/flink/lib/cp ./mysql-connector-j-8.0.33.jar /usr/local/program/flink/lib
重启操作
重启flink集群和sql-client
bin/start-cluster.shbin/sql-client.sh
hive metastore服务
启动外置的hive metastore服务
Hive metastore必须作为独立服务运行,因此,在Hive的hive-site.xml中添加配置
<property><name>hive.metastore.uris</name><value>thrift://node01:9083</value></property>
# 前台运行
hive --service metastore# 后台运行
hive --service metastore &
创建Catalog
创建Catalog参数说明
| 配置项 | 必需 | 默认值 | 类型 | 说明 |
|---|---|---|---|---|
| type | Yes | (none) | String | Catalog类型,创建HiveCatalog时必须设置为’hive’ |
| name | Yes | (none) | String | Catalog的唯一名称 |
| hive-conf-dir | No | (none) | String | 包含hive -site.xml的目录,需要Hadoop文件系统支持。如果没指定hdfs协议,则认为是本地文件系统。如果不指定该选项,则在类路径中搜索hive-site.xml |
| default-database | No | default | String | Hive Catalog使用的默认数据库 |
| hive-version | No | (none) | String | HiveCatalog能够自动检测正在使用的Hive版本。建议不要指定Hive版本,除非自动检测失败 |
| hadoop-conf-dir | No | (none) | String | Hadoop conf目录的路径。只支持本地文件系统路径。设置Hadoop conf的推荐方法是通过HADOOP_CONF_DIR环境变量。只有当环境变量不适合你时才使用该选项,例如,如果你想分别配置每个HiveCatalog |
CREATE CATALOG myhive WITH ('type' = 'hive','default-database' = 'default','hive-conf-dir' = '/usr/local/program/hive/conf'
);
查看与使用Catalog
查看Catalog
Flink SQL> SHOW CATALOGS;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| myhive |
+-----------------+
2 rows in set--查看当前的CATALOG
SHOW CURRENT CATALOG;
使用指定Catalog
Flink SQL> use catalog myhive;
[INFO] Execute statement succeed.
Flink与Hive中操作
Flink中查看
Flink SQL> SHOW DATABASES;
+---------------+
| database name |
+---------------+
| default |
+---------------+
1 row in set
操作Hive
# 创建数据库demo
hive (default)> create database demo;# 切换数据库
hive (default)> use demo;# 创建表tb_user
hive (demo)> create table tb_user(id int,name string, age int);# 插入数据
hive (demo)> insert into tb_user values(1,"test",22);
Flink中再次查看
Flink SQL> SHOW DATABASES;
+---------------+
| database name |
+---------------+
| default |
| demo |
+---------------+
2 rows in setFlink SQL> use demo;
[INFO] Execute statement succeed.Flink SQL> show tables;
+------------+
| table name |
+------------+
| tb_user |
+------------+Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau';
[INFO] Execute statement succeed.Flink SQL> select * from tb_user;2023-07-09 21:58:25,620 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 1+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | test | 22 |
+----+-------------+--------------------------------+-------------+
Received a total of 1 row
在Flink中插入
Flink SQL> insert into tb_user values(2,'flink',22);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 9fe32af97cfb9e507ce84263cae65d23Flink SQL> select * from tb_user;2023-07-09 22:05:47,521 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 2+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | test | 22 |
| +I | 2 | flink | 22 |
+----+-------------+--------------------------------+-------------+
Received a total of 2 rows
Hive中查询
hive (demo)> select * from tb_user;
自动初始化catalog
进入SQL客户端自动初始化catalog,创建vim sql-client-init.sql初始化脚本
SET sql-client.execution.result-mode = 'tableau';CREATE CATALOG myhive WITH ('type' = 'hive','default-database' = 'default','hive-conf-dir' = '/usr/local/program/hive/conf'
);use catalog myhive ;
进入客户端时指定初始化文件
bin/sql-client.sh -i ./sql-client-init.sql
可以发现数据信息任然存在
Flink SQL> use catalog myhive;
[INFO] Execute statement succeed.Flink SQL> show databases;
+---------------+
| database name |
+---------------+
| default |
| demo |
+---------------+
2 rows in set
用户自定义Catalog
实现Catalog
用户可以通过实现Catalog接口来开发自定义 Catalog
public class CustomCatalog implements Catalog {public CustomCatalog(String catalogName, String defaultDatabase) {}@Overridepublic void open() {// 实现 Catalog 打开的逻辑}@Overridepublic void close() {// 实现 Catalog 关闭的逻辑}@Overridepublic List<String> listDatabases() {// 实现获取数据库列表的逻辑return null;}@Overridepublic CatalogDatabase getDatabase(String databaseName) {// 实现获取指定数据库的逻辑return null;}@Overridepublic boolean databaseExists(String databaseName) {// 实现检查数据库是否存在的逻辑return false;}@Overridepublic void createDatabase(String name, CatalogDatabase database, boolean ignoreIfExists) {// 实现创建数据库的逻辑}@Overridepublic void dropDatabase(String name, boolean ignoreIfNotExists, boolean cascade) {// 实现删除数据库的逻辑}@Overridepublic List<String> listTables(String databaseName) {// 实现获取数据库中表的列表的逻辑return null;}@Overridepublic CatalogBaseTable getTable(ObjectPath tablePath) {// 实现获取指定表的逻辑return null;}@Overridepublic boolean tableExists(ObjectPath tablePath) {// 实现检查表是否存在的逻辑return false;}@Overridepublic void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists) {// 实现创建表的逻辑}@Overridepublic void dropTable(ObjectPath tablePath, boolean ignoreIfNotExists) {// 实现删除表的逻辑}@Overridepublic List<String> listFunctions(String dbName) {// 实现获取数据库中函数的逻辑return null;}// 其他方法的实现
}
使用Catalog
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 注册自定义 CatalogtableEnv.registerCatalog("my_catalog", new CustomCatalog("my_catalog", "default"));// 使用自定义 CatalogtableEnv.useCatalog("my_catalog");// 执行 SQL 查询或 Table API 操作tableEnv.sqlQuery("SELECT * FROM my_table").execute().print();}
Catalog API
数据库操作
public static void main(String[] args) throws Exception {// 创建一个基于内存的Catalog实例GenericInMemoryCatalog catalog = new GenericInMemoryCatalog("myCatalog");catalog.open();// 创建数据库Map<String, String> properties = new HashMap<>();properties.put("key", "value");CatalogDatabase database = new CatalogDatabaseImpl(properties, "create comment");catalog.createDatabase("mydb", database, false);// 列出Catalog中的所有数据库System.out.println("列出Catalog中的所有数据库 = " + catalog.listDatabases());// 获取数据库CatalogDatabase createDb = catalog.getDatabase("mydb");System.out.println("获取数据库,comment = " + createDb.getComment() + " ,properties = " + createDb.getProperties());// 修改数据库Map<String, String> properties2 = new HashMap<>();properties2.put("key", "value1");catalog.alterDatabase("mydb", new CatalogDatabaseImpl(properties2, "alter comment"), false);// 获取数据库CatalogDatabase alterDb = catalog.getDatabase("mydb");System.out.println("获取数据库,comment = " + alterDb.getComment() + " ,properties = " + alterDb.getProperties());// 检查数据库是否存在System.out.println("检查数据库是否存在 = " + catalog.databaseExists("mydb"));// 删除数据库catalog.dropDatabase("mydb", false);// 关闭 Catalogcatalog.close();}
列出Catalog中的所有数据库 = [default, mydb]
获取数据库,comment = create comment ,properties = {key=value}
获取数据库,comment = alter comment ,properties = {key=value1}
检查数据库是否存在 = true
表操作
// 创建表
catalog.createTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);// 删除表
catalog.dropTable(new ObjectPath("mydb", "mytable"), false);// 修改表
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);// 重命名表
catalog.renameTable(new ObjectPath("mydb", "mytable"), "my_new_table");// 获取表
catalog.getTable("mytable");// 检查表是否存在
catalog.tableExists("mytable");// 列出数据库中的所有表
catalog.listTables("mydb");视图操作
// 创建视图
catalog.createTable(new ObjectPath("mydb", "myview"), new CatalogViewImpl(...), false);// 删除视图
catalog.dropTable(new ObjectPath("mydb", "myview"), false);// 修改视图
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogViewImpl(...), false);// 重命名视图
catalog.renameTable(new ObjectPath("mydb", "myview"), "my_new_view", false);// 获取视图
catalog.getTable("myview");// 检查视图是否存在
catalog.tableExists("mytable");// 列出数据库中的所有视图
catalog.listViews("mydb");分区操作
// 创建分区
catalog.createPartition(new ObjectPath("mydb", "mytable"),new CatalogPartitionSpec(...),new CatalogPartitionImpl(...),false);// 删除分区
catalog.dropPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...), false);// 修改分区
catalog.alterPartition(new ObjectPath("mydb", "mytable"),new CatalogPartitionSpec(...),new CatalogPartitionImpl(...),false);// 获取分区
catalog.getPartition(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));// 检查分区是否存在
catalog.partitionExists(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));// 列出表的所有分区
catalog.listPartitions(new ObjectPath("mydb", "mytable"));// 根据给定的分区规范列出表的分区
catalog.listPartitions(new ObjectPath("mydb", "mytable"), new CatalogPartitionSpec(...));// 根据表达式过滤器列出表的分区
catalog.listPartitions(new ObjectPath("mydb", "mytable"), Arrays.asList(epr1, ...));函数操作
// 创建函数
catalog.createFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);// 删除函数
catalog.dropFunction(new ObjectPath("mydb", "myfunc"), false);// 修改函数
catalog.alterFunction(new ObjectPath("mydb", "myfunc"), new CatalogFunctionImpl(...), false);// 获取函数
catalog.getFunction("myfunc");// 检查函数是否存在
catalog.functionExists("myfunc");// 列出数据库中的所有函数
catalog.listFunctions("mydb");相关文章:

Flink之Catalog
Catalog Catalog概述Catalog分类 GenericInMemoryCatalogJdbcCatalog下载JAR包及使用重启操作创建Catalog查看与使用Catalog自动初始化catalog HiveCatalog下载JAR包及使用重启操作hive metastore服务创建Catalog查看与使用CatalogFlink与Hive中操作自动初始化catalog 用户自定…...

计算机网络——物理层-传输方式(串行传输、并行传输,同步传输、异步传输,单工、半双工和全双工通信)
目录 串行传输和并行传输 同步传输和异步传输 单工、半双工和全双工通信 串行传输和并行传输 串行传输是指数据是一个比特一个比特依次发送的。因此在发送端和接收端之间,只需要一条数据传输线路即可。 并行传输是指一次发送n个比特,而不是一个比特&…...
男科医院服务预约小程序的作用是什么
医院的需求度从来都很高,随着技术发展,不少科目随之衍生出新的医院的,比如男科医院、妇科医院等,这使得目标群体更加精准,同时也赋能用户可以快速享受到服务。 当然相应的男科医院在实际经营中也面临痛点:…...
有没有实时检测微信聊天图片的软件,只要微信收到了有二维码的图片就把它提取出来?
10-2 如果你有需要自动并且快速地把微信收到的二维码图片保存到指定文件夹的需求,那本文章非常适合你,本文章教你如何实现自动保存微信收到的二维码图片到你指定的文件夹中,助你快速扫码,比别人领先一步。 首先需要准备好的材料…...

core-site.xml,yarn-site.xml,hdfs-site.xml,mapred-site.xml配置
core-site.xml <?xml version"1.0" encoding"UTF-8"?> <?xml-stylesheet type"text/xsl" href"configuration.xsl"?> <!--Licensed under the Apache License, Version 2.0 (the "License");you may no…...
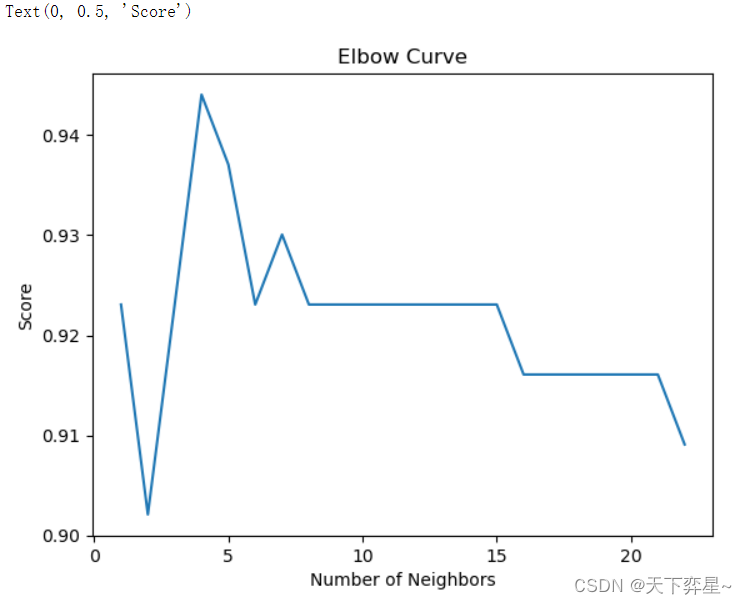
数据分析实战 | KNN算法——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型改进 十一、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://dow…...
JS实现数据结构与算法
队列 1、普通队列 利用数组push和shif 就可以简单实现 2、利用链表的方式实现队列 class MyQueue {constructor(){this.head nullthis.tail nullthis.length 0}add(value){let node {value}if(this.length 0){this.head nodethis.tail node}else{this.tail.next no…...

计算机毕业设计 基于SpringBoot的驾校管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
S7-1200PLC和SMART PLC开放式以太网通信(UDP双向通信)
S7-1200PLC的以太网通信UDP通信相关介绍还可以参考下面文章链接: 博途PLC开放式以太网通信TRCV_C指令应用编程(运动传感器UDP通信)-CSDN博客文章浏览阅读2.8k次。博途PLC开放式以太网通信TSENG_C指令应用,请参看下面的文章链接:博途PLC 1200/1500PLC开放式以太网通信TSEND_…...

作用域插槽slot-scope
一般用于组件封装,将使用props传入组件的数据再次调出来或者单纯调用组件中的数据。也可用于为组件某个部分自定义样式以及为某次使用组件自定义样式。 直接拿elementui的el-table举例: <template><el-table v-loading"loading&q…...

Redis学习笔记13:基于spring data redis及lua脚本list列表实现环形结构案例
工作过程中需要用到环形结构,确保环上的各个节点数据唯一,如果有新的不同数据到来,则将最早入环的数据移除,每次访问环形结构都自动刷新有效期;可以基于lua 的列表list结构来实现这一功能,lua脚本可以节省网…...

c# 将excel导入 sqlite
nuget 须要加载 EPPlus.Core ExcelDataReader ExcelDataReader.DataSet //需要引用的扩展 using ExcelDataReader; using ExcelPackage OfficeOpenXml.ExcelPackage; public static void CreateZhouPianChaTable(){string tbname "zhou_pian_cha1";//判断表是否存…...

KafkaConsumer 消费逻辑
版本:kafka-clients-2.0.1.jar 之前想写个插件修改 kafkaConsumer 消费者的逻辑,根据 header 过滤一些消息。于是需要了解一下 kafkaConsumer 具体是如何拉取消费消息的,确认在消费之前过滤掉消息是否会有影响。 下面是相关的源码࿰…...
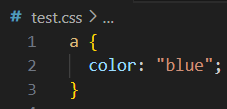
scss 实用教程
变量 $ 定义变量 $link-color: blue;变量名可以与css中的属性名和选择器名称相同 使用变量 a {color: $link_color; }$highlight-border: 1px solid $link_color;中划线和下划线相互兼容,即中划线声明的变量可以使用下划线的方式引用,反之亦然。 $li…...
NO.304 二维区域和检索 - 矩阵不可变
题目 给定一个二维矩阵 matrix,以下类型的多个请求: 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, col1) ,右下角 为 (row2, col2) 。 实现 NumMatrix 类: NumMatrix(int[][] matrix) 给定整数矩阵 …...

牛客---简单密码python
现在有一种密码变换算法。 九键手机键盘上的数字与字母的对应: 1--1, abc--2, def--3, ghi--4, jkl--5, mno--6, pqrs--7, tuv--8 wxyz--9, 0--0,把密码中出现的小写字母都变成九键键盘对应的数字,如:a 变成 2&#x…...
devops完整搭建教程(gitlab、jenkins、harbor、docker)
devops完整搭建教程(gitlab、jenkins、harbor、docker) 文章目录 devops完整搭建教程(gitlab、jenkins、harbor、docker)1.简介:2.工作流程:3.优缺点4.环境说明5.部署前准备工作5.1.所有主机永久关闭防火墙…...

页面上时间显示为数字 后端返回给前端 response java系统
有时候,在一个系统里,会看到,有的页面时间显示正常,有的页面时间显示成数字。像这样: "createTime": 1698706491000 这是因为出参没有做转换,直接将java.util.Date类型的数据返回给前端了。 返…...

idea怎么配置tomcat
要在IntelliJ IDEA中配置Tomcat,请按照以下步骤操作: 打开IntelliJ IDEA,点击File -> Settings(或者使用快捷键CtrlAltS)。 在设置窗口左侧导航栏中,选择Build, Execution, Deployment -> Applicati…...
GoLong的学习之路(二十三)进阶,语法之并发(go最重要的特点)(锁,sync包,原子操作)
这章是我并发系列中最后的一章。这章主要讲的是锁。但是也会讲上一章channl遗留下的一些没有讲到的内容。select关键字的用法,以及错误的一些channl用法。废话不多说。。。 文章目录 select多路复用通道错误示例并发安全和锁问题描述互斥锁读写互斥锁 syncsync.Wait…...

Cpp2IL:深入解析Unity IL2CPP逆向工程的利器
Cpp2IL:深入解析Unity IL2CPP逆向工程的利器 【免费下载链接】Cpp2IL Work-in-progress tool to reverse unitys IL2CPP toolchain. 项目地址: https://gitcode.com/gh_mirrors/cp/Cpp2IL 在Unity游戏开发中,IL2CPP编译技术将C#代码转换为原生二进…...

SQLite 3.53.0 发布,更新亮点多
世界上使用最多的数据库引擎 SQLite 发布了 3.53.0 版本。此次更新涵盖修复漏洞、新增功能与接口、改进查询规划等多方面,为开发者带来诸多便利。SQLite 简介SQLite 是一个用 C 语言编写的小型、快速且独立的 SQL 数据库引擎,其源代码属公共领域…...

云容笔谈·东方红颜影像生成系统环境配置详解:Anaconda虚拟环境管理
云容笔谈东方红颜影像生成系统环境配置详解:Anaconda虚拟环境管理 如果你刚接触AI图像生成,想在本地跑起来一个像“东方红颜”这样的模型,第一步往往不是写代码,而是配环境。我见过太多朋友,兴致勃勃地下载了模型代码…...

5个关键技巧:用InteractiveHtmlBom提升PCB设计效率300%
5个关键技巧:用InteractiveHtmlBom提升PCB设计效率300% 【免费下载链接】InteractiveHtmlBom Interactive HTML BOM generation plugin for KiCad, EasyEDA, Eagle, Fusion360 and Allegro PCB designer 项目地址: https://gitcode.com/gh_mirrors/in/Interactive…...

【CTFhub】web安全实战:备份文件泄露与源码保护策略
1. 备份文件泄露:Web安全的隐形炸弹 第一次参加CTF比赛时,我遇到一道看似简单的Web题,花了三小时都没解出来。直到偶然尝试访问/index.php.bak,才发现整个网站源码就躺在那儿等着我拿。这种"开门送分题"在真实网络攻防中…...

AudioSeal保姆级教程:从ffmpeg预处理到CUDA加速检测完整步骤
AudioSeal保姆级教程:从ffmpeg预处理到CUDA加速检测完整步骤 1. 项目概述 AudioSeal是Meta公司开源的一款专业级音频水印系统,专门用于AI生成音频的检测和溯源。这个工具就像给音频文件装上了一个"数字身份证",无论音频被如何编辑…...

突破数字音乐格式壁垒:NCM文件解密技术深度解析与实践指南
突破数字音乐格式壁垒:NCM文件解密技术深度解析与实践指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 技术背景与用户痛点 在数字音乐生态系统中,格式兼容性问题一直是困扰用户的隐形障碍。当用户下载了…...

AI 工作流防线失守:Flowise 漏洞被黑客大规模利用
网络安全研究人员发现,威胁攻击者已找到向Flowise低代码平台注入任意JavaScript的方法。该平台主要用于构建定制化大语言模型(LLM)和Agent系统。 Flowise : Build AI Agents And LLM Workflows Visually - OSTechNix 这一代码注入漏洞源于平…...

3个实用技巧让你成为网页资源嗅探专家:猫抓浏览器扩展深度解析
3个实用技巧让你成为网页资源嗅探专家:猫抓浏览器扩展深度解析 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法保存网页视频…...

毕业季求生指南:如何用智能工具搞定论文全流程?百考通AI深度体验
又到一年毕业季,图书馆的灯光彻夜长明,键盘敲击声与无声的焦虑交织。你是否也正在为堆砌如山的文献、难以降低的查重率、晦涩的数据分析,或是严苛的期刊投稿格式而焦头烂额?从开题到答辩,论文写作堪称一场对心力、脑力…...