Pytorch从零开始实战09
Pytorch从零开始实战——YOLOv5-Backbone模块实现
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——YOLOv5-Backbone模块实现
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的理解YOLOv5-C3模块。
第一步,导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
创建设备对象,并且查看GPU数量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count() # (device(type='cuda'), 2)
数据集
本次实验与上次实验仅仅是网络上的差异,其他并没有什么不同,本次数据集还是使用天气识别的数据集,分别有四个类别,cloudy、rain、shine、sunrise,不同的类别存放在不同的文件夹中,文件夹名是类别名。
使用pathlib查看类别
import pathlib
data_dir = './data/weather_photos/'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['cloudy', 'sunrise', 'shine', 'rain']
使用transforms对数据集进行统一处理,并且根据文件夹名映射对应标签
all_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/weather_photos/", transform=all_transforms)
total_data.class_to_idx # {'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
随机查看五张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(total_data)

根据8比2划分数据集和测试集,并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (901, 226)
模型选择
此次模型借用K同学所绘制的模型图
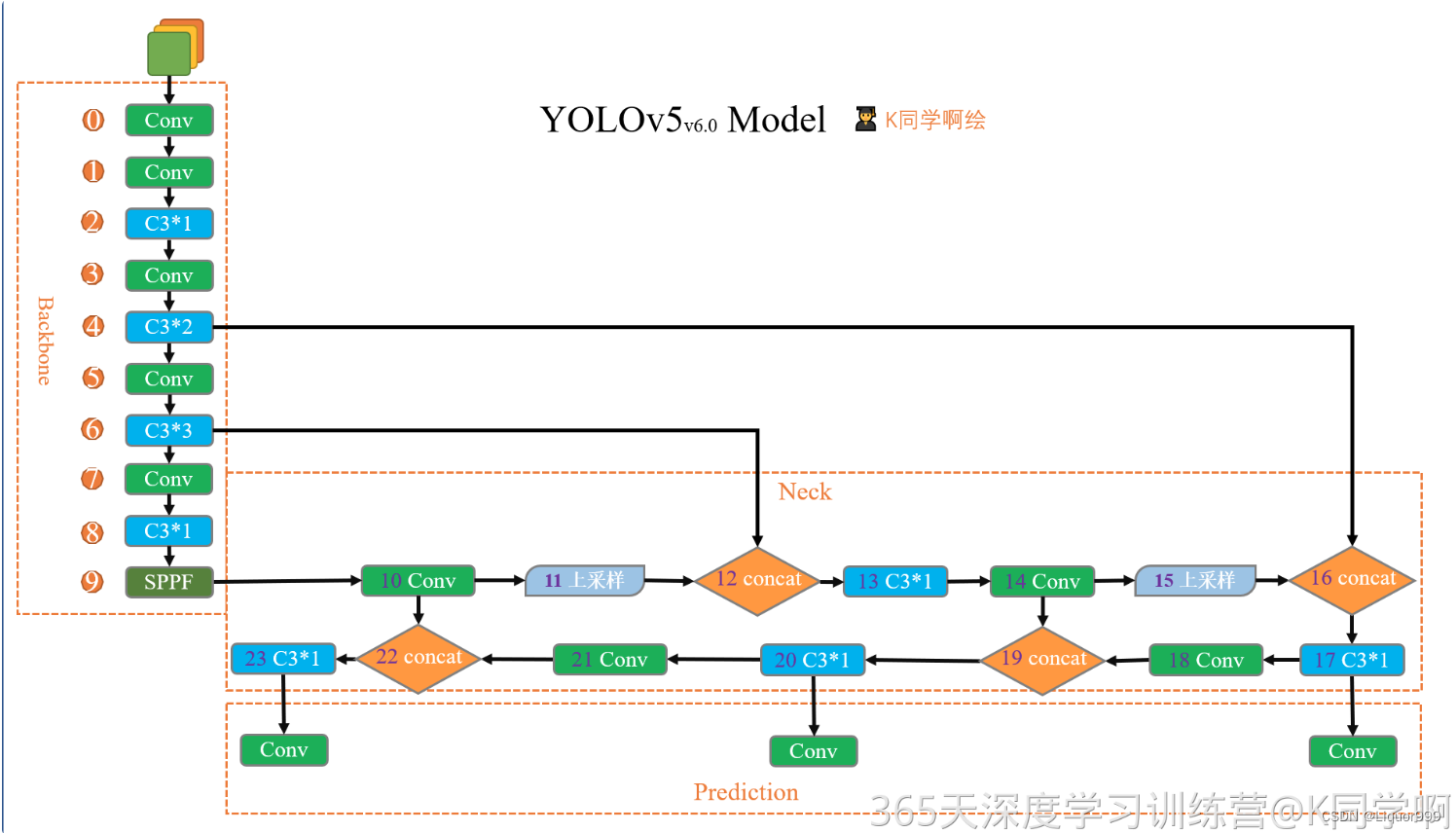
定义了一个autopad函数,用于确定卷积操作的填充,如果提供了p参数,则函数将使用提供的填充大小,否则函数中的填充计算将根据卷积核的大小k来确定,如果k是整数,那么将应用方形卷积核,填充大小将设置为k // 2,如果k是一个包含两个整数的列表,那么将应用矩形卷积核,填充大小将分别设置为列表中两个值的一半。
def autopad(k, p=None): if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] return p
定义自定义卷积层,在init方法中:创建了一个卷积层 self.conv,使用了 nn.Conv2d,该卷积层接受输入通道数 c1,输出通道数 c2,卷积核大小 k,步幅 s,填充 p,分组数 g,并且没有偏置项(bias=False)。创建了一个批归一化层 self.bn,用于规范化卷积层的输出。创建了一个激活函数层 self.act,其类型取决于 act 参数。如果 act 为 True,它将使用 SiLU(Sigmoid Linear Unit)激活函数;如果 act 为其他的 nn.Module 类,它将直接使用提供的激活函数;否则,它将使用恒等函数(nn.Identity)作为激活函数。其中,SiLU激活函数为SiLU(x) = x * sigmoid(x)。
class Conv(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))
定义Bottleneck类,这个模块的作用是实现标准的残差连接,以提高网络性能。在 init方法中:计算了中间隐藏通道数 c_,它是输出通道数 c2 乘以扩张因子 e 的整数部分。创建了两个 Conv 模块 self.cv1 和 self.cv2,分别用于进行卷积操作。self.cv1 使用 1x1 的卷积核,将输入特征图的通道数从 c1 变换为 c_。self.cv2 使用 3x3 的卷积核,将通道数从 c_ 变换为 c2。创建了一个布尔值 self.add,用于指示是否应用残差连接。self.add 为 True 的条件是 shortcut 为 True 且输入通道数 c1 等于输出通道数 c2。
在forward 方法中,首先,通过 self.cv1(x) 将输入 x 传递给第一个卷积层,然后通过self.cv2(self.cv1(x)) 将结果传递给第二个卷积层。最后,根据 self.add 的值来决定是否应用残差连接。如果 self.add 为 True,将输入 x 与第二个卷积层的输出相加,否则直接返回第二个卷积层的输出。这样模块在需要时应用残差连接,以保留和传递更多的信息。
class Bottleneck(nn.Module):def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
C3模块整体如上图所示,cv1 和 cv2 是两个独立的卷积操作,它们的输入通道数都是 c1,并经过相应的卷积操作后,输出通道数变为 c_。这是为了将输入特征映射进行降维和变换。cv3 接受 cv1 和 cv2 的输出,并且希望在这两部分特征上进行进一步的操作。为了能够将它们连接起来,cv3 的输入通道数必须匹配这两部分特征的输出通道数的总和,因此是 2 * c_。其中这个模块可以叠加n个Bottleneck块。
class C3(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
下面定义了SPPF模块,初始化SPPF模块时,c1 是输入通道数,c2 是输出通道数,k 是池化核的大小,默认为5。在初始化过程中,通过除以2来得到隐藏通道数 c_。同时,定义了两个卷积层 cv1 和 cv2,以及一个最大池化层 m。
forward 函数中,首先,输入通过卷积层 cv1 进行处理,然后通过最大池化层 m 进行两次池化,分别得到 y1 和 y2。最后,将原始输入 x、y1、y2 以及 y2 经过一次最大池化后的结果进行通道拼接,并通过卷积层 cv2 处理,得到最终输出。
这个模块实现了一种特殊的池化操作(空间金字塔池化),有助于提取输入特征的不同尺度信息。
class SPPF(nn.Module):def __init__(self, c1, c2, k=5): super().__init__()c_ = c1 // 2 self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
YOLOv5——backbone模块将上面模块组合起来,包括一系列卷积、C3、SPPF和全连接层
class YOLOv5_backbone(nn.Module):def __init__(self):super(YOLOv5_backbone, self).__init__()self.Conv_1 = Conv(3, 64, 3, 2, 2) self.Conv_2 = Conv(64, 128, 3, 2) self.C3_3 = C3(128,128)self.Conv_4 = Conv(128, 256, 3, 2) self.C3_5 = C3(256,256)self.Conv_6 = Conv(256, 512, 3, 2) self.C3_7 = C3(512,512)self.Conv_8 = Conv(512, 1024, 3, 2) self.C3_9 = C3(1024, 1024)self.SPPF = SPPF(1024, 1024, 5)self.classifier = nn.Sequential(nn.Linear(in_features=65536, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv_1(x)x = self.Conv_2(x)x = self.C3_3(x)x = self.Conv_4(x)x = self.C3_5(x)x = self.Conv_6(x)x = self.C3_7(x)x = self.Conv_8(x)x = self.C3_9(x)x = self.SPPF(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
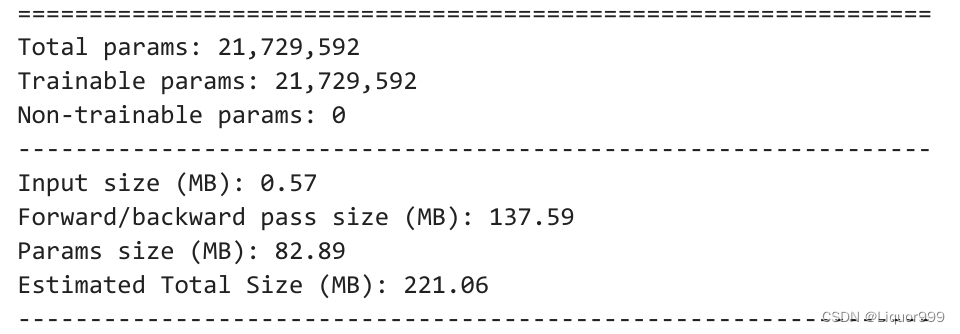
使用summary查看模型架构
from torchsummary import summary
summary(model, input_size=(3, 224, 224))
开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义学习率、损失函数、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
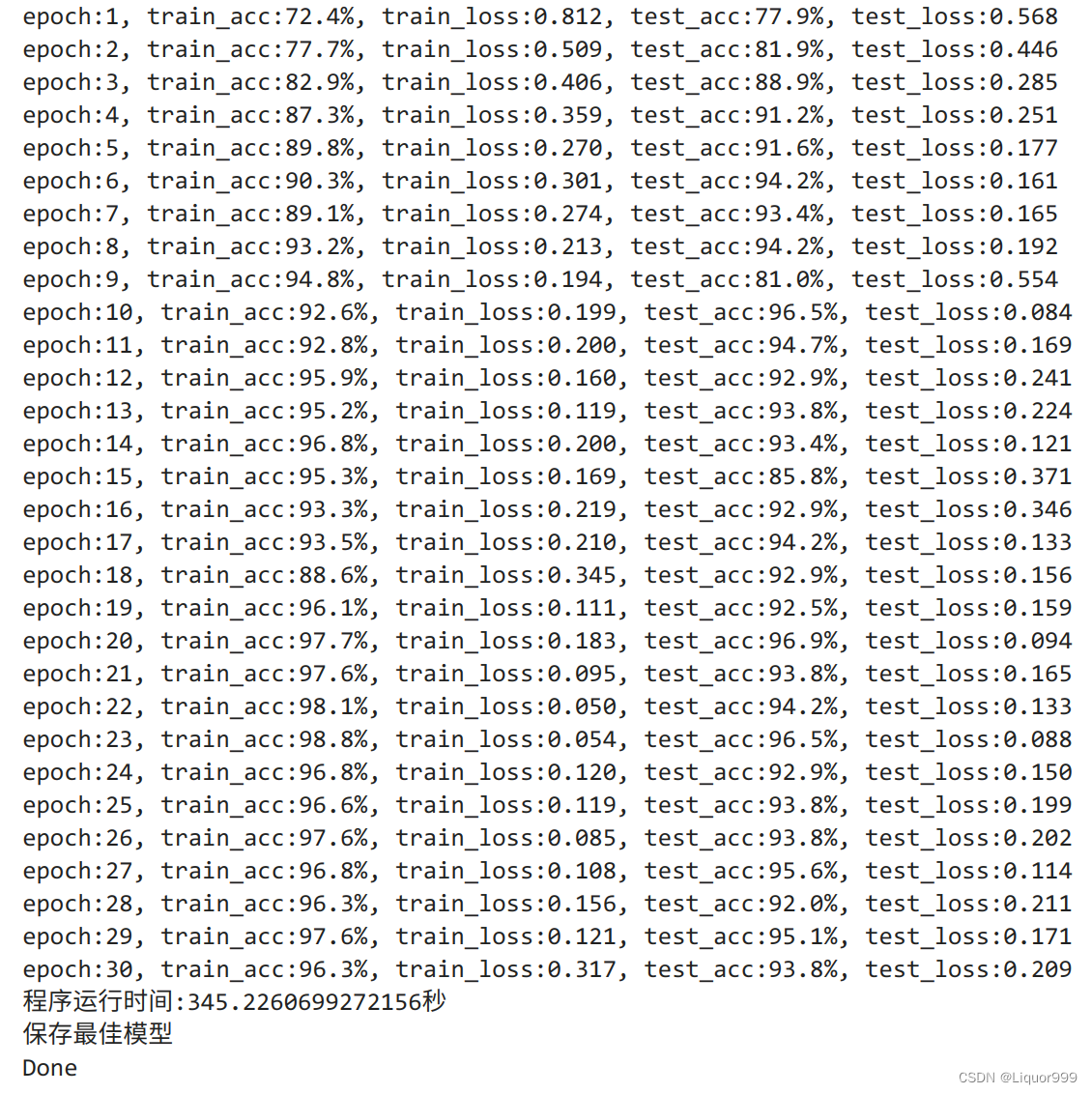
开始训练,epoch设置为30
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")
可视化
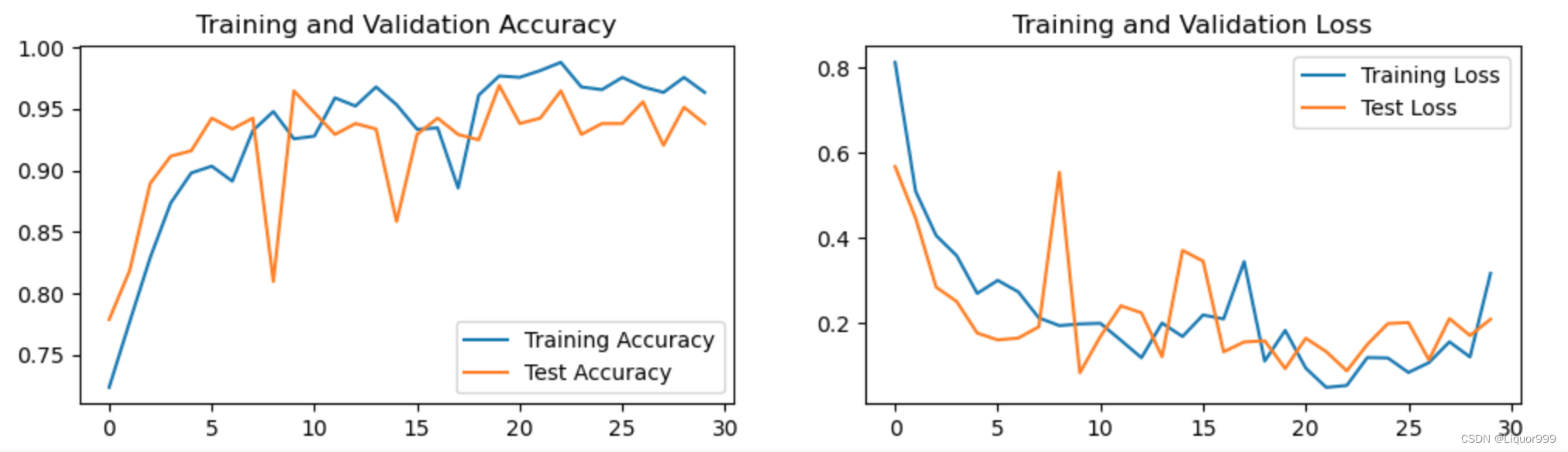
将训练与测试过程可视化
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义预测函数
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
预测一张图片
predict_one_image(image_path='./data/weather_photos/cloudy/cloudy10.jpg', model=model, transform=all_transforms, classes=classes) # 预测结果是:cloudy
查看一下最佳模型的epoch_test_acc, epoch_test_loss
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.9690265486725663, 0.09377550333737972)
总结
本次实验了解到模型由卷积、批归一化和残差连接组成,可以进一步提取和强化特征,同时又了解到SPPF层的实现,其用于捕获不同尺度的上下文信息。
相关文章:
Pytorch从零开始实战09
Pytorch从零开始实战——YOLOv5-Backbone模块实现 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——YOLOv5-Backbone模块实现环境准备数据集模型选择开始训练可视化模型预测总结 环境准备 本文基于Jupyter notebook,使用Python3.…...
Milvus Cloud ——Agent 的展望
Agent 的展望 目前,LLM Agent 大多是处于实验和概念验证的阶段,持续提升 Agent 的能力才能让它真正从科幻走向现实。当然,我们也可以看到,围绕 LLM Agent 的生态也已经开始逐渐丰富,大部分工作都可以归类到以下三个方面进行探索: Agent模型 AgentBench[4] 指出了不同的 L…...

EM@比例恒等式@分式恒等式
文章目录 比例恒等式(分式恒等式)分式等式链例 比例恒等式(分式恒等式) 设 a b c d \frac{a}{b}\frac{c}{d} badc(0)令这个比值为 k k k,则 a k b akb akb(0-1), c k d ckd ckd(0-2),以下恒等式在表达式有意义的情形下成立(例如分母不为0) 合比定理: a b b c d d \f…...

使用米联客FPGA开发板进行光口开发时遇到的问题总结
使用的开发板型号:米联客MA703FA, 实物图如下 FPGA型号为a35t 米联客提供的开发板资料中的FPGA型号为a100,所以要想使用开发板例程必须进行FPGA的重新选择。如下图 通过对开发板原理图的分析,例程代码不用做任何修改就可使用&am…...

【chat】 1:Ubuntu 20.04.3 编译安装moduo master分支
muduo 基于reactor反应堆模型的多线程C++网络库大佬的官方仓库有cpp17分支看了下cmakelist文件里面还是要依赖不少库,比如boost protobuf而且cpp17 似乎 是2021年的master 是2022更新的那么还是选择master吧。ubuntu版本 Ubuntu 20.04.3 root@k8s-master-2K4G:~# uname -a Lin…...
C#基于inpoutx64读写ECRAM硬件信息
inpoutx64.dll分享路径: 链接:https://pan.baidu.com/s/1rOt0xtt9EcsrFQtf7S91ag 提取码:7om1 1.InpOutManager: using System; using System.Collections.Generic; using System.Linq; using System.Runtime.InteropServi…...
图论13-最小生成树-Kruskal算法+Prim算法
文章目录 1 最小生成树2 最小生成树Kruskal算法的实现2.1 算法思想2.2 算法实现2.2.1 如果图不联通,直接返回空,该图没有mst2.2.2 获得图中的所有边,并且进行排序2.2.2.1 Edge类要实现Comparable接口,并重写compareTo方法 2.2.3 取…...
免费博客搭建笔记
title: 免费博客搭建笔记 tags: 博客搭建 本次是对自己在网上学习github搭建一个 👇个人免费静态网站的总结当然不是很完美👇 Bow to the new king iYANG (yangsongl1n.github.io) 接着我会从我的写笔记的个人习惯来逐步介绍如何搭建这个网站 1.写笔…...

网络运维Day10
文章目录 SHELL基础查看有哪些解释器使用usermod修改用户解释器BASH基本特性 shell脚本的设计与运行编写问世脚本脚本格式规范执行shell脚本方法一方法二实验 变量自定义变量环境变量位置变量案例 预定义变量 变量的扩展运用多种引号的区别双引号的应用单引号的应用反撇号或$()…...

@Cacheable 注解的 @CacheManager 示例
pom.xml 依赖包: <dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId></dependency><dependency><groupId>redis.clients</groupId><artifactId>jed…...

springboot二维码示例
pom.xml依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.16</version></dependency><dependency><groupId>com.google.zxing</groupId><artifactId>…...

nacos做服务配置和服务器发现
一、创建项目 1、创建一个spring-boot的项目 2、创建三个模块file、system、gateway模块 3、file和system分别配置启动信息,并且创建一个简单的控制器 server.port9000 spring.application.namefile server.servlet.context-path/file4、在根目录下引入依赖 <properties&g…...

KCC@广州与 TiDB 社区联手—广州开源盛宴
10月21日,KCC广州与 TiDB 社区联手,在海珠区保利中悦广场 29 楼召开了一次难忘的开源盛宴。这不仅仅是 KCC广州的又一次线下见面,更代表着与 TiDB 社区及广州技术社区的首次深度合作。 活动的策划与组织由 KCC广州负责人 - 惠世冀、PingCAP 的…...
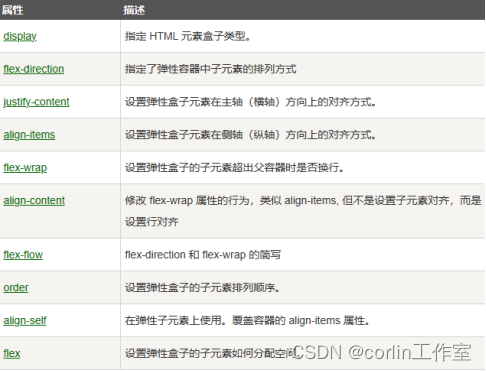
CSS3 分页、框大小、弹性盒子
一、CSS3分页: 网站有很多个页面,需要使用分页来为每个页面做导航。示例: <style> ul.pagination { display: inline-block; padding: 0; margin: 0; } ul.pagination li {display: inline;} ul.pagination li a { color: black; f…...
函数,以提取指定范围内的逐日的二氧化氮平均浓度为例)
GEE问题——GEE中循环的使用map()函数,以提取指定范围内的逐日的二氧化氮平均浓度为例
问题: 我有一个简单的代码,可以帮助计算德克萨斯州每个县的对流层二氧化氮平均浓度。目前,我可以将其导出为我指定的任何日期范围的 csv 表,但我想 1) 提取每天平均值,例如 3 个月(2020 年 3 月至 2020 年 5 月,约 90 天)--手动多次运行肯定不是办法,而且我的编码技…...

短信验证码实现(阿里云)
如果实现短信验证,上教程,这里用的阿里云短信服务 短信服务 (aliyun.com) 进入短信服务后开通就行,可以体验100条免费,刚好测试用 这里由自定义和专用,测试的话就选择专用吧,自定义要审核, Se…...

如何对element弹窗进行二次封装
方式一使用$refs 个人比较喜欢用这种的 通过$refs打开的同时 还能给弹窗组件传参 一些框架使用的也是这种方式 父组件 <template><div><el-button type"text" click"handleDialogOpen">打开嵌套表单的 Dialog</el-button><Dia…...
【微服务专题】手写模拟SpringBoot
目录 前言阅读对象阅读导航前置知识笔记正文一、工程项目准备1.1 新建项目1.1 pom.xml1.2 业务模拟 二、模拟SpringBoot启动:好戏开场2.1 启动配置类2.1.1 shen-base-springboot新增2.1.2 shen-example客户端新增启动类 三、run方法的实现3.1 步骤一:启动…...
七个优秀微服务跟踪工具
随着微服务架构复杂性的增加,在问题出现时确定问题的根本原因变得更具挑战性。日志和指标为我们提供了有用的信息,但并不能提供系统的完整概况。这就是跟踪的用武之地。通过跟踪,开发人员可以监控微服务之间的请求进度,从而使他们…...

redis 问题解决 1
1.1 常见考点 1、Redis 为何这么快? Redis 是一款基于内存的数据结构存储系统,它之所以能够提供非常快的读写性能,主要是因为以下几个方面的原因: 基于内存存储:Redis 所有的数据都存储在内存中,而内存的访问速度比磁盘要快得多。因此,Redis 可以提供非常快的读写性能…...

重构浏览器书签管理哲学:Neat Bookmarks的树形思维与信息架构实践
重构浏览器书签管理哲学:Neat Bookmarks的树形思维与信息架构实践 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 当数字书签堆积如山&…...

深入理解计算机系统——浮点数
目录 一、为什么需要浮点数? 1.1 二进制小数的局限 1.2 浮点数的思想 二、IEEE 754 浮点数标准 2.1 表示形式 2.2 两种精度 2.3 编码的三种情况 三、浮点数的舍入(Rounding) 3.1 为什么要舍入? 3.2 四种舍入模式&#x…...
)
OKNet实战:用63x63超大卷积核搞定图像去雾/去雪/去模糊(附PyTorch配置指南)
OKNet实战:用63x63超大卷积核搞定图像去雾/去雪/去模糊(附PyTorch配置指南) 当你在处理一张被雾气笼罩的风景照,或是被雪花覆盖的街景,亦或是因手抖而模糊的人物特写时,是否曾想过AI如何让这些图像重获新生…...


CentOS7.9下Ollama安装避坑指南:从Python3.8升级到Docker部署全流程
CentOS7.9下Ollama部署实战:从Python升级到容器化避坑全记录 当你在生产环境遇到CentOS7.9这样的"老将"系统时,部署现代AI工具链往往像在古董电脑上跑最新游戏——各种兼容性问题接踵而至。最近我在为一家金融机构升级他们的机器学习平台时就…...

如何快速将设计稿转换为动画:AEUX终极动效制作指南
如何快速将设计稿转换为动画:AEUX终极动效制作指南 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX 还在为Figma到After Effects的转换烦恼吗?AEUX设计稿转换插件…...

终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南
终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南 【免费下载链接】walkway An easy way to animate SVG elements. 项目地址: https://gitcode.com/gh_mirrors/wa/walkway Walkway.js是一款轻量级的SVG动画库,让开发者能够轻松为…...

碧蓝航线自动化终极指南:3大核心功能+5步部署解放你的游戏时间
碧蓝航线自动化终极指南:3大核心功能5步部署解放你的游戏时间 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你…...
---GUI-MCP 整体架构挚)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---GUI-MCP 整体架构挚
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...

RGB LCD显示屏残存显示问题
📊 ESP32-S3 RGB接口LCD(ST7701S等)显示异常问题全总结 结合你遇到的烧录后残影、断电恢复、花屏/竖条等现象,我把这类问题的根因分类、排查逻辑、避坑方案、应急解决做了完整梳理,方便你以后快速定位和根治。一、 核…...