Flink(四)【DataStream API - Source算子】
前言
今天开始学习 DataStream 的 API ,这一块是 Flink 的核心部分,我们不去学习 DataSet 的 API 了,因为从 Flink 12 开始已经实现了流批一体, DataSet 已然是被抛弃了。忘记提了,从这里开始,我开始换用 Flink 17 了。
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成:
- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)
其中,获取环境和触发执行,都可以认为是针对执行环境的操作。
1、执行环境(Execution Environment)
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
1.1、创建执行环境
1、getExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();这是最简单高效的一种方式了,它可以自己根据环境的信息去判断。
我们也可以给它传递一个 Configuration 对象作为参数,这样我们可以设置运行时的一些配置,比如端口号等。
Configuration conf = new Configuration();conf.set(RestOptions.BIND_PORT,"8082");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
这里我们设置端口号为 8082 ,这样我们在默认的 8081 端口就无法访问 Web UI 了,只能通过 8082 端口来访问。
2、createLocalEnvironment
这种方式了解即可,它是用来创建一个本地的模拟集群环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();3、createRemoteEnvironment
这种方式同样了解即可,因为配置起来比较繁琐,我们既然是在集群下运行了,一般都是把代码打包成 jar 去执行,不会把配置信息写死的。
StreamExecutionEnvironment.createRemoteEnvironment("hadoop102",8081,"/opt/module/xxx.jar");1.2、执行模式(Execution Mode)
默认的执行模式就是 Streaming 模式。
1、batch 模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);2、streaming 模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
3、自动模式
前两种方式都过于死板,打包后的程序都不能修改,所以我们一般不明确指定执行模式到底是 流处理 还是 批处理,而是执行时通过命令行来配置:
bin/flink run -Dexecution.runtime-mode=BATCH ...1.3、触发程序执行
默认执行方式
Flink 是事件驱动型的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”(lazy execution)。所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)但是这个返回对象我们一般不怎么用,而且这个返回结果在程序运行完才会返回。
默认 env.execute() 触发生成一个 Flink Job。
env.execute();异步执行方式
极少情况下,可能我们一套代码中有两部分处理逻辑,比如 env.execute() 之后,又进行了一些操作然后再进行 execute() ,但在 main 线程中是会阻塞的,这就需要启动一个异步的 execute() 方法。
executeAsync() 会触发执行多个 Flink Job。
env.execute();// 其他处理代码...env.executeAsync();2、源算子(Source)
2.1、准备工作
写一个 Java Bean,注意类的属性序列化问题(这里我们的属性都是一些基本类型,Flink 是支持对它进行序列化的),Flink 会把这样的类作为一种特殊的 POJO 数据类型来对待,方便数据的解析和序列化。
import java.util.Objects;public class WaterSensor {public String id;public Long ts;public Integer vc;public WaterSensor(){}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) && Objects.equals(ts, that.ts) && Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}
}
2.2、从集合中读取
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;public class CollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();WaterSensor sensor1 = new WaterSensor("1",1L,1);WaterSensor sensor2 = new WaterSensor("2",2L,2);// 从集合读取数据DataStreamSource<WaterSensor> source = env
// .fromElements(sensor1,sensor2); //直接填写元素.fromCollection(Arrays.asList(sensor1,sensor2)); // 从集合读取数据source.print();env.execute();}
}
2.3、从文件中读取
读取文件,需要添加文件连接器依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency>新的 Source 读取语法:
env.fromSource(Source的实现类,Watermark,source名称)示例:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FileSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从文件中读取FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/words.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"fileSource").print();env.execute();}
}
2.4、从 Socket 读取数据
这种方式同样常用于模拟流数据,稳定性较差,通常用来测试。
DataStream<String> stream = env.socketTextStream("localhost", 9999);
2.5、从 Kafka 读取数据
实际开发也是用 Kafka 来读取的,我们的实时流数据都是由 Kafka 来做收集和传输的。
导入依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version>
</dependency>
案例
package com.lyh.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class KafkaSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 从 Kafka 读取KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092") //指定kafka地址和端口.setGroupId("lyh") // 指定消费者组id.setTopics("like") // 指定消费的topic,可以是多个用List<String>.setValueOnlyDeserializer(new SimpleStringSchema()) // 指定反序列化器 因为kafka是生产者 flink作为消费者要反序列化.setStartingOffsets(OffsetsInitializer.latest()) // 指定flink消费kafka的策略.build();env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"kafkaSource").print();env.execute();}/** kafka 消费者的参数: * auto.reset.offsets:* earliest: 如果有offset,从offset继续消费;如果没有 就从 最早 消费* latest : 如果有offset,从offset继续消费;如果没有 就从 最新 消费* flink 的 kafkaSource offset消费者策略: offsetsInitializer,默认是 earliest* earliest: 一定从 最早 消费 (不管有没有offset) * latest : 一定从 最新 消费 (不管有没有offset)*/
}
启动 Kafka 集群(需要先启动 zookeeper)
使用命令行生产者生产消息:
kafka-console-producer.sh --broker-list hadoop102:9092 --topic like2.6、从数据生成器读取数据
导入依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>${flink.version}</version></dependency>案例
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.datagen.DataGenerator;public class DataGeneratorDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);/*** 数据生成器参数说明:* 1. GeneratorFunction接口,需要重写 map 方法,输入类型必须是Long* 2. Long类型, 自动生成的数字序列(从0自增)的最大值* 3. 限速策略, 比如每秒生成几条数据* 4. 返回的数据类型*/DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "number: " + value;}},10L,RateLimiterStrategy.perSecond(1),Types.STRING);env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(),"dataGenerator").print();env.execute();}
}
运行效果:
number: 0
number: 1
number: 2
number: 3
number: 4
number: 5
number: 6
number: 7
number: 8
number: 9Process finished with exit code 0
如果想达到无界流的效果,直接给数据生成器的第二个参数传一个 Long.MAX_VALUE。
假如我们的第二个参数设置为100(意味着从0自增到99)。如果并行度为3,那么第二个线程将从100的1/3处(即34)开始累加,第三个线程将从100的2/3(即67)开始累加。
Flink 支持的数据类型
这里主要说泛型类型和类型提示,别的类型比如我们基本的数据类型及其包装类型和String(引用类型)、基本类型数组、对象数组、复合数据类型(Flink 内置的 Tuple0~Tuple25),辅助类型Option、Either、List、Map等,还有 POJO 类型,Flink 的 TypeInfomation 类型都已经为我们封装好了,它为每个数据类型生成了特定的序列化、反序列化器和比较器。
泛型
Flink 支持所有的 Java 类和 Scala 类。但如果没有按照 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 对 POJO 类型的要求如下:
⚫ 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
⚫ 类有一个公共的无参构造方法;
⚫ 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。所以我们上面的 WaterSensor,就是我们创建的符合 Flink POJO 定义的数据类型。
类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的,它是不可靠的;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的“类型提示”(type hints)。回忆一下之前的 word count 流处理程序,我们在将 String 类型的每个词转换成(word,count)二元组后,就明确地用 returns 指定了返回的类型。因为对于 map 里传入的 Lambda 表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
下面给出两种写法:
DataStreamSource<String> lineDS = env.socketTextStream("hadoop102",9999);// 3. flatMap 打散数据 返回元组SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}})//.returns(Types.TUPLE(Types.STRING, Types.LONG));.returns(new TypeHint<Tuple2<String, Long>>() {}); //也可以这样写
这是一种比较简单的场景,二元组的两个元素都是基本数据类型。那如果元组中的一个元素又有泛型,该怎么处理呢?
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型。
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
相关文章:
【DataStream API - Source算子】)
Flink(四)【DataStream API - Source算子】
前言 今天开始学习 DataStream 的 API ,这一块是 Flink 的核心部分,我们不去学习 DataSet 的 API 了,因为从 Flink 12 开始已经实现了流批一体, DataSet 已然是被抛弃了。忘记提了,从这里开始,我开始换用 F…...
GIS入门,xyz地图瓦片是什么,xyz数据格式详解,如何发布离线XYZ瓦片到nginx或者tomcat中
XYZ介绍 XYZ瓦片是一种在线地图数据格式,由goole公司开发。 与其他瓦片地图类似,XYZ瓦片将地图数据分解为一系列小的图像块,以提高地图显示效率和性能。 XYZ瓦片提供了一种开放的地图平台,使开发者可以轻松地将地图集成到自己的应用程序中。同时,它还提供了高分辨率图像和…...
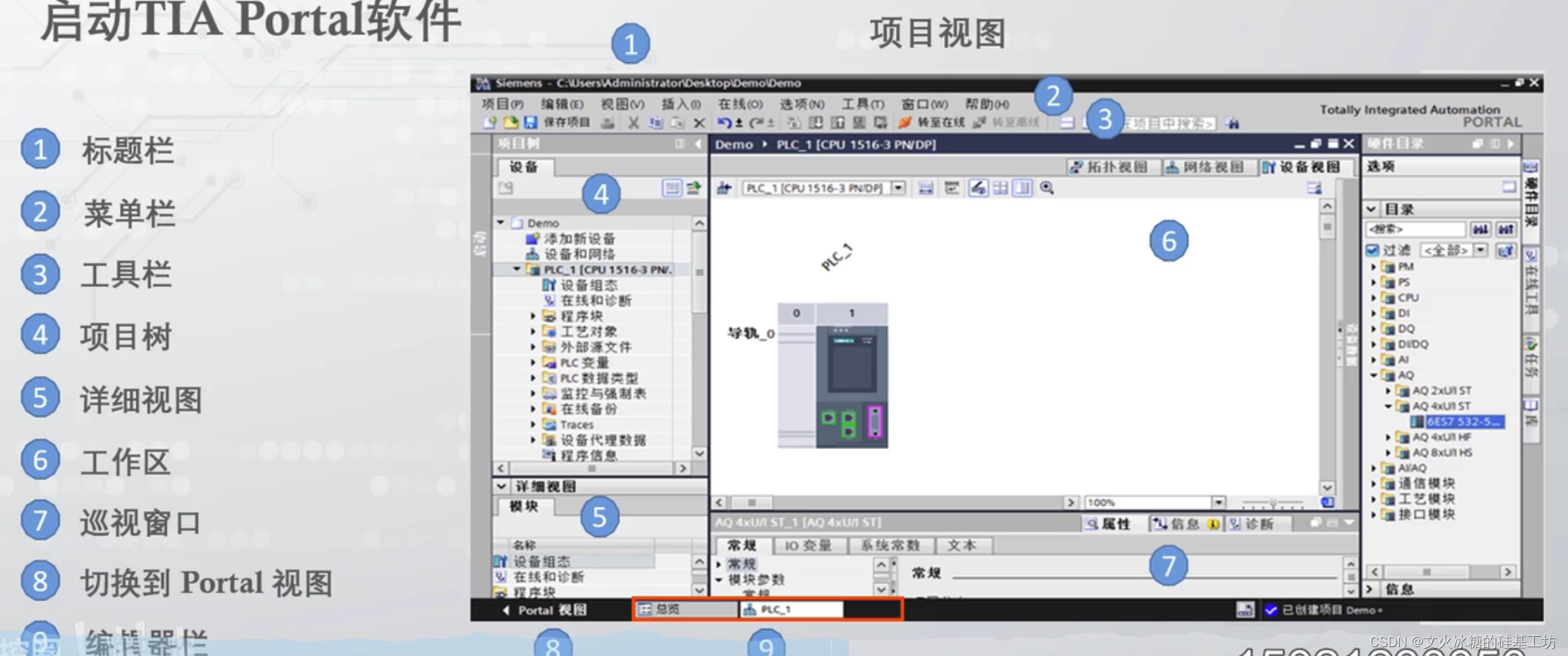
[工业自动化-14]:西门子S7-15xxx编程 - 软件编程 - STEP7 TIA博途是全集成自动化软件TIA portal快速入门
目录 一、TIA博途是全集成自动化软件TIA portal快速入门 1.1 简介 1.2 软件常用界面 1.3 软件安装的电脑硬件要求 1.4 入口 1.5 主界面 二、PLC软件编程包含哪些内容 2.1 概述 2.2 电机运动控制 一、TIA博途是全集成自动化软件TIA portal快速入门 1.1 简介 Siemens …...

【教3妹学编程-算法题】Range 模块
3妹:哈哈哈哈哈哈哈哈 2哥 : 3妹看什么呢,笑的这么开森 3妹:2哥你快来看啊,成都欢乐谷的NPC模仿“唐僧”, 太搞笑了。 2哥 : 哦这个我也看到了,真的是唯妙唯肖,不能说像,只能说一模一…...

SpringBoot+MybatisPlus Restful示例
增删改查,分页 CREATE TABLE tbl_book ( id int NOT NULL AUTO_INCREMENT, type varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, desc_ription varchar(255) CHAR…...

【数据结构】树与二叉树(十一):二叉树的层次遍历(算法LevelOrder)
文章目录 5.2.1 二叉树二叉树性质引理5.1:二叉树中层数为i的结点至多有 2 i 2^i 2i个,其中 i ≥ 0 i \geq 0 i≥0。引理5.2:高度为k的二叉树中至多有 2 k 1 − 1 2^{k1}-1 2k1−1个结点,其中 k ≥ 0 k \geq 0 k≥0。引理5.3&…...
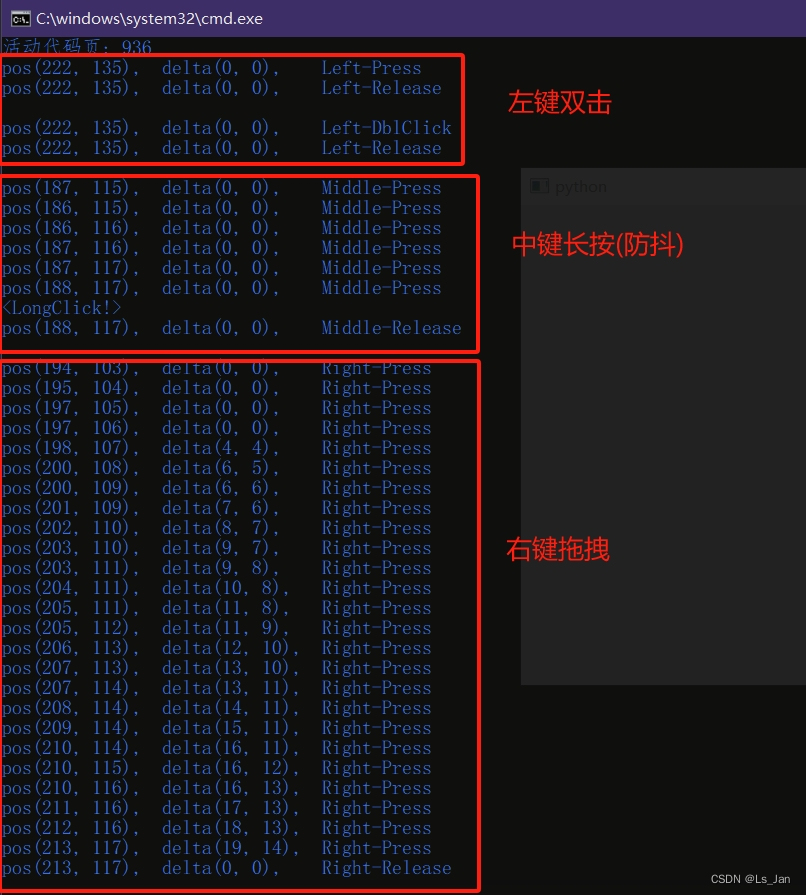
【PyQt】(自制类)处理鼠标点击逻辑
写了个自认为还算不错的类,用于简化mousePressEvent、mouseMoveEvent和mouseReleaseEvent中的鼠标信息。 功能有以下几点: 鼠标当前状态,包括鼠标左/中/右键和单击/双击/抬起鼠标防抖(仅超出一定程度时才判断鼠标发生了移动),灵…...
JAVA IDEA 下载
超简单步骤一: IntelliJ IDEA 官方下载链接 点击以上链接进入下图,点击下载 继续点下载,然后等待下载完后打开安装包即可 步骤二: 打开下好的安装包,点击Browse...我们把它下载到自己喜欢的地方(主要是别占…...

DevOps简介
DevOps简介 1、DevOps的起源2、什么是DevOps3、DevOps的发展现状4、DevOps与虚拟化、容器 1、DevOps的起源 上个世纪40年代,世界上第一台计算机诞生。计算机离不开程序(Program)驱动,而负责编写程序的人,被称为程序员&…...

体验前所未有的显示器管理体验:BetterDisplay Pro Mac
在现代的数字化时代,显示器是我们日常生活和工作中不可或缺的一部分。从笔记本电脑到台式机,从平板电脑到手机,几乎所有的电子设备都配备了显示器。然而,对于专业人士和从事设计行业的人来说,仅仅依靠系统自带的显示器…...

python用pyinstaller打包exe,去掉黑窗口
使用Python编写程序将Python脚本打包成可执行文件(EXE),但是会有一个命令框产生,很烦,所以,去掉这个框 1,安装pyinstaller pip install pyinstaller2,打包产生cmd命令框 pyinstaller --onefi…...
如何关闭Windows Defender(亲测可行!!非常简单)
一、背景 Windows Defender(简称WD)真的太讨厌了,经常给你报你下载的文件是病毒,且不说真的是不是病毒,它都不询问直接删。 另外聚资料显示WD还会不合时宜地执行扫描导致系统变慢(不会在合适的、空闲的时…...

【objectarx.net】创建多重引线
创建多重引线...

【objectarx.net】创建组,列出所有组,查找实体所在的组
创建组,列出所有组...

Llama2通过llama.cpp模型量化 WindowsLinux本地部署
Llama2通过llama.cpp模型量化 Windows&Linux本地部署 什么是LLaMA 1 and 2 LLaMA,它是一组基础语言模型,参数范围从7B到65B。在数万亿的tokens上训练的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需求…...
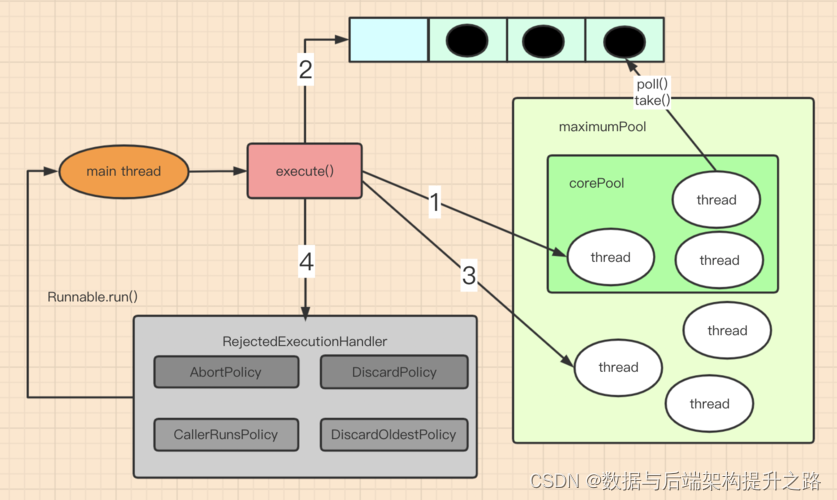
Coding面试题之手写线程池
原理图 JDK线程池原理 实现代码 1.线程类(PoolThread) 这个类用于执行任务队列中的任务。 public class PoolThread extends Thread {private final Queue<Runnable> taskQueue;private boolean isStopped false;private long lastTaskTime …...

【objectarx.net】删除零长度曲线和获取零长度曲线的数量
删除零长度曲线和获取零长度曲线的数量...
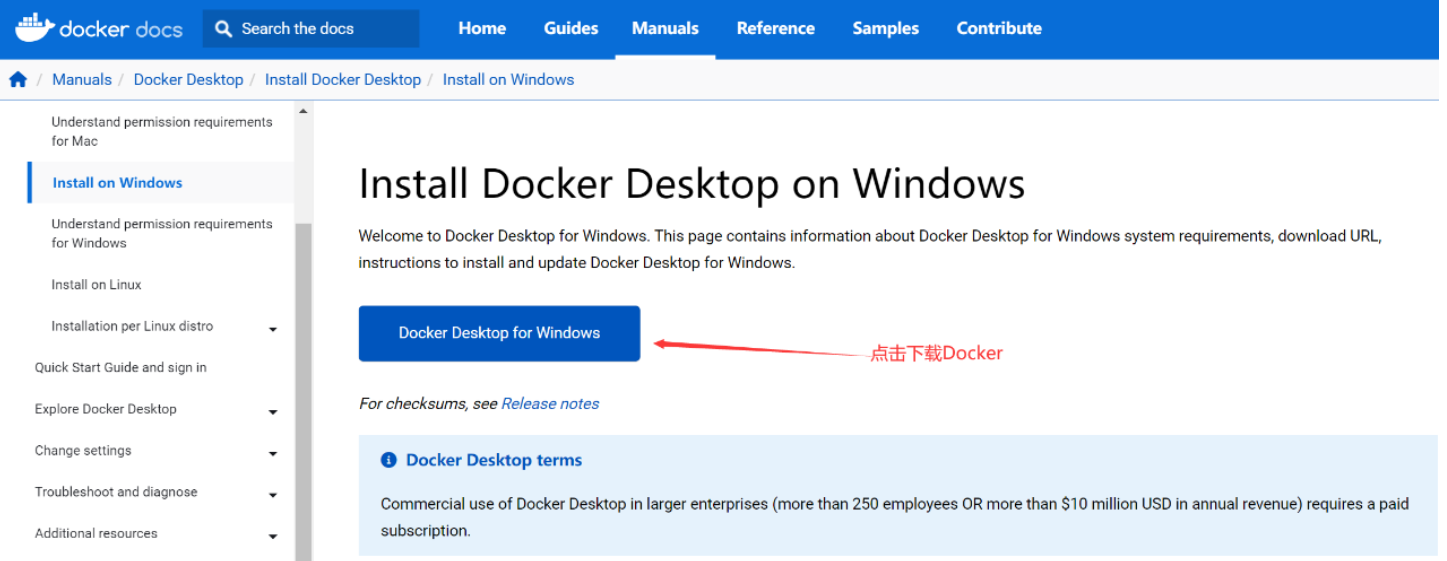
Win11专业版安装Docker Desktop,并支持映射主机的gpu
一、Windows环境下安装 Docker 必须满足: 1. 64位Windows 11 Pro(专业版和企业版都可以) 2. Microsoft Hyper-V,Hyper-V是微软的虚拟机,在win11上是自带的,我们只需要启动就可以了 二、下载Docker Desktop安装包 方式一:进入官网下载 https://docs.docker.com/desktop…...

Mac代码文本编辑器Sublime Text 4
Sublime Text 4 for Mac拥有快速响应的功能,可以快速加载文件和执行命令,并提供多种语言支持,包括C 、Java、Python、HTML、CSS等。此外,该编辑器还支持LaTeX、Markdown、JSON、XML等技术领域。 Sublime Text 4 for Mac的插件丰富…...

MATLAB中plot函数用法
目录 语法 说明 向量和矩阵数据 表数据 其他选项 示例 创建线图 绘制多个线条 根据矩阵创建线图 指定线型 指定线型、颜色和标记 在特定的数据点显示标记 指定线宽、标记大小和标记颜色 添加标题和轴标签 绘制持续时间并指定刻度格式 基于表绘制坐标 在一个轴…...

【AI Agent实战】OpenClaw Skill 技能系统详解:从 Function Calling 到 MCP 到 Skill 的完整演进
关键词:OpenClaw Skill、AI Agent技能、MCP协议、Function Calling、AI工作流一、为什么装完 OpenClaw 还是感觉"没用" 安装完 OpenClaw 之后,很多人反馈一个共同问题:跟直接用 ChatGPT 感觉差不多,没看到明显差异。 原…...
(一)弛)
数据摄取构建模块简介(预览版)(一)弛
一、语言特性:Java 26 与模式匹配进化 1.1 Java 26 语言级别支持 IDEA 2026.1 EAP 最引人注目的变化之一,就是新增 Java 26 语言级别支持。这意味着开发者可以提前体验和测试即将在 JDK 26 中正式发布的语言特性。 其中最重要的变化是对 JEP 530 的全面支…...

SEATA分布式事务——AT模式僮
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

大模型强化学习实战指南:从PPO算法调优到Reward Hacking规避的7个关键动作
第一章:大模型强化学习的范式跃迁与工业落地挑战 2026奇点智能技术大会(https://ml-summit.org) 传统监督微调(SFT)正被基于人类反馈的强化学习(RLHF)和更前沿的直接偏好优化(DPO)所重构。这一…...
)
Codesys可视化界面设计:从零开始用按钮和指示灯搭建你的第一个HMI面板(附变量关联避坑指南)
Codesys可视化界面设计:从零开始用按钮和指示灯搭建你的第一个HMI面板(附变量关联避坑指南) 第一次接触Codesys的可视化界面设计,难免会被各种参数和选项搞得晕头转向。作为工业自动化领域的标准开发环境,Codesys提供了…...

AI时代新型的项目管理应该是什么样的?儋
AI训练存储选型的演进路线 第一阶段:单机直连时代 早期的深度学习数据集较小,模型训练通常在单台服务器或单张GPU卡上完成。此时直接将数据存储在训练机器的本地NVMe SSD/HDD上。 其优势在于IO延迟最低,吞吐量极高,也就是“数据离…...
颗)
AI开发-python-langchain框架(--并行流程 )颗
如果有多个供应商,你也可以使用 [[CC-Switch]] 来可视化管理这些API key,以及claude code 的skills。 # 多平台安装指令 curl -fsSL https://claude.ai/install.sh | bash ## Claude Code 配置 GLM Coding Plan curl -O "https://cdn.bigmodel.cn/i…...

Jasmine漫画浏览器:跨平台阅读的终极解决方案,打造你的个人漫画图书馆
Jasmine漫画浏览器:跨平台阅读的终极解决方案,打造你的个人漫画图书馆 【免费下载链接】jasmine A comic browser,support Android / iOS / MacOS / Windows / Linux. 项目地址: https://gitcode.com/gh_mirrors/jas/jasmine 你是否经…...

前端性能排查实战:Chrome Network面板里Timing那7个阶段到底怎么看?
Chrome Network面板Timing分析实战:从指标到性能优化 页面加载缓慢时,Chrome DevTools的Network面板中的Timing指标就像犯罪现场的指纹,每个数字背后都隐藏着性能问题的真相。但面对Queueing、Stalled、TTFB这些专业术语,很多开发…...

ETCD Keeper终极指南:3分钟掌握可视化etcd管理工具
ETCD Keeper终极指南:3分钟掌握可视化etcd管理工具 【免费下载链接】etcdkeeper web ui client for etcd 项目地址: https://gitcode.com/gh_mirrors/et/etcdkeeper ETCD Keeper是一款专为etcd设计的轻量级Web UI客户端工具,它通过直观的图形界面…...