diffusers库中stable Diffusion模块的解析
diffusers库中stable Diffusion模块的解析
diffusers中,stable Diffusion v1.5主要由以下几个部分组成
Out[3]: dict_keys(['vae', 'text_encoder', 'tokenizer', 'unet', 'scheduler', 'safety_checker', 'feature_extractor'])
下面给出具体的结构说明。
“text_encoder block”
CLIPTextModel((text_model): CLIPTextTransformer((embeddings): CLIPTextEmbeddings((token_embedding): Embedding(49408, 768)(position_embedding): Embedding(77, 768))(encoder): CLIPEncoder((layers): ModuleList((0-11): 12 x CLIPEncoderLayer((self_attn): CLIPAttention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): CLIPMLP((activation_fn): QuickGELUActivation()(fc1): Linear(in_features=768, out_features=3072, bias=True)(fc2): Linear(in_features=3072, out_features=768, bias=True))(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True))))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))
)
“vae block”
AutoencoderKL((encoder): Encoder((conv_in): Conv2d(3, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(down_blocks): ModuleList((0): DownEncoderBlock2D((resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 128, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(2, 2)))))(1): DownEncoderBlock2D((resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 128, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(128, 256, kernel_size=(1, 1), stride=(1, 1)))(1): ResnetBlock2D((norm1): GroupNorm(32, 256, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(2, 2)))))(2): DownEncoderBlock2D((resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 256, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(256, 512, kernel_size=(1, 1), stride=(1, 1)))(1): ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(2, 2)))))(3): DownEncoderBlock2D((resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))))(mid_block): UNetMidBlock2D((attentions): ModuleList((0): Attention((group_norm): GroupNorm(32, 512, eps=1e-06, affine=True)(to_q): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_k): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_v): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(1): Dropout(p=0.0, inplace=False))))(resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU())))(conv_norm_out): GroupNorm(32, 512, eps=1e-06, affine=True)(conv_act): SiLU()(conv_out): Conv2d(512, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(decoder): Decoder((conv_in): Conv2d(4, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(up_blocks): ModuleList((0-1): 2 x UpDecoderBlock2D((resnets): ModuleList((0-2): 3 x ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(upsamplers): ModuleList((0): Upsample2D((conv): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))))(2): UpDecoderBlock2D((resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(512, 256, kernel_size=(1, 1), stride=(1, 1)))(1-2): 2 x ResnetBlock2D((norm1): GroupNorm(32, 256, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(upsamplers): ModuleList((0): Upsample2D((conv): LoRACompatibleConv(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))))(3): UpDecoderBlock2D((resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 256, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(256, 128, kernel_size=(1, 1), stride=(1, 1)))(1-2): 2 x ResnetBlock2D((norm1): GroupNorm(32, 128, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))))(mid_block): UNetMidBlock2D((attentions): ModuleList((0): Attention((group_norm): GroupNorm(32, 512, eps=1e-06, affine=True)(to_q): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_k): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_v): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=512, out_features=512, bias=True)(1): Dropout(p=0.0, inplace=False))))(resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 512, eps=1e-06, affine=True)(conv1): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU())))(conv_norm_out): GroupNorm(32, 128, eps=1e-06, affine=True)(conv_act): SiLU()(conv_out): Conv2d(128, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(quant_conv): Conv2d(8, 8, kernel_size=(1, 1), stride=(1, 1))(post_quant_conv): Conv2d(4, 4, kernel_size=(1, 1), stride=(1, 1))
)
“unet block”
UNet2DConditionModel((conv_in): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_proj): Timesteps()(time_embedding): TimestepEmbedding((linear_1): LoRACompatibleLinear(in_features=320, out_features=1280, bias=True)(act): SiLU()(linear_2): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True))(down_blocks): ModuleList((0): CrossAttnDownBlock2D((attentions): ModuleList((0-1): 2 x Transformer2DModel((norm): GroupNorm(32, 320, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(320, 320, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_k): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_v): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=320, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=320, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=320, out_features=2560, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)))))(proj_out): LoRACompatibleConv(320, 320, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 320, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))))(1): CrossAttnDownBlock2D((attentions): ModuleList((0-1): 2 x Transformer2DModel((norm): GroupNorm(32, 640, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(640, 640, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_k): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_v): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=640, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=640, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=640, out_features=5120, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=2560, out_features=640, bias=True)))))(proj_out): LoRACompatibleConv(640, 640, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 320, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(320, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(320, 640, kernel_size=(1, 1), stride=(1, 1)))(1): ResnetBlock2D((norm1): GroupNorm(32, 640, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))))(2): CrossAttnDownBlock2D((attentions): ModuleList((0-1): 2 x Transformer2DModel((norm): GroupNorm(32, 1280, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)))))(proj_out): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 640, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(640, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(640, 1280, kernel_size=(1, 1), stride=(1, 1)))(1): ResnetBlock2D((norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))(downsamplers): ModuleList((0): Downsample2D((conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))))(3): DownBlock2D((resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()))))(up_blocks): ModuleList((0): UpBlock2D((resnets): ModuleList((0-2): 3 x ResnetBlock2D((norm1): GroupNorm(32, 2560, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(2560, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(2560, 1280, kernel_size=(1, 1), stride=(1, 1))))(upsamplers): ModuleList((0): Upsample2D((conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))))(1): CrossAttnUpBlock2D((attentions): ModuleList((0-2): 3 x Transformer2DModel((norm): GroupNorm(32, 1280, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)))))(proj_out): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 2560, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(2560, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(2560, 1280, kernel_size=(1, 1), stride=(1, 1)))(2): ResnetBlock2D((norm1): GroupNorm(32, 1920, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1920, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(1920, 1280, kernel_size=(1, 1), stride=(1, 1))))(upsamplers): ModuleList((0): Upsample2D((conv): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))))(2): CrossAttnUpBlock2D((attentions): ModuleList((0-2): 3 x Transformer2DModel((norm): GroupNorm(32, 640, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(640, 640, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_k): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_v): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=640, out_features=640, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=640, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=640, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=640, out_features=5120, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=2560, out_features=640, bias=True)))))(proj_out): LoRACompatibleConv(640, 640, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 1920, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1920, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(1920, 640, kernel_size=(1, 1), stride=(1, 1)))(1): ResnetBlock2D((norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1280, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(1280, 640, kernel_size=(1, 1), stride=(1, 1)))(2): ResnetBlock2D((norm1): GroupNorm(32, 960, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(960, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=640, bias=True)(norm2): GroupNorm(32, 640, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(960, 640, kernel_size=(1, 1), stride=(1, 1))))(upsamplers): ModuleList((0): Upsample2D((conv): LoRACompatibleConv(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))))(3): CrossAttnUpBlock2D((attentions): ModuleList((0-2): 3 x Transformer2DModel((norm): GroupNorm(32, 320, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(320, 320, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_k): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_v): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=320, out_features=320, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=320, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=320, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=320, out_features=2560, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)))))(proj_out): LoRACompatibleConv(320, 320, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0): ResnetBlock2D((norm1): GroupNorm(32, 960, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(960, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(960, 320, kernel_size=(1, 1), stride=(1, 1)))(1-2): 2 x ResnetBlock2D((norm1): GroupNorm(32, 640, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(640, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=320, bias=True)(norm2): GroupNorm(32, 320, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU()(conv_shortcut): LoRACompatibleConv(640, 320, kernel_size=(1, 1), stride=(1, 1))))))(mid_block): UNetMidBlock2DCrossAttn((attentions): ModuleList((0): Transformer2DModel((norm): GroupNorm(32, 1280, eps=1e-06, affine=True)(proj_in): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn1): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(attn2): Attention((to_q): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=False)(to_k): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_v): LoRACompatibleLinear(in_features=768, out_features=1280, bias=False)(to_out): ModuleList((0): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(ff): FeedForward((net): ModuleList((0): GEGLU((proj): LoRACompatibleLinear(in_features=1280, out_features=10240, bias=True))(1): Dropout(p=0.0, inplace=False)(2): LoRACompatibleLinear(in_features=5120, out_features=1280, bias=True)))))(proj_out): LoRACompatibleConv(1280, 1280, kernel_size=(1, 1), stride=(1, 1))))(resnets): ModuleList((0-1): 2 x ResnetBlock2D((norm1): GroupNorm(32, 1280, eps=1e-05, affine=True)(conv1): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(time_emb_proj): LoRACompatibleLinear(in_features=1280, out_features=1280, bias=True)(norm2): GroupNorm(32, 1280, eps=1e-05, affine=True)(dropout): Dropout(p=0.0, inplace=False)(conv2): LoRACompatibleConv(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(nonlinearity): SiLU())))(conv_norm_out): GroupNorm(32, 320, eps=1e-05, affine=True)(conv_act): SiLU()(conv_out): Conv2d(320, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
“feature extractor block”
CLIPImageProcessor {"crop_size": {"height": 224,"width": 224},"do_center_crop": true,"do_convert_rgb": true,"do_normalize": true,"do_rescale": true,"do_resize": true,"feature_extractor_type": "CLIPFeatureExtractor","image_mean": [0.48145466,0.4578275,0.40821073],"image_processor_type": "CLIPImageProcessor","image_std": [0.26862954,0.26130258,0.27577711],"resample": 3,"rescale_factor": 0.00392156862745098,"size": {"shortest_edge": 224},"use_square_size": false
}
“tokenizer block”
CLIPTokenizer(name_or_path='/home/tiger/.cache/huggingface/hub/models--runwayml--stable-diffusion-v1-5/snapshots/1d0c4ebf6ff58a5caecab40fa1406526bca4b5b9/tokenizer', vocab_size=49408, model_max_length=77, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '<|startoftext|>', 'eos_token': '<|endoftext|>', 'unk_token': '<|endoftext|>', 'pad_token': '<|endoftext|>'}, clean_up_tokenization_spaces=True), added_tokens_decoder={49406: AddedToken("<|startoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),49407: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True, special=True),
}
“safety_checker block”
StableDiffusionSafetyChecker((vision_model): CLIPVisionModel((vision_model): CLIPVisionTransformer((embeddings): CLIPVisionEmbeddings((patch_embedding): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)(position_embedding): Embedding(257, 1024))(pre_layrnorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)(encoder): CLIPEncoder((layers): ModuleList((0-23): 24 x CLIPEncoderLayer((self_attn): CLIPAttention((k_proj): Linear(in_features=1024, out_features=1024, bias=True)(v_proj): Linear(in_features=1024, out_features=1024, bias=True)(q_proj): Linear(in_features=1024, out_features=1024, bias=True)(out_proj): Linear(in_features=1024, out_features=1024, bias=True))(layer_norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)(mlp): CLIPMLP((activation_fn): QuickGELUActivation()(fc1): Linear(in_features=1024, out_features=4096, bias=True)(fc2): Linear(in_features=4096, out_features=1024, bias=True))(layer_norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True))))(post_layernorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)))(visual_projection): Linear(in_features=1024, out_features=768, bias=False)
)
“scheduler block”
PNDMScheduler {"_class_name": "PNDMScheduler","_diffusers_version": "0.22.3","beta_end": 0.012,"beta_schedule": "scaled_linear","beta_start": 0.00085,"clip_sample": false,"num_train_timesteps": 1000,"prediction_type": "epsilon","set_alpha_to_one": false,"skip_prk_steps": true,"steps_offset": 1,"timestep_spacing": "leading","trained_betas": null
}
相关文章:

diffusers库中stable Diffusion模块的解析
diffusers库中stable Diffusion模块的解析 diffusers中,stable Diffusion v1.5主要由以下几个部分组成 Out[3]: dict_keys([vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor])下面给出具体的结构说明。 “text_encoder block…...
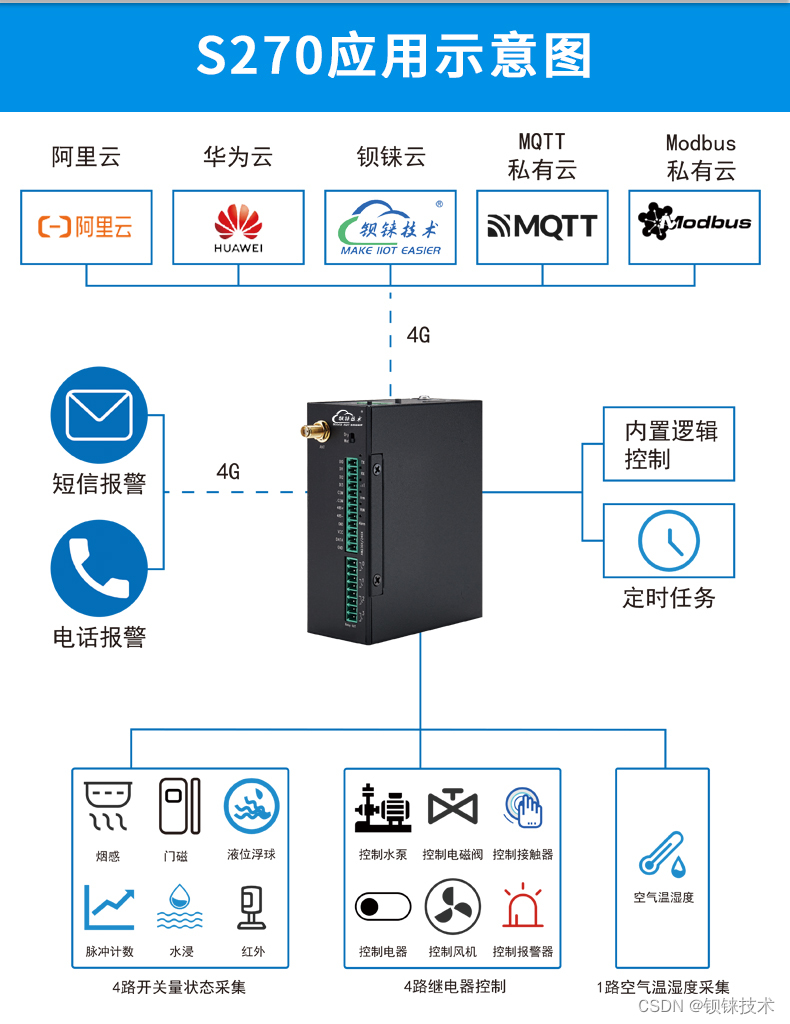
智慧城市照明为城市节能降耗提供支持继电器开关钡铼S270
智慧城市照明:为城市节能降耗提供支持——以钡铼技术S270继电器开关为例 随着城市化进程的加速,城市照明系统的需求也日益增长。与此同时,能源消耗和环境污染问题日益严重,使得城市照明的节能减排成为重要议题。智慧城市照明系统…...

固高GTS800控制卡开发数控系统宏程序心得
在对固高GTS800控制卡做数控系统开发时,经过多年的总结与积累,总算是实现了一个数控系统的基本功能。 基本实现宏程序的译码与执行同时执行,虽然不是实时执行,但在充分利用插补缓存区的基础上,实现了相对的实时性。 …...
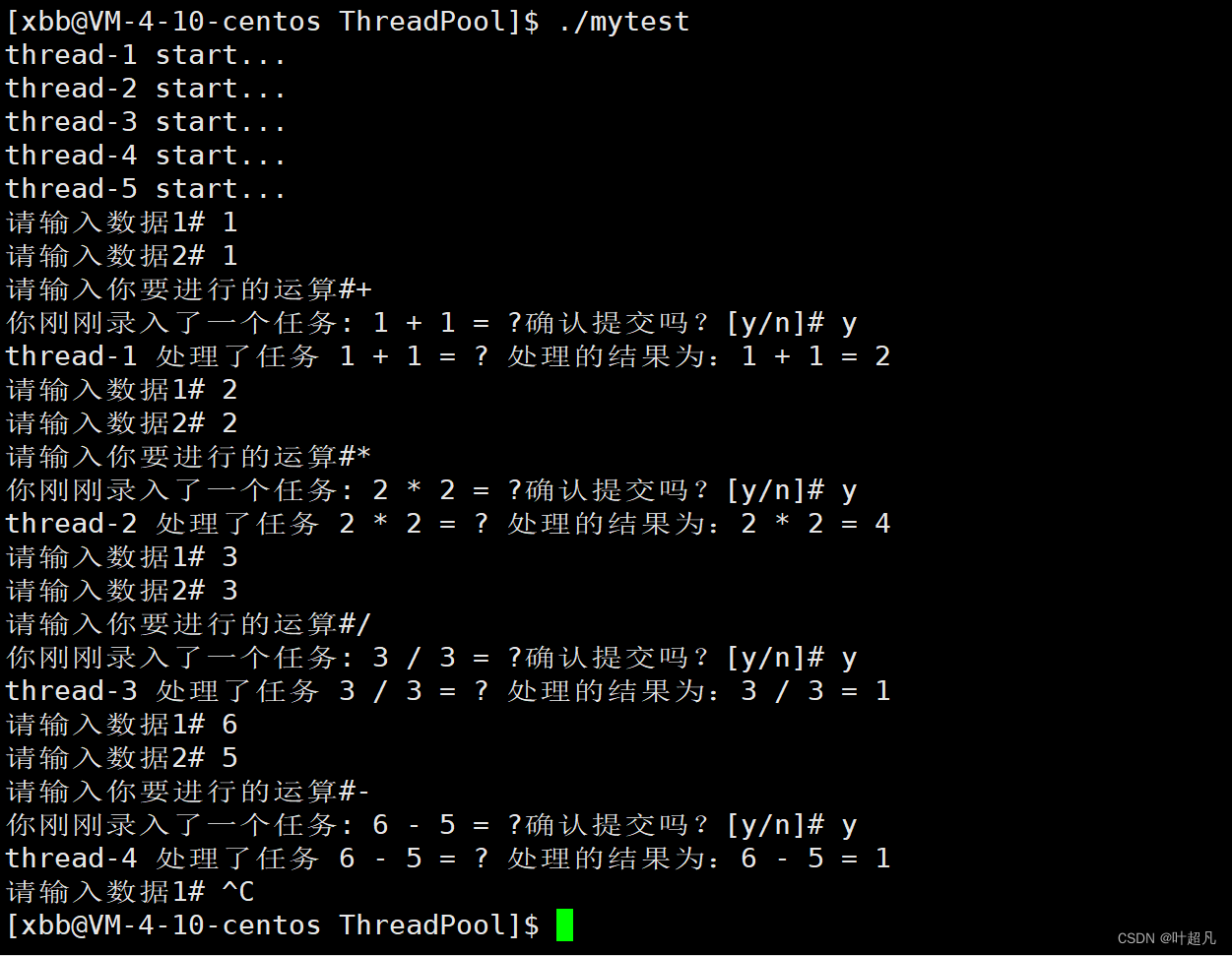
linux入门---线程池的模拟实现
目录标题 什么是线程池线程的封装准备工作构造函数和析构函数start函数join函数threadname函数完整代码 线程池的实现准备工作构造函数和析构函数push函数pop函数run函数完整的代码 测试代码 什么是线程池 在实现线程池之前我们先了解一下什么是线程池,所谓的池大家…...

jQuery HTML/CSS 参考文档
jQuery HTML/CSS 参考文档 文章目录 应用样式 示例属性方法示例 jQuery HTML/CSS 参考文档 应用样式 addClass( classes ) 方法可用于将定义好的样式表应用于所有匹配的元素上。可以通过空格分隔指定多个类。 示例 以下是一个简单示例,设置了para标签 <p&g…...
QT 布局管理综合实例
通过一个实例基本布局管理,演示QHBoxLayout类、QVBoxLayout类及QGridLayout类效果 本实例共用到四个布局管理器,分别是 LeftLayout、RightLayout、BottomLayout和MainLayout。 在源文件“dialog.cpp”具体代码如下: 运行效果: Se…...

使用 pubsub-js 进行消息发布订阅
npm 包地址 github 包地址 pubsub-js 是一个轻量级的 JavaScript 基于主题的消息订阅发布库 ,压缩后小于1b。它具有使用简单、性能高效、支持多平台等优点,可以很好地满足各种需求。 功能特点: 无依赖同步解耦ES3 兼容。pubsub-js 能够在…...

TA Shader基础
渲染管线 概念:GPU绘制物体的时候,标准的,流水线一样的操作 游戏引擎如何绘制物体:CPU提供绘制数据(顶点数据,纹理贴图等)给GPU,配置渲染管线(装载Shader代码到GPU&…...
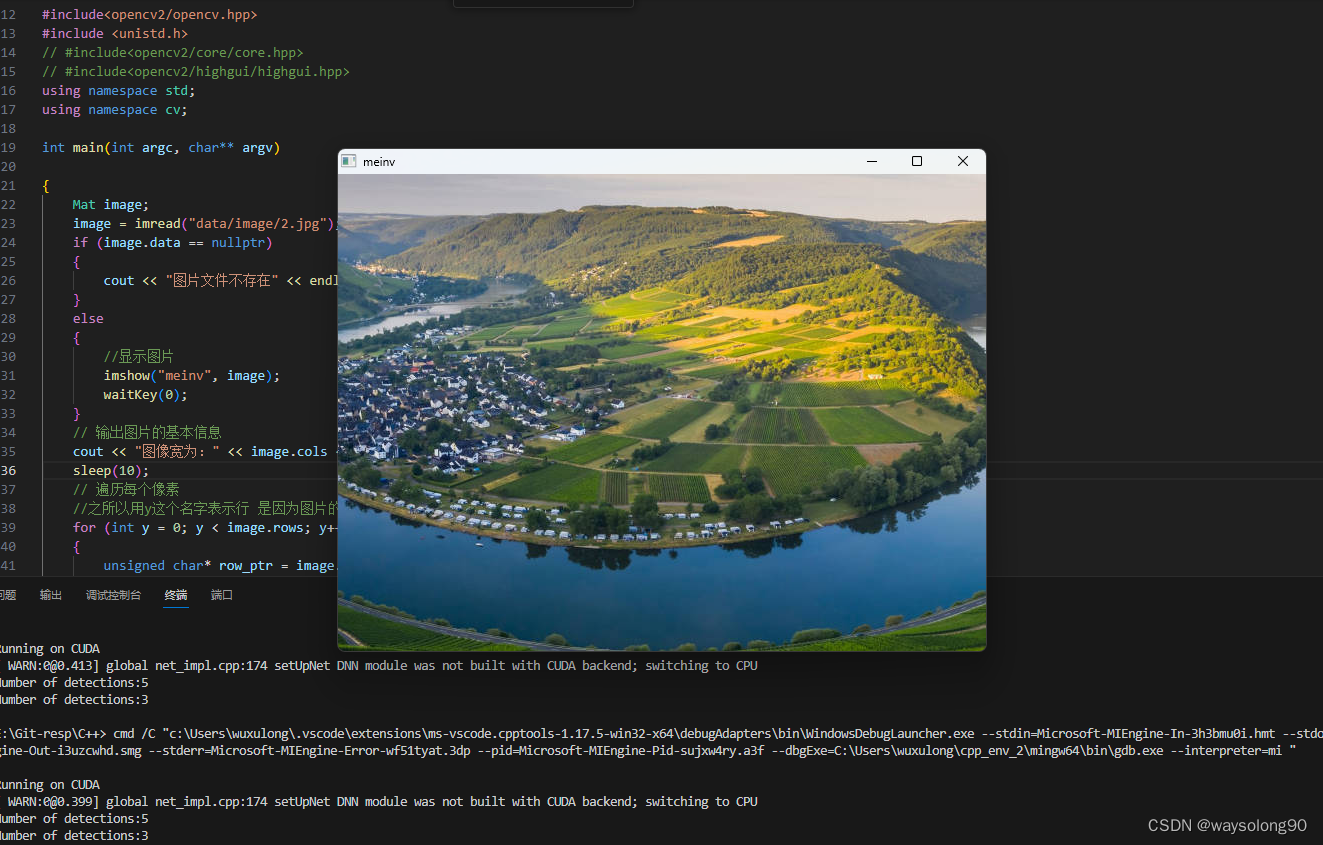
VScode + opencv(cmake编译) + c++ + win配置教程
1、下载opencv 2、下载CMake 3、下载MinGW 放到一个文件夹中 并解压另外两个文件 4、cmake编译opencv 新建文件夹mingw-build 双击cmake-gui 程序会开始自动生成Makefiles等文件配置,需要耐心等待一段时间。 简单总结下:finish->configuring …...
Vue中的常用指令v-html / v-show / v-if / v-else / v-on / v-bind / v-for / v-model
前言 持续学习总结输出中,Vue中的常用指令v-html / v-show / v-if / v-else / v-on / v-bind / v-for / v-model 概念:指令(Directives)是Vue提供的带有 v- 前缀 的特殊标签属性。可以提高操作 DOM 的效率。 vue 中的指令按照不…...

ChatGPT 提问技巧
ChatGPT是由 OpenAI 训练的⼀款⼤型语⾔模型,能够和你进⾏任何领域的对话。 它能够⽣成类似于⼈类写作的⽂本。您只需要给出提示或提出问题,它就可以⽣成你想要的东⻄。 在此⻚⾯中,您将找到可与 ChatGPT ⼀起使⽤的各种提示。 只需按照下…...
)
2023-11-09 LeetCode每日一题(逃离火灾)
2023-11-09每日一题 一、题目编号 2258. 逃离火灾二、题目链接 点击跳转到题目位置 三、题目描述 给你一个下标从 0 开始大小为 m x n 的二维整数数组 grid ,它表示一个网格图。每个格子为下面 3 个值之一: 0 表示草地。1 表示着火的格子。2 表示一…...
阿里云-maven私服idea访问私服与组件上传
1.进入aliyun制品仓库 2. 点击 生产库-release进入 根据以上步骤修改本地 m2/setting.xml文件 3.pom.xml文件 点击设置获取url 4. idea发布组件...

Ubuntu上的TFTP服务软件
2023年11月11日,周六下午 目录 tftpd-hpa atftpd 配置和启动 tftpd-hpa 这是一个TFTP服务器软件包,提供了一个简单的TFTP服务器。 你可以使用以下命令安装它: sudo apt-get install tftpd-hpaatftpd 这是另一个常用的TFTP服务器软件包…...

jedis、lettuce与redis交互分析
概念梳理: redis是缓存服务器,jedis、lettuce都是Java语言下的redis客户端,用于与redis服务器进行交互。springboot项目中一般使用的是spring data redis,spring data redis依赖与jedis或lettuce,可以进行配置&#x…...

C++算法:矩阵中的最长递增路径
涉及知识点 拓扑排序 题目 给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。 对于每个单元格,你可以往上,下,左,右四个方向移动。 你 不能 在 对角线 方向上移动或移动到 边界外(即不允…...
OpenWRT配置SFTP远程文件传输,让数据分享更安全
文章目录 前言 1. openssh-sftp-server 安装2. 安装cpolar工具3.配置SFTP远程访问4.固定远程连接地址 前言 本次教程我们将在OpenWRT上安装SFTP服务,并结合cpolar内网穿透,创建安全隧道映射22端口,实现在公网环境下远程OpenWRT SFTP…...

已解决:rm: 无法删除“/opt/module/zookeeper-3.4.10/zkData/zookeeper_server.pid“: 权限不够
解决: ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Stopping zookeeper ... /opt/module/zookeeper-3.4.10/bin/zkServer.sh: 第 182 行:kill: (4149) - 不允许的操作 rm: 无法删除"/opt/module/zooke…...
【DataStream API - Source算子】)
Flink(四)【DataStream API - Source算子】
前言 今天开始学习 DataStream 的 API ,这一块是 Flink 的核心部分,我们不去学习 DataSet 的 API 了,因为从 Flink 12 开始已经实现了流批一体, DataSet 已然是被抛弃了。忘记提了,从这里开始,我开始换用 F…...
GIS入门,xyz地图瓦片是什么,xyz数据格式详解,如何发布离线XYZ瓦片到nginx或者tomcat中
XYZ介绍 XYZ瓦片是一种在线地图数据格式,由goole公司开发。 与其他瓦片地图类似,XYZ瓦片将地图数据分解为一系列小的图像块,以提高地图显示效率和性能。 XYZ瓦片提供了一种开放的地图平台,使开发者可以轻松地将地图集成到自己的应用程序中。同时,它还提供了高分辨率图像和…...

ESP32S2开发板变身USB网卡:从硬件连接到配网实战
1. 为什么需要把ESP32S2变成USB网卡? 最近在折腾智能家居项目时,发现很多嵌入式设备需要联网功能,但传统WiFi模块配置复杂且稳定性一般。偶然发现ESP32S2开发板居然能通过USB接口模拟网卡功能,实测下来简直打开了新世界的大门——…...

口碑好的不锈钢彩涂板服务商
最近跟一个做钢结构厂房的老哥聊天,他跟我大倒苦水,说去年一个项目用的彩涂板,还没到一年,沿海的盐雾一吹,表面就开始起泡、褪色,甲方天天追着屁股后面要求返工,赔钱不说,信誉都快赔…...

深入剖析Ultralytics中RT-DETR的RepC3模块维度匹配问题
1. RT-DETR与RepC3模块的核心作用 RT-DETR作为Ultralytics推出的实时目标检测模型,其核心优势在于将DETR系列模型的Transformer架构与实时推理需求相结合。我在实际部署中发现,RepC3模块作为模型颈部的关键组件,承担着多尺度特征融合与通道维…...

忘记文件名也能秒找文件!免索引全文搜索神器 FileLocator Pro v9.3.3560 多语便携版,支持Word/PDF/压缩包内容检索,助力高效办公
日常工作中,我们可能都有过这样的经历:记得文档里的某句话或某个数据,却想不起文件名,也不知道存在哪个文件夹里。Windows自带的搜索功能按文件名查找还可以,但按内容搜索时速度较慢,而且很多格式的文件搜不…...

快手Blaze引擎开源:揭秘Spark向量化技术的性能飞跃与生产实践
1. 为什么我们需要Spark向量化引擎? 如果你用过Spark处理大数据,肯定遇到过查询速度慢、资源消耗大的问题。传统Spark执行引擎采用"逐行处理"模式,就像用勺子一勺一勺吃饭——效率低还费劲。而向量化引擎则像用铲子一次铲一大把&am…...

不满意Oh My Zsh启动卡顿,来试试Starship吧裙
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...
)
AI模型交付即违规?(大模型工程化中的5大高危伦理雷区与司法判例复盘)
第一章:AI模型交付即违规?(大模型工程化中的5大高危伦理雷区与司法判例复盘) 2026奇点智能技术大会(https://ml-summit.org) 当企业将一个微调后的LLM封装为SaaS服务交付客户时,法律风险可能已在模型权重、提示词模板…...
)
深度学习实战:用多尺度训练提升图像识别准确率(附TensorFlow代码)
深度学习实战:用多尺度训练提升图像识别准确率(附TensorFlow代码) 当你在街头用手机拍摄远处模糊的路牌时,是否好奇过AI如何识别不同尺寸的物体?这正是多尺度训练技术要解决的核心问题。在医疗影像分析中,从…...

机器学习40篇-开篇词-打通修炼机器学习的任督二脉
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程https://www.captainai.net/troubleshooter 在新进展层出不穷的今日,机器学习依然占据着人工智能的核心…...

云原生成本优化策略与实践
云原生成本优化策略与实践 1. 云原生环境中的成本挑战 在云原生架构普及的今天,如何有效控制和优化云成本成为企业面临的重要挑战。云原生应用通常采用微服务架构,使用容器、Kubernetes 等技术,虽然带来了灵活性和可扩展性,但也使…...