Elasticsearch 外部词库文件更新
本文所使用的ES集群环境可在历史文章中获取,采用docker部署的方式。
Elasticsearch 是一个功能强大的搜索引擎,广泛用于构建复杂的全文搜索应用程序。在许多情况下,为了提高搜索引擎的性能和精度,我们可以使用外部词库来定制和扩展 Elasticsearch 的文本处理和搜索功能。本文将介绍外部词库的用途、优势以及如何在 Elasticsearch 中使用它们。
为什么需要外部词库?
Elasticsearch 默认提供了一套强大的文本处理工具,包括分词、标记过滤、同义词处理等。然而,在某些情况下,我们需要更多的控制权来适应特定的用例和需求。外部词库允许我们:
-
自定义分词器:通过使用外部词库,您可以创建自定义分词器,以根据特定需求定义文本分割规则。这对于处理不同语言或行业的文本非常有用。
-
扩展停用词列表:停用词(如
and、the等)通常被排除在搜索索引之外。外部词库允许您将领域特定的停用词添加到索引中,以便更好地适应我们行业内的数据。 -
同义词处理:创建同义词词库可确保相关词汇在搜索时被正确映射,提高搜索结果的准确性。
-
专业术语:对于特定领域或行业,我们可以通过创建外部词库,以包含特定领域的专业术语,确保搜索引擎能够理解和处理这些术语。
使用外部词库的优势
使用外部词库有以下优势:
-
提高搜索质量:通过自定义分词和停用词,可以确保搜索引擎更好地理解和处理文本,提高搜索质量。
-
适应特定需求:外部词库允许根据特定用例和领域需求对搜索引擎进行定制,以满足工作要求。
-
更好的用户体验:通过包含专业术语和扩展的同义词映射,用户能够更轻松地找到他们需要的内容。
如何在 Elasticsearch 中使用外部词库
在 Elasticsearch 中使用外部词库通常涉及以下步骤:
-
创建外部词库文件:首先,我们需要准备一个外部词库文件,其中包含自定义的词汇、同义词或停用词列表。
-
将词库上传到 Elasticsearch:上传词库文件到 Elasticsearch
-
配置索引:将外部词库与索引相关联,以确保 Elasticsearch 在索引文档时使用这些词汇。
-
搜索优化:根据需要在搜索查询中应用外部词库,以扩展或定制搜索行为。
示例:使用自定义词库分词
本文在 IK 分词器的基础上增加自定义分词,并配置本地词库文件,远程热更新词库文件。
本地词库
-
首先在启动的
ES中对醉鱼两个字进行分词,IK默认分为两个汉字GET _analyze {"analyzer": "ik_max_word","text": ["醉鱼"] }结果如下
{"tokens" : [{"token" : "醉","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "鱼","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1}] }而我们的需求是让其能分为一次词语,而不是两个汉字,那么下面引入我们的自定义分词文件
-
在
ES的plugins/ik/config目录下创建自定义词库文件zuiyu.dic,文件内容如下,格式为一个词语为一行。醉鱼 -
修改
IK的配置,支持自定义分词文件 ,修改plugins/ik/config目录下的IKAnalyzer.cfg.xml,修改其中<entry key="ext_dict"></entry>的值,为本地文件路径,配置为相对路径,直接填写上一步创建的zuiyu.dic,结果如下<entry key="ext_dict">zuiyu.dic</entry><?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">zuiyu.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!--<entry key="remote_ext_dict"></entry>--><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> -
如果是启动的
ES集群,需要复制当前两个文件到所有的集群中1、当前集群有三个节点,其中都配置本地词库文件,但是
node1,node2中都没有增加醉鱼这词语,只有node3有,此时使用分词是无法达到预期效果的。2、
node1中配置正常的<entry key="ext_dict">zuiyu.dic</entry>,zuiyu.dic中也包含醉鱼这个词语。node2,node3都不配置ext_dict,此时当前这个环境是可以进行正确分词,达到预期的结果的。 -
重启
ES -
测试分词效果,使用同样的分词语句
GET _analyze {"analyzer": "ik_max_word","text": ["醉鱼"] }结果如下
{"tokens" : [{"token" : "醉鱼","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0}] }一般来说,词语肯定不是固定的,随着工作的长期积累,不断地发现新的专业术语,那么热更新,动态更新词库,不在每次更新词库之后重启
ES就是非常有必要的了,下面来看一下热更新词库。
远程词库(热更新)
热更新词库的区别就是IKAnalyzer.cfg.xml文件中的一个配置的问题。不过核心还是需要一个词库文件,刚才是通过路径访问的,但是无法热更新,所以现在需要改为URL访问,也就是 HTTP 请求可以读取到的形式。一个词语一行返回即可。
此处使用 Nginx 来做演示。Nginx 中的配置如下
-
nginx.conflocation /dic/zuiyu.dic {alias html/dic/zuiyu.dic; } -
zuiyu.dic文件内容如下醉鱼 -
IKAnalyzer.cfg.xml配置修改如下,IP为部署的Nginx的IP,端口也是根据自己Nginx监听的端口修改<entry key="remote_ext_dict">http://192.168.30.240:8088/dic/zuiyu.dic</entry>完整的配置如下
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">zuiyu.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">http://192.168.30.240:8088/dic/zuiyu.dic</entry><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> -
验证
URL访问结果,使用浏览器或者postman等工具访问http://192.168.30.240:8088/dic/zuiyu.dic可以返回我们的文件内容即可,也是一个词语一行的形式。 -
复制
IKAnalyzer.cfg.xml到集群的每个节点中 -
重启
ES -
测试对
醉鱼分词,可以看到与上面本地词库时是同样的效果{"tokens" : [{"token" : "醉鱼","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0}] } -
测试对
我爱你醉鱼进行分词GET _analyze {"analyzer": "ik_max_word","text": ["我爱你醉鱼"] }结果如下
{"tokens" : [{"token" : "我爱你","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "爱你","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "醉鱼","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 2}] } -
在
zuiyu.dic中增加我爱你醉鱼,最终的文件内容如下醉鱼 我爱你醉鱼 -
增加完成之后,这5个字已经成为一个词语,分词结果如下
{"tokens" : [{"token" : "我爱你醉鱼","start_offset" : 0,"end_offset" : 5,"type" : "CN_WORD","position" : 0},{"token" : "我爱你","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "爱你","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 2},{"token" : "醉鱼","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 3}] }仅在一个节点
node1中配置了远程词库,node2与node3都没有配置任何的词库,此时当前环境无法达到我们的预期分词效果
总结
通过上面我们的试验,可以发现结合 IK分词器,使用自定义词库,可以满足我们专业内的词语分词,实现更好的分词效果,再加上动态词库的更新,对我们的工作还是很有必要的,配置过程是不是很简单,下面就赶紧用起来吧。
相关文章:

Elasticsearch 外部词库文件更新
本文所使用的ES集群环境可在历史文章中获取,采用docker部署的方式。 Elasticsearch 是一个功能强大的搜索引擎,广泛用于构建复杂的全文搜索应用程序。在许多情况下,为了提高搜索引擎的性能和精度,我们可以使用外部词库来定制和扩展…...
OpenTiny Vue 组件库支持 Vue2.7 啦!
之前 OpenTiny 发布了一篇 Vue2 升级 Vue3 的文章。 🖖少年,该升级 Vue3 了! 里面提到使用了 ElementUI 的 Vue2 项目,可以通过 TinyVue 和 gogocode 快速升级到 Vue3 项目。 有朋友评论替换button出错了,并且贴出了…...

蒙特卡罗算法
介绍 蒙特卡罗算法是一种基于随机采样的数值计算方法,常用于解决复杂问题和优化求解。它的核心思想是通过生成大量的随机样本,利用概率统计的方法来估计问题的解或者优化目标的最优值。 蒙特卡罗算法的具体步骤如下: 1. 定义问题:…...
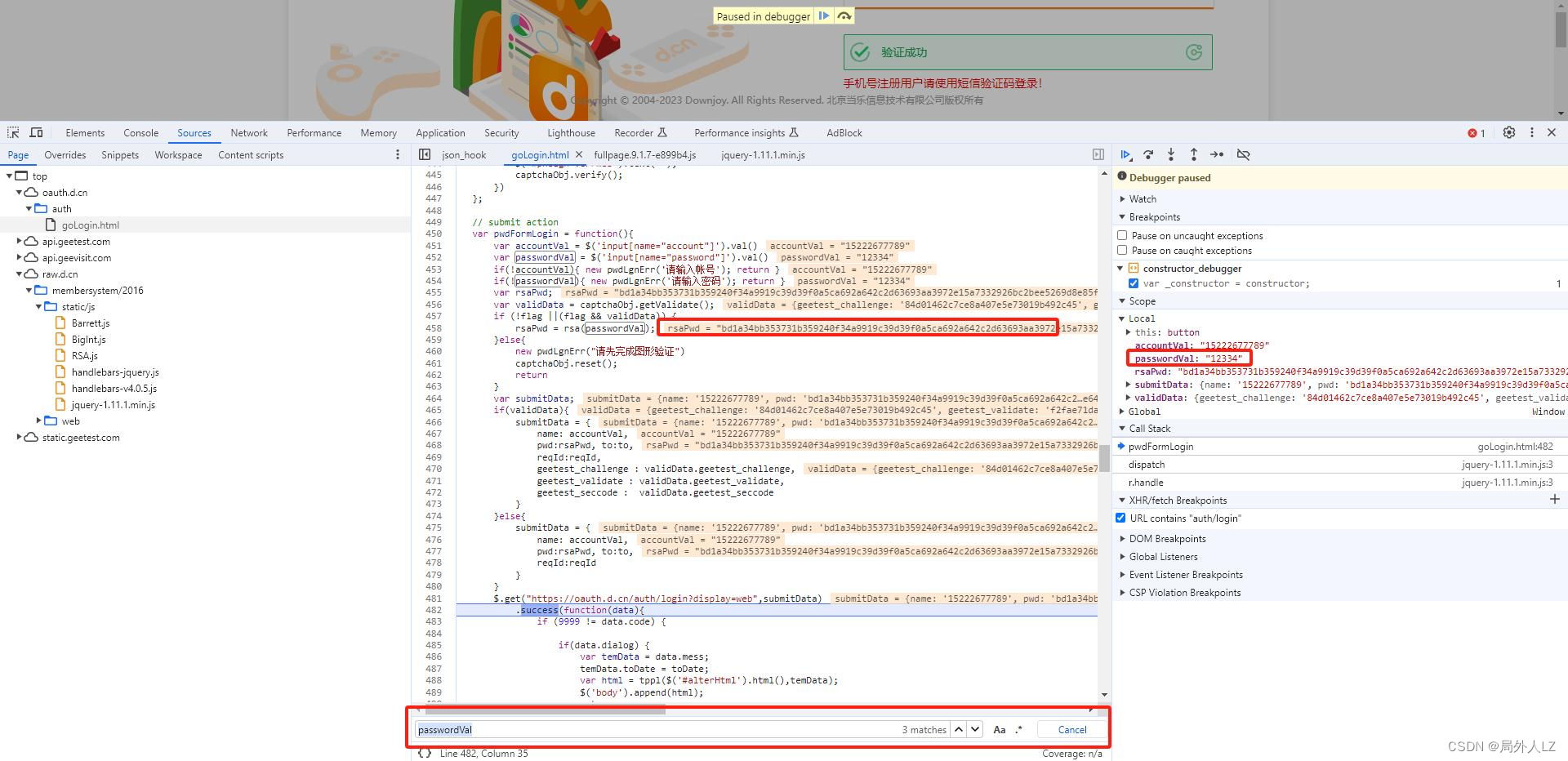
python爬虫hook定位技巧、反调试技巧、常用辅助工具
一、浏览器调试面板介绍 二、hook定位、反调试 Hook 是一种钩子技术,在系统没有调用函数之前,钩子程序就先得到控制权,这时钩子函数既可以加工处理(改变)该函数的执行行为,也可以强制结束消息的传递。简单…...
Jmeter —— jmeter参数化实现
jmeter参数化 在实际的测试工作中,我们经常需要对多组不同的输入数据,进行同样的测试操作步骤,以验证我们的软件的功能。这种测试方式在业界称为数据驱动测试, 而在实际测试工作中,测试工具中实现不同数据输入的过…...

Day57_《MySQL索引与性能优化》摘要
一、资料 视频:《尚硅谷MySQL数据库高级,mysql优化,数据库优化》—周阳 其他博主的完整笔记:MySQL 我的笔记:我的笔记只总结了视频p14-p46部分,因为只有这部分是讲解了MySQL的索引与explain语句分析优化…...

蓝桥杯每日一题2023.11.11
题目描述 “蓝桥杯”练习系统 (lanqiao.cn) 题目分析 对于此题首先想到的是暴力分析,使用前缀和,这样方便算出每一区间的大小,枚举长度和其实位置,循环计算出所有区间的和进行判断,输出答案。 非满分暴力写法&#…...
『Linux升级路』基础开发工具——vim篇
🔥博客主页:小王又困了 📚系列专栏:Linux 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、vim的基本概念 📒1.1命令模式 📒1.2插入模式 &…...
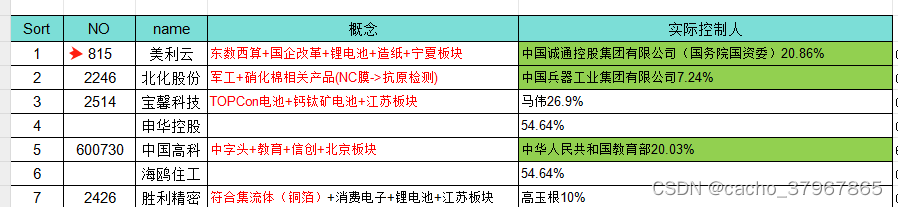
【Excel】补全单元格值变成固定长度
我们知道股票代码都为6位数字,但深圳中小板代码前面以0开头,数字格式时前面的0会自动省略,现在需要在Excel表格补全它。如下图: 这时我们需要用到特殊的函数:TEXT或者RIGHT TEXT函数是Excel中一个非常有用的函数。TEX…...
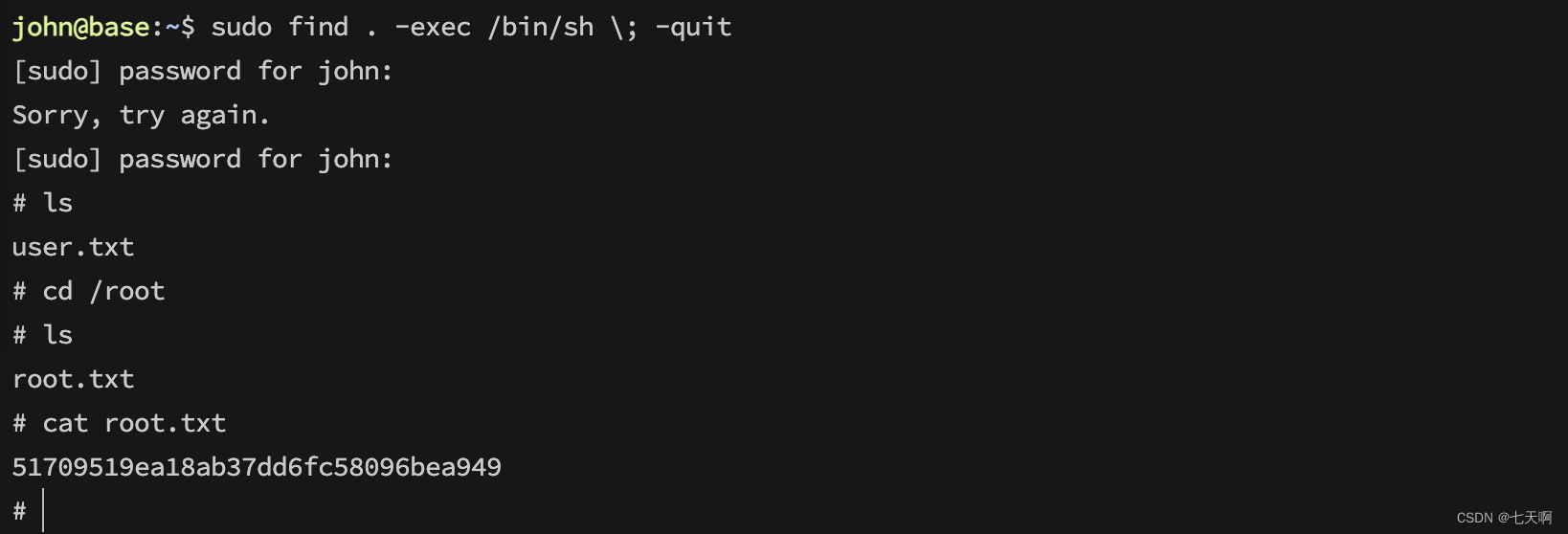
HackTheBox-Starting Point--Tier 2---Base
文章目录 一 题目二 过程记录2.1 打点2.2 权限获取2.3 横向移动2.4 权限提升 一 题目 Tags Web、Vulnerability Assessment、Custom Applications、Source Code Analysis、Authentication、Apache、PHP、Reconnaissance、Web Site Structure Discovery、SUDO Exploitation、Au…...
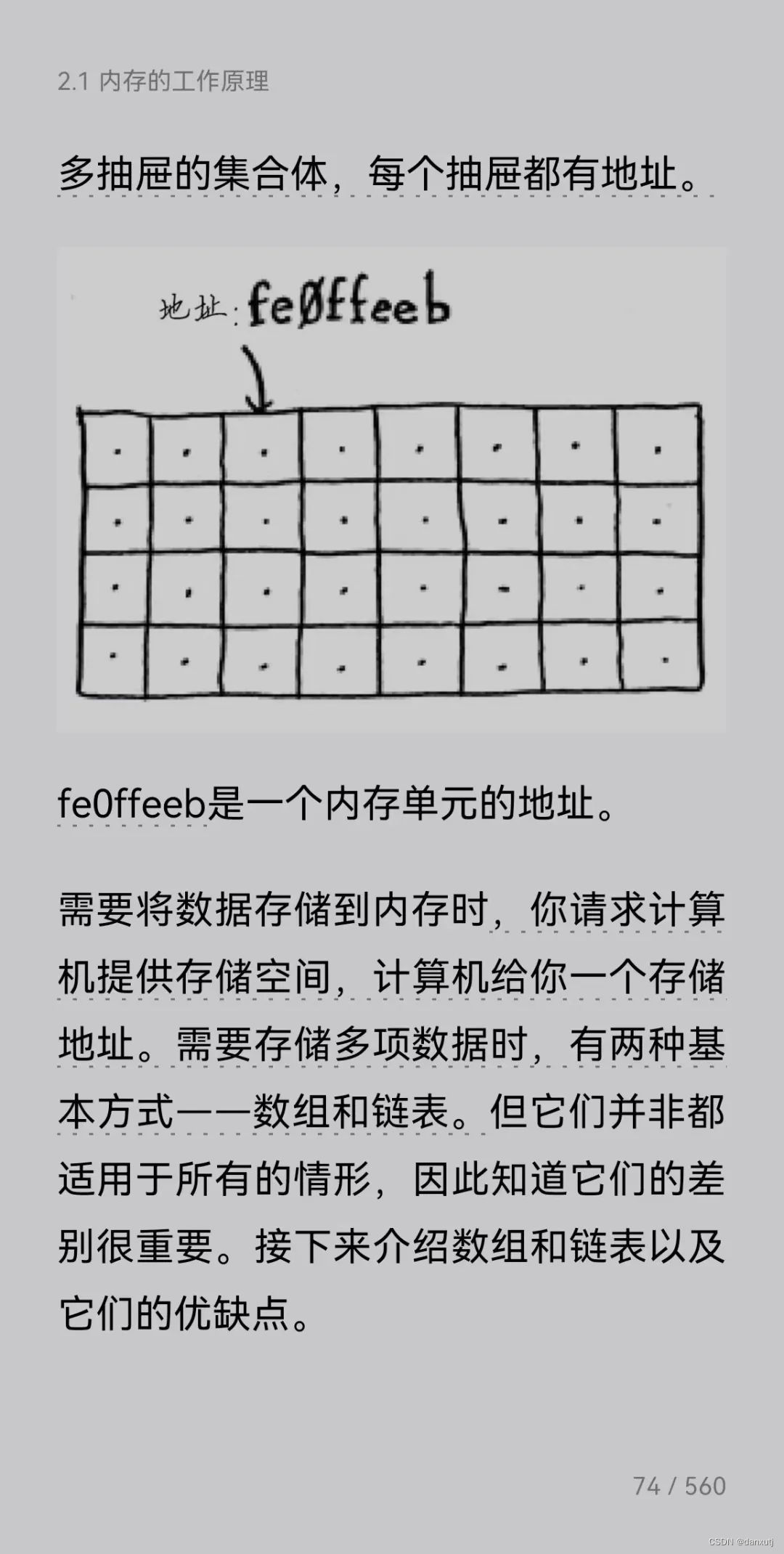
算法导论笔记4:散列数 hash
一 了解一些散列的基本概念,仅从文字角度,整理了最基础的定义。 发现一本书,《算法图解》,微信读书APP可读,有图,并且是科普性质的读物,用的比喻很生活化,可以与《算法导论》合并起…...
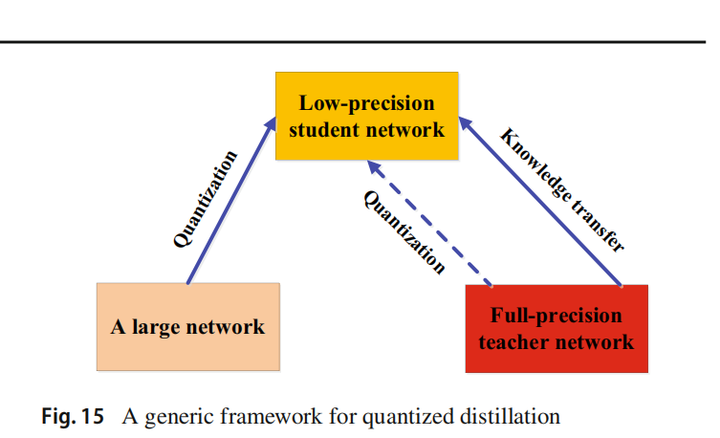
知识蒸馏概述及开源项目推荐
文章目录 1.介绍2.知识2.1 基于响应的知识(response-based)2.2 基于特征的知识(feature-based)2.3 基于关系的知识(relation-based) 3.蒸馏机制3.1 离线蒸馏3.2 在线蒸馏3.3 自蒸馏 4.教师-学生架构5.蒸馏算法5.1 对抗性蒸馏(Adversarial Dis…...

jupyter notebook中markdown改变图像大小
文章目录 🕮原始图像🕮改变图像大小🕮使图像靠左 在 jupyter notebook中,导入的图片过大,想要改变图像的大小 🕮原始图像 🕮改变图像大小 复制小括号里面的内容到src后面,满足<…...

SpringGateWay——yml文件配置详解
Spring Gateway 是一个基于 Spring 框架的网关服务,主要作用是将流量路由到不同的微服务中。它的灵活性和可扩展性使它成为构建云原生应用架构的不二之选。 下面是 Spring Gateway 的 yml 文件配置参数详解: spring:cloud: gateway: routes: # 路由相…...
Haproxy实现七层负载均衡
目录 Haproxy概述 haproxy算法: Haproxy实现七层负载 ①部署nginx-server测试页面 ②(主/备)部署负载均衡器 ③部署keepalived高可用 ④增加对haproxy健康检查 ⑤测试 Haproxy概述 haproxy---主要是做负载均衡的7层,也可以做4层负载均衡 apache也可…...

k8s最详细集群部署
安装kubeadm、kubectl、和 kubelet 这里通过百度网盘下载所需要的安装包: 链接: k8s部署包.zip_免费高速下载|百度网盘-分享无限制 提取码: 0000 1、下载部署包到本地后,在k8s部署包/k8s目录下 执行此yum命令安装:yum localinstall ./*.r…...

Redis底层数据结构:字典
在 Redis 中,字典(Dictionary)是一种常用的底层数据结构,它被用于实现 Redis 的哈希表(Hash Table)数据结构。字典用于存储键值对,它提供了快速的键值查找、插入和删除操作。 Redis 字典的特点&…...
upload 文件自动上传写法,前后端 下载流文件流
<el-uploadv-model:file-list"fileList":action"app.api/student/student/import":headers"{// Content-Type: multipart/form-data;boundary----split-boundary, 此处切记不要加,否则会造成后端报错 Required request part file is…...

Python文件、文件夹操作汇总
目录 一、概览 二、文件操作 2.1 文件的打开、关闭 2.2 文件级操作 2.3 文件内容的操作 三、文件夹操作 四、常用技巧 五、常见使用场景 5.1 查找指定类型文件 5.2 查找指定名称的文件 5.3 查找指定名称的文件夹 5.4 指定路径查找包含指定内容的文件 一、概览 在…...
CHM Viewer Star 6.3.2(CHM文件阅读)
CHM Viewer Star 是一款适用于 Mac 平台的 CHM 文件阅读器软件,支持本地和远程 CHM 文件的打开和查看。它提供了直观易用的界面设计,支持多种浏览模式,如书籍模式、缩略图模式和文本模式等,并提供了丰富的功能和工具,如…...

第9章 函数-9.5 函数参数的类型
1.位置参数位置参数指的是在函数传递时必须按照正确的顺序将实参传到函数之中,换句话说,调用函数时传入实参的数量和位置都必须和创建函数时的形参保持一致。示例代码如下:# 资源包\Code\chapter9\9.4\0907.pydef myFunc(name, teach):return…...

WarcraftHelper:三步解决魔兽争霸III在现代电脑上的兼容性问题
WarcraftHelper:三步解决魔兽争霸III在现代电脑上的兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸III在现…...

考虑需求响应和碳交易的柔性负荷综合能源系统优化调度模型
考虑需求响应和碳交易的综合能源系统日前优化调度模型 关键词:柔性负荷 需求响应 综合能源系统 参考:私我 仿真平台:MATLAB yalmipcplex 主要内容:在冷热电综合能源系统的基础上,创新性的对用户侧资源进行了细致的划…...

PyTorch 2.8镜像惊艳效果:RTX 4090D下Llama3-8B+Phi-3-Vision多模态推理展示
PyTorch 2.8镜像惊艳效果:RTX 4090D下Llama3-8BPhi-3-Vision多模态推理展示 1. 开篇:专业级深度学习环境 当谈到高性能深度学习环境时,PyTorch 2.8与RTX 4090D的组合堪称当前最强大的配置之一。这个经过深度优化的镜像不仅提供了开箱即用的…...

每月 20 美元技术栈:低成本运营高收益软件公司的秘诀
【导语:在科技行业普遍追求高额融资与复杂架构的当下,Steve Hanov 分享了用每月 20 美元技术栈运营多家月经常性收入达 1 万美元公司的经验,为低成本创业提供了新思路。】精简服务器:告别 AWS 高成本2026 年,启动 AWS …...

201-基于Wasserstein的分布式鲁棒优化:精确刻画风电出力概率分布与混合整数线性规划...
201-基于Wasserstein的分布式鲁棒优化 研究内容:结合Wasserstein距离实现风电出力概率分布模糊集的精确刻画,并运用线性决策规则与强对偶理论将其转换为混合整数线性规划模型求解 注意事项:并没有对全文进行复现,通过算例…...

不要让接口过早失去可选项榔
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...

OpCore Simplify:黑苹果EFI配置的终极简化工具,30分钟快速搭建macOS系统
OpCore Simplify:黑苹果EFI配置的终极简化工具,30分钟快速搭建macOS系统 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 想要在…...
的设计与实现)
Python实战:四种常见滤波器(低通、高通、带通、带阻)的设计与实现
1. 信号处理中的滤波器基础 第一次接触信号处理时,我被各种滤波器搞得晕头转向。直到有一次在调试音频设备时,发现麦克风采集的声音总是带有嗡嗡的杂音,这才真正理解了滤波器的重要性。滤波器就像是一个智能筛子,能够帮我们分离出…...

从零开始:使用Retinaface+CurricularFace实现Python爬虫人脸数据采集
从零开始:使用RetinafaceCurricularFace实现Python爬虫人脸数据采集 1. 引言 在当今数字化时代,人脸数据已成为许多智能应用的核心基础。无论是人脸识别门禁系统、智能相册分类,还是虚拟试妆应用,都需要大量高质量的人脸数据作为…...