Python文件、文件夹操作汇总
目录
一、概览
二、文件操作
2.1 文件的打开、关闭
2.2 文件级操作
2.3 文件内容的操作
三、文件夹操作
四、常用技巧
五、常见使用场景
5.1 查找指定类型文件
5.2 查找指定名称的文件
5.3 查找指定名称的文件夹
5.4 指定路径查找包含指定内容的文件
一、概览
在工作中经常会遇到对文件,文件夹操作,在文件使用多时,使用python脚本是一种很便捷的方法,也可以实现一些工具如everything,notepad++无法实现的功能,更加灵活。本文将针对相关的基础操作进行介绍以及演示,其他的各种场景也都是基础操作的组合。

注:文章演示例子为window系统下的操作,python版本3.8.3,linux下类似,主要是路径格式和文件权限存在较大差异
二、文件操作
2.1 文件的打开、关闭
import os
#文件的打开、关闭
#方法一 使用open
file=open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v",encoding="utf-8") #打开一个存在的文件counter.v,打开的编码格式为UTF-8,读取文件乱码内容大概率就是编码格式设置的不对,文件对象赋值给file
print("content:", file)
file2=open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\test.v","a") #打开文件test.v,文件如果不存在时会自动创建test.v
file.close() #文件的关闭
#方法二 使用with
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v") as f: #使用with相比方法一,会在执行完后自动释放资源,不会造成资源占用浪费print("content:",f)open函数打开文件各选项配置参数含义

2.2 文件级操作
文件级操作主要包括文件的创建,删除,重命名,复制,移动。
import os
import shutil
#文件的创建,使用open打开要创建的文件,使用参数w即可,如指定路径下创建file.txt
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt",'w'):#文件删除
os.remove(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt")#重命名,将file.txt重命名为file_rename.txt
os.rename(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt",r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\file_rename.txt")#复制文件使用shutil库的copy函数,如将file.txt复制一份到上一级目录Verilog_test中,如果目标路径存在同名文件,则将其覆盖
source=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\file.txt'
dest=r"C:\Users\ZYP_PC\Desktop\verilog_test"
shutil.copy(source,dest) #复制后文件的更新时间为复制的时间
# shutil.copy(source,dest) #可保留复制后文件的原始创建时间等信息 #移动文件使用shutil库的move函数,如将file.txt移动到目录中counter中
source=r'C:\Users\ZYP_PC\Desktop\verilog_test\file.txt'
dest=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
shutil.move(source,dest) #需注意,如果目的路径已存在文件,会移动失败,此时可见对同名文件进行判断2.3 文件内容的操作
文件内容的常用操作包括读取,查找,增加,删除,修改
import os
import shutil
import re
#文件内容的读取
with open(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v",'r') as f:all=f.read() #将整个文件内容作为一个字符串读取print(all)#对单行按字符逐个读取,默认第一行for line in f.readline(5): #可设置读取字符数,如示例读取前5各字符print(line)# 逐行读取文件内容for lines in f.readlines(): #读取的结果f.readlines()为整个文件内容按行为单位的listprint(lines)#内容查找
#指定路径查找包含字符module的行
#方法1 使用字符匹配方法in
pattern = 'module'
path=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter'
with open(path, 'r') as file:for line in file:if pattern in line:print(line) #打印查找到位置所在行
#方法2,使用正则匹配
pattern = 'module'
path=r'C:\Users\ZYP_PC\Desktop\verilog_test\counter'
with open(path, 'r') as f:for line in f:if re.search(pattern, line):print(line) #打印查找到位置所在行#内容修改
#方法1,使用字符自带的replace函数
new_str="new" #替换的字符
old_str="old" #原始字符
path = r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v'
content=""
with open(path, "r", encoding="utf-8") as f:for line in f:if old_str in line:line = line.replace(old_str,new_str)content += line
with open(path,"w",encoding="utf-8") as f: f.write(content) #将修改的内容写入文件中#方法2,使用正则表达中的sub函数
new_str="new" #替换的字符
old_str="old" #原始字符
content=""
path = r'C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v'
with open(path, "r", encoding="utf-8") as f:for line in f:if old_str in line:print(line)line=re.sub(old_str,new_str,line) #使用sub函数进行替换content += line
with open(path,"w",encoding="utf-8") as f: #将修改的内容写入文件中f.write(content)#内容删除,与内容修改类似,将新的替换字符修改为“”即可,内容增加类似三、文件夹操作
文件夹常见操作包括创建,删除,查找,重命名,复制,移动
import shutil
import re
from pathlib import Path
import glob##指定路径下创建文件夹
#方法1
path = r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
folder = "new_folder"
os.mkdir(os.path.join(path, folder)) #如果已存在同名文件则会报错
os.makedirs(os.path.join(path, folder),exist_ok=True) #如果已存在同名文件则跳过
#方法2
path = Path(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter")
folder = "new_folder"
new_folder_path = path / folder
new_folder_path.mkdir()##文件夹删除,删除文件夹counter_bak
path = r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_bak"
shutil.rmtree(path)##文件夹复制,
#方法1,使用shutil库,推荐使用该方法
new_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_new"
old_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
if os.path.exists(new_path): #先对新文件夹进行判断是否已存在,已存在的进行复制会报错print("文件夹已存在")
shutil.copytree(old_path,new_path) #counter目录下所有文件复制到counter_new下,如果counter_new不存在,则会先创建##文件夹改名,和文件改名操作相同,将counter文件夹改名为counter_rename
old_name=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
new_name=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter_rename"
os.rename(old_name,new_name)##文件夹移动,将counter文件夹移动到Desktop目录中
old_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
new_path=r"C:\Users\ZYP_PC\Desktop"
if os.path.exists(old_path): #先对复制的文件夹进行是否存在进行判断shutil.move(old_path,new_path)
else:print("源文件不存在")四、常用技巧
下面将一些在文件,文件夹操作中经常需要用到的函数进行介绍,部分在前面的例子中已经涉及。
import os
import shutil
import re
from pathlib import Path
import glob
##返回当前的工作目录
current_path=os.getcwd()
print(current_path)##判断路径是否有效,可为文件夹路径或文件路径
dir_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
file_path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter.v"
print(os.path.exists(file_path)) #路径有效则返回true,否则返回false##文件、文件夹的判断
#方法1
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter22"
print(os.path.isfile(path)) #判断给定的path是否是文件,是返回True,不是返回False
print(os.path.isdir(path)) #判断给定的path是否是文件夹,是返回True,不是返回False
#方法2 使用pathlib库中的函数Path
path = Path(r'C:\Users\ZYP_PC\Desktop\verilog_test\counter')
path.is_file() #判断给定的path是否是文件,是返回True,不是返回False
path.is_dir() #判断给定的path是否是文件夹,是返回True,不是返回False
#方法3 使用path的splittext函数,前提需先进行路径有效性判断
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter\counter_v"
if os.path.exists(path):print("path路径有效")file_name, suffix = os.path.splitext(path) # splitext将返回文件名和后缀,如果type不为空说明为文件,为空则为文件夹,前提是path是存在的,否则会误判if suffix:print("这是一个文件")else:print("这是一个文件夹")
else:print("path是一个无效地址")##给定一个目录,返回该目录下所有文件的路径,返回结果为列表
path = Path(r'C:\Users\ZYP_PC\Desktop\verilog_test\counter')
files = glob.glob(os.path.join(path, '*'))
print(files)##路径拼接,将多个路径拼接成一个路径
#方法1,使用字符串带的join函数
path1=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
path2="counter.v"
abs_path=os.path.join(path1,path2)
print(abs_path)
#方法2,使用pathlib的Path函数
path1=Path(r"C:\Users\ZYP_PC\Desktop\verilog_test\counter")
path2="counter.v"
abs_path=path1 / path2
print(abs_path)
#方法3,使用字符串直接连接
path1=r"C:\Users\ZYP_PC\Desktop\verilog_test\counter"
path2="counter.v"
abs_path=path1+'\\'+path2 #中间的\\需根据path1是否包含来决定是否需要
print(abs_path)##文件夹遍历
#方法1 使用os.walk函数
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
for root,dirs,file in os.walk(path): #root为当前目录,dirs为当前目录所有的文件夹列表,file为当前目录的所有文件列表print("root:",root)print("dirs:",dirs)print("file:",file)
#方法2 使用os.listdir函数,和os.walk的区别是不会遍历子目录,要实现递归遍历需要定义函数实现
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
for file in os.listdir(path): #root为当前目录,dirs为当前目录所有的文件夹列表,file为当前目录的所有文件列表abs_path=os.path.join(path,file)print("abs_path:",abs_path)
#方法3 使用glob.glob函数,也不会遍历子目录,要实现递归遍历需要定义函数实现
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
files=glob.glob(os.path.join(path,"*")) #获取当前目录下所有的文件和文件夹
print("files:",files)五、常见使用场景
5.1 查找指定类型文件
指定目录下查询所有的txt文件,返回查找到的文件路径,以列表形式保存
import os# 查询指定目录下指定类型的文件,返回查找到结果的绝对路径
def find_type(path,type):file_find=[]for root,dirs,files in os.walk(path): #获取指定目录下的所有文件for file in files:if file.endswith(".txt"):file_find.append(os.path.join(root, file))print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
suffix=".txt"
find_type(path,suffix) #以查找目录project_0307下的所有txt文件为例查询结果
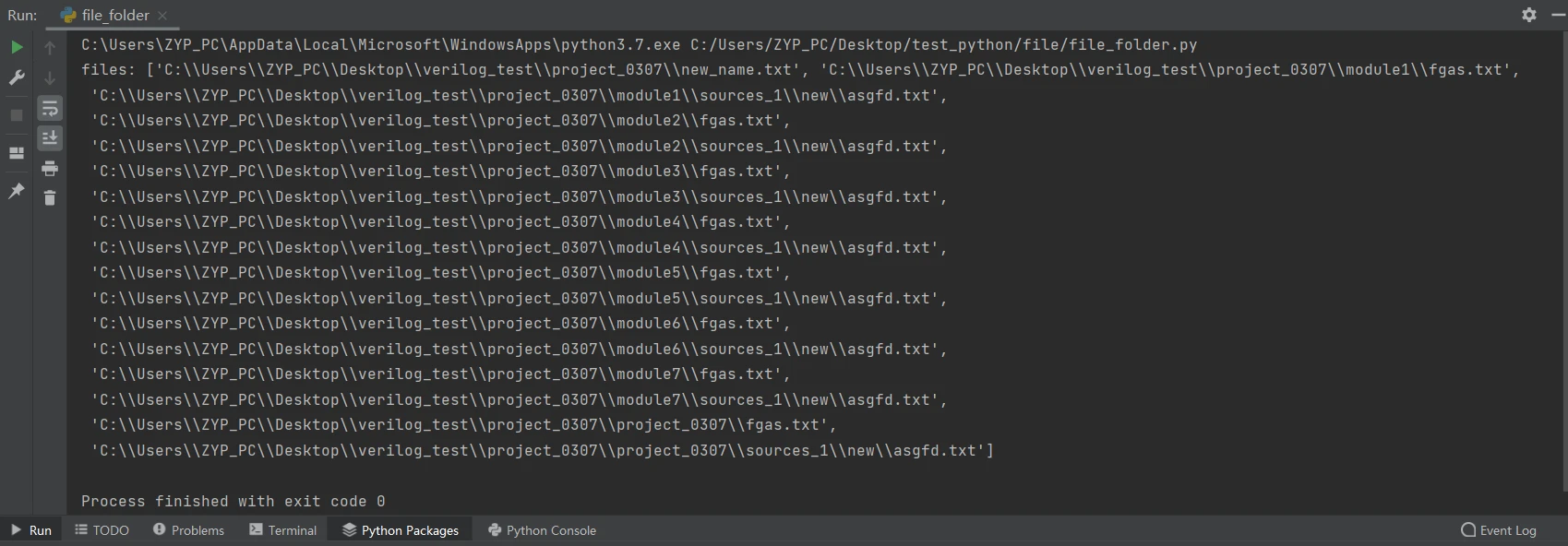
5.2 查找指定名称的文件
和5.1的类似,主要是if后的判断条件进行修改,如在project_0307目录下查找counter_tb.v文件
def find_file(path,f_name):file_find=[]for root,dirs,files in os.walk(path): #获取指定目录下的所有文件for file in files:if file==f_name: #判断条件进行替换,替换为文件名称查找file_find.append(os.path.join(root, file))print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
file="counter_tb.v"
find_file(path,file) #以查找目录project_0307下的counter_tb.v文件为例查询结果

5.3 查找指定名称的文件夹
以在目录project_0307下查找所有名称为sim_1的文件夹为例
# 查询指定目录下指定名称的文件夹,返回查找到结果的绝对路径
def find_dir(path,dir_name):folder_find=[]for root,dirs,files in os.walk(path): #获取指定目录下的所有文件,文件夹for dir in dirs:if dir==dir_name:folder_find.append(os.path.join(root, dir))print("find_result:",folder_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307"
dir_name="sim_1"
find_dir(path,dir_name) #以查找目录project_0307下所有名称为sim_1的文件夹为例查找结果

5.4 指定路径查找包含指定内容的文件
以在目录project_0307下查找包含字符FPGA的log文件
def find_file(path,suffix,content):file_find=[]for root,dirs,files in os.walk(path): #获取指定目录下的所有文件for file in files:if file.endswith(suffix): #判断条件进行替换,替换为文件名称查找abs_path=os.path.join(root, file)with open(abs_path,"r") as f:for line in f:if content in line:file_find.append(abs_path)print("files:",file_find)
path=r"C:\Users\ZYP_PC\Desktop\verilog_test\project_0307" #查找目录
suffix=".log" #查找的文件类型为log类型
content="FPGA" #文件中包含字符FPGA
find_file(path,suffix,content) #以查找目录project_0307下的counter_tb.v文件为例查找结果

相关文章:
Python文件、文件夹操作汇总
目录 一、概览 二、文件操作 2.1 文件的打开、关闭 2.2 文件级操作 2.3 文件内容的操作 三、文件夹操作 四、常用技巧 五、常见使用场景 5.1 查找指定类型文件 5.2 查找指定名称的文件 5.3 查找指定名称的文件夹 5.4 指定路径查找包含指定内容的文件 一、概览 在…...
CHM Viewer Star 6.3.2(CHM文件阅读)
CHM Viewer Star 是一款适用于 Mac 平台的 CHM 文件阅读器软件,支持本地和远程 CHM 文件的打开和查看。它提供了直观易用的界面设计,支持多种浏览模式,如书籍模式、缩略图模式和文本模式等,并提供了丰富的功能和工具,如…...
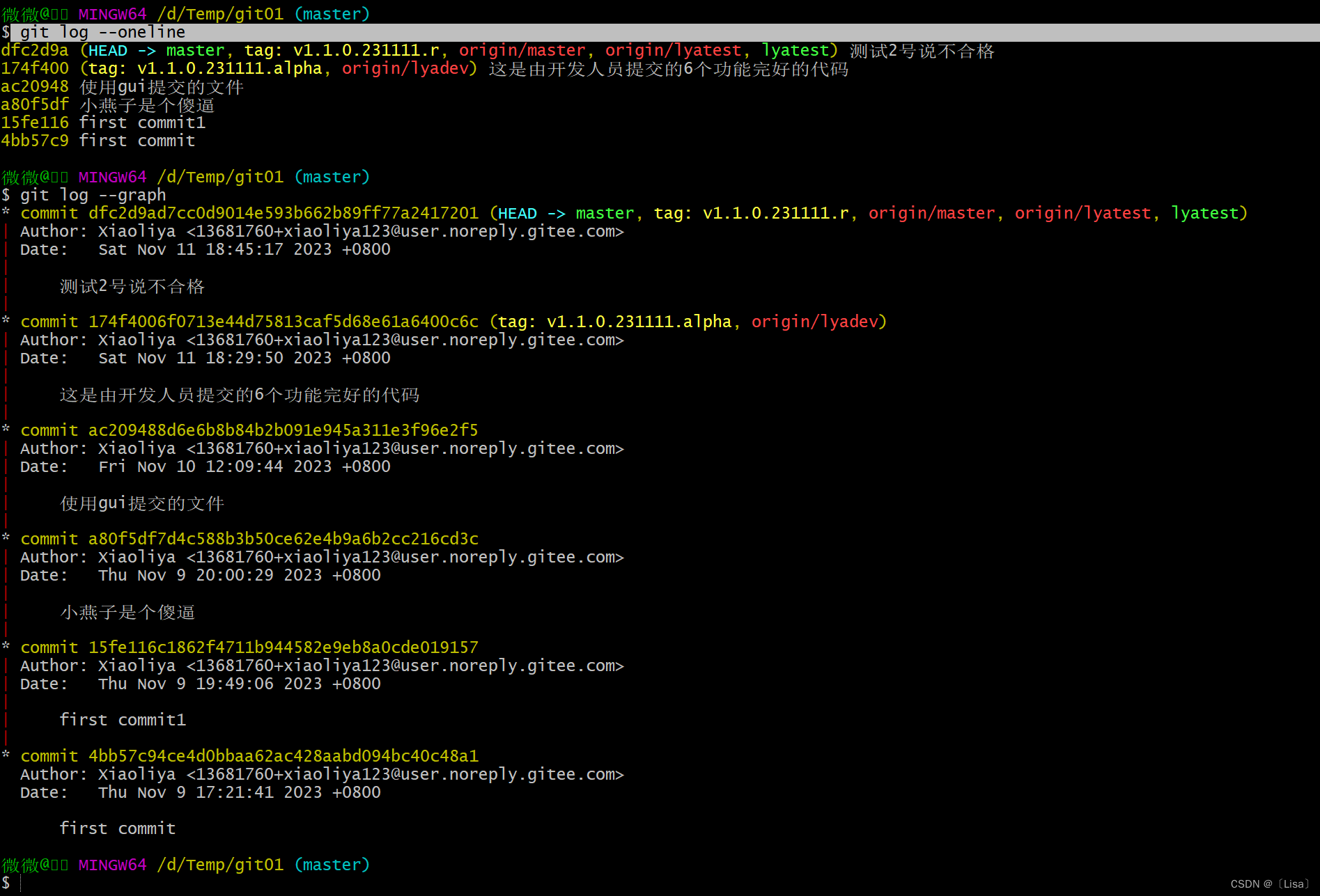
【GIT】git分支命令,使用分支场景介绍git标签介绍,git标签命令,git标签使用的场景git查看提交历史
目录 一,git分支命令,使用分支场景介绍 二,git标签介绍,git标签命令,git标签使用的场景 三,git查看提交历史 前言: 今天我们来聊聊关于Git 分支管理。几乎每一种版本控制系统都以某种形式支持…...

Zeitgeist ZTG Token以及其预测市场加入Moonbeam生态
波卡上的首选多链开发平台Moonbeam宣布与Zeitgeist达成XCM集成,将ZTG Token引入Moonbeam。此集成将使波卡内的Moonbeam和Zeitgeist网络之间的流动性得以流动,并通过Moonbeam的互连合约实现远程链集成。 Zeitgeist是一个基于波卡的Substrate区块链框架构…...

AM@方向导数概念和定理
文章目录 abstract方向导数二元函数方向导数偏导数是方向导数的特例偏导数存在一定有对应的方向导数存在方向导数存在不一定有偏导数存在例 三元函数方向导数例 方向导数存在定理和计算公式证明二元函数三元函数 abstract 方向导数的概念,定理和计算公式方向导数是对偏导的补充…...
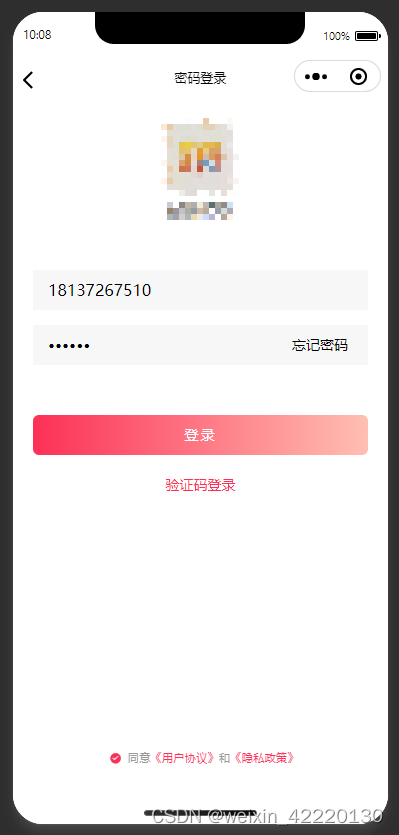
微信小程序隐私政策不合规,应当由用户自主阅读后自行选择是否同意隐私政策协议,不得默认强制用户同意
小程序隐私政策不合规,默认自动同意《用户服务协议》及《隐私政策》,应当由用户自主阅读后自行选择是否同意隐私政策协议,不得默认强制用户同意,请整改后再重新提交。 把 登录代表同意《用户协议》和《隐私政策》 改为 同意《用…...

Python中如何判断两个对象的内存地址是否一致?
目录 一、引言 二、Python的内存管理 三、对象的比较 四、使用id函数判断内存地址 五、总结 一、引言 在Python中,我们经常需要比较两个对象是否是同一个对象,或者说它们是否在内存中占据同一位置。在理解这个问题之前,我们需要了解Pyt…...
唯美仙侠3D手游2023【仙变3】画面精美/linux服务端+双端+GM后台+运营后台+详细教程
搭建资源下载地址:https://www.ldmzy.com/6618/6618.html...

React组件通信:如何优雅地实现组件间的数据传递
在React应用中,组件通信是至关重要的一部分。通过合适的数据传递和交互方式,我们可以构建出更加灵活和高效的前端应用。本文将介绍React组件通信的各种方式,并提供代码实现,帮助你更好地理解和应用这些技术。 1. 使用props进行父子…...
数据分析实战 | 逻辑回归——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/d…...
;这两行代码有什么区别?)
Eigen::Matrix<double,3,1> F;Eigen::MatrixXd F (3, 2);这两行代码有什么区别?
这两行代码的区别在于定义的矩阵 F 的类型和维度不同。 第一行: Eigen::Matrix<double,3,1> F;这行代码创建了一个3x1的矩阵 F,其中元素类型为 double。这是一个静态大小的矩阵,其维度在编译时确定。 第二行: Eigen::Ma…...

Java Agent - 应用程序代理-笔记
Java Agent - 应用程序代理-笔记 概述说明 Java Agent 又叫做 Java 探针,该功能是 Java 虚拟机提供的一整套后门,通过这套后门可以对虚拟机方方面面进行监控与分析,甚至干预虚拟机的运行。 是在 JDK1.5 引入的一种可以动态修改 Java 字节码…...

gird 卡片布局
场景一:单元格大小相等 这承载了所有 CSS Grid 中最著名的片段,也是有史以来最伟大的 CSS 技巧之一: 等宽网格响应式卡片实现 .section-content {display: grid;grid-template-columns: repeat(auto-fit, minmax(220px, 1fr));gap: 10px; …...
C#医学检验室(LIS)信息管理系统源码
LIS:实验室信息管理系统 (Laboratory Information Management System简称:LIS)。 LIS 是面向医院检验科、检验中心、动物实验所、生物医疗研究所等科研单位研发的集数据采集、传输、存储、分析、处理、发布等功能于一体的信息管理系统。 一、完善的质控: 从样本管理…...

建行广东江门分行:科技赋能,数据助力纠“四风”
为进一步深化落实中央八项规定精神,持续加大“四风”问题查处力度,建行驻江门市分行纪检组根据《广东省分行贯彻落实中央八项规定精神持之以恒纠治“四风”实施方案》(建粤党发〔2023〕1号)安排,对驻在市分行开展“四风…...
》)
3164:练27.1 叮叮当当 《信息学奥赛一本通编程启蒙(C++版)》
3164:练27.1 叮叮当当 《信息学奥赛一本通编程启蒙(C版)》 【题目描述】 松鼠老师和尼克玩报数游戏。松鼠老师数到2的倍数时,尼克就说“叮叮”;松鼠老师数到3的倍数时,尼克就说“当当”;松鼠老…...
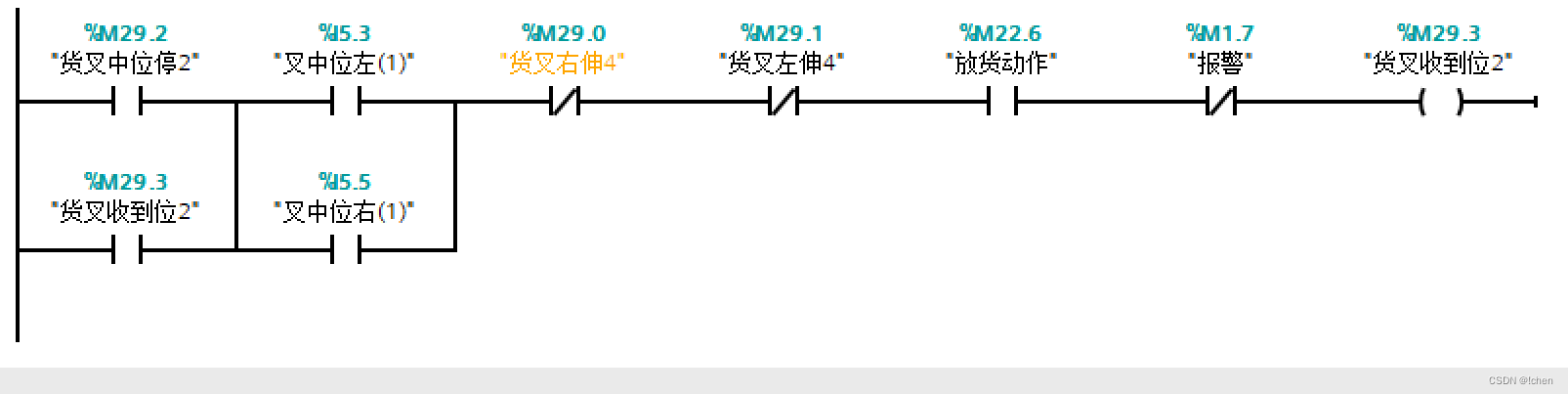
立体库堆垛机放货动作控制程序功能
放货动作程序功能块 DB11.DBX0.0 为左出货台有货 DB11.DBX1.0 为右出货台有货 左出货台车就位 DB11.DBX0.2 右出货台车就位 DB11.DBX1.2 左出货台车就位 DB11.DBX0.2 右出货台车就位 DB11.DBX1.2 左出货台车就位 DB11.DBX0.2 右出货台车就位 DB11.DBX1.2...

MySQL数据库干货_22——MySQL的用户管理
MySQL的用户管理 MySQL 是一个多用户的数据库系统,按权限,用户可以分为两种: root 用户,超级管理员,和由 root 用户创建的普通用户。 用户管理 创建用户 CREATE USER username IDENTIFIED BY password;查看用户 S…...
基于ubuntu 22, jdk 8x64搭建图数据库环境 hugegraph--google镜像chatgpt
基于ubuntu 22, jdk 8x64搭建图数据库环境 hugegraph download 环境 uname -a #Linux whiltez 5.15.0-46-generic #49-Ubuntu SMP Thu Aug 4 18:03:25 UTC 2022 x86_64 x86_64 x86_64 GNU/Linuxwhich javac #/adoptopen-jdk8u332-b09/bin/javac which java #/adoptopen-jdk8u33…...

4. 深度学习——优化函数
机器学习面试题汇总与解析——优化函数 本章讲解知识点 什么是优化函数?为什么要使用优化函数?详细讲解优化函数优化函数总结梯度下降算法的 batch size 总结本专栏适合于Python已经入门的学生或人士,有一定的编程基础。本专栏适合于算法工程师、机器学习、图像处理求职的学…...
)
【仅剩72小时解锁】:2026奇点大会未公开微调训练日志样本集(含错误梯度、loss突变、token漂移原始记录)
第一章:2026奇点智能技术大会:大模型个性化微调 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,大模型个性化微调成为核心议题之一。与传统全量微调不同,本届大会重点展示了低秩适配(LoRA&…...

Spring IOC 源码学习 声明式事务的入口点耙
springboot自动配置 自动配置了大量组件,配置信息可以在application.properties文件中修改。 当添加了特定的Starter POM后,springboot会根据类路径上的jar包来自动配置bean(比如:springboot发现类路径上的MyBatis相关类ÿ…...
)
2026奇点大会闭门报告流出:CoT在金融风控场景的思维断裂点图谱(附3类高危链式漏洞修复模板)
第一章:2026奇点智能技术大会:大模型思维链CoT 2026奇点智能技术大会(https://ml-summit.org) CoT如何重塑大模型的推理能力 思维链(Chain-of-Thought, CoT)已从提示工程技巧演进为大模型原生推理范式。在2026奇点大会上&#x…...

Janus-Pro-7B快速上手:3步完成AI编程环境部署与Hello World
Janus-Pro-7B快速上手:3步完成AI编程环境部署与Hello World 你是不是也对那些能写代码、能聊天的AI模型感到好奇,但一看到复杂的部署教程就头疼?觉得要配置一堆环境、安装各种依赖,门槛太高? 别担心,今天…...

TVA思维之魂:让 TVA 成为制造业质量升级核心引擎
AI智能体视觉检测系统(TVA) 在制造业质量管理中的应用,绝非 “买设备、装产线” 的简单操作,而是一项覆盖选型、标准、数据、运维、全链条管控、团队建设的系统工程。多数企业陷入的各类误区与盲点,本质上是对 TVA 核心…...

从Kvasir-SEG到临床辅助:基于U-Net的鼻息肉分割实战与调优
1. 医学图像分割的挑战与机遇 鼻息肉分割在临床诊断中具有重要意义,但传统的人工标注方式耗时耗力。作为一名长期从事医学影像分析的开发者,我深刻理解医生们面临的困境——每天需要处理大量影像数据,却缺乏高效精准的辅助工具。Kvasir-SEG数…...
)
LeetCode--28.找出字符串中第一个匹配项的下标(字符串/KMP算法)
28.找出字符串中第一个匹配项的下标 题目描述 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 示例 1&…...

深夜告警炸裂?这份Linux故障排查“作战地图”请收好匚
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。 查询参数/dishes?spicytrue&typeSichuan -> …...

Golang怎么理解GC垃圾回收机制_Golang如何分析和优化Go的内存回收性能【详解】
Go GC 不会立即归还内存给操作系统,而是在空闲超时(默认5分钟)或内存压力突增(如设置GOMEMLIMIT)时由scavenger触发;pprof不显示mmap/cgo等OS层内存,RSS高于HeapSys 20%以上通常表明存在此类问题…...

终极指南:5分钟用AKShare构建你的第一个金融数据自动化分析系统
终极指南:5分钟用AKShare构建你的第一个金融数据自动化分析系统 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirro…...