Clickhouse学习笔记(3)—— Clickhouse表引擎
前言:
有关Clickhouse的前置知识详见:
1.ClickHouse的安装启动_clickhouse后台启动_THE WHY的博客-CSDN博客
2.ClickHouse目录结构_clickhouse 目录结构-CSDN博客
Cickhouse创建表时必须指定表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
数据一般存储在本地,默认路径是
/var/lib/clickhouse/
除此之外也可以集成一些外部的数据库,如Hive,MySQL等
- 支持哪些查询以及如何支持
数组在mergetree引擎中无法使用
- 并发数据访问
- 索引的使用(如果存在)
- 是否可以执行多线程请求
- 数据复制参数
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景
MergeTree*(合并树)
MergeTree支持索引和分区
建表语句如下:
create table t_order_mt(id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime)engine = MergeTree partition by toYYYYMMDD(create_time) primary key(id) order by (id,sku_id);需要注意的是,clickhouse中主键会自动创建索引,但并不唯一;
而且order by设置的排序是在分区内排序
插入数据
insert into t_order_mt values \
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');进行查询:

可以看到通过命令行查询出的数据可以明显观察到分区
语法知识
MergeTree | ClickHouse Docs
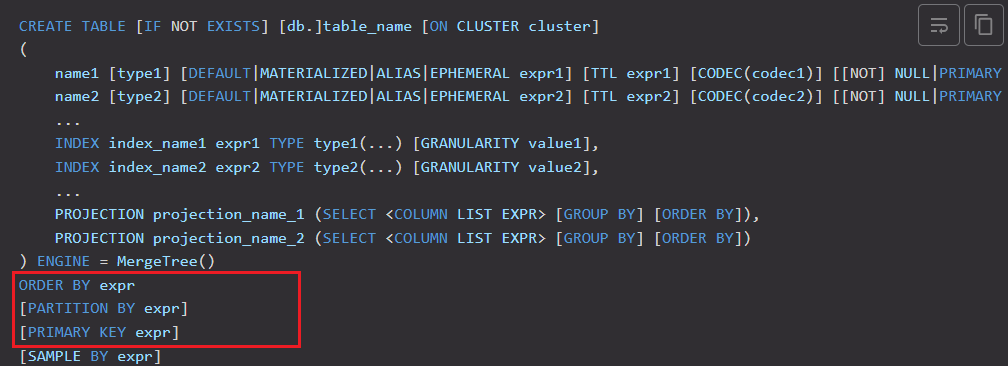
可以看到,primary key 和 partition by字段都不是必须的,但order by字段是必须的
分区合并
分区的目的主要是降低扫描的范围,优化查询速度
在hive中,分区是通过HDFS中分目录实现的;clickhouse中也是通过分目录实现的,只不过是在本地磁盘
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中
具体操作
向表中插入数据:
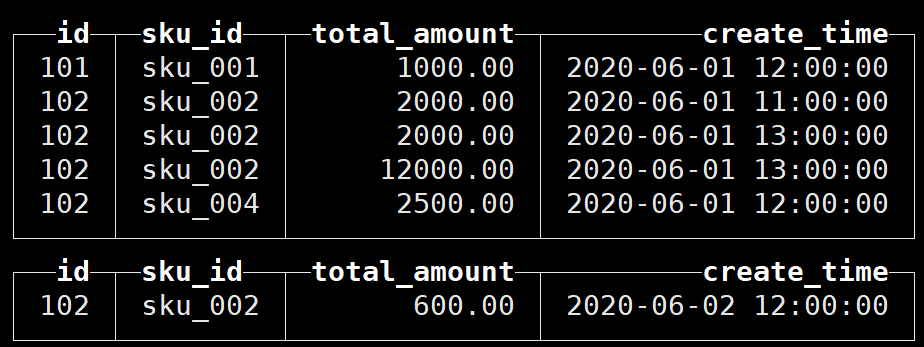
在本地按分区存储数据:

再次插入数据:
可以看到数据并没有纳入任何分区,这是因为任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区;写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作
也可以手动通过 optimize 执行,把临时分区的数据,合并到已有分区中:
optimize table xxxx final
详细语法见:OPTIMIZE Statement | ClickHouse Docs
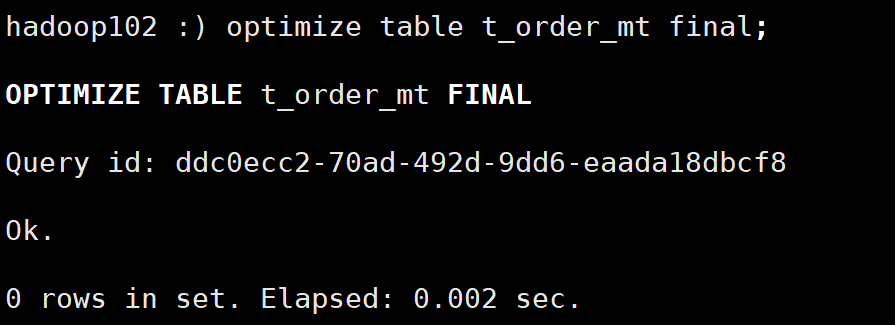
查看数据文件可以看到合并后的分区数据:
可以看到最小分区块编号、最大分区块编号和合并层级都发生了变化
需要注意:手动执行分区合并后会生成新的数据文件,但过期数据不会立即删除
等到自动合并操作执行后,过期数据就会被删除了;因此过一段时间再去查看:

除此之外,optimize还可以指定要合并的分区:
optimize table xxxx PARTITION partition final;
示例:
插入一些数据,目前的分区如下:
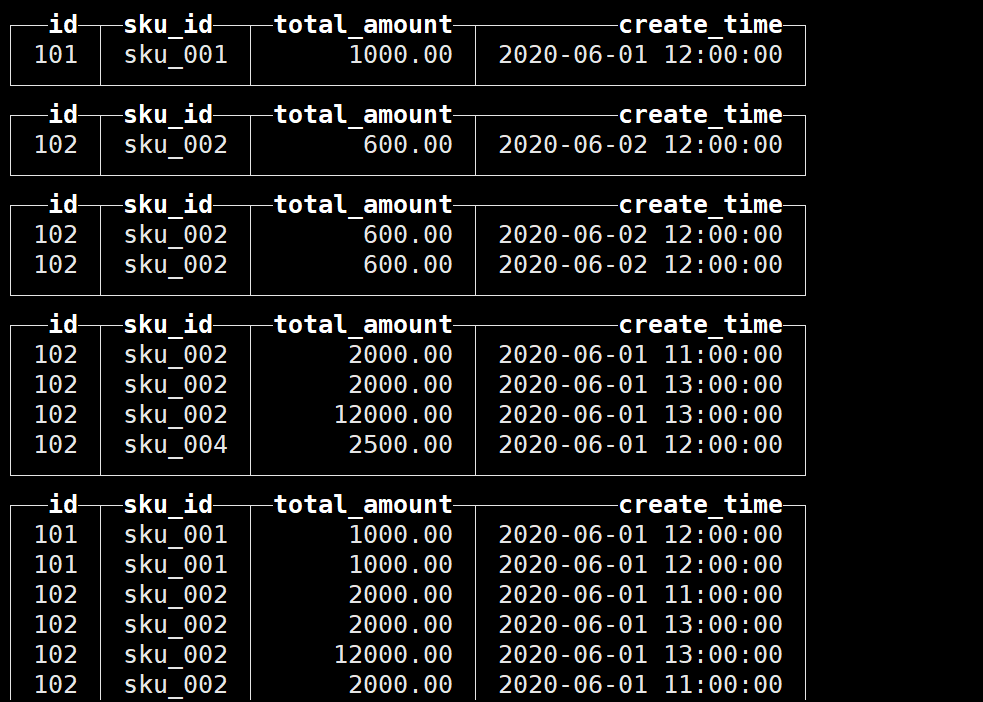
接下来只合并分区id为20200601的数据:
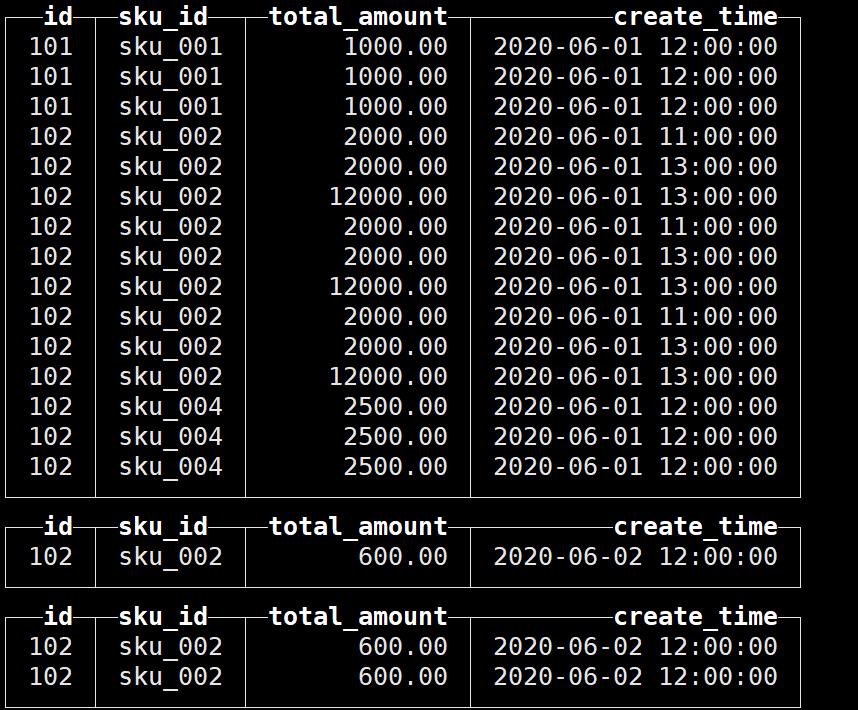
optimize table t_order_mt partition '20200601' final;
合并结果如下:
primary key
MergeTree | ClickHouse Docs
- 只提供了数据的一级索引,但是却不是唯一约束
- 主键的设定主要依据是查询语句中的 where 条件,根据条件通过对主键进行某种形式的二分查找,能够定位到对应的
index granularity避免了全表扫描
index granularity:索引粒度;也就是在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192;官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据
稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描
order by
- order by进行分区内排序,是必须设置的(因为clickhouse使用稀疏索引,如果数据无序,无法根据索引来进行定位)
- 主键必须是 order by 字段的前缀字段
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
假如主键是sku_id,那么可以发现数据在主键维度上是无序的,索引依然无法定位
二级索引
clickhouse从v20.1.2.4 开始全面支持二级索引
创建二级索引的语法:
INDEX a total_amount TYPE minmax GRANULARITY 5索引名 对应的列 二级索引的类型 粒度
注意:这里的粒度指的是二级索引相对于一级索引的粒度
测试
建表
create table t_order_mt2( \id UInt32,\sku_id String,\total_amount Decimal(16,2),\create_time Datetime,\
INDEX a total_amount TYPE minmax GRANULARITY 5\
) engine =MergeTree\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);插入数据:
insert into t_order_mt2 values \
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');测试二级索引是否发挥作用:
clickhouse-client --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900., 2)';可以看到:

index a在查询过程中起到了粒度划分的作用;
TTL
MergeTree | ClickHouse Docs
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能
对于表和列都可以指定TTL;
指定列的TTL(建表时)
TTL time_column + interval
建表测试:
create table t_order_mt3(\id UInt32,\sku_id String,\total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,\create_time Datetime \
) engine =MergeTree\
partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);对total_amount列设置了TTL
插入数据:
insert into t_order_mt3 values \
(106,'sku_001',1000.00,'2023-07-31 20:45:10'),\
(107,'sku_002',2000.00,'2023-07-31 20:45:10'),\
(110,'sku_003',600.00,'2023-07-31 20:45:10');插入完成后可以正常查询到数据:
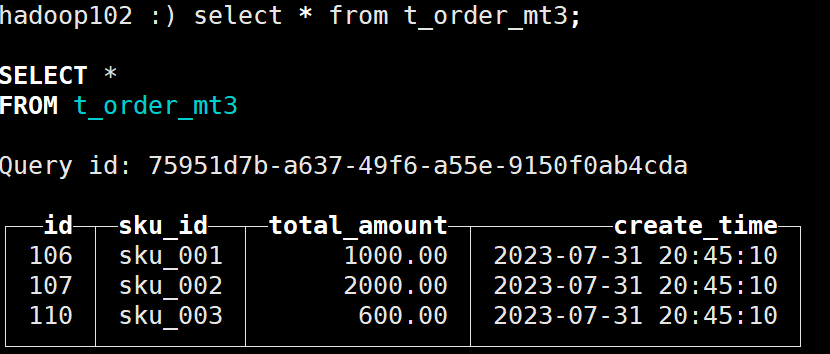
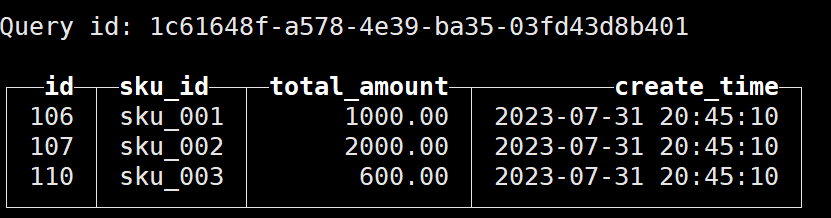
等待到20:45:20之后再次查询:
发现依然能查询到数据:
可能是因为尚未合并导致的,因此手动合并:
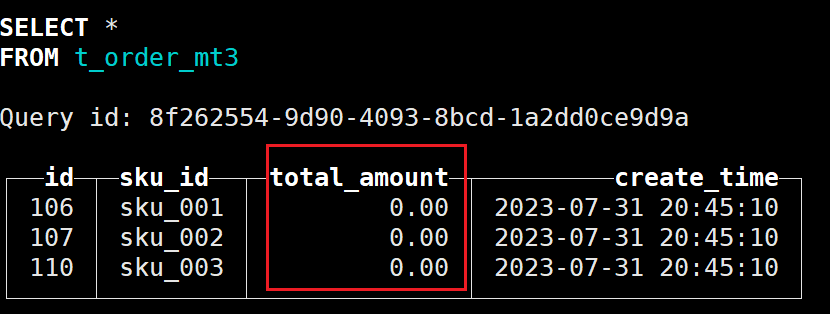
optimize table t_order_mt3 final
发现字段值已经清空:
如果没有反应,可以尝试重启以下clickhouse的服务器,因为TTL操作是单独开启一个进程去完成的,如果机器资源较少,可能出现应答不及时的情况;
修改列的TTL
语法:
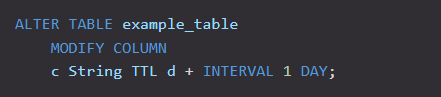
通过MODIFY COLUMN实现,简单来说就是重新定义一下这个列;
指定表的TTL
语法:

就是在ORDER BY后面设置TTL即可
官网给出了TTL到达后的三种策略
DELETE:删除对应数据
TO DISK 'aaa':将数据移动到磁盘'aaa'
TO VOLUME 'bbb':将数据移动到磁盘'bbb'
修改表的TTL
语法:

ReplacingMergeTree(去重)
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是
多了一个去重的功能(根据order by字段进行去重,而不是主键)
去重时机:数据的去重只会在合并的过程中出现(合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理)
在新版本中插入数据时会先进行一次去重
去重范围:分区内去重,无法跨分区去重
测试
创建表,指定引擎为ReplacingMergeTree
create table t_order_rmt(\id UInt32,\sku_id String,\total_amount Decimal(16,2) ,\create_time Datetime \
) engine =ReplacingMergeTree(create_time)\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的
如果不填版本字段,默认按照插入顺序保留最后一条
插入数据:
insert into t_order_rmt values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
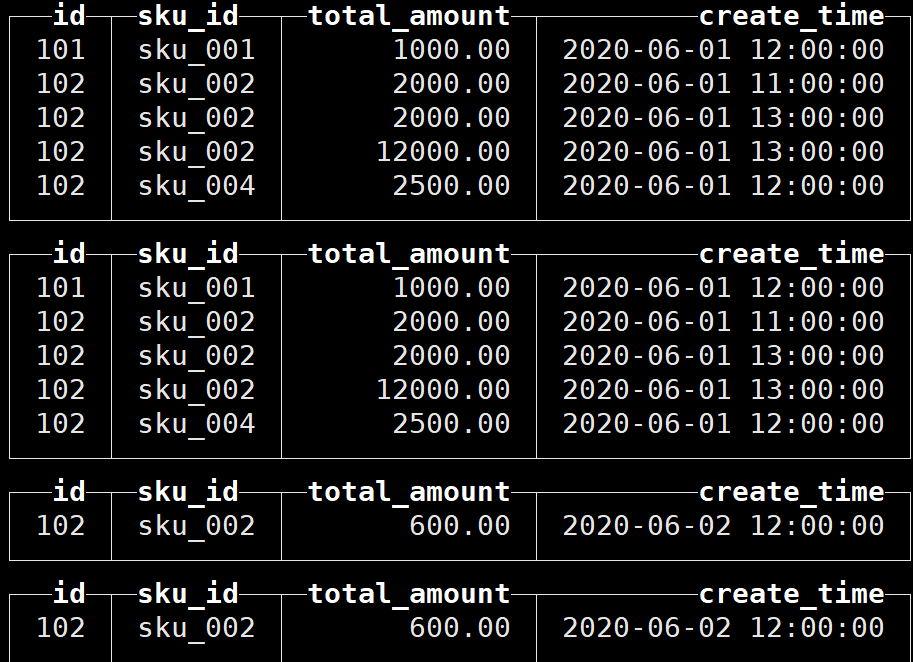
(102,'sku_002',600.00,'2020-06-02 12:00:00');查询结果如下:
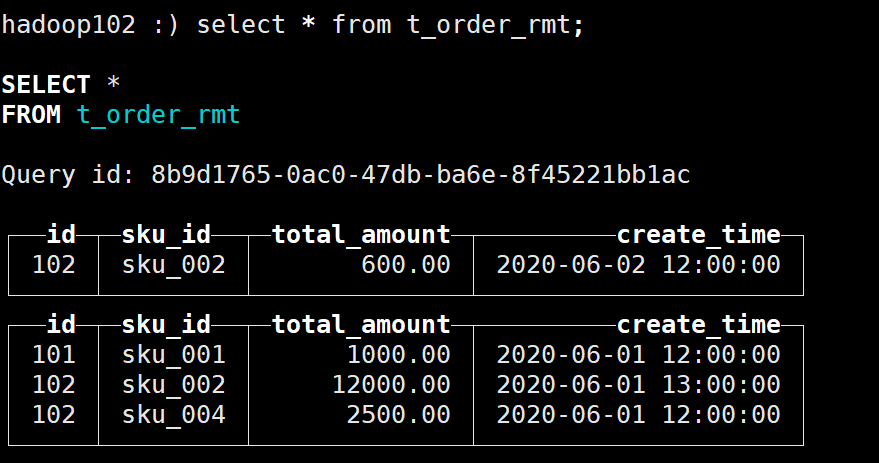
与下图对比可知在插入数据时已经进行了去重
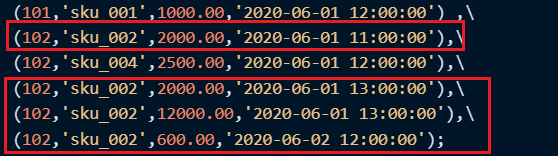
注意到有两条数据的版本字段相同:

最终保留的数据是:
![]()
因此可以看到,但版本字段相同时,按照插入顺序保留最后一条
接下来再次插入数据,查询结果如下:
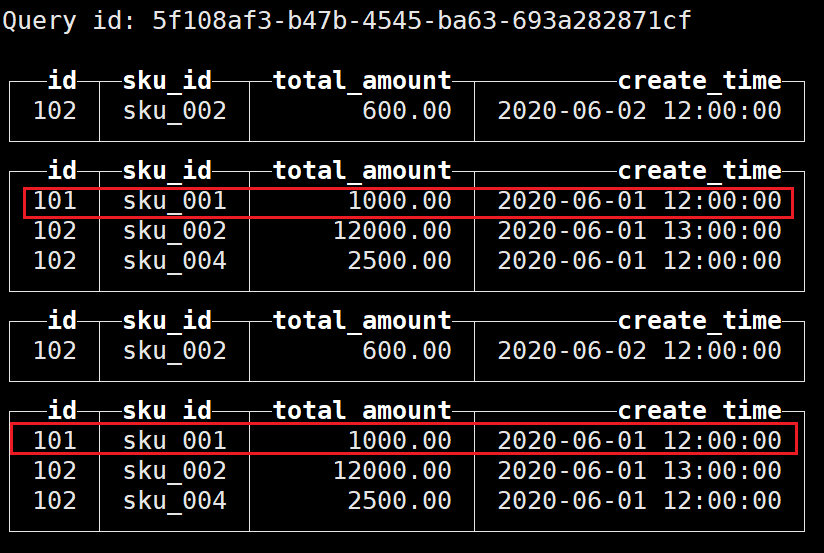
可以看到同一分区内的数据并未进行去重
因此手动执行合并后再查询:

可以看到已经进行了去重;
SummingMergeTree(聚合)
适用于不查询明细,只关心以维度进行汇总聚合结果的场景,可以避免因临时聚合而带来的开销
测试
创建表,指定引擎为SummingMergeTree
create table t_order_smt(\id UInt32,\sku_id String,\total_amount Decimal(16,2) ,\create_time Datetime \
) engine =SummingMergeTree(total_amount)\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id,sku_id );注意,SummingMergeTree()中的字段为聚合字段,即在哪一维度上进行聚合,这里指定的是total_amount,也可以指定多个字段,但必须是数值类型;
如果不填,以所有非维度列且为数字列的字段为汇总数据列
插入数据:
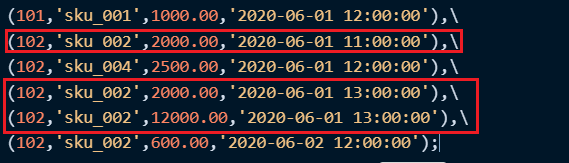
insert into t_order_smt values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');查询结果如下:
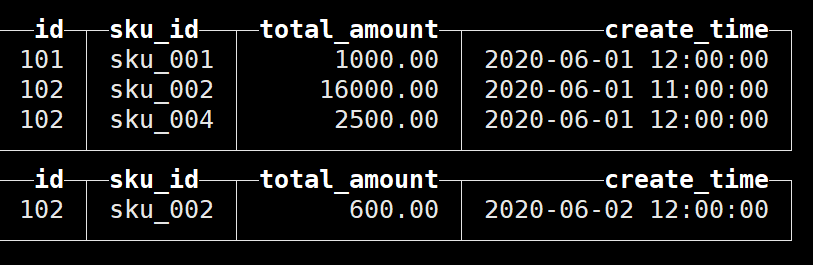
首先可以发现,SummingMergeTree是以order by的列作为维度列进行聚合的,而且是分区内聚合;
同时可以看到,同一分区内的相应数据已经进行了聚合:
👇
![]()
除了维度列和聚合字段之外,create_time这一列保留最早插入的一行;
再次插入数据进行测试:
可以看到并未进行聚合:
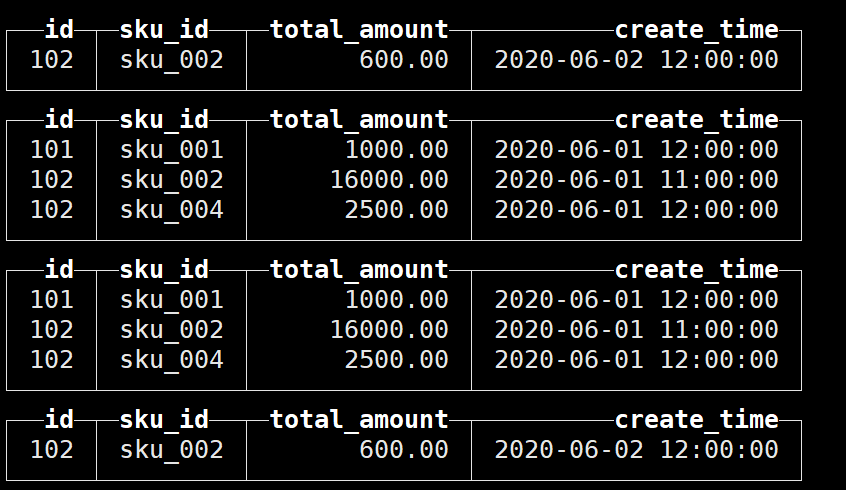
这是因为SummingMergeTree和ReplacingMergeTree一样,都是只有在同一批次插入(新版本)或分片合并时才会进行聚合
因此手动执行合并:optimize table t_order_smt final
可以看到成功聚合:
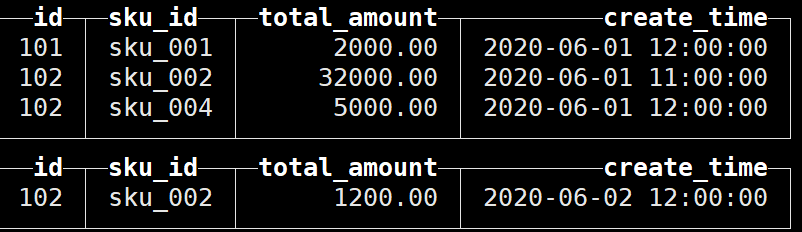
根据聚合表的特性,在实际开发中设计聚合表时,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳
相关文章:
Clickhouse学习笔记(3)—— Clickhouse表引擎
前言: 有关Clickhouse的前置知识详见: 1.ClickHouse的安装启动_clickhouse后台启动_THE WHY的博客-CSDN博客 2.ClickHouse目录结构_clickhouse 目录结构-CSDN博客 Cickhouse创建表时必须指定表引擎 表引擎(即表的类型)决定了&…...

WebSocket是什么以及其与HTTP的区别
新钛云服已累计为您分享774篇技术干货 HTTP协议 HTTP是单向的,客户端发送请求,服务器发送响应。举个例子,当用户向服务器发送请求时,该请求采用HTTP或HTTPS的形式,在接收到请求后,服务器将响应发送给客户端…...

Flutter 实战:构建跨平台应用
文章目录 一、简介二、开发环境搭建三、实战案例:开发一个简单的天气应用1. 项目创建2. 界面设计3. 数据获取4. 实现数据获取和处理5. 界面展示6. 添加动态效果和交互7. 添加网络错误处理8. 添加刷新功能9. 添加定位功能10. 添加通知功能11. 添加数据持久化功能 《F…...

Python中68个内置函数的使用与归类
前言 在Python解释器中内置的、可以直接使用的函数。这些函数不需要额外的导入或安装,可以直接在Python代码中调用。Python内置函数包括了很多常用的功能,比如对数据类型的操作、数学运算、字符串处理、文件操作等。一些常见的内置函数包括print()、len…...

AGV無人搬送車控制系统Pytorn
import tkinter as tk import Main import monitoring # メインウィンドウを作成 root tk.Tk() root.title("AGV無人搬送車控制系统 ver1.0.0") # ウィンドウサイズを固定 root.geometry("501x340") root.resizable(False, False) # サイズ変更を…...
使用MVS-GaN HEMT紧凑模型促进基于GaN的射频和高电压电路设计
标题:Facilitation of GaN-Based RF- and HV-Circuit Designs Using MVS-GaN HEMT Compact Model 来源:IEEE TRANSACTIONS ON ELECTRON DEVICES(19年) 摘要—本文阐述了基于物理的紧凑器件模型在研究器件行为细微差异对电路和系统…...

Android13分享热点设置安全性为wpa3
Android13分享热点设置安全性为wpa3 文章目录 Android13分享热点设置安全性为wpa3一、前言热点WPA3加密类型是需要底层硬件支持的。Wifi WPA3 和 热点 WPA3 是不一样的分享初衷 二、代码分析1、应用代码中热点设置WPA3 加密格式报错部分日志信息: 2、系统代码分析&a…...

2023-11-12 LeetCode每日一题(Range 模块)
2023-03-29每日一题 一、题目编号 715. Range 模块二、题目链接 点击跳转到题目位置 三、题目描述 Range模块是跟踪数字范围的模块。设计一个数据结构来跟踪表示为 半开区间 的范围并查询它们。 半开区间 [left, right) 表示所有 left < x < right 的实数 x 。 实…...

【六袆 - Framework】Angular-framework;前端框架Angular发展的由来0001;
Angular发展介绍,Angular17新特性 官方文档Angular框架发展的由来何为结构化、模块化 Angular17新特性 English unit Embarking on the journey of deep technical learning requires a well-structured approach, applicable to any programming language. The key…...

JAVA集合学习
一、结构 List和Set继承了Collection接口,Collection继承了Iterable Object类是所有类的根类,包括集合类,集合类中的元素通常是对象,继承了Object类中的一些基本方法,例如toString()、equals()、hashCode()。 Collect…...
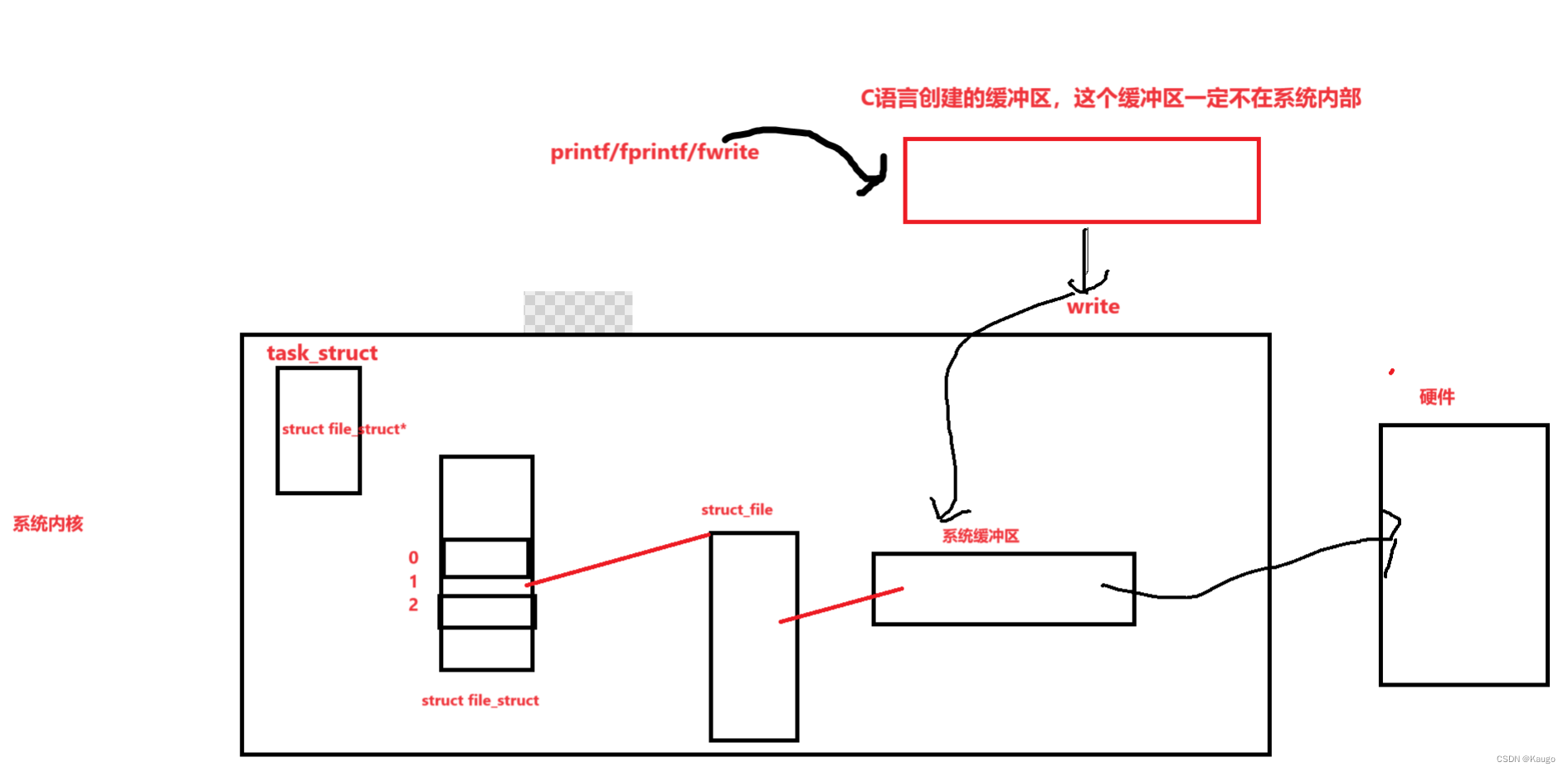
【Linux】语言层面缓冲区的刷新问题以及简易模拟实现
文章目录 前言一、缓冲区刷新方法分类a.无缓冲--直接刷新b.行缓冲--不刷新,直到碰到\n才刷新c.全缓冲--缓冲区满了才刷新 二、 缓冲区的常见刷新问题1.问题2.刷新本质 三、模拟实现1.Mystdio.h2.Mystdio.c3.main.c 前言 我们接下来要谈论的是我们语言层面的缓冲区&…...
Mac安装与配置eclipse
目录 一、安装Java:Mac环境配置(Java)----使用bash_profile进行配置(附下载地址) 二、下载和安装eclipse 1、进入eclipse的官网 (1)、点击“Download Packages ”编辑 (2)、找到macOS选择符合自己电脑的框架选项…...
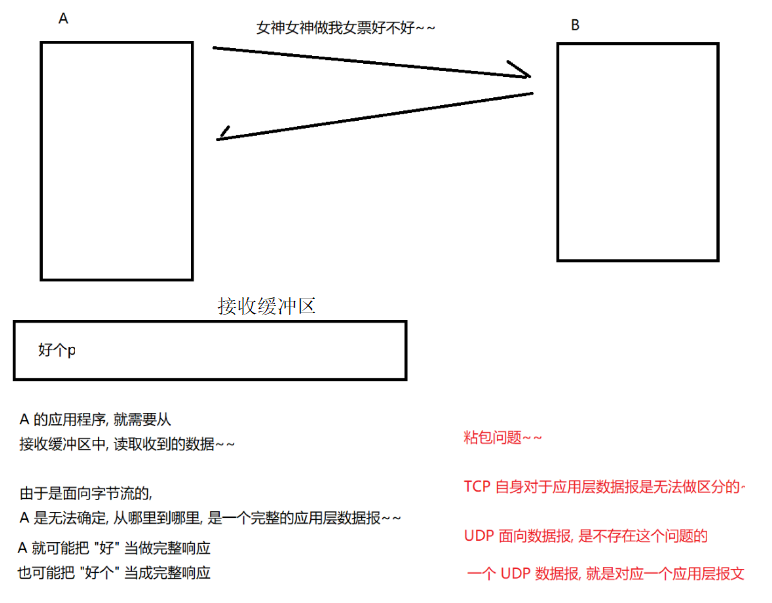
TCP协议(建议收藏)
1. TCP特点 有连接:需要双方建立连接才能通信,在socket编程中服务端new ServerSocket(port)需要绑定端口,在客服端new Socket(serverIp, serverPort)与服务端建立连接可靠传输:确认应答机制,超时重传机制面向字节流&a…...
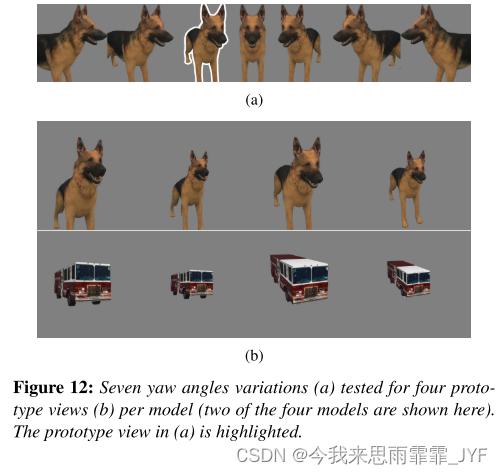
Interactive Analysis of CNN Robustness
Interactive Analysis of CNN Robustness----《CNN鲁棒性的交互分析》 摘要 虽然卷积神经网络(CNN)作为图像相关任务的最先进模型被广泛采用,但它们的预测往往对小的输入扰动高度敏感,而人类视觉对此具有鲁棒性。本文介绍了 Pert…...

Java,多线程,线程的通信机制
线程间通信的理解: 当我们需要多个线程来共同完成一件任务,并且我们希望他们有规律地执行,那么多线程之间需要一些通信机制。可以协调它们的工作,以此实现多线程共同操作一份数据。 关于线程间的通信,以下代码为例&am…...

ArcGIS进阶:栅格计算器里的Con函数使用方法
本实验操作为水土保持功能重要性评价: 所用到的数据包括:土地利用类型数据(矢量)、植被覆盖度数据(矢量)和地形坡度数据(栅格)。 由于实验数据较少,其思路也较为简单&a…...
小程序多文件上传 Tdesign
众所周知,小程序文件上传还是有点麻烦的,其实主要还是小程序对的接口有诸多的不便,比如说,文件不能批量提交,只能一个个的提交,小程序的上传需要专门的接口。 普通的小程序的页面也比普通的HTML复杂很多 现…...

Java多线程锁
AQS 互斥锁,悲观锁 public class Demo1 {// 从0累加到1000 悲观锁static Integer num 0;public static void main(String[] args) {for (int i 0; i < 3; i) {Thread t new Thread(() -> {while (num < 1000) {synchronized (num.getClass()) {if (nu…...

【Docker】Web应用通过jar打包成WAR文件
把当前目录下的所有文件打包成game.war jar -cvfM0 game.war ./ -c 创建war包 -v 显示过程信息 -f -M -0 这个是阿拉伯数字,只打包不压缩的意思 解压game.war jar -xvf game.war 解压到当前目录 环境 RedHat Linux 9 VWWare 8.0 SSH 3.2.9 Putty 0.62 问题…...

Elasticsearch 外部词库文件更新
本文所使用的ES集群环境可在历史文章中获取,采用docker部署的方式。 Elasticsearch 是一个功能强大的搜索引擎,广泛用于构建复杂的全文搜索应用程序。在许多情况下,为了提高搜索引擎的性能和精度,我们可以使用外部词库来定制和扩展…...
)
Xcode开发者福音:Baidu Comate 3.5S实战体验(附iOS项目避坑指南)
Xcode开发者福音:Baidu Comate 3.5S实战体验(附iOS项目避坑指南) 作为一名长期深耕iOS生态的开发者,我经历过无数次Xcode的"玄学报错"和SwiftUI的"神秘崩溃"。直到遇见Baidu Comate 3.5S,这款专为…...
)
别再手动敲命令了!用Docker Compose一键部署MinIO(附Windows/Linux双平台配置)
告别繁琐配置:用Docker Compose三分钟搭建高可用MinIO存储系统 在云原生时代,对象存储已成为现代应用架构的标配组件。MinIO作为高性能、兼容S3协议的开源解决方案,凭借其轻量级特性和企业级功能,从测试环境到生产系统都能看到它…...
)
FAST Planner实战:在ROS Noetic上从零搭建无人机避障仿真环境(附完整代码)
FAST Planner实战:在ROS Noetic上从零搭建无人机避障仿真环境(附完整代码) 当你第一次接触FAST Planner这个强大的无人机轨迹规划框架时,是否曾被复杂的依赖关系和编译错误困扰?本文将带你穿越重重障碍,从…...

从ELK自建到拥抱SLS:我们团队如何省下60%的运维成本并实现秒级告警
从ELK自建到拥抱SLS:我们团队如何省下60%的运维成本并实现秒级告警 当我们的微服务集群规模突破200个节点时,凌晨三点被Elasticsearch集群告警电话吵醒已成常态。JVM老年代GC停顿导致查询延迟飙升、Shard分配不均引发的热点节点、冷数据归档策略失效造成…...

瑜伽主题AI绘画落地案例:雯雯的后宫-Z-Image模型在健康类新媒体中的应用
瑜伽主题AI绘画落地案例:雯雯的后宫-Z-Image模型在健康类新媒体中的应用 1. 引言:当瑜伽内容创作遇上AI绘画 如果你是健康、瑜伽或女性生活方式类新媒体账号的运营者,相信你一定遇到过这样的困境:每天需要大量的高质量配图来吸引…...

2026届学术党必备的六大降AI率网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 第一步努力呈现,先去调整句式结构,要避免那种过于工整的排比还有重复…...
到微服务的演进之路)
SOA架构实战:从企业服务总线(ESB)到微服务的演进之路
SOA架构实战:从企业服务总线(ESB)到微服务的演进之路 当企业IT系统从单体架构迈向分布式架构时,SOA(面向服务的架构)曾是最重要的技术范式之一。然而随着云计算和容器技术的普及,传统的ESB(企业服务总线&am…...

Windows 11终极瘦身指南:用Win11Debloat告别卡顿与隐私烦恼
Windows 11终极瘦身指南:用Win11Debloat告别卡顿与隐私烦恼 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...
被VS Code和NCS v3.0.0正确识别?)
Win11 WSL2 + Ubuntu 24.04 下,如何让nRF开发板(DK)被VS Code和NCS v3.0.0正确识别?
Win11 WSL2环境下nRF开发板与NCS v3.0.0深度集成指南 当嵌入式开发遇上WSL2的Linux高效编译环境,硬件连接往往成为最后一道障碍。本文将彻底解决nRF开发板在Windows主机与WSL2 Ubuntu子系统间的识别难题,打造无缝硬件调试体验。 1. 环境准备与核心工具链…...

书匠策AI:毕业论文写作的“智能魔法棒”,开启学术新纪元!
在学术的浩瀚宇宙中,毕业论文如同璀璨星辰,既照亮了我们求知的道路,也考验着我们的智慧与毅力。然而,撰写一篇高质量的毕业论文并非易事,它需要我们跨越选题迷雾、穿越文献丛林、构建逻辑框架、雕琢内容细节࿰…...