Redis五种数据类型及命令操作(二)
🎈个人公众号:🎈 :✨✨✨ 可为编程✨ 🍟🍟
🔑个人信条:🔑 知足知不足 有为有不为 为与不为皆为可为🌵
🍉本篇简介:🍉 本篇记录Redis五种数据类型及命令操作,如有出入还望指正。
Redis哈希(Hash)
简介
Redis中的Hash是一个键值对集合。Redis Hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似于java里面的Map<String,Object>集合一样,如果内存足够大的话,一个Redis的Hash结构可以存储2的32次幂-1个键值对,相当于40亿条数据,其实Hash类型的vlue在Redis中存储时其存储的还是String类型的字符串。下面就针对Hash的一些命令进行实战化演练。
常用命令
hset:设置多个field的值
hset key field value [field value ...]将哈希表
key中的域field的值设为value。如果
key不存在,一个新的哈希表被创建并进行 hset 操作。如果域
field已经存在于哈希表中,旧值将被覆盖。返回值:
如果
field是哈希表中的一个新建域,并且值设置成功,返回1。如果哈希表中域
field已经存在且旧值已被新值覆盖,返回0。
示例
hget:获取指定filed的值
hget key field
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 18#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hget user name #获取user中的name
"kewei"
hgetall:返回hash表所有的域和值
hgetall key
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 18#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hgetall user #获取user所有信息
1)"name"
2)"kewei"
3)"age"
4)"18"
hmset:和hset类似(已弃用)
hmset key field value [field value ...]
hexists:判断给定的field是否存在,1:存在,0:不存在
hexists key field
查看哈希表
key中,给定域field是否存在。返回值:
如果哈希表含有给定域,返回
1。如果哈希表不含有给定域,或
key不存在,返回0。关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 30#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hexists user name #user中存在name域
(integer)1
127.0.0.1:6379> hexists user address #user中不存在address域,返回0
(integer)0
127.0.0.1:6379> hexists user1 address #user1这个key不存在,返回0
(integer)0
hkeys:列出所有的filed
hkeys key
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 30#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hkeys user #获取user中的所有filed
1)"name"
2)"age"
hvals:列出所有的value
hvals key
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 30#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hvals user #获取user中的所有filed的值列表
1)"kewei"
2)"30"
hlen:返回filed的数量
HLEN key
返回哈希表
key中域的数量。返回值:
哈希表中域的数量。
当
key不存在时,返回0。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 30#哈希表user中设置2个域:name和age,name的值为kewei,age的值为30
(integer)2
127.0.0.1:6379> hlen user
(integer)2
hincrby:filed的值加上指定的增量
hincrby key field increment
为哈希表 key 中的域 field 的值加上增量 increment 。增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0。如果对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误,因此只有当值为整型时才会起作用。
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
返回值:
执行 hincrby 命令之后,哈希表
key中域field的值。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset siteInfo site kewei pv 1000#hash表siteInfo中有2个域:{site:"kewei",pv:1000}
(integer)2
127.0.0.1:6379> hget siteInfo pv #获取siteInfo中pv的值
"1000"
127.0.0.1:6379> hincrby siteInfo pv 10#siteInfo中的pv值增加10
(integer)1010
127.0.0.1:6379> hget siteInfo pv #获取siteInfo中的pv
"1010"
127.0.0.1:6379> hincrby siteInfo uv 500#siteInfo中的uv值增加500,uv这个域不存在,则会先添加,然后再执行hincrby
(integer)500
hsetnx:当filed不存在的时候,设置filed的值
hsetnx key field value
将哈希表
key中的域field的值设置为value,当且仅当域field不存在。若域
field已经存在,该操作无效。如果
key不存在,一个新哈希表被创建并执行 hsetnx 命令。返回值:
设置成功,返回
1。如果给定域已经存在且没有操作被执行,返回
0。关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> hset user name kewei age 30#创建user,包含2个域:name、age
(integer)2
127.0.0.1:6379> hsetnx user name tom #name已存在,设置失败,返回0
(integer)0
127.0.0.1:6379> hget user name #name依旧是kewei
"kewei"
127.0.0.1:6379> hsetnx user address shanghai #address不存在,设置成功
(integer)1
127.0.0.1:6379> hget user address #输出address的值
"shanghai"
数据结构
Hash类型对应的数据结构是2种:一种是ziplist(压缩列表),第二种时hashtable(哈希表)。当存储的数据不多时采用ziplist,当超过配置文件中的阈值时,采用hashtable进行存储。当field-vaklue长度较短个数较少时,使用ziplist,否则使用hashtable。
Redis有序集合(zset/sortedset)
简介
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个分数(score),这个分数(score)被用来按照从最低分到最高分的方式排序集合中的成员。ZSet 有两种不同的实现,分别是ziplist(压缩表)和skiplist(跳表)。具体使用哪种结构进行存储,规则如下:
ziplist满足以下两个条件:
-
[value,score] 键值对数量少于128个
-
每个元素的长度小于 64 字节
skiplist:不满足以上两个条件时使用跳表、组合了 hash 和 skiplist
-
hash 用来存储 value 到 score 的映射,这样就可以在 O(1) 时间内找到 value 对应的分数。
-
skiplist 按照从小到大的顺序存储分数。
-
skiplist 每个元素的值都是 [value,score] 对。
因为元素是有序的,所以可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
常用命令
zadd:添加元素
zadd <key><score1><member1><score2><member2>...
将一个或多个
member元素及其score值加入到有序集key当中。如果某个
member已经是有序集的成员,那么更新这个member的score值,并通过重新插入这个member元素,来保证该member在正确的位置上。
score值可以是整数值或双精度浮点数。如果
key不存在,则创建一个空的有序集并执行 zadd 操作。当
key存在但不是有序集类型时,返回一个错误。返回值:
被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++50 php 70 js #创建名称为topn的zset,添加了5个元素
(integer)5
zrange:score升序,获取指定索引范围的元素
zrange key start top [withscores]
返回存储在有序集合
key中的指定范围的元素。返回的元素可以认为是按score从最低到最高排列,如果得分相同,将按字典排序。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。你也可以使用负数下标,以
-1表示最后一个成员,-2表示倒数第二个成员,以此类推。zrange key 0 -1:可以获取所有元素
withscores:让成员和它的
score值一并返回,返回列表以value1,score1, ..., valueN,scoreN的格式表示可用版本:
>= 1.2.0
时间复杂度:
O(log(N)+M),
N为有序集的基数,而M为结果集的基数。返回值:
指定区间内,带有
score值(可选)的有序集成员的列表。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++ 50 php 70 js #创建名称为topn的zset,添加了5个元素
(integer)5
127.0.0.1:6379> zrange topn 0 -1#按score升序,返回topn中所有元素的值
1)"php"
2)"js"
3)"c"
4)"c++"
5)"java"
127.0.0.1:6379> zrange topn 0 -1 withscores #按score升序,返回所有元素的值以及score
1)"php"
2)"50"
3)"js"
4)"70"
5)"c"
6)"80"
7)"c++"
8)"90"
9)"java"
10)"100"
127.0.0.1:6379> zrange topn 24#返回索引范围[2,4]内的3个元素
1)"c"
2)"c++"
3)"java"
zrevrange:score降序,获取指定索引范围的元素
zrevrange key start stop [WITHSCORES]
返回存储在有序集合
key中的指定范围的元素。返回的元素可以认为是按score最高到最低排列, 如果得分相同,将按字典排序。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。你也可以使用负数下标,以
-1表示最后一个成员,-2表示倒数第二个成员,以此类推。withscores:让成员和它的
score值一并返回,返回列表以value1,score1, ..., valueN,scoreN的格式表示
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++50 php 70 js #创建名称为topn的zset,添加了5个元素
(integer)5
127.0.0.1:6379> zrevrange topn 0-1#按照score降序获取所有元素
1)"java"
2)"c++"
3)"c"
4)"js"
5)"php"
127.0.0.1:6379> zrevrange topn 02#按照score降序获取前3名
1)"java"
2)"c++"
3)"c"
zrangebyscore:按照score升序,返回指定score范围内的数据
zrangebyscore key min max [WITHSCORES][LIMIT offset count]
返回有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列。具有相同
score值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。可选的
LIMIT参数指定返回结果的数量及区间(就像SQL中的SELECT LIMIT offset, count),注意当offset很大时,定位offset的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。可选的
WITHSCORES参数决定结果集是单单返回有序集的成员,还是将有序集成员及其score值一起返回。关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++50 php 70 js #创建名称为topn的zset,添加了5个元素
(integer)5
127.0.0.1:6379> zrangebyscore topn 7090#score升序,获取score位于[70,90]区间中的元素值
1)"js"
2)"c"
3)"c++"
127.0.0.1:6379> zrangebyscore topn 7090 withscores #score升序,获取score位于[70,90]区间中的元素值及score
1)"js"
2)"70"
3)"c"
4)"80"
5)"c++"
6)"90"
127.0.0.1:6379> zrangebyscore topn 7090 withscores limit 12#相当于:select value,score from topn集合 where score>=70 and score<=90 order by score asc limit 1,2
1)"c"
2)"80"
3)"c++"
4)"90"
zrevrangebyscore:按照score降序,返回指定score范围内的数据
zrevrangebyscore key max min [WITHSCORES][LIMIT offset count]
返回有序集
key中,score值介于max和min之间(默认包括等于max或min)的所有的成员。有序集成员按score值递减(从大到小)的次序排列。具有相同
score值的成员按字典序的逆序排列。除了成员按
score值递减的次序排列这一点外, zrevrangebyscore 命令的其他方面和 zrangebyscore 命令一样。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topn 100 java 80 c 90 c++50 php 70 js #创建名称为topn的zset,添加了5个元素
(integer)5
127.0.0.1:6379> zrevrangebyscore topn 10090#score降序,获取score位于[70,90]区间中的元素值
1)"java"
2)"c++"
127.0.0.1:6379> zrevrangebyscore topn 10090 withscores #score降序,获取score位于[70,90]区间中的元素值及score
1)"java"
2)"100"
3)"c++"
4)"90"
zincrby:为指定元素的score加上指定的增量
zincrby key increment member
为有序集
key的成员member的score值加上增量increment。可以通过传递一个负数值
increment,让score减去相应的值,比如ZINCRBY key -5 member,就是让member的score值减去5。当
key不存在,或member不是key的成员时,ZINCRBY key increment member等同于ZADD key increment member。当
key不是有序集类型时,返回一个错误。
score值可以是整数值或双精度浮点数。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++#集合topx中添加3个元素:java、c、c++,对应的score分别是:90、70、80
(integer)3
127.0.0.1:6379> zrevrange topx 0-1 withscores #输出集合topx中的元素,包含score
1)"java"
2)"90"
3)"c++"
4)"80"
5)"c"
6)"70"
127.0.0.1:6379> zincrby topx 5 java #对topx中的元素java的score加5,变成95了
"95"
127.0.0.1:6379> zrevrange topx 0-1 withscores # 输出集合元素,注意java的score是95了
1)"java"
2)"95"
3)"c++"
4)"80"
5)"c"
6)"70"
zrem:删除集合中多个元素
zrem key member [member ...]
移除有序集
key中的一个或多个成员,不存在的成员将被忽略。当
key存在但不是有序集类型时,返回一个错误。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++#集合topx中添加3个元素:java、c、c++,对应的score分别是:90、70、80
(integer)3
127.0.0.1:6379> zrange topx 0-1#输出集合topx中所有元素
1)"c"
2)"c++"
3)"java"
127.0.0.1:6379> zrem topx c c++#删除集合topx中的2个元素:c、c++
(integer)2
127.0.0.1:6379> zrange topx 0-1#输出集合topx中所有元素
1)"java"
zremrangebyrank:根据索引范围删除元素
zremrangebyrank key start stop
移除有序集
key中,指定排名(rank)区间内的所有成员。区间分别以下标参数
start和stop指出,包含start和stop在内。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。你也可以使用负数下标,以
-1表示最后一个成员,-2表示倒数第二个成员,以此类推。关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++#集合topx中添加3个元素:java、c、c++,对应的score分别是:90、70、80
(integer)3
127.0.0.1:6379> zrange topx 0-1#输出集合topx中所有元素
1)"c"
2)"c++"
3)"java"
127.0.0.1:6379> zremrangebyrank topx 01#删除索引范围[0,1]的数据
(integer)2
127.0.0.1:6379> zrange topx 0-1#输出topx中所有元素
1)"java"
zremrangebyscore:根据score的范围删除元素
zremrangebyscore key min max
移除有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++50 php #topx集合中添加4个元素
(integer)4
127.0.0.1:6379> zrange topx 0 -1 withscores #输出topx中所有元素值、score
1)"php"
2)"50"
3)"c"
4)"70"
5)"c++"
6)"80"
7)"java"
8)"90"
127.0.0.1:6379> zremrangebyscore topx 7080#删除score位于[70,80]区间的元素
(integer)2
127.0.0.1:6379> zrange topx 0 -1 withscores #输出剩下的元素
1)"php"
2)"50"
3)"java"
4)"90"
zcount:统计指定score范围内元素的个数
zcount key min max
返回有序集
key中,score值在min和max之间(默认包括score值等于min或max)的成员的数量
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++50 php #topx集合中添加4个元素
(integer)4
127.0.0.1:6379> zcount topx 80100#统计score位于[80,100]区间中的元素个数
(integer)2
zrank:按照score升序,返回某个元素在集合中的排名
zrank key member
返回有序集
key中成员member的排名。其中有序集成员按score值递增(从小到大)顺序排列。排名以
0为底,也就是说,score值最小的成员排名为0。关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++50 php #topx集合中添加4个元素
(integer)4
127.0.0.1:6379> zrank topx c #获取元素c的排名,返回1表示排名第2
(integer)1
127.0.0.1:6379> zrange topx 0-1#输出集合中所有元素,看一下c的位置确实是2
1)"php"
2)"c"
3)"c++"
4)"java"
zrevrank:按照score降序,返回某个元素在集合中的排名
返回有序集
key中成员member的排名。其中有序集成员按score值递减(从大到小)排序。排名以
0为底,也就是说,score值最大的成员排名为0。
示例
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++50 php #topx集合中添加4个元素
(integer)4
127.0.0.1:6379> zrange topx 0-1
1)"php"
2)"c"
3)"c++"
4)"java"
127.0.0.1:6379> zrevrank topx java #score降序,得到java的排名,排在第1位
(integer)0
zscore:返回集合中指定元素的score
zscore key member
返回有序集
key中,成员member的score值。如果
member元素不是有序集key的成员,或key不存在,返回nil。
127.0.0.1:6379> flushdb #清空db,方便测试
OK
127.0.0.1:6379> zadd topx 90 java 70 c 80 c++50 php #topx集合中添加4个元素
(integer)4
127.0.0.1:6379> zrange topx 0-1#输出topx集合所有元素
1)"php"
2)"c"
3)"c++"
4)"java"
127.0.0.1:6379> zscore topx java #获取集合topx中java的score
"90"
数据结构
SortedSet(zset)是redis提供的一个非常特别的数据结构,内部使用到了2种数据结构。
1、hash表
类似于java中的Map<String,score>,key为集合中的元素,value为元素对应的score,可以用来快速定位元素定义的score,时间复杂度为O(1)。
2、跳表
跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入、删除、查找的复杂度均为O(logN)。类似java中的ConcurrentSkipListSet,根据score的值排序后生成的一个跳表,可以快速按照位置的顺序或者score的顺序查询元素。
这里我们来看一下跳表的原理:
首先从考虑一个有序表开始:

从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉搜索树,我们把一些节点提取出来,作为索引。得到如下结构:

这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:

这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。

Redis概述和安装
Redis五种数据类型及命令操作(一)
IOC容器创建bean实例的4种方式
由表及里分析Spring-IOC容器始末
Spring中的核心概念
关于高并发你必须知道的几个概念
线程的创建方式对比与线程池相关原理剖析

相关文章:
Redis五种数据类型及命令操作(二)
🎈个人公众号:🎈 :✨✨✨ 可为编程✨ 🍟🍟 🔑个人信条:🔑 知足知不足 有为有不为 为与不为皆为可为🌵 🍉本篇简介:🍉 本篇记录Redis五种数据类型及命令操作,如…...
:MDA模型驱动架构及元数据系统设计)
低代码信创开发核心技术(三):MDA模型驱动架构及元数据系统设计
前言 写最后一篇文章的时候,我本人其实犹豫了半年,在想是否发布出这篇文章,因为可能会动了很多人的利益。所以这篇文章既是整个低代码信创开发的高度总结,也是最为精华的一部分,它点明了低代码中最为核心的技术。虽然…...
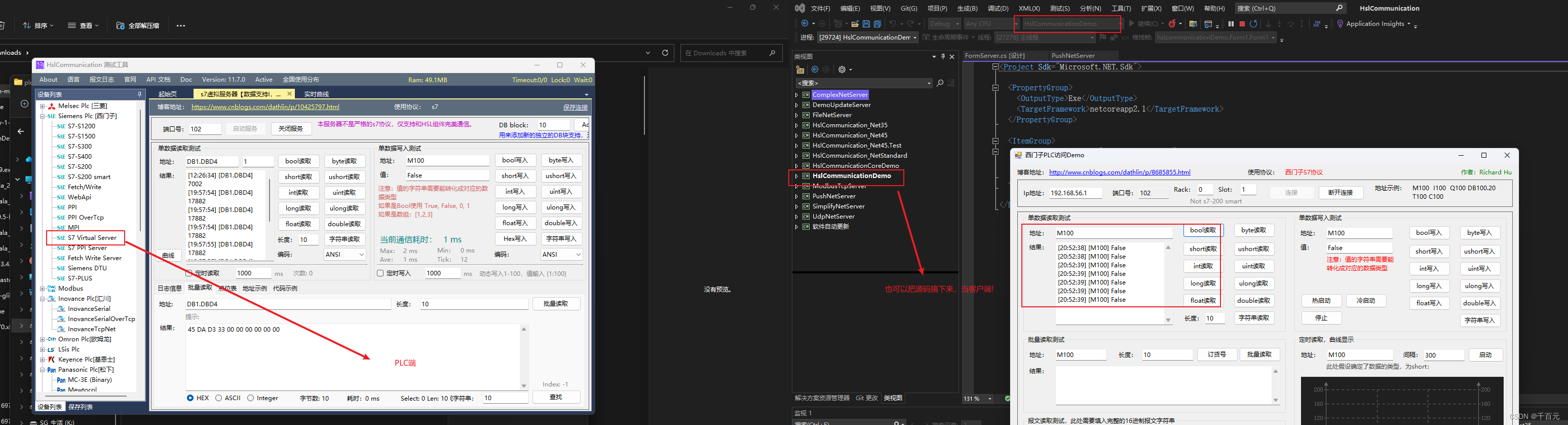
HslCommunication模拟西门子读写数据
导入HslCommunication C#端代码(上位机) 这里要注意的是上位机IP用的当前电脑的IP。 using HslCommunication; using HslCommunication.Profinet.Siemens; using System; using System.Collections.Generic; using System.ComponentModel; using Syste…...

多测师肖sir_高级金牌讲师_ui自动化po框架版本02
ui自动化po框架版本02 一、 pages下的BasePage.py模块 此模块是封装所有用例的基类 比如说:所有用例要用到的元素定位,以及输入框输入,点击,下拉等等公共方法import unittest #导入unittest 框架 from time import *# 调试代码…...
)
线性判别分析(Linear Discriminant Analysis,LDA)
Linear Discriminant Analysis(LDA) 输入: 原始数据$D((x_1,y_1),(x_2,y_2),...,(x_m,y_m)$ 、 类别标签$Y[y_1,y_2,...,y_n]$、 降维到的维度d输出: 投影矩阵W、投影后的样本$Z$、算法步骤: 1.计算类内散度…...
git的分支及标签使用及情景演示
目录 一. 环境讲述 二.分支 1.1 命令 1.2情景演练 三、标签 3.1 命令 3.2 情景演示 编辑 一. 环境讲述 当软件从开发到正式环境部署的过程中,不同环境的作用如下: 开发环境:用于开发人员进行软件开发、测试和调试。在这个环境中…...
深度解析找不到msvcp120.dll相关问题以及解决方法
在计算机使用过程中,我们经常会遇到一些错误提示,其中之一就是“msvcp120.dll丢失”。这个错误通常会导致某些应用程序无法正常运行,给用户带来很大的困扰。那么,如何解决msvcp120.dll丢失的问题呢?本文将为大家介绍…...
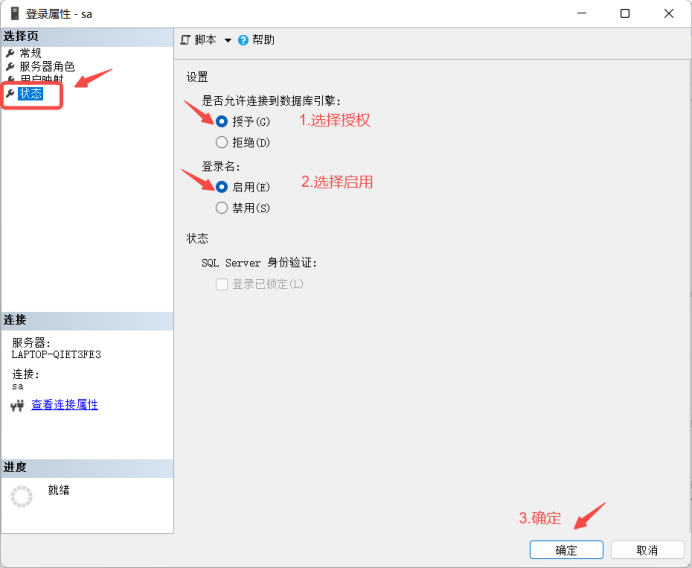
SQL Server 2022 安装步骤——SQL Server设置身份验证教程
目录 前言: 安装详细步骤: 第一步: 第二步: 第三步: 第四步: SQL Server 连接的方式: Window验证: SQL Server验证: 两者之间区别: 总结: SQL Server身份验证登录配置教程: 第一步: 第二步: 第三步: 番外篇: 前言: 本文讲解,如何安装SQL Server安…...

Maven各方面配置好了却无法显示版本
今天配置了maven环境,各方面都配置好了命令行却一直没办法显示maven的版本,原因 竟是两个JDK导致maven无法选择,因为maven依赖于JDK,导致在选择JDK的时候差生了二义 性,在环境变量里面删除不常用的JDK,只…...

Jdk 1.8 for mac 详细安装教程(含版本切换)
Jdk 1.8 for mac 详细安装教程(含版本切换) 官网下载链接 https://www.oracle.com/cn/java/technologies/downloads/#java8-mac 一、选择我们需要安装的jdk版本,这里以jdk8为例,下载 macOS 版本,M芯片下载ARM64版本…...
02MyBatisPlus条件构造器,自定义SQL,Service接口
一、条件构造器 1.MyBatis支持各种复杂的where条件,满足开发的需求 Wrapper是条件构造器,构建复杂的where查询 AbstractWrapper有构造where条件的所有方法,QueryWrapper继承后并有自己的select指定查询字段。UpdateWrapper有指定更新的字段的…...

c语言练习11周(6~10)
输入任意字串,将串中除了首尾字符的其他字符升序排列显示,串中字符个数最多20个。 题干 输入任意字串,将串中除了首尾字符的其他字符升序排列显示,串中字符个数最多20个。输入样例gfedcba输出样例gbcdefa 选择排序 #include<s…...
钉钉API与集简云无代码开发连接:电商平台与营销系统的自动化集成
连接科技与能源:钉钉API与集简云的一次集成尝试 在数字化时代,许多公司面临着如何将传统的工作方式转变为更智能、高效的挑战。某能源科技有限公司也不例外,他们是一家专注于能源科技领域的公司,产品包括节能灯具、光伏逆变器、电…...

C++算法:包含三个字符串的最短字符串
涉及知识点 有序集合 字符串 题目 给你三个字符串 a ,b 和 c , 你的任务是找到长度 最短 的字符串,且这三个字符串都是它的 子字符串 。 如果有多个这样的字符串,请你返回 字典序最小 的一个。 请你返回满足题目要求的字符串。…...

华为开源carbondata中的使用问题处理
carbondata中的使用问题处理 Q:什么是不良记录? A:由于数据类型不兼容而无法加载到CarbonData中的记录或为空或具有不兼容格式的记录被归类为不良记录。 Q:CarbonData中的不良记录存储在哪里? A:不良记录…...

AI:76-基于机器学习的智能城市交通管理
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...

区块链游戏,游戏开发
区块链游戏是一种基于区块链技术的新兴游戏类型,它具有去中心化、安全性高、透明度高、可追溯等特点。与传统的游戏开发相比,区块链游戏开发需要更多的技术和知识储备,同时也需要更加注重游戏本身的玩法和用户体验。 在区块链游戏中ÿ…...

单片机程序无法下载?
原因一:电源问题 电源可能是导致STM32微控制器无法下载程序的一个常见原因。确保电源稳定对于正常运行和下载程序至关重要。以下是一些电源问题: 1. 电源电压不足:如果STM32微控制器没有足够的电压供应,它可能无法正常工作或下载程…...

【数据库】【sql】如何用SQL实现跨行计算
【背景】 这里的跨行计算不是指整体聚合类的函数比如SUM等的功能,而是指递归算法。 比如我接到有需求,有一个结果字段需要是目前所有行该字段的和,这是属于递归类的算法,SQL中如何实现呢? 【方法】 可以使用窗口函数…...
)
Oracle(概念含安装)
Oracle是一种关系数据库管理系统(RDBMS),是由美国甲骨文公司(Oracle Corporation)开发的。它是一个客户端/服务器系统,可以在各种操作系统上运行,包括Windows、Linux和Unix等。Oracle的设计重点…...

Mac上使用Docker快速部署SQL Server指南
1. 为什么要在Mac上通过Docker运行SQL Server? 作为常年使用Mac的开发者,我最初也很困惑:微软的SQL Server明明是为Windows设计的,为什么要在macOS上折腾?直到接手了一个使用SQL Server作为数据库的老项目才明白——当…...
)
小白程序员也能看懂的大模型内部原理:从加减乘除到Llama 3.1(收藏版)
本文深入浅出地解析了大语言模型(LLM)的工作原理,从基础的加减乘除运算开始,逐步构建一个生成式AI,并最终理解现代LLM和Transformer架构。文章剥去了机器学习领域的复杂术语,将一切还原为数字,帮…...
)
GBase 8c数据库全链路精准降本详解(下)
南大通用GBase 8c数据库(gbase database)用五招硬核技术,从存储、内存、CPU到I/O,全链路精准降本。不是省钱降质,而是让每一分硬件投入都产生最大价值。3第三招:内存精准管控,不浪费每一兆内存价格居高不下…...

Spring Boot 3.2 集成 Shiro 2.0.1 踩坑实录:从 javax.servlet 到 jakarta.servlet 的完整迁移指南
Spring Boot 3.2 与 Shiro 2.0.1 深度整合实战:跨越 Jakarta EE 的兼容性鸿沟 当我们将项目从 Spring Boot 2.x 升级到 3.2 版本时,许多开发者都会遇到一个令人头疼的问题——原本运行良好的 Shiro 安全框架突然失效了。这背后隐藏着一个更深层次的变革&…...

DXVK深度解析:彻底解决GTA IV在Linux平台的纹理模糊问题终极指南
DXVK深度解析:彻底解决GTA IV在Linux平台的纹理模糊问题终极指南 【免费下载链接】dxvk Vulkan-based implementation of D3D8, 9, 10 and 11 for Linux / Wine 项目地址: https://gitcode.com/gh_mirrors/dx/dxvk DXVK是一个基于Vulkan的D3D8、9、10和11实现…...

新手程序员必看!用缓存优化RAG,让你的大模型知识库性能飙升,收藏学习!
本文介绍了RAG在大模型知识库中的应用及其面临的性能挑战,提出通过结果缓存、检索结果缓存和嵌入缓存等策略来优化RAG系统。文章强调缓存机制能有效提升响应速度、降低Token消耗,并阐述了构建高效知识缓存体系的原则,如冷热分层、设置TTL和监…...
_kaic)
weixin291基于微信小程序的家政服务预约系统的设计与实现+php(文档+源码)_kaic
第4章 系统详细实现 4.1登录功能模块的界面实现 在系统调试运行后,可以进入本界面&am…...

CLIP-GmP-ViT-L-14部署教程:Airflow调度定时批量图文匹配任务流
CLIP-GmP-ViT-L-14部署教程:Airflow调度定时批量图文匹配任务流 1. 项目概述 CLIP-GmP-ViT-L-14是一个经过几何参数化(GmP)微调的CLIP模型,在ImageNet和ObjectNet数据集上能达到约90%的准确率。这个强大的视觉语言模型可以帮助我们实现图片和文本之间的…...

保姆级教程:用VESTA软件5分钟搞定纳米颗粒Wulff Construction模型
5分钟玩转VESTA:科研小白的纳米颗粒建模可视化指南 在材料科学和计算化学领域,纳米颗粒的形貌预测一直是研究热点。想象一下,你刚完成一系列表面能计算,手握着宝贵的数据,却苦于无法直观展示这些抽象数字背后的三维结构…...

玻璃K值如何测试?
玻璃K值如何测试? 玻璃K值测试方法有测试+计算法、防护热板法/热流计法、标定热箱法、现场测试方法等,标准有JGJ/T 151、GB/T 2680、GB/T 22476、GB/T 10294、GB/T 8484、GB/T 36261等;经常有朋友咨询该用哪种方法、哪个标准?本期做个梳理,不妥之处敬请指正! 1、测试+计…...