MySQL join原理及优化
MySQL的JOIN原理是基于索引和算法的。在执行JOIN查询时,MySQL会根据连接字段上的索引来查找匹配的记录。
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。
在进行JOIN查询时,MySQL还采用了一些优化策略来提高查询性能,例如使用嵌套循环连接算法(Nested-Loop Join)和索引优化技术。
嵌套循环连接算法按照指定的连接方式执行查询,不会自己选择驱动表。当连接字段上有索引时,MySQL会使用索引来加速查找过程
Join 算法
使用 left join 时,左边的表不一定是驱动表,优化器可能会将语句优化为join。如果需要 left join 的语义,就不能把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,必须都写在 on 里面
为了便于量化分析各种Join 算法,以下创建两个表 t1 和 t2 来说明
CREATE TABLE `t2` (`id` int(11) NOT NULL,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `a` (`a`)
) ENGINE=InnoDB;drop procedure idata;
delimiter ;;
create procedure idata()
begindeclare i int;set i=1;while(i<=1000)doinsert into t2 values(i, i, i);set i=i+1;end while;
end;;
delimiter ;
call idata();create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
可以看到,这两个表都有一个主键索引 id 和一个索引 a,字段 b 上无索引。存储过程 idata() 往表 t2 里插入了 1000 行数据,在表 t1 里插入的是 100 行数据
Index Nested-Loop Join
select * from t1 straight_join t2 on (t1.a=t2.a);
为了便于分析执行过程中的性能问题,我改用straight_join让 MySQL 使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去 join。在这个语句里,t1 是驱动表,t2 是被驱动表
如果直接使用 join 语句,MySQL 优化器可能会选择表 t1 或 t2 作为驱动表,这样会影响我们分析 SQL 语句的执行过程

INL算法步骤为先遍历表 t1,然后根据从表 t1 中取出的每行数据中的 a 值,去表 t2 中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引

查询复杂度
在INL算法程中,驱动表是走全表扫描,而被驱动表是走树搜索
假设被驱动表的行数是 M。每次在被驱动表查一行数据,要先搜索索引 a,再搜索主键索引。每次搜索一棵树近似复杂度是以 2 为底的 M 的对数,记为 l o g 2 M log_2M log2M,所以在被驱动表上查一行的时间复杂度是 2 ∗ l o g 2 M 2 * log_2M 2∗log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是 N + N ∗ 2 ∗ l o g 2 M N + N* 2*log_2M N+N∗2∗log2M
Simple Nested-Loop Join
select * from t1 straight_join t2 on (t1.a=t2.b);
若把SQL 语句改成这样,由于表 t2 的字段 b 上没有索引,因此再用上图的执行流程时,每次到 t2 去匹配的时候,就要做一次全表扫描。复杂度是 M * N。这个 SQL 请求就要扫描表 t2 多达 100 次,总共扫描 100*1000=10 万行
MySQL 没有使用 Simple Nested-Loop Join 算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称 BNL
Block Nested-Loop Join
join_buffer是一个用于存储连接操作(join)中临时数据的缓冲区。当执行连接操作时,MySQL将从连接的表中读取数据,并临时存储在join_buffer中,以便执行连接操作的计算和比较
当被驱动表上没有可用的索引,算法的流程是这样的
- 把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是
select *,因此是把整个表 t1 放入了内存; - 扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 JOIN 条件的,作为结果集的一部分返回
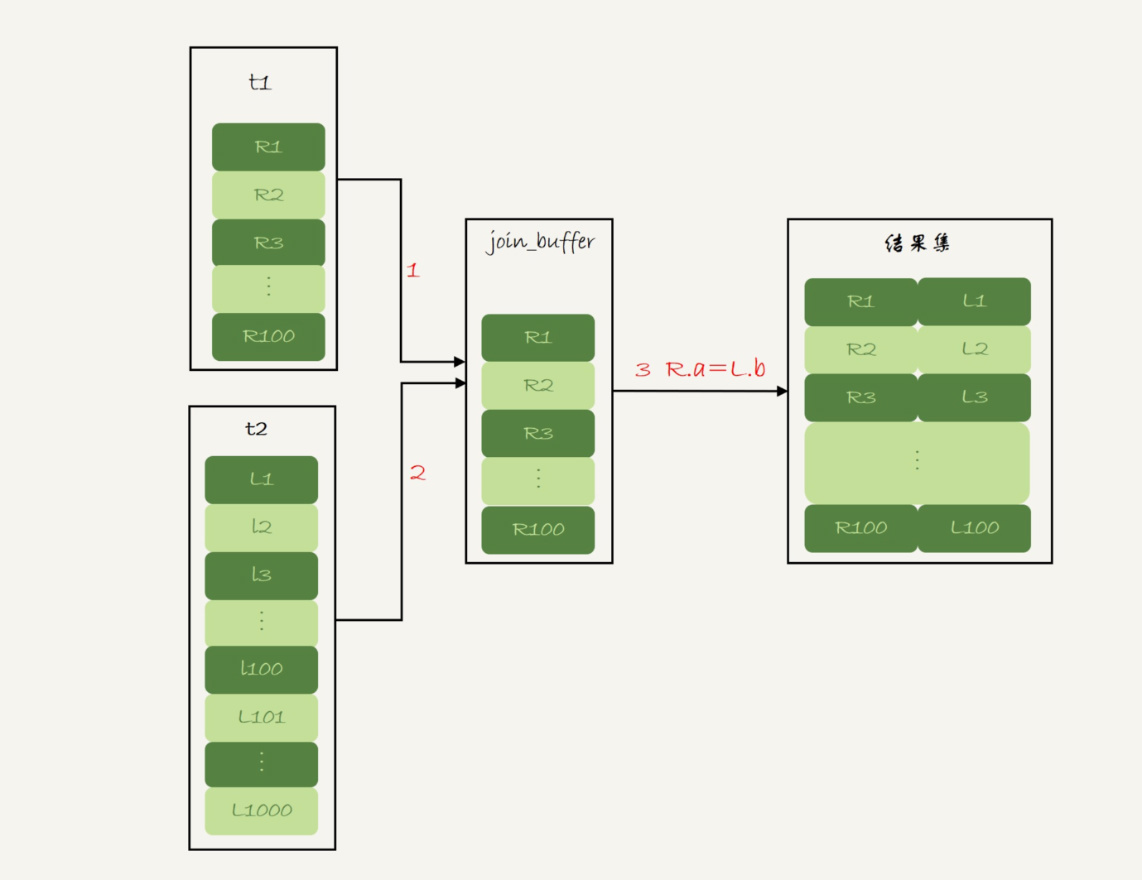

可以看到,在这个过程中,对表 t1 和 t2 都做了一次全表扫描,因此总的扫描行数是 1100。由于 join_buffer 是以无序数组的方式组织的,因此对表 t2 中的每一行,都要做 100 次判断,总共需要在内存中做的判断次数是:100*1000=10 万次
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。 如果放不下表 t1 的所有数据话,策略很简单,就是分块放
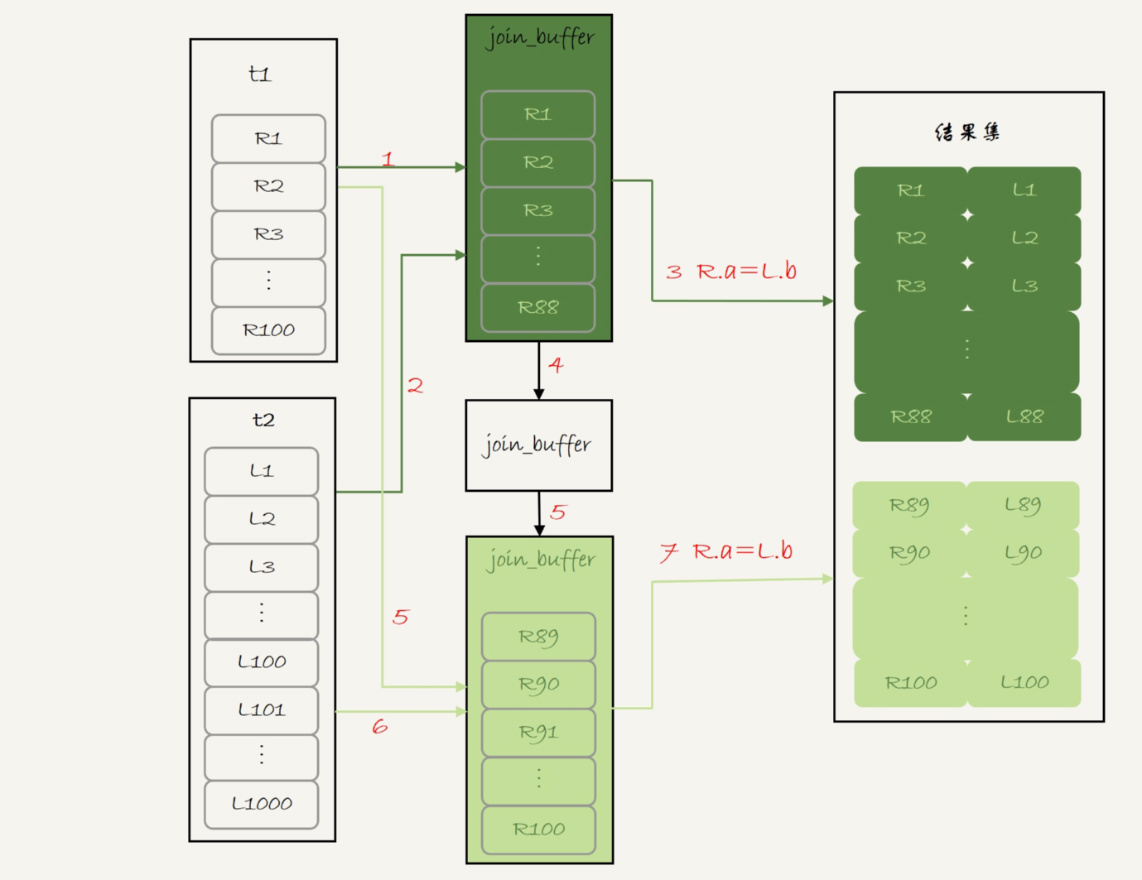
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。
注意,这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。
所以,在这个算法的执行过程中:
- 扫描行数是 N+λNM;
- 内存判断 N*M 次
SNL与BNL对比
SNL/BNL 算法对系统的影响主要包括三个方面:
- 可能会多次扫描被驱动表,占用磁盘 IO 资源;
- 判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源;
- 可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率
大表 join 操作虽然对 IO 有影响,但是在语句执行结束后,对 IO 的影响也就结束了。但是,对 Buffer Pool 的影响就是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率。
为了减少这种影响,可以考虑增大join_buffer_size的值,减少对被驱动表的扫描次数
BNL 算法的执行逻辑是:将驱动表的数据全部读入内存 join_buffer 中,然后将连接操作划分为多个块,每个块包含一定数量的记录。每一行数据都跟 join_buffer 中的数据进行匹配,匹配成功则作为结果集的一部分返回。
SNL 算法的执行逻辑是:顺序取出驱动表中的每一行数据,到被驱动表去做全表扫描匹配,匹配成功则作为结果集的一部分返回
BNL算法在处理连接操作时采用了块状处理和索引优化技术(转为BKA),使得它在处理大规模数据时能够比SNL算法更快地完成查询操作
Batched Key Access
理解了 MRR 性能提升的原理,我们就能理解 MySQL 在 5.6 版本后开始引入的 Batched KEY Access(BKA) 算法了。这个 BKA 算法,其实就是对 NLJ 算法的优化
join_buffer 在 BNL 算法里的作用,是暂存驱动表的数据。在 NLJ 算法复用 join_buffer ,就优化为BKA 算法了
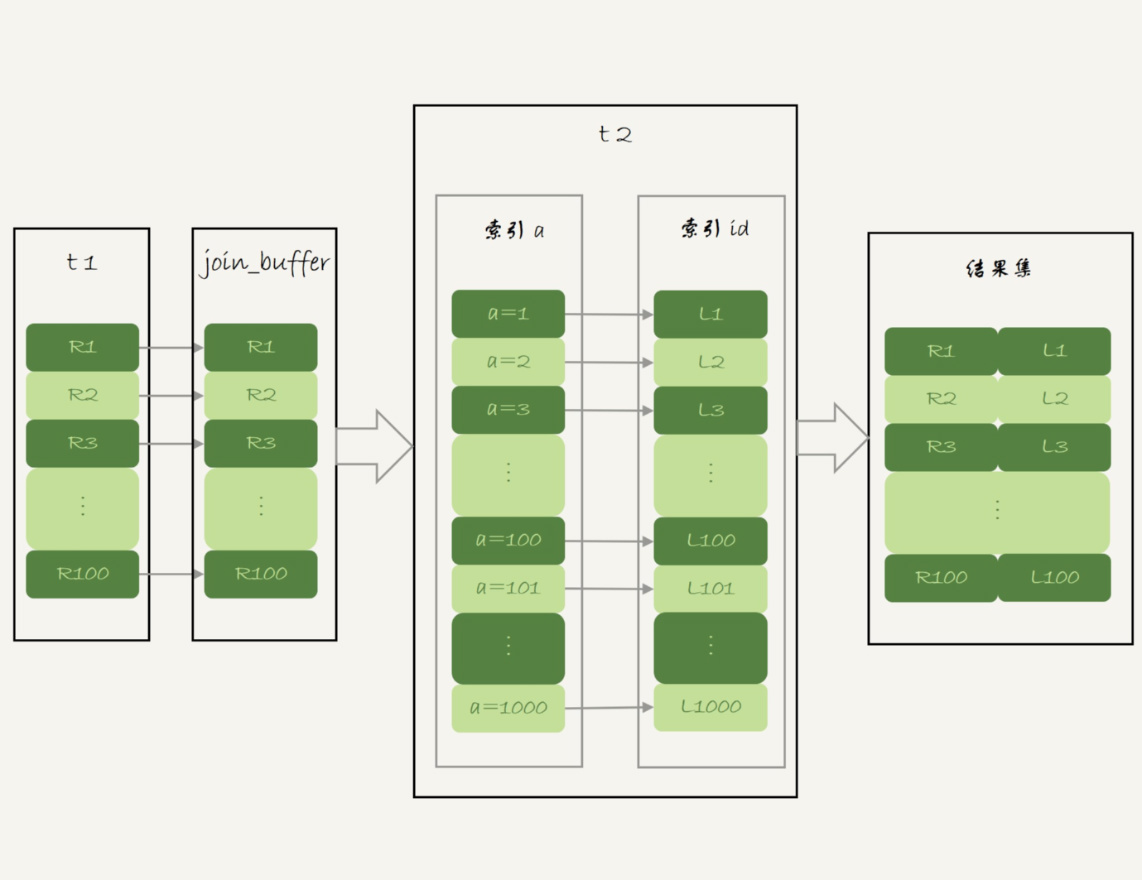
图中在 join_buffer 中放入的数据是 R1~R100,表示的是只会取查询需要的字段。当然,如果 JOIN buffer 放不下 R1~R100 的所有数据,就会把这 100 行数据分成多段执行上图的流程
使用 BKA 优化算法,需要在执行 SQL 语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中,前两个参数的作用是要启用 MRR。这么做的原因是,BKA 算法的优化要依赖于 MRR
Join 优化
Multi-Range Read 优化
Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升。Multi-Range Read优化可适用于range,ref,eq_ref类型的查询
MRR优化的优点及工作方式详见 MRR优化
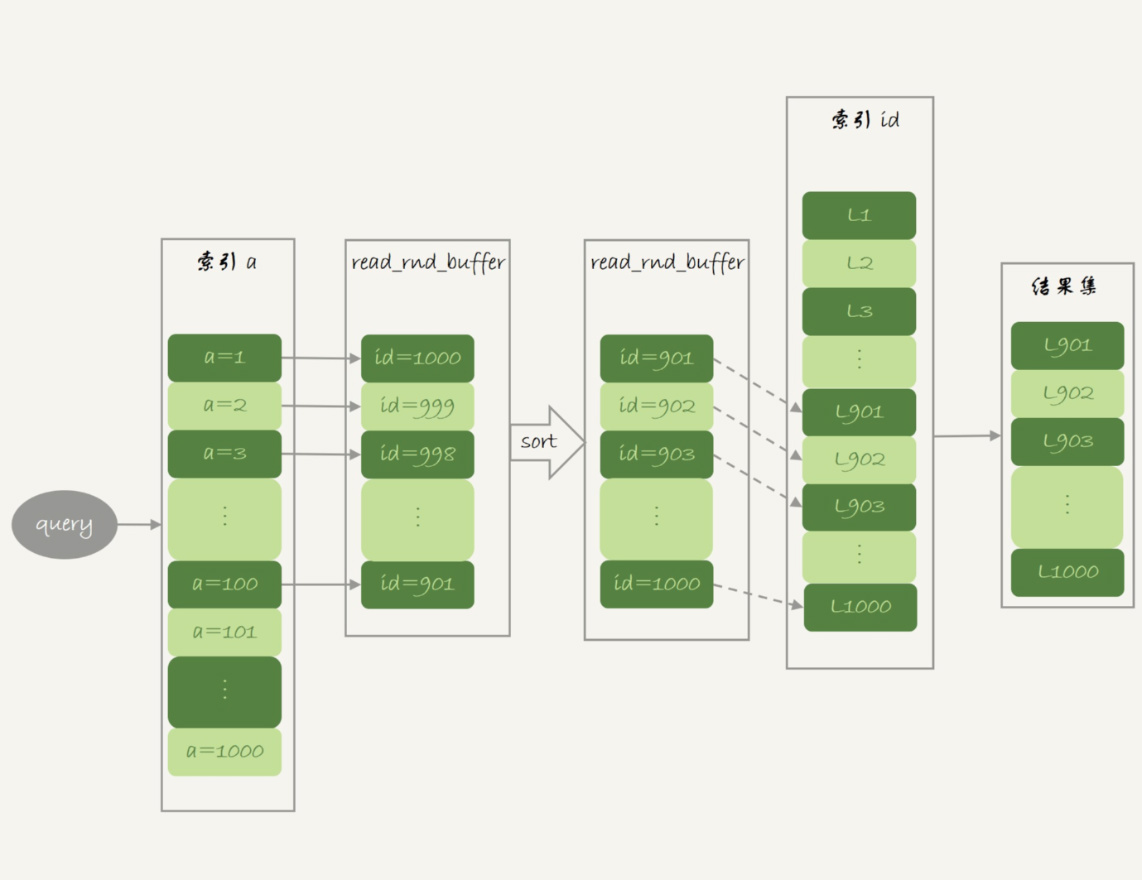
如果随着 a 的值递增顺序查询的话,id 的值就变成随机的,那么就会出现随机访问,性能相对较差。而通过MRR优化后,会将满足条件的记录id值放入read_rnd_buffer中,再讲id进行递增排序后依次查记录并返回结果。执行流程如下图所示
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能

BNL 转 BKA
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;

对于表 t2 的每一行,判断 JOIN 是否满足的时候,都需要遍历 join_buffer 中的所有行。因此判断等值条件的次数是 1000*100 万 =10 亿次,这个判断的工作量很大
对于这种不适合在被驱动表上建索引的情况,可以考虑使用临时表
大致思路是:
- 把表 t2 中满足条件的数据放在临时表 tmp_t 中;
- 为了让 JOIN 使用 BKA 算法,给临时表 tmp_t 的字段 b 加上索引;
- 让表 t1 和 tmp_t 做 JOIN 操作
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
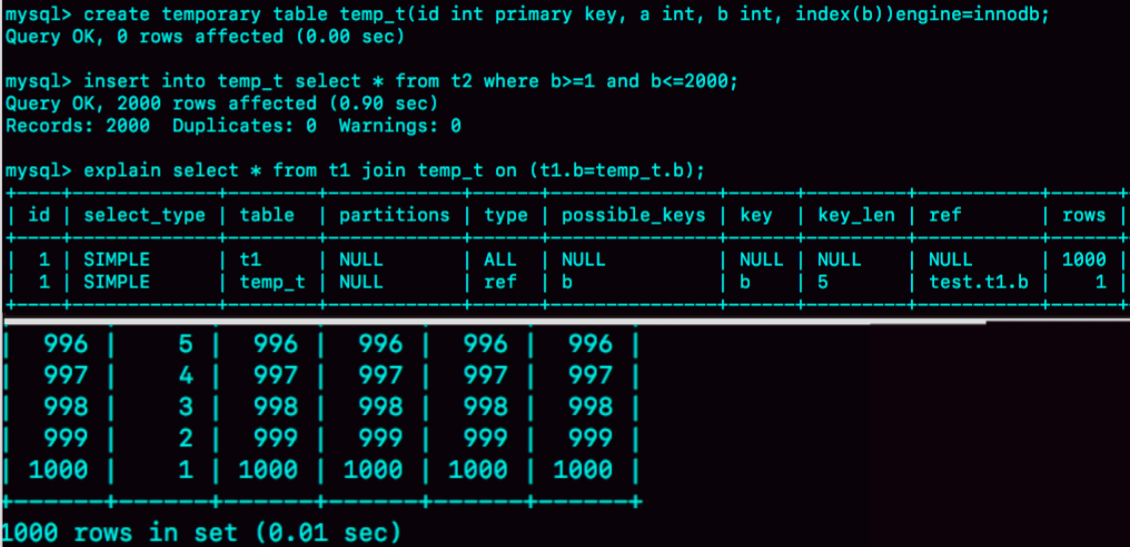
总体来看,不论是在原表上加索引,还是用有索引的临时表,我们的思路都是让 JOIN 语句能够用上被驱动表上的索引,来触发 BKA 算法,提升查询性能
Hash join
业务多次查询,再到hash结构的数据表中寻找匹配的数据
对于上面计算 10 亿次那个操作,看上去有点儿傻。如果 join_buffer 里面维护的不是一个无序数组,而是一个哈希表的话,那么就不是 10 亿次判断,而是 100 万次 HASH 查找
然而 MySQL 的优化器和执行器一直被诟病的一个原因:不支持哈希 join。所以将两个表的数据分别查询,在业务中组合匹配的效率其实更高
流程大致如下:
select * from t1;取得表 t1 的全部 1000 行数据,在业务端存入一个 HASH 结构,比如 C++ 里的 set、PHP 的数组这样的数据结构。select * from t2 where b>=1 and b<=2000;获取表 t2 中满足条件的 2000 行数据。- 把这 2000 行数据,一行一行地取到业务端,到 HASH 结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行。
总结
- .两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表
- 如果可以使用被驱动表的索引,join 语句还是有其优势的
- BKA 优化是 MySQL 已经内置支持的,建议默认使用
- BNL 算法效率低,建议你都尽量转成 BKA 算法。优化的方向就是给被驱动表的关联字段加上索引
- 基于临时表的改进方案,对于能够提前过滤出小数据的 join 语句来说,效果还是很好的
- MySQL 目前的版本还不支持 hash join,但你可以配合应用端自己模拟出来,理论上效果要好于临时表的方案
参考资料:
- MySQL 四十五讲——到底可不可以使用join?
- MySQL 四十五讲——join语句怎么优化
- MySQL 四十五讲——join的写法
- MRR优化
相关文章:
MySQL join原理及优化
MySQL的JOIN原理是基于索引和算法的。在执行JOIN查询时,MySQL会根据连接字段上的索引来查找匹配的记录。 这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就…...

js案例:打地鼠游戏(打灰太狼)
效果预览图 游戏规则 当灰太狼出现的时候鼠标左键点击灰太狼加10分,小灰灰出现的时候鼠标左键点小灰灰击减10分,不点击不减分不加分。 整体思路 1.把获取背景图片中每个地洞的位置,把所有位置放到一个数组中。 2.封装随机数函数,随…...
删除杀软回调 bypass EDR 研究
01 — 杀软或EDR内核回调简介 Windows x64 系统中,由于 PatchGuard 的限制,杀软或EDR正常情况下,几乎不能通过 hook 的方式,完成其对恶意软件的监控和查杀。那怎么办呢?别急,微软为我们提供了其他的方法&a…...

Ansible自动化部署工具-组件及语法介绍
大家好,我是蓝胖子,我认为自动化运维要做的事情就是把运维过程中的某些步骤流程化,代码化,这样在以后执行类似的操作的时候就可以解放双手了,让程序自动完成。避免出错,Ansible就是这方面非常好用的工具。它…...
postgresql实现job的六种方法
简介 在postgresql数据库中并没有想oracle那样的job功能,要想实现job调度,就需要借助于第三方。本人更为推荐kettle,pgagent这样的图形化界面,对于开发更为友好 优势劣势Linux 定时任务(crontab) 简单易用…...

layui 表格(table)合计 取整数
第一步 开启合计行 是否开启合计行区域 table.render({elem: #myTable, url: ../baidui/, page: true, cellMinWidth: 100,totalRow:true,cols: [[ //表头//{ type: checkbox },{ type: checkbox,totalRowText: "合计" },//合计行区域{ field: id, align: center,…...

深入理解 TCP;场景复现,掌握鲜为人知的细节
握手失败 第一次握手丢失了,会发生什么? 当客户端想和服务端建立 TCP 连接的时候,首先第一个发的就是 SYN 报文,然后进入到 SYN_SENT 状态。 在这之后,如果客户端迟迟收不到服务端的 SYN-ACK 报文(第二次…...

【MySQL系列】 第二章 · SQL(中)
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...

IBM Qiskit量子机器学习速成(一)
声明:本篇笔记基于IBM Qiskit量子机器学习教程的第一节,中文版译文详见:https://blog.csdn.net/qq_33943772/article/details/129860346?spm1001.2014.3001.5501 概述 首先导入关键的包 from qiskit import QuantumCircuit from qiskit.u…...

音视频基础知识
图像(YUV RGB) 这个讲的比较好 RGB颜色编码 图像显示主要是由像素组成,每个像素点的颜色组成都是采用RGB格式,RGB就是红、绿、蓝,RGB分别取不同的值,展示不同的颜色。 YUV…...
ida81输入密码验证算法分析以及破解思路
本文分析了ida81对输入密码的验证流程,分别对输入密码到生成解密密钥、密码素材的生成过程以及文件数据的加密过程这三个流程进行分析,并尝试找一些可利用的破绽。很遗憾,由于水平有限,目前也只是有个思路未能完全实现,…...
C语言——贪吃蛇
一. 游戏效果 贪吃蛇 二. 游戏背景 贪吃蛇是久负盛名的游戏,它也和俄罗斯⽅块,扫雷等游戏位列经典游戏的⾏列。 贪吃蛇起源于1977年的投币式墙壁游戏《Blockade》,后移植到各种平台上。具体如下: 起源。1977年,投币式…...

Android sqlite 使用简介
进行Android应用开发时经常会用到数据库。Android系统支持sqlite数据库,在app开发过程中很容易通过SQLiteOpenHelper使用数据库,SQLiteOpenHelper依赖于Context对象,但是基于uiatomator1.0和Java程序等无法获取Context的应用如何使用数据库呢…...
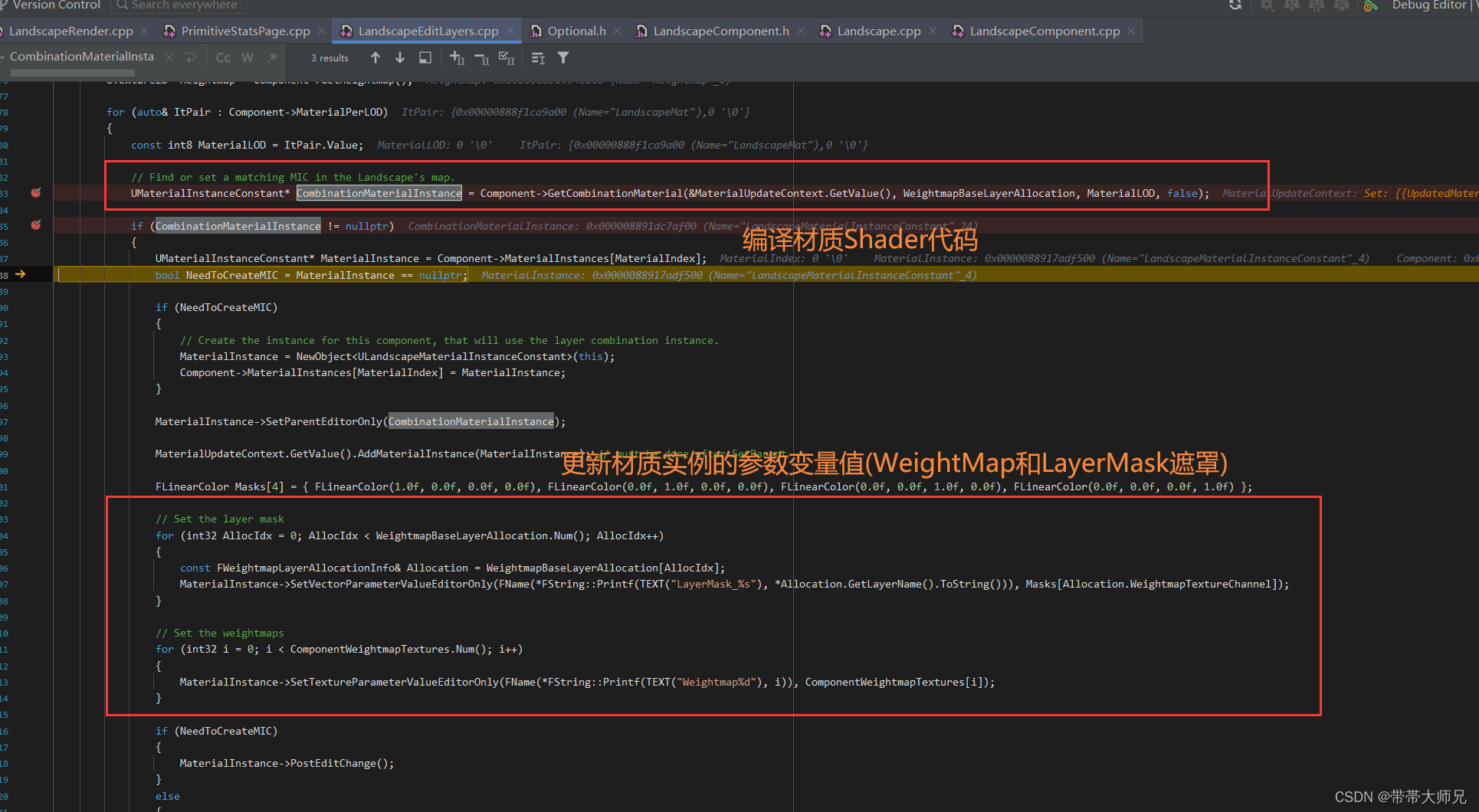
UE地形系统材质混合实现和Shader生成分析(UE5 5.2)
前言 随着电脑和手机硬件性能越来越高,游戏越来越追求大世界,而大世界非常核心的一环是地形系统,地形系统两大构成因素:高度和多材质混合,此篇文章介绍下UE4/UE5 地形的材质混合方案----基于WeightMap混合。 材质层 …...

Git分支与Git标签的介绍及其场景应用
目录 一、Git分支 1.1 定义 1.2 基本概念 1.3 特点与优势 1.4 Git分支操作命令 1.4.1 查看分支 1.4.2 创建分支 1.4.3 删除分支 1.4.4 切换分支 1.4.5 创建并切换到新建分支 1.5 场景应用 1.5.1 前期准备 1.5.2 具体操作 二、Git标签 2.1 定义 2.2 类型 2.3 标…...

Three.js——基于原生WebGL封装运行的三维引擎
文章目录 前言一、什么是WebGL?二、Three.js 特性 前言 Three.js中文官网 Three.js是基于原生WebGL封装运行的三维引擎,在所有WebGL引擎中,Three.js是国内文资料最多、使用最广泛的三维引擎。既然Threejs是一款WebGL三维引擎,那么…...

第八章认识Express框架
目录 Express模块化路由 基本概述 基本使用 基本构建 案例项目 Express接收请求参数 基本概述 基本类别 Express接收GET请求参数 Express接收POST请求参数 Express接收路由参数 Express模块化路由 基本概述 在Express中,路由是指确定应用程序如何响应对…...

【K8s集群离线安装-kubeadm】
1、kubeadm概述 kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。这个工具能通过两条指令快速完成一个kubernetes集群的部署。 2、环境准备 2.1 软件环境 软件版本操作系统CentOS 7Docker19.03.13K8s1.23 2.2 服务器 最小硬件配置:2核CPU、2G内存…...
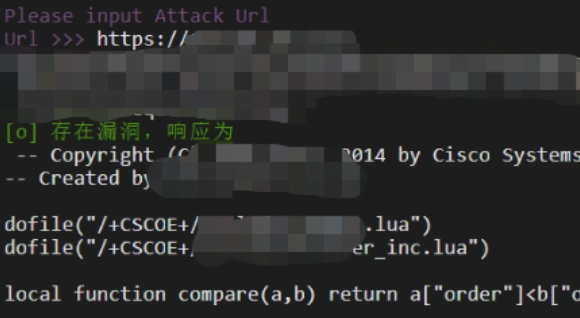
python工具CISCO ASA设备任意文件读取
python漏洞利用 构造payload: /CSCOT/translation-table?typemst&textdomain/%2bCSCOE%2b/portal_inc.lua&default-language&lang../漏洞证明: 文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。 免…...

TCP关闭的两种方法概述
一个TCP需要经过四次挥手才可以关闭连接,能够开启四次挥手的函数有两个: int close(int sockfd) int shutdown(int sockfd,int howto) 接下来就分别讲解一下这两个函数。 close()函数 函数原型 #include<unistd.h> int close(int sockfd)这个函…...

SITS2026首席架构师亲授:从代码提交率到AI协作熵值——用4类文化指标量化研发团队AI就绪度
第一章:SITS2026演讲:AI原生研发的文化变革 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026主会场,来自全球17家头部科技企业的工程负责人共同指出:AI原生研发已不再仅是工具升级,而是一场覆盖协作范式、质…...

5步轻松升级:让2008-2017年Intel Mac运行最新macOS的完整指南
5步轻松升级:让2008-2017年Intel Mac运行最新macOS的完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为苹果官方不再支持的老款Mac而…...

springboot基于微信小程序的个人记账本 论文
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分数据统计模块扩展功能模块技术实现要点创新性设计方向项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用户管理模…...

STM32N6开发板跑YOLOv8人脸检测,从模型转换到烧录的‘避坑’实战记录
STM32N6开发板部署YOLOv8人脸检测的十二个致命陷阱与突围方案 当我在深夜第三次面对开发板毫无反应的LCD屏幕时,咖啡杯旁的示波器探头正闪烁着诡异的蓝光。这不是教科书上的标准流程演示,而是一场真实发生在嵌入式AI部署前线的技术突围战。STM32N6这颗搭…...

基于Carsim与Simulink联合仿真的汽车ESP系统单侧双轮制动控制模型与说明
汽车ESP系统仿真建模,基于carsim与simulink联合仿真做的联合仿真,采用单侧双轮制动的控制方法。 有完整的模型和说明 汽车电子稳定程序(ESP)就像车辆的"防上头助手",关键时刻一把拽住快要失控的车身。但要让…...

3大优化策略:霞鹜文楷屏幕阅读版字体解决数字时代视觉疲劳难题
3大优化策略:霞鹜文楷屏幕阅读版字体解决数字时代视觉疲劳难题 【免费下载链接】LxgwWenKai-Screen LXGW WenKai for Screen Reading. 项目地址: https://gitcode.com/gh_mirrors/lx/LxgwWenKai-Screen 你是否经常在长时间面对屏幕后感到眼睛干涩、视觉疲劳&…...

claw-code 源码分析:大型移植的测试哲学——如何用 unittest 门禁守住「诚实未完成」的口碑?
涉及源码:tests/test_porting_workspace.py、src/setup.py、src/parity_audit.py、src/main.py、src/hooks/__init__.py、src/execution_registry.py;对照 Rust rust/crates/compat-harness 中「无夹具则早退」的测试写法。1. 门禁长什么样:单…...

WordPress AI评论插件V1.3:智能互动与自动化管理实战指南
1. WordPress AI评论插件V1.3的核心价值 如果你运营着一个WordPress网站,可能经常为评论区冷清而头疼。手动维护互动耗时耗力,而垃圾评论又让人防不胜防。这正是AI评论插件V1.3要解决的问题——我用这个插件三个月,网站互动量提升了217%&…...

我“调教”了一个AI Agent,让它全天自动写测试用例:3分钟24条,准确率70%+
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中…...

Mermaid:基于文本驱动的图表生成架构,重塑技术文档的可视化协作范式
Mermaid:基于文本驱动的图表生成架构,重塑技术文档的可视化协作范式 【免费下载链接】mermaid Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown 项目地址: https://gitcode.com/GitHub_Trend…...